优云智算镜像社区 - 海量AI模型一键部署
默认排序
视频生成


LTX-2.3视频生成合集!支持文生视频、图生视频、数字人视频等
 284
284@与AI同行
 认证作者
认证作者 4308
4308 10896H
10896H更新时间:2026-05-30
 支持自启动
支持自启动开源版Sora2发布,LTX-2.3整合包合集,支持文生视频、图生视频、数字人!支持20s视频、1080P视频直出、批量队列生成、高清放大!
开源版Sora2发布,LTX-2.3整合包合集,支持文生视频、图生视频、数字人!支持20s视频、1080P视频直出、批量队列生成、高清放大!
数字人

LiveTalking
117@lipku
认证作者431380075H更新时间:2026-06-16
支持自启动LiveTalking镜像提供实时交互数字人解决方案,支持ERNerf、MuseTalk、Wav2Lip,实现单张人脸照片驱动的超低延迟(<100ms)唇形同步、表情及头部运动控制。
LiveTalking镜像提供实时交互数字人解决方案,支持ERNerf、MuseTalk、Wav2Lip,实现单张人脸照片驱动的超低延迟(<100ms)唇形同步、表情及头部运动控制。
数字人

最强AI数字人InfiniteTalk-图片和视频数字人
619@与AI同行
认证作者1541698636H更新时间:2026-03-31
支持自启动支持图片数字人、视频数字人、双人数字人,支持说话+唱歌对口型、长视频、完整歌曲生成、批量生成、高清放大!
支持图片数字人、视频数字人、双人数字人,支持说话+唱歌对口型、长视频、完整歌曲生成、批量生成、高清放大!
语音合成语音克隆

SVC-Fusion
128@aiguoliuguo
认证作者772743445H更新时间:2026-06-29
本整合包将整合So-Vits-SVC4.1、RVC、DDSP-SVC-6.3/6.1/6.0、ReFlow-VAE-SVC多种SVC模型训练及推理
本整合包将整合So-Vits-SVC4.1、RVC、DDSP-SVC-6.3/6.1/6.0、ReFlow-VAE-SVC多种SVC模型训练及推理
ComfyUI图片生成

RedCraft-Krea-2-GGUF,红潮特化,洗图,文生图,自定义lora,图生图,自定义提示词,8G显存可用,支持50系,批量任务队列
2@刘悦的技术博客
认证作者109H更新时间:2026-07-05
支持自启动RedCraft-Krea-2-GGUF,红潮特化,洗图,文生图,自定义lora,图生图,自定义提示词,8G显存可用,支持50系,批量任务队列
RedCraft-Krea-2-GGUF,红潮特化,洗图,文生图,自定义lora,图生图,自定义提示词,8G显存可用,支持50系,批量任务队列
其他

sora2文生视频、图生视频工作流
105@鸡你太美
认证作者4201727H更新时间:2026-07-05
支持自启动修改img-all六分钱模型香蕉出图模型生成报错问题
修改img-all六分钱模型香蕉出图模型生成报错问题
数字人语音合成视频生成

织梦智能体-数字人合成-语音合成-超级混剪
0@织梦智能体
00H更新时间:2026-07-06
支持自启动全网最牛逼最便宜的口播智能体,没有之一
全网最牛逼最便宜的口播智能体,没有之一
视频生成

超强AI生成视频,Wan2.2 Remix-V3,效果优质!图生视频 | 首尾帧视频 | 高清放大 | 视频插帧 | 批量生成
32@与AI同行
认证作者229100H更新时间:2026-07-03
支持自启动超强AI生成视频,Wan2.2 Remix-V3,效果优质!图生视频 | 首尾帧视频 | 高清放大 | 视频插帧 | 批量生成
超强AI生成视频,Wan2.2 Remix-V3,效果优质!图生视频 | 首尾帧视频 | 高清放大 | 视频插帧 | 批量生成
图片生成图片编辑

免费版GPT-Image2,Krea2高质量版,超强图片细节美感!图生图洗图 | 高清放大 | 支持LoRA
3@与AI同行
认证作者218H更新时间:2026-07-03
支持自启动免费版GPT-Image2,Krea2高质量版,超强图片细节美感!生图洗图 | 高清放大 | 支持LoRA
免费版GPT-Image2,Krea2高质量版,超强图片细节美感!生图洗图 | 高清放大 | 支持LoRA
语音合成Qwen3-TTSAI电商

【VoxCPM2/Qwen3TTS/IndexTTS2/OmniVoice】N合一AI语音整合TTS ALL in ONE
103@淼淼爸的ai笔记
认证作者13407840H更新时间:2026-07-04
支持自启动本镜像专为AI语音直播项目打造,也可以直接在线推理webui使用,集成VoxCPM2/IndexTTS-2等, 支持API调用,直播带货,tiktok直播,在线克隆,语气语调自然,音色还原度高
本镜像专为AI语音直播项目打造,也可以直接在线推理webui使用,集成VoxCPM2/IndexTTS-2等, 支持API调用,直播带货,tiktok直播,在线克隆,语气语调自然,音色还原度高
ComfyUI图片生成图片编辑

Boogu-Image-fix-4step,文生图,图像修改,8G显存可用,支持50系,批量任务队列
1@刘悦的技术博客
认证作者63H更新时间:2026-07-03
支持自启动Boogu-Image-fix-4step,文生图,图像修改,8G显存可用,支持50系,批量任务队列
Boogu-Image-fix-4step,文生图,图像修改,8G显存可用,支持50系,批量任务队列
语音合成SVCAI音乐

So-VITS-SVC-CU128 (即开即用, 无需部署)
2@SHthemW
认证作者11H更新时间:2026-07-02
So-VITS-SVC的2026全新Fork, 已经预配置好环境, 开箱即用. 支持Cuda12.8和RTX50系显卡, 训练/推理速度大大加快!
So-VITS-SVC的2026全新Fork, 已经预配置好环境, 开箱即用. 支持Cuda12.8和RTX50系显卡, 训练/推理速度大大加快!
文本模型

长篇小说&有声小说工作站
0@IAI666
00H更新时间:2026-07-02
支持自启动AI驱动的长篇小说创作与有声书生成工作站,支持大纲管理、角色系统、AI续写、质量审阅和语音合成全流程。
AI驱动的长篇小说创作与有声书生成工作站,支持大纲管理、角色系统、AI续写、质量审阅和语音合成全流程。
语音合成

VoxCPM2 ONNX版本
1@雨落实战
认证作者177H更新时间:2026-07-02
支持自启动VoxCPM2 ONNX加速版
VoxCPM2 ONNX加速版
OCR识别

Unlimited-OCR文本识别
0@鹄仙
认证作者20H更新时间:2026-06-30
Unlimited-OCR文本识别
Unlimited-OCR文本识别
ComfyUI图片生成Lora训练

Aitookit_krea2_lora_training
4@有趣的80后程序员
认证作者1710H更新时间:2026-06-30
支持自启动Krea2 Lora 训练镜像,包含模型,数据集以及一次训练结果
Krea2 Lora 训练镜像,包含模型,数据集以及一次训练结果
ComfyUI图片生成Qwen-Image

Anima Omni 动漫插画全能镜像
3@AI-KSK
认证作者147H更新时间:2026-07-01
支持自启动Anima Omni 动漫插画全能镜像内置20套精选工作流,覆盖基础出图、极速生成、NAG增强、LLLite控制、区域构图、局部重绘、脸手修复、风格混合、高清修复与分块放大。
Anima Omni 动漫插画全能镜像内置20套精选工作流,覆盖基础出图、极速生成、NAG增强、LLLite控制、区域构图、局部重绘、脸手修复、风格混合、高清修复与分块放大。
语音合成AI音乐

RVC-WebUI
15@乔大峰
认证作者224916H更新时间:2026-07-01
RVC-WebUI网页端训练镜像支持RVC/Replay翻唱模型/变声器
RVC-WebUI网页端训练镜像支持RVC/Replay翻唱模型/变声器
目标检测

ultralytics
1@muyulin
00H更新时间:2026-06-29
Ultralytics模型基于深度学习和计算机视觉其精简的设计,该镜像可以实现YOLOv8,YOLOv9,YOLOv10,YOLOv11,YOlOv26模型的应用
Ultralytics模型基于深度学习和计算机视觉其精简的设计,该镜像可以实现YOLOv8,YOLOv9,YOLOv10,YOLOv11,YOlOv26模型的应用
ComfyUI图片生成图片编辑

Krea-2-GGUF,洗图,文生图,自定义lora,图生图,No-Safety-Filter,8G显存可用,支持50系,批量任务队列
6@刘悦的技术博客
认证作者5847H更新时间:2026-06-28
支持自启动Krea-2-GGUF,洗图,文生图,自定义lora,图生图,No-Safety-Filter,8G显存可用,支持50系,批量任务队列
Krea-2-GGUF,洗图,文生图,自定义lora,图生图,No-Safety-Filter,8G显存可用,支持50系,批量任务队列
ComfyUILTX视频生成

ComfyUI
5@Time-AI
认证作者50217H更新时间:2026-06-29
支持自启动LTX2.3导演台2.0全整合视频,包括文生视频、图生视频、音频视频、首尾帧视频、视频输入续写、去字幕、嘴型编辑、beta局部片段编辑
LTX2.3导演台2.0全整合视频,包括文生视频、图生视频、音频视频、首尾帧视频、视频输入续写、去字幕、嘴型编辑、beta局部片段编辑
图片生成Lora训练Flux

Krea2的Lora训练
8@梦影Erislia
75368H更新时间:2026-06-27
Krea2的Lora训练
Krea2的Lora训练
Qwen-imageWanLora训练

AiToolKit汉化版
140@Doc_workBox
认证作者209527227H更新时间:2026-06-27
支持自启动Aitoolkit汉化版,自适应UI方便手机端查看训练进度
Aitoolkit汉化版,自适应UI方便手机端查看训练进度
视频生成视频编辑

最强视频替换人物&动作迁移,Scail2合集,超强效果 | 超长视频生成 | 批量生成 | 爆款视频复刻
25@与AI同行
认证作者309926H更新时间:2026-06-27
支持自启动最强视频替换人物&动作迁移,Scail2合集,超强效果 | 超长视频生成 | 批量生成 | 爆款视频复刻
最强视频替换人物&动作迁移,Scail2合集,超强效果 | 超长视频生成 | 批量生成 | 爆款视频复刻
AI漫剧数字人ComfyUI

202604全新ComfyUI整合包,主流模型都有,附带40个实用工作流,体积不到100G
82@老徐Ai研习社
认证作者8755372H更新时间:2026-06-27
支持自启动ComfyUI整合包20260506
ComfyUI整合包20260506
生物信息分子动力
ESMFold
0@苍耳阿猫
认证作者00H更新时间:2026-06-29
ESMFold
ESMFold
ComfyUI图片生成

Ideogram-4-Single,单模型8步采样,单提示词,图生图,文生图,8G显存可用,No-Safety-Filter,批量任务,支持50系
0@刘悦的技术博客
认证作者1510H更新时间:2026-06-26
支持自启动Ideogram-4-Single,单模型8步采样,单提示词,图生图,文生图,8G显存可用,No-Safety-Filter,批量任务,支持50系
Ideogram-4-Single,单模型8步采样,单提示词,图生图,文生图,8G显存可用,No-Safety-Filter,批量任务,支持50系
SVC

SVC-Fusion_api_rvc
1@杭州
14932090H更新时间:2026-06-26
支持自启动支持了rvc模型算法的SVC-Fusion_api
支持了rvc模型算法的SVC-Fusion_api
数字人视频生成语音合成

OpenTalking
4@Opentalking
70141H更新时间:2026-06-26
支持自启动OpenTalking 是一个面向实时数字人对话与应用开发的开源平台,用统一的 WebUI、知识库、语音、模型运行时和部署链路,把数字人从单次演示连接成可落地的应用系统。
OpenTalking 是一个面向实时数字人对话与应用开发的开源平台,用统一的 WebUI、知识库、语音、模型运行时和部署链路,把数字人从单次演示连接成可落地的应用系统。
ComfyUILTX视频生成

LTX2.3-Director-v2最新版-完美去除视频字幕的导演工作流
3@匹夫
认证作者2655H更新时间:2026-06-25
LTX2.3-Director-v2最新版-完美去除视频字幕的导演工作流
LTX2.3-Director-v2最新版-完美去除视频字幕的导演工作流
ComfyUILTX视频生成

KSK LTX2.3 3.5满血整合镜像|22B视频创作套件
5@AI-KSK
认证作者4640H更新时间:2026-06-26
支持自启动基于 ComfyUI 深度整合的 LTX2.3 3.5 满血镜像,内置 22B 主模型、插件依赖与多套核心工作流,支持文生视频、图生视频、数字人、分镜控制和视频增强,真正做到开箱即用。
基于 ComfyUI 深度整合的 LTX2.3 3.5 满血镜像,内置 22B 主模型、插件依赖与多套核心工作流,支持文生视频、图生视频、数字人、分镜控制和视频增强,真正做到开箱即用。
ComfyUI图片生成Flux

Krea2 Turbo Engine|ComfyUI 本地加速镜像
1@AI-KSK
认证作者2673H更新时间:2026-06-24
支持自启动基于 Krea 2 Turbo 的本地化 ComfyUI 推理环境,优化生成速度与稳定性,适用于高频文生图与风格测试。
基于 Krea 2 Turbo 的本地化 ComfyUI 推理环境,优化生成速度与稳定性,适用于高频文生图与风格测试。
ComfyUI图片生成

Krea-2-GGUF,文生图,图生图,No-Safety-Filter,8G显存可用,支持50系,批量任务队列
0@刘悦的技术博客
认证作者2515H更新时间:2026-06-24
支持自启动Krea-2-GGUF,文生图,图生图,No-Safety-Filter,8G显存可用,支持50系,批量任务队列
Krea-2-GGUF,文生图,图生图,No-Safety-Filter,8G显存可用,支持50系,批量任务队列
语音合成语音分离语音识别

dots.tts语音克隆视频配音平台
2@K哥讲AI
认证作者1539H更新时间:2026-06-23
支持自启动dots.tts语音克隆视频配音平台
dots.tts语音克隆视频配音平台
Lora训练图片生成图片编辑

Boogu Image的lora训练AI-TOOLKIT
1@梦影Erislia
617H更新时间:2026-06-22
Boogu Image的lora训练AI-TOOLKIT
Boogu Image的lora训练AI-TOOLKIT
数字人ComfyUI

ComfyUI云端整合包2506
0@鹄仙
认证作者2135H更新时间:2026-06-26
ComfyUI云端整合包2606
ComfyUI云端整合包2606
ComfyUI图片编辑图片生成

Boogu-Image-GGUF,文生图,图像修改,8G显存可用,支持50系,批量任务队列
1@刘悦的技术博客
认证作者3752H更新时间:2026-06-21
支持自启动Boogu-Image-GGUF,文生图,图像修改,8G显存可用,支持50系,批量任务队列
Boogu-Image-GGUF,文生图,图像修改,8G显存可用,支持50系,批量任务队列
AI应用语音合成

专业级Seed-TTS-Eval语音评测工具
1@雨落实战
认证作者71H更新时间:2026-06-22
支持自启动这是一个用于评测TTS语音质量的工具
这是一个用于评测TTS语音质量的工具
3D生成

单图生成3D高斯文件,TripoSplat,超强3D效果!游戏3D | AR/VR | 3D资产创作 | 批量生成
4@与AI同行
认证作者123H更新时间:2026-06-19
支持自启动单图生成3D高斯文件,TripoSplat,超强3D效果!游戏3D | AR/VR | 3D资产创作 | 批量生成
单图生成3D高斯文件,TripoSplat,超强3D效果!游戏3D | AR/VR | 3D资产创作 | 批量生成
语音合成IndexTTSAI应用

新一代高质量语音生成模型VoxCPM 2.0 整合包升级了, 支持 30 种语言、9 种中文方言!
11@余子越Talk
认证作者128418H更新时间:2026-06-19
支持自启动是 VoxCPM 系列的新一代语音生成模型,基于 2B 参数规模,并使用超过 200 万小时的多语言语音数据训练,支持 30 种语言、9 种中文方言
是 VoxCPM 系列的新一代语音生成模型,基于 2B 参数规模,并使用超过 200 万小时的多语言语音数据训练,支持 30 种语言、9 种中文方言
ComfyUI图片生成Lora训练

AnimaBase的Lora融合训练Comfy和Trainer
7@梦影Erislia
43124H更新时间:2026-06-18
AnimaBase的Lora融合训练Comfy和Trainer
AnimaBase的Lora融合训练Comfy和Trainer
数字人
infinitetakl数字人云端版本
11@pappyai
89256H更新时间:2026-06-18
支持自启动infinitetakl数字人,支持单人对口型,双人对口型以及单人视频对口型
infinitetakl数字人,支持单人对口型,双人对口型以及单人视频对口型
ComfyUILTX视频生成

JoyAI-Echo-ComfyUI-无损版
4@有趣的80后程序员
认证作者72H更新时间:2026-06-18
支持自启动JoyAI-Echo的comfyUI版本,全量模型无损版
JoyAI-Echo的comfyUI版本,全量模型无损版
ComfyUI图片生成图片编辑

Ideogram-4-GGUF,自动提示词,图生图,文生图,8G显存可用,No-Safety-Filter,批量任务,Lora使用,支持50系
1@刘悦的技术博客
认证作者215H更新时间:2026-06-18
支持自启动Ideogram-4-GGUF,自动提示词,图生图,文生图,8G显存可用,No-Safety-Filter,批量任务,Lora使用,支持50系
Ideogram-4-GGUF,自动提示词,图生图,文生图,8G显存可用,No-Safety-Filter,批量任务,Lora使用,支持50系
数字人CosyVoiceDeepSeek
数字人直播
5@AI开发日记
5294H更新时间:2026-06-25
支持自启动数字人直播
数字人直播
语音合成

VoxCPM2 声音克隆系统webui开机即用
0@鸡你太美
认证作者306H更新时间:2026-06-18
支持自启动VoxCPM2 声音克隆系统webui开机即用
VoxCPM2 声音克隆系统webui开机即用
ComfyUI视频生成视频编辑

SCAIL2-那颗星星自制工作流,动作迁移,人物替换,可以直出长视频
10@那颗星星
158387H更新时间:2026-06-16
支持自启动自制SCAIL2 ComfyUI工作流,可以动作迁移,人物替换,可以直出长视频,并且我大幅简化了流程,十分简单易用
自制SCAIL2 ComfyUI工作流,可以动作迁移,人物替换,可以直出长视频,并且我大幅简化了流程,十分简单易用
IndexTTS语音合成AI应用

indextts-2.0 升级版,影视配音,情绪小短片,情绪精准控制!
27@余子越Talk
认证作者365769H更新时间:2026-06-15
支持自启动支持8个角色配音,速度控制,高精度的SRT字幕同步生成,SRT字幕生成配音,情绪控制,海量预设音色列表,语速可调,多音字,专业术语控制。
支持8个角色配音,速度控制,高精度的SRT字幕同步生成,SRT字幕生成配音,情绪控制,海量预设音色列表,语速可调,多音字,专业术语控制。
Wan视频生成视频编辑

Bernini-Diffusers满血版|MLLM语义规划视频生成编辑WebUI镜像
5@AI-KSK
认证作者3753H更新时间:2026-06-15
支持自启动完整Bernini-Diffusers满血版,内置中文WebUI,保留MLLM语义规划能力,支持AI视频生成、视频编辑与参考图驱动。
完整Bernini-Diffusers满血版,内置中文WebUI,保留MLLM语义规划能力,支持AI视频生成、视频编辑与参考图驱动。
语音合成

TTS集合1688——客户定制
0@是你k哥啊
15564H更新时间:2026-06-16
TTS集合
TTS集合
ComfyUIZ-Image

Zit-Turbo-Engineer-V6,文生图,图生图,洗图,6G显存可用,局部重绘,支持50系,批量任务队列
5@刘悦的技术博客
认证作者4337H更新时间:2026-06-15
支持自启动Zit-Turbo-Engineer-V6,文生图,图生图,洗图,6G显存可用,局部重绘,支持50系,批量任务队列
Zit-Turbo-Engineer-V6,文生图,图生图,洗图,6G显存可用,局部重绘,支持50系,批量任务队列
ComfyUI视频生成

Scail2角色替换Scail2动作迁移低显存无限时长ComfyUI工作流
6@鸡你太美
认证作者97275H更新时间:2026-06-15
支持自启动Scail2角色替换Scail2动作迁移低显存无限时长ComfyUI工作流
Scail2角色替换Scail2动作迁移低显存无限时长ComfyUI工作流
数字人AI音乐LTX

LTX2.3一键整合包,数字人对口型,AI唱歌,首尾帧,图生视频,文生视频,图片编辑,文生图,支持50系显卡,8G显存可用,64G内存。
6@余子越Talk
认证作者141290H更新时间:2026-06-15
支持自启动无需任何配置,一键运行 LTX2.3 数字人 镜像,然后通过公网IP访问生成服务。
无需任何配置,一键运行 LTX2.3 数字人 镜像,然后通过公网IP访问生成服务。
Lora训练图片生成其他

Ideogram4的Lora训练AI-Toolkit
0@梦影Erislia
1167H更新时间:2026-06-13
Ideogram4的Lora训练AI-Toolkit
Ideogram4的Lora训练AI-Toolkit
ComfyUI视频编辑视频生成

Scail-2,视频动作迁移,目标替换,指定目标替换,多人迁移,8G显存可用,支持50系
8@刘悦的技术博客
认证作者103220H更新时间:2026-06-12
支持自启动Scail-2,视频动作迁移,目标替换,指定目标替换,多人迁移,8G显存可用,支持50系
Scail-2,视频动作迁移,目标替换,指定目标替换,多人迁移,8G显存可用,支持50系
其他

oac
0@lxg
00H更新时间:2026-06-18
支持自启动实时数字人
实时数字人
ComfyUI图片生成

Ideogram-4-GGUF,文生图,8G显存可用,No-Safety-Filter,批量任务,Lora使用,支持50系
4@刘悦的技术博客
认证作者3523H更新时间:2026-06-10
支持自启动 Ideogram-4-GGUF,文生图,8G显存可用,No-Safety-Filter,批量任务,Lora使用,支持50系
Ideogram-4-GGUF,文生图,8G显存可用,No-Safety-Filter,批量任务,Lora使用,支持50系
ComfyUIWan视频生成

AI跳舞矩阵批量镜像:人物图像×舞蹈动作,一键组合自动执行
8@AI-KSK
认证作者43401H更新时间:2026-06-11
支持自启动AI跳舞矩阵镜像,支持人物图像×舞蹈动作一键配对,批量生成冷启动测试素材。
AI跳舞矩阵镜像,支持人物图像×舞蹈动作一键配对,批量生成冷启动测试素材。
语音合成IndexTTSAI应用

小红书 AI 语音 dots.tts 开源 48kHz 高保真语音生成,停顿断句自然,支持50系显卡。
12@余子越Talk
认证作者202439H更新时间:2026-06-15
支持自启动dots.tts 拥有约 20 亿参数规模,支持零样本声音克隆、高保真语音生成以及自然的情感表达。多个权威榜单 SOTA:Seed-TTS-Eval 平均表现最佳
dots.tts 拥有约 20 亿参数规模,支持零样本声音克隆、高保真语音生成以及自然的情感表达。多个权威榜单 SOTA:Seed-TTS-Eval 平均表现最佳
AI应用
comfyui_纯净_2.12-13
1@kmkm99
60H更新时间:2026-06-08
支持自启动纯净版本的comfyui
纯净版本的comfyui
视频生成视频编辑

开源版Google Omni!Bernini视频万物编辑,视频元素添加+删除+修改 | 视频消除物体 | 换背景 | 视频插入视频 | 风格转换 | 支持参考视频+多参考图
16@与AI同行
认证作者107172H更新时间:2026-06-08
支持自启动开源版Google Omni!Bernini视频万物编辑,视频元素添加+删除+修改 | 视频消除物体 | 换背景 | 视频插入视频 | 风格转换 | 支持参考视频+多参考图
开源版Google Omni!Bernini视频万物编辑,视频元素添加+删除+修改 | 视频消除物体 | 换背景 | 视频插入视频 | 风格转换 | 支持参考视频+多参考图
语音合成IndexTTSAI应用

PilotTTS 高德开源语音克隆,8G显存可用,支持 11 种情感、14 种方言的 LLM TTS 系统
0@余子越Talk
认证作者33118H更新时间:2026-06-15
支持自启动PilotTTS 是一套基于大语言模型的开源 TTS 系统,核心特点是"有意简化的架构 + 严格的数据工程"。它提供完全开源的数据处理流水线,支持零样本音色克隆。
PilotTTS 是一套基于大语言模型的开源 TTS 系统,核心特点是"有意简化的架构 + 严格的数据工程"。它提供完全开源的数据处理流水线,支持零样本音色克隆。
ComfyUI图片生成

Ideogram-4,文生图,细化描述,至少需要14G显存,批量任务,支持50系
1@刘悦的技术博客
认证作者2488H更新时间:2026-06-08
支持自启动Ideogram-4,文生图,细化描述,至少需要14G显存,批量任务,支持50系
Ideogram-4,文生图,细化描述,至少需要14G显存,批量任务,支持50系
语音合成CosyVoice

PilotTTS,TTS语音模型,情绪控制,接口api使用,8G显存可用,速度1比1,支持超长文本,声音克隆,文本指令
3@刘悦的技术博客
认证作者3636H更新时间:2026-06-03
支持自启动PilotTTS,TTS语音模型,情绪控制,接口api使用,8G显存可用,速度1比1,支持超长文本,声音克隆,文本指令
PilotTTS,TTS语音模型,情绪控制,接口api使用,8G显存可用,速度1比1,支持超长文本,声音克隆,文本指令
其他

那颗星星自制工作流
30@那颗星星
3013119H更新时间:2026-06-08
支持自启动颠覆性设计,真正在ComfyUI内实现无限画布体验
颠覆性设计,真正在ComfyUI内实现无限画布体验
ComfyUI图片编辑图片生成

Anima-Base,文生图,图像修改,6G显存可用,批量任务,支持50系
5@刘悦的技术博客
认证作者6483H更新时间:2026-06-01
支持自启动Anima-Base,文生图,图像修改,6G显存可用,批量任务,支持50系
Anima-Base,文生图,图像修改,6G显存可用,批量任务,支持50系
ComfyUI图片生成

Lens-Turbo,文生图,图生图,至少需要12G显存,批量任务,支持50系
2@刘悦的技术博客
认证作者2830H更新时间:2026-05-30
支持自启动Lens-Turbo,文生图,图生图,至少需要12G显存,批量任务,支持50系
Lens-Turbo,文生图,图生图,至少需要12G显存,批量任务,支持50系
语音合成AI应用

MOSS-TTS-v1.5 音色克隆,文字转语音TTS,效果非常稳定,相似度高,支持30种语言,精准控制停顿,拼音,长参考音频+短目标文本的克隆更可靠!
19@余子越Talk
认证作者358567H更新时间:2026-06-15
支持自启动支持任意时刻停顿:用户可以在文本中插入类似 [pause 3.2s] 的标记,精确控制语音中的停顿时长。更稳定的音色克隆.
支持任意时刻停顿:用户可以在文本中插入类似 [pause 3.2s] 的标记,精确控制语音中的停顿时长。更稳定的音色克隆.
AI音乐AI应用SVC

SVC-Fusion_api
4@aiguoliuguo
认证作者189940H更新时间:2026-05-29
支持自启动SVC Fusion-api服务端
SVC Fusion-api服务端
ComfyUILTX视频生成

LTX2.3 10Eros 图生视频双工作流:相似度保持 + 分块增强,一张图生成更稳更清晰的视频
19@AI-KSK
认证作者163685H更新时间:2026-06-11
支持自启动LTX2.3 10Eros 图生视频双工作流,支持相似度保持与分块增强,一张图生成更稳、更清晰的视频。
LTX2.3 10Eros 图生视频双工作流,支持相似度保持与分块增强,一张图生成更稳、更清晰的视频。
LongCat图片生成图片编辑

LongCat-Image-Edit-Turbo,文生图,图生图,局部重绘,4k超分,批量任务,支持50系
11@刘悦的技术博客
认证作者9240H更新时间:2026-05-28
支持自启动LongCat-Image-Edit-Turbo,文生图,图生图,局部重绘,4k超分,批量任务,支持50系
LongCat-Image-Edit-Turbo,文生图,图生图,局部重绘,4k超分,批量任务,支持50系
ComfyUI

RUIQILI_COMFYUI
7@李睿琪
170745H更新时间:2026-06-01
支持自启动建筑模型 ComfyUI
建筑模型 ComfyUI
数字人AI电商ComfyUI

20260527ComfyUI全能整合包
14@老徐Ai研习社
认证作者1671429H更新时间:2026-05-30
支持自启动20260527ComfyUI全能整合包
20260527ComfyUI全能整合包
AI音乐AI应用AI漫剧

StableAudio3
2@余子越Talk
认证作者1834H更新时间:2026-06-15
支持自启动Stability AI 开源新王炸 Stable-Audio-3, 音效和纯音乐生成,4G显存可用,支持纯CPU,支持中文提示词!
Stability AI 开源新王炸 Stable-Audio-3, 音效和纯音乐生成,4G显存可用,支持纯CPU,支持中文提示词!
ComfyUIWan

ComfyUI纯净版,集成wan2.2图生视频
0@
1627H更新时间:2026-05-28
支持自启动小白初学入门,纯净官方无冗余,详细看介绍
小白初学入门,纯净官方无冗余,详细看介绍
ComfyUILTX图片编辑

Comfy打开即用LTX2.3Dasiwa视频生成qwen图像编辑
16@梦影Erislia
147396H更新时间:2026-05-25
Comfy打开即用LTX2.3Dasiwa视频生成qwen图像编辑
Comfy打开即用LTX2.3Dasiwa视频生成qwen图像编辑
视频生成

LongCat-Video-1.5来自美团最新开源视频模型文生视频图生视频数字人视频webui
6@鸡你太美
认证作者53122H更新时间:2026-05-24
LongCat-Video-1.5来自美团最新开源视频模型文生视频图生视频数字人视频webui
LongCat-Video-1.5来自美团最新开源视频模型文生视频图生视频数字人视频webui
数字人LTX视频生成

LTX-2.3-OmniNFT-文图生视频-多人对话-单人数字人,8G显存可用,自动补帧,支持50系,自定义分辨率,自适应端口,批量任务队列
11@刘悦的技术博客
认证作者109145H更新时间:2026-05-23
支持自启动LTX-2.3-OmniNFT-文图生视频-多人对话-单人数字人,8G显存可用,自动补帧,支持50系,自定义分辨率,自适应端口,批量任务队列
LTX-2.3-OmniNFT-文图生视频-多人对话-单人数字人,8G显存可用,自动补帧,支持50系,自定义分辨率,自适应端口,批量任务队列
视频生成LongCat数字人

LongCat Avatar 1.5|WebUI 无限时长数字人镜像
11@AI-KSK
认证作者75178H更新时间:2026-05-24
支持自启动内置简易 WebUI,支持 6 种运行方式,主打高清数字人长视频生成。480P 可用 48G 显卡运行,720P 建议更高规格 GPU,适合低中断率超长视频制作。
内置简易 WebUI,支持 6 种运行方式,主打高清数字人长视频生成。480P 可用 48G 显卡运行,720P 建议更高规格 GPU,适合低中断率超长视频制作。
语音合成

超强TTS情感控制VoxCPM云端API接口
1@河狸配音工坊
24286H更新时间:2026-06-09
支持自启动超强TTS情感控制VoxCPM云端API接口
超强TTS情感控制VoxCPM云端API接口
视频生成

来自英伟达的长视频开源解决方案LongLive 2.0 WebUI
1@鸡你太美
认证作者31H更新时间:2026-05-23
支持自启动来自英伟达的长视频开源解决方案LongLive 2.0 WebUI
来自英伟达的长视频开源解决方案LongLive 2.0 WebUI
Lora训练

Animal Lora训练器 附详细说明
9@野生技能师
27122H更新时间:2026-05-25
Animal Lora训练器,有训练设置的详细说明
Animal Lora训练器,有训练设置的详细说明
语音合成AI音乐

Stable-Audio-3,声音生成,4G显存可用,支持纯CPU,支持中文提示词,接口API调用,ASMR助眠,文字生成声音和音乐,支持老显卡,支持50系
4@刘悦的技术博客
认证作者1210H更新时间:2026-05-22
支持自启动Stable-Audio-3,声音生成,4G显存可用,支持纯CPU,支持中文提示词,接口API调用,ASMR助眠,文字生成声音和音乐,支持老显卡,支持50系
Stable-Audio-3,声音生成,4G显存可用,支持纯CPU,支持中文提示词,接口API调用,ASMR助眠,文字生成声音和音乐,支持老显卡,支持50系
ComfyUI图片生成Lora训练

Anima LoRA 批量炼丹工厂
13@AI-KSK
认证作者129282H更新时间:2026-05-22
支持自启动内置 AnimaForge 批量 LoRA 训练插件,支持自动打标、Caption 清洗、触发词保护与批量训练。
内置 AnimaForge 批量 LoRA 训练插件,支持自动打标、Caption 清洗、触发词保护与批量训练。
混元3D生成其他

混元World模型Mirror
2@梦影Erislia
55H更新时间:2026-05-22
生成3d高斯,法线图等
生成3d高斯,法线图等
数字人

羲和AI爆款IP口播智能体
3@羲和AI爆款IP口播智能体
48232H更新时间:2026-05-21
支持自启动羲和AI爆款IP口播智能体官方团队打造
羲和AI爆款IP口播智能体官方团队打造
语音合成SVC

SVC-WebUI
66@乔大峰
认证作者146216290H更新时间:2026-05-21
一键训练SVC模型,支持上传压缩干声文件,训练完成发送提醒,一键清空训练环境,追求的就是高效率
一键训练SVC模型,支持上传压缩干声文件,训练完成发送提醒,一键清空训练环境,追求的就是高效率
语音合成LTX

DramaBox,语义化场景描述语音模型,TTS,接口api使用,8G显存可用,文本转语音,语速调节
3@刘悦的技术博客
认证作者153H更新时间:2026-05-20
支持自启动DramaBox,语义化场景描述语音模型,TTS,接口api使用,8G显存可用,文本转语音,语速调节
DramaBox,语义化场景描述语音模型,TTS,接口api使用,8G显存可用,文本转语音,语速调节
视频生成

超强AI字幕识别翻译,Captions_Auto_V1,工业级别效果,本地无限生成!音视频字幕识别 | 字幕翻译 | 短视频文案识别
4@与AI同行
认证作者1633H更新时间:2026-05-20
支持自启动超强AI字幕识别翻译,Captions_Auto_V1,工业级别效果,本地无限生成!音视频字幕识别 | 字幕翻译 | 短视频文案识别
超强AI字幕识别翻译,Captions_Auto_V1,工业级别效果,本地无限生成!音视频字幕识别 | 字幕翻译 | 短视频文案识别
IndexTTS

Index TTS2长视频配音
2@
1815H更新时间:2026-05-20
支持自启动本镜像是一个基于 IndexTTS2 的中英视频自动配音工具,适合将英文视频或音频批量转换为中文克隆配音。
本镜像是一个基于 IndexTTS2 的中英视频自动配音工具,适合将英文视频或音频批量转换为中文克隆配音。
ComfyUIWan视频生成

Wan2.2-ReMixV3.0
45@刘悦的技术博客
认证作者530643H更新时间:2026-05-19
支持自启动Wan2.2-ReMixV3.0-SVI2-VBVR,文生视频,图生视频,无限时长,首尾帧,自动补帧,自适应端口号,支持50系,支持批量任务
Wan2.2-ReMixV3.0-SVI2-VBVR,文生视频,图生视频,无限时长,首尾帧,自动补帧,自适应端口号,支持50系,支持批量任务
视频生成Wan

Wan2.2-ReMix3.0-Relay-Smart-图生视频-文生视频
14@刘悦的技术博客
认证作者165997H更新时间:2026-05-19
支持自启动Wan2.2-ReMix3.0-Relay-Smart-图生视频-文生视频
Wan2.2-ReMix3.0-Relay-Smart-图生视频-文生视频
Lora训练图片生成其他

二次元Anima的Lora训练UI
134@梦影Erislia
201311277H更新时间:2026-06-15
二次元AnimaBase的Lora训练UI,一键打标训练
二次元AnimaBase的Lora训练UI,一键打标训练
ComfyUILTX视频生成

LTX-2.3-Prompt-Relay-Smart-图生视频-多人对话-单人数字人,自动补帧,支持50系,自定义分辨率,自适应端口,批量任务队列
8@刘悦的技术博客
认证作者94435H更新时间:2026-05-16
支持自启动LTX-2.3-Prompt-Relay-Smart-图生视频-多人对话-单人数字人,自动补帧,支持50系,自定义分辨率,自适应端口,批量任务队列
LTX-2.3-Prompt-Relay-Smart-图生视频-多人对话-单人数字人,自动补帧,支持50系,自定义分辨率,自适应端口,批量任务队列
图片生成图片编辑

HiDream-O1 新架构图像生成
0@鹄仙
认证作者44H更新时间:2026-05-14
新架构2K直出图像模型
新架构2K直出图像模型
图片生成图片编辑

hidream-o1-image,文生图,图片编辑,多图编辑,4k超分,批量任务,支持50系
7@刘悦的技术博客
认证作者8238H更新时间:2026-05-14
支持自启动hidream-o1-image,文生图,图片编辑,多图编辑,4k超分,批量任务,支持50系
hidream-o1-image,文生图,图片编辑,多图编辑,4k超分,批量任务,支持50系
FluxWanComfyUI

Bob同学的comfyui云端镜像系列
427@Bob同学
认证作者677724513H更新时间:2026-05-14
支持自启动此版本内置 (Wan2.2\Flux\Kontext)系列的全部基础模型及工作流
此版本内置 (Wan2.2\Flux\Kontext)系列的全部基础模型及工作流
ComfyUILTXInfiniteTalk

官方出手:LTX2.3视频人物一键改台词
5@AI-KSK
认证作者3615H更新时间:2026-05-12
支持自启动基于 LTX2.3 的视频改台词配音镜像,支持新语音生成、口型同步与说话人风格保留。
基于 LTX2.3 的视频改台词配音镜像,支持新语音生成、口型同步与说话人风格保留。
数字人AI漫剧AI电商

ComfyUI-音图视量产-DD布丁AIGC-多人小说配音-短剧-二创-电商
24@DD布丁AIGC
96375H更新时间:2026-05-14
支持自启动从多人配音到短剧量产,自研节点驱动的 AIGC 工业化终极方案。(这不只是一个装好插件的镜像,这是一套我跑通了千万级流量、踩过无数坑后,沉淀下来的‘生产力闭环’。)
从多人配音到短剧量产,自研节点驱动的 AIGC 工业化终极方案。(这不只是一个装好插件的镜像,这是一套我跑通了千万级流量、踩过无数坑后,沉淀下来的‘生产力闭环’。)
图片生成视频生成AI漫剧

Huobao-Drama
30@huobao-ai
认证作者156468H更新时间:2026-05-11
支持自启动Huobao Drama 是一个基于 AI 的短剧自动化生产平台,实现从剧本生成、角色设计、分镜制作到视频合成的全流程自动化
Huobao Drama 是一个基于 AI 的短剧自动化生产平台,实现从剧本生成、角色设计、分镜制作到视频合成的全流程自动化
LTX视频生成ComfyUI

Sulphur-2-GGUF-图生视频-文生视频,自动补帧,支持50系,自定义分辨率,自适应端口,批量任务队列
16@刘悦的技术博客
认证作者195574H更新时间:2026-05-09
支持自启动Sulphur-2-GGUF-图生视频-文生视频,自动补帧,支持50系,自定义分辨率,自适应端口,批量任务队列
Sulphur-2-GGUF-图生视频-文生视频,自动补帧,支持50系,自定义分辨率,自适应端口,批量任务队列
数字人
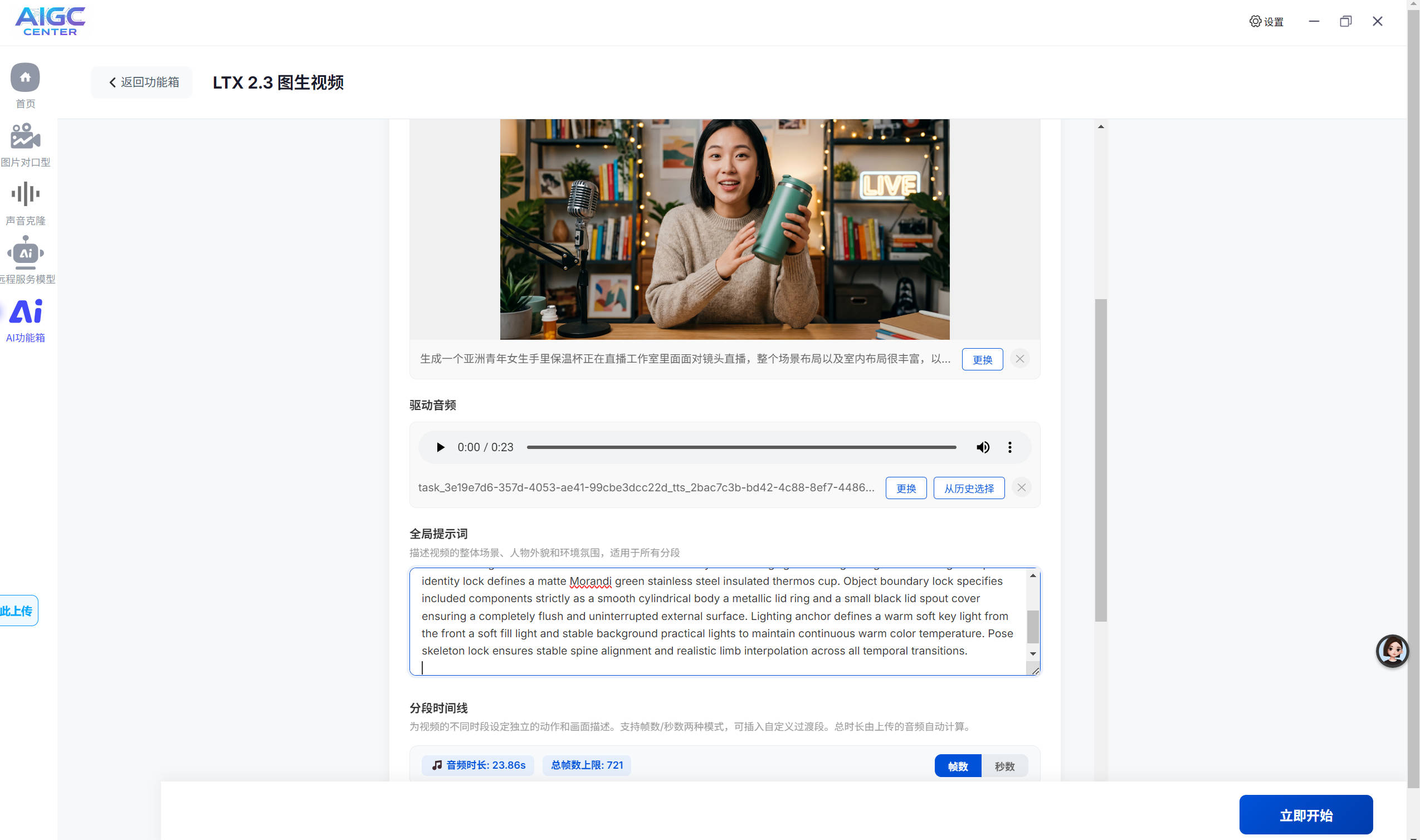
ltx2.3图片可控分镜数字人
3@pappyai
61H更新时间:2026-06-04
支持自启动ltx2.3可控分镜图片数字人生成。
ltx2.3可控分镜图片数字人生成。
语音识别

准确率极高的离线字幕.SRT生成,带时间轴,下载即可使用
1@星尘玩AI
00H更新时间:2026-05-20
支持自启动普通话不标准也能准确率极高的字幕.SRT,带时间轴,下载即可使用,支持中英文
普通话不标准也能准确率极高的字幕.SRT,带时间轴,下载即可使用,支持中英文
Qwen

GRPO_qwen2.5_1.5B
0@云龙老师
10H更新时间:2026-05-08
通过该镜像可以实现qwen2.5-1.5B的强化学习训练
通过该镜像可以实现qwen2.5-1.5B的强化学习训练
文本模型数字人行业模型

Gemma-4-26B-A4B-it-Uncensored,8K上下文,AI女友,大语言模型,语音对话,适合甜品卡,支持50系
4@刘悦的技术博客
认证作者2012H更新时间:2026-05-08
支持自启动Gemma-4-26B-A4B-it-Uncensored,8K上下文,AI女友,大语言模型,语音对话,适合甜品卡,支持50系
Gemma-4-26B-A4B-it-Uncensored,8K上下文,AI女友,大语言模型,语音对话,适合甜品卡,支持50系
视频生成Wan

TurboDiffusion清华大学等推出的视频生成加速框架 webUI二次修改构建by科哥
5@鸡你太美
认证作者8866H更新时间:2026-05-08
支持自启动ai视频生成速度提升百倍!基于wan2.1,wan2.2加速ai优化推理速度
ai视频生成速度提升百倍!基于wan2.1,wan2.2加速ai优化推理速度
语音合成

MOSS TTSD 0.7
1@super-Z
20H更新时间:2026-05-08
MOSS TTSD 0.7,主要用于双人对话生成
MOSS TTSD 0.7,主要用于双人对话生成
ComfyUILTX视频生成

Sulphur& 10Eros ltx2.3视频生产解锁镜像
41@AI-KSK
认证作者265663H更新时间:2026-05-26
支持自启动Sulphur-10Eros-LTX2.3 解锁视频生产镜像,基于 ComfyUI 搭建,内置 Sulphur Distill BF16、10Eros BF16,支持官方工作流和高自由度私域视频创作。
Sulphur-10Eros-LTX2.3 解锁视频生产镜像,基于 ComfyUI 搭建,内置 Sulphur Distill BF16、10Eros BF16,支持官方工作流和高自由度私域视频创作。
AI漫剧Lora训练AI电商

20260506_aitoolkit全能lora模型训练王
23@老徐Ai研习社
认证作者119847H更新时间:2026-05-06
支持自启动aitoolkit全能lora模型训练王
aitoolkit全能lora模型训练王
其他
anima炼丹v2
7@zhanglang
27169H更新时间:2026-05-08
anima炼丹
anima炼丹
ComfyUILTX视频生成

LTX-2.3-10Eros-图生视频-文生视频-多人对话-单人数字人
12@刘悦的技术博客
认证作者139173H更新时间:2026-05-08
支持自启动LTX-2.3-10Eros-图生视频-文生视频-多人对话-单人数字人,8G显存可用,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
LTX-2.3-10Eros-图生视频-文生视频-多人对话-单人数字人,8G显存可用,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
ComfyUI图片生成图片编辑

Pmaster-v3.5-Turbo,文生图,图生图,洗图
7@刘悦的技术博客
认证作者6864H更新时间:2026-05-08
支持自启动Pmaster-v3.5-Turbo,文生图,图生图,洗图,6G显存可用,4k超分,局部重绘,自动提示词,支持50系,批量任务队列
Pmaster-v3.5-Turbo,文生图,图生图,洗图,6G显存可用,4k超分,局部重绘,自动提示词,支持50系,批量任务队列
ComfyUI图片生成视频生成

sd2-fast在线使用sedance2.0-fast无须排队高并发api企业框架接口视频生成
7@鸡你太美
认证作者36546H更新时间:2026-05-08
支持自启动任意机器可以运行该项目开机自动运行
任意机器可以运行该项目开机自动运行
语音合成IndexTTSQwen3-TTS

声音克隆OmniVoice——600+语言音色克隆 - 音色设计 - 多语言语音生成
15@星尘玩AI
111167H更新时间:2026-05-20
支持自启动支持600+语言音色克隆 - 音色设计 - 多语言语音生成
支持600+语言音色克隆 - 音色设计 - 多语言语音生成
数字人LTX视频生成

LTX-2.3-22B-DISTILLED-1.1-VBVR-文生视频-首尾帧,单图无限时长
22@刘悦的技术博客
认证作者176274H更新时间:2026-05-08
支持自启动LTX-2.3-22B-DISTILLED-1.1-VBVR-文生视频-首尾帧,单图无限时长,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
LTX-2.3-22B-DISTILLED-1.1-VBVR-文生视频-首尾帧,单图无限时长,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
数字人ComfyUILTX

LTX-2.3-22B-DISTILLED-1.1-VBVR-图片数字人-自动补帧
16@刘悦的技术博客
认证作者109148H更新时间:2026-05-08
支持自启动LTX-2.3-22B-DISTILLED-1.1-VBVR-图片数字人-自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词
LTX-2.3-22B-DISTILLED-1.1-VBVR-图片数字人-自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词
LTXComfyUI视频生成

LTX-2.3-DISTILLED-1.1-多人对话-男女对唱-图片数字人
12@刘悦的技术博客
认证作者56110H更新时间:2026-05-08
支持自启动LTX-2.3-DISTILLED-1.1-多人对话-男女对唱-图片数字人,8G显存可用,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
LTX-2.3-DISTILLED-1.1-多人对话-男女对唱-图片数字人,8G显存可用,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
图片生成ComfyUI

RedMix-Ernie-Image,4k超分,文生图,图生图,自动提示词,批量任务
3@刘悦的技术博客
认证作者5929H更新时间:2026-05-02
支持自启动RedMix-Ernie-Image,4k超分,文生图,图生图,自动提示词,批量任务
RedMix-Ernie-Image,4k超分,文生图,图生图,自动提示词,批量任务
LTX视频生成视频编辑

LTX-2.3-DISTILLED-1.1-视频编辑-视频内容修改
8@刘悦的技术博客
认证作者64102H更新时间:2026-04-30
支持自启动LTX-2.3-DISTILLED-1.1-视频编辑-视频内容修改
LTX-2.3-DISTILLED-1.1-视频编辑-视频内容修改
语音合成

超强AI语音克隆,VOXCPM-V2合集,语音克隆 | 音色保存 | 多音字 | 批量生成 | 超长文本生成
44@与AI同行
认证作者358523H更新时间:2026-04-30
支持自启动超强AI语音克隆,VOXCPM-V2合集,语音克隆 | 音色保存 | 多音字 | 批量生成 | 超长文本生成
超强AI语音克隆,VOXCPM-V2合集,语音克隆 | 音色保存 | 多音字 | 批量生成 | 超长文本生成
ComfyUIFlux图片生成

Flux2 Klein 微操级控图 一致性镜像
16@AI-KSK
认证作者144806H更新时间:2026-04-30
支持自启动基于 ComfyUI、Flux2 Klein 9B,集成提示词增强、参考图控制、身份保持、颜色锚定和实验采样,适合保脸换姿势、多图合成、图生图精修与高一致性人像编辑。
基于 ComfyUI、Flux2 Klein 9B,集成提示词增强、参考图控制、身份保持、颜色锚定和实验采样,适合保脸换姿势、多图合成、图生图精修与高一致性人像编辑。
AI音乐

最强免费生成音乐,ACE-Step-V1.5-XL,免费版Suno,商业级别音乐效果!
10@与AI同行
认证作者4581H更新时间:2026-04-30
支持自启动最强免费生成音乐,ACE-Step-V1.5-XL,免费版Suno,商业级别音乐效果
最强免费生成音乐,ACE-Step-V1.5-XL,免费版Suno,商业级别音乐效果
具身智能

openVLA
1@
10H更新时间:2026-04-30
优云首个openvla推理镜像,实现输入图片,得到动作输出
优云首个openvla推理镜像,实现输入图片,得到动作输出
ComfyUILTX数字人

LTX2.3 大丝袜视频工作流 I2V/T2V/V2V/首尾帧/音频一体化镜像
12@AI-KSK
认证作者12887H更新时间:2026-04-30
支持自启动LTX2.3 DaSiWa 视频生成整合镜像,基于 ComfyUI 封装,内置 OmniForge 工作流,支持图生视频、文生视频、首尾帧过渡、视频转视频与音频生成
LTX2.3 DaSiWa 视频生成整合镜像,基于 ComfyUI 封装,内置 OmniForge 工作流,支持图生视频、文生视频、首尾帧过渡、视频转视频与音频生成
AI音乐Lora训练ComfyUI

ACE-Step-1.5UI音乐生成和Lora训练
25@梦影Erislia
167705H更新时间:2026-04-26
ACE-Step-1.5UI音乐生成和Lora训练
ACE-Step-1.5UI音乐生成和Lora训练
AI漫剧

融光短视频创作平台webUI开源全流程AI视频创作平台自动化工作流
2@鸡你太美
认证作者2440H更新时间:2026-04-27
支持自启动可以无卡模式运行改项目
可以无卡模式运行改项目
图片生成图片编辑

GPT-Image-2,4k超分,文生图,图生图,自动提示词,批量任务,基于国内DMXAPI接口平台
8@刘悦的技术博客
认证作者11096H更新时间:2026-04-26
支持自启动GPT-Image-2,4k超分,文生图,图生图,自动提示词,批量任务,基于国内DMXAPI接口平台
GPT-Image-2,4k超分,文生图,图生图,自动提示词,批量任务,基于国内DMXAPI接口平台
语音合成语音识别

OmniVoice,批量任务,智能字幕SRT配音,多人对话,接口api使用,速度1比0.3,支持超长文本,声音克隆
7@刘悦的技术博客
认证作者661257H更新时间:2026-04-25
支持自启动OmniVoice,批量任务,智能字幕SRT配音,多人对话,接口api使用,速度1比0.3,支持超长文本,声音克隆
OmniVoice,批量任务,智能字幕SRT配音,多人对话,接口api使用,速度1比0.3,支持超长文本,声音克隆
语音合成

OmniVoice维吾尔语TTS在线webui文本转语音声音专版
3@鸡你太美
认证作者3756H更新时间:2026-04-27
支持自启动维吾尔语TTS在线webui文本转语音声音专版
维吾尔语TTS在线webui文本转语音声音专版
图片生成

AI图片新王登基,GPT-Image-2合集,超强图片细节,低至0.04元/张!图片生成 | 多图编辑 | 批量生成 | 最火爆的60+种提示词玩法
20@与AI同行
认证作者2211025H更新时间:2026-04-24
支持自启动AI图片新王登基,GPT-Image-2合集,超强图片细节,低至0.04元/张!图片生成 | 多图编辑 | 批量生成 | 最火爆的60+种提示词玩法
AI图片新王登基,GPT-Image-2合集,超强图片细节,低至0.04元/张!图片生成 | 多图编辑 | 批量生成 | 最火爆的60+种提示词玩法
视频编辑

facefusion3.5.1离线全部模型最新TensorRT加速官方原版图片换脸视频换脸高清图片 构建By科哥
39@鸡你太美
认证作者5082539H更新时间:2026-04-27
支持自启动facefusion3.6.1全模型离线
facefusion3.6.1全模型离线
语音合成IndexTTSSVC

动漫短剧多人对话配音ComfyUi_voxcpm2
2@星尘玩AI
1727H更新时间:2026-05-20
支持自启动支持多种语言的,单多人对话声音克隆配音
支持多种语言的,单多人对话声音克隆配音
ComfyUI图片生成

Ernie-Image-AIO-Rapid,4k超分,文生图,图生图,自动提示词,批量任务,支持50系
8@刘悦的技术博客
认证作者4717H更新时间:2026-04-23
支持自启动Ernie-Image-AIO-Rapid,4k超分,文生图,图生图,自动提示词,批量任务,支持50系
Ernie-Image-AIO-Rapid,4k超分,文生图,图生图,自动提示词,批量任务,支持50系
AI音乐ComfyUILTX

202604ComfyUI全能整合包,LTX2.3最新cu130环境更快更稳定
19@老徐Ai研习社
认证作者206664H更新时间:2026-04-22
支持自启动cu130环境更快更稳定
cu130环境更快更稳定
IndexTTS语音合成SVC

AI动漫配音—VoxCPM2一键语音克隆、配音、训练、支持LoRA
26@星尘玩AI
109266H更新时间:2026-05-20
支持自启动VoxCPM2支持AI动漫配音等多种应用场景,一键语音克隆、配音、训练、支持LoRA
VoxCPM2支持AI动漫配音等多种应用场景,一键语音克隆、配音、训练、支持LoRA
文本模型

谷歌最新本地模型gemma4最强智能助理hermes agent一个本地免token的智能助理模型全部离线
5@鸡你太美
认证作者81109H更新时间:2026-04-27
支持自启动谷歌最新本地模型gemma4最强智能助理hermes agent一个本地免token的智能助理模型全部离线
谷歌最新本地模型gemma4最强智能助理hermes agent一个本地免token的智能助理模型全部离线
推理框架

ollama
0@苍耳阿猫
认证作者2480H更新时间:2026-04-21
ollama-0.21.0
ollama-0.21.0
ComfyUIWan视频生成

Wan2.2_LightX2V-260412-文生视频-首尾帧-单图无限时长,自动补帧,自定义分辨率,自适应端口,自动提示词,自动任务控制
27@刘悦的技术博客
认证作者238441H更新时间:2026-04-20
支持自启动Wan2.2_LightX2V-260412-文生视频-首尾帧-单图无限时长,自动补帧,自定义分辨率,自适应端口,自动提示词,自动任务控制
Wan2.2_LightX2V-260412-文生视频-首尾帧-单图无限时长,自动补帧,自定义分辨率,自适应端口,自动提示词,自动任务控制
ComfyUILTX视频生成

LTX-2.3-DISTILLED-1.1-IC-Lora-动作迁移,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
13@刘悦的技术博客
认证作者233248H更新时间:2026-04-19
支持自启动LTX-2.3-DISTILLED-1.1-IC-Lora-动作迁移,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
LTX-2.3-DISTILLED-1.1-IC-Lora-动作迁移,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
图片生成视频生成其他

猫影短剧AI驱动的小说转短剧全流程生产平台小说文本自动转换为短剧视频 构建by科哥
12@鸡你太美
认证作者68158H更新时间:2026-04-27
支持自启动可以无卡模式运行改项目0.15元每小时按秒计费
可以无卡模式运行改项目0.15元每小时按秒计费
图生文图片生成视频生成

火宝AI短视频创作系统可以无卡模型运行该项目使用前阅读使用说明
0@鸡你太美
认证作者1861H更新时间:2026-04-27
支持自启动可以无卡模式运行改项目0.15元每小时按秒计费
可以无卡模式运行改项目0.15元每小时按秒计费
图片生成视频生成其他

moyin AI影视生产级工具支持 Seedance 2.0剧本到成片全流程批量化 构建by科哥
15@鸡你太美
认证作者6460H更新时间:2026-04-27
支持自启动可以无卡模式运行改项目0.15元每小时按秒计费
可以无卡模式运行改项目0.15元每小时按秒计费
图片生成视频生成

Toonflow一款AI短剧创作工具将小说自动转化为剧本生成 AI 图片和视频的平台 构建by科哥
10@鸡你太美
认证作者6050H更新时间:2026-04-27
支持自启动可以无卡模式运行改项目0.15元每小时按秒计费
可以无卡模式运行改项目0.15元每小时按秒计费
语音合成Lora训练

VoxCPM2 一键切片打标训练集准备&训练生成一体化镜像
7@AI-KSK
认证作者3128H更新时间:2026-04-19
支持自启动集成 VoxCPM2 一键切片、自动打标、训练集整理、LoRA 训练与生成推理,开箱即用的全流程声音克隆训练镜像。
集成 VoxCPM2 一键切片、自动打标、训练集整理、LoRA 训练与生成推理,开箱即用的全流程声音克隆训练镜像。
数字人ComfyUIInfiniteTalk

InfiniteTalk数字人量化版
8@阿凯CDZK6688
132740H更新时间:2026-05-10
支持自启动InfiniteTalk数字人量化版4090效果最好,3090也可用
InfiniteTalk数字人量化版4090效果最好,3090也可用
ComfyUI图片生成

ERNIE-Image:开源图像生成新王炸
7@AI-KSK
认证作者45136H更新时间:2026-04-17
支持自启动ERNIE-Image ComfyUI镜像,集成百度开源文生图模型,擅长文字排版、复杂指令与结构化出图,适合海报、信息图等场景
ERNIE-Image ComfyUI镜像,集成百度开源文生图模型,擅长文字排版、复杂指令与结构化出图,适合海报、信息图等场景
语音合成

VoxCPM2雨落版整合包
20@雨落实战
认证作者1601407H更新时间:2026-04-17
支持自启动VoxCPM2雨落版整合包,支持多种业务场景
VoxCPM2雨落版整合包,支持多种业务场景
ComfyUI图片生成

Ernie-Image-Turbo-uncensored,文生图,图生图,自动提示词,批量任务,支持50系
5@刘悦的技术博客
认证作者7161H更新时间:2026-04-16
支持自启动Ernie-Image-Turbo-uncensored,文生图,图生图,自动提示词,批量任务,支持50系
Ernie-Image-Turbo-uncensored,文生图,图生图,自动提示词,批量任务,支持50系
数字人视频生成

Musetalk训练专用
0@有黑眼圈的小竹熊
41H更新时间:2026-04-17
支持自启动Musetalk训练专用
Musetalk训练专用
语音合成

最强AI语音克隆,LongcatAudio合集,语音克隆 | 音色保存 | 多人对话 | 字幕生成语音| 多音字 | 批量生成
19@与AI同行
认证作者105100H更新时间:2026-04-15
支持自启动最强AI语音克隆,LongcatAudio合集,语音克隆 | 音色保存 | 多人对话 | 字幕生成语音| 多音字 | 批量生成,6G显存可用!
最强AI语音克隆,LongcatAudio合集,语音克隆 | 音色保存 | 多人对话 | 字幕生成语音| 多音字 | 批量生成,6G显存可用!
Lora训练图片生成其他

百度ERNIE-Image的Lora训练AI-TOOLKIT
0@梦影Erislia
26211H更新时间:2026-04-15
百度ERNIE-Image的Lora训练AI-TOOLKIT
百度ERNIE-Image的Lora训练AI-TOOLKIT
视频生成

VAD-fast3.0 图生视频模型,可批量生成,3分钟出15秒视频
9@Ai老邱
4327H更新时间:2026-04-15
支持自启动图生视频模型,可真人批量生成,3分钟出15秒视频
图生视频模型,可真人批量生成,3分钟出15秒视频
文本模型

hermes-webui中文版支持自定义任意大模型支持微信飞书等接入
3@鸡你太美
认证作者1442H更新时间:2026-04-27
支持自启动hermes-webui中文版支持自定义任意大模型支持微信飞书等接入
hermes-webui中文版支持自定义任意大模型支持微信飞书等接入
AI应用语音合成

ComfyUI_voxcpm全能生成_那颗星星(支持多人配音,支持lora训练,老版本支持)
19@那颗星星
133404H更新时间:2026-04-15
支持自启动最强大的VoxCPM节点,支持多人配音、支持训练lora(包含数据集准备节点,傻瓜式操作)、兼容老模型
最强大的VoxCPM节点,支持多人配音、支持训练lora(包含数据集准备节点,傻瓜式操作)、兼容老模型
ComfyUILora训练语音合成

VoxCPM2语音克隆工作流LORA训练comfy支持
7@梦影Erislia
6689H更新时间:2026-04-14
VoxCPM2 TTS语音克隆工作流LORA训练comfy支持
VoxCPM2 TTS语音克隆工作流LORA训练comfy支持
语音合成

最强AI音色克隆,OmniVoice合集,音色克隆 | 语气控制 | 音色保存 | 多音字 | 批量生成
22@与AI同行
认证作者974962H更新时间:2026-04-13
支持自启动最强AI音色克隆,OmniVoice合集,音色克隆 | 语气控制 | 音色保存 | 多音字 | 批量生成
最强AI音色克隆,OmniVoice合集,音色克隆 | 语气控制 | 音色保存 | 多音字 | 批量生成
FluxComfyUI图片生成

Flux.2-Klein-9B-GGUF
86@刘悦的技术博客
认证作者10812154H更新时间:2026-04-13
支持自启动Flux.2-Klein-9B-GGUF,局部重绘,文生图,图像编辑,多图编辑,自动提示词,批量任务,支持最新50系和计算卡
Flux.2-Klein-9B-GGUF,局部重绘,文生图,图像编辑,多图编辑,自动提示词,批量任务,支持最新50系和计算卡
语音合成AI音乐

Ace-Step-1.5-XL-Turbo,歌曲生成,音乐生成,文字转歌曲,歌曲创作,支持50系
7@刘悦的技术博客
认证作者43298H更新时间:2026-04-12
支持自启动Ace-Step-1.5-XL-Turbo,歌曲生成,音乐生成,文字转歌曲,歌曲创作,支持50系
Ace-Step-1.5-XL-Turbo,歌曲生成,音乐生成,文字转歌曲,歌曲创作,支持50系
IndexTTSQwen3-TTSCosyVoice

咸鱼鱼VoxCPM
8@后期咸鱼鱼-小帆
99114H更新时间:2026-04-13
支持自启动VoxCPM2
VoxCPM2
语音合成

VoxCPM2
5@鹄仙
认证作者67280H更新时间:2026-04-11
多语言的声音克隆和设计项目,支持lora训练
多语言的声音克隆和设计项目,支持lora训练
语音合成IndexTTS语音识别

LongCat-AudioDiT 剧本创作台
1@K哥讲AI
认证作者12155H更新时间:2026-04-13
支持自启动LongCat-AudioDiT WebUI 是基于该模型的可视化工具,支持音色库管理、剧本队列编排、长文本切分及音频生成,模块化设计配中文注释,本地部署开源免费,小白可轻松实现高质量语音克隆。
LongCat-AudioDiT WebUI 是基于该模型的可视化工具,支持音色库管理、剧本队列编排、长文本切分及音频生成,模块化设计配中文注释,本地部署开源免费,小白可轻松实现高质量语音克隆。
AI漫剧

AutoAnimation短剧漫剧自动化工具
53@IAI666
3301299H更新时间:2026-04-10
AutoAnimation短剧漫剧自动化工具及配套ComfyUI包含ZImage、flux2-kelin、qwenedit2511、wan2.2、qwen-tts、index-tts
AutoAnimation短剧漫剧自动化工具及配套ComfyUI包含ZImage、flux2-kelin、qwenedit2511、wan2.2、qwen-tts、index-tts
ComfyUILTXLora训练

ltx2.3-aitookit
5@有趣的80后程序员
认证作者70121H更新时间:2026-04-13
支持自启动ltx2.3 aitookit Lora训练镜像
ltx2.3 aitookit Lora训练镜像
IndexTTS语音合成AI应用

indextts-v1.52支持api调用deepspeed推理加速,并发请求,为AI直播优化的版本
7@屾哥日记
7029564H更新时间:2026-04-10
支持自启动indextts-v1.52支持api调用deepspeed推理加速,并发请求,为AI直播优化的版本
indextts-v1.52支持api调用deepspeed推理加速,并发请求,为AI直播优化的版本
物理模拟分子动力

Gromacs系列
28@苍耳阿猫
认证作者59219241H更新时间:2026-04-09
该镜像集成开源高性能分子动力学模拟软件,通过强化多精度算法与GPU并行加速(支持NVIDIA/AMD显卡)实现纳秒级生物大分子运动模拟,优化AI辅助建模与超大体系计算效率,提供跨平台开箱即用解决方案
该镜像集成开源高性能分子动力学模拟软件,通过强化多精度算法与GPU并行加速(支持NVIDIA/AMD显卡)实现纳秒级生物大分子运动模拟,优化AI辅助建模与超大体系计算效率,提供跨平台开箱即用解决方案
GLMOCR识别

GLM-OCR
1@苍耳阿猫
认证作者31H更新时间:2026-04-09
GLM-OCR
GLM-OCR
语音合成语音识别

VOXCPM2语音合成,TTS,多音字控制,接口API调用,语速调节,支持50系,支持老显卡,音色保存,方言控制,开源阅读,支持超长文本
10@刘悦的技术博客
认证作者132200H更新时间:2026-04-08
支持自启动VOXCPM2语音合成,TTS,多音字控制,接口API调用,语速调节,支持50系,支持老显卡,音色保存,方言控制,开源阅读,支持超长文本
VOXCPM2语音合成,TTS,多音字控制,接口API调用,语速调节,支持50系,支持老显卡,音色保存,方言控制,开源阅读,支持超长文本
AI音乐

AI音乐制作ACE-Step-1.5XL官方包
8@鹄仙
认证作者58441H更新时间:2026-04-08
专业级别的AI音乐制作项目升级XL
专业级别的AI音乐制作项目升级XL
文本模型推理框架

Gemma-4 + GPT-OSS-120B 双破限大模型 WebUI 开箱即用镜像
23@AI-KSK
认证作者121135H更新时间:2026-04-09
支持自启动基于 Ollama + Open WebUI 搭建的双破限大模型共享镜像,集成 Gemma-4 与 GPT-OSS-120B 两类核心模型,支持浏览器直接访问与可视化聊天。
基于 Ollama + Open WebUI 搭建的双破限大模型共享镜像,集成 Gemma-4 与 GPT-OSS-120B 两类核心模型,支持浏览器直接访问与可视化聊天。
数字人LTXComfyUI

LTX-2.3-VBVR-图片数字人,真正无限时长,分片推理,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
13@刘悦的技术博客
认证作者102173H更新时间:2026-04-07
支持自启动LTX-2.3-VBVR-图片数字人,真正无限时长,分片推理,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
LTX-2.3-VBVR-图片数字人,真正无限时长,分片推理,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
视频生成LTX

LTX-2.3-VBVR-文生视频-首尾帧,单图无限时长,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
13@刘悦的技术博客
认证作者106108H更新时间:2026-04-07
支持自启动LTX-2.3-VBVR-文生视频-首尾帧,单图无限时长,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
LTX-2.3-VBVR-文生视频-首尾帧,单图无限时长,自动补帧,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
语音合成语音识别

OmniVoice,接口api使用,支持600种语言,4G显存可用,速度1比0.3,文本指令,支持呻吟笑声,文字转语音,支持超长文本,声音克隆,小米k2-fsa团队开源
21@刘悦的技术博客
认证作者223728H更新时间:2026-04-05
支持自启动OmniVoice,接口api使用,支持600种语言,4G显存可用,速度1比0.3,文本指令,支持呻吟笑声,文字转语音,支持超长文本,声音克隆,小米k2-fsa团队开源
OmniVoice,接口api使用,支持600种语言,4G显存可用,速度1比0.3,文本指令,支持呻吟笑声,文字转语音,支持超长文本,声音克隆,小米k2-fsa团队开源
语音合成语音识别

LongCat-AudioDiT-1B-3.5B,TTS,音色保存,接口API调用,支持超长文本,支持50系显卡,语速调节,文字转语音,TTS
4@刘悦的技术博客
认证作者4440H更新时间:2026-04-05
支持自启动LongCat-AudioDiT-1B-3.5B,6G显存可用,TTS,音色保存,接口API调用,支持超长文本,支持50系显卡,语速调节,文字转语音,TTS
LongCat-AudioDiT-1B-3.5B,6G显存可用,TTS,音色保存,接口API调用,支持超长文本,支持50系显卡,语速调节,文字转语音,TTS
语音合成

ComfyUI-OmniVoice-TTS小米团队开源单人多人声音克隆语音克隆捏声音
4@鸡你太美
认证作者4435H更新时间:2026-04-27
支持自启动ComfyUI-OmniVoice-TTS小米团队开源单人多人声音克隆语音克隆捏声音
ComfyUI-OmniVoice-TTS小米团队开源单人多人声音克隆语音克隆捏声音
其他

trading-agents针对国内股票的股票交易Agent
1@鸡你太美
认证作者745H更新时间:2026-04-27
支持自启动trading-agents针对国内股票的股票交易Agent
trading-agents针对国内股票的股票交易Agent
视频生成

最强AI视频抠像,MatAnyone2,超强抠像效果,支持超长视频!
10@与AI同行
认证作者100186H更新时间:2026-04-06
支持自启动最强AI视频抠像,MatAnyone2,超强抠像效果,支持超长视频!
最强AI视频抠像,MatAnyone2,超强抠像效果,支持超长视频!
Lora训练

ai-toolkit全能Lora模型训练王
18@老徐Ai研习社
认证作者2083328H更新时间:2026-04-09
支持自启动主流模型都有
主流模型都有
ComfyUI视频生成视频编辑

wan2.2动作迁移
27@
20854H更新时间:2026-04-02
wan2.2动作迁移
wan2.2动作迁移
ComfyUIQwen-Image图片编辑

Qwen-Edit-2511-Rapid-V23,图像编辑,表情控制,多图编辑,自动提示词,批量任务,支持50系
32@刘悦的技术博客
认证作者4361008H更新时间:2026-04-01
支持自启动Qwen-Edit-2511-Rapid-V23,图像编辑,表情控制,多图编辑,自动提示词,批量任务,支持50系
Qwen-Edit-2511-Rapid-V23,图像编辑,表情控制,多图编辑,自动提示词,批量任务,支持50系
AI应用图片编辑图像分割

Live2d神器一键拆分See-through
50@梦影Erislia
8521757H更新时间:2026-03-31
Live2d神器一键拆分See-through
Live2d神器一键拆分See-through
语音合成

MOSS-TTS 语音模型
5@刘悦的技术博客
认证作者5464H更新时间:2026-03-31
支持自启动MOSS-TTS,接口API,语音合成,声音克隆,TTS,支持超长文本,支持50系
MOSS-TTS,接口API,语音合成,声音克隆,TTS,支持超长文本,支持50系
ComfyUILTX视频生成

LTX-2.3-Transition-文生视频
7@刘悦的技术博客
认证作者110118H更新时间:2026-03-30
支持自启动LTX-2.3-Transition-文生视频-首尾帧,无限时长,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
LTX-2.3-Transition-文生视频-首尾帧,无限时长,支持50系,自定义分辨率,自适应端口,自动提示词,批量任务队列
ComfyUIWan视频生成

Wan 2.2 无限制 3.0
58@AI-KSK
认证作者5051748H更新时间:2026-04-09
集成 SmoothMix T2V 3.0 与 Remix I2V 3.0,支持无限制文本生视频与图生视频创作,兼顾画质、动态、运镜与一致性,适合快速出片与高完成度表达。
集成 SmoothMix T2V 3.0 与 Remix I2V 3.0,支持无限制文本生视频与图生视频创作,兼顾画质、动态、运镜与一致性,适合快速出片与高完成度表达。
视频生成

X-Dub-WebUI
1@鸡你太美
认证作者2020H更新时间:2026-04-27
支持自启动X-Dub-WebUI可灵团队推出的视频驱动唇形生成与任意尺寸视频数字人视频生成 二次开发webui构建By科哥
X-Dub-WebUI可灵团队推出的视频驱动唇形生成与任意尺寸视频数字人视频生成 二次开发webui构建By科哥
LTX视频生成数字人

LTX-2.3-Transition--图片数字人
11@刘悦的技术博客
认证作者112148H更新时间:2026-03-30
支持自启动LTX-2.3-Transition--图片数字人,更好的稳定性,无限时长,支持50系,自定义分辨率
LTX-2.3-Transition--图片数字人,更好的稳定性,无限时长,支持50系,自定义分辨率
图片生成图片编辑

最强AI图片编辑,FireRed-Edit整合包合集,商用顶级图片效果!
27@与AI同行
认证作者3742286H更新时间:2026-03-31
支持自启动最强AI图片编辑,FireRed-Edit整合包合集,商用顶级图片效果!支持多图编辑、局部涂抹编辑、高清放大,解压即用,一键启动!
最强AI图片编辑,FireRed-Edit整合包合集,商用顶级图片效果!支持多图编辑、局部涂抹编辑、高清放大,解压即用,一键启动!
ComfyUI视频编辑视频生成

陈晨的comfyui云端镜像系列
13@陈晨
117248H更新时间:2026-03-30
支持自启动内置多个工作流 开箱即用
内置多个工作流 开箱即用
数字人ComfyUI视频生成

图片·声音·视频·2603comfyui全能整合包
34@老徐Ai研习社
认证作者3102851H更新时间:2026-03-26
支持自启动图片·声音·视频·2603comfyui全能整合包
图片·声音·视频·2603comfyui全能整合包
ComfyUILTX视频生成

LTX-2.3 LoRA训练 +AIToolkit 4090/48G/5090 一键开训
6@AI-KSK
认证作者79626H更新时间:2026-03-28
集成AIToolkit与LTX-2 LoRA训练全套环境,适配4090 48G/5090预设参数,支持一键启动、缓存优化、依赖预装,开箱即可进行音视频LoRA训练
集成AIToolkit与LTX-2 LoRA训练全套环境,适配4090 48G/5090预设参数,支持一键启动、缓存优化、依赖预装,开箱即可进行音视频LoRA训练
数字人ComfyUIFlux

LTX2.3 创作增强旗舰版
19@AI-KSK
认证作者139227H更新时间:2026-03-26
基于LTX2.3深度整合的全功能创作镜像,集成ID-LoRA、换头、局部重绘、多图首尾帧等特色能力,环境完整、依赖丰富,适合视频生成、角色一致性控制与多场景创作。
基于LTX2.3深度整合的全功能创作镜像,集成ID-LoRA、换头、局部重绘、多图首尾帧等特色能力,环境完整、依赖丰富,适合视频生成、角色一致性控制与多场景创作。
LTXLora训练视频生成

LTX2.3Lora训练用AI-toolkit,简单配置一键训练
10@梦影Erislia
1532129H更新时间:2026-03-25
LTX2.3Lora训练用AI-toolkit,简单配置一键训练
LTX2.3Lora训练用AI-toolkit,简单配置一键训练
数据分析其他

MiroFish一个ai预测系统数据模型预测ai系统 构建by科哥
4@鸡你太美
认证作者1839H更新时间:2026-04-27
支持自启动MiroFish一个ai预测系统数据模型预测ai系统 构建by科哥
MiroFish一个ai预测系统数据模型预测ai系统 构建by科哥
AI应用视频编辑图片编辑

MatAnyone2
3@刘悦的技术博客
认证作者92119H更新时间:2026-03-23
支持自启动MatAnyone2,视频图片一键去背,换背景,智能提取前景主体,支持GPU和纯CPU推理,绿幕生成器
MatAnyone2,视频图片一键去背,换背景,智能提取前景主体,支持GPU和纯CPU推理,绿幕生成器
AI音乐

SoulX-Singer-SVC
18@鹄仙
认证作者177304H更新时间:2026-03-20
一键翻唱神器
一键翻唱神器
Lora训练LTX其他

LTX2.3Lora训练支持Musubi-tuner
6@梦影Erislia
90528H更新时间:2026-03-18
LTX2.3Lora训练支持Musubi-tuner
LTX2.3Lora训练支持Musubi-tuner
Qwen3-TTS语音合成语音识别

Faster-Qwen3-TTS
82@刘悦的技术博客
认证作者302717H更新时间:2026-03-18
支持自启动Faster-Qwen3-TTS,流式接口API,实时推理,速度1比0.5,多人对话,智能多音字,4G显存可用,批量任务,支持超长文本,支持50系显卡,支持老显卡
Faster-Qwen3-TTS,流式接口API,实时推理,速度1比0.5,多人对话,智能多音字,4G显存可用,批量任务,支持超长文本,支持50系显卡,支持老显卡
语音合成

Fish-Speech-S2-Pro-4B
9@刘悦的技术博客
认证作者98317H更新时间:2026-03-18
支持自启动Fish-Speech-S2-Pro-4B,接口api使用,支持62种语言,文本指令,文字转语音,声音克隆,zero-shot
Fish-Speech-S2-Pro-4B,接口api使用,支持62种语言,文本指令,文字转语音,声音克隆,zero-shot
AI音乐

SongGeneration音乐生成
7@鹄仙
认证作者2324H更新时间:2026-03-20
音乐生成工具,应用简单
音乐生成工具,应用简单
ComfyUIZ-Image图片生成

Z-Image Turbo 无限制生成控制放大一体化镜像
34@AI-KSK
认证作者405876H更新时间:2026-03-13
集成文生图、图生图、ControlNet 控制、提示词优化、放大增强等全员破限工作流。
集成文生图、图生图、ControlNet 控制、提示词优化、放大增强等全员破限工作流。
ComfyUIWan视频超分

视频批量补帧、超分放大与细节修复,ComfyUI视频增强镜像,Seedance2.0黄金搭档
36@AI-KSK
认证作者2081092H更新时间:2026-03-12
集成 FlashVSR / GIMM / LTX-2 / SeedVR2 的 ComfyUI 视频增强镜像,一键批量补帧、放大、细节修复。
集成 FlashVSR / GIMM / LTX-2 / SeedVR2 的 ComfyUI 视频增强镜像,一键批量补帧、放大、细节修复。
LTXComfyUI数字人

LTX-2.3-GGUF-图片数字人
19@刘悦的技术博客
认证作者197349H更新时间:2026-03-18
支持自启动LTX-2.3-GGUF-图片数字人-无限时长,更好的一致性,8步采样,支持50系,自定义分辨率,自动补帧,自动提示词,批量任务队列
LTX-2.3-GGUF-图片数字人-无限时长,更好的一致性,8步采样,支持50系,自定义分辨率,自动补帧,自动提示词,批量任务队列
ComfyUILTX视频生成

LTX-2.3-GGUF-图生视频
30@刘悦的技术博客
认证作者356571H更新时间:2026-03-18
支持自启动LTX-2.3-GGUF-图生视频-无限时长,更好的一致性,8步采样,自定义分辨率,自动补帧,自动提示词,批量任务队列
LTX-2.3-GGUF-图生视频-无限时长,更好的一致性,8步采样,自定义分辨率,自动补帧,自动提示词,批量任务队列
Lora训练推理框架文本模型

大模型微调部署测评_LLaMa-Factory>vLLM>opencompass
3@影赤
33185H更新时间:2026-03-10
大模型微调部署测评全流程环境已安装
大模型微调部署测评全流程环境已安装
ComfyUILTXWan

图片-声音-视频Comfyui全量整合包-LTX2.3-Wan2.2-Z-Image-Turbo漫剧全能助手
71@老徐Ai研习社
认证作者6837170H更新时间:2026-03-10
支持自启动漫剧全能助手
漫剧全能助手
ComfyUIQwen-Image图片编辑

FireRed-ImageEdit-V1.1-GGUF
23@刘悦的技术博客
认证作者185240H更新时间:2026-03-18
支持自启动FireRed-ImageEdit-V1.1-GGUF,局部重绘,图像编辑,4步采样,多图编辑,支持50系,自定义分辨率
FireRed-ImageEdit-V1.1-GGUF,局部重绘,图像编辑,4步采样,多图编辑,支持50系,自定义分辨率
LTXComfyUI视频生成

LTX-2.3 开源音视频一体生成模型|文生视频+图生视频
12@AI-KSK
认证作者142376H更新时间:2026-03-10
基于 LTX-2.3 的音视频一体生成模型镜像,支持文生视频、图生视频等常见生成方式
基于 LTX-2.3 的音视频一体生成模型镜像,支持文生视频、图生视频等常见生成方式
Lora训练

Z-Image 模型一站式训练 & 推理-None_Z-trainer
5@zypAIGC
279H更新时间:2026-03-06
支持自启动Z-Image 模型一站式训练 & 推理-None_Z-trainer
Z-Image 模型一站式训练 & 推理-None_Z-trainer
ComfyUIWan视频生成

Wan2.2-SmoothMixV20-SVI2-VBVR,图生视频,无限时长,自动补帧,8步采样,无须手动复制粘贴节点,,支持批量任务,Comfyui
43@刘悦的技术博客
认证作者473988H更新时间:2026-03-06
支持自启动Wan2.2-SmoothMixV20-SVI2-VBVR,图生视频,无限时长,自动补帧,8步采样,无须手动复制粘贴节点,,支持批量任务,Comfyui
Wan2.2-SmoothMixV20-SVI2-VBVR,图生视频,无限时长,自动补帧,8步采样,无须手动复制粘贴节点,,支持批量任务,Comfyui
Lora训练

diffusion-pipe+ai-toolkit丹炉
3@zypAIGC
810H更新时间:2026-03-06
支持自启动diffusion-pipe+ai-toolkit
diffusion-pipe+ai-toolkit
ComfyUIZ-Image图片生成

Qwen3-4b-Z-Image-Engineer,文生图,图生图,洗图,6G显存可用,局部重绘,自动提示词,支持50系,批量任务队列
37@刘悦的技术博客
认证作者413782H更新时间:2026-03-10
支持自启动Qwen3-4b-Z-Image-Engineer,文生图,图生图,洗图,6G显存可用,局部重绘,自动提示词,支持50系,批量任务队列
Qwen3-4b-Z-Image-Engineer,文生图,图生图,洗图,6G显存可用,局部重绘,自动提示词,支持50系,批量任务队列
视频生成

SoulX-FlashTalk数字人视频图片生成ai数字人说话数字人 webui二次开发
6@鸡你太美
认证作者1331H更新时间:2026-05-09
支持自启动SoulX-FlashTalk数字人视频图片生成ai数字人说话数字人 webui二次开发 构建by科哥
SoulX-FlashTalk数字人视频图片生成ai数字人说话数字人 webui二次开发 构建by科哥
生物信息分子动力

RFantibody
1@苍耳阿猫
认证作者627H更新时间:2026-03-03
RFantibody
RFantibody
AI应用

OpenClaw / ClawdBot
26@优云智算
50816566H更新时间:2026-03-16
OpenClaw 2026.3.2版本,支持飞书、Telegram接入,支持优云智算模型API
OpenClaw 2026.3.2版本,支持飞书、Telegram接入,支持优云智算模型API
数字人WanLTX

SoulX-FlashHead-图片数字人,支持贴回全身数字人,低配版InfiniteTalk,唱歌数字人,支持长视频
20@刘悦的技术博客
认证作者136219H更新时间:2026-03-03
支持自启动SoulX-FlashHead-图片数字人,支持贴回全身数字人,低配版InfiniteTalk,唱歌数字人,支持长视频
SoulX-FlashHead-图片数字人,支持贴回全身数字人,低配版InfiniteTalk,唱歌数字人,支持长视频
Qwen

Qwen3.5_35b_a3b_Q4_K_M
7@
65373H更新时间:2026-03-02
qwen3.5
qwen3.5
ComfyUIWan视频生成

Wan2.2双增强:UnifiedReward让文生视频更符合审美预期,VBVR让图生视频更符合真实运动逻辑
13@AI-KSK
认证作者191427H更新时间:2026-03-06
这个镜像内置 Wan2.2 两套增强技术:UnifiedReward 让文生视频更好看、更符合偏好,VBVR 让图生视频动作更合理、更符合逻辑。
这个镜像内置 Wan2.2 两套增强技术:UnifiedReward 让文生视频更好看、更符合偏好,VBVR 让图生视频动作更合理、更符合逻辑。
语音识别Qwen3-TTS语音分离

Qwen3-ASR-1.7B,语音转文字字幕,视频转字幕,支持50系显卡,批量任务,支持热词控制
8@刘悦的技术博客
认证作者97887H更新时间:2026-06-05
支持自启动Qwen3-ASR-1.7B,语音转文字字幕,视频转字幕,支持50系显卡,批量任务,支持热词控制
Qwen3-ASR-1.7B,语音转文字字幕,视频转字幕,支持50系显卡,批量任务,支持热词控制
InfiniteTalk其他数字人

life学员
6@life
37205H更新时间:2026-02-28
life学员专用数字人镜像
life学员专用数字人镜像
ComfyUIWan视频生成

Comfy漫画上色DasiWa视频支持自由拉取C站模型更新等
8@梦影Erislia
94338H更新时间:2026-02-27
Comfy漫画上色DasiWa视频支持自由拉取C站模型更新等
Comfy漫画上色DasiWa视频支持自由拉取C站模型更新等
视频生成

超快视频替换背景Video-BGR
17@与AI同行
认证作者6448H更新时间:2026-03-31
支持自启动超快视频替换背景Video-BGR
超快视频替换背景Video-BGR
数字人视频超分

HeyGem数字人最新Onnx优化版,多人同时驱动,多人指定面部驱动,接口API调用,支持50系,面部超分,推理速度1比1,唱歌数字人,批量任务
48@刘悦的技术博客
认证作者85210245H更新时间:2026-03-09
支持自启动HeyGem数字人最新Onnx优化版,多人同时驱动,多人指定面部驱动,接口API调用,支持50系,面部超分,推理速度1比1,唱歌数字人,批量任务
HeyGem数字人最新Onnx优化版,多人同时驱动,多人指定面部驱动,接口API调用,支持50系,面部超分,推理速度1比1,唱歌数字人,批量任务
AI应用

DocCaptioner 打标器
14@Doc_workBox
认证作者133230H更新时间:2026-02-26
支持自启动Doc的打标器,支持 Qwen3vl及 API 调用
Doc的打标器,支持 Qwen3vl及 API 调用
语音合成语音识别

Ming-omni-tts-0.5B,接口API调用,支持超长文本,情感控制,中英混读,支持50系显卡
6@刘悦的技术博客
认证作者38326H更新时间:2026-02-25
支持自启动 Ming-omni-tts-0.5B,接口API调用,支持超长文本,情感控制,中英混读,支持50系显卡
Ming-omni-tts-0.5B,接口API调用,支持超长文本,情感控制,中英混读,支持50系显卡
语音识别

FireRedASR2S语音识别转文字语音转文本音频转文本模型ai系统 二次构建开发 by科哥
2@鸡你太美
认证作者2628H更新时间:2026-04-27
支持自启动FireRedASR2S语音识别转文字语音转文本音频转文本模型ai系统 二次构建开发 by科哥
FireRedASR2S语音识别转文字语音转文本音频转文本模型ai系统 二次构建开发 by科哥
ComfyUI视频生成Wan

终极角色动画合集镜像Wan 2.2、SCAIL、SteadyDancer、OneToAll 和VACE Phantom
16@AI-KSK
认证作者4732H更新时间:2026-02-26
Wan 2.2、SCAIL、SteadyDancer、OneToAll 和VACE_Skyreels_V3_R2V的“五合一”整合镜像
Wan 2.2、SCAIL、SteadyDancer、OneToAll 和VACE_Skyreels_V3_R2V的“五合一”整合镜像
目标检测

羊羊小栈-YOLO目标检测大模型分析系统
1@
20203H更新时间:2026-02-25
支持自启动YOLO模型训练
YOLO模型训练
语音合成

AudioX 统一音频生成平台通过一段提示词一段视频推理一段配音音效 webui汉化构建by科哥
2@鸡你太美
认证作者2756H更新时间:2026-04-27
支持自启动AudioX 统一音频生成平台通过一段提示词一段视频推理一段配音音效 webui汉化构建by科哥
AudioX 统一音频生成平台通过一段提示词一段视频推理一段配音音效 webui汉化构建by科哥
文本模型行业模型推理框架

HunYuan-MT-7B-abliterated,40种多国语言无限制双向翻译,长文本翻译,字幕翻译,双语字幕,腾讯开源,不文明用语翻译
5@刘悦的技术博客
认证作者1610H更新时间:2026-02-25
支持自启动HunYuan-MT-7B-abliterated,40种多国语言无限制双向翻译,长文本翻译,字幕翻译,双语字幕,腾讯开源,不文明用语翻译
HunYuan-MT-7B-abliterated,40种多国语言无限制双向翻译,长文本翻译,字幕翻译,双语字幕,腾讯开源,不文明用语翻译
ComfyUIQwen-Image图片编辑

FireRed-ImageEdit,图像编辑,多图编辑,支持50系,自定义分辨率,自动提示词,批量任务队列,基于Comfyui
29@刘悦的技术博客
认证作者298534H更新时间:2026-02-25
支持自启动FireRed-ImageEdit,图像编辑,多图编辑,支持50系,自定义分辨率,自动提示词,批量任务队列,基于Comfyui
FireRed-ImageEdit,图像编辑,多图编辑,支持50系,自定义分辨率,自动提示词,批量任务队列,基于Comfyui
图片生成AI应用

BitDance-14B高速自回归生图模型,自启动WebUI版测试镜像
0@AI-KSK
认证作者2432H更新时间:2026-02-25
支持自启动BitDance-14B自启动 WebUI 测试镜像:开箱即用、中文可用、512/1024 双分辨率支持,面向高效验证与稳定出图。
BitDance-14B自启动 WebUI 测试镜像:开箱即用、中文可用、512/1024 双分辨率支持,面向高效验证与稳定出图。
AI音乐语音识别

SoulX-Singer歌曲翻唱 带官方Midi编辑器
8@鹄仙
认证作者6947H更新时间:2026-03-20
SoulX-Singer歌曲翻唱 带官方Midi编辑器完成精细翻唱编辑
SoulX-Singer歌曲翻唱 带官方Midi编辑器完成精细翻唱编辑
语音合成Qwen3-TTS

Qwen3-TTS-AllinOne
41@刘悦的技术博客
认证作者4961659H更新时间:2026-02-27
支持自启动Qwen3-TTS-AllinOne,多音字控制,英文数字发音纠正,批量任务,音色保存,接口API调用,支持超长文本,语速调节,文字转语音,TTS
Qwen3-TTS-AllinOne,多音字控制,英文数字发音纠正,批量任务,音色保存,接口API调用,支持超长文本,语速调节,文字转语音,TTS
图片生成视频生成

Penguin-Magic一个图片视频API在线生成的无限画布的批量生成工作流开源项目 构建by科哥
1@鸡你太美
认证作者613H更新时间:2026-04-27
支持自启动Penguin-Magic一个图片视频API在线生成的无限画布的批量生成工作流开源项目 构建by科哥 版权属于原作者
Penguin-Magic一个图片视频API在线生成的无限画布的批量生成工作流开源项目 构建by科哥 版权属于原作者
数字人
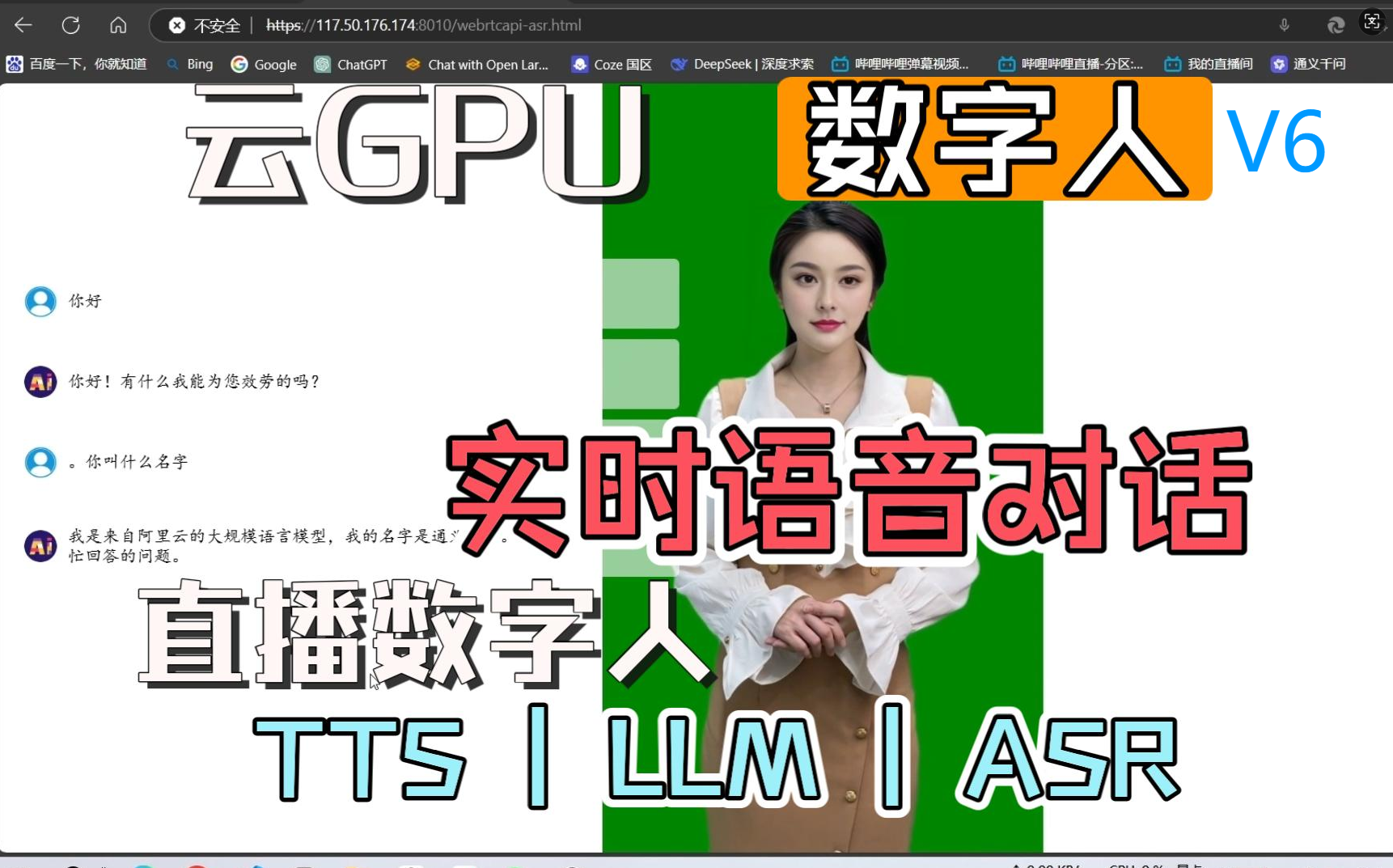
LiveTalking_GPT-SOVITS-V2_Ollama_洛曦AI数字人
28@Ikaros
77683H更新时间:2026-02-24
LiveTalking + GPT-SOVITS V2 + Ollama + FunASR 洛曦AI定制版,实时语音对话数字人 + 直播版数字人
LiveTalking + GPT-SOVITS V2 + Ollama + FunASR 洛曦AI定制版,实时语音对话数字人 + 直播版数字人
视频超分

最快AI视频高清修复FlashVSR-支持批量生成
140@与AI同行
认证作者264010795H更新时间:2026-03-31
支持自启动最快AI视频高清修复FlashVSR
最快AI视频高清修复FlashVSR
语音合成语音分离AI音乐

SoulX-Singer
16@刘悦的技术博客
认证作者103106H更新时间:2026-02-27
支持自启动SoulX-Singer,零样本变声器,AI歌曲翻唱,歌词修改,改歌词,语音内容修改
SoulX-Singer,零样本变声器,AI歌曲翻唱,歌词修改,改歌词,语音内容修改
ComfyUIWanQwen-Image

ComfyUI云端整合包2602
23@鹄仙
认证作者2381405H更新时间:2026-02-13
全面升级到torch2.10+cu130
全面升级到torch2.10+cu130
音乐语音分离语音识别

AI音乐制作项目ACE-Step-1.5官方包
11@鹄仙
认证作者90588H更新时间:2026-02-25
专业级别的AI音乐制作项目
专业级别的AI音乐制作项目
AI音乐

ACE-Step-1.5,AI歌曲生成,男女对唱,纯音乐生成
12@刘悦的技术博客
认证作者60133H更新时间:2026-02-25
支持自启动ACE-Step-1.5,AI歌曲生成,男女对唱,纯音乐生成
ACE-Step-1.5,AI歌曲生成,男女对唱,纯音乐生成
3D生成

UltraShape-1.0
1@苍耳阿猫
认证作者2235H更新时间:2026-02-25
UltraShape-1.0
UltraShape-1.0
AI应用视频生成视频编辑

LingBot-World
0@敢敢のwings
认证作者1767H更新时间:2026-02-25
蚂蚁集团旗下具身智能公司灵波科技(Robbyant)正式开源了其世界模型 LingBot-World。这一消息发布后迅速登顶全球社交媒体热榜,引发了人工智能领域的广泛关注
蚂蚁集团旗下具身智能公司灵波科技(Robbyant)正式开源了其世界模型 LingBot-World。这一消息发布后迅速登顶全球社交媒体热榜,引发了人工智能领域的广泛关注
视频生成

最强AI生成数字人,InfiniteTalk官方版 v260209
33@与AI同行
认证作者4732744H更新时间:2026-03-31
支持自启动最强AI生成数字人,InfiniteTalk官方版 v260209,支持图片数字人,支持超长视频、批量队列生成!
最强AI生成数字人,InfiniteTalk官方版 v260209,支持图片数字人,支持超长视频、批量队列生成!
ComfyUIIndexTTSWan

comfyui工作站
14@AI绘视玩家
1491054H更新时间:2026-02-10
支持自启动集成图片生成|视频生成|数字人|声音编辑|音乐生成!配套Comfyui批量管理生成软件到(B站)【AI绘视玩家】处获取~
集成图片生成|视频生成|数字人|声音编辑|音乐生成!配套Comfyui批量管理生成软件到(B站)【AI绘视玩家】处获取~
ComfyUIWan数字人

Comfyui2月最新整合包,含最新klein、Z-image全系、WAN全系、LTX2.0等
70@老许爱吃肉丶
3541507H更新时间:2026-02-25
支持自启动自用!Comfyui2月最新整合包,含最新klein、Z-image全系、WAN全系、LTX2.0等
自用!Comfyui2月最新整合包,含最新klein、Z-image全系、WAN全系、LTX2.0等
语音合成AI音乐

ACE-Step-1.5官方原版,修复吞歌词问题,音乐重构,音乐重绘,AI歌曲生成,男女对唱,纯音乐生成,相关竞品:DiffRhythm/yuE/HeartMuLa
8@刘悦的技术博客
认证作者4241H更新时间:2026-02-25
支持自启动ACE-Step-1.5官方原版,修复吞歌词问题,音乐重构,音乐重绘,AI歌曲生成,男女对唱,纯音乐生成,相关竞品:DiffRhythm/yuE/HeartMuLa
ACE-Step-1.5官方原版,修复吞歌词问题,音乐重构,音乐重绘,AI歌曲生成,男女对唱,纯音乐生成,相关竞品:DiffRhythm/yuE/HeartMuLa
ComfyUI视频生成数字人

LTX2-Rapid-Merges视频生成
51@AI-KSK
认证作者279425H更新时间:2026-02-25
包含了文生、图生、首尾帧、对口型 4 大类工作流,提供SFW/NSFW的完整体验
包含了文生、图生、首尾帧、对口型 4 大类工作流,提供SFW/NSFW的完整体验
其他

ROX Quant 3.0 - 量化投研系统可无卡模式运行 投资有风险交易须谨慎
5@鸡你太美
认证作者1337H更新时间:2026-04-27
支持自启动ROX Quant 3.0 - 量化投研系统可无卡模式运行 投资有风险交易须谨慎
ROX Quant 3.0 - 量化投研系统可无卡模式运行 投资有风险交易须谨慎
语音合成语音克隆

【Qwen3TTS】声音克隆 音色定制 长文本推理优化镜像
17@两只鸽子
223453H更新时间:2026-02-25
支持自启动Qwen3TTS推理镜像
Qwen3TTS推理镜像
InfiniteTalk数字人

InfiniteTalk数字人最新官方更新,上下文循环,一致性和速度优化,4步采样,高清放大,批量任务队列,基于comfyui,工作流
50@刘悦的技术博客
认证作者621883H更新时间:2026-02-06
支持自启动InfiniteTalk数字人最新官方更新,上下文循环,一致性和速度优化,4步采样,高清放大,批量任务队列,基于comfyui,工作流
InfiniteTalk数字人最新官方更新,上下文循环,一致性和速度优化,4步采样,高清放大,批量任务队列,基于comfyui,工作流
语音合成AI音乐

K哥配音工作室(indextts2音色克隆+qwen3-tts音色生成+HeartMuLay音乐生成)
22@K哥讲AI
认证作者3205255H更新时间:2026-02-05
支持自启动多功能配音镜像,融合 indextts2.qwen3-tts音色克隆 HeartMuLa音乐生成,支持多角色配音、文本创音色、一键克隆、音乐一键生成,还有 AI 角色分配.基础音色库及多语言.方言配音
多功能配音镜像,融合 indextts2.qwen3-tts音色克隆 HeartMuLa音乐生成,支持多角色配音、文本创音色、一键克隆、音乐一键生成,还有 AI 角色分配.基础音色库及多语言.方言配音
ComfyUILTX

ComfyUI云端整合包LTX-2特别版
19@鹄仙
认证作者55200H更新时间:2026-02-12
支持LTX-2 scail wan2.2系列
支持LTX-2 scail wan2.2系列
图片生成Z-Image

red-Z-Image-Base,15步采样,自定义分辨率,文生图,图生图,自动提示词,批量任务
18@刘悦的技术博客
认证作者225139H更新时间:2026-02-04
支持自启动red-Z-Image-Base,15步采样,自定义分辨率,文生图,图生图,自动提示词,批量任务
red-Z-Image-Base,15步采样,自定义分辨率,文生图,图生图,自动提示词,批量任务
Qwen语音识别

Qwen-ASR
0@有黑眼圈的小竹熊
2466H更新时间:2026-02-04
Qwen3-ASR 系列包括 Qwen3-ASR-1.7B 和 Qwen3-ASR-0.6B,支持 52 种语言和方言的语言识别与语音识别(ASR)。
Qwen3-ASR 系列包括 Qwen3-ASR-1.7B 和 Qwen3-ASR-0.6B,支持 52 种语言和方言的语言识别与语音识别(ASR)。
ComfyUILTX

LTX-2-RapID-GGUF-图生视频-无限时长
19@刘悦的技术博客
认证作者129224H更新时间:2026-02-04
支持自启动LTX-2-RapID-GGUF-图生视频-无限时长
LTX-2-RapID-GGUF-图生视频-无限时长
ComfyUILTX

LTX-2-RapID-GGUF-图片数字人-无限时长
10@刘悦的技术博客
认证作者4553H更新时间:2026-02-05
支持自启动LTX-2-RapID-GGUF-图片数字人-无限时长
LTX-2-RapID-GGUF-图片数字人-无限时长
推理框架Qwen

nano-vllm
0@kq123jk6n9
735H更新时间:2026-02-03
从0到1,理解vllm的核心内容。包含注释讲解和使用实例,使用教程。帮助大家学习vllm
从0到1,理解vllm的核心内容。包含注释讲解和使用实例,使用教程。帮助大家学习vllm
ComfyUILTX

LTX2-视频生成最新整个大包(202602)
14@NiuGee
认证作者109144H更新时间:2026-02-04
支持自启动震惊!LTX-2开源视频模型,人人都能当导演?牛哥一键整合免费AI创作神器!
震惊!LTX-2开源视频模型,人人都能当导演?牛哥一键整合免费AI创作神器!
WanQwen-Image数字人
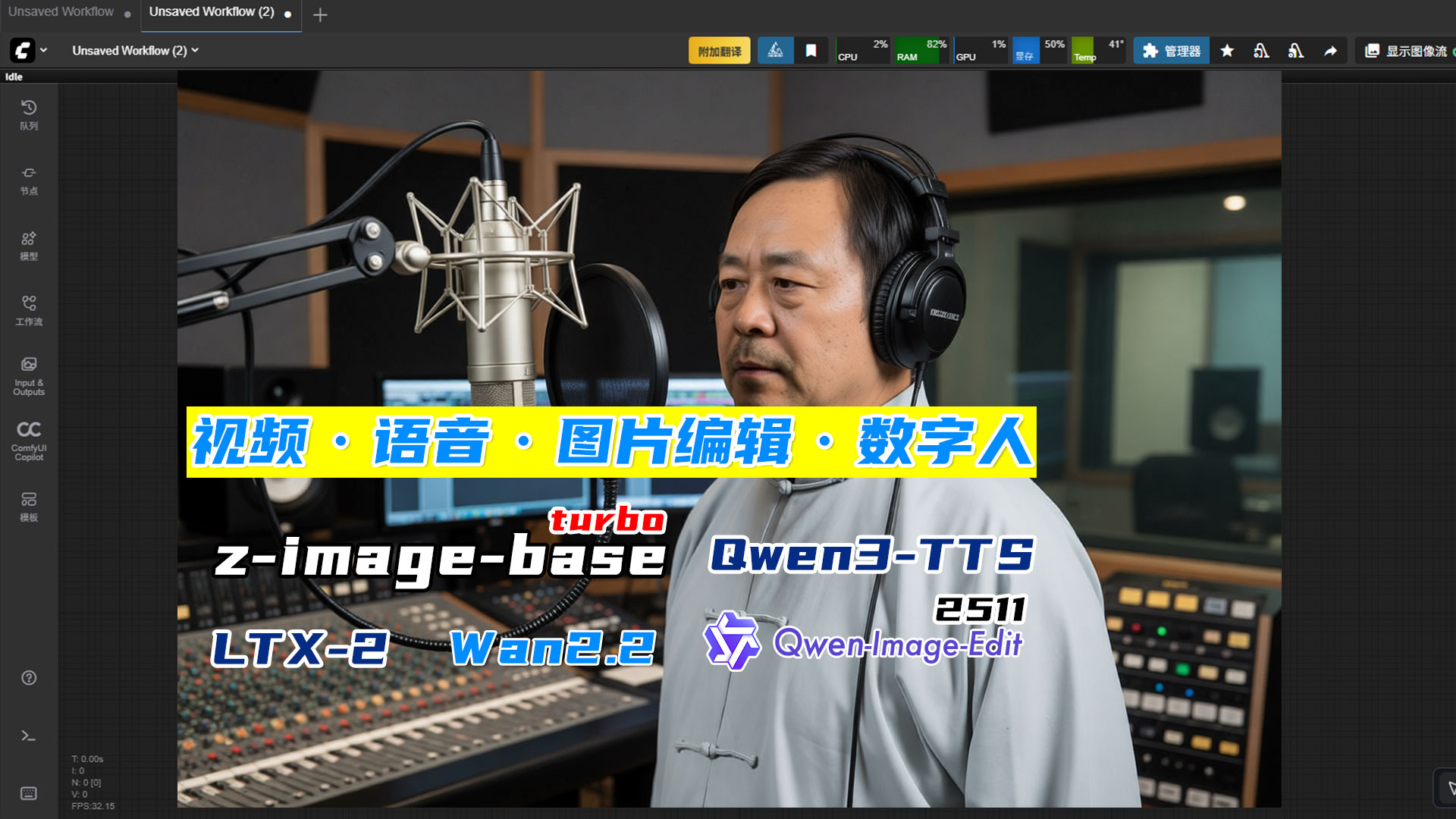
数字人-语音克隆-wan2.2视频换人换装-Qwen-Image-Edit2509整合包
91@老徐Ai研习社
认证作者8582632H更新时间:2026-02-02
支持自启动数字人-语音克隆-wan2.2视频换人换装-Qwen-Image-Edit2511整合包
数字人-语音克隆-wan2.2视频换人换装-Qwen-Image-Edit2511整合包
OCR识别

LightOn-OCR-1B,图片和PDF文字提取,图文混排,实时生成MarkDown文档,MarkDown文档下载,支持PDF全量解析
1@刘悦的技术博客
认证作者150H更新时间:2026-02-02
支持自启动LightOn-OCR-1B,图片和PDF文字提取,图文混排,实时生成MarkDown文档,MarkDown文档下载,支持PDF全量解析
LightOn-OCR-1B,图片和PDF文字提取,图文混排,实时生成MarkDown文档,MarkDown文档下载,支持PDF全量解析
图片生成Z-ImageQwen-Image

最全图片编辑模型大全-qwen2511多角度工作流-flux2-klein-9b全图片编辑模型-z-image-base图片生成模型
29@匹夫
认证作者3561289H更新时间:2026-02-04
最全图片编辑模型大全-qwen2511多角度工作流-flux2-klein-9b全图片编辑模型-z-image-base图片生成模型
最全图片编辑模型大全-qwen2511多角度工作流-flux2-klein-9b全图片编辑模型-z-image-base图片生成模型
Lora训练Z-Image

Z-Image-Base的Lora训练同时支持FluxKlein-AI-TOOLKIT
12@梦影Erislia
1511341H更新时间:2026-02-02
Z-Image-Base的Lora训练同时支持FluxKlein-AI-TOOLKIT
Z-Image-Base的Lora训练同时支持FluxKlein-AI-TOOLKIT
Lora训练LTXWan

ai-toolkit全能Lora模型训练器
21@老徐Ai研习社
认证作者2882109H更新时间:2026-02-01
支持自启动支持主流模型lora训练
支持主流模型lora训练
图片生成Lora训练

AI图片ZImage模型训练,一键启动WebUI、无需配置
114@与AI同行
认证作者6442678H更新时间:2026-03-31
支持自启动AI图片ZImage模型训练,一键启动WebUI、无需配置
AI图片ZImage模型训练,一键启动WebUI、无需配置
图片生成Z-Image

Nunchaku-ZImage极速出图
5@Tanjie7
314H更新时间:2026-01-30
ZImage Nunchaku版本,已经配置好nunchaku环境,可以直接启动使用comfyui+nunchaku zimage出图
ZImage Nunchaku版本,已经配置好nunchaku环境,可以直接启动使用comfyui+nunchaku zimage出图
ComfyUIWan视频生成

2026最新ComfyUI整合包_图片·视频·声音
22@老徐Ai研习社
认证作者2424053H更新时间:2026-01-30
支持自启动2026最新ComfyUI整合包_图片·视频·声音
2026最新ComfyUI整合包_图片·视频·声音
图片生成Z-Image

Z-Image-Base,35步采样,文生图,图生图,自动提示词,批量任务
15@刘悦的技术博客
认证作者170236H更新时间:2026-01-29
支持自启动Z-Image-Base,35步采样,文生图,图生图,自动提示词,批量任务
Z-Image-Base,35步采样,文生图,图生图,自动提示词,批量任务
ComfyUI

Comfyui 一张照片制作一个lora训练数据集
29@Prompt娄
1821008H更新时间:2026-01-29
支持自启动一张照片制作一个角色一致性lora训练数据集
一张照片制作一个角色一致性lora训练数据集
Z-Image图片生成

Z-Image
23@十字鱼
认证作者152950H更新时间:2026-01-30
支持自启动Z-Image是一个拥有6B参数的强大且高效的图像生成模型。
Z-Image是一个拥有6B参数的强大且高效的图像生成模型。
语音克隆

超级AI语音Qwen3-TTS合集,超强音色克隆、音色设计、情绪控制!
52@与AI同行
认证作者5061174H更新时间:2026-03-31
支持自启动超强AI语音生成,Qwen3-TTS整合包合集!超强音色克隆、音色设计、情绪控制,支持音色保存、多音字、超长文本生成。支持批量上传多个文件生成!
超强AI语音生成,Qwen3-TTS整合包合集!超强音色克隆、音色设计、情绪控制,支持音色保存、多音字、超长文本生成。支持批量上传多个文件生成!
图片生成Z-Image

Z-Image系列,Base+Tubro反推生图放大一体化
9@社恐的知识树
认证作者58273H更新时间:2026-01-28
支持自启动阿里开源的Z-Image系列模型
阿里开源的Z-Image系列模型
DeepSeekOCR识别
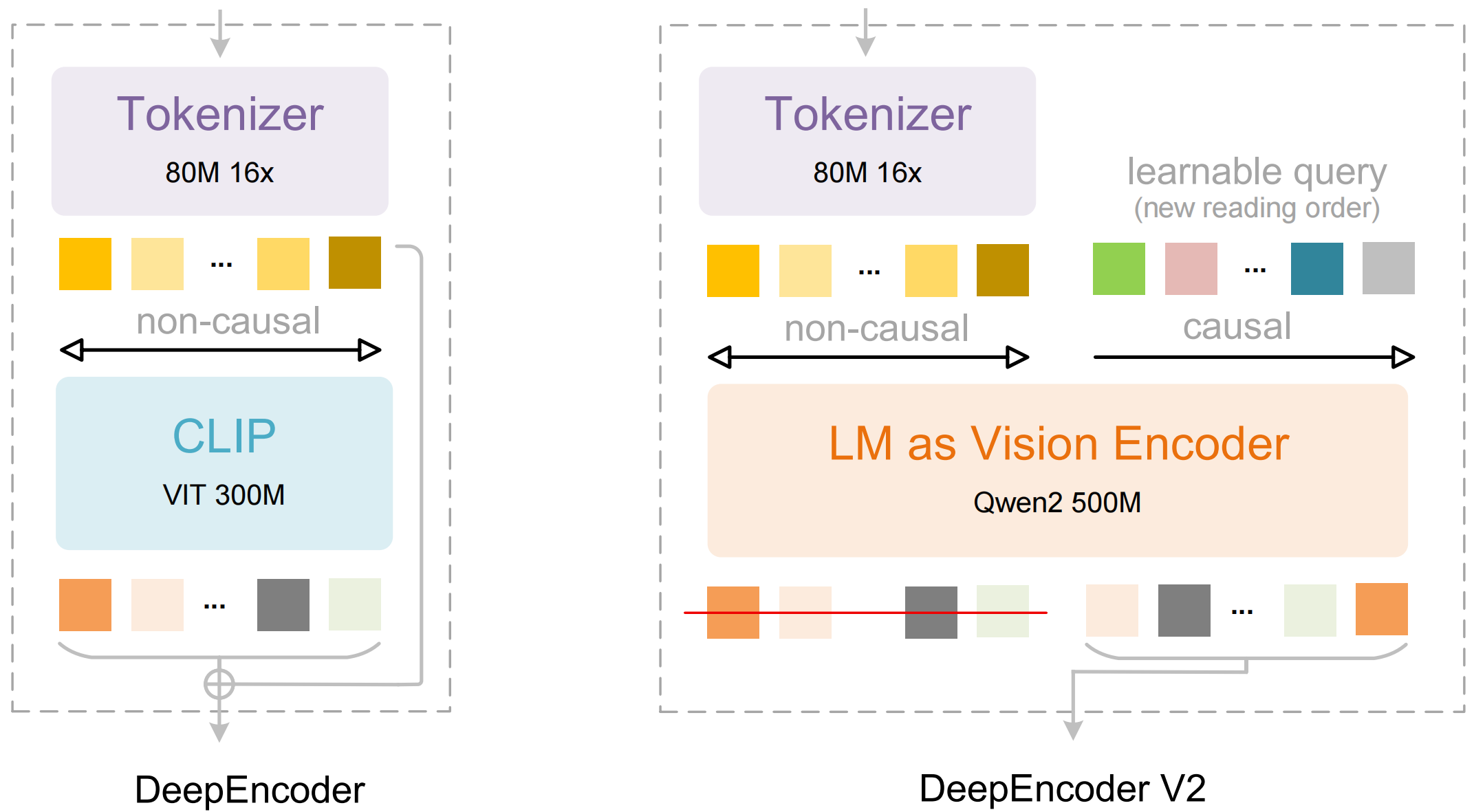
DeepSeek-OCR-2
1@敢敢のwings
认证作者824214H更新时间:2026-01-29
DeepSeek-OCR 2 是 DeepSeek 团队开源的新一代 OCR 模型,该模型能够像人类一样带着逻辑去阅读文档。
DeepSeek-OCR 2 是 DeepSeek 团队开源的新一代 OCR 模型,该模型能够像人类一样带着逻辑去阅读文档。
ComfyUI

ComfyUI学习版,内置多种基础模型-MumuOpenK
28@MumuOpenK
55110487H更新时间:2026-01-29
支持自启动内置多种基础模型,快速开启comfyui体验
内置多种基础模型,快速开启comfyui体验
数字人语音合成语音克隆

AI音乐、声音克隆:顶级数字人长视频套件V2
7@AI-KSK
认证作者2934H更新时间:2026-02-11
镜像打通HeartMuLa音乐、Qwen3-TTS音色克隆、InfiniteTalk/LongCat长对话数字人与LTX2视频:写歌配音→照片开口→长时稳成片。
镜像打通HeartMuLa音乐、Qwen3-TTS音色克隆、InfiniteTalk/LongCat长对话数字人与LTX2视频:写歌配音→照片开口→长时稳成片。
语音合成Qwen3-TTS

Qwen3-TTS语音模型, | 声音克隆 | 语音定制 | 语音预设 |
10@社恐的知识树
认证作者136114H更新时间:2026-01-27
阿里千问开源的最新语音类模型,显存占用小,生成速度快,支持10种主流语言。
阿里千问开源的最新语音类模型,显存占用小,生成速度快,支持10种主流语言。
AI音乐

HeartMuLa-HL,支持中文提示词,无须标签式歌词,更自然的AI歌曲生成,开源版Suno
4@刘悦的技术博客
认证作者4431H更新时间:2026-01-26
支持自启动HeartMuLa-HL,支持中文提示词,无须标签式歌词,更自然的AI歌曲生成,开源版Suno
HeartMuLa-HL,支持中文提示词,无须标签式歌词,更自然的AI歌曲生成,开源版Suno
AI音乐Qwen3-TTS

HeartMula& Qwen3TTS 歌曲生成与语音设计
0@鹄仙
认证作者112H更新时间:2026-01-29
基于HeartMula和Qwen3TTS的歌曲生成与语音设计
基于HeartMula和Qwen3TTS的歌曲生成与语音设计
FluxLora训练

Flux.Klein模型Lora训练AI-Toolkit
16@梦影Erislia
1571028H更新时间:2026-01-26
Flux.Klein模型Lora训练AI-Toolkit
Flux.Klein模型Lora训练AI-Toolkit
语音合成Qwen3-TTS

Qwen3-TTS-0.6B,推理速度1比0.5,音色保存,接口API调用,支持超长文本,支持50系显卡,语速调节,音频超分降噪,接入开源阅读,文字转语音,TTS
6@刘悦的技术博客
认证作者4425H更新时间:2026-01-26
支持自启动Qwen3-TTS-0.6B,推理速度1比0.5,音色保存,接口API调用,支持超长文本,支持50系显卡,语速调节,音频超分降噪,接入开源阅读,文字转语音,TTS
Qwen3-TTS-0.6B,推理速度1比0.5,音色保存,接口API调用,支持超长文本,支持50系显卡,语速调节,音频超分降噪,接入开源阅读,文字转语音,TTS
语音合成Qwen3-TTS

Qwen3-TTS-语音克隆工作流合集
5@匹夫
认证作者7286H更新时间:2026-01-26
Qwen3-TTS-语音克隆工作流合集
Qwen3-TTS-语音克隆工作流合集
语音合成Qwen3-TTS

Qwen3-TTS捏声音自定义声音tts语音克隆语音克隆声音flash_attn加速版Comfyui工作流版 构建by科哥
15@鸡你太美
认证作者172321H更新时间:2026-04-27
支持自启动Qwen3-TTS捏声音自定义声音tts语音克隆语音克隆声音flash_attn加速版Comfyui工作流版 构建by科哥
Qwen3-TTS捏声音自定义声音tts语音克隆语音克隆声音flash_attn加速版Comfyui工作流版 构建by科哥
语音合成Qwen3-TTS

Qwen3-TTS-1.7B,Flash-Attn加速,音色保存,接口API调用,支持超长文本,语速调节,音频超分降噪,接入开源阅读,文字转语音,TTS
10@刘悦的技术博客
认证作者119174H更新时间:2026-01-26
支持自启动Qwen3-TTS-1.7B,Flash-Attn加速,音色保存,接口API调用,支持超长文本,语速调节,音频超分降噪,接入开源阅读,文字转语音,TTS
Qwen3-TTS-1.7B,Flash-Attn加速,音色保存,接口API调用,支持超长文本,语速调节,音频超分降噪,接入开源阅读,文字转语音,TTS
OCR识别

LightOnOCR-2高效的1B参数视觉语言模型用于OCR识别pdf转文本jpg转文本图片转文本 二次开发构建by科哥
1@鸡你太美
认证作者32H更新时间:2026-04-27
支持自启动LightOnOCR-2高效的1B参数视觉语言模型用于OCR识别pdf转文本jpg转文本图片转文本 二次开发构建by科哥
LightOnOCR-2高效的1B参数视觉语言模型用于OCR识别pdf转文本jpg转文本图片转文本 二次开发构建by科哥
Lora训练LTX

LTX2模型Lora训练AI-Toolkit
2@梦影Erislia
22131H更新时间:2026-01-24
LTX2模型Lora训练AI-Toolkit
LTX2模型Lora训练AI-Toolkit
AI音乐

HeartMuLa,AI歌曲生成,开源版Suno
10@刘悦的技术博客
认证作者169H更新时间:2026-01-23
支持自启动HeartMuLa,AI歌曲生成,开源版Suno
HeartMuLa,AI歌曲生成,开源版Suno
AI音乐

歌曲与音效生成
3@老徐Ai研习社
认证作者196H更新时间:2026-01-22
支持自启动HeartMula根据歌词生成音乐,根据画面生成音效
HeartMula根据歌词生成音乐,根据画面生成音效
GLM文本模型

GLM-4.7-Flash
2@苍耳阿猫
认证作者37180H更新时间:2026-01-22
GLM-4.7-Flash
GLM-4.7-Flash
语音识别

微软开源VibeVoice ASR TTS集合webui语音到文本 文本到语音模型 二次卡发构建by科哥
1@鸡你太美
认证作者174H更新时间:2026-04-27
支持自启动微软开源VibeVoice ASR TTS集合webui语音到文本 文本到语音模型 二次卡发构建by科哥
微软开源VibeVoice ASR TTS集合webui语音到文本 文本到语音模型 二次卡发构建by科哥
视频生成

超强视频替换人物MoCha
68@与AI同行
认证作者441559H更新时间:2026-03-31
支持自启动最新视频替换人物,MoCha-Preview 整合包,支持视频替换人物,卡通动漫效果更佳,支持添加批量任务, 支持高清修复
最新视频替换人物,MoCha-Preview 整合包,支持视频替换人物,卡通动漫效果更佳,支持添加批量任务, 支持高清修复
GLM文本模型

智普开源GLM-4.7-Flash GGUF推理服务编程文本大模型速度很快 webui开发构建by科哥
2@鸡你太美
认证作者2759H更新时间:2026-04-27
支持自启动智普开源GLM-4.7-Flash GGUF推理服务编程文本大模型API+webui开发构建by科哥
智普开源GLM-4.7-Flash GGUF推理服务编程文本大模型API+webui开发构建by科哥
LTXLora训练

AIToolkit Ltx-2 Lora Training,4090 24G / 48G / 5090 预设多挡位支持
5@AI-KSK
认证作者861281H更新时间:2026-01-22
基于AI Toolkit,内置4090、48G及5090专属精调预设。告别复杂调参,只需加载对应JSON文件,即可解锁硬件最优性能,零门槛获得专家级训练方案。
基于AI Toolkit,内置4090、48G及5090专属精调预设。告别复杂调参,只需加载对应JSON文件,即可解锁硬件最优性能,零门槛获得专家级训练方案。
语音合成

indextts2-IndexTTS2 最新 V23版本的全面升级情感控制更好 构建by科哥
56@鸡你太美
认证作者14097335H更新时间:2026-04-27
支持自启动V23版本的全面升级情感控制更好
V23版本的全面升级情感控制更好
语音合成

NovaSR一个开源的音频超分辨率模型低音质转高清音质声音修复模型 webui开发构建by科哥
0@鸡你太美
认证作者113H更新时间:2026-04-27
支持自启动NovaSR一个开源的音频超分辨率模型低音质转高清音质声音修复模型 webui开发构建by科哥
NovaSR一个开源的音频超分辨率模型低音质转高清音质声音修复模型 webui开发构建by科哥
行业模型

sinong南京农业大学开源面向通用农业领域的垂直8B32B全离线模型 webui开发构建by科哥
0@鸡你太美
认证作者00H更新时间:2026-04-27
支持自启动sinong南京农业大学开源面向通用农业领域的垂直8B32B全离线模型 webui开发构建by科哥
sinong南京农业大学开源面向通用农业领域的垂直8B32B全离线模型 webui开发构建by科哥
生物信息行业模型

谷歌最新开源MedGemma医学AI助手 问诊问病例查看CT拍片x光拍片病理答疑问 webui开发构建by科哥
1@鸡你太美
认证作者1643H更新时间:2026-04-27
支持自启动谷歌最新开源MedGemma医学AI助手 问诊问病例查看CT拍片x光拍片病理答疑问 webui开发构建by科哥
谷歌最新开源MedGemma医学AI助手 问诊问病例查看CT拍片x光拍片病理答疑问 webui开发构建by科哥
图片生成GLM

GLM-Image
1@十字鱼
认证作者194H更新时间:2026-01-19
支持自启动智谱开源图像生成和编辑模型
智谱开源图像生成和编辑模型
视频超分

sora2视频二次高清工作流视频高清修复flashvsr工作流Comfyui工作流 构建by科哥
7@鸡你太美
认证作者7948H更新时间:2026-04-27
支持自启动sora2视频二次高清工作流视频高清修复flashvsr工作流Comfyui工作流 构建by科哥
sora2视频二次高清工作流视频高清修复flashvsr工作流Comfyui工作流 构建by科哥
图片生成Qwen-image

超强AI图片编辑,QwenEdit-2511合集,单图/双图编辑, 超强人脸一致性,精准涂抹编辑、无色差/位移,一键生成24张姿势图、九宫格分镜
94@与AI同行
认证作者12283343H更新时间:2026-03-31
支持自启动超强AI图片编辑,QwenEdit-2511合集,单图/双图编辑, 超强人脸一致性,精准涂抹编辑、无色差/位移,一键生成24张姿势图、九宫格分镜
超强AI图片编辑,QwenEdit-2511合集,单图/双图编辑, 超强人脸一致性,精准涂抹编辑、无色差/位移,一键生成24张姿势图、九宫格分镜
FluxComfyUI图片生成

FLUX2-Klein-黑森林开源最强编辑模型,秒级生图,效果可控!
14@社恐的知识树
认证作者143295H更新时间:2026-01-19
黑森林团队开源的FLUX2-Klein多功能模型,生成速度快,编辑能力强!
黑森林团队开源的FLUX2-Klein多功能模型,生成速度快,编辑能力强!
行业模型

谷歌最新翻译模型TranslateGemma支持全世界50多种语言的翻译文本多语言翻译 二次webui开发 构建by科哥
0@鸡你太美
认证作者62H更新时间:2026-04-27
支持自启动谷歌最新翻译模型TranslateGemma支持全世界50多种语言的翻译文本多语言翻译 二次webui开发 构建by科哥
谷歌最新翻译模型TranslateGemma支持全世界50多种语言的翻译文本多语言翻译 二次webui开发 构建by科哥
图片生成AI电商

BananaMall一个 AI 驱动的电商详情页生成的ai工具结合谷歌nano banana谷歌香蕉模型 开发构建by科哥
13@鸡你太美
认证作者59218H更新时间:2026-04-27
支持自启动BananaMall一个 AI 驱动的电商详情页生成的ai工具结合谷歌nano banana谷歌香蕉模型 开发构建by科哥
BananaMall一个 AI 驱动的电商详情页生成的ai工具结合谷歌nano banana谷歌香蕉模型 开发构建by科哥
Z-Image图片生成

全能图片编辑王flux2_klein|Qwen_Image_Edit2511|Z-image-turbo
29@老徐Ai研习社
认证作者2576880H更新时间:2026-01-21
支持自启动全能图片生成与编辑
全能图片生成与编辑
目标检测

YOLO26
6@苍耳阿猫
认证作者39981H更新时间:2026-01-16
YOLO26
YOLO26
具身智能

Alpamayo
1@苍耳阿猫
认证作者632H更新时间:2026-01-20
Alpamayo 1 是一个预训练推理模型,旨在加速自动驾驶(AV)领域的研发。
Alpamayo 1 是一个预训练推理模型,旨在加速自动驾驶(AV)领域的研发。
音乐

NotaGen基于 LLM 范式的高音乐性古典符号化音乐生成模型 二次开发构建by科哥
1@鸡你太美
认证作者911H更新时间:2026-04-27
支持自启动NotaGen基于 LLM 范式的高音乐性古典符号化音乐生成模型 二次开发构建by科哥
NotaGen基于 LLM 范式的高音乐性古典符号化音乐生成模型 二次开发构建by科哥
Wan图片生成视频生成

闪电AI视频、图片生成镜像
10@cola
5555H更新时间:2026-01-16
支持自启动基于lightx2v框架加速的视频、图片生成服务,快速生成视频图片,基于模型wan2.2、qwen-image、z-image
基于lightx2v框架加速的视频、图片生成服务,快速生成视频图片,基于模型wan2.2、qwen-image、z-image
Wan视频生成ComfyUI

DaSiWa & Remix:Wan 2.2 双神N版
39@AI-KSK
认证作者362963H更新时间:2026-01-16
本镜像高度集成 Wan 2.2 视频生成环境,预装社区领先四套核心工作流,融合 DaSiWa 高保真与 Remix 逻辑优化,提供一站式 T2V 文生视频与 I2V 图生视频解决方案。
本镜像高度集成 Wan 2.2 视频生成环境,预装社区领先四套核心工作流,融合 DaSiWa 高保真与 Remix 逻辑优化,提供一站式 T2V 文生视频与 I2V 图生视频解决方案。
LTX视频生成

LTX-2 Audio-Video:开源首个 · 音画同步生成
14@AI-KSK
认证作者135327H更新时间:2026-01-21
双官方流程全覆盖:同时支持 ComfyUI 官方 LTX 工作流示例 + Lightricks 官方 ComfyUI-LTXVideo 自定义节点与全部示例工作流
双官方流程全覆盖:同时支持 ComfyUI 官方 LTX 工作流示例 + Lightricks 官方 ComfyUI-LTXVideo 自定义节点与全部示例工作流
语音合成AI应用

voice pro给视频做多语言配音翻译克隆特定视频声音 直译视频声音本地化 汉化构建by科哥
10@鸡你太美
认证作者2711H更新时间:2026-04-27
支持自启动voice pro给视频做多语言配音翻译克隆特定视频声音 直译视频声音本地化 汉化构建by科哥
voice pro给视频做多语言配音翻译克隆特定视频声音 直译视频声音本地化 汉化构建by科哥
LTXLora训练

LTX2官方训练器Lora训练
1@梦影Erislia
29109H更新时间:2026-01-21
LTX2官方训练器的lora训练支持,内置模型t2v,小白可以一键运行,也可以根据官方文档进行进阶操作
LTX2官方训练器的lora训练支持,内置模型t2v,小白可以一键运行,也可以根据官方文档进行进阶操作
LTX视频生成

ltx-2全能lora运镜comfyui工作流文生视频图生视频一键运行 构建by科哥
7@鸡你太美
认证作者4529H更新时间:2026-04-27
支持自启动ltx-2全能lora运镜comfyui工作流文生视频图生视频一键运行 构建by科哥
ltx-2全能lora运镜comfyui工作流文生视频图生视频一键运行 构建by科哥
Qwen-Image

Tongbi-支持Qwen-Image和Qwen-Image-Edit
49@十字鱼
认证作者2748434H更新时间:2026-02-02
支持自启动阿里通义千问开源最强图像模型,强大的文字渲染能力,强大的图像编辑能力
阿里通义千问开源最强图像模型,强大的文字渲染能力,强大的图像编辑能力
其他

nano banana谷歌香蕉在线绘画在线改图修改图片模型香蕉模型
3@鸡你太美
认证作者6718H更新时间:2026-04-27
支持自启动nano banana谷歌香蕉在线绘画在线改图修改图片模型香蕉模型
nano banana谷歌香蕉在线绘画在线改图修改图片模型香蕉模型
语音合成

【音谷官方】indextts2-api
91@音谷官方
22898540H更新时间:2026-04-27
支持自启动【音谷官方】音谷对应的API
【音谷官方】音谷对应的API
LTX视频生成

LTX-2 WebUI版
6@鹄仙
认证作者4340H更新时间:2026-01-10
基于wangp的LTX-2,WebUI版
基于wangp的LTX-2,WebUI版
视频生成

开源版Veo3!LTX2-视频生成合集,文生视频、图生视频、视频人物配音+口型同步、直出1080P,高清细节放大、提示词增强、支持线条+深度+姿势控制!
59@与AI同行
认证作者300211H更新时间:2026-03-31
支持自启动开源版Veo3!LTX2-视频生成合集,文生视频、图生视频、视频人物配音+口型同步、直出1080P,高清细节放大、提示词增强、支持线条+深度+姿势控制!
开源版Veo3!LTX2-视频生成合集,文生视频、图生视频、视频人物配音+口型同步、直出1080P,高清细节放大、提示词增强、支持线条+深度+姿势控制!
LTXComfyUI数字人

LTX-2:首个开源音画同步生成模型,提示词遵从比肩Sora,理解分镜脚本,一键AI成片!
9@社恐的知识树
认证作者4245H更新时间:2026-01-22
LTX-2 是由 Lightricks 开源的 DiT 架构音频-视频基础模型,核心特点是:在同一个模型里同步生成视频与音频,超强提示词理解,支持多镜头脚本,关键词自动匹配视频风格,一键AI成片!
LTX-2 是由 Lightricks 开源的 DiT 架构音频-视频基础模型,核心特点是:在同一个模型里同步生成视频与音频,超强提示词理解,支持多镜头脚本,关键词自动匹配视频风格,一键AI成片!
语音合成

Voice Sculptor捏声音基于LLaSA和CosyVoice2的指令化语音合成语音模型 二次开发构建by科哥
4@鸡你太美
认证作者184H更新时间:2026-04-27
支持自启动Voice Sculptor捏声音基于LLaSA和CosyVoice2的指令化语音合成语音模型 二次开发构建by科哥
Voice Sculptor捏声音基于LLaSA和CosyVoice2的指令化语音合成语音模型 二次开发构建by科哥
Qwen-Image图片生成ComfyUI

LTX-2.0音画同步视频生成|Z-Image-Turbo&Qwen-Image-Edit1图片编辑
12@老徐Ai研习社
认证作者6366H更新时间:2026-02-05
支持自启动LTX-2.0音画同步视频生成
LTX-2.0音画同步视频生成
ComfyUIWan

Comfy二次元跑图生视频DaSiWa和vace跳舞
23@梦影Erislia
182369H更新时间:2026-01-22
Comfy二次元跑图生视频DaSiWa和vace跳舞
Comfy二次元跑图生视频DaSiWa和vace跳舞
语音识别

SenseVoice多语言语音识别情感识别系统 二次开发构建by科哥
2@鸡你太美
认证作者117H更新时间:2026-04-27
支持自启动SenseVoice多语言语音识别情感识别系统 二次开发构建by科哥
SenseVoice多语言语音识别情感识别系统 二次开发构建by科哥
语音识别

FunASR中文语音识别音频转文本声音转文本系统 二次webui开发构建by科哥
2@鸡你太美
认证作者248H更新时间:2026-04-27
支持自启动音频声音识别系统
音频声音识别系统
语音分离

SAM Audio一个Meta开源的音频分割模型声音分离音频音乐分离应用 二次开发构建by科哥
3@鸡你太美
认证作者3635H更新时间:2026-04-27
支持自启动可从复杂的音频混合中分离出特定的声音
可从复杂的音频混合中分离出特定的声音
图片编辑

UNet Universal Matting基于UNet模型抠图批量抠图 webUI一键抠图 构建by科哥
0@鸡你太美
认证作者1743H更新时间:2026-04-27
支持自启动基于UNet模型抠图批量抠图 webUI一键抠图 构建by科哥
基于UNet模型抠图批量抠图 webUI一键抠图 构建by科哥
ComfyUI

ComfyUI_最新26年01月-Niugee-牛哥整合包-V2
25@NiuGee
认证作者258540H更新时间:2026-01-08
整合26年最新版本ComfyUI,已下载好常用图像模型,修改端口到7860方便管理界面一键启动
整合26年最新版本ComfyUI,已下载好常用图像模型,修改端口到7860方便管理界面一键启动
视频生成

最强AI生成长视频,Wan2.2-SVI2Pro整合包!一次性生成一分钟视频,一次性生成30s分镜视频!
54@与AI同行
认证作者3821570H更新时间:2026-03-31
支持自启动最强AI生成长视频,Wan2.2-SVI2Pro整合包!一次性生成一分钟视频,一次性生成30s分镜视频!
最强AI生成长视频,Wan2.2-SVI2Pro整合包!一次性生成一分钟视频,一次性生成30s分镜视频!
ComfyUI

ComfyUI云端整合包2601
8@鹄仙
认证作者71351H更新时间:2026-01-23
长视频系列升级 不仅仅是SVI2 pro 长视频、LongCat数字人
长视频系列升级 不仅仅是SVI2 pro 长视频、LongCat数字人
Qwen-ImageLora训练图片生成

Qwen 2512的Lora训练,内置模型,一键训练AI-Toolkit
10@梦影Erislia
126699H更新时间:2026-01-23
Qwen 2512的Lora训练,内置模型,一键训练AI-Toolkit
Qwen 2512的Lora训练,内置模型,一键训练AI-Toolkit
AI应用

banana-slides基于谷歌人工智能ai制作幻灯片ai制作ppt制作幻灯片 构建by科哥
3@鸡你太美
认证作者1986H更新时间:2026-04-27
支持自启动banana-slides基于谷歌人工智能ai制作幻灯片ai制作ppt制作幻灯片 构建by科哥
banana-slides基于谷歌人工智能ai制作幻灯片ai制作ppt制作幻灯片 构建by科哥
Qwen-Image图片生成ComfyUI

Qwen-Image-2512模型_QwenVL3反推_SeedVR2放大多合一
8@社恐的知识树
认证作者93200H更新时间:2026-01-03
集成千问图像2512模型+QwenVL3图像视频反推API+最强放大SeedVR2多合一工作流,Comfyui-v0.7.0
集成千问图像2512模型+QwenVL3图像视频反推API+最强放大SeedVR2多合一工作流,Comfyui-v0.7.0
AI电商

magic-tryon图片视频虚拟试装换装模特换衣 二次webui开发构建by科哥
3@鸡你太美
认证作者554H更新时间:2026-04-27
支持自启动magic-tryon图片视频虚拟试装换装模特换衣
magic-tryon图片视频虚拟试装换装模特换衣
AI应用

图文创作神器一句话一张图片生成小红书图文 构建by科哥
1@鸡你太美
认证作者64H更新时间:2026-04-27
支持自启动图文创作神器一句话一张图片生成小红书图文
图文创作神器一句话一张图片生成小红书图文
Qwen-Image图片生成

阿里千问开源Qwen-Image-2512图像生成模型 二次开发构建by科哥
5@鸡你太美
认证作者147H更新时间:2026-04-27
支持自启动需要80gb显存运行该项目
需要80gb显存运行该项目
物理模拟分子动力
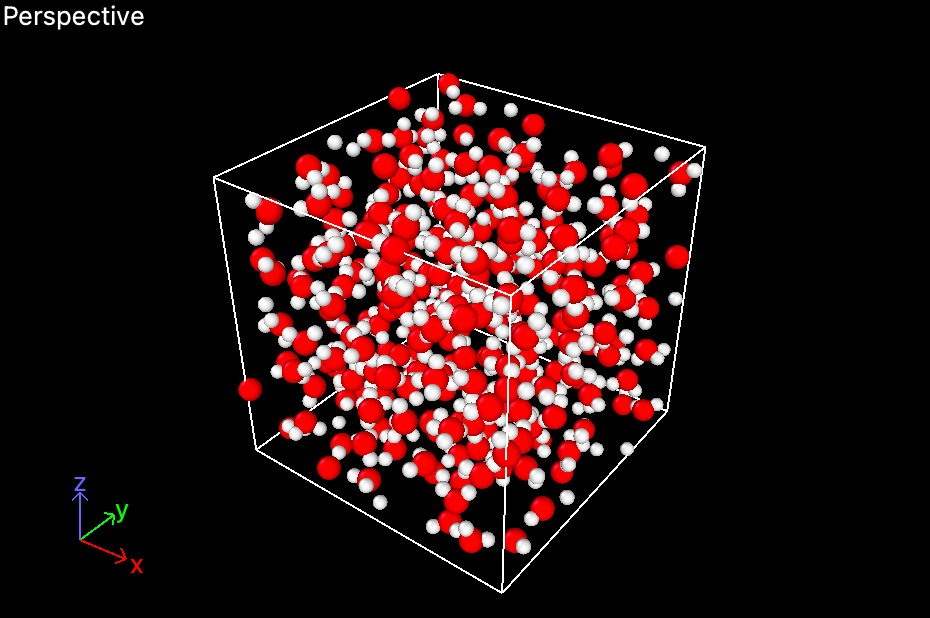
gromacs_deepmd机器学习训练水分子力场
0@tty
14350H更新时间:2026-01-26
内含deepmd机器学习力场训练水分子,gromacs调用运行例子
内含deepmd机器学习力场训练水分子,gromacs调用运行例子
物理模拟分子动力
deepmd_lammps训练和运行镜像
0@tty
21103H更新时间:2026-01-26
内含ch4简单例子,也可用来训练自己的模型,3080ti版本
内含ch4简单例子,也可用来训练自己的模型,3080ti版本
混元

HY-Motion1.0腾讯混元开源的文本到3D动作生成模型 汉化构建by科哥
2@鸡你太美
认证作者1322H更新时间:2026-04-27
HY-Motion1.0腾讯混元开源的文本到3D动作生成模型 汉化构建by科哥
HY-Motion1.0腾讯混元开源的文本到3D动作生成模型 汉化构建by科哥
Wan视频编辑

wan2.1-scail动作迁移
27@匹夫
认证作者237380H更新时间:2026-01-26
wan2.1-scail动作迁移
wan2.1-scail动作迁移
Qwen-Image图片生成

Qwen‑Image‑Edit‑2511-LoRA训练 x AI Toolkit
6@AI-KSK
认证作者1231177H更新时间:2026-01-01
这是一个集成了 Qwen-Image-Edit-2511模型与 AI Toolkit 训练框架的预配置环境,旨在支持用户高效微调出具备精准图像编辑、风格迁移及多主体一致性能力的定制化 LoRA 模型。
这是一个集成了 Qwen-Image-Edit-2511模型与 AI Toolkit 训练框架的预配置环境,旨在支持用户高效微调出具备精准图像编辑、风格迁移及多主体一致性能力的定制化 LoRA 模型。
语音合成

ChatterBox多语言语音合成语言克隆声音克隆 webui二次开发构建by科哥
4@鸡你太美
认证作者3331H更新时间:2026-04-27
支持自启动支持23个国家的语言声音克隆
支持23个国家的语言声音克隆
数字人

LatentSync 1.6 纯净版
5@knzskl
4284H更新时间:2026-01-26
字节跳动、北京交通大学联合推出的端到端唇形同步框架。Latent Sync利用稳定扩散和TREPA的力量,为动态和逼真的视频生成提供精确的高分辨率唇形同步。
字节跳动、北京交通大学联合推出的端到端唇形同步框架。Latent Sync利用稳定扩散和TREPA的力量,为动态和逼真的视频生成提供精确的高分辨率唇形同步。
SDLora训练

SDXL及系列衍生模型训练,内置WD打标编辑,任意C站模型导入,小白也能轻松上手,AI-Toolkit
82@梦影Erislia
15129831H更新时间:2025-12-30
SDXL及系列衍生模型训练,内置WD打标编辑,任意C站模型导入,小白也能轻松上手,AI-Toolkit
SDXL及系列衍生模型训练,内置WD打标编辑,任意C站模型导入,小白也能轻松上手,AI-Toolkit
视频生成图片生成ComfyUI

启梦光影高质量出图二合一
2@麦子AI
36105H更新时间:2026-01-28
支持自启动高质量文生图、图生视频。只适配40系显卡
高质量文生图、图生视频。只适配40系显卡
Wan视频编辑

StoryMem基于wan2.2逐镜脚本生成高连贯电影级1分钟多镜头叙事视频 二次开发构建by科哥
11@鸡你太美
认证作者3920H更新时间:2026-04-27
支持自启动StoryMem基于wan2.2逐镜脚本生成高连贯电影级1分钟多镜头叙事视频 二次开发构建by科哥
StoryMem基于wan2.2逐镜脚本生成高连贯电影级1分钟多镜头叙事视频 二次开发构建by科哥
ComfyUI

ComfyUI学习版_torch_2.8.0
6@智绘Store
认证作者49121H更新时间:2026-03-17
支持自启动此版本镜像,5090、4090、3090、3080Ti等系列显卡可用,P40显卡不可用
此版本镜像,5090、4090、3090、3080Ti等系列显卡可用,P40显卡不可用
ComfyUI

ComfyUI学习版镜像_torch-2.7.1
10@智绘Store
认证作者29100H更新时间:2026-03-17
支持自启动ComfyUI学习版镜像_torch-2.7.1,高性价比镜像,可开P40显卡,5090显卡勿用,会报错
ComfyUI学习版镜像_torch-2.7.1,高性价比镜像,可开P40显卡,5090显卡勿用,会报错
Qwen-Image

qwen-image工作流合集edit2511-z-image-turbo
9@匹夫
认证作者86171H更新时间:2026-01-27
qwen-image工作流合集
qwen-image工作流合集
语音合成

VoxCPM1.5面壁智能开源的端到端语音合成模型附训练lora训练器 构建by科哥
1@鸡你太美
认证作者2523H更新时间:2026-04-27
支持自启动语音合成模型+训练lora训练器
语音合成模型+训练lora训练器
Qwen-ImageLora训练图片生成

Qwen-2511和Z图像的Lora训练AI-TOOLKIT
9@梦影Erislia
57342H更新时间:2026-01-27
Qwen-2511和Z图像的Lora训练AI-TOOLKIT
Qwen-2511和Z图像的Lora训练AI-TOOLKIT
Wan视频生成

Egox任意视频一键转第一人称视角视频基于wan2.1模型 webui二次开发构建by科哥
3@鸡你太美
认证作者98H更新时间:2026-04-27
支持自启动将任意视频一键转第一人称视角视频
将任意视频一键转第一人称视角视频
视频生成图片生成ComfyUI

启梦光影VIP快速出图二合一
2@麦子AI
11155H更新时间:2026-01-27
支持自启动2s出图,超级快。注意!本镜像需要部署在50系列显卡上。
2s出图,超级快。注意!本镜像需要部署在50系列显卡上。
数字人

One-to-All-Animation单图片转换动画视频数字人视频动作模仿器 构建by科哥
1@鸡你太美
认证作者116H更新时间:2026-04-27
支持自启动单图片转换动画视频数字人视频动作模仿器
单图片转换动画视频数字人视频动作模仿器
数字人

personaLive实时数字人系统
13@有趣的80后程序员
认证作者83208H更新时间:2025-12-27
支持自启动实时数字人系统,直播室直接生成分身,低延迟
实时数字人系统,直播室直接生成分身,低延迟
Qwen-Image图片生成

Qwen-Image-Edit-2511阿里通义推出的全能图像编辑模型 webui二次修改构建by科哥
4@鸡你太美
认证作者811115H更新时间:2026-04-27
支持自启动图片编辑模型 一致性更加好 中文支持更好
图片编辑模型 一致性更加好 中文支持更好
语音克隆语音合成

超强AI音色克隆,VoxCPM-V1.5,支持超长文本生成、批量生成,支持音色保存、多音字修改、语速调节,速度超快!
30@与AI同行
认证作者1263750H更新时间:2026-03-31
支持自启动超强AI音色克隆,VoxCPM-V1.5,支持超长文本生成、批量生成,支持音色保存、多音字修改、语速调节,速度超快!
超强AI音色克隆,VoxCPM-V1.5,支持超长文本生成、批量生成,支持音色保存、多音字修改、语速调节,速度超快!
ComfyUIWanQwen-Image

2025.12全新模型ComfyUI整合包
19@老徐Ai研习社
认证作者123480H更新时间:2025-12-26
支持自启动ComfyUI2025.12整合包
ComfyUI2025.12整合包
ComfyUI

ComfyUI云端整合包2512
15@鹄仙
认证作者711432H更新时间:2026-01-27
ComfyUI云端整合包2512 支持Z-Image 混元1.5,新增到63个插件,带文件管理系统
ComfyUI云端整合包2512 支持Z-Image 混元1.5,新增到63个插件,带文件管理系统
Qwen-Image视频编辑

千问2511与动作迁移三剑客
3@鹄仙
认证作者1733H更新时间:2025-12-27
一个基于Wan2GP的图像编辑与动作迁移视频生成的WebUI项目
一个基于Wan2GP的图像编辑与动作迁移视频生成的WebUI项目
Wan视频生成ComfyUI

TurboDiffusion 100–200×加速ComfyUI-Wan图到视频生成
16@AI-KSK
认证作者143371H更新时间:2025-12-25
这是一个超快的AI视频生成工具,1分钟就能把图片变成短视频,速度是普通AI的200倍。
这是一个超快的AI视频生成工具,1分钟就能把图片变成短视频,速度是普通AI的200倍。
语音合成

VoxCPM1.5雨落版整合包
7@雨落实战
认证作者97200H更新时间:2025-12-24
支持自启动VoxCPM1.5的雨落版整合包
VoxCPM1.5的雨落版整合包
AI应用图片生成

PromptFill专为AI绘画设计的开源结构化提示词生成工具 构建by科哥
2@鸡你太美
认证作者811H更新时间:2026-04-27
支持自启动专为AI绘画设计的开源结构化提示词生成工具
专为AI绘画设计的开源结构化提示词生成工具
LongCat数字人

最强长视频数字人:LongCat-Avatar尝鲜版,其他热门生图、视频也都备好了!
16@老许爱吃肉丶
67211H更新时间:2026-01-27
支持自启动最强长视频数字人:LongCat-Avatar尝鲜版,其他热门生图、视频也都备好了!
最强长视频数字人:LongCat-Avatar尝鲜版,其他热门生图、视频也都备好了!
LongCat数字人

SOTA级音频驱动数字人-LongCat-Video-Avatar
13@AI-KSK
认证作者7171H更新时间:2026-01-27
实现身份永续、动作自然的数字人生成
实现身份永续、动作自然的数字人生成
视频生成数字人

AI数字人LongCatAvatar,超强口型+表情+姿势效果,支持长视频!
59@与AI同行
认证作者382420H更新时间:2026-03-31
支持自启动AI数字人LongCatAvatar,超强口型+表情+姿势效果,支持长视频!
AI数字人LongCatAvatar,超强口型+表情+姿势效果,支持长视频!
3D生成

SHARP–苹果开源的3D场景生成AI模型图片转3d模型 二次开发构建by科哥
3@鸡你太美
认证作者28563H更新时间:2026-04-27
支持自启动SHARP–苹果开源的3D场景生成AI模型图片转3d模型
SHARP–苹果开源的3D场景生成AI模型图片转3d模型
GLM语音识别

GLM-ASR智谱开源的语音识别、语音转文本模型 二次开发构建By科哥
0@鸡你太美
认证作者81H更新时间:2026-04-27
支持自启动智谱开源的语音识别语音转文本声音转文本模型
智谱开源的语音识别语音转文本声音转文本模型
分子动力生物信息

Rosetta
2@苍耳阿猫
认证作者326H更新时间:2025-12-23
Rosetta
Rosetta
AI应用视频生成

Pixelle-Video|一句话生成短视频
9@鸡你太美
认证作者4216H更新时间:2026-04-27
支持自启动零门槛,零剪辑经验,让视频创作成为一句话的事
零门槛,零剪辑经验,让视频创作成为一句话的事
其他

ai小说ai在线写作系统ai智能写作系统 构建by科哥
7@鸡你太美
认证作者22137H更新时间:2026-04-27
支持自启动ai小说ai在线写作系统ai智能写作系统
ai小说ai在线写作系统ai智能写作系统
Lora训练

ai-toolkit炼丹炉,支持多种常见模型训练,内置多种模型
4@MumuOpenK
77482H更新时间:2026-01-29
支持自启动ai-toolkit炼丹炉(汉化版)
ai-toolkit炼丹炉(汉化版)
语音合成GLM

智谱开源的AI文本转语音模型支持声音克隆GLM-TTS 语音合成系统 二次开发构建by科哥
0@鸡你太美
认证作者3826H更新时间:2026-04-27
支持自启动智谱开源的AI文本转语音模型支持声音克隆GLM-TTS 语音合成系统 二次开发构建by科哥
智谱开源的AI文本转语音模型支持声音克隆GLM-TTS 语音合成系统 二次开发构建by科哥
ComfyUIQwen-Image图片生成

Twinflow双流加速千问生图1秒1张
5@smthem
2314H更新时间:2025-12-20
支持自启动最快千问生图方法,顶配1秒1张
最快千问生图方法,顶配1秒1张
3D生成ComfyUI

Trellis2代一键图片生成3D模型
9@smthem
189361H更新时间:2025-12-19
支持自启动一键图片生成3D模型,输出glb和obj格式,带贴图和法线,自动脱底
一键图片生成3D模型,输出glb和obj格式,带贴图和法线,自动脱底
Wan视频生成ComfyUI

TurboDiffusion-ultra-fast-wan
7@有趣的80后程序员
认证作者69107H更新时间:2025-12-18
让阿里wan模型的视频生成速度提升200倍
让阿里wan模型的视频生成速度提升200倍
语音合成

cosyvoce3阿里最新开源声音克隆应用普通话粤语英语日语方言更加精准情感丰富 二次开发构建By科哥
6@鸡你太美
认证作者6879H更新时间:2026-04-27
支持自启动cosyvoce3阿里最新开源声音克隆应用普通话粤语英语日语方言更加精准情感丰富 二次开发构建By科哥
cosyvoce3阿里最新开源声音克隆应用普通话粤语英语日语方言更加精准情感丰富 二次开发构建By科哥
分子动力

cp2k
2@苍耳阿猫
认证作者965H更新时间:2025-12-18
cp2k-v2025.2
cp2k-v2025.2
语音合成

CosyVoice3,多音字控制,音色保存,接口API调用,流式接口,音频降噪
45@刘悦的技术博客
认证作者4865336H更新时间:2026-01-28
支持自启动CosyVoice3,多音字控制,音色保存,接口API调用,流式接口,音频降噪
CosyVoice3,多音字控制,音色保存,接口API调用,流式接口,音频降噪
ComfyUIAI电商

电商换装到视频-全流程
23@积木comfyui
165145H更新时间:2026-01-28
支持自启动换装-换模特-换姿势-换背景-打光-放大-模特图生视频-全流程
换装-换模特-换姿势-换背景-打光-放大-模特图生视频-全流程
分子动力

DeePMD-kit
0@苍耳阿猫
认证作者44H更新时间:2025-12-16
DeePMD-kit-v3.1.2
DeePMD-kit-v3.1.2
分子动力

LAMMPS
3@苍耳阿猫
认证作者34306H更新时间:2025-12-16
lammps
lammps
Wan视频生成数字人

LiveAvatar
9@十字鱼
认证作者2520H更新时间:2026-01-28
支持自启动流式实时音频驱动头像生成,无限长度
流式实时音频驱动头像生成,无限长度
AI应用

AI命理预测系统ai算命系统ai大模型算命系统 二次开发构建by科哥
1@鸡你太美
认证作者1839H更新时间:2026-04-27
使用最新的ai大模型结合中国传统命理系统开发 可以无卡模式运行这个项目
使用最新的ai大模型结合中国传统命理系统开发 可以无卡模式运行这个项目
OCR识别

PaddleOCR-VL
23@十字鱼
认证作者140481H更新时间:2026-01-28
支持自启动支持 109 种语言 擅长识别文本、表格、公式和图表
支持 109 种语言 擅长识别文本、表格、公式和图表
语音合成GLM

GLM-TTS
11@十字鱼
认证作者451223H更新时间:2026-01-28
支持自启动可控且富有情感表达的零样本TTS
可控且富有情感表达的零样本TTS
数字人

知鱼-焕焕镜像
1@
10140H更新时间:2026-01-28
支持自启动数字人视频生成/Digital Human Video Generation
数字人视频生成/Digital Human Video Generation
GLMAI应用
AutoGLM-Phone-9B
0@Ikaros
1020H更新时间:2025-12-12
支持自启动AutoGLM-Phone-9B一键启动镜像
AutoGLM-Phone-9B一键启动镜像
Wan视频生成

Wan2.2-14B加速版TTP图片放大ttp加速插画图片放大图片高清图片细节放大 科哥构建
5@鸡你太美
认证作者4089H更新时间:2026-04-27
支持自启动专注图片细节放大工作流
专注图片细节放大工作流
LongCat图片生成图片编辑

LongCat-Image
4@十字鱼
认证作者236H更新时间:2025-12-09
支持自启动美团龙猫开源图像模型,包含LongCat-Image文生图和LongCat-Image-Edit图像编辑
美团龙猫开源图像模型,包含LongCat-Image文生图和LongCat-Image-Edit图像编辑
Z-ImageLora训练

z-image-turbo lora炼丹炉ai-toolkit lora模型训练器
53@老徐Ai研习社
认证作者6866414H更新时间:2026-01-22
支持自启动z-image-turbo lora炼丹炉ai-toolkit lora模型训练器
z-image-turbo lora炼丹炉ai-toolkit lora模型训练器
数字人

Heygem数字人视频生成系统批量版webui版 二次开发构建by科哥
19@鸡你太美
认证作者3335414H更新时间:2026-04-27
支持自启动一键批量生成 一键打包下载视频
一键批量生成 一键打包下载视频
OCR识别

PaddleOCR在线webui文字文稿识别多种识别pdf文字识别 二次开发构建by科哥
1@鸡你太美
认证作者2840H更新时间:2026-04-27
支持自启动PaddleOCR在线webui文字文稿识别多种识别pdf文字识别 二次开发构建by科哥
PaddleOCR在线webui文字文稿识别多种识别pdf文字识别 二次开发构建by科哥
LongCat图片生成图片编辑

LongCat:双语超强图像生成与编辑,引领写实与精准创作新标准。
3@AI-KSK
认证作者70H更新时间:2025-12-08
LongCat 是美团开源的双语图像生成与编辑模型,具备高效写实表现、强中文渲染与精准一致性编辑能力,在开源领域表现领先。
LongCat 是美团开源的双语图像生成与编辑模型,具备高效写实表现、强中文渲染与精准一致性编辑能力,在开源领域表现领先。
语音合成

VoxCPM
5@十字鱼
认证作者4149H更新时间:2025-12-08
支持自启动面壁智能开源语音克隆 全新1.5版本
面壁智能开源语音克隆 全新1.5版本
语音合成

VoxCPM 1.5B
3@鹄仙
认证作者69123H更新时间:2025-12-07
全新VoxCPM1.5B,增强长音频输出稳定性
全新VoxCPM1.5B,增强长音频输出稳定性
语音合成

VibeVoice语音合成系统二次webui开发构建by科哥
0@鸡你太美
认证作者100H更新时间:2026-04-27
支持自启动基于微软 VibeVoice 的实时语音合成
基于微软 VibeVoice 的实时语音合成
Qwen-Image图片编辑Lora训练

Qwen-Edit 2509的Lora训练AI-toolkit
3@梦影Erislia
39243H更新时间:2026-01-29
Qwen-Edit 2509,qwen-edit和z-image的Lora训练DiffusionPipe
Qwen-Edit 2509,qwen-edit和z-image的Lora训练DiffusionPipe
数字人

Imtalker
2@有趣的80后程序员
认证作者3030H更新时间:2026-01-29
支持自启动语音驱动数字人、支持生成超长语音
语音驱动数字人、支持生成超长语音
视频生成

最新视频动作迁移,SteadyDancer,南京大学&腾讯开源!
74@与AI同行
认证作者621856H更新时间:2026-03-31
支持自启动最新视频动作迁移,SteadyDancer整合包!南京大学&腾讯开源,支持视频动作迁移,支持长视频、批量队列生成、高清放大
最新视频动作迁移,SteadyDancer整合包!南京大学&腾讯开源,支持视频动作迁移,支持长视频、批量队列生成、高清放大
目标检测图像分割

SAM3 常见使用案例大全
0@敢敢のwings
认证作者1927H更新时间:2026-01-29
SAM 3提出的PCS任务从根本上突破了这一限制,模型需要检测、分割并追踪输入图像或视频中所有符合该概念的实例。
SAM 3提出的PCS任务从根本上突破了这一限制,模型需要检测、分割并追踪输入图像或视频中所有符合该概念的实例。
数字人

Fay数字人-3.1.1
3@郭泽斌
认证作者251695H更新时间:2025-12-05
Fay数字人3.1.1最小可运行版。fay是一个帮助数字人(2.5d、3d、移动、pc、网页)或大语言模型(openai兼容、deepseek)连通业务系统的mcp框架。
Fay数字人3.1.1最小可运行版。fay是一个帮助数字人(2.5d、3d、移动、pc、网页)或大语言模型(openai兼容、deepseek)连通业务系统的mcp框架。
ComfyUI视频生成图片生成

娱乐AI,唱歌跳舞,一应俱全
10@老猫本猫
98194H更新时间:2026-01-29
支持自启动娱乐AI,唱歌跳舞,一应俱全
娱乐AI,唱歌跳舞,一应俱全
ComfyUI图片编辑AI电商

人物,商品,背景,随心所欲替换。
39@老猫本猫
382515H更新时间:2026-01-29
支持自启动人物,商品,背景,随心所欲替换。
人物,商品,背景,随心所欲替换。
视频编辑

长视频SteadyDancer动作迁移
63@ifelse
391522H更新时间:2025-12-05
支持自启动去闪长视频SteadyDancer动作迁移
去闪长视频SteadyDancer动作迁移
图片生成

Ovis-Image阿里开源文本生图像大模型在线webui体验版 构建二次开发by科哥
1@鸡你太美
认证作者101H更新时间:2026-04-27
支持自启动Ovis-Image阿里开源文本生图像大模型在线webui体验版
Ovis-Image阿里开源文本生图像大模型在线webui体验版
视频生成

UltraVideo生成高质量超高清1k到4K视频 webUI二次开发构建By科哥
3@鸡你太美
认证作者2415H更新时间:2026-04-27
基于wan2.1UltraVideo生成高质量超高清1k到4K视频
基于wan2.1UltraVideo生成高质量超高清1k到4K视频
推理框架

vLLM-Omni
1@敢敢のwings
认证作者611H更新时间:2026-01-29
vLLM项目团队推出了vLLM-Omni框架,这是一个专门为全模态模型设计的高性能推理系统,旨在将vLLM在文本推理领域积累的性能优势,扩展到包含图像、音频、视频在内的完整多模态生态。
vLLM项目团队推出了vLLM-Omni框架,这是一个专门为全模态模型设计的高性能推理系统,旨在将vLLM在文本推理领域积累的性能优势,扩展到包含图像、音频、视频在内的完整多模态生态。
图片生成

超强AI图片ZImage-支持批量生成、SeedVR2高清放大
104@与AI同行
认证作者12063755H更新时间:2026-03-31
支持自启动阿里ZImageTurbo图片生成整合包,图片真实感、细节全面提升,支持批量生成、SeedVR2高清放大,支持NSFW, 最低6G显存可用!
阿里ZImageTurbo图片生成整合包,图片真实感、细节全面提升,支持批量生成、SeedVR2高清放大,支持NSFW, 最低6G显存可用!
其他

MetaGR
1@Anaconda
272H更新时间:2026-01-29
Meta的生成式推荐论文开源仓库的实现。
Meta的生成式推荐论文开源仓库的实现。
Z-ImageLora训练

Z-Image-Turbo LoRA训练-AI Toolkit-极致风格化
10@AI-KSK
认证作者1962310H更新时间:2025-12-04
支持 Z-Image-Turbo LoRA 快速训练的 AI Toolkit 镜像
支持 Z-Image-Turbo LoRA 快速训练的 AI Toolkit 镜像
IndexTTS语音合成

IndexTTS2整合包雨落版
186@雨落实战
认证作者265012748H更新时间:2025-12-03
支持自启动IndexTTS2.0整合包雨落版本,欢迎使用
IndexTTS2.0整合包雨落版本,欢迎使用
视频编辑

SteadyDancer-FP8量化,视频动作迁移,支持5090新卡,支持A800计算卡,基于Comfyui,workflow,工作流,批量任务
22@刘悦的技术博客
认证作者141128H更新时间:2026-01-29
支持自启动SteadyDancer-FP8量化,视频动作迁移,支持5090新卡,支持A800计算卡,基于Comfyui,workflow,工作流,批量任务
SteadyDancer-FP8量化,视频动作迁移,支持5090新卡,支持A800计算卡,基于Comfyui,workflow,工作流,批量任务
Z-ImageLora训练

Z-image Lora训练,小白也能轻松上手,AI-toolkit
39@梦影Erislia
4244185H更新时间:2026-01-29
Z-image Lora训练,小白也能轻松上手,AI-toolkit
Z-image Lora训练,小白也能轻松上手,AI-toolkit
图片生成

AI艺术二维码生成器在线生成个性二维码 二次开发构建by科哥
0@鸡你太美
认证作者14H更新时间:2026-04-27
支持自启动AI艺术二维码生成器在线生成个性二维码
AI艺术二维码生成器在线生成个性二维码
Z-Image图片生成

Z-Image-Turbo-GGUF,局部重绘,文生图,图生图,Qwen3-vl自动提示词,支持5090新卡,支持A800,批量任务队列
20@刘悦的技术博客
认证作者246180H更新时间:2026-01-29
支持自启动Z-Image-Turbo-GGUF,局部重绘,文生图,图生图,Qwen3-vl自动提示词,支持5090新卡,支持A800,批量任务队列
Z-Image-Turbo-GGUF,局部重绘,文生图,图生图,Qwen3-vl自动提示词,支持5090新卡,支持A800,批量任务队列
Qwen-Image

Qwen-Image的Lora训练DiffusionPipe
1@梦影Erislia
2781H更新时间:2026-01-29
使用diffusion pipe进行qwen image的lora训练,小白也可简单上手,上传image即可开始训练
使用diffusion pipe进行qwen image的lora训练,小白也可简单上手,上传image即可开始训练
数字人

HeyGem数字人最新多人面部驱动数字人,支持5090新卡,支持A800计算卡,修复黑框问题,GFP面部超分,修复超长视频上下游阻塞问题
43@刘悦的技术博客
认证作者5534315H更新时间:2026-01-29
支持自启动HeyGem数字人最新多人面部驱动数字人,支持5090新卡,支持A800计算卡,修复黑框问题,GFP面部超分,修复超长视频上下游阻塞问题
HeyGem数字人最新多人面部驱动数字人,支持5090新卡,支持A800计算卡,修复黑框问题,GFP面部超分,修复超长视频上下游阻塞问题
Z-Image图片生成

阿里通义开源Z-Image文生图片无限制wenbui中文特别版 构建by科哥
11@鸡你太美
认证作者105716H更新时间:2026-04-27
支持自启动文生图片无限制wenbui中文特别版
文生图片无限制wenbui中文特别版
Wan视频生成

ComyUI批量z-image出图 SeedVR2 TTP放大 4K Wan2.2图生视频
5@ifelse
135731H更新时间:2026-01-29
支持自启动ComyUI批量z-image出图 SeedVR2 TTP放大 4K Wan2.2图生视频
ComyUI批量z-image出图 SeedVR2 TTP放大 4K Wan2.2图生视频
Z-ImageLora训练

aitookit_z-image_lora_train镜像
27@有趣的80后程序员
认证作者2821650H更新时间:2026-01-29
aitookit_z-image_lora_train镜像
aitookit_z-image_lora_train镜像
数字人

echomimic_v3阿里蚂蚁团队开源图片加声音生成说话数字人视频基于Comfyui加速和二次高清输出 构建By科哥
3@鸡你太美
认证作者48546H更新时间:2026-04-27
echomimic_v3阿里蚂蚁团队开源图片加声音生成说话数字人视频基于Comfyui加速和二次高清输出 构建By科哥
echomimic_v3阿里蚂蚁团队开源图片加声音生成说话数字人视频基于Comfyui加速和二次高清输出 构建By科哥
Z-Image图片生成

Z-Image-Turbo 最真实的生图模型
89@匹夫
认证作者428982H更新时间:2026-01-30
Z-Image-Turbo 最真实的生图模型
Z-Image-Turbo 最真实的生图模型
数据分析AI应用

Crawl4AI:基于AI的网络爬虫和数据抓取工具
6@AI画师大阳
认证作者2027H更新时间:2026-01-30
支持自启动Crawl4AI:基于AI的网络爬虫和数据抓取工具
Crawl4AI:基于AI的网络爬虫和数据抓取工具
Flux图片生成图片编辑
![FLUX.2 [dev]](https://ucompshare-community-image.cn-wlcb.ufileos.com/66534582_64548608/compshareImage-1jr0j4ji32kd_1764262347.png)
FLUX.2 [dev]
7@十字鱼
认证作者8486H更新时间:2025-11-28
支持自启动FLUX.2 [dev] 是一个拥有32B参数的流匹配Transformer模型,能够生成和编辑图像。
FLUX.2 [dev] 是一个拥有32B参数的流匹配Transformer模型,能够生成和编辑图像。
FluxComfyUI图片生成

flux.2工作流合集-加图片放大工作流
33@匹夫
认证作者2651275H更新时间:2026-01-30
flux.2工作流合集-及图片高清放大工作流
flux.2工作流合集-及图片高清放大工作流
Z-Image图片生成

Z-Image-Turbo · 8步极速 · 无限制生成
12@AI-KSK
认证作者209478H更新时间:2025-11-27
Z-Image-Turbo 是一款仅用 8 步即可生成旗舰级图像的高效扩散模型,具备快速生成、双语文本渲染、强指令理解与创意编辑能力,是当前开源图像模型中兼具速度与质量的优秀代表。
Z-Image-Turbo 是一款仅用 8 步即可生成旗舰级图像的高效扩散模型,具备快速生成、双语文本渲染、强指令理解与创意编辑能力,是当前开源图像模型中兼具速度与质量的优秀代表。
FluxComfyUI图片生成

flux2最新发布f8优化极速版3090显卡可玩含sora2工作流 构建by科哥
4@鸡你太美
认证作者4551H更新时间:2026-04-27
支持自启动flux2最新发布f8优化极速版3090显卡可玩含sora2工作流 构建by科哥
flux2最新发布f8优化极速版3090显卡可玩含sora2工作流 构建by科哥
ComfyUI

ComfyUI基础镜像纯净版0.3.50
9@龙没耳
认证作者55356H更新时间:2026-01-30
支持自启动ComfyUI基础镜像纯净版0.3.50
ComfyUI基础镜像纯净版0.3.50
AI应用

PDFMathTranslate-next基于 AI 完整保留排版的 PDF 文档全文双语翻译
6@AI画师大阳
认证作者821727H更新时间:2026-01-30
支持自启动基于 AI 完整保留排版的 PDF 文档全文双语翻译
基于 AI 完整保留排版的 PDF 文档全文双语翻译
FluxComfyUI图片生成

FLUX.2:下一代视觉生成引擎
7@AI-KSK
认证作者60102H更新时间:2026-01-30
Flux.2 是 2025 年最全面、最专业、最强大的统一视觉生成模型之一。
Flux.2 是 2025 年最全面、最专业、最强大的统一视觉生成模型之一。
ComfyUI图片编辑Qwen-Image

aha的ComfyUI镜像——姿态编辑
7@叫我aha就好
95445H更新时间:2026-01-30
SDPose_OOD+Pose_editor+qwen image edit 2509,姿态估计与编辑,随心所欲修改姿态
SDPose_OOD+Pose_editor+qwen image edit 2509,姿态估计与编辑,随心所欲修改姿态
混元视频生成

HunyuanVideo 1.5开源视频生成模型-ComfyUI实现
10@AI-KSK
认证作者92166H更新时间:2026-01-30
该镜像集成了刚刚开源的 HunyuanVideo 1.5 模型
该镜像集成了刚刚开源的 HunyuanVideo 1.5 模型
ComfyUI

ComfyUI整合镜像
7@鹄仙
认证作者68331H更新时间:2026-01-30
一个Comfy UI的整合包,自用版,带插件和部分模型
一个Comfy UI的整合包,自用版,带插件和部分模型
DeepSeekOCR识别

Deepseek orc webui在线图片识别文字pdf文件转文字 七种识别文字 构建by科哥
3@鸡你太美
认证作者42489H更新时间:2026-04-27
Deepseek orc webui在线图片识别文字pdf文件转文字
Deepseek orc webui在线图片识别文字pdf文件转文字
混元3D生成

ComfyUI-SAM3-Hunyuan3D-Part-SAM3DBody工作流集合 构建By科哥
1@鸡你太美
认证作者2022H更新时间:2026-04-27
支持自启动sam3是谷歌开源的一个项目图像拆分,3D渲染等
sam3是谷歌开源的一个项目图像拆分,3D渲染等
混元视频生成

HunyuanVideo-1.5
6@十字鱼
认证作者3153H更新时间:2025-11-24
支持自启动一个领先的超轻量级视频生成模型
一个领先的超轻量级视频生成模型
IndexTTS语音合成

AI听书 IndexTTS vllm加速版
10@CyberWon
9075H更新时间:2026-01-23
低成本高质量快速生成有声书。
低成本高质量快速生成有声书。
ComfyUIQwen-Image图片生成

一张图生成多角度工作流-万物融合工作流升级版
20@匹夫
认证作者151345H更新时间:2026-01-30
一张图生成多角度工作流-万物融合工作流升级版
一张图生成多角度工作流-万物融合工作流升级版
视频生成

超强AI图生视频RemixV2-支持批量生成、首尾帧视频、高清放大
95@与AI同行
认证作者12846230H更新时间:2026-03-31
支持自启动AI生成视频,Wan2.2-RemixV2整合包,支持图生视频、首尾帧视频,支持批量单图视频、批量首尾帧,支持高清放大、加载Lora、NSFW,最低8G显存可用
AI生成视频,Wan2.2-RemixV2整合包,支持图生视频、首尾帧视频,支持批量单图视频、批量首尾帧,支持高清放大、加载Lora、NSFW,最低8G显存可用
语音合成
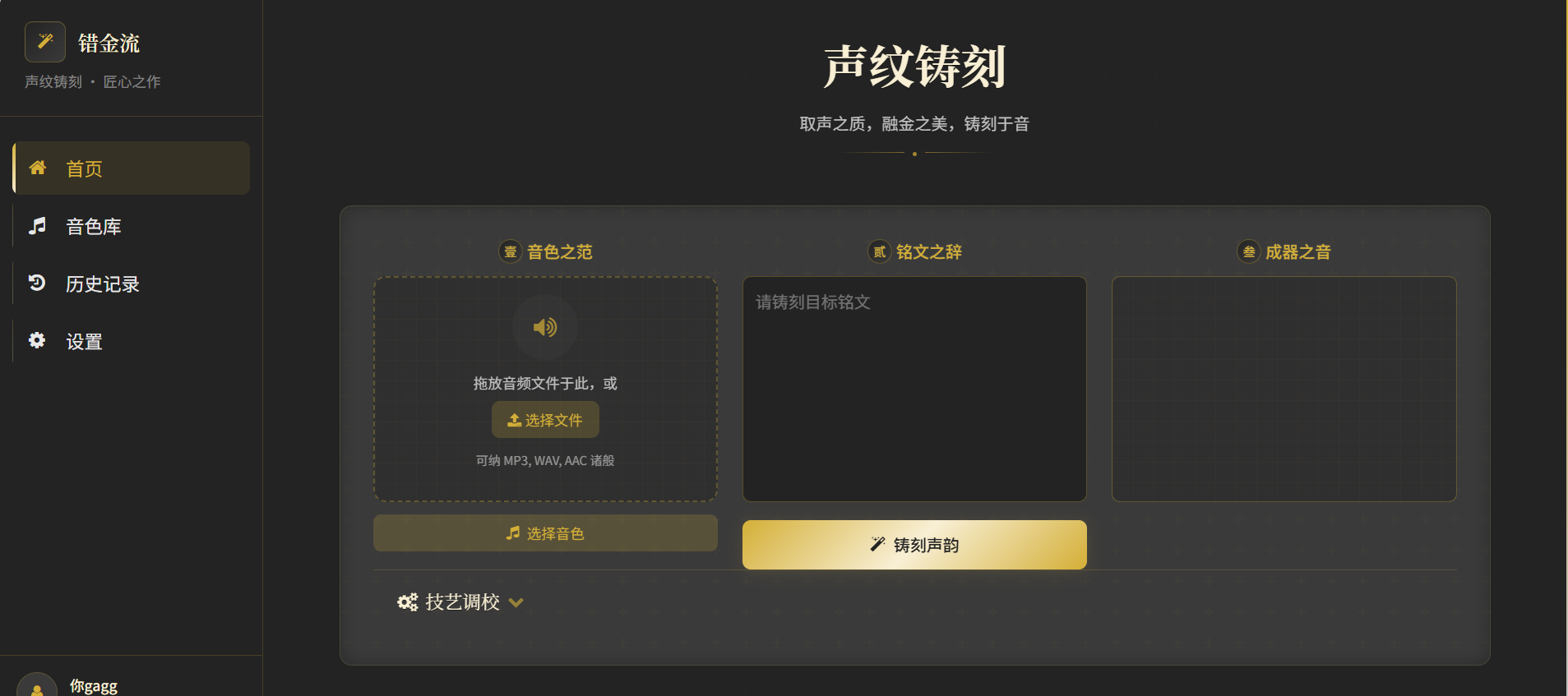
错金流TTS地表炸天TTS工具,一百多款自然人声,极速复刻
4@独立工作者
51186H更新时间:2026-02-02
地表炸天TTS工具,一百多款自然人声,极速复刻
地表炸天TTS工具,一百多款自然人声,极速复刻
视频超分

FlashVSR 视频高清放大工具
21@AI画师大阳
认证作者458900H更新时间:2026-01-30
支持自启动FlashVSR 视频高清放大工具
FlashVSR 视频高清放大工具
AI应用

video-subtitle-extractor视频字幕提取器 全智能加速优化版 构建by科哥
0@鸡你太美
认证作者1219H更新时间:2026-04-27
一键提取视频字幕 加速优化
一键提取视频字幕 加速优化
语音合成语音识别

Step-Audio-EditX
3@十字鱼
认证作者2924H更新时间:2025-11-14
支持自启动一个强大的 3B 参数、基于 LLM 的强化学习音频编辑模型,擅长编辑情感、说话风格和副语言,并具有稳健的零样本文本转语音功能
一个强大的 3B 参数、基于 LLM 的强化学习音频编辑模型,擅长编辑情感、说话风格和副语言,并具有稳健的零样本文本转语音功能
语音合成

VibeVoice:富有表现力的长篇多人对话语音合成工具
14@AI画师大阳
认证作者167736H更新时间:2026-01-30
支持自启动富有表现力的长篇多人对话语音合成工具
富有表现力的长篇多人对话语音合成工具
语音合成语音克隆

IndexTTS2 B站开源超强语音克隆
385@十字鱼
认证作者270611471H更新时间:2026-03-16
支持自启动B站开源超强语音克隆,在情感表达和时长控制方面取得突破的自回归零样本文本合成系统
B站开源超强语音克隆,在情感表达和时长控制方面取得突破的自回归零样本文本合成系统
Wan视频编辑ComfyUI

Remix-Wan2.2一体化多功能创作镜像
34@AI-KSK
认证作者2353270H更新时间:2026-01-30
一体化整合Remix-Wan 2.2 文生视频、图生视频、首尾帧生成与 Qwen3 自动提示词的多功能创作镜像
一体化整合Remix-Wan 2.2 文生视频、图生视频、首尾帧生成与 Qwen3 自动提示词的多功能创作镜像
视频生成

AI视频消除万物-支持消除人物、物体、水印、字幕等
94@与AI同行
认证作者11412031H更新时间:2026-03-31
支持自启动AI视频消除万物整合包,支持消除人物、物体、水印、字幕等,支持较长视频、添加队列任务,打开即用,一键运行!
AI视频消除万物整合包,支持消除人物、物体、水印、字幕等,支持较长视频、添加队列任务,打开即用,一键运行!
图片编辑图片生成ComfyUI

ChromoEdit-GGUF模型,,图片修改,图像修改,图生视频,支持5090新卡,comfyui,工作流,workflow
9@刘悦的技术博客
认证作者6923H更新时间:2026-01-30
支持自启动ChromoEdit-GGUF模型,,图片修改,图像修改,图生视频,支持5090新卡,comfyui,工作流,workflow
ChromoEdit-GGUF模型,,图片修改,图像修改,图生视频,支持5090新卡,comfyui,工作流,workflow
InfiniteTalk数字人

InfiniteTalk数字人视频制作软件,图片转视频,视频人物配音
37@AI画师大阳
认证作者585867H更新时间:2026-02-02
支持自启动InfiniteTalk 是一个无限长度的对话视频生成模型,支持音频驱动的视频到视频和图像到视频的生成
InfiniteTalk 是一个无限长度的对话视频生成模型,支持音频驱动的视频到视频和图像到视频的生成
ComfyUI

Diffusion_pipe_in_ComfyUI天冬
3@天冬
1777H更新时间:2025-11-11
支持自启动为 ComfyUI 提供了完整的 Diffusion 模型训练和微调功能。这个项目允许用户在 ComfyUI 的图形界面中配置和启动各种先进 AI 模型的训练,支持 LoRA 和全量微调
为 ComfyUI 提供了完整的 Diffusion 模型训练和微调功能。这个项目允许用户在 ComfyUI 的图形界面中配置和启动各种先进 AI 模型的训练,支持 LoRA 和全量微调
语音合成语音识别

Step-Audio-EditX
3@鹄仙
认证作者2345H更新时间:2025-11-24
一个音频编辑项目,“情绪编辑”“风格编辑”“语气编辑”和“降噪变速”
一个音频编辑项目,“情绪编辑”“风格编辑”“语气编辑”和“降噪变速”
其他

猫哥的商业化AI,SORA2
20@老猫本猫
8512957H更新时间:2026-01-30
支持自启动SORA2文生视频,图生视频
SORA2文生视频,图生视频
AI应用

AI-Trader港大开源的AI自动交易竞赛框架 汉化构建By科哥
1@鸡你太美
认证作者106H更新时间:2026-04-27
股市有风险 投资请谨慎!
股市有风险 投资请谨慎!
Qwen-Image图片生成

Qwen-Image-Edit-2509多图编辑及人物一致性生成
4@AI画师大阳
认证作者166183H更新时间:2026-01-30
支持自启动Qwen-Image-Edit-2509精准多图内容编辑及人物一致性图片生成
Qwen-Image-Edit-2509精准多图内容编辑及人物一致性图片生成
视频生成

超强Sora2视频去水印
54@与AI同行
认证作者309549H更新时间:2026-03-31
支持自启动超强Sora2视频去水印
超强Sora2视频去水印
InfiniteTalkWan数字人

SDPOSE 超复杂骨骼识别系统 X Lynx + InfiniteTalk + VACE + Wan 无限时长视频转绘体系
8@AI-KSK
认证作者4068H更新时间:2026-01-30
以 SDPOSE 为核心,融合 Lynx、InfiniteTalk、VACE 与Wan ,构建出一个可无限时长、骨骼级精度的人体视频转绘与智能生成体系
以 SDPOSE 为核心,融合 Lynx、InfiniteTalk、VACE 与Wan ,构建出一个可无限时长、骨骼级精度的人体视频转绘与智能生成体系
视频超分

ComfyUI_FlashVSR 实时视频超分,支持1分钟以上视频超分
11@smthem
158138H更新时间:2025-11-27
支持自启动实时视频超分项目,显存如果够大,所有视频超分到4K
实时视频超分项目,显存如果够大,所有视频超分到4K
QwenVL视觉理解

Qwen3-vl-abliterated视觉模型,视频理解,多图理解,批量任务,反推提示词
34@刘悦的技术博客
认证作者1681144H更新时间:2026-01-30
支持自启动Qwen3-vl-abliterated视觉模型,视频理解,多图理解,批量任务,反推提示词
Qwen3-vl-abliterated视觉模型,视频理解,多图理解,批量任务,反推提示词
Wan视频编辑

animate完美一致性人物迁移
38@
251354H更新时间:2026-01-30
支持自启动无惧镜头切换人物迁移
无惧镜头切换人物迁移
视频编辑ComfyUI

4步骤完成风格转绘vlog
3@鹄仙
认证作者1385H更新时间:2026-01-09
支持自启动4步骤完成风格转绘vlog
4步骤完成风格转绘vlog
WanLora训练

Wan2.2-Lora训练diffusionpipe
12@梦影Erislia
102543H更新时间:2026-01-30
Wan2.2Lora训练diffusionpipe
Wan2.2Lora训练diffusionpipe
图片编辑图片生成

ChronoEdit
3@十字鱼
认证作者116H更新时间:2025-11-04
支持自启动面向图像编辑和世界模拟的时序推理
面向图像编辑和世界模拟的时序推理
Wan视频编辑

wan2.2视频编辑人物替换背景替换
92@老徐Ai研习社
认证作者9671954H更新时间:2025-11-24
支持自启动视频编辑人物替换背景替换局部修改
视频编辑人物替换背景替换局部修改
语音合成

SoulX-Podcast:能说方言、带情绪的真实感长播客生成工具 构建by科哥
6@鸡你太美
认证作者75136H更新时间:2026-04-27
支持自启动SoulX-Podcast:能说方言、带情绪的真实感长播客生成工具
SoulX-Podcast:能说方言、带情绪的真实感长播客生成工具
语音合成

SoulX-Podcast-1.7B语音合成,接口API调用,多人播客合成,方言合成,语速调节,支持笑声咳嗽指令,支持5090新卡,音色保存
9@刘悦的技术博客
认证作者87124H更新时间:2025-11-14
支持自启动SoulX-Podcast-1.7B语音合成,接口API调用,多人播客合成,方言合成,语速调节,支持笑声咳嗽指令,支持5090新卡,音色保存
SoulX-Podcast-1.7B语音合成,接口API调用,多人播客合成,方言合成,语速调节,支持笑声咳嗽指令,支持5090新卡,音色保存
图片生成

最强AI图片编辑-QwenImageEdit加速版-支持换装、换姿势、批量生成、高清放大
41@与AI同行
认证作者372894H更新时间:2026-03-31
支持自启动最强AI图片编辑-QwenImageEdit-支持换装、换姿势、批量生成、SeedVR2高清放大
最强AI图片编辑-QwenImageEdit-支持换装、换姿势、批量生成、SeedVR2高清放大
视频编辑

facefusion3.4.1图片视频换脸神器 汉化版构建by科哥
25@鸡你太美
认证作者167226H更新时间:2026-04-27
facefusion3.4官方原版
facefusion3.4官方原版
Flux图片生成

DYPE超大分辨率1600万像素图像生成,ComfyUI插件实现
1@smthem
1442H更新时间:2025-11-02
支持自启动消费级显卡开始生成4096*4096的超大尺寸图片
消费级显卡开始生成4096*4096的超大尺寸图片
Wan视频编辑ComfyUI

wan2.2视频瞳孔转场
5@skyrimprey
7169H更新时间:2026-01-30
挂载wan2.2瞳孔转场lora,实现专业的视频转场效果
挂载wan2.2瞳孔转场lora,实现专业的视频转场效果
图片编辑AI工具
最强照片上色DDColor-牛哥定制版
5@NiuGee
认证作者22138H更新时间:2026-01-30
支持自启动🎨 DDColor 牛哥镜像版 - 黑白图像智能上色 牛哥针对DDColor黑白图像上色模型制作的一手镜像,这应该是目前效果最好的黑白照片智能上色解决方案之一。
🎨 DDColor 牛哥镜像版 - 黑白图像智能上色 牛哥针对DDColor黑白图像上色模型制作的一手镜像,这应该是目前效果最好的黑白照片智能上色解决方案之一。
IndexTTS语音合成

IndexTTS2/GPT-SoVITS+Srt-AI-Voice-Assistant多角色字幕长文本一键配音镜像
41@数列解析几何一生之敌
认证作者3534143H更新时间:2026-02-02
支持自启动Srt-AI-Voice-Assistant配音辅助工具搭配IndexTTS2/GSV的镜像
Srt-AI-Voice-Assistant配音辅助工具搭配IndexTTS2/GSV的镜像
视频生成

超强AI生成视频-SmoothMix-V2合集-效果超强
46@与AI同行
认证作者4591775H更新时间:2026-03-31
支持自启动SmoothMix-V2合集-效果超强,支持文生视频、图生视频、首尾帧、批量首尾帧视频,支持NSFW、高清修复!
SmoothMix-V2合集-效果超强,支持文生视频、图生视频、首尾帧、批量首尾帧视频,支持NSFW、高清修复!
LongCat视频生成

美团LongCat-ComfyUI|文生视频·图生视频·视频延续|长视频生成
12@AI-KSK
认证作者114364H更新时间:2026-01-30
这是一个集成了美团LongCat模型与ComfyUI的镜像,提供文生视频、图生视频和视频延续三大功能,核心优势在于能生成长时间且质量稳定的视频。
这是一个集成了美团LongCat模型与ComfyUI的镜像,提供文生视频、图生视频和视频延续三大功能,核心优势在于能生成长时间且质量稳定的视频。
视频生成

超强AI生成视频-Lightx2v-I2V-超强动态、分镜效果
18@与AI同行
认证作者207538H更新时间:2026-03-31
支持自启动超强AI生成视频-Lightx2v-I2V-超强动态、分镜效果。支持图生视频,首尾帧、批量首尾帧视频、批量生成、高清修复
超强AI生成视频-Lightx2v-I2V-超强动态、分镜效果。支持图生视频,首尾帧、批量首尾帧视频、批量生成、高清修复
LongCat视频生成

美团Longcat-video视频模型
7@社恐的知识树
认证作者30146H更新时间:2025-10-29
支持自启动美团开源的长视频生成模型-Longcat,ComfyUI抢先体验版,后续优化后继续更新!
美团开源的长视频生成模型-Longcat,ComfyUI抢先体验版,后续优化后继续更新!
数字人

LatentSync抖音出品高质量对口型软件
69@AI画师大阳
认证作者9647646H更新时间:2026-01-30
支持自启动高质量对口型工具
高质量对口型工具
视频超分

FlashVSR_Ultra_Fast,图片视频超清放大,支持批量任务,支持5090新卡
45@刘悦的技术博客
认证作者8934344H更新时间:2026-01-30
支持自启动FlashVSR_Ultra_Fast,图片视频超清放大,支持批量任务,支持5090新卡
FlashVSR_Ultra_Fast,图片视频超清放大,支持批量任务,支持5090新卡
视频编辑ComfyUI

一键视频转绘Ditto
6@鹄仙
认证作者5967H更新时间:2026-02-02
把视频整体转会成其他风格
把视频整体转会成其他风格
ComfyUI

积木comfyui
11@积木comfyui
4462H更新时间:2026-02-02
支持自启动简单易懂,用核心原理展示工作流
简单易懂,用核心原理展示工作流
Qwen-ImageComfyUIWan

Pony V7 × Qwen AIO × Smooth 2.0无限制生产|图像 / 编辑 / 视频 一体化
19@AI-KSK
认证作者3171497H更新时间:2026-02-02
这是一个整合图像生成、图像编辑和视频生产的 AI 创作工具。
这是一个整合图像生成、图像编辑和视频生产的 AI 创作工具。
数字人
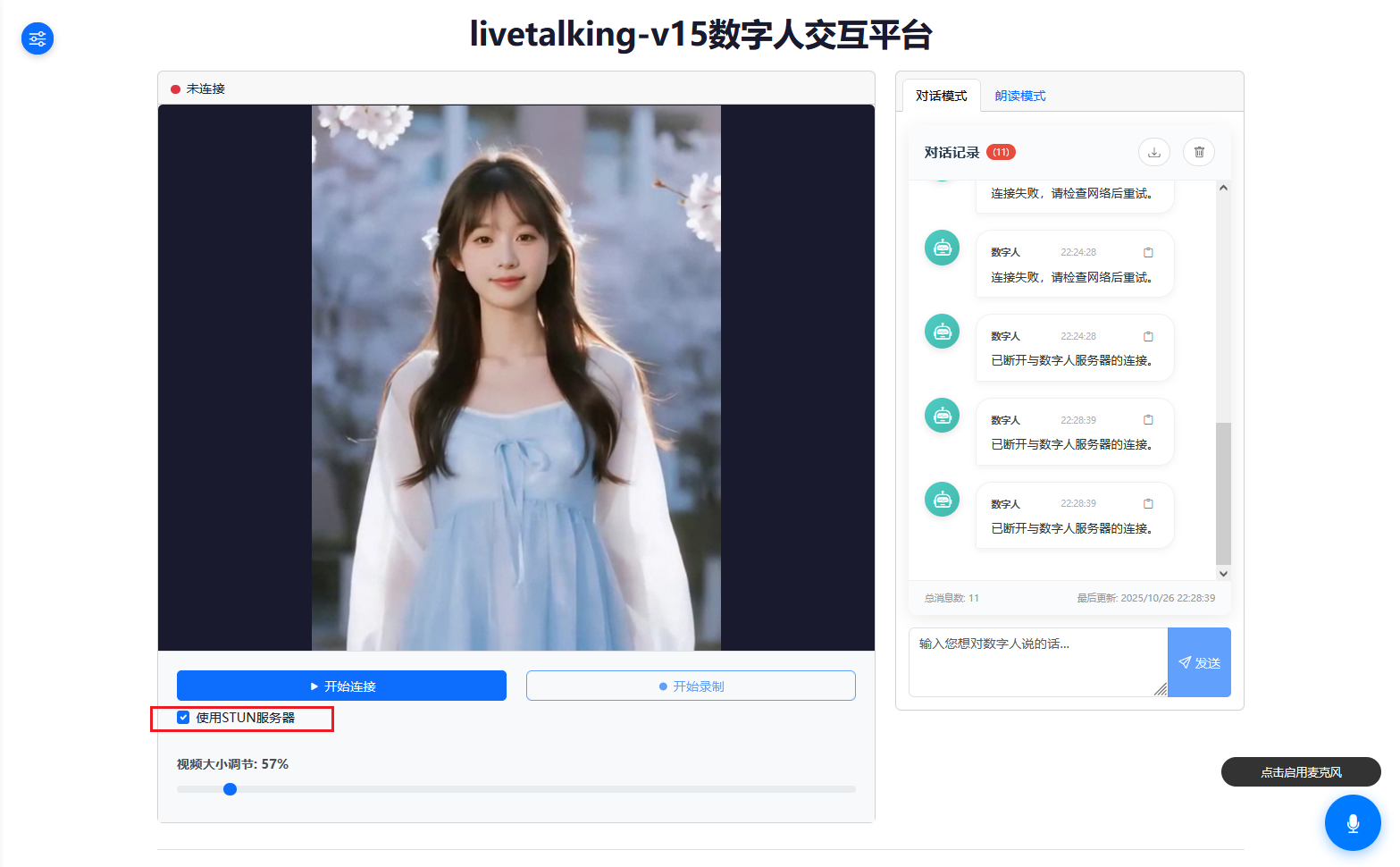
LiveTalking-V1.5
6@有黑眼圈的小竹熊
2522877H更新时间:2026-02-02
实时数字人解决方案
实时数字人解决方案
ComfyUIWan视频生成

Comfyui_Ditto
4@skyrimprey
1217H更新时间:2026-02-02
Ditto:基于指令的视频编辑框架,可以用于视频内元素的风格转换 本镜像为https://github.com/EzioBy/Ditto的Comfyui实现
Ditto:基于指令的视频编辑框架,可以用于视频内元素的风格转换 本镜像为https://github.com/EzioBy/Ditto的Comfyui实现
AI应用

MinerU:高质量PDF转Markdown/JSON
12@AI画师大阳
认证作者233896H更新时间:2026-02-02
支持自启动快速高效的将PDF文档转为Markdown/JSON文件
快速高效的将PDF文档转为Markdown/JSON文件
视频生成

超强AI视频风格重绘-Ditto-支持长视频、批量生成
17@与AI同行
认证作者97187H更新时间:2026-03-31
支持自启动超强AI视频重绘Ditto-支持长视频、批量生成,支持视频风格转换、动漫转真人视频,超级方便!
超强AI视频重绘Ditto-支持长视频、批量生成,支持视频风格转换、动漫转真人视频,超级方便!
3D生成

微软TRELLIS图片/文本转3D模型资产
4@AI画师大阳
认证作者107274H更新时间:2026-02-02
支持自启动高质量图片/文本转3D网格模型
高质量图片/文本转3D网格模型
DeepSeekOCR识别

DeepSeek-OCR
16@十字鱼
认证作者61803H更新时间:2025-10-24
上下文光学压缩
上下文光学压缩
Qwen-ImageComfyUI

Qwen-image-Nunchaku智能扩图,AI绘图,关键词扩图,图像填充,图像延展,支持5090新卡
5@刘悦的技术博客
认证作者6049H更新时间:2026-02-02
支持自启动Qwen-image-Nunchaku智能扩图,AI绘图,关键词扩图,图像填充,图像延展,支持5090新卡
Qwen-image-Nunchaku智能扩图,AI绘图,关键词扩图,图像填充,图像延展,支持5090新卡
InfiniteTalk数字人

ComfyUI_infiniteTalk数字人工作流
85@好奇漫步
164835714H更新时间:2026-02-02
本镜像包含ComfyUI许多工作流,目前优先测试部署完毕infiniteTalk数字人工作流、Wan2.2生视频工作流、HoMo数字人工作流等,后续会继续部署完善更多的工作流。
本镜像包含ComfyUI许多工作流,目前优先测试部署完毕infiniteTalk数字人工作流、Wan2.2生视频工作流、HoMo数字人工作流等,后续会继续部署完善更多的工作流。
WanQwen-Image视频生成

Qwen-image以及WAN视频系列,打开即用!
12@老许爱吃肉丶
1822265H更新时间:2026-02-02
支持自启动comfyui工作流,Qwen-image以及WAN2.1/2.2视频,都已经部署好,里面内置工作流,打开即可使用!
comfyui工作流,Qwen-image以及WAN2.1/2.2视频,都已经部署好,里面内置工作流,打开即可使用!
视频超分

FlashVSR视频高清放大webUI狂暴优化版 一键启用多倍放大 二次开发构建by科哥
10@鸡你太美
认证作者151168H更新时间:2026-04-27
FlashVSR视频高清放大webUI狂暴优化版 一键启用多倍放大
FlashVSR视频高清放大webUI狂暴优化版 一键启用多倍放大
Wan视频生成ComfyUI

Smooth Wan 2.2 动态↑速度↑NSFW↑文生/图生视频&首尾帧
111@AI-KSK
认证作者14469102H更新时间:2026-02-02
Smooth是最新的被社区广泛认可的Wan 2.2无限制合并模型
Smooth是最新的被社区广泛认可的Wan 2.2无限制合并模型
OCR识别

baidu-paddle-ocr
3@有趣的80后程序员
认证作者51131H更新时间:2026-02-02
ocr模型天花板、支持109种语言、公式、表格、图标
ocr模型天花板、支持109种语言、公式、表格、图标
视频超分

Flash-VSR-1.3B 图片/视频超清放大
8@刘悦的技术博客
认证作者9841H更新时间:2026-02-02
支持自启动Flash-VSR-1.3B,图片/视频超清放大,支持5090新显卡,支持批量任务
Flash-VSR-1.3B,图片/视频超清放大,支持5090新显卡,支持批量任务
目标检测VL视觉理解

Rex-Omni
3@十字鱼
认证作者23350H更新时间:2025-10-19
支持自启动通过下一个点预测来检测任何事物
通过下一个点预测来检测任何事物
Wan视频生成

Wan2.2-SmoothMix 更丝滑的图生视频
29@刘悦的技术博客
认证作者263202H更新时间:2026-02-02
支持自启动Wan2.2-SmoothMix,更丝滑的图生视频,首尾帧连贯动画,4步采样,支持5090新卡
Wan2.2-SmoothMix,更丝滑的图生视频,首尾帧连贯动画,4步采样,支持5090新卡
Wan视频编辑ComfyUI

Wan2.2-KJ氦气加速ComfyUI 6步极速版(唯一正版授权)
20@龙没耳
认证作者139900H更新时间:2026-02-02
支持自启动Wan2.2KJ氦气加速6步极速版唯一正版授权镜像——AI来事&龙没耳联合推出
Wan2.2KJ氦气加速6步极速版唯一正版授权镜像——AI来事&龙没耳联合推出
Wan视频编辑

Animate-v2-最强人物替换工作流
50@匹夫
认证作者466810H更新时间:2026-02-02
支持自启动Animate-v2-最强人物替换工作流
Animate-v2-最强人物替换工作流
图片编辑图片生成ComfyUI

DreamOmni2 ComfyUI 量化版
2@鹄仙
认证作者3166H更新时间:2025-11-07
支持自启动超级强大的图像编辑项目
超级强大的图像编辑项目
视频生成

OVI一款使用提示生成音频音效,或者完整的有声视频开源模型
2@社恐的知识树
认证作者2613H更新时间:2026-02-02
一个类似Veo3 Sora的开源模型,使用提示词自动生成音频视频
一个类似Veo3 Sora的开源模型,使用提示词自动生成音频视频
视频生成Wan

最强视频编辑-阿里WanAnimate-Q8超高精度-合集
230@与AI同行
认证作者452517646H更新时间:2026-03-31
支持自启动最强视频编辑-阿里Wan-Animate-Q8超高精度-合集
最强视频编辑-阿里Wan-Animate-Q8超高精度-合集
Wan视频编辑ComfyUI

视频重绘_跳舞姿势视频迁移Wan2.2图生视频
33@梦影Erislia
186143H更新时间:2026-02-02
视频重绘_跳舞姿势视频迁移Wan2.2图生视频
视频重绘_跳舞姿势视频迁移Wan2.2图生视频
ComfyUIAI电商

电商-AI模特/饰品/眼镜/假发模特,ComfyUI一键启动镜像
17@AI美研所
210524H更新时间:2026-02-03
支持自启动适用电商的ComfyUI镜像环境,包括:饰品佩戴、 多姿势,多角度, 一致性模特工作流,一键换装工作流,眼镜模特工作流,假发模特工作流镜像;本镜像采取一键打包形式,不用输入一句命令,点击几次即可
适用电商的ComfyUI镜像环境,包括:饰品佩戴、 多姿势,多角度, 一致性模特工作流,一键换装工作流,眼镜模特工作流,假发模特工作流镜像;本镜像采取一键打包形式,不用输入一句命令,点击几次即可
Wan视频编辑ComfyUI

Wan-Lynx 面部信息迁移图生视频+人脸一致性保持
20@刘悦的技术博客
认证作者8960H更新时间:2026-02-02
支持自启动Wan-Lynx,面部信息迁移图生视频,人脸一致性保持,6步采样,支持5090新卡,支持批量任务,Comfyui,工作流
Wan-Lynx,面部信息迁移图生视频,人脸一致性保持,6步采样,支持5090新卡,支持批量任务,Comfyui,工作流
VL视觉理解

Ming-UniVision
2@十字鱼
认证作者154H更新时间:2026-02-02
支持自启动使用连续统一分词器进行联合图像理解和生成
使用连续统一分词器进行联合图像理解和生成
Wan视频编辑ComfyUI

Wan2.2-N版-文生图生视频VACE-10流整合
41@AI-KSK
认证作者4021024H更新时间:2026-02-02
支持自启动Smooth&Remix&AllInOne-N版合并模型的一键镜像
Smooth&Remix&AllInOne-N版合并模型的一键镜像
AI应用

PDFMathTranslate
5@十字鱼
认证作者53H更新时间:2026-02-02
支持自启动基于 AI 完整保留排版的 PDF 文档全文双语翻译,支持 Google/DeepL/Ollama/OpenAI 等服务
基于 AI 完整保留排版的 PDF 文档全文双语翻译,支持 Google/DeepL/Ollama/OpenAI 等服务
IndexTTS语音合成

indextts2-IndexTTS2 最新 V23 版本的全面升级
52@鸡你太美
认证作者8402198H更新时间:2026-04-27
IndexTTS2 最新 V23 版本的全面升级
IndexTTS2 最新 V23 版本的全面升级
混元3D生成

腾讯混元3d-Omni在线生成Hunyuan3D-Omni轻量版3d模型生成命令行版 构建by科哥
3@鸡你太美
认证作者31352H更新时间:2026-04-27
24gb可以运行该应用
24gb可以运行该应用
视频生成

Ovi 来啦!开源免费,体验一下类似 SORA 2 的视频+音频生成
7@AI-KSK
认证作者6323H更新时间:2026-02-02
认识一下 Ovi —— 一个很像 SORA 2 的免费 AI 模型。它能生成带声音的完整视频,让你探索下一代 AI 创作的无限可能!
认识一下 Ovi —— 一个很像 SORA 2 的免费 AI 模型。它能生成带声音的完整视频,让你探索下一代 AI 创作的无限可能!
混元图片生成

HunyuanImage-3.0
13@十字鱼
认证作者6393H更新时间:2025-10-06
支持自启动腾讯开源80B图像生成模型 原生多模态 自回归框架
腾讯开源80B图像生成模型 原生多模态 自回归框架
视频生成

Ovi 音频视频生成
12@十字鱼
认证作者5734H更新时间:2025-10-20
支持自启动用于音频视频生成的双主干交叉模态融合
用于音频视频生成的双主干交叉模态融合
语音合成

GPT-SoVITS
116@aiguoliuguo
认证作者360440043H更新时间:2026-02-03
GPT-SoVITS-V4(v2Pro,v2ProPlus),所需素材少,训练耗时短,情绪可控。
GPT-SoVITS-V4(v2Pro,v2ProPlus),所需素材少,训练耗时短,情绪可控。
语音分离

MSST
46@aiguoliuguo
认证作者22445148H更新时间:2025-10-05
MSST-webUI版本,更简单,加入一键处理,效率更高,更好用的干声分离以及去和声混响的项目,可以作为传统UVR的上位替代,并兼容UVR的模型,简单且快。
MSST-webUI版本,更简单,加入一键处理,效率更高,更好用的干声分离以及去和声混响的项目,可以作为传统UVR的上位替代,并兼容UVR的模型,简单且快。
IndexTTS语音合成

index-tts2高质量声音克隆语音合成软件
62@AI画师大阳
认证作者15695159H更新时间:2026-02-02
支持自启动index-tts2高质量声音克隆语音合成软件
index-tts2高质量声音克隆语音合成软件
Wan视频编辑ComfyUI

WAN22增强版-eddy-ode采样,文生视频/图生视频
19@AI-KSK
认证作者217225H更新时间:2026-02-02
视频生产更精细、更流畅、更智能、更快速、更具视觉表现力。
视频生产更精细、更流畅、更智能、更快速、更具视觉表现力。
混元3D生成

腾讯混元3D2.1生成3d模型hunyuan 3d 构建by科哥
4@鸡你太美
认证作者5091H更新时间:2026-04-27
24gb最低显存
24gb最低显存
图片编辑

超强图片编辑工具OmniGen2,一句话修改图片内容
14@AI画师大阳
认证作者12388H更新时间:2026-02-02
支持自启动一句话快速精准修改图片内容
一句话快速精准修改图片内容
数字人

StableAvatar快速生成对口型数字人视频 12gb显卡爆改by科哥
9@鸡你太美
认证作者95126H更新时间:2026-04-27
对口型数字人视频wan2.1优化项目 12gb显卡爆改by科哥
对口型数字人视频wan2.1优化项目 12gb显卡爆改by科哥
ComfyUI视频生成

Lynx字节跳动高保真人脸视频生成方法comfyUI镜像
2@smthem
1122H更新时间:2026-02-02
非量化版LYNX,非KJ版,24G显存才能跑
非量化版LYNX,非KJ版,24G显存才能跑
InfiniteTalkIndexTTS数字人

顶级中文数字人套件-Easy-IndexTTS2 · FireRedTTS · InfiniteTalk
18@AI-KSK
认证作者1611145H更新时间:2026-02-02
克隆目标声音,保留音色、语气与情感;将静态图片与音频驱动生成动态视频。
克隆目标声音,保留音色、语气与情感;将静态图片与音频驱动生成动态视频。
IndexTTS语音合成

IndexTTS-V2 DeepSpeed编译加速版
136@刘悦的技术博客
认证作者323610192H更新时间:2026-02-02
支持自启动支持异步批量任务,支持接口API并发请求,语速调节,音色保存,情绪控制
支持异步批量任务,支持接口API并发请求,语速调节,音色保存,情绪控制
推理框架

bunkws
2@杭州国芯微
392622H更新时间:2026-02-02
Bunkws 是杭州国芯微自研的一款端到端唤醒词训练框架
Bunkws 是杭州国芯微自研的一款端到端唤醒词训练框架
Wan视频编辑

Wan-2.2-Animate视频主体替换,支持批量任务队列
46@刘悦的技术博客
认证作者367450H更新时间:2026-02-02
支持自启动Wan-2.2-Animate视频主体替换,支持批量任务队列,初始化后,等待服务启动,大概2分钟左右,随后点击SD-WEBUI按钮即可
Wan-2.2-Animate视频主体替换,支持批量任务队列,初始化后,等待服务启动,大概2分钟左右,随后点击SD-WEBUI按钮即可
IndexTTS语音合成

Niugee-IndexTTS-V2
37@NiuGee
认证作者355923H更新时间:2026-02-02
支持自启动目前情感效果最好,没有幻觉的文本转语音AI工具
目前情感效果最好,没有幻觉的文本转语音AI工具
语音合成

VoxCPM-小而美的TTS
5@鹄仙
认证作者38304H更新时间:2026-02-02
比IndexTTS更小的语音生成模型,支持语音克隆、文生语音
比IndexTTS更小的语音生成模型,支持语音克隆、文生语音
Qwen-Image图片生成ComfyUI

Qwen-Image-Edit-2509 三图融合,4步采样
25@刘悦的技术博客
认证作者179230H更新时间:2026-02-02
支持自启动Qwen-Image-Edit-2509三图融合.4步采样,支持自定义多重Lora嵌套,AI图片编辑修改,支持批量任务队列
Qwen-Image-Edit-2509三图融合.4步采样,支持自定义多重Lora嵌套,AI图片编辑修改,支持批量任务队列
ComfyUI

培训师的comfyUI
6@鹄仙
认证作者63404H更新时间:2026-02-02
组合了图像生成、视频生成、数字人的面向培训师群体的ComfyUI
组合了图像生成、视频生成、数字人的面向培训师群体的ComfyUI
WanQwen-Image视频生成

Qwen edit+Wan2.2 出图+视频的神! 平替Banana
36@不止设计工作室
3201773H更新时间:2026-02-02
qwen edit满血模型部署!替代banana,结合comfyui工作流轻松实现出图、p图、视频生成
qwen edit满血模型部署!替代banana,结合comfyui工作流轻松实现出图、p图、视频生成
数字人

MultiTalk-生成音乐MV
31@乔大峰
认证作者99203H更新时间:2026-02-02
支持自启动MultiTalk-只需上传图片和音频,帮你生成音乐MV
MultiTalk-只需上传图片和音频,帮你生成音乐MV
Wan视频编辑ComfyUI

WanAnimate
20@十字鱼
认证作者113164H更新时间:2025-11-06
支持自启动Wan2.2-Animate 动作迁移&人物替换 迟来的AnimateAnyone
Wan2.2-Animate 动作迁移&人物替换 迟来的AnimateAnyone
Wan视频编辑ComfyUI

Wan-Animate-ComfyUI:角色动画生成与角色替换
13@AI-KSK
认证作者150295H更新时间:2026-02-02
Wan-Animate 是阿里巴巴通义实验室提出的一个统一框架,用于 角色动画生成与角色替换。
Wan-Animate 是阿里巴巴通义实验室提出的一个统一框架,用于 角色动画生成与角色替换。
视频超分

SeedVR2-视频高清放大工作流
24@鸡你太美
认证作者9099H更新时间:2026-04-27
支持自启动二次高清放大视频!3b、7b模型gguf量化加速版 不易爆显存 镜像by科哥
二次高清放大视频!3b、7b模型gguf量化加速版 不易爆显存 镜像by科哥
语音合成

VoxCPM-来自面壁智能和清华的语音生成模型
4@鸡你太美
认证作者2664H更新时间:2026-04-27
支持自启动几秒音频即可克隆声音 构建by科哥
几秒音频即可克隆声音 构建by科哥
Wan视频生成

Wan2.2官方VACE-ComfyUI七大视频生成编辑工作流
9@AI-KSK
认证作者165372H更新时间:2026-02-02
开源的统一视频生成与编辑框架,Wan2.2-VACE-Fun一个模型即可支持文生视频、图生视频、视频编辑、局部修改、等多项任务
开源的统一视频生成与编辑框架,Wan2.2-VACE-Fun一个模型即可支持文生视频、图生视频、视频编辑、局部修改、等多项任务
数字人视频生成

humo-HuMo清华大学联合字节推出的多模态视频生成框架 二改by科哥
9@鸡你太美
认证作者2355H更新时间:2026-04-27
支持自启动优化1.7b可以24gb显存运行起来了!
优化1.7b可以24gb显存运行起来了!
语音合成

FireRedTTS2
9@十字鱼
认证作者49756H更新时间:2026-02-02
支持自启动面向播客和聊天机器人的长对话语音生成
面向播客和聊天机器人的长对话语音生成
ComfyUIWan

阿里Wan2.2-14B图生视频超高画质-Q8
92@与AI同行
认证作者10905362H更新时间:2026-03-31
支持自启动AI生成视频Wan2.2图生视频,使用量化版Wan2.2-I2V-A14B模型
AI生成视频Wan2.2图生视频,使用量化版Wan2.2-I2V-A14B模型
Wan视频生成

Wan-2.2-Fun-Vace视频主体替换
17@刘悦的技术博客
认证作者7480H更新时间:2026-02-02
支持自启动Wan-2.2-Fun-Vace,视频主体替换、跳舞视频主体替换、广告模特替换
Wan-2.2-Fun-Vace,视频主体替换、跳舞视频主体替换、广告模特替换
数字人视频生成

HuMo: 基于协作多模态条件的人体中心视频生成
8@Ikaros
1819H更新时间:2026-02-02
HuMo是一个统一的、以人为中心的视频生成框架,旨在从多模态输入(包括文本、图像和音频)生成高质量、细粒度且可控的人体视频。它支持强大的文本提示跟随、一致的主体保持和同步的音频驱动动作。
HuMo是一个统一的、以人为中心的视频生成框架,旨在从多模态输入(包括文本、图像和音频)生成高质量、细粒度且可控的人体视频。它支持强大的文本提示跟随、一致的主体保持和同步的音频驱动动作。
语音合成语音识别

FireRedASR语音识别、语音转文字 构建by科哥
2@鸡你太美
认证作者2715H更新时间:2026-04-27
支持自启动FireRedASR语音识别系统语音转文字语音转文本千问开源 构建by科哥
FireRedASR语音识别系统语音转文字语音转文本千问开源 构建by科哥
语音识别

FunASR在线语音识别/语音生成 二次开发构建by科哥
1@鸡你太美
认证作者3753H更新时间:2026-04-27
来自阿里开源 科哥二次构建开发webui
来自阿里开源 科哥二次构建开发webui
SD

SD高质量CG绘画
11@AI画师大阳
认证作者1981045H更新时间:2025-09-17
支持自启动SD高质量CG绘画
SD高质量CG绘画
目标检测图像分割

SAM 2:图像和视频中的任何内容分割
1@Ikaros
1511H更新时间:2026-02-02
SAM 2:图像和视频中的任何内容分割。比如切出视频中的人物、物体等,可以对目标和背景进行扣除换色等效果设置。
SAM 2:图像和视频中的任何内容分割。比如切出视频中的人物、物体等,可以对目标和背景进行扣除换色等效果设置。
数字人

AnchorCrafter:通过人体-物体交互视频生成动画化您的产品销售数字人
11@Ikaros
264505H更新时间:2026-02-02
AnchorCrafter,生成带货数字人视频。通过人体-物体交互视频生成动画化您的产品销售数字人
AnchorCrafter,生成带货数字人视频。通过人体-物体交互视频生成动画化您的产品销售数字人
数字人

OpenAvatarChat——十字鱼镜像
80@十字鱼
认证作者7129281H更新时间:2026-02-03
支持自启动阿里开源实时交互数字。 模块化的交互数字人对话实现,能够在单台PC上运行完整功能。
阿里开源实时交互数字。 模块化的交互数字人对话实现,能够在单台PC上运行完整功能。
数字人视频生成

HuMo
5@十字鱼
认证作者1311H更新时间:2026-02-02
支持自启动以人为中心的视频生成方法——协作多模态条件化
以人为中心的视频生成方法——协作多模态条件化
语音合成语音克隆

超强AI音频变声器SeedVC-2.1
33@与AI同行
认证作者3722583H更新时间:2026-03-31
支持自启动超强AI音频变声器SeedVC-2.1
超强AI音频变声器SeedVC-2.1
语音合成语音克隆

最强AI音色克隆IndexTTS-V2-批量生成
218@与AI同行
认证作者28128742H更新时间:2026-03-31
支持自启动最强AI音色克隆IndexTTS-V2-批量生成
最强AI音色克隆IndexTTS-V2-批量生成
数字人

AnchorCrafter-WebUI
16@乔大峰
认证作者2836H更新时间:2026-02-02
支持自启动开箱即用,生成真实的带货视频
开箱即用,生成真实的带货视频
IndexTTS语音合成

index-tts2 声音克隆
32@有趣的80后程序员
认证作者3691657H更新时间:2025-11-07
让ai声音更真实,更自然,更有温度
让ai声音更真实,更自然,更有温度
视频生成

MAGI-1
1@苍耳阿猫
认证作者712H更新时间:2026-02-02
MAGI-1,一个通过 自回归 预测视频块序列来生成视频的世界模型
MAGI-1,一个通过 自回归 预测视频块序列来生成视频的世界模型
视频编辑
大鹏最强FusionX动作迁移(和真人一模一样)
68@大鹏
认证作者400368H更新时间:2026-02-02
支持自启动这个版本无敌了,出的效果兄弟们话不多说直接看图
这个版本无敌了,出的效果兄弟们话不多说直接看图
IndexTTS语音合成

IndexTTS2 模型镜像 汉化构建by科哥
22@鸡你太美
认证作者248384H更新时间:2026-04-27
B站开源的indextts2.0版本,强势来袭!
B站开源的indextts2.0版本,强势来袭!
语音识别

最好用的中文音频视频语音识别转文本字幕软件FunASR
9@AI画师大阳
认证作者110362H更新时间:2026-02-02
支持自启动将音频视频语音识别转为文本文件和SRT字幕文件
将音频视频语音识别转为文本文件和SRT字幕文件
数字人

HeyGem数字人优化加速版,GFPGAN面部超分增强
59@刘悦的技术博客
认证作者9655443H更新时间:2025-11-14
支持自启动HeyGem数字人优化加速版,GFPGAN面部超分增强,批量任务,修复多面部报错,推理速度1比2,唱歌数字人
HeyGem数字人优化加速版,GFPGAN面部超分增强,批量任务,修复多面部报错,推理速度1比2,唱歌数字人
Wan视频生成

Wan2.2-图生视频-批量任务队列版本
40@刘悦的技术博客
认证作者5571692H更新时间:2026-02-02
支持自启动Wan2.2-图生视频-批量任务队列版本-自定义lora-自定义首尾帧
Wan2.2-图生视频-批量任务队列版本-自定义lora-自定义首尾帧
IndexTTS语音合成

indexTTS2
16@白菜工厂1145号员工
认证作者306992H更新时间:2026-02-02
支持自启动无需训练,开源最强zero shot语音合成
无需训练,开源最强zero shot语音合成
混元视频生成

HunyuanVideo-Foley
5@鹄仙
认证作者3169H更新时间:2026-02-02
为视频添加音效
为视频添加音效
IndexTTS语音合成

Index-TTS2--B站9月8日最新开源语音克隆模型ComfyUI版
12@社恐的知识树
认证作者189413H更新时间:2025-09-12
Index-tts2-B站最新开源语音大模型:声音克隆,情感复刻,多人对话,ComfyUI版
Index-tts2-B站最新开源语音大模型:声音克隆,情感复刻,多人对话,ComfyUI版
ComfyUI视频生成图片生成

换装+换脸+换一切+动作迁移+图片视频N合一
100@大鹏
认证作者7471188H更新时间:2026-05-21
支持自启动换装+换脸+换一切+动作迁移+图片视频N合一,最快wan2.2加速,最新kontext换一切,最强换装,最强换姿态迁移图片视频方案+最速换脸
换装+换脸+换一切+动作迁移+图片视频N合一,最快wan2.2加速,最新kontext换一切,最强换装,最强换姿态迁移图片视频方案+最速换脸
视频编辑

Facefusion3.4最新官方原版 图片换脸视频换脸高清图片 构建By科哥
5@鸡你太美
认证作者70114H更新时间:2026-04-27
支持自启动Facefusion3.4最新3.4官方原本全部模型已经下载11gb!!!
Facefusion3.4最新3.4官方原本全部模型已经下载11gb!!!
Qwen-Image图片生成ComfyUI

musubi-qwen-image lora 训练镜像
22@有趣的80后程序员
认证作者169794H更新时间:2025-09-09
最简单占用资源最小的lora训练镜像
最简单占用资源最小的lora训练镜像
Wan视频生成

Wan2.2-图生视频-灵活海量批量任务
20@星悦
认证作者115178H更新时间:2026-02-02
支持自启动Wan2.2图生视频灵活批量任务。启动后自动运行。1.在本地修改图片文件名。2.上传到云端文件夹【待处理图片】。3.稍等,下载视频文件夹视频【生成结果】。
Wan2.2图生视频灵活批量任务。启动后自动运行。1.在本地修改图片文件名。2.上传到云端文件夹【待处理图片】。3.稍等,下载视频文件夹视频【生成结果】。
其他

cuda124-py310-torch2.7基础镜像版本
5@鸡你太美
认证作者332760H更新时间:2026-04-27
cuda124-py310-torch2.7基础镜像版本
cuda124-py310-torch2.7基础镜像版本
Wan数字人

Wan2.2-S2V-14B: 音频驱动的电影视频生成
2@AI画师大阳
认证作者119120H更新时间:2026-02-02
支持自启动通过音频驱动的图片转视频生成软件,支持声音克隆功能
通过音频驱动的图片转视频生成软件,支持声音克隆功能
Wan数字人

WAN2.2-S2V最新版数字人+动作参考
12@社恐的知识树
认证作者104121H更新时间:2025-09-06
阿里开源音+图片+动作参考生成视频模型,Comfyui官方最终优化版工作流
阿里开源音+图片+动作参考生成视频模型,Comfyui官方最终优化版工作流
图像修复视频生成

最强AI高清修复-SeedVR2-图片和视频高清放大
106@与AI同行
认证作者155617108H更新时间:2026-03-31
支持自启动最强AI高清修复-SeedVR2-图片和视频高清放大
最强AI高清修复-SeedVR2-图片和视频高清放大
视频编辑
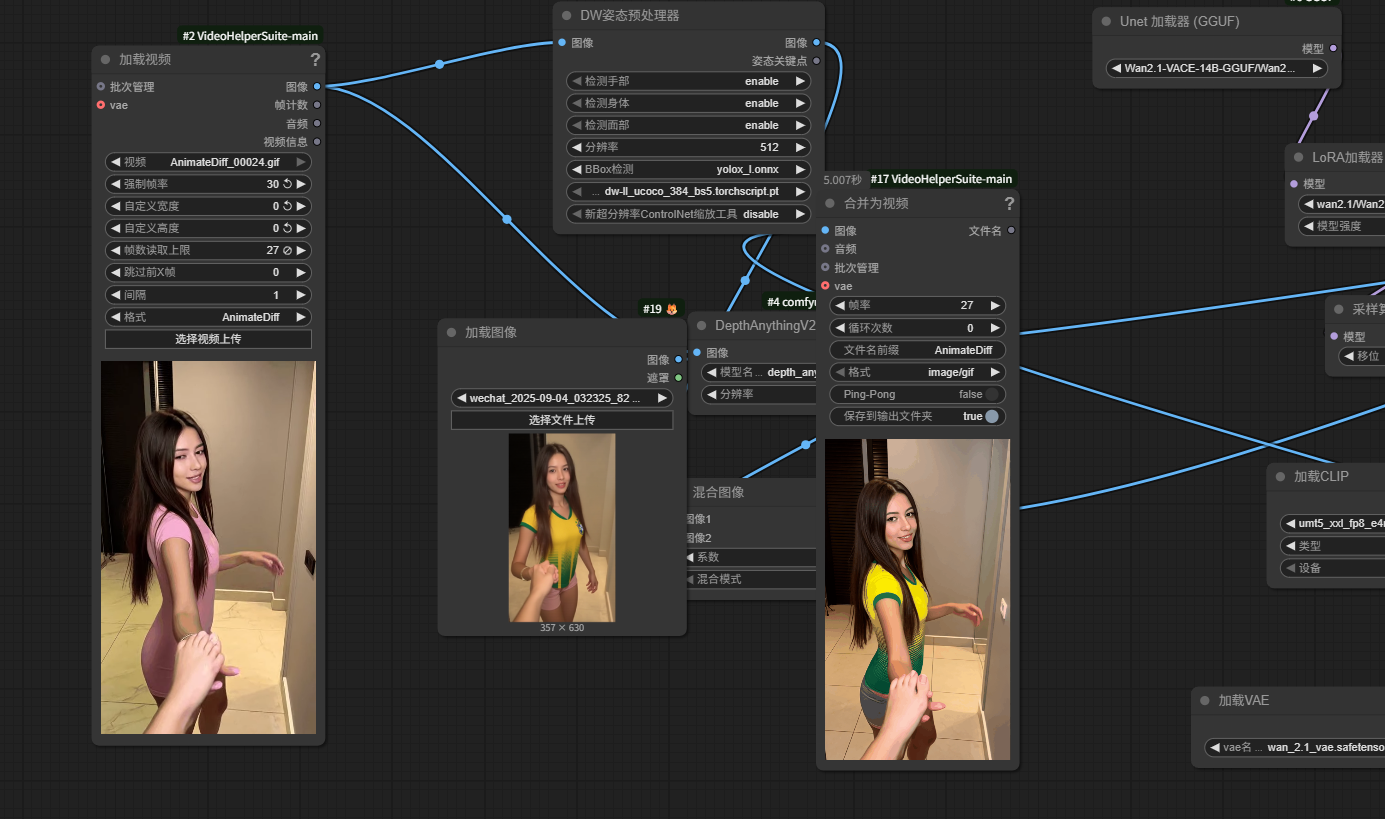
大鹏姿态迁移,图片,视频,换装,图生视频四合一
28@大鹏
认证作者181208H更新时间:2026-02-02
支持自启动高质量工作流,点开即可运行
高质量工作流,点开即可运行
ComfyUI视频生成

Work-Fisher短片制作整合包
19@Work-Fisher
94145H更新时间:2026-02-02
创造属于你的AI短片
创造属于你的AI短片
AI应用

PDF文档翻译器BabelDOC
3@AI画师大阳
认证作者87355H更新时间:2026-02-02
基于强大在线大语言模型的PDF文档翻译器
基于强大在线大语言模型的PDF文档翻译器
ComfyUIFlux

牛哥的专属ComfyUI大集合版-V1
18@NiuGee
认证作者119201H更新时间:2026-02-02
牛哥的专属ComfyUI大集合版本,功能持续扩充,点击即用
牛哥的专属ComfyUI大集合版本,功能持续扩充,点击即用
混元3D生成

HunyuanWorld-WebUI fp8量化魔改版 开发构建by科哥
3@鸡你太美
认证作者47115H更新时间:2026-04-27
HunyuanWorld 3d世界生成系统 腾讯开源
HunyuanWorld 3d世界生成系统 腾讯开源
Hunyuan音乐

最强AI视频配音-腾讯Hunyuan-Foley
26@与AI同行
认证作者138253H更新时间:2026-03-31
最强AI视频配音-腾讯Hunyuan-Foley
最强AI视频配音-腾讯Hunyuan-Foley
AI应用语音识别

音频视频语音识别转文本字幕faster-whisper 1.2
20@AI画师大阳
认证作者2562129H更新时间:2026-02-02
将音频或视频文件语音识别转为文本文件或字幕文件
将音频或视频文件语音识别转为文本文件或字幕文件
三维重建

Unique3D在线生成3D模型 汉化构建By科哥
3@鸡你太美
认证作者4556H更新时间:2026-04-27
一张图片就可以生成3D glb模型
一张图片就可以生成3D glb模型
ComfyUI图片生成

gen_backview
0@frankyxu
71055H更新时间:2026-02-02
gen_backview bug 修复
gen_backview bug 修复
Wan视频生成

Wan2.2 S2V 数字人 阿里通义千问出品
17@十字鱼
认证作者184341H更新时间:2026-02-02
Wan2.2 S2V 数字人 阿里通义千问出品 这是一个音频驱动的电影视频生成模型
Wan2.2 S2V 数字人 阿里通义千问出品 这是一个音频驱动的电影视频生成模型
混元视频生成

HunyuanVideo-Foley腾讯开源视频音效配音文本配音 汉化构建by科哥
7@鸡你太美
认证作者5161H更新时间:2026-04-27
根据一段文本或者视频,生成你的配音
根据一段文本或者视频,生成你的配音
混元AI音乐

HunyuanVideo-Foley 腾讯混元开源音效模型
3@十字鱼
认证作者1310H更新时间:2025-09-03
一键视频配音,完美自动化
一键视频配音,完美自动化
混元视频生成

HunyuanVideoFoley-AI视频配乐
14@匹夫
认证作者113216H更新时间:2026-02-02
支持自启动HunyuanVideoFoley-能自动给视频配乐的AI模型
HunyuanVideoFoley-能自动给视频配乐的AI模型
Wan视频生成

Wan2GP——十字鱼镜像
5@十字鱼
认证作者49195H更新时间:2026-02-02
Wan2GP,高度优化的视频生成项目,支持Wan、Hunyuan和LTX等相关模型
Wan2GP,高度优化的视频生成项目,支持Wan、Hunyuan和LTX等相关模型
数字人

HeyGem-webui在线数字人视频口播数字人 构建bu科哥
13@鸡你太美
认证作者173357H更新时间:2026-04-27
一键运行优化版,开机自启动
一键运行优化版,开机自启动
数字人ComfyUI

AI换人术一键将跳舞视频主角变成你!(Stand-In + VACE + ComfyUI 镜像版)
30@电磁波Studio
认证作者289693H更新时间:2026-02-02
AI换人术一键将跳舞视频主角变成你!(Stand-In + VACE + ComfyUI 镜像版)
AI换人术一键将跳舞视频主角变成你!(Stand-In + VACE + ComfyUI 镜像版)
WanLora训练

musubi-tunner-wan2.2训练镜像
33@有趣的80后程序员
认证作者4102659H更新时间:2025-10-28
musubi-tunner-wan2.2 lora 训练镜像,内置模型数据集
musubi-tunner-wan2.2 lora 训练镜像,内置模型数据集
InfiniteTalk数字人

InfiniteTalk数字人,4步采样,无限时长,说话数字人,唱歌数字人
75@刘悦的技术博客
认证作者17693265H更新时间:2026-02-02
InfiniteTalk数字人,4步采样,无限时长,说话数字人,唱歌数字人,支持反推关键词,基于comfyui工作流
InfiniteTalk数字人,4步采样,无限时长,说话数字人,唱歌数字人,支持反推关键词,基于comfyui工作流
Qwen-Image

Qwen-image-千问合集
4@虚幻1024
87418H更新时间:2026-02-02
ComfyUI - qwen-image-千问合集
ComfyUI - qwen-image-千问合集
3D生成三维重建

SpatialGen - 3D场景生成器
1@鸡你太美
认证作者1111H更新时间:2026-04-27
基于多视角多模态扩散模型的3D场景生成工具 支持图像到3D场景和文本到3D场景的生成
基于多视角多模态扩散模型的3D场景生成工具 支持图像到3D场景和文本到3D场景的生成
语音合成

ThinkSound视频配音
2@鸡你太美
认证作者34123H更新时间:2026-04-27
支持自启动ThinkSound视频配音
ThinkSound视频配音
Wan视频生成

wan2.2-S2V数字人,支持批量任务队列
13@刘悦的技术博客
认证作者146145H更新时间:2026-02-02
支持自启动支持批量任务队列,说话数字人,唱歌数字人,支持反推关键词,基于comfyui工作流
支持批量任务队列,说话数字人,唱歌数字人,支持反推关键词,基于comfyui工作流
Wan视频生成

Wan2.2-S2V数字人-对口型-音频驱动视频生成
23@AI-KSK
认证作者234297H更新时间:2026-02-02
Wan2.2-S2V数字人,通过一张静态图片和一段音频(如说话或唱歌)自动生成高质量、口型同步的电影级视频。
Wan2.2-S2V数字人,通过一张静态图片和一段音频(如说话或唱歌)自动生成高质量、口型同步的电影级视频。
ComfyUI图片编辑

视频人物主体替换
7@AI画师大阳
认证作者6128H更新时间:2025-08-27
支持自启动用一张图片中人物替换视频中的人物主体
用一张图片中人物替换视频中的人物主体
Qwen-Image图片生成

Qwen-Image-Edit-多图融合-面部一致性保持
22@刘悦的技术博客
认证作者163310H更新时间:2026-02-02
支持自启动Qwen-Image-Edit-多图融合-面部一致性保持,基于comfyui工作流
Qwen-Image-Edit-多图融合-面部一致性保持,基于comfyui工作流
WanLora训练

Wan2.2-Lora训练,文生视频与图生视频Lora训练,AIToolkit
28@AI-KSK
认证作者3963596H更新时间:2026-02-02
用做训练Wan2.2文生视频或者/图生视频的 LoRA 模型
用做训练Wan2.2文生视频或者/图生视频的 LoRA 模型
OCR识别

RapidOCR_API_Torch_GPU
1@SWHL
认证作者510H更新时间:2026-02-02
基于 ONNXRuntime、OpenVINO、PaddlePaddle 和 PyTorch 的超棒 OCR 多编程语言工具包。
基于 ONNXRuntime、OpenVINO、PaddlePaddle 和 PyTorch 的超棒 OCR 多编程语言工具包。
Qwen-image

最强AI图片QwenImage-Edit-WebUI-支持Lora
15@与AI同行
认证作者167206H更新时间:2026-03-31
支持自启动QwenImage+Edit-WebUI-支持Lora
QwenImage+Edit-WebUI-支持Lora
VL视觉理解

VL视觉模型集合
1@Ikaros
596H更新时间:2026-02-02
内置InternVL3-8B、GLM-4.1V-9B-Thinking、GLM-4.1V-9B-Thinking-bnb-4bit 一键启动API服务
内置InternVL3-8B、GLM-4.1V-9B-Thinking、GLM-4.1V-9B-Thinking-bnb-4bit 一键启动API服务
混元

HunyuanWorld-1.0-lite 腾讯混元3D世界lite
1@鸡你太美
认证作者1521H更新时间:2026-04-27
快速打造你的3D游戏世界1.0,通过jupyterlab命令行运行生成3D游戏世界
快速打造你的3D游戏世界1.0,通过jupyterlab命令行运行生成3D游戏世界
InfiniteTalk数字人

infinitetalk数字人工作流
80@匹夫
认证作者13976613H更新时间:2026-02-02
支持自启动infinitetalk,音频+图片参考、音频+视频参考工作流
infinitetalk,音频+图片参考、音频+视频参考工作流
Wan视频生成ComfyUI

wan2.1文生视频动作迁移
10@AI画师大阳
认证作者148234H更新时间:2026-02-02
支持自启动模仿参考视频人物动作快速生成新的人物视频
模仿参考视频人物动作快速生成新的人物视频
推理框架

ms-swift轻量级微调模型框架
1@bright
30527H更新时间:2026-02-02
ms-swift是魔搭社区提供的大模型与多模态大模型微调部署框架.
ms-swift是魔搭社区提供的大模型与多模态大模型微调部署框架.
Qwen-Image图片生成

Qwen-Image-Edit-4步采样
5@刘悦的技术博客
认证作者5059H更新时间:2026-02-02
支持自启动支持自定义Lora,AI图片编辑修改,支持反推提示词
支持自定义Lora,AI图片编辑修改,支持反推提示词
语音合成
voice-changer
5@aiguoliuguo
认证作者29714600H更新时间:2025-08-27
Voice Changer 云端在线变声器
Voice Changer 云端在线变声器
ComfyUI

ComfyUI高清4K文生图
5@AI画师大阳
认证作者91379H更新时间:2026-02-02
支持自启动ComfyUI版实现stable diffusion文生图高清放大人脸修复,直出4K
ComfyUI版实现stable diffusion文生图高清放大人脸修复,直出4K
Wan视频生成ComfyUI

WAN2.2视频生产加速套件-ComfyUI
10@AI-KSK
认证作者82176H更新时间:2026-02-02
WAN 2.2极速性能优化10工作流多任务视频生成套件
WAN 2.2极速性能优化10工作流多任务视频生成套件
数字人

MultiTalk数字人优化加速版本-无限时长-唱歌/说话数字人
5@刘悦的技术博客
认证作者1301437H更新时间:2026-02-02
支持自启动MultiTalk数字人优化加速版本-2步采样,对精度有要求修改采样数为4或者8
MultiTalk数字人优化加速版本-2步采样,对精度有要求修改采样数为4或者8
视频超分

Seed-VR2-7B,图片视频超清放大,人体细节部位放大,支持批量任务
11@刘悦的技术博客
认证作者139139H更新时间:2025-11-14
支持自启动Seed-VR2-7B,图片视频超清放大,人体细节部位放大,支持批量任务,初始化后,等待服务启动,大概2分钟,然后点击SD-WEBUI即可
Seed-VR2-7B,图片视频超清放大,人体细节部位放大,支持批量任务,初始化后,等待服务启动,大概2分钟,然后点击SD-WEBUI即可
图像编辑AI应用

ben2抠图-在线去除图片、视频背景神器,绿幕抠图神器 构建By科哥
6@鸡你太美
认证作者92143H更新时间:2026-04-27
支持自启动ben2抠图webui在线抠视频除去图片视频背景神器绿幕抠图神器 构建By科哥
ben2抠图webui在线抠视频除去图片视频背景神器绿幕抠图神器 构建By科哥
语音合成

CosyVoice界面优化版 可以粤语、普通、英语、日语、四川话、天津话、上海话等声音克隆
10@鸡你太美
认证作者216444H更新时间:2026-04-27
支持自启动CosyVoice界面优化版 可以粤语、普通、英语、日语、四川话、天津话、上海话等声音克隆
CosyVoice界面优化版 可以粤语、普通、英语、日语、四川话、天津话、上海话等声音克隆
图片编辑

DiffBIR一键图片老照片高清修复 汉化构建by科哥
7@鸡你太美
认证作者7030H更新时间:2026-04-27
支持自启动DiffBIR一键图片老照片高清修复 汉化构建by科哥
DiffBIR一键图片老照片高清修复 汉化构建by科哥
视频生成

最强人脸迁移生成视频Stand-In支持批量生成
16@与AI同行
认证作者8057H更新时间:2026-03-31
支持自启动最强人脸迁移生成视频Stand-In-支持批量生成
最强人脸迁移生成视频Stand-In-支持批量生成
数字人

HeyGem数字人加速优化版,解决多脸型报错
5@刘悦的技术博客
认证作者138410H更新时间:2025-11-14
支持自启动HeyGem数字人加速优化版,解决多脸型报错,解决没有脸报错,
HeyGem数字人加速优化版,解决多脸型报错,解决没有脸报错,
图片编辑AI应用

HYPIR一个基于扩散生成的分数进行图像恢复的应用 汉化构建By科哥
3@鸡你太美
认证作者1426H更新时间:2026-04-27
支持自启动一键进行修复图片
一键进行修复图片
AI电商

Magic-TryOn图片换装视频换装 构建by科哥
2@鸡你太美
认证作者28104H更新时间:2026-04-27
Magic-TryOn图片换装视频换装 构建by科哥
Magic-TryOn图片换装视频换装 构建by科哥
Wan视频生成

Wan2.2-图生视频-批量任务-自定义lora-自定义首尾帧
29@刘悦的技术博客
认证作者3901986H更新时间:2026-02-02
支持自启动Wan2.2-图生视频-批量任务-自定义lora-自定义首尾帧
Wan2.2-图生视频-批量任务-自定义lora-自定义首尾帧
推理框架

LlamaFactory纯净版-微调使用
7@WYSLOVE
2092881H更新时间:2025-08-12
在conda环境下仅安装了LlamaFactory,以及llama.cpp,llama.cpp未编译,可用convert.py来导出gguf模型文件
在conda环境下仅安装了LlamaFactory,以及llama.cpp,llama.cpp未编译,可用convert.py来导出gguf模型文件
数字人

RuoYI AI 二开AI数字人
4@熊猫助手
认证作者24156H更新时间:2025-08-14
基于livetalking二开,实现AI数字人功能,支持coze智能体工作流对接,功能更加强大!
基于livetalking二开,实现AI数字人功能,支持coze智能体工作流对接,功能更加强大!
视频生成

FramePack-F1 牛哥版
8@NiuGee
认证作者86249H更新时间:2026-02-02
FramePack F1 牛哥加速版
FramePack F1 牛哥加速版
SD

秋叶丹炉(Lora-Scripts)1.12
34@龙没耳
认证作者6065681H更新时间:2026-02-03
支持自启动秋叶丹炉lora-scripts1.12+Joy Caption 3原创可视化自动批量打标工具1.4版
秋叶丹炉lora-scripts1.12+Joy Caption 3原创可视化自动批量打标工具1.4版
FluxComfyUI图片生成

Flux_Krea_Flux_Dev-Loras
9@seazou
3936H更新时间:2025-08-11
Flux_Krea&Flux_Dev-loras,本镜像包含多个用于Flux的lora
Flux_Krea&Flux_Dev-loras,本镜像包含多个用于Flux的lora
Qwen-Image

Qwen-Image蒸馏加速版,批量生成,自定义Lora
4@刘悦的技术博客
认证作者78115H更新时间:2026-02-02
Qwen-Image-蒸馏加速版,支持自定义Lora,支持批量抽卡,文字生成图片
Qwen-Image-蒸馏加速版,支持自定义Lora,支持批量抽卡,文字生成图片
语音合成

MOSS TTSD + Qwen3,自动生成完整语音播客(PodCast)
13@刘悦的技术博客
认证作者119211H更新时间:2026-02-02
支持自启动MOSS-TTSD结合Qwen3-30B-A3B-Instruct-2507,自动生成完整语音播客(PodCast),初始化之后,等待服务启动,大概2分钟左右,然后点击 SD-WEBUI 按钮即可
MOSS-TTSD结合Qwen3-30B-A3B-Instruct-2507,自动生成完整语音播客(PodCast),初始化之后,等待服务启动,大概2分钟左右,然后点击 SD-WEBUI 按钮即可
数字人

EchoMimicV3
5@十字鱼
认证作者56184H更新时间:2026-02-02
EchoMimicV3:1.3B 参数即可实现统一的多模态和多任务人体动画
EchoMimicV3:1.3B 参数即可实现统一的多模态和多任务人体动画
WanLora训练

aitookit_wan21_t2v_lora_训练镜像
11@有趣的80后程序员
认证作者2042834H更新时间:2026-02-02
aitookit_wan21_t2v_lora_训练镜像,内置模型、数据集 cuda 12.6 pytorch 2.7
aitookit_wan21_t2v_lora_训练镜像,内置模型、数据集 cuda 12.6 pytorch 2.7
语音合成

mega-tts3无须官方npy文件 几秒音频克隆情感一致的声音字节开源 构建by科哥
4@鸡你太美
认证作者58436H更新时间:2026-04-27
支持自启动mega-tts3无须官方npy文件 几秒音频克隆情感一致的声音
mega-tts3无须官方npy文件 几秒音频克隆情感一致的声音
Qwen-Image图片生成ComfyUI

comfyui万物迁移,万物移除,qwen-image,kontext整合包
12@匹夫
认证作者218634H更新时间:2026-02-02
支持自启动comfyui万物迁移、万物移除、qwen-image、kontext整合包
comfyui万物迁移、万物移除、qwen-image、kontext整合包
图片生成Qwen-image

最强AI生成图片-阿里QwenImage-批量生成图片
10@与AI同行
认证作者97137H更新时间:2026-03-31
支持自启动最强AI生成图片-阿里QwenImage-批量生成图片
最强AI生成图片-阿里QwenImage-批量生成图片
视频超分

DLoRAL视频超分
2@Ikaros
1421H更新时间:2025-08-07
一步扩散实现细节丰富且时间一致的视频超分辨率
一步扩散实现细节丰富且时间一致的视频超分辨率
AI音乐

jam在线歌词生成音乐 音乐生成音乐 构建By科哥
5@鸡你太美
认证作者3713H更新时间:2026-04-27
根据歌词,原音乐创作你的音乐。
根据歌词,原音乐创作你的音乐。
数字人

HeyGem数字人加速优化版,批量任务支持唱歌数字人
28@刘悦的技术博客
认证作者474878H更新时间:2026-02-02
支持自启动HeyGem数字人加速优化版,支持唱歌数字人,批量任务, 部署后,等待服务启动,大概2分钟,然后点击 SD-WebUi
HeyGem数字人加速优化版,支持唱歌数字人,批量任务, 部署后,等待服务启动,大概2分钟,然后点击 SD-WebUi
文本模型

OpenAI-GPT-OSS-120B/20B
4@敢敢のwings
认证作者37100H更新时间:2026-02-02
OpenAI正式发布了其首个开源大语言模型系列——gpt-oss,这标志着自GPT-2以来OpenAI首次将其核心模型技术开源。
OpenAI正式发布了其首个开源大语言模型系列——gpt-oss,这标志着自GPT-2以来OpenAI首次将其核心模型技术开源。
Qwen-Image

Qwen-Image文字生成图片
7@刘悦的技术博客
认证作者117291H更新时间:2026-02-02
支持自启动Qwen-Image文生图,支持SD-WebUI和Comfyui,10步采样,在图片上精准生成汉字,支持反推提示词
Qwen-Image文生图,支持SD-WebUI和Comfyui,10步采样,在图片上精准生成汉字,支持反推提示词
AI应用
Video subtitle remover
1@如月风铃
1918H更新时间:2025-08-06
一个github上的视频硬字幕去除项目
一个github上的视频硬字幕去除项目
视频生成图片生成

星梦AI
4@星悦
认证作者2079H更新时间:2026-02-02
文生图,图片局部编辑,人物换装,图生视频,多功能文本配音,多功能数字人对口型。
文生图,图片局部编辑,人物换装,图生视频,多功能文本配音,多功能数字人对口型。
混元3D生成

混元世界大模型-v1.0
2@Ikaros
3527H更新时间:2025-08-07
HunyuanWorld 1.0 是由腾讯混元团队开发并开源的创新3D世界生成框架,它代表了计算机视觉和图形学领域的一项重大突破。该框架旨在解决现有3D世界生成方法中的局限性,通过融合基于视频的方法的多样性与基于三维几何方法的一致性,提供了一种新的解决方案1。 核心功能上,HunyuanWorld 1.0 提供了以下三大优势: 沉浸式体验:利用全景图像作为360°的世界代理,提供了全方位的沉浸式视觉体验。 工业级兼容性:支持将生成的3D场景导出为标准网格格式,可以无缝集成到现有的3D建模软件和游戏引擎中,如Blender、Unreal Engine和Unity等,增强了模型的实用性和灵活性。 增强交互性:采用解耦式的物体表示方法,实现了对场景中物体的单独编辑和交互,提高了用户的操作自由度和创造力。 在技术实现方面,HunyuanWorld 1.0 利用了先进的语义分层3D网格表征技术和两阶段生成范式,即首先通过一个特制的3D感知变分自编码器(VAE)来理解3D世界,然后使用扩散Transformer(DiT)进行创造性的3D世界构建。这种架构不仅能够从文本描述或图片输入中生成高质量的3D全景图,还能够处理复杂的场景分解与重建任务,从而确保生成世界的连贯性和细节丰富度15。 此外,HunyuanWorld 1.0 的应用场景广泛,涵盖了虚拟现实(VR)、物理仿真、游戏开发以及交互式内容创作等多个领域。其强大的功能和高度的兼容性使得它成为了推动这些行业发展的重要工具,预示着AI驱动的3D内容创作新时代的到来7。 综上所述,HunyuanWorld 1.0 不仅是一个技术上的飞跃,也是一个开启未来无限可能的关键里程碑,为创作者提供了前所未有的能力去探索和创建数字世界。
HunyuanWorld 1.0 是由腾讯混元团队开发并开源的创新3D世界生成框架,它代表了计算机视觉和图形学领域的一项重大突破。该框架旨在解决现有3D世界生成方法中的局限性,通过融合基于视频的方法的多样性与基于三维几何方法的一致性,提供了一种新的解决方案1。 核心功能上,HunyuanWorld 1.0 提供了以下三大优势: 沉浸式体验:利用全景图像作为360°的世界代理,提供了全方位的沉浸式视觉体验。 工业级兼容性:支持将生成的3D场景导出为标准网格格式,可以无缝集成到现有的3D建模软件和游戏引擎中,如Blender、Unreal Engine和Unity等,增强了模型的实用性和灵活性。 增强交互性:采用解耦式的物体表示方法,实现了对场景中物体的单独编辑和交互,提高了用户的操作自由度和创造力。 在技术实现方面,HunyuanWorld 1.0 利用了先进的语义分层3D网格表征技术和两阶段生成范式,即首先通过一个特制的3D感知变分自编码器(VAE)来理解3D世界,然后使用扩散Transformer(DiT)进行创造性的3D世界构建。这种架构不仅能够从文本描述或图片输入中生成高质量的3D全景图,还能够处理复杂的场景分解与重建任务,从而确保生成世界的连贯性和细节丰富度15。 此外,HunyuanWorld 1.0 的应用场景广泛,涵盖了虚拟现实(VR)、物理仿真、游戏开发以及交互式内容创作等多个领域。其强大的功能和高度的兼容性使得它成为了推动这些行业发展的重要工具,预示着AI驱动的3D内容创作新时代的到来7。 综上所述,HunyuanWorld 1.0 不仅是一个技术上的飞跃,也是一个开启未来无限可能的关键里程碑,为创作者提供了前所未有的能力去探索和创建数字世界。
语音合成

CosyVoice2-0.5B
6@鸡你太美
认证作者114280H更新时间:2026-04-27
支持自启动CosyVoice阿里云同义实验室开源的AI声音克隆应用
CosyVoice阿里云同义实验室开源的AI声音克隆应用
Wan视频生成ComfyUI

Wan2.2-14B-图生视频-自定义首尾帧,自定义Lora,6步采样,反推提示词
70@刘悦的技术博客
认证作者8405306H更新时间:2026-02-02
支持自启动Wan2.2-14B-图生视频-自定义首尾帧,自定义Lora,6步采样,反推提示词,初始化之后,等待服务启动,大概2分钟左右,点击SD-Webui按钮即可,上传首尾帧图片,输入提示词,点击生成即可
Wan2.2-14B-图生视频-自定义首尾帧,自定义Lora,6步采样,反推提示词,初始化之后,等待服务启动,大概2分钟左右,点击SD-Webui按钮即可,上传首尾帧图片,输入提示词,点击生成即可
ComfyUI
![ComfyUI最简搭建基座镜像[最新纯净版]](https://ucompshare-community-image.cn-wlcb.ufileos.com/66533527_64607610/compshareImage-1f6lhgte6iyt_1754311625.png)
ComfyUI最简搭建基座镜像[最新纯净版]
2@ai来事
认证作者1084H更新时间:2025-08-05
支持自启动最容易的ComfyUI搭建,最新纯净版基座镜像
最容易的ComfyUI搭建,最新纯净版基座镜像
语音合成

Step-Audio TTS在线语音克隆3B模型 构建By科哥
3@鸡你太美
认证作者2831H更新时间:2026-04-27
支持自启动Step-Audio TTS在线语音克隆3B模型 构建By科哥
Step-Audio TTS在线语音克隆3B模型 构建By科哥
AI应用

Joy Cation WebUI批量打标工具独立版
3@龙没耳
认证作者4323H更新时间:2026-02-02
支持自启动Joy Cation WebUI批量打标工具独立版
Joy Cation WebUI批量打标工具独立版
推理框架
thinking-budget-vllm010
2@不要葱姜蒜
认证作者40H更新时间:2026-02-02
使用vllm实现思考预算
使用vllm实现思考预算
语音分离

MSST-更多模型
16@我就是五字
认证作者4741132H更新时间:2025-09-05
本镜像参考了[原MSST镜像作者大大bilibili@爱过_留过]老师的模型启动方法,添加了常用的分离伴奏、人声、和声、混响、降噪等模型
本镜像参考了[原MSST镜像作者大大bilibili@爱过_留过]老师的模型启动方法,添加了常用的分离伴奏、人声、和声、混响、降噪等模型
Wan视频生成ComfyUI

wan2.2工作流合集
74@匹夫
认证作者115113033H更新时间:2025-08-05
支持自启动wan2.2-首尾帧、文生图、文生视频、图生视频、kontext、flux-krea
wan2.2-首尾帧、文生图、文生视频、图生视频、kontext、flux-krea
Wan视频生成ComfyUI
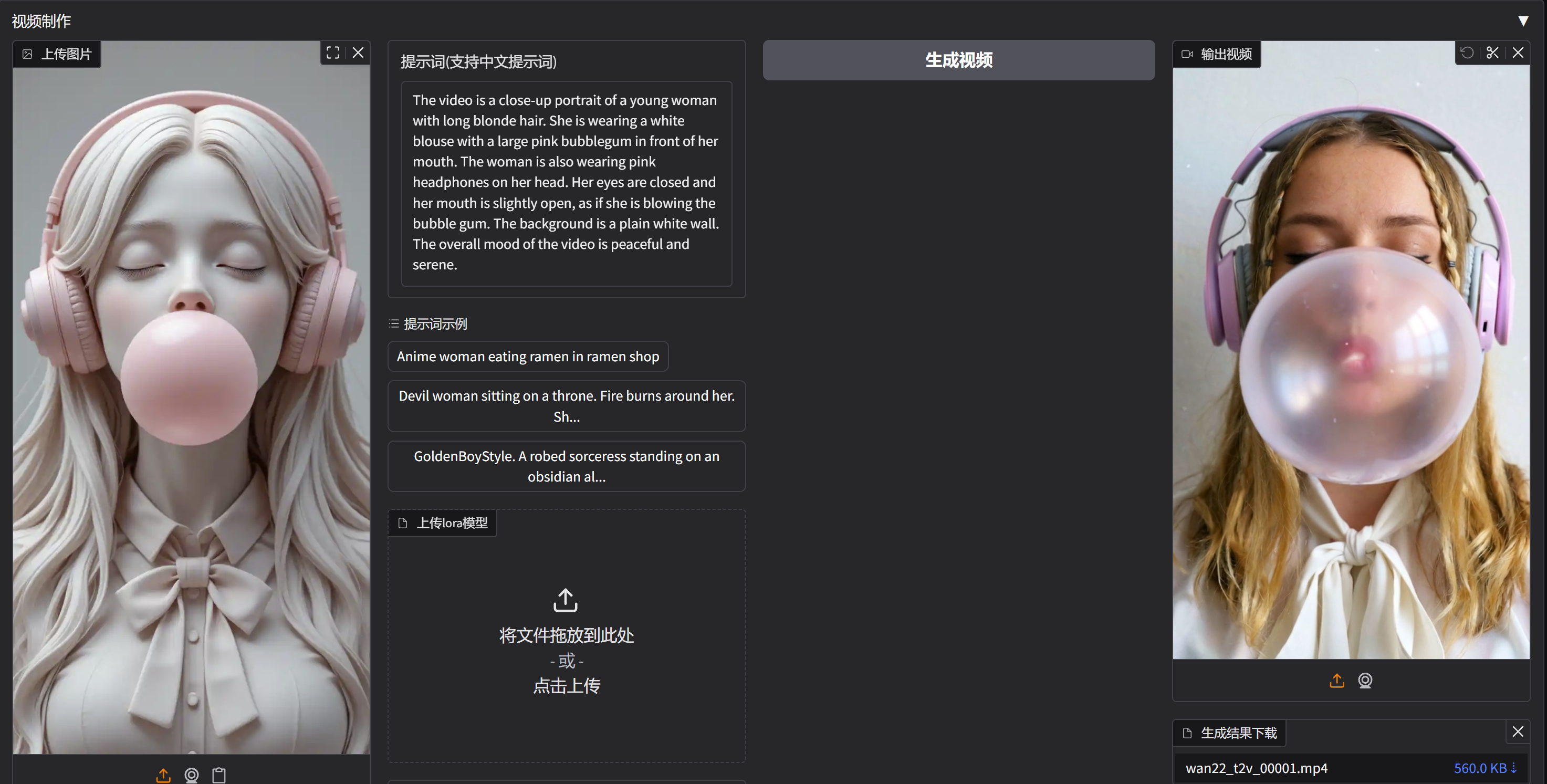
Wan2.2-14B-文生视频,自定义Lora,反推提示词,lightx2V加速,6步采样
13@刘悦的技术博客
认证作者148306H更新时间:2025-11-14
支持自启动Wan2.2-14B-文生视频,自定义Lora,反推提示词,lightx2V加速,6步采样,初始化后,等待服务启动,大概2分钟,然后点击 SD-WEBUI 按钮即可
Wan2.2-14B-文生视频,自定义Lora,反推提示词,lightx2V加速,6步采样,初始化后,等待服务启动,大概2分钟,然后点击 SD-WEBUI 按钮即可
Qwen
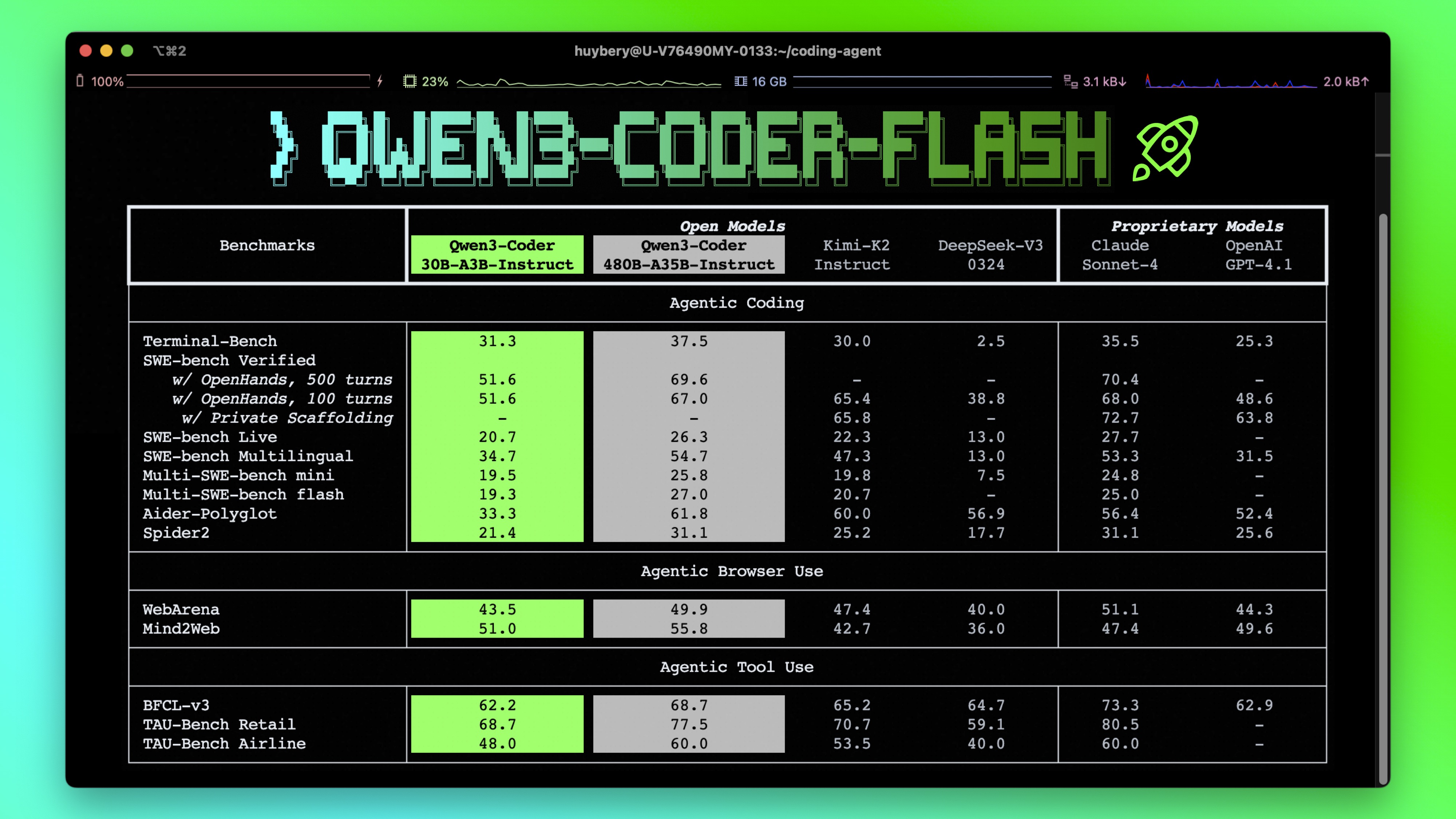
Qwen3-coder-30B-A3B
4@苍耳阿猫
认证作者3265H更新时间:2025-08-05
qwen3-coder-30B-A3B可视化使用
qwen3-coder-30B-A3B可视化使用
目标检测

Yolov13
2@alex
401594H更新时间:2025-08-01
Yolov13 版本镜像,导入可直接部署运行对应项目。 可直接运行目标检测,分割,分类等视觉任务。
Yolov13 版本镜像,导入可直接部署运行对应项目。 可直接运行目标检测,分割,分类等视觉任务。
Wan视频生成ComfyUI
Wan2.2-14B-Lightx2V加速,6步采样,自动提示词
10@刘悦的技术博客
认证作者287871H更新时间:2025-11-14
支持自启动Wan2.2-14B-Lightx2V加速,6步采样,自动提示词
Wan2.2-14B-Lightx2V加速,6步采样,自动提示词
Wan视频生成ComfyUI
Wan2.2-Diffusers
3@十字鱼
认证作者35148H更新时间:2025-07-30
Wan2.2-I2V-A14B-Diffusers + WebUI
Wan2.2-I2V-A14B-Diffusers + WebUI
文本模型GLM

self-llm-GLM-4.5-Air
1@不要葱姜蒜
认证作者37H更新时间:2025-07-29
self-llm-GLM-4.5-Air vllm LORA镜像
self-llm-GLM-4.5-Air vllm LORA镜像
Wan视频生成ComfyUI

WAN2.2-ComfyUI 开源SOTA级AI视频生成
7@AI-KSK
认证作者1371243H更新时间:2025-08-01
开源AI视频模型中的SOTA,WAN 2.2的ComfyUI实现,包含5b、14b全部模型
开源AI视频模型中的SOTA,WAN 2.2的ComfyUI实现,包含5b、14b全部模型
数字人

星悦数字人-专业版
5@星悦
认证作者52267H更新时间:2026-02-03
星悦数字人专业版,文本转语音,灵活配音,数字人对口型,灵活批量生成数字人。
星悦数字人专业版,文本转语音,灵活配音,数字人对口型,灵活批量生成数字人。
语音合成
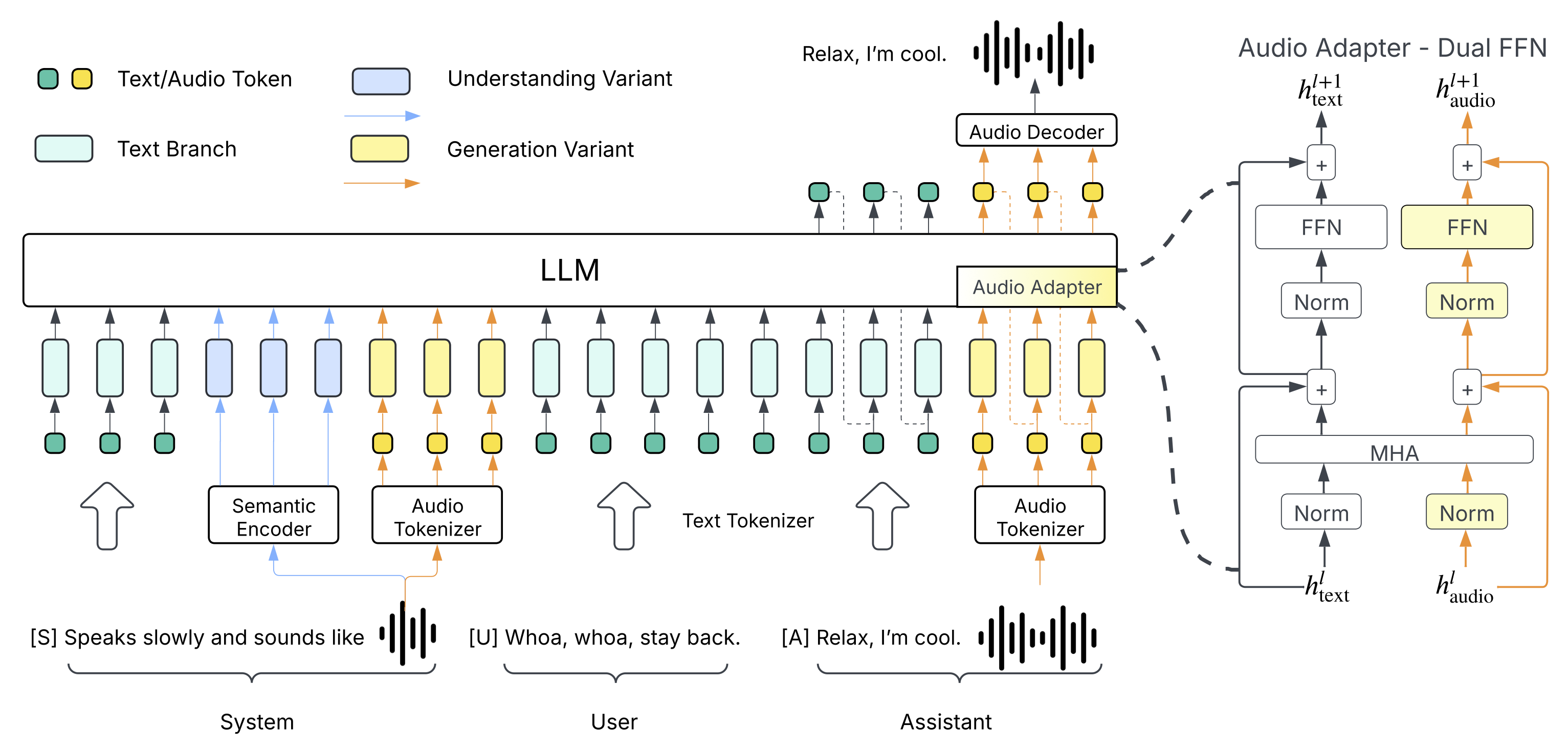
Higgs_Audio_V2
1@敢敢のwings
认证作者823H更新时间:2026-02-03
支持自启动沐神新作,不得不学
沐神新作,不得不学
ComfyUI
ComfyUI童装一键换装
8@xiaofang
3319H更新时间:2026-02-03
支持自启动本镜像基于ComfyUI平台,提供专业的童装一键换装功能,可快速、精准地替换图片中儿童的服装款式。
本镜像基于ComfyUI平台,提供专业的童装一键换装功能,可快速、精准地替换图片中儿童的服装款式。
数字人

LatentSync1.5数字人视频制作v1.5.3
7@鸡你太美
认证作者185533H更新时间:2026-04-27
支持自启动LatentSync1.5是字节跳动2025年3月开源的端到端唇形同步框架,基于潜在扩散模型,仅用6 GB显存即可将任意音频驱动成高分辨率、时序连贯的中文说话视频
LatentSync1.5是字节跳动2025年3月开源的端到端唇形同步框架,基于潜在扩散模型,仅用6 GB显存即可将任意音频驱动成高分辨率、时序连贯的中文说话视频
IndexTTS语音合成
index-tts
7@十字鱼
认证作者137378H更新时间:2026-02-03
B站开源工业级可控高效语音克隆
B站开源工业级可控高效语音克隆
语音合成

Srt-AI-Voice-Assistant+GPT-SoVITS-2506(V2Pro)
5@数列解析几何一生之敌
认证作者1523524H更新时间:2026-02-03
支持自启动Srt-AI-Voice-Assistant配音辅助工具搭配GSV的镜像
Srt-AI-Voice-Assistant配音辅助工具搭配GSV的镜像
FluxLora训练

ai-tookit-lora-train
4@有趣的80后程序员
认证作者1821543H更新时间:2026-02-03
aitookit lora 训练镜像-包含flux kontext 模型与数据集
aitookit lora 训练镜像-包含flux kontext 模型与数据集
AI应用ChatBot

AstrBot
2@AstrBotDevs
认证作者45961H更新时间:2025-07-31
AstrBot 是一个支持 QQ、微信、飞书等多消息平台部署、具有易用的插件系统和完善的大语言模型(LLM)接入功能的聊天机器人及开发框架。
AstrBot 是一个支持 QQ、微信、飞书等多消息平台部署、具有易用的插件系统和完善的大语言模型(LLM)接入功能的聊天机器人及开发框架。
SD

Forge WebUI大镜像
10@龙没耳
认证作者1571517H更新时间:2026-02-03
Forge WebUI大镜像
Forge WebUI大镜像
语音合成

vits-simple-api
5@Artrajz
认证作者191505H更新时间:2026-02-03
vits-simple-api语音合成推理服务,支持vits、hubert-vits、w2v2-vits、bert-vits2、gpt-sovits
vits-simple-api语音合成推理服务,支持vits、hubert-vits、w2v2-vits、bert-vits2、gpt-sovits
数字人ComfyUI

最强图片数字人Multitalk唱歌说话(支持长视频)
21@与AI同行
认证作者3812099H更新时间:2026-03-31
支持自启动最强的图片数字人,支持唱歌、说话,效果超强!
最强的图片数字人,支持唱歌、说话,效果超强!
数字人

musetalk1.5音频驱动视频生成数字人汉化webUI版 构建By科哥
10@鸡你太美
认证作者165588H更新时间:2026-04-27
支持自启动musetalk1.5音频驱动视频生成数字人汉化webUI版 构建By科哥
musetalk1.5音频驱动视频生成数字人汉化webUI版 构建By科哥
IndexTTS语音合成

index-tts-api-v1.5-ap在线推理服务deepspeed加速版
3@鸡你太美
认证作者5142H更新时间:2026-04-27
index-tts-api-v1.5 在线推理服务deepspeed加速版封装,支持自行调用API
index-tts-api-v1.5 在线推理服务deepspeed加速版封装,支持自行调用API
数字人
MuseTalk
6@有黑眼圈的小竹能
238638H更新时间:2026-02-03
MuseTalk数字人模型,建议选择显存48G及以上的GPU
MuseTalk数字人模型,建议选择显存48G及以上的GPU
语音识别

ASR大集合-V1.0
3@Ikaros
39301H更新时间:2026-02-03
搜集主流的开源ASR项目,提供api接口或webui页面完成ASR工作。
搜集主流的开源ASR项目,提供api接口或webui页面完成ASR工作。
语音合成

MOSS-TTSD邱锡鹏团队开源最新百万小时训练声音推理模型声音克隆 构建By科哥
2@鸡你太美
认证作者8499H更新时间:2026-04-27
支持自启动MOSS-TTSD邱锡鹏团队开源最新百万小时训练声音推理模型声音克隆 构建By科哥
MOSS-TTSD邱锡鹏团队开源最新百万小时训练声音推理模型声音克隆 构建By科哥
文本模型ChatBot

LangBot
1@LangBotTeam
认证作者517H更新时间:2026-02-03
简单易用的大模型即时通信机器人开发平台,支持 QQ 微信 企微 飞书 钉钉 等多种平台,已配置好 Ollama DeepSeek 模型
简单易用的大模型即时通信机器人开发平台,支持 QQ 微信 企微 飞书 钉钉 等多种平台,已配置好 Ollama DeepSeek 模型
SDLora训练

lora-scripts
15@Faych
1741112H更新时间:2025-07-04
lora-scripts镜像提供轻量级LoRA训练套件,集成Kohya_ss训练器与WebUI界面,支持一键式模型微调、数据集预处理及参数可视化,简化Stable Diffusion衍生模型的定制流程,开箱即用。
lora-scripts镜像提供轻量级LoRA训练套件,集成Kohya_ss训练器与WebUI界面,支持一键式模型微调、数据集预处理及参数可视化,简化Stable Diffusion衍生模型的定制流程,开箱即用。
数字人

Latentsync1.6最新牛哥魔改版本
23@NiuGee
认证作者423187579H更新时间:2026-02-03
牛哥专属调教版本: 开机即用 默认授权码9259 做了队列限制,多人排队,默认依次执行
牛哥专属调教版本: 开机即用 默认授权码9259 做了队列限制,多人排队,默认依次执行
Flux图片生成

Kontext-Nunchaku极速修图(含基础工作流)
5@ai来事
认证作者95225H更新时间:2026-02-03
支持自启动Kontext-Nunchaku 是一款结合了 FLUX.1 Kontext 图像编辑模型与 Nunchaku 高性能推理加速引擎的工具。
Kontext-Nunchaku 是一款结合了 FLUX.1 Kontext 图像编辑模型与 Nunchaku 高性能推理加速引擎的工具。
FluxComfyUI图片生成

ComfyUI_nunchaku 双节棍极速搓图
1@ai来事
认证作者6194H更新时间:2026-02-03
支持自启动comfyui+nunchaku极速出图、改图!
comfyui+nunchaku极速出图、改图!
FluxComfyUI图片生成

Flux-kontext & Nunchaku急速高清修复工作流
9@匹夫
认证作者3692175H更新时间:2025-07-07
Flux-kontext & Nunchaku急速高清修复工作流
Flux-kontext & Nunchaku急速高清修复工作流
FluxComfyUI图片生成

Kontext-ComfyUI-多种玩法合集
5@AI-KSK
认证作者6368H更新时间:2025-07-29
开源的SOTA级图像编辑模型的多种应用
开源的SOTA级图像编辑模型的多种应用
FluxComfyUI图片生成

comfyui_Kontext_Dev
3@ai来事
认证作者57445H更新时间:2026-02-03
最强大的图片编辑模型,支持基础修改、风格转换、角色一致性、文本编辑
最强大的图片编辑模型,支持基础修改、风格转换、角色一致性、文本编辑
Flux图片生成

FLUX.1-Kontext-dev
4@十字鱼
认证作者151271H更新时间:2025-07-14
FLUX.1-Kontext-dev是Black Forest Labs开源的120亿参数图像编辑模型,基于文本指令修改图片,支持角色、风格、物体引用,无需微调即可多步编辑,训练效率高
FLUX.1-Kontext-dev是Black Forest Labs开源的120亿参数图像编辑模型,基于文本指令修改图片,支持角色、风格、物体引用,无需微调即可多步编辑,训练效率高
语音合成
voice-changer
2@skl
认证作者2521233H更新时间:2026-02-03
Voice-Changer(VCClient)是 w-okada 开源的跨平台实时 AI 变声器,内置 RVC、Beatrice v2、MMVC、DDSP-SVC 等主流模型
Voice-Changer(VCClient)是 w-okada 开源的跨平台实时 AI 变声器,内置 RVC、Beatrice v2、MMVC、DDSP-SVC 等主流模型
语音合成数字人

multitalk数字人-indextts语音克隆工作流
16@匹夫
认证作者320862H更新时间:2026-02-03
镜像集成了multitalk数字人工作流与indextts语音克隆工作流
镜像集成了multitalk数字人工作流与indextts语音克隆工作流
IndexTTS语音合成

index-tts在线api声音克隆快速声音生成api服务用于听小说语音直播等
1@鸡你太美
认证作者120737H更新时间:2026-04-27
index-tts在线api声音克隆快速声音生成api服务用于听小说语音直播等
index-tts在线api声音克隆快速声音生成api服务用于听小说语音直播等
Wan视频生成

6-20更新-大凯智障君VACE/FusionX专属AI视频镜像
5@大凯智障君
认证作者111480H更新时间:2026-02-03
WAN 2.1-人脸追踪-工作流概述 VACE14B-T2V + Causvid 加速 - comfyUI精品课程 > 对应课程的更新镜像版本,更新了模型和实用的自定义节点。
WAN 2.1-人脸追踪-工作流概述 VACE14B-T2V + Causvid 加速 - comfyUI精品课程 > 对应课程的更新镜像版本,更新了模型和实用的自定义节点。
Hunyuan

Hunyuan3D-2.1
1@苍耳阿猫
认证作者44217H更新时间:2026-02-12
Hunyuan3D-2.1是腾讯开源的3D生成大模型,支持文本、图片、草图输入,生成高精度PBR材质与几何模型,加速游戏、影视、工业设计等领域3D资产创建,推动3D生成技术发展
Hunyuan3D-2.1是腾讯开源的3D生成大模型,支持文本、图片、草图输入,生成高精度PBR材质与几何模型,加速游戏、影视、工业设计等领域3D资产创建,推动3D生成技术发展
3D生成
PartPacker
1@十字鱼
认证作者3058H更新时间:2025-07-14
单图生成零件级3D模型-PartPacker是 NVIDIA 开源的单视图零件级 3D 对象生成框架,通过“双体素打包”将整体与部件隐式编码解耦
单图生成零件级3D模型-PartPacker是 NVIDIA 开源的单视图零件级 3D 对象生成框架,通过“双体素打包”将整体与部件隐式编码解耦
AI应用

n8n
3@敢敢のwings
认证作者1755H更新时间:2026-02-03
n8n 是一个工作流自动化平台,为技术团队提供代码的灵活性和无代码的速度。拥有 400+ 集成、原生 AI 功能和公平代码许可证,n8n 让您构建强大的自动化,同时保持对数据和部署的完全控制。
n8n 是一个工作流自动化平台,为技术团队提供代码的灵活性和无代码的速度。拥有 400+ 集成、原生 AI 功能和公平代码许可证,n8n 让您构建强大的自动化,同时保持对数据和部署的完全控制。
Flux视频生成

大凯智障君-VACE / FusionX 专属AI视频镜像
3@大凯智障君
认证作者90454H更新时间:2025-07-03
大凯智障君-VACE / FusionX 专属AI视频镜像:包含Flux文生图高清放大、VACE模型视频创作流程、FusionX模型的图生视频、文生视频、视频转视频等最新的comfyUI工作流,我会定期更新本教学镜像,欢迎大家学习和测试使用。
大凯智障君-VACE / FusionX 专属AI视频镜像:包含Flux文生图高清放大、VACE模型视频创作流程、FusionX模型的图生视频、文生视频、视频转视频等最新的comfyUI工作流,我会定期更新本教学镜像,欢迎大家学习和测试使用。
AI音乐

SongGeneration
0@Smzh
认证作者1342H更新时间:2026-02-03
tencent-ailab旗下的SongGeneration项目,目前只有base模型
tencent-ailab旗下的SongGeneration项目,目前只有base模型
语音合成

Voila-语音语言模型
0@敢敢のwings
认证作者166H更新时间:2026-02-03
Voila是一个超越人类反应速度的开源语音大模型,专为实时情感对话而设计。作采用端到端架构,实现了195ms超快响应,支持百万音色和10秒声音克隆,是构建有温度AI语音交互系统的理想选择。
Voila是一个超越人类反应速度的开源语音大模型,专为实时情感对话而设计。作采用端到端架构,实现了195ms超快响应,支持百万音色和10秒声音克隆,是构建有温度AI语音交互系统的理想选择。
推理框架其他

Langchain-Chatchat
0@BhAem
77H更新时间:2026-02-03
Langchain-Chatchat 是一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案
Langchain-Chatchat 是一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案
具身智能
v-jepa2
0@敢敢のwings
认证作者322H更新时间:2026-02-03
V-JEPA 2是Meta AI在世界模型构建领域的重大突破,这是一个能够像人类一样理解、预测和规划的自监督视频模型
V-JEPA 2是Meta AI在世界模型构建领域的重大突破,这是一个能够像人类一样理解、预测和规划的自监督视频模型
ComfyUI

Comfyui热门工作流
51@匹夫
认证作者15129089H更新时间:2026-02-03
最新版comfyui,集成了360旋转工作流,WAN2.1视频转绘工作流,和图片重绘、flux-kontex工作流
最新版comfyui,集成了360旋转工作流,WAN2.1视频转绘工作流,和图片重绘、flux-kontex工作流
语音合成

GPT-Sovits_V4
89@红血球AE3803
认证作者311820763H更新时间:2026-01-30
GPT-SoVITS V4 是 RVC-Boss 开源的极致低门槛 TTS/变声器,仅需 1 分钟干声即可训练高相似音色,支持中英日韩粤五语种零样本与跨语言推理
GPT-SoVITS V4 是 RVC-Boss 开源的极致低门槛 TTS/变声器,仅需 1 分钟干声即可训练高相似音色,支持中英日韩粤五语种零样本与跨语言推理
FluxLora训练

FluxGym
19@匹夫
认证作者5331775H更新时间:2025-08-01
最简单的lora制作工具,三步让你制作出自己的lora
最简单的lora制作工具,三步让你制作出自己的lora
推理框架其他

TabbyAPI
1@Smzh
认证作者497H更新时间:2026-02-03
TabbyAPI 是 ExLlamaV2 官方开源的高性能文本生成服务器,OpenAI 兼容、轻量极速,支持 Exl2/GPTQ/FP16 模型,内置并发批处理、LoRA 热插、工具调用与草稿推测解码
TabbyAPI 是 ExLlamaV2 官方开源的高性能文本生成服务器,OpenAI 兼容、轻量极速,支持 Exl2/GPTQ/FP16 模型,内置并发批处理、LoRA 热插、工具调用与草稿推测解码
文本模型

Text-Generation-Webui
2@Smzh
认证作者131143H更新时间:2026-02-03
Text-Generation-Webui大语言模型综合终端。
Text-Generation-Webui大语言模型综合终端。
Wan视频生成

Wan2.1-AI视频创作多功能合集
3@AI-KSK
认证作者195843H更新时间:2026-02-03
这是一套强大的AI视频生成工具包,支持文生视频、图生视频,具备动作、镜头、参考图等高级控制功能,并可进行首尾特效、风格转绘、数字人生成等后期处理。
这是一套强大的AI视频生成工具包,支持文生视频、图生视频,具备动作、镜头、参考图等高级控制功能,并可进行首尾特效、风格转绘、数字人生成等后期处理。
Wan视频生成ComfyUI

ComfyUI-WAN-AI视频
2@Hugo
认证作者61396H更新时间:2026-02-03
支持自启动Wan2.1模型的文生视频、图生视频、首尾帧过渡动画体验镜像
Wan2.1模型的文生视频、图生视频、首尾帧过渡动画体验镜像
AI应用ChatBot

吟惋兮-自动部署本地QQ机器人
0@吟惋兮
认证作者532272H更新时间:2025-07-04
一键部署AstrBot+NapCat+Ollama,兼容所有nv显卡
当廉价的喜欢布满街道
纯粹的爱意显得弱不禁风
一键部署AstrBot+NapCat+Ollama,兼容所有nv显卡
当廉价的喜欢布满街道
纯粹的爱意显得弱不禁风
DeepSeek

DeepSeek-R1-0528-Qwen3-8B
4@苍耳阿猫
认证作者72332H更新时间:2025-07-14
DeepSeek R1 模型进行了小版本升级,当前版本为 DeepSeek-R1-0528。在最新的更新中,DeepSeek R1 通过利用增加的计算资源并在后训练期间引入算法优化机制,显著提高了其推理和推理能力的深度。
DeepSeek R1 模型进行了小版本升级,当前版本为 DeepSeek-R1-0528。在最新的更新中,DeepSeek R1 通过利用增加的计算资源并在后训练期间引入算法优化机制,显著提高了其推理和推理能力的深度。
图片生成

Niugee-HiDream-I1
7@NiuGee
认证作者4462H更新时间:2026-02-03
支持自启动使用Hidream,一次性生成一批图片
使用Hidream,一次性生成一批图片
IndexTTS语音合成

Index-TTS
0@鸡你太美
认证作者104372H更新时间:2026-04-27
index-tts来自B站的一个工业级别的声音克隆应用
index-tts来自B站的一个工业级别的声音克隆应用
数字人

HeyGem-Linux-Python-Hack-v1.0.2
4@鸡你太美
认证作者2051516H更新时间:2026-04-27
支持自启动HeyGem的docker免费离线版本,你只需要Python和Linux!
HeyGem的docker免费离线版本,你只需要Python和Linux!
语音合成

F5-TTS
2@鸡你太美
认证作者63320H更新时间:2026-04-27
支持自启动F5-TTS 是由上海交通大学、剑桥大学和吉利汽车于 2024 年共同开源的一款高性能文本到语音系统,它基于流匹配的非自回归生成方法,结合了扩散变换器技术。
F5-TTS 是由上海交通大学、剑桥大学和吉利汽车于 2024 年共同开源的一款高性能文本到语音系统,它基于流匹配的非自回归生成方法,结合了扩散变换器技术。
语音合成
Voice-Changer
2@icecoins
认证作者1422962H更新时间:2026-02-03
Voice-Changer 云端在线变声器。
Voice-Changer 云端在线变声器。
图片生成

HiDream-I1
0@苍耳阿猫
认证作者1714H更新时间:2026-02-03
HiDream-I1是一种新的开源图像生成基础模型,具有 17B 参数,可在几秒钟内实现最先进的图像生成质量。
HiDream-I1是一种新的开源图像生成基础模型,具有 17B 参数,可在几秒钟内实现最先进的图像生成质量。
Qwen文本模型

LLaMAFactory-0.9.3.dev-Qwen3-8B
7@llamafactory_cn
认证作者1645687H更新时间:2026-02-04
本镜像基于 LLaMA-Factory 框架,支持在多张 4090 GPU 上进行模型微调。
本镜像基于 LLaMA-Factory 框架,支持在多张 4090 GPU 上进行模型微调。
生物信息

Alphafold3
2@
15159H更新时间:2025-09-18
Alphafold3基础镜像,无MSA所需的数据库,无模型权重文件,需要自行下载
Alphafold3基础镜像,无MSA所需的数据库,无模型权重文件,需要自行下载
Wan视频生成ComfyUI

AI视频生成-ComfyUI-Wan2.1-多功能大合集
15@AI-KSK
认证作者314960H更新时间:2025-08-31
这是一套强大的AI视频生成工具包,支持文生视频、图生视频,具备动作、镜头、参考图等高级控制功能,并可进行首尾特效、风格转绘、数字人生成等后期处理。
这是一套强大的AI视频生成工具包,支持文生视频、图生视频,具备动作、镜头、参考图等高级控制功能,并可进行首尾特效、风格转绘、数字人生成等后期处理。
语音合成

gpt-sovits-v4
8@39c5bb
认证作者3334084H更新时间:2026-02-04
GPT-SoVITS,已更新V4,[优先使用较新镜像],所需素材少,训练耗时短,情绪较可控。已打包好整个流程所需的所有环境,开箱即用。
GPT-SoVITS,已更新V4,[优先使用较新镜像],所需素材少,训练耗时短,情绪较可控。已打包好整个流程所需的所有环境,开箱即用。
ComfyUI

三面ComfyUI
1@三面君
认证作者246441H更新时间:2026-02-04
支持自启动三面ComfyUI,400GB精选模型 + 105个常用节点
三面ComfyUI,400GB精选模型 + 105个常用节点
官方镜像Qwen文本模型

Qwen3-vLLM-Series
8@优云智算
2421607H更新时间:2025-07-03
Qwen3系列模型,单卡4090推荐0.6B-8B模型,2卡推荐14B模型,4卡推荐32B模型
Qwen3系列模型,单卡4090推荐0.6B-8B模型,2卡推荐14B模型,4卡推荐32B模型
WanLora训练

Wan2.1-Lora训练
1@麻雀
2646H更新时间:2026-02-04
WAN2.1-lora训练包,基于kohya的musubi-tuner和TTP大佬的gui,我增加了tensorboard功能,希望能够帮助到大家!共建wan视频生态。
WAN2.1-lora训练包,基于kohya的musubi-tuner和TTP大佬的gui,我增加了tensorboard功能,希望能够帮助到大家!共建wan视频生态。
Qwen文本模型

Qwen3-Ollama-Series
2@苍耳阿猫
认证作者57287H更新时间:2025-07-14
Qwen3-0.6B-235B量化模型,支持OpenWebUI。Qwen3-0.6B-235B 是通义千问开源的完整量化模型矩阵,覆盖 0.6B-235B 共 8 个规模(含 MoE 235B-A22B 旗舰),均已 AWQ/FP8/GGUF 量化
Qwen3-0.6B-235B量化模型,支持OpenWebUI。Qwen3-0.6B-235B 是通义千问开源的完整量化模型矩阵,覆盖 0.6B-235B 共 8 个规模(含 MoE 235B-A22B 旗舰),均已 AWQ/FP8/GGUF 量化
视频生成

FramePack图生视频
2@xiaoxu
104306H更新时间:2026-02-04
FramePack 是 lllyasviel 开源的“下一帧预测”视频扩散框架
FramePack 是 lllyasviel 开源的“下一帧预测”视频扩散框架
数字人

DeepFaceLab训练环境dfl训练linux环境v1.0
8@鸡你太美
认证作者60317H更新时间:2026-04-27
DeepFaceLab训练环境dfl训练linux环境v1.0
DeepFaceLab训练环境dfl训练linux环境v1.0
数字人

Heygem数字人WebUI轻量版 By科哥
7@鸡你太美
认证作者3741119H更新时间:2026-04-27
支持自启动Heygem数字人WebUI轻量版视频生成数字人克隆对口型音频驱动视频构建By科哥
Heygem数字人WebUI轻量版视频生成数字人克隆对口型音频驱动视频构建By科哥
ComfyUI

ComfyUI-v0.3.26+JoyCaption2
0@龙没耳
认证作者82610H更新时间:2026-02-04
ComfyUI-v0.3.26+JoyCaption2 集成包开箱即用,已预装 ComfyUI-v0.3.26 及 JoyCaption2 反推节点,支持图生文、批量打标、中文语义优化
ComfyUI-v0.3.26+JoyCaption2 集成包开箱即用,已预装 ComfyUI-v0.3.26 及 JoyCaption2 反推节点,支持图生文、批量打标、中文语义优化
数字人

HeyGem-lite
4@优云智算
7472H更新时间:-
HeyGem镜像使用教程,HeyGem是由Duix.com开发的免费开源 AI 头像项目。
HeyGem镜像使用教程,HeyGem是由Duix.com开发的免费开源 AI 头像项目。
推理框架

LLaMA-Factory-YingHuoAI
13@萤火君
2274028H更新时间:2026-02-04
LLaMA-Factory(v0.9.2)大模型训练环境,内置WebUI启动器和API启动器,以及常用的6B、7B、8B、9B模型。
LLaMA-Factory(v0.9.2)大模型训练环境,内置WebUI启动器和API启动器,以及常用的6B、7B、8B、9B模型。
官方镜像Qwen

Qwen-vLLM-Series
3@优云智算
982742H更新时间:2026-02-04
包含Qwen2.5-VL多模态、QWQ-32B两个模型,并带有WebUI界面,立即部署即可快速使用
包含Qwen2.5-VL多模态、QWQ-32B两个模型,并带有WebUI界面,立即部署即可快速使用
Qwen文本模型

Qwen2.5-Omni
0@苍耳阿猫
认证作者2391H更新时间:2026-02-04
Qwen 2.5-Omni是一个端到端的多模态大语言模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式的方式生成文本和自然语音响应,该镜像推荐使用单卡A100
Qwen 2.5-Omni是一个端到端的多模态大语言模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式的方式生成文本和自然语音响应,该镜像推荐使用单卡A100
文本模型

gemma3
1@Coderabo
认证作者2218H更新时间:2026-02-04
Google发布的Gemma_3全系列模型
Google发布的Gemma_3全系列模型
具身智能
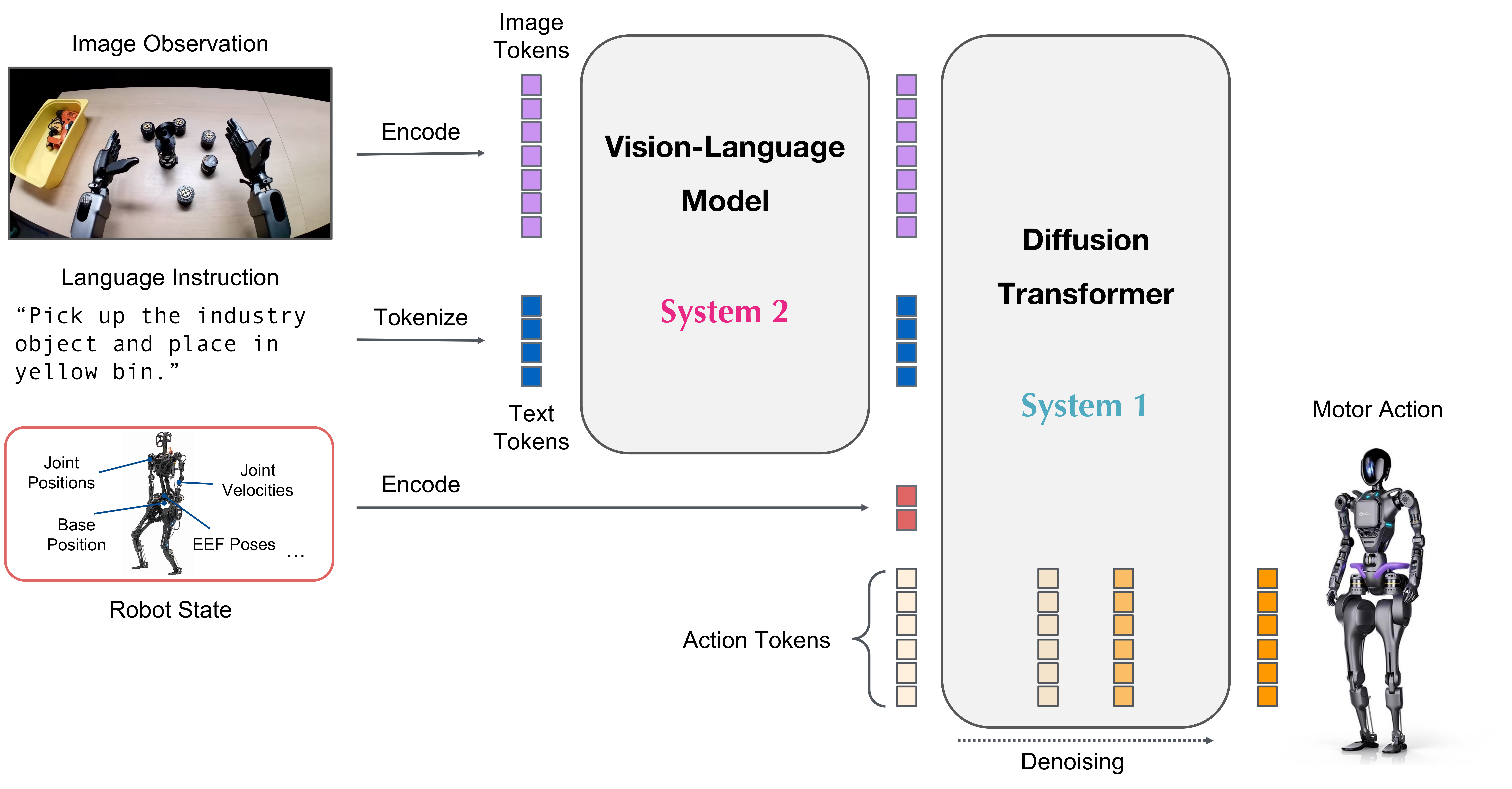
GR00T-NIVIDIA
0@敢敢のwings
认证作者33278H更新时间:2025-07-28
NVIDIA Isaac GR00T N1是全球首个用于通用人形机器人推理和技能的开源基础模型。
NVIDIA Isaac GR00T N1是全球首个用于通用人形机器人推理和技能的开源基础模型。
混元3D生成

hunyuan3D-2
2@苍耳阿猫
认证作者4550H更新时间:2025-07-14
混元 3D 2.0 是一款先进的大规模 3D 资产创作系统,它可以用于生成带有高分辨率纹理贴图的高保真度3D模型。该系统包含两个基础组件:一个大规模几何生成模型 — 混元 3D-DiT,以及一个大规模纹理生成模型 — 混元 3D-Paint
混元 3D 2.0 是一款先进的大规模 3D 资产创作系统,它可以用于生成带有高分辨率纹理贴图的高保真度3D模型。该系统包含两个基础组件:一个大规模几何生成模型 — 混元 3D-DiT,以及一个大规模纹理生成模型 — 混元 3D-Paint
混元3D生成

Hunyuan3D-2.0
0@39c5bb
认证作者2729H更新时间:2025-07-01
腾讯混元3d生成模型,自带环境,开箱即用
腾讯混元3d生成模型,自带环境,开箱即用
文本模型

Ollama-Gemma 3
1@苍耳阿猫
认证作者74128H更新时间:2026-02-04
Gemma 3 是谷歌最新推出的开源轻量级多模态模型
Gemma 3 是谷歌最新推出的开源轻量级多模态模型
ComfyUI

ComfyUI-v0.3.26
3@龙没耳
认证作者290508H更新时间:2026-02-04
ComfyUI-v0.3.26,预装了ComfyUI相关常用插件,点击立即部署开箱即用,快速体验
ComfyUI-v0.3.26,预装了ComfyUI相关常用插件,点击立即部署开箱即用,快速体验
Wan视频生成ComfyUI

ComfyUI-Wanx-I2V
1@Faych
151468H更新时间:2025-07-14
ComfyUI-Wanx-I2V是社区为阿里开源视频模型 Wan2.1 定制的 ComfyUI 原生图生视频工作流节点包,一键运行wanx i2v
ComfyUI-Wanx-I2V是社区为阿里开源视频模型 Wan2.1 定制的 ComfyUI 原生图生视频工作流节点包,一键运行wanx i2v
语音合成

GPT-SoVITS-V3
4@39c5bb
认证作者296102H更新时间:2025-07-10
GPT-SoVITS,已更新V3,[优先使用较新镜像],所需素材少,训练耗时短,情绪较可控。已打包好整个流程所需的所有环境,开箱即用。
GPT-SoVITS,已更新V3,[优先使用较新镜像],所需素材少,训练耗时短,情绪较可控。已打包好整个流程所需的所有环境,开箱即用。
Qwen文本模型

QwQ-32B-深度思考满血版
1@敢敢のwings
认证作者3325H更新时间:2026-02-04
QwQ-32B基于Qwen2.5-32B,并通过强化学习(RL)进行进一步优化。
QwQ-32B基于Qwen2.5-32B,并通过强化学习(RL)进行进一步优化。
Qwen文本模型

QwQ-32B-GGUF
1@苍耳阿猫
认证作者4451H更新时间:2026-02-04
QwQ-32B 是一个中等规模的推理模型,其性能可以与最先进的推理模型相媲美,例如 DeepSeek-R1、o1-mini
QwQ-32B 是一个中等规模的推理模型,其性能可以与最先进的推理模型相媲美,例如 DeepSeek-R1、o1-mini
数字人

LivePortrait
2@windsing
103151H更新时间:2026-02-04
LivePortrait是由快手科技、中国科学技术大学和复旦大学联合开发的一个项目,旨在将驱动视频的表情和姿态迁移到静态或动态人像视频上,生成极具表现力的视频结果
LivePortrait是由快手科技、中国科学技术大学和复旦大学联合开发的一个项目,旨在将驱动视频的表情和姿态迁移到静态或动态人像视频上,生成极具表现力的视频结果
Lora训练

Koyha-ss Lora训练
1@windsing
48421H更新时间:2026-02-04
Koyha_ss项目使用了gradio对lora的训练任务进行了封装,提供了可视化交互界面,通过交互界面,可以方面修改训练参数的配置,对小白更加友好。
Koyha_ss项目使用了gradio对lora的训练任务进行了封装,提供了可视化交互界面,通过交互界面,可以方面修改训练参数的配置,对小白更加友好。
Wan视频生成

Wan2.1-T2V-1.3B
0@Alex
认证作者1347H更新时间:2026-02-04
Wan2.1-T2V-1.3B是阿里开源的极速版文本到视频扩散模型,仅13亿参数,支持中英文动态文字与复杂运动场景
Wan2.1-T2V-1.3B是阿里开源的极速版文本到视频扩散模型,仅13亿参数,支持中英文动态文字与复杂运动场景
数字人

marketing_creator_pro_max
3@
115294H更新时间:2026-02-04
数字人成品项目包含数字人克隆、声音克隆、短视频生成、直播(待发布)、AI配音、AI字幕,包括Windows安装版,Web版,H5版,小程序版,副业必备
数字人成品项目包含数字人克隆、声音克隆、短视频生成、直播(待发布)、AI配音、AI字幕,包括Windows安装版,Web版,H5版,小程序版,副业必备
Wan视频生成

Wan2.1-WebUI
1@苍耳阿猫
认证作者63184H更新时间:2026-02-04
Wan2.1-WebUI是阿里通义开源视频大模型Wan-2.1的浏览器操作界面,已内置1.3B与14B双精度模型,支持文本/图像一键生成高清视频,提供实时预览、批量脚本与LoRA扩展
Wan2.1-WebUI是阿里通义开源视频大模型Wan-2.1的浏览器操作界面,已内置1.3B与14B双精度模型,支持文本/图像一键生成高清视频,提供实时预览、批量脚本与LoRA扩展
Wan视频生成ComfyUI

ComfyUI-Wan2.1
3@O_O
11037H更新时间:2026-02-04
阿里推出的视频生成模型,效果媲美商用模型,ComfyUI-Wan2.1镜像集成定制化高级图像生成工作流套件,开箱即用
阿里推出的视频生成模型,效果媲美商用模型,ComfyUI-Wan2.1镜像集成定制化高级图像生成工作流套件,开箱即用
推理框架

ollama
1@Faych
74139H更新时间:2025-07-14
Ollama镜像提供轻量级大语言模型本地运行框架,支持-R1 (7B/4.7GB)、Llama3.3 一键拉取与运行包括但不限于以下模型:DeepSeek、Llama3.2 、Phi4 、Gemma2:2b 、Mistral
Ollama镜像提供轻量级大语言模型本地运行框架,支持-R1 (7B/4.7GB)、Llama3.3 一键拉取与运行包括但不限于以下模型:DeepSeek、Llama3.2 、Phi4 、Gemma2:2b 、Mistral
推理框架

SPO-自监督提示优化
0@Airmomo
认证作者4374H更新时间:2025-02-27
基于大语言模型自监督能力的提示优化框架,SPO通过对比不同提示生成的输出质量,自主完成优化迭代。
基于大语言模型自监督能力的提示优化框架,SPO通过对比不同提示生成的输出质量,自主完成优化迭代。
推理框架

xinference_GPU
0@
42281H更新时间:2025-07-14
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种AI 模型的运行和集成。 借助Xinference,可以使用任何开源LLM、Embedding模型和Rerank模型在云端或本地环境中运行推理
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种AI 模型的运行和集成。 借助Xinference,可以使用任何开源LLM、Embedding模型和Rerank模型在云端或本地环境中运行推理
语音合成

Zonos-v0.1
1@HelloGitHub
2015H更新时间:2025-09-09
Zonos 是一款由 Zyphra 开发的先进开源文本到语音(TTS)模型,基于超过 20 万小时的多语言语音数据训练而成。
Zonos 是一款由 Zyphra 开发的先进开源文本到语音(TTS)模型,基于超过 20 万小时的多语言语音数据训练而成。
语音合成

RVC
124@aiguoliuguo
认证作者948936781H更新时间:2026-04-18
AI翻唱+语音变声器:RVC语音转换训练推理用WebUI,3分钟极速训练新模型
AI翻唱+语音变声器:RVC语音转换训练推理用WebUI,3分钟极速训练新模型
AI应用VL视觉理解
OmniParser
0@HelloGitHub
442018H更新时间:2025-07-14
OmniParser 是微软推出的一款强大的屏幕解析工具,专注于将用户界面截图转化为结构化元素,从而提升视觉模型在图形界面中的交互能力。它通过细粒度的图标检测和交互性预测,为自动化测试、智能助手开发以及无障碍技术提供了强大的支持
OmniParser 是微软推出的一款强大的屏幕解析工具,专注于将用户界面截图转化为结构化元素,从而提升视觉模型在图形界面中的交互能力。它通过细粒度的图标检测和交互性预测,为自动化测试、智能助手开发以及无障碍技术提供了强大的支持
SD

sdwebui_xl_2
11@xiaolxl
认证作者5373402H更新时间:2026-02-04
本镜像是基于Stable Diffusion WebUI 1.10.0的一站式整合包
本镜像是基于Stable Diffusion WebUI 1.10.0的一站式整合包
DeepSeek

LLaMAFactory-0.9.2.dev-DeepSeek-R1-Distill
4@llamafactory_cn
认证作者231652H更新时间:2026-02-04
使用[LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory)在多张RTX4090上微调DeepSeek-R1-Distill系列模型
使用[LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory)在多张RTX4090上微调DeepSeek-R1-Distill系列模型
目标检测
SF_Loc
0@敢敢のwings
认证作者4199H更新时间:2026-02-04
SF-Loc应该算是DBA-Fusion(RAL2024)的改进版。
SF-Loc应该算是DBA-Fusion(RAL2024)的改进版。
FluxLora训练

Flux-Lora训练ai-toolkit极简可视化窗口
6@南墙_Rylee
204769H更新时间:2025-07-02
终端输入 cd /root/ai-toolkit && bash /root/ai-toolkit/运行.sh
终端输入 cd /root/ai-toolkit && bash /root/ai-toolkit/运行.sh
DeepSeek推理框架

KTransformers-DeepSeek-R1
2@敢敢のwings
认证作者8266H更新时间:2026-02-04
建议4卡4090,内存300G以上!KTransformers 使用说明文档,目前支持Q4级别的deepseek的QA对话
建议4卡4090,内存300G以上!KTransformers 使用说明文档,目前支持Q4级别的deepseek的QA对话
语音合成

BertVits2-2.4中文特化版
0@aiguoliuguo
认证作者1933H更新时间:2026-02-04
该镜像目前为Bert-VITS2 2.4中文特化版,在中文特化版上所作的一些小优化,模型完全兼容,可进行无缝迁移。
该镜像目前为Bert-VITS2 2.4中文特化版,在中文特化版上所作的一些小优化,模型完全兼容,可进行无缝迁移。
语音合成
FishSpeech
3@aiguoliuguo
认证作者97147H更新时间:2026-02-04
Fish Speech,已发布正式版1.5,强大的zero shot能力,支持中日英德法阿拉伯等多国语言。镜像打包了所需的环境,包括干声分离,切片,标注等工具,开箱即用。
Fish Speech,已发布正式版1.5,强大的zero shot能力,支持中日英德法阿拉伯等多国语言。镜像打包了所需的环境,包括干声分离,切片,标注等工具,开箱即用。
目标检测

YOLOv5
0@BhAem
94581H更新时间:2026-02-04
YOLOv5 是当前工业界最流行的目标检测算法之一,本镜像是基于 **YOLOv5 v7.0** 构建的 YOLOv5 镜像,方便用户测试 YOLOv5 模型。
YOLOv5 是当前工业界最流行的目标检测算法之一,本镜像是基于 **YOLOv5 v7.0** 构建的 YOLOv5 镜像,方便用户测试 YOLOv5 模型。
GLM文本模型

ChatGLM3
2@BhAem
4253H更新时间:2025-07-14
ChatGLM3 镜像,开源双语对话语言模型,支持模型的推理和模型微调。ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型
ChatGLM3 镜像,开源双语对话语言模型,支持模型的推理和模型微调。ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型
推理框架

SGLang推理加速
1@whisdom
1129H更新时间:2026-02-04
这个镜像将会创建大模型推理加速SGLang框架所需的环境,同时将会采用Xinference作为模型管理工具。
这个镜像将会创建大模型推理加速SGLang框架所需的环境,同时将会采用Xinference作为模型管理工具。
图像分割

segment-anything
1@naoxin
1354H更新时间:2025-07-03
分割任何物体模型 (SAM)可根据点或框等输入提示生成高质量物体蒙版,并可用于为图像中的所有物体生成蒙版。该模型已在包含 1100 万张图像和 11 亿个蒙版的数据集上进行了训练,并且在各种分割任务中具有强大的零样本性能
分割任何物体模型 (SAM)可根据点或框等输入提示生成高质量物体蒙版,并可用于为图像中的所有物体生成蒙版。该模型已在包含 1100 万张图像和 11 亿个蒙版的数据集上进行了训练,并且在各种分割任务中具有强大的零样本性能
目标检测图像分割

Fastsam
1@naoxin
87H更新时间:2025-07-15
快速分割任何内容。快速分割任意模型 (FastSAM)是一个 CNN 分割任意模型,仅使用 SAM 作者发布的 SA-1B 数据集的 2% 进行训练。FastSAM 实现了与 SAM 方法相当的性能,但运行速度提高了 50 倍
快速分割任何内容。快速分割任意模型 (FastSAM)是一个 CNN 分割任意模型,仅使用 SAM 作者发布的 SA-1B 数据集的 2% 进行训练。FastSAM 实现了与 SAM 方法相当的性能,但运行速度提高了 50 倍
DeepSeek

DeepSeek-R1:32b
5@fancy
认证作者561993H更新时间:2026-02-04
deepseek-r1:32b版本,单卡4090可以流畅推理,适合用于自己的知识库构建。
deepseek-r1:32b版本,单卡4090可以流畅推理,适合用于自己的知识库构建。
ComfyUI

兰雀ComfyUI
0@兰雀AI
认证作者2614044H更新时间:2026-02-04
最强大和模块化的扩散模型GUI、api和后端,具有图形/节点界面,专业人士首选。
最强大和模块化的扩散模型GUI、api和后端,具有图形/节点界面,专业人士首选。
语音合成

BertVits2-2.3
0@aiguoliuguo
认证作者3352H更新时间:2026-02-04
该镜像目前更新为Bert-VITS2 2.3版本
该镜像目前更新为Bert-VITS2 2.3版本
语音合成

CosyVoice
3@aiguoliuguo
认证作者12886H更新时间:2025-07-02
阿里 TTS模型,提供多语言语音生成、零样本语音生成、跨语言语音克隆和指令跟随能力
阿里 TTS模型,提供多语言语音生成、零样本语音生成、跨语言语音克隆和指令跟随能力
DeepSeek

Ollama-DeepSeek-R1-70B
4@敢敢のwings
认证作者457131H更新时间:2025-07-02
需要双卡,Ollama 和 Open WebUI搭建的DeepSeek-R1-70B版本,支持API调用
需要双卡,Ollama 和 Open WebUI搭建的DeepSeek-R1-70B版本,支持API调用
DeepSeek

vLLM-DeepSeek-R1-Distill
7@优云智算
48527330H更新时间:2025-09-17
DeepSeek-R1-Distill系列模型--基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 蒸馏模型
DeepSeek-R1-Distill系列模型--基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 蒸馏模型
DeepSeek

Ollama-DeepSeek-R1-32B
4@敢敢のwings
认证作者14091168H更新时间:2025-07-02
本手册提供了 Ollama 和 Open WebUI 的安装和使用指南,支持deepseek r1版本
本手册提供了 Ollama 和 Open WebUI 的安装和使用指南,支持deepseek r1版本
DeepSeekVL视觉理解

Janus-Pro-7B
2@优云智算
11163469H更新时间:2025-07-14
DeepSeek Janus-Pro 是一种创新的自回归框架,旨在统一多模态理解与生成任务。它通过将视觉编码解耦为独立的路径,同时仍采用单一的统一 Transformer 架构进行处理,不仅终结了传统模型在视觉理解与图像生成间的两难抉择,更以统一架构刷新性能极限
DeepSeek Janus-Pro 是一种创新的自回归框架,旨在统一多模态理解与生成任务。它通过将视觉编码解耦为独立的路径,同时仍采用单一的统一 Transformer 架构进行处理,不仅终结了传统模型在视觉理解与图像生成间的两难抉择,更以统一架构刷新性能极限
语音合成

Diffsinger
6@39c5bb
认证作者36308H更新时间:2025-07-14
diffsinger基本全自动的声库制作镜像,镜像内涵盖了所有环境,开箱即用。DiffSinger是AAAI 2022官方开源的PyTorch歌声合成模型,通过浅扩散机制实现SVS与TTS统一框架,支持中文/英文多语种所制作声库用于openutau歌声合成引擎,该镜像使用diffsinger的多字典分支,默认支持中日跨语种,但仅支持中文的全自动数据集处理。
diffsinger基本全自动的声库制作镜像,镜像内涵盖了所有环境,开箱即用。DiffSinger是AAAI 2022官方开源的PyTorch歌声合成模型,通过浅扩散机制实现SVS与TTS统一框架,支持中文/英文多语种所制作声库用于openutau歌声合成引擎,该镜像使用diffsinger的多字典分支,默认支持中日跨语种,但仅支持中文的全自动数据集处理。
分子动力

cp2k_lammps_deepmd-kit
1@苍耳阿猫
认证作者2454H更新时间:2026-02-04
cp2k_lammps_deepmd-kit是连接第一性原理与经典分子动力学的极简工作流:用CP2K算少量高精度数据→DeepMD-kit训练DPA-2势函数→LAMMPS驱动亿级原子长时程模拟
cp2k_lammps_deepmd-kit是连接第一性原理与经典分子动力学的极简工作流:用CP2K算少量高精度数据→DeepMD-kit训练DPA-2势函数→LAMMPS驱动亿级原子长时程模拟
AI应用

HivisonIDPhoto
0@Samphi
5442H更新时间:2025-07-02
一款简单易用的 AI 证件照制作工具,能够生成标准证件照和六寸排版照。支持抠图、尺寸调整和自定义底色等功能。
一款简单易用的 AI 证件照制作工具,能够生成标准证件照和六寸排版照。支持抠图、尺寸调整和自定义底色等功能。
生物信息图像分割

SAMed
1@naoxin
61H更新时间:2025-07-14
用于医学图像分割的定制化 Segment Anything 模型。SAMed是面向医学影像的轻量化SAM定制方案,基于LoRA微调ViT编码器+提示编码器+掩码解码器,仅需更新18M参数即可在Synapse多器官数据集上达到81.88 DSC精度,支持224/512分辨率一键推理与训练
用于医学图像分割的定制化 Segment Anything 模型。SAMed是面向医学影像的轻量化SAM定制方案,基于LoRA微调ViT编码器+提示编码器+掩码解码器,仅需更新18M参数即可在Synapse多器官数据集上达到81.88 DSC精度,支持224/512分辨率一键推理与训练
文本模型

MiniCPM-o-2.6
0@liusha
1129H更新时间:2025-06-27
MiniCPM-o 是从 MiniCPM-V 分级的最新端侧多模态 LLM (MLLM) 系列。这些模型现在可以将图像、视频、文本和音频作为输入,并以端到端方式提供高质量的文本和语音输出。
MiniCPM-o 是从 MiniCPM-V 分级的最新端侧多模态 LLM (MLLM) 系列。这些模型现在可以将图像、视频、文本和音频作为输入,并以端到端方式提供高质量的文本和语音输出。
具身智能
Cosmos-v1.0
2@苍耳阿猫
认证作者196H更新时间:2026-02-04
Cosmos-v1.0是英伟达开源的首款物理世界生成模型,可同时处理文本、图像、激光雷达等多模态输入,一键生成高逼真机器人或自动驾驶训练视频
Cosmos-v1.0是英伟达开源的首款物理世界生成模型,可同时处理文本、图像、激光雷达等多模态输入,一键生成高逼真机器人或自动驾驶训练视频
语音合成SVC

DDSP-SVC-6.2
8@39c5bb
认证作者3605817H更新时间:2025-07-14
ddsp6.2,内置环境,上传数据即可训练,支持批量推理。后续会更新。DDSP-SVC-6.2是轻量级端到端歌声转换开源框架,基于DDSP+Rectified Flow双路径建模,推理显存≤4G即可实时变声,训练速度十倍于SO-VITS,集成RMVPE基频提取、NSF-HiFiGAN声码器、内容编码器一键切换,支持多人混合音色、滑窗交叉淡入、SOLA低延迟拼接,附赠Gradio GUI与预训练模型,开箱即唱。
ddsp6.2,内置环境,上传数据即可训练,支持批量推理。后续会更新。DDSP-SVC-6.2是轻量级端到端歌声转换开源框架,基于DDSP+Rectified Flow双路径建模,推理显存≤4G即可实时变声,训练速度十倍于SO-VITS,集成RMVPE基频提取、NSF-HiFiGAN声码器、内容编码器一键切换,支持多人混合音色、滑窗交叉淡入、SOLA低延迟拼接,附赠Gradio GUI与预训练模型,开箱即唱。
文本模型

LLaMA3-8B
1@liusha
1523H更新时间:2025-07-14
Meta Llama3-8B是2024年4月发布的80亿参数自回归大模型,基于15T多语言公开数据预训练,8K上下文Grouped-Query Attention架构,指令版经SFT+RLHF对齐,在通用、推理、代码等基准全面领先同级开源模型
Meta Llama3-8B是2024年4月发布的80亿参数自回归大模型,基于15T多语言公开数据预训练,8K上下文Grouped-Query Attention架构,指令版经SFT+RLHF对齐,在通用、推理、代码等基准全面领先同级开源模型
推理框架

TensorRT-LLM
2@Tlntin
2114H更新时间:2025-07-02
TensorRT-LLM 为用户提供了易于使用的 Python API,用于定义大型语言模型 (LLM) 并构建包含最先进优化的 TensorRT 引擎,以便在 NVIDIA GPU 上高效执行推理。TensorRT-LLM 还包含用于创建执行这些 TensorRT 引擎的 Python 和 C++ 运行时的组件。
TensorRT-LLM 为用户提供了易于使用的 Python API,用于定义大型语言模型 (LLM) 并构建包含最先进优化的 TensorRT 引擎,以便在 NVIDIA GPU 上高效执行推理。TensorRT-LLM 还包含用于创建执行这些 TensorRT 引擎的 Python 和 C++ 运行时的组件。
数字人

Xier-EchoMimicV2
0@Xier
11665H更新时间:2025-07-02
EchoMimicV2是阿里蚂蚁集团推出的半身人体AI数字人项目,基于参考图片、音频剪辑和手部姿势序列生成高质量动画视频,确保音频内容与半身动作的一致性。
EchoMimicV2是阿里蚂蚁集团推出的半身人体AI数字人项目,基于参考图片、音频剪辑和手部姿势序列生成高质量动画视频,确保音频内容与半身动作的一致性。
视频编辑AI应用

Xier-FunClip
4@Xier
92H更新时间:2025-06-27
FunClip 是一款开源的自动化视频剪辑工具,通过集成先进的 AI 技术,降低了视频剪辑的难度,使得非专业人士也能够轻松制作出专业水准的视频内容。
FunClip 是一款开源的自动化视频剪辑工具,通过集成先进的 AI 技术,降低了视频剪辑的难度,使得非专业人士也能够轻松制作出专业水准的视频内容。
三维重建
guassion_splat_cuda 3D高斯点云渲染
7@敢敢のwings
认证作者6141H更新时间:2026-02-04
集成CUDA加速的高斯点云渲染框架,通过纯CUDA重构核心渲染管线实现10倍于原始实现的性能提升,支持实时高保真3D场景重建与渲染。支持cuda版本的高斯渲染的代码操作,并支持二次激光雷达开发
集成CUDA加速的高斯点云渲染框架,通过纯CUDA重构核心渲染管线实现10倍于原始实现的性能提升,支持实时高保真3D场景重建与渲染。支持cuda版本的高斯渲染的代码操作,并支持二次激光雷达开发
AI应用

VoiceTransl
12@Simple
认证作者6541229H更新时间:2025-07-04
VoiceTransl是一站式离线AI视频字幕生成和翻译软件,从视频下载,音频提取,听写打轴,字幕翻译各个环节为翻译者提供便利。
VoiceTransl是一站式离线AI视频字幕生成和翻译软件,从视频下载,音频提取,听写打轴,字幕翻译各个环节为翻译者提供便利。
具身智能

Genesis
0@敢敢のwings
认证作者331088H更新时间:2025-07-02
Compshare云服务平台Genesis世界模型的上手与测试。详情可以参考:https://hermit.blog.csdn.net/article/details/144665610
Compshare云服务平台Genesis世界模型的上手与测试。详情可以参考:https://hermit.blog.csdn.net/article/details/144665610
混元视频生成

ComfyUI-HunyuanVideo-Lora_Train
2@39c5bb
认证作者118937H更新时间:2026-02-04
混元视频模型lora一键训练,镜像内打包了标注,训练,和用于测试的comfyui,打包所有环境,支持上传图片一键训练
混元视频模型lora一键训练,镜像内打包了标注,训练,和用于测试的comfyui,打包所有环境,支持上传图片一键训练
混元视频生成

ComfyUI-HunyuanVideo
0@39c5bb
认证作者19329H更新时间:2025-06-19
基于ComfyUI,支持当前最强的开源视频基础模型,目前支持t2v,之后会更i2v和v2v,镜像内置完整环境,包含bf16和fp8量化后占用更小的两种模型,并链接了插帧和超分功能,开箱即用
基于ComfyUI,支持当前最强的开源视频基础模型,目前支持t2v,之后会更i2v和v2v,镜像内置完整环境,包含bf16和fp8量化后占用更小的两种模型,并链接了插帧和超分功能,开箱即用
语音合成SVC

so-vits-svc
20@39c5bb
认证作者168210544H更新时间:2026-02-04
sovits svc项目的主分支,带干声分离和音频切割,打包了整套数据集制作工具,基本一键训练,开箱即用
sovits svc项目的主分支,带干声分离和音频切割,打包了整套数据集制作工具,基本一键训练,开箱即用
具身智能

Diffusion_Policy具身智能
0@敢敢のwings
认证作者36465H更新时间:2026-02-04
Diffusion_Policy扩散策略,这是一种生成机器人行为的新方法
Diffusion_Policy扩散策略,这是一种生成机器人行为的新方法
目标检测

rtdetr环境,数据集,代码,全套可,一键部署
2@Ai学术叫叫兽
32859H更新时间:2025-07-14
RT-DETR镜像集成首个实时端到端目标检测框架,Ai学术叫叫兽出品,必属精品!RT-DETR环境,数据集,代码,全套可,一键跑通,通过混合编码器与查询去噪技术实现高精度实时检测,支持ResNet/DarkNet等多种骨干网络开箱即用部署
RT-DETR镜像集成首个实时端到端目标检测框架,Ai学术叫叫兽出品,必属精品!RT-DETR环境,数据集,代码,全套可,一键跑通,通过混合编码器与查询去噪技术实现高精度实时检测,支持ResNet/DarkNet等多种骨干网络开箱即用部署
目标检测

YOLOv9环境,数据集,代码,全套可,一键跑通
0@Ai学术叫叫兽
1629H更新时间:2025-07-14
YOLOv9镜像集成新一代实时目标检测框架,Ai学术叫叫兽出品,必属精品!YOLOv9环境,数据集,代码,全套可,一键跑通,通过PGI可编程梯度信息与GELAN架构实现精度-速度-泛化性三重突破,支持端到端训练与开箱即用部署
YOLOv9镜像集成新一代实时目标检测框架,Ai学术叫叫兽出品,必属精品!YOLOv9环境,数据集,代码,全套可,一键跑通,通过PGI可编程梯度信息与GELAN架构实现精度-速度-泛化性三重突破,支持端到端训练与开箱即用部署
目标检测

YOLOv5环境,数据集,代码,全套可,一键跑通
0@Ai学术叫叫兽
51223H更新时间:2025-07-14
YOLOv5镜像集成Ultralytics经典目标检测框架,Ai学术叫叫兽出品必属精品!完整提供环境配置、数据集与代码,通过CSP骨干网络与自适应锚框计算实现高精度实时检测,全套支持一键跑通,开箱即用。
YOLOv5镜像集成Ultralytics经典目标检测框架,Ai学术叫叫兽出品必属精品!完整提供环境配置、数据集与代码,通过CSP骨干网络与自适应锚框计算实现高精度实时检测,全套支持一键跑通,开箱即用。
目标检测

YOLOv8环境,数据集,代码,全套可,一键跑通
1@Ai学术叫叫兽
2713166H更新时间:2025-07-14
YOLOv8镜像集成Ultralytics实时目标检测框架,Ai学术叫叫兽出品必属精品!完整提供环境配置、数据集与代码,通过无锚点设计及任务特定优化实现精度-速度平衡,全套支持一键跑通,开箱即用
YOLOv8镜像集成Ultralytics实时目标检测框架,Ai学术叫叫兽出品必属精品!完整提供环境配置、数据集与代码,通过无锚点设计及任务特定优化实现精度-速度平衡,全套支持一键跑通,开箱即用
图像分割

Unet算法环境,数据集,代码,全套可,一键跑通
1@Ai学术叫叫兽
46655H更新时间:2025-07-14
UNet镜像集成经典医学图像分割架构,通过对称编码器-解码器结构与跳跃连接实现高精度像素级定位,支持端到端训练与轻量部署,适用于生物医学影像分析、工业缺陷检测等场景,提供PyTorch实现的开箱即用解决方案。
UNet镜像集成经典医学图像分割架构,通过对称编码器-解码器结构与跳跃连接实现高精度像素级定位,支持端到端训练与轻量部署,适用于生物医学影像分析、工业缺陷检测等场景,提供PyTorch实现的开箱即用解决方案。
目标检测

YOLOv10环境,数据集,代码,全套可,一键跑通
1@Ai学术叫叫兽
81460H更新时间:2025-07-14
YOLOv10镜像集成最新实时目标检测框架,Ai学术叫叫兽出品必属精品!完整提供环境配置、数据集与代码,通过无NMS设计及整体-局部蒸馏技术实现端到端训练与精度-速度双提升,全套支持一键跑通,开箱即用。
YOLOv10镜像集成最新实时目标检测框架,Ai学术叫叫兽出品必属精品!完整提供环境配置、数据集与代码,通过无NMS设计及整体-局部蒸馏技术实现端到端训练与精度-速度双提升,全套支持一键跑通,开箱即用。
目标检测

YOLOv11算法环境-数据集-代码全套
4@Ai学术叫叫兽
4947614H更新时间:2025-12-17
YOLOv11镜像集成最新目标检测框架升级版,关注B站:Ai学术叫叫兽,跟着视频教程一分钟快速跑通,免费福利专为遥遥领先大家庭小伙伴提供,开箱即用。
YOLOv11镜像集成最新目标检测框架升级版,关注B站:Ai学术叫叫兽,跟着视频教程一分钟快速跑通,免费福利专为遥遥领先大家庭小伙伴提供,开箱即用。
视频编辑

facefusion3.0.1图片视频换脸应用
2@鸡你太美
认证作者285181H更新时间:2026-04-27
FaceFusion 3.0.1镜像集成开源人脸融合与增强工具,支持图像/视频/直播流的高精度人脸交换、年龄性别编辑及清晰度修复,通过多线程优化与显存管理实现实时处理速度,提供简洁API与开箱即用的一键式本地部署方案。
FaceFusion 3.0.1镜像集成开源人脸融合与增强工具,支持图像/视频/直播流的高精度人脸交换、年龄性别编辑及清晰度修复,通过多线程优化与显存管理实现实时处理速度,提供简洁API与开箱即用的一键式本地部署方案。
语音分离

MSST-WebUI
7@39c5bb
认证作者201197H更新时间:2025-07-02
MSST,更好用的干声分离以及去和声混响的项目,可以作为传统UVR的上位替代,并兼容UVR的模型,带webui,也可通过笔记本一键处理音频,简单且高效
MSST,更好用的干声分离以及去和声混响的项目,可以作为传统UVR的上位替代,并兼容UVR的模型,带webui,也可通过笔记本一键处理音频,简单且高效
三维重建

3dgs
6@敢敢のwings
认证作者51184H更新时间:2025-07-11
3DGS镜像集成开源3D高斯点云渲染框架,通过高效可微栅格化技术实现实时的照片级场景重建与渲染,支持从稀疏图像生成高质量动态3D场景,在渲染速度与视觉保真度上超越传统神经辐射场方案,适用于虚拟现实、数字孪生及影视制作领域
3DGS镜像集成开源3D高斯点云渲染框架,通过高效可微栅格化技术实现实时的照片级场景重建与渲染,支持从稀疏图像生成高质量动态3D场景,在渲染速度与视觉保真度上超越传统神经辐射场方案,适用于虚拟现实、数字孪生及影视制作领域
目标检测VL视觉理解
MixVpr
0@敢敢のwings
认证作者727H更新时间:2025-07-11
MixVPR镜像集成全局特征聚合的位置识别模型,通过混合多尺度特征与自适应聚合技术提升复杂场景(如视角/光照变化)下的定位鲁棒性,支持端到端训练与轻量部署,适用于自动驾驶、机器人导航等视觉定位任务
MixVPR镜像集成全局特征聚合的位置识别模型,通过混合多尺度特征与自适应聚合技术提升复杂场景(如视角/光照变化)下的定位鲁棒性,支持端到端训练与轻量部署,适用于自动驾驶、机器人导航等视觉定位任务
目标检测

YOLOv5
1@狼哥
59350H更新时间:2025-07-02
这是一个基于 YOLOv5 v7.0 版本构建的 YOLO Docker 镜像,适用于 YOLOv5 v7.0版本的 AI 视觉处理任务。通过该镜像,用户可以轻松进行 图像分类、目标检测、目标跟踪、姿态识别、图像分割 等任务,该镜像支持以下操作: 模型训练(train):在自定义数据集上训练 YOLO 模型。 模型验证(val):验证模型性能,获得关键指标。 模型推理(inf):对图像、视频流进行目标检测和分类。 部署优化(opt):通过 TensorRT 等工具,优化 GPU 加速推理。
这是一个基于 YOLOv5 v7.0 版本构建的 YOLO Docker 镜像,适用于 YOLOv5 v7.0版本的 AI 视觉处理任务。通过该镜像,用户可以轻松进行 图像分类、目标检测、目标跟踪、姿态识别、图像分割 等任务,该镜像支持以下操作: 模型训练(train):在自定义数据集上训练 YOLO 模型。 模型验证(val):验证模型性能,获得关键指标。 模型推理(inf):对图像、视频流进行目标检测和分类。 部署优化(opt):通过 TensorRT 等工具,优化 GPU 加速推理。
推理框架

LLaMAFactory
2@Faych
6889H更新时间:2025-07-11
LLaMAFactory镜像提供一站式开源大语言模型微调框架,支持全参数/部分参数/QLoRA等高效微调方法,兼容LLaMA、BLOOM等主流架构,通过无需代码的Web界面简化训练流程,显著降低模型定制门槛,开箱即用。内置Qwen2.5-7B-Instruct和alpaca_zh供测试
LLaMAFactory镜像提供一站式开源大语言模型微调框架,支持全参数/部分参数/QLoRA等高效微调方法,兼容LLaMA、BLOOM等主流架构,通过无需代码的Web界面简化训练流程,显著降低模型定制门槛,开箱即用。内置Qwen2.5-7B-Instruct和alpaca_zh供测试
数字人

AniTalker
0@O_O
433H更新时间:2026-02-04
AniTalker镜像集成清华大学开源的2D动画角色口型同步工具
AniTalker镜像集成清华大学开源的2D动画角色口型同步工具
目标检测

YOLOv8
0@狼哥
80314H更新时间:2025-07-02
这是一个基于 YOLOv8 构建的 YOLO Docker 镜像,适用于 YOLOv8 及以上版本的 AI 视觉处理任务。通过该镜像,用户可以轻松进行 图像分类、目标检测、目标跟踪、姿态识别、图像分割 等任务,该镜像支持以下操作:
模型训练(train):在自定义数据集上训练 YOLOv8 模型。
模型验证(val):验证模型性能,获得关键指标。
模型推理(inf):对图像、视频流进行目标检测和分类。
部署优化(opt):通过 TensorRT 等工具,优化 GPU 加速推理。
这是一个基于 YOLOv8 构建的 YOLO Docker 镜像,适用于 YOLOv8 及以上版本的 AI 视觉处理任务。通过该镜像,用户可以轻松进行 图像分类、目标检测、目标跟踪、姿态识别、图像分割 等任务,该镜像支持以下操作:
模型训练(train):在自定义数据集上训练 YOLOv8 模型。
模型验证(val):验证模型性能,获得关键指标。
模型推理(inf):对图像、视频流进行目标检测和分类。
部署优化(opt):通过 TensorRT 等工具,优化 GPU 加速推理。
语音合成

ChatTTS
4@Faych
633741H更新时间:2025-09-09
ChatTTS镜像集成开源对话式文本转语音模型,支持中英双语自然语音合成与细粒度韵律控制(笑声/停顿/情感调节),针对对话场景优化,具备高保真音质与低延迟特性,提供零依赖部署及API服务。
ChatTTS镜像集成开源对话式文本转语音模型,支持中英双语自然语音合成与细粒度韵律控制(笑声/停顿/情感调节),针对对话场景优化,具备高保真音质与低延迟特性,提供零依赖部署及API服务。
ComfyUI

ComfyUI-V2
4@🎉Astro
394904H更新时间:2025-07-11
ComfyUI-V2镜像集成Flux工作流与Stable Diffusion 3.5模型,预装六大核心插件:汉化支持、ControlNet预处理、IP适配增强、图像浏览工具、节点管理器及工作流增强组件(开关/图像对比),提供开箱即用的高级AI绘画与图像处理环境。
ComfyUI-V2镜像集成Flux工作流与Stable Diffusion 3.5模型,预装六大核心插件:汉化支持、ControlNet预处理、IP适配增强、图像浏览工具、节点管理器及工作流增强组件(开关/图像对比),提供开箱即用的高级AI绘画与图像处理环境。
FluxComfyUI图片生成

ComfyUI-Flux.1-dev
3@O_O
193147H更新时间:2026-02-04
ComfyUI-Flux.1-dev 镜像预装 Flux.1 开发版工作流套件,集成 ComfyUI 核心环境与常用节点依赖,支持 Stable Diffusion 高级图像生成与处理任务,开箱即用。
ComfyUI-Flux.1-dev 镜像预装 Flux.1 开发版工作流套件,集成 ComfyUI 核心环境与常用节点依赖,支持 Stable Diffusion 高级图像生成与处理任务,开箱即用。
语音合成

GPT-SoVITS-V2
3@39c5bb
认证作者32099H更新时间:2025-07-11
GPT-SoVITS-V2镜像提供高效零样本语音克隆与文本转语音工具,所需训练素材少、耗时短且情绪控制更精准,集成完整API接口及环境依赖,开箱即用。相比V1版本显著优化音色还原度与合成自然度,并增强跨语言支持与长音频稳定性,支持一键式本地部署。
GPT-SoVITS-V2镜像提供高效零样本语音克隆与文本转语音工具,所需训练素材少、耗时短且情绪控制更精准,集成完整API接口及环境依赖,开箱即用。相比V1版本显著优化音色还原度与合成自然度,并增强跨语言支持与长音频稳定性,支持一键式本地部署。
官方镜像推理框架

LLaMAFactory-WebUI
8@优云智算
2291912H更新时间:-
LLaMA-Factory镜像提供一站式大语言模型微调框架,支持全参数、部分参数及高效QLoRA等多种微调方法,兼容LLaMA、BLOOM等主流架构,内置Web界面简化训练流程,显著提升模型定制效率与易用性。多模型支持,LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Qwen2-VL等。
LLaMA-Factory镜像提供一站式大语言模型微调框架,支持全参数、部分参数及高效QLoRA等多种微调方法,兼容LLaMA、BLOOM等主流架构,内置Web界面简化训练流程,显著提升模型定制效率与易用性。多模型支持,LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Qwen2-VL等。
 扫码关注公众号
扫码关注公众号