Atom-7B
Atom-7B镜像集成高性能轻量级开源大语言模型,基于2T高质量多语种数据预训练,具备高效推理与强泛化能力,支持中英双语任务处理及低成本本地部署,兼顾性能与资源效率,开箱即用。
 0
00元/小时
v1.0
Atom-7B-chat项目介绍
快速运行镜像Demo步骤
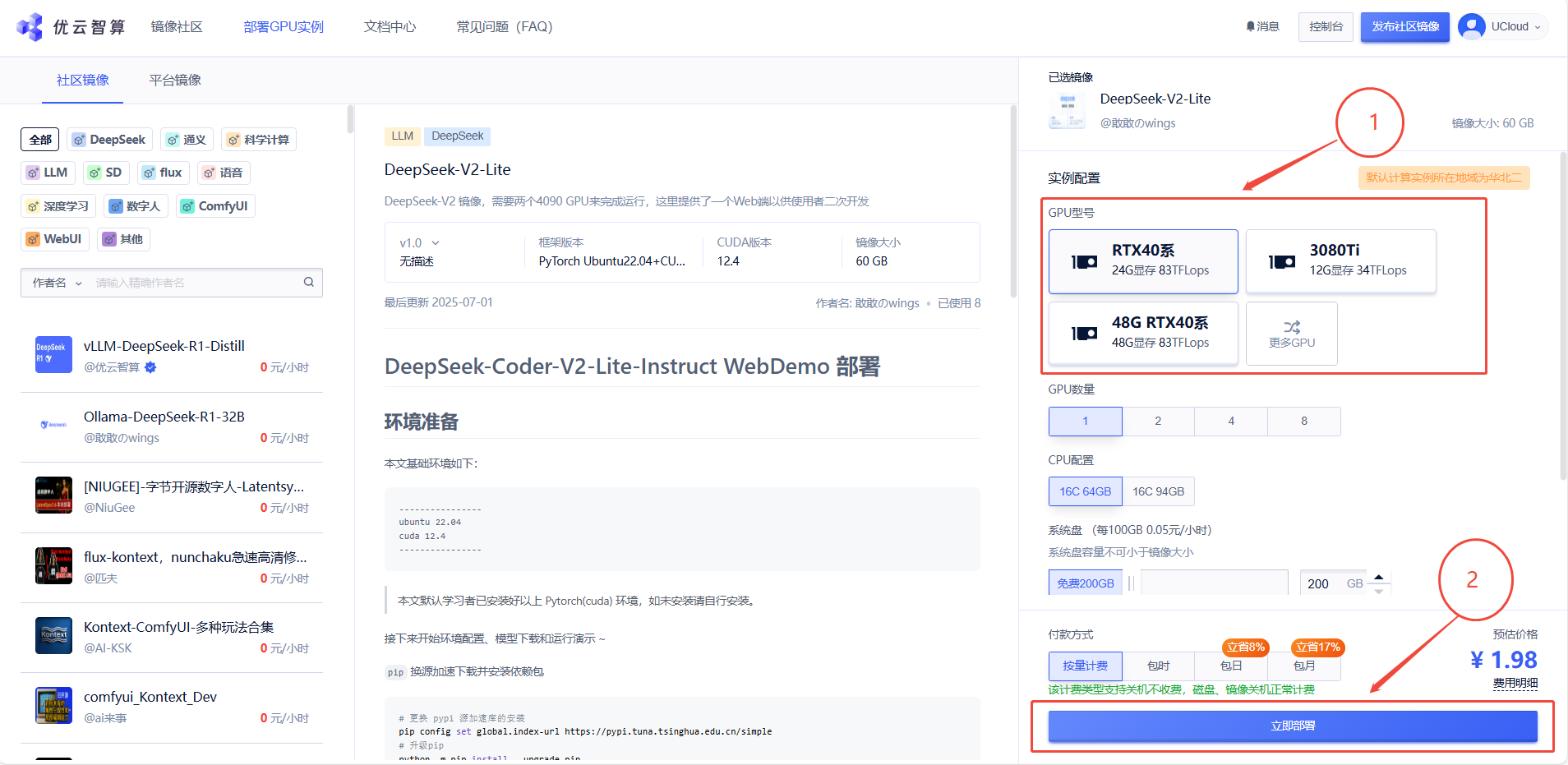
1. 先选择GPU型号,再点击“立即部署”
2. 待实例初始化完成后,在控制台-应用中打开“JupyterLab”

3. 进入Jupyter后,新建一个终端Terminal,输入以下指令
cd /workspace/Atom/compshare-tmp/Llama2-Chinese/
python examples/chat_gradio.py --model_name_or_path /workspace/Atom/compshare-tmp/FlagAlpha/Atom-7B-Chat/
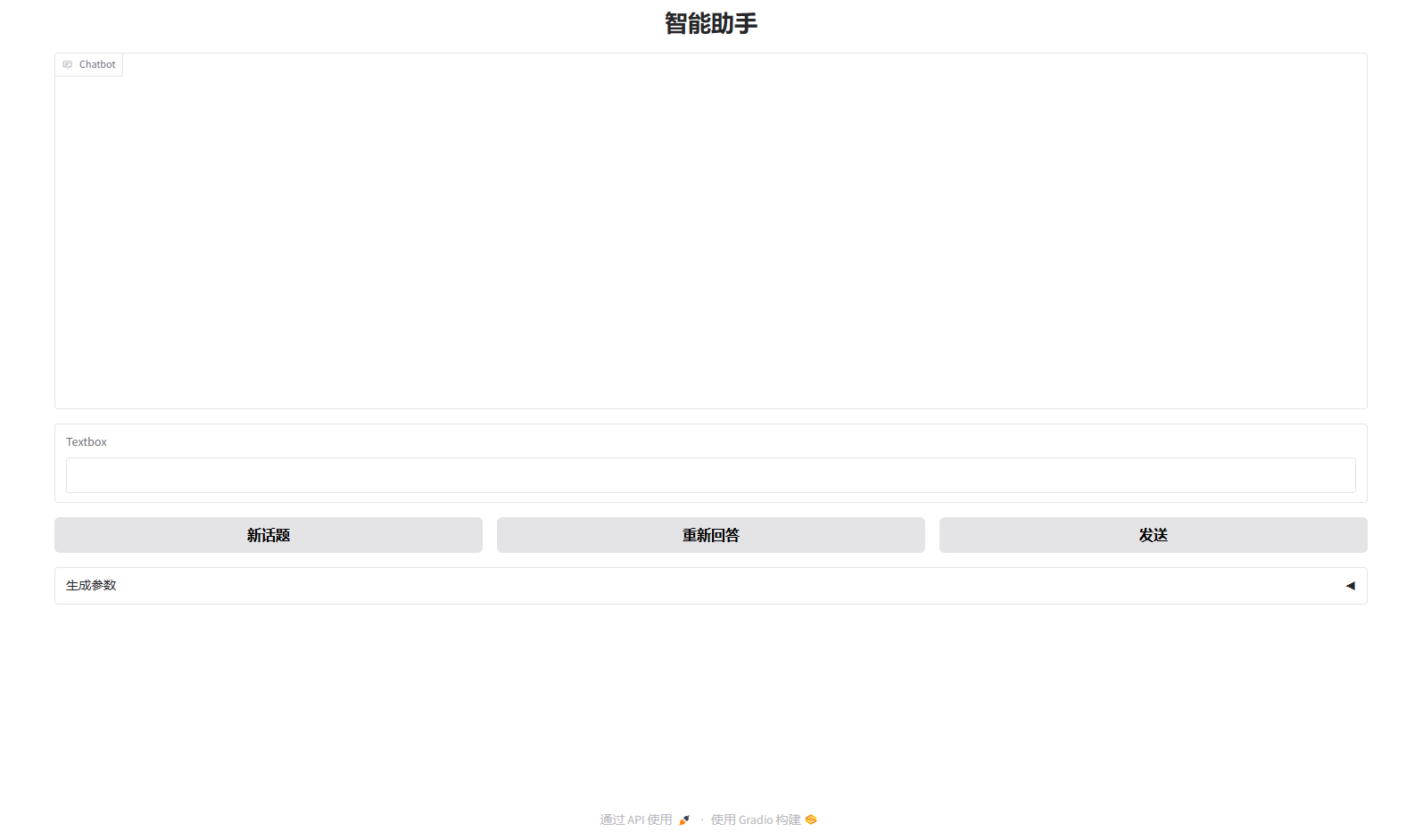
4. 运行出现如下结果时,即可在浏览器中访问 http://0.0.0.0:11434 ,其中0.0.0.0替换为外网ip,外网ip可以在控制台-基础网络(外)中获取

成功进入web界面如下图所示
环境准备
我们打开刚刚租用服务器的JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行demo。
pip换源和安装依赖包
#安装项目相关依赖包
pip install modelscope==1.9.5 transformers==4.35.2 gradio==4.4.1 SentencePiece==0.1.99 accelerate==0.24.1 bitsandbytes==0.41.2.post2 bitsandbytes
模型下载
使用 modelscope 中的snapshot_download函数下载模型,第一个参数为模型名称,参数cache_dir为模型的下载路径。
在 /workspace/Atom/compshare-tmp 路径下新建 download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python /workspace/Atom/compshare-tmp/download.py执行下载,模型大小为 13 GB,下载模型大概需要 10~20 分钟
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download(FlagAlpha/Atom-7B-Chat, cache_dir=/workspace/Atom/compshare-tmp, revision=master)
代码准备
切换路径, clone代码.
cd /workspace/Atom/compshare-tmp
git clone https://github.com/FlagAlpha/Llama2-Chinese.git
切换commit版本,与教程commit版本保持一致,可以让大家更好的复现。
cd Llama2-Chinese
git checkout 0a2b588c5716f26f1e37affa308283354b3612be
demo运行
进入代码目录,运行demo启动脚本,在--model_name_or_path 参数后填写下载的模型目录
cd /workspace/Atom/compshare-tmp/Llama2-Chinese/
python examples/chat_gradio.py --model_name_or_path /workspace/Atom/compshare-tmp/FlagAlpha/Atom-7B-Chat/
在浏览器中打开链接 http://(外部IP):11434/ ,即可看到聊天界面。
@敢敢のwings 认证作者
认证作者
认证作者
镜像信息
已使用1 次
运行时长
0 H
镜像大小
60GB
最后更新时间
2025-07-11
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
自定义开放端口
11434
+1
版本
v1.0
2025-07-11