 0
0Unsloth-DeepSeek-R1-GGUF
DeepSeek R1
所使用项目 unsloth、llama.cpp、open-webui、ollama
目前在各种视频上看见的deepseek R1大部分都是distill(蒸馏)模型,底模并非deepseek,比如常说的32b,70b等。ollama那里只有671这一个是deepseek r1模型
该镜像默认使用的是经过量化后的deepseek r1,由unsloth发布
llama.cpp仓库地址:https://github.com/ggerganov/llama.cpp
open-webui文档地址: https://docs.openwebui.com/
ollama官网:https://ollama.com/
使用到的模型仓库:https://huggingface.co/unsloth/DeepSeek-R1-GGUF/
unsloth官方的部署文档:https://unsloth.ai/blog/deepseekr1-dynamic
该镜像由bilibili@kiss丿冷鸟鸟 所制作
有问题可以bilibili私信我(点个关注谢谢喵)
视频教程:[待制作]
QQ交流群:829974025
一些说明
unsloth文档给了四个模型
| MoE Bits | Type | Disk Size | Accuracy | Details |
|---|---|---|---|---|
| 1.58bit | UD-IQ1_S | 131GB | Fair | MoE all 1.56bit. down_proj in MoE mixture of 2.06/1.56bit |
| 1.73bit | UD-IQ1_M | 158GB | Good | MoE all 1.56bit. down_proj in MoE left at 2.06bit |
| 2.22bit | UD-IQ2_XXS | 183GB | Better | MoE all 2.06bit. down_proj in MoE mixture of 2.5/2.06bit |
| 2.51bit | UD-Q2_K_XL | 212GB | Best | MoE all 2.5bit. down_proj in MoE mixture of 3.5/2.5bit |
①镜像选择1.58的作为默认配置
②部署1.58bit的如果需要全部加载到显存上,需要2x80GB的显卡,换算成24g的4090需要挺多张,但是相较于需要一大堆H100的671b的原本模型,所用配置已经相当低了,全部加载到内存上推理可能会比较慢,因此可以通过将部分layer卸载到显存上从而加快推理速度
③单卡4090的话不是很推荐,因为平台给的内存也挺低的,貌似显存内存加在一起都有点放不下,只有0.17token/s,双卡4090,layer为17或者16,大概1.5token/s到2tokens/s之间,再多的话没测过,虽然这速度也不是不能用,三卡应该就能正常用了,当然,选择更大显存的A100或者H100,即可全部吃下,飞快使用(
④当然,该镜像还搭载了ollama,你不想使用r1模型的话也可以试试蒸馏模型,单卡4090妥妥够了,70b的那个中文效果还不如32g,镜像内自带的两个蒸馏模型分别是32b官方版和32b越狱般。启动ollama服务后,再启动open-webui,进入到open-webui即可使用
⑤量化模型也可以在llama.cpp的serve上面推,open-webui并不是必须的
大概就这样
使用教程
1. 待实例初始化完成后,在控制台-中打开“JupyterLab”
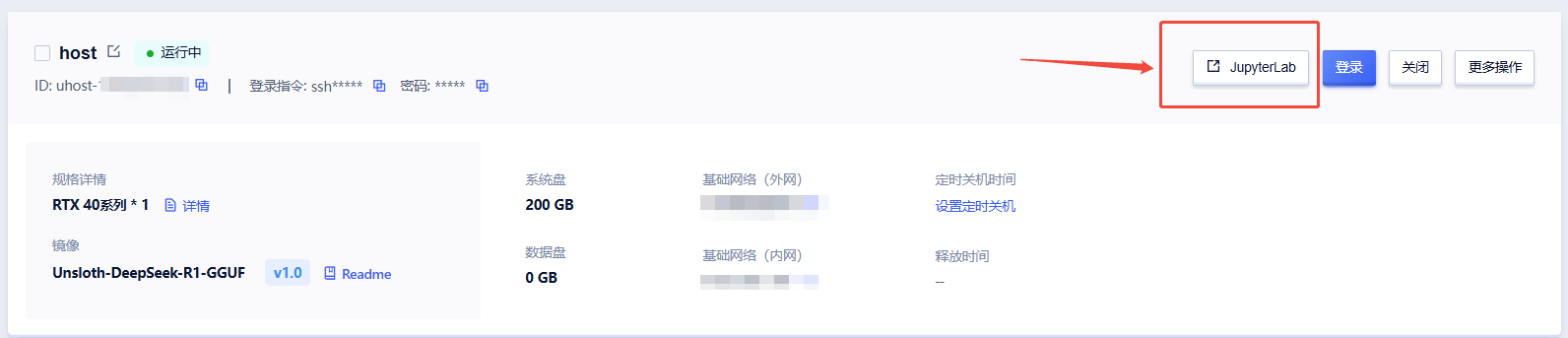
2. 进入JupyterLab后,先打开“启动ollama.ipynb”这个文件,运行前两个代码块以启动ollama服务


3. 再打开”启动openwebui“这个文件,运行启动open-webui代码块
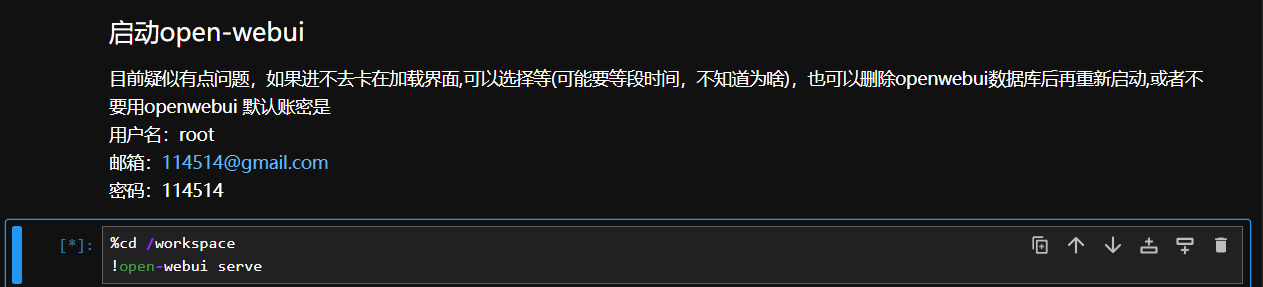
当运行结果如下图所示时,即可在浏览器中输入 http://0.0.0.0:8080 访问WebUI界面,0.0.0.0替换为控制台上-基础网络(外网)中的ip地址

默认使用用户名:root 邮箱:114514@gmail.com 密码:114514 进行登录
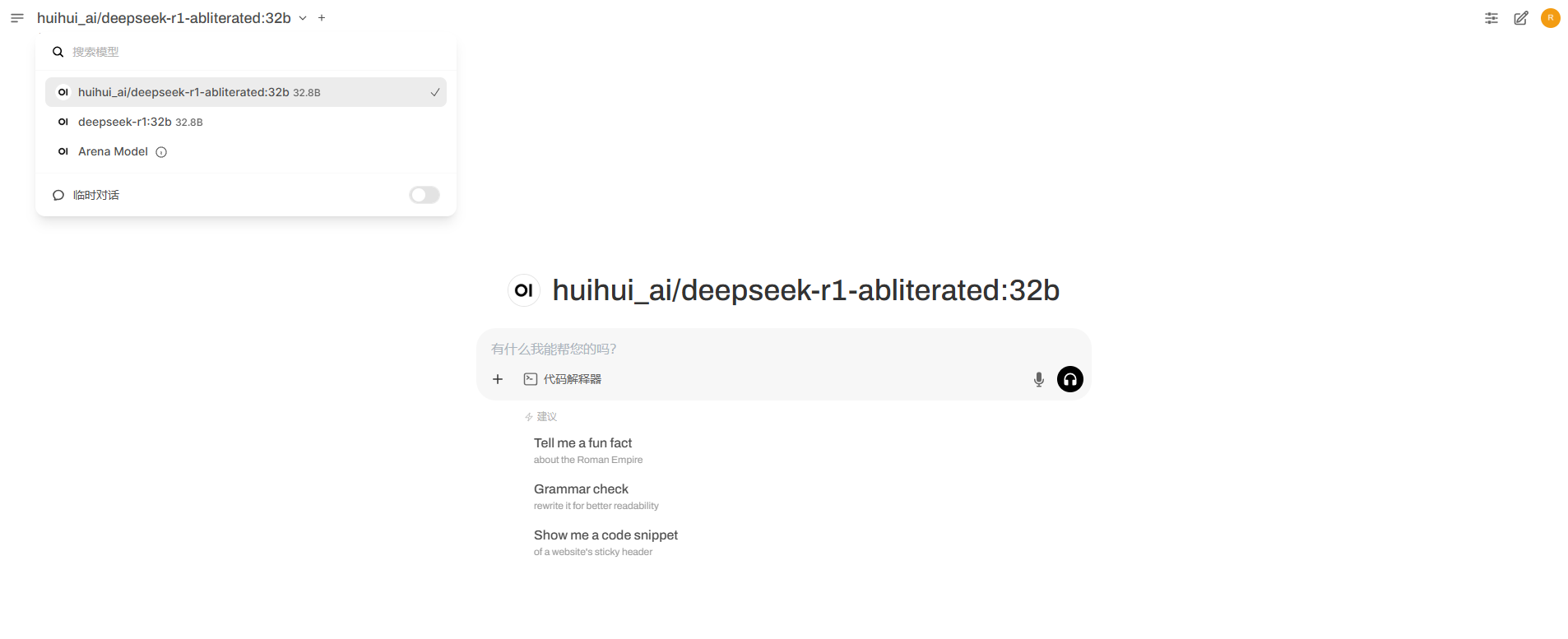
进入WebUI界面后如下图所示,在左上角位置可以切换模型
扫码加入DeepSeek使用交流群

 认证作者
认证作者