 0
0BertVits2-2.3
镜像简介
该镜像目前更新为Bert-VITS2 2.3版本,取消了对2.2及其以下(2.0.1、1.0.1、1.1、1.1.1 版本仅支持推理兼容,不支持这三个版本的训练)
该镜像主要基于Bert-vits2项目,项目地址:https://github.com/fishaudio/Bert-VITS2
内置了audio-slicer进行数据集的切割,使用funasr进行数据集的标注,使用MSST进行音频分离
aiguoliuguo-镜像作者交流群

云端训练部分教程
1.创建实例
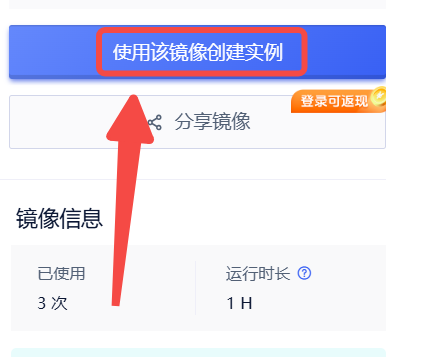
2.选择合适的机型,立即部署
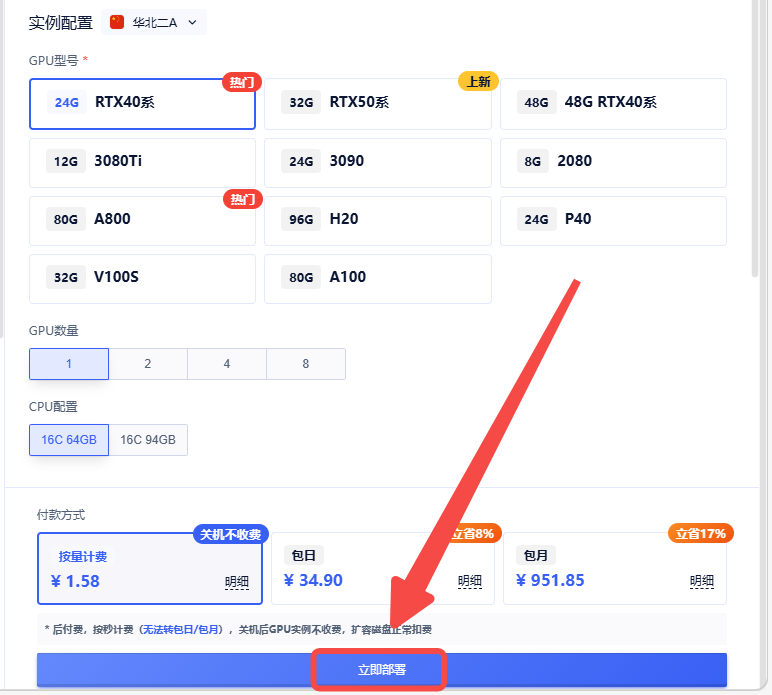
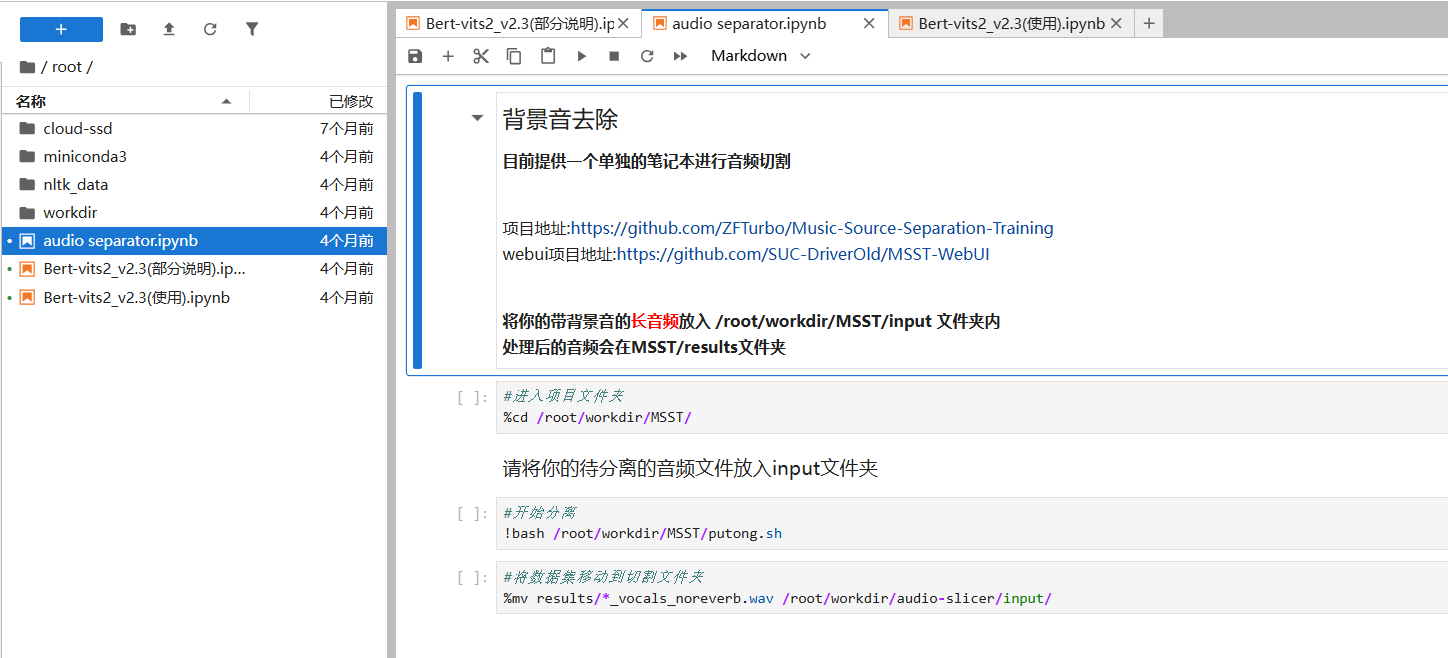
3.返回实例页面,点击【JupyterLab】 初次使用小白请仔细阅读Jupyter中的内容和代码块中的注释
镜像已经内置了训练/推理Bert-vits2的所有环境,无需额外下载,并且内置切片工具和标注工具,开箱即用
关于数据集:
数据集分为两部分,一部分是音频,一部分是标注
1.数据集需要是无背景音,长度为5-15s左右的纯人声。短点也行,但是不要太长,不要超过30秒
2.时长推荐1h以上,长音频可以放到audio-slicer/input内,内置切割工具。已经切割好的音频放置于auto-VITS-DataLabeling/raw_audio内
3.标注文件的格式每个版本都相同,因此标注文件是通用的,比如你可以把1.0.1的标注塞到2.0上面使用,但是bert文件需要重新生成
4.镜像内置标注工具,除了中文数据集推荐使用funasr以外,其余的建议使用whisper
5.生成的标注文件位于filelist文件夹内
6.未处理的数据集存放于dataset_raw,处理后的数据集存放于dataset
7.单speaker的数据集存放格式如下 dataset_raw └───speaker0 ├───xxx1-xxx1.wav ├───... └───Lxx-0xx8.wav
8.处理后的数据集位于dataset,应当有xxxx.bert.pt开头的文件,xxxx.spec.pt开头的不用管,会在开始训练后生成
关于训练
1.训练之前可以根据你的配置和数据集修改一下配置文件,不会改默认也行
2.开始训练和继续训练都是同一条命令,训练之前检查一下你的数据集,并且确保你已经运行过准备部分的第二条命令
3.开始训练之前请检查一下模型文件夹是否有装载底模
4.默认保存15个模型,会自动删除旧模型,保存的模型会保存在Data文件夹,比如我的speaker是ATRI,我的模型就保存在Data/ATRI/models/ATRI/目录内用与标注,
关于推理
0.gradio webui已经弃用,需要的自己改配置文件自己开
1.gui带使用帮助,自己看,逐字阅读,纯小白只需要看帮助页面的推理部分
2.翻译和随机音频示例不可用(可以自己改)
3.推理参数 sdp_ratio = SDP/DP混合比 noise_scale = 感情调节 noise_scale_w = 音素长度 length_scale = 语速
4.混合推理目前该ui不支持,不过在路上了。可使用gradio webui进行。混合推理和多说话人推理使用方法如下
[说话人2]
5.目前gradio ui已支持支持多语言自动识别推理
 认证作者
认证作者
