KTransformers-DeepSeek-R1
建议4卡4090,内存300G以上!KTransformers 使用说明文档,目前支持Q4级别的deepseek的QA对话
 2
20元/小时
v1.0
KTransformers 使用说明文档
镜像简介
本镜像提供专为DeepSeek-R1优化的KTransformers高性能推理框架,支持多卡并行(建议4卡4090)与先进内存管理,显著提升大模型推理速度与稳定性。集成主流量化与长上下文优化技术,适用于企业级AI应用、大规模语言模型服务部署及前沿研究等对性能有严苛要求的专业场景。
镜像使用教程
1. 先选择GPU型号和数量(该镜像建议4卡RTX40系运行)
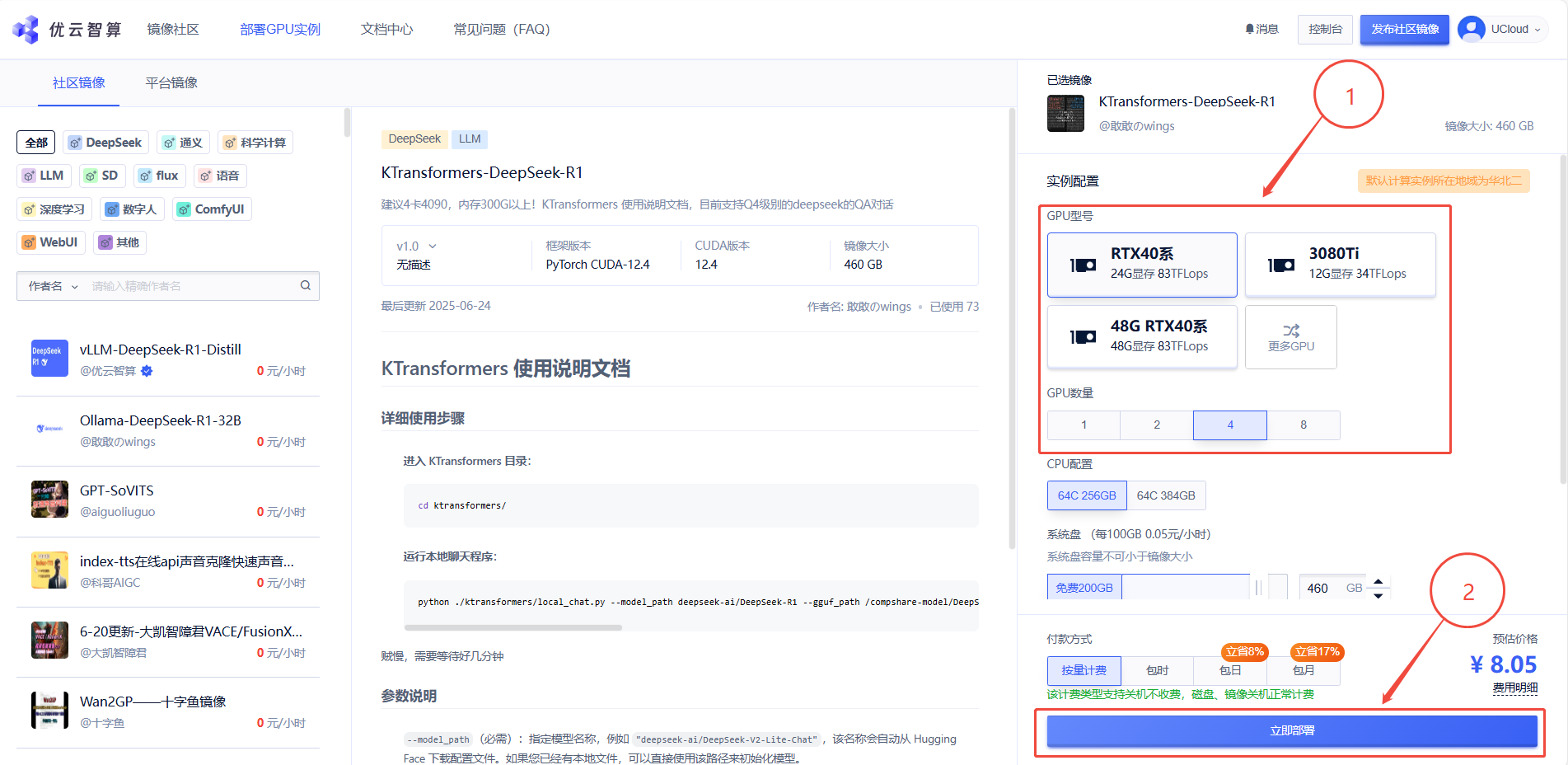
2. 待实例初始化完成后,在控制台-应用中打开“JupyterLab”
3. 进入JupyterLab后,新建一个终端Terminal,在终端中依次输入以下指令
进入 KTransformers 目录:
cd ktransformers/
运行本地聊天程序(速度较慢,需等待几分钟):
python ./ktransformers/local_chat.py --model_path deepseek-ai/DeepSeek-R1 --gguf_path /compshare-model/DeepSeek-R1-GGUF/DeepSeek-R1-Q4_K_M --force_think true --cpu_infer 60 --max_new_tokens 1000 --optimize_rule_path ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-multi-gpu.yaml
参数说明
-
--model_path(必需):指定模型名称,例如"deepseek-ai/DeepSeek-V2-Lite-Chat",该名称会自动从 Hugging Face 下载配置文件。如果您已经有本地文件,可以直接使用该路径来初始化模型。注意:目录中不需要
.safetensors文件。我们只需要配置文件来构建模型和分词器。 -
--gguf_path(必需):指定包含 GGUF 文件的目录路径,这些文件可以从 Hugging Face 下载。注意该目录应仅包含当前模型的 GGUF 文件,这意味着每个模型需要一个单独的目录。 -
--optimize_rule_path(除 Qwen2Moe 和 DeepSeek-V2 外必需):指定包含优化规则的 YAML 文件路径。ktransformers/optimize/optimize_rules目录中预先写好了两个规则文件,用于优化 DeepSeek-V2 和 Qwen2-57B-A14,这两个是当前最先进的 MoE 模型。 -
--max_new_tokens:整数(默认值为 1000)。生成的新令牌的最大数量。 -
--cpu_infer:整数(默认值为 10)。用于推理的 CPU 数量。理想情况下应设置为(总核心数 - 2)。
@敢敢のwings 认证作者
认证作者
认证作者
镜像信息
已使用81 次
运行时长
54 H
镜像大小
460GB
最后更新时间
2026-02-04
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
版本
v1.0
2026-02-04