Flux-Lora训练ai-toolkit极简可视化窗口
镜像使用教程
通过该链接注册可额外获得算力赠金 https://passport.compshare.cn/register?referral_code=E7taRbLv8LLEEZf8eNcsxB
1. 先选择GPU型号,再点击”立即部署“ ;开启镜像后可能会开始初始化,需要等待片刻。(首次创建较慢,下一次使用就好了)
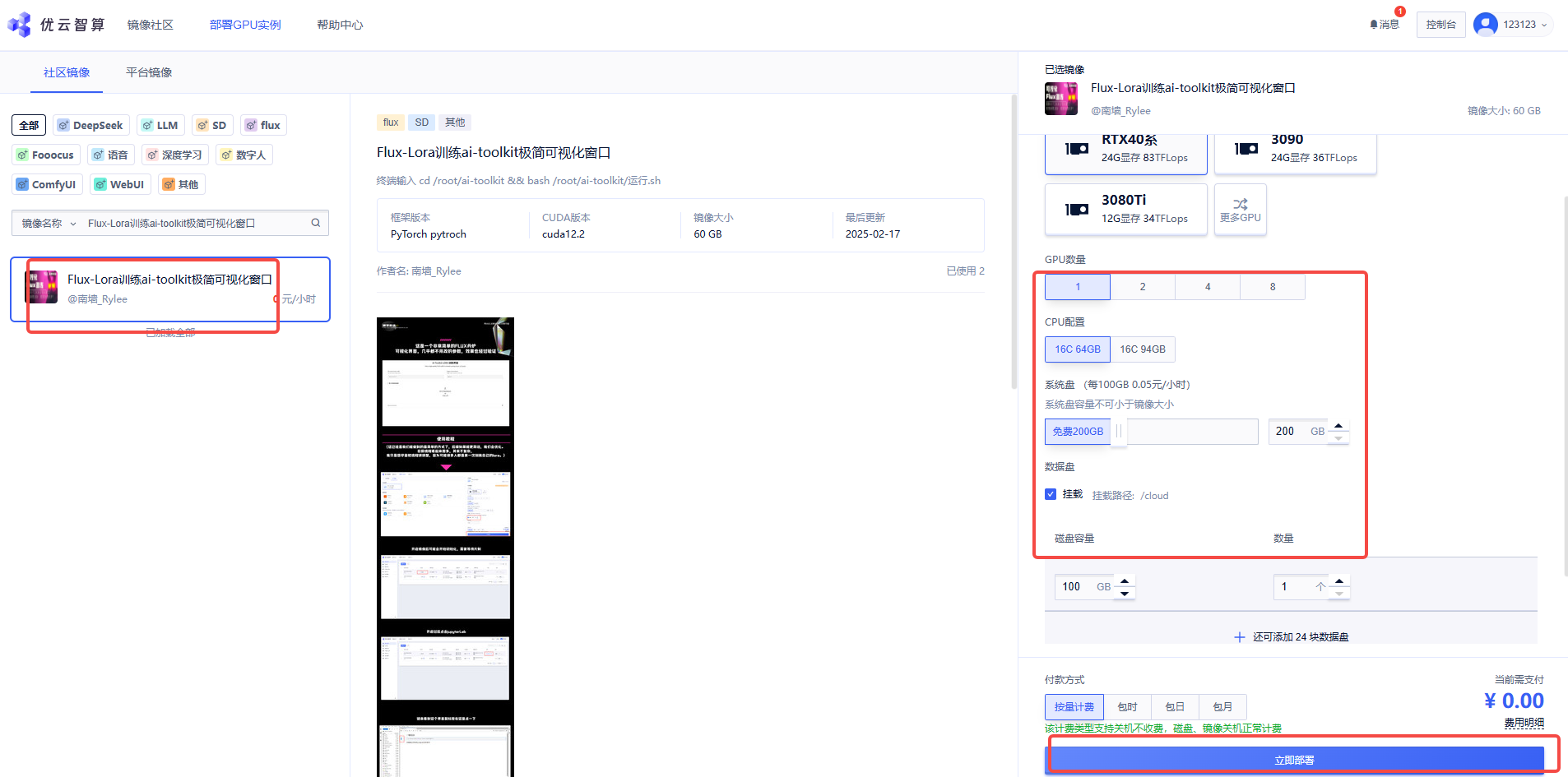
2. 待实例初始化完成后,在控制台-应用中打开”JupyterLab“

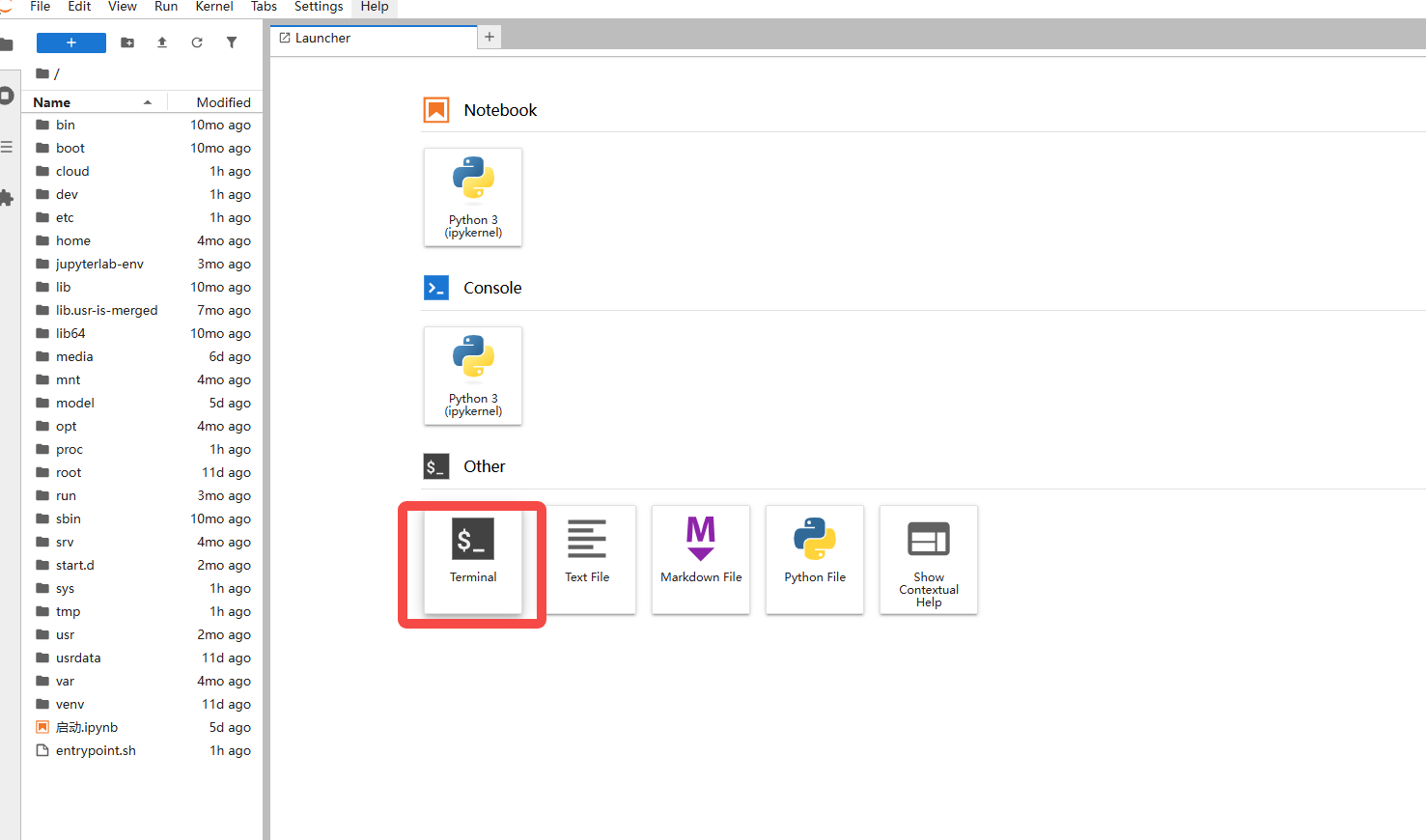
3. 进入JupyterLab后,新建一个终端Terminal,输入以下指令
cd /root/ai-toolkit && bash /root/ai-toolkit/运行.sh
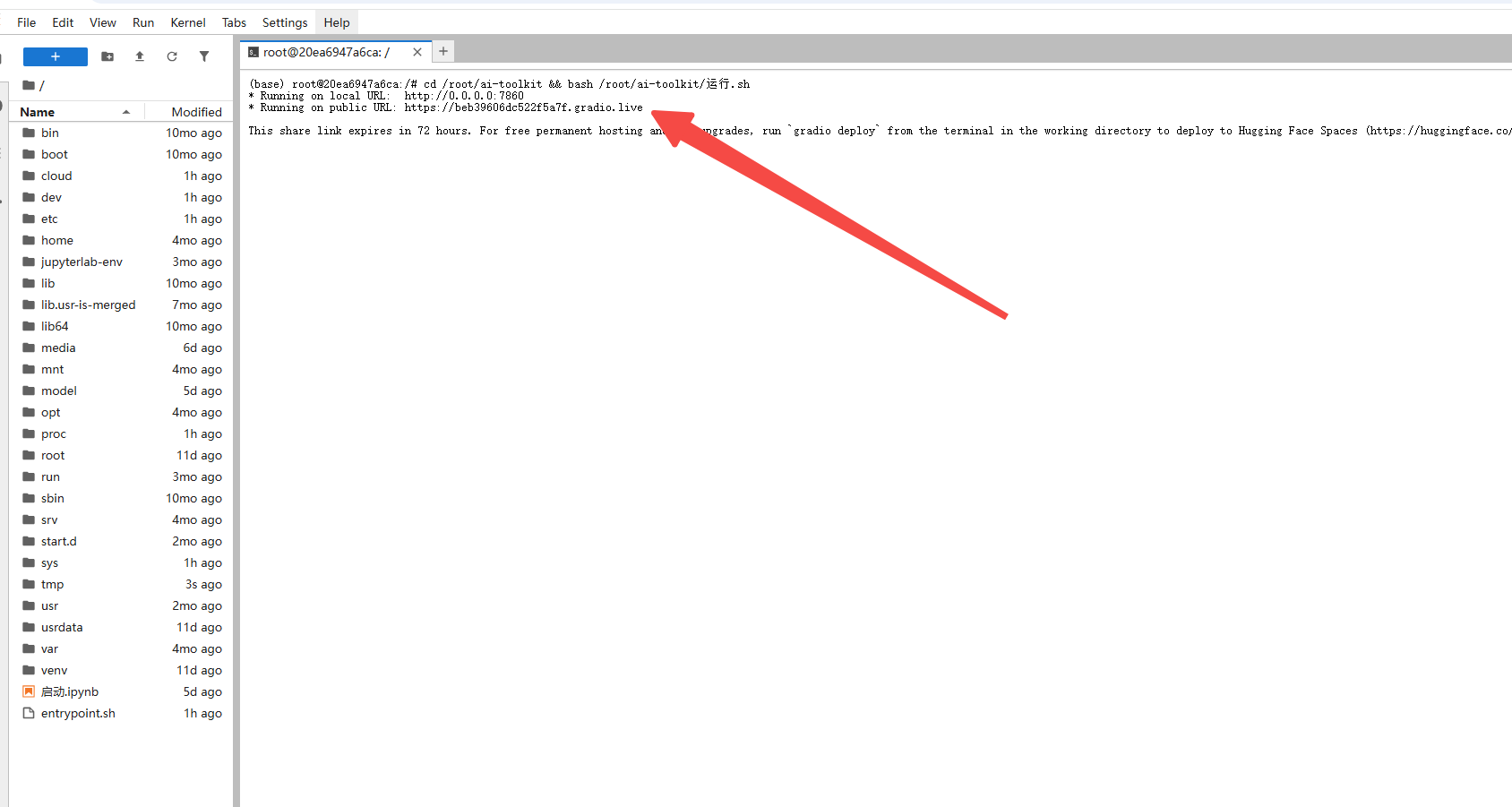
可能需要加载片刻,耐心一点
出现以下字符,则表示运行成功:
Running on local URL:http://0.0.0.0:7860 Running on public URL:http://6b390417ea3d72b51d.gradio.live This share link expires in 72 hours.For free permanent hosting and GPU upgrades,run'gradio deploy'from the terminal in the working directory to hugging Face Spaces (https://huggingface.co/spaces)
点击箭头所指示的第二个链接,界面如下
1)这里的训练集上限是300个文件,也就是最多支持150张图+150个打标文件。
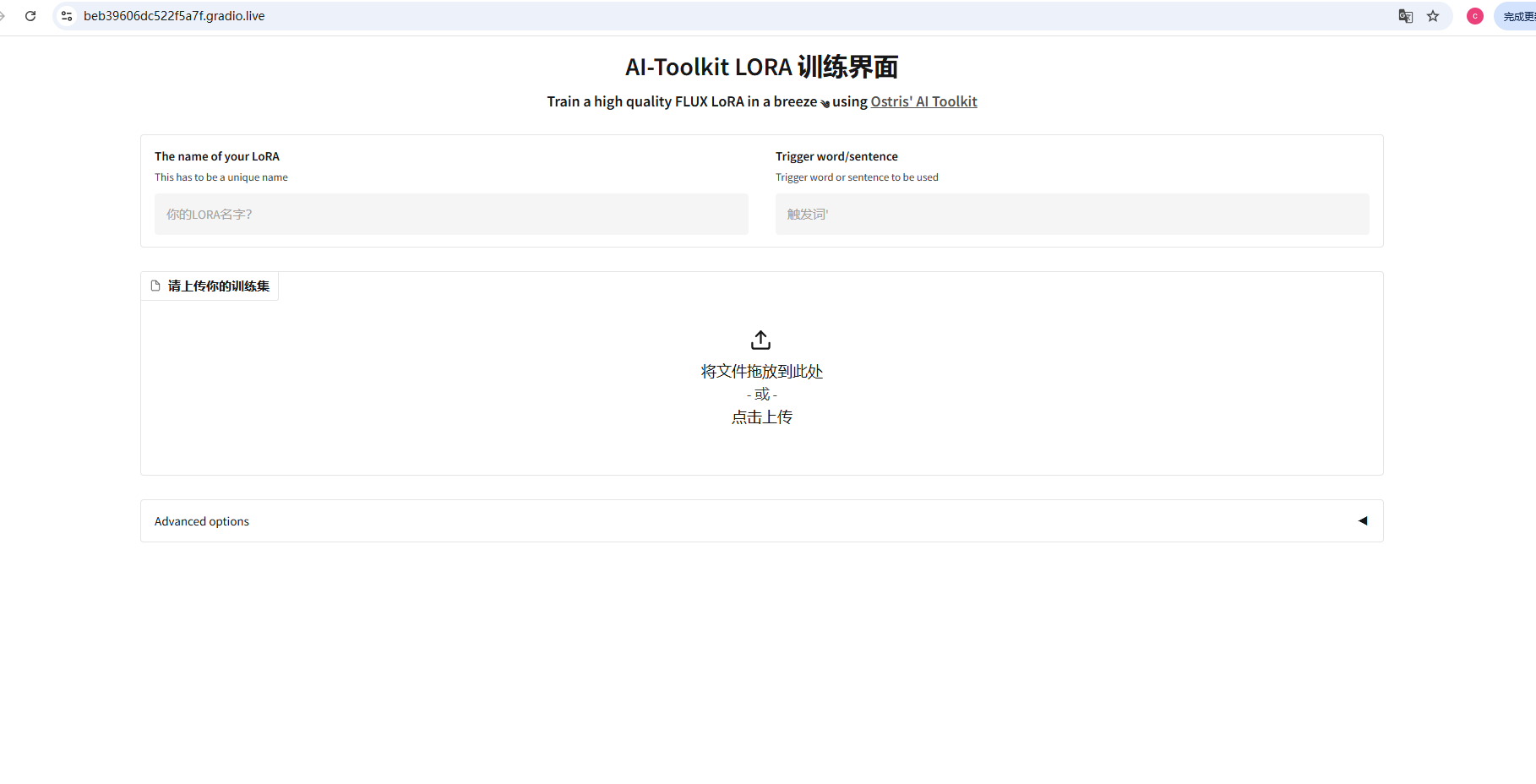
2)触发词可有可无,必填项只有你的lora名称
3)没打标的图像也可以直接上传,训练器自带了Florence-2打标器,打标自然语言效果还是很不错的~
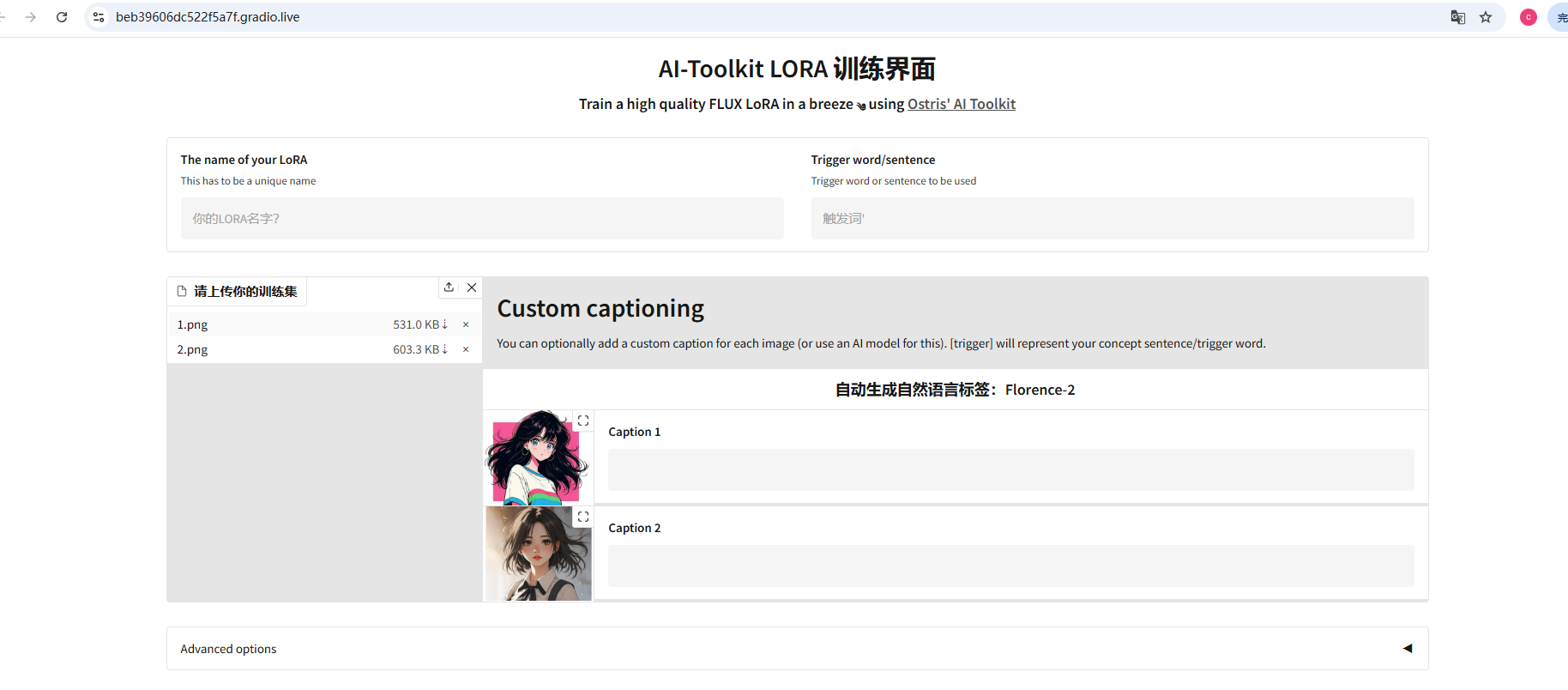
4)下面的大部分选项都可以保持不管,实在看不懂的就保持默认就好。
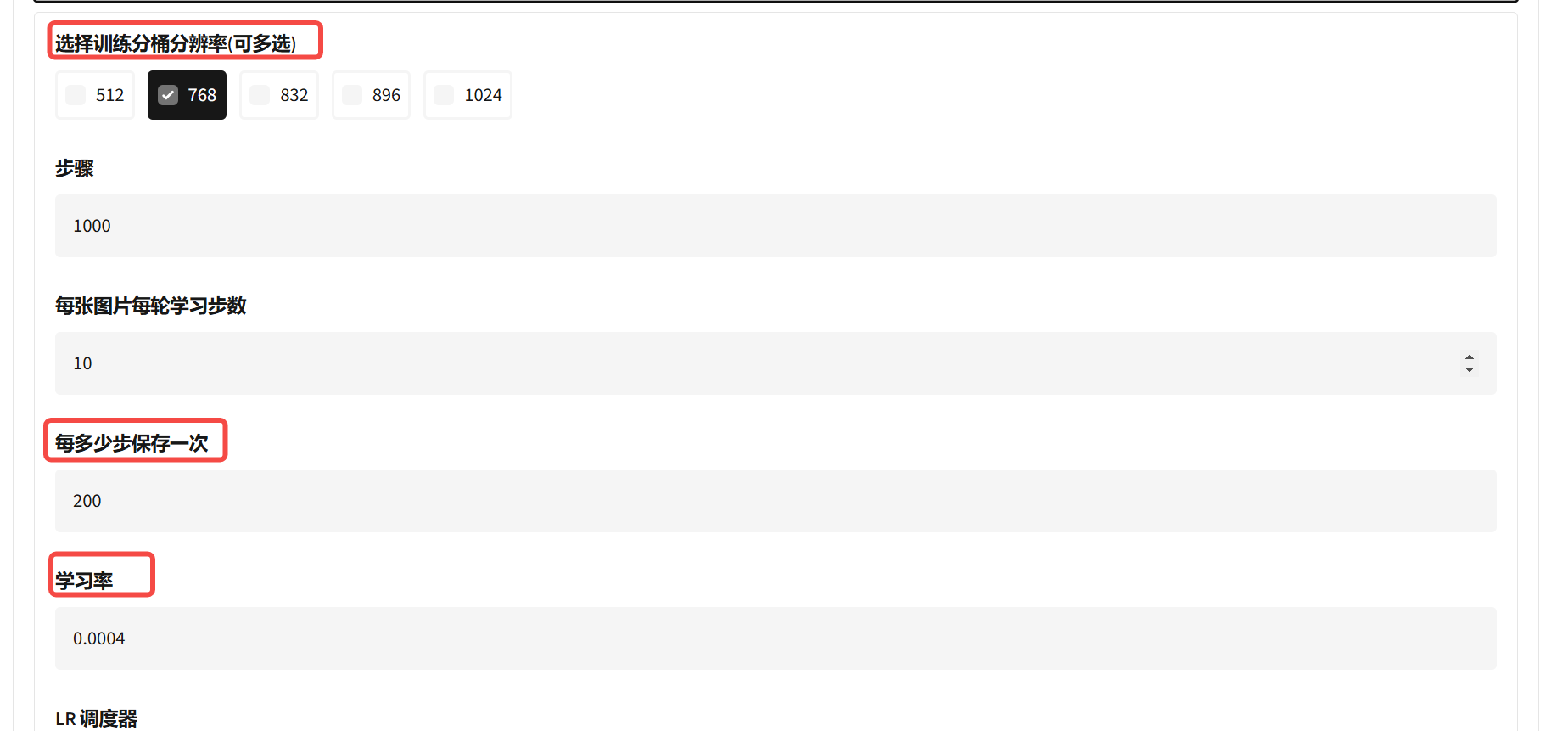
5)【分桶】尽量选择接近训练集图像分辨率的(如果不确定或者懒得看,可以全选)
6)【每多少步保存一次】,意思就是不同步数保存的lora ,这个可以自己根据总步数来算一下会保存多少个。 (训练好的lora在output文件夹里)
7)学习率可以保持默认,也可以调整0.0002-0.0005区间,
可以默认先炼,如果你觉得模型“没学会”,再来调高学习率和步数。
8)【Lora Rank】推荐8、16、32(不是越高越好,这个也影响训练速度和最终的文件大小,
画风类可以低一些,写实人像类可以高一些,不确定就16先尝试。)
9)【Sample Steps】是每多少步生成一次预览图(建议和上面的【每多少步保存一次】步数一样。)
10)下面的高级参数,如果你看不明白~ 建议别去动
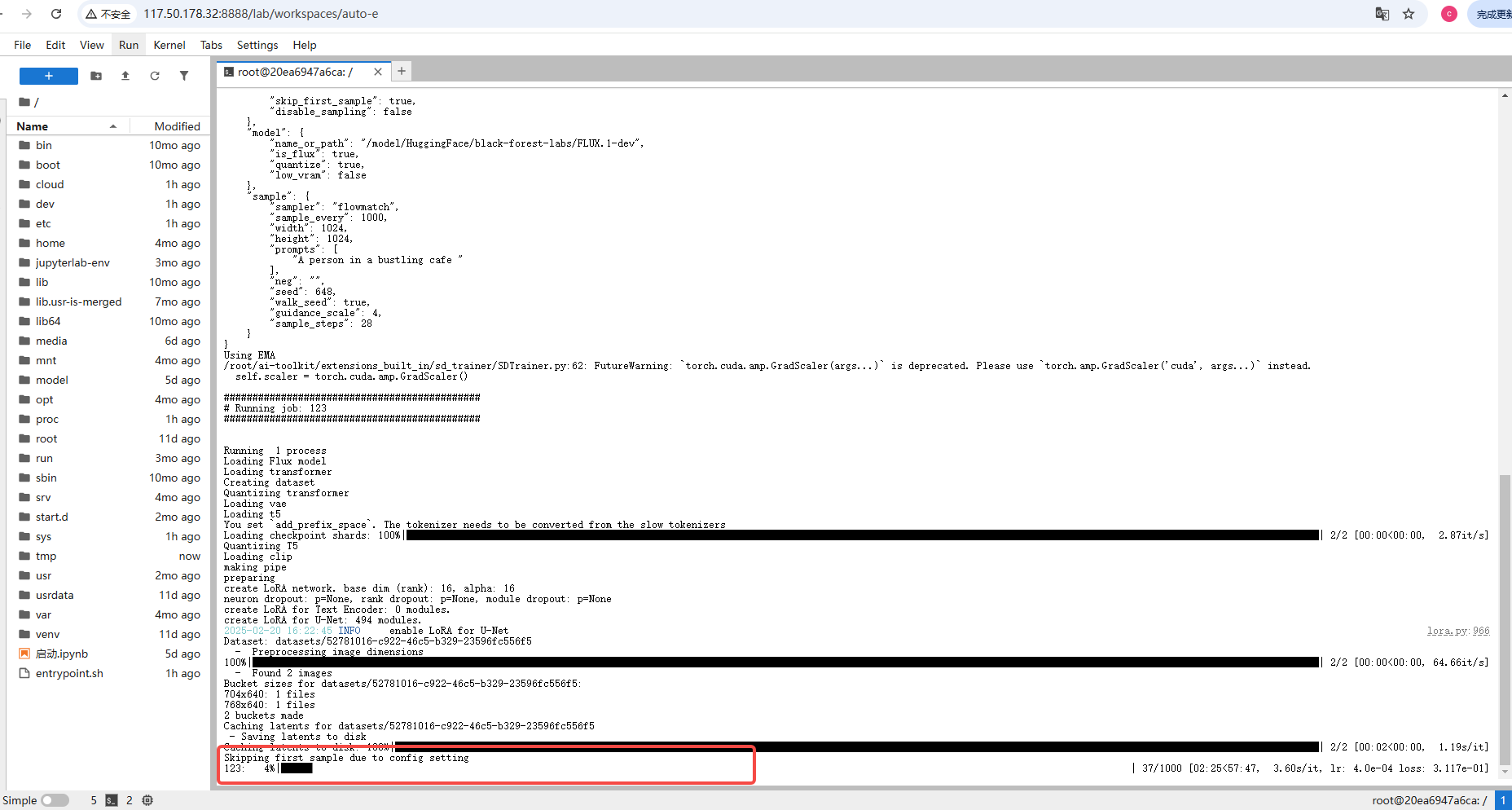
→ 返回最开始的jupyterLab界面就可以看到训练日志
训练好的文件在output文件夹中
(就是看看训练进度,不必太纠结这里的数值,主要是看剩余时间就行,模型最重要的是最终的训练测试结果)
这是我们目前能做到的最简洁的方式了,新手第一次过流程可能费劲一点,熟练就好了。 教程也尽量详细的在写,后续有更好的优化都会更新的!


 扫码加入用户交流群
扫码加入用户交流群