QwQ-32B-GGUF
QwQ-32B 是一个中等规模的推理模型,其性能可以与最先进的推理模型相媲美,例如 DeepSeek-R1、o1-mini
 1
10元/小时
v1.0
通义千问 QwQ-32B 镜像
镜像简介
QwQ 是 Qwen 系列中的推理模型。与传统的指令调优模型相比,具备思考和推理能力的 QwQ 在下游任务中,特别是在解决难题时,能够显著提升性能。QwQ-32B 是一个中等规模的推理模型,其性能可以与最先进的推理模型相媲美,例如 DeepSeek-R1、o1-mini
官方博客:QwQ-32B:拥抱强化学习的力量
此镜像包含 QwQ 32B 模型,具有以下特点:
- 类型:因果语言模型
- 训练阶段:预训练及后训练(监督微调和强化学习)
- 架构:带有 RoPE、SwiGLU、RMSNorm 和 Attention QKV 偏置的 transformers
- 参数数量:325 亿
- 非嵌入参数数量:310 亿
- 层数:64 层
- 注意力头数(GQA):Q 为 40 个,KV 为 8 个
- 上下文长度:完整支持 131,072 个 tokens
镜像使用教程
此镜像基于ollama运行,并安装了open-webui的dev分支实现可视化模型聊天,预先下载了QwQ-32b模型。
注:由于open-webui会出现连接不上open api导致网页暂停加载5分钟的情况,我在bashrc中添加export AIOHTTP_CLIENT_TIMEOUT_MODEL_LIST=5,强制设为只暂停加载5秒。
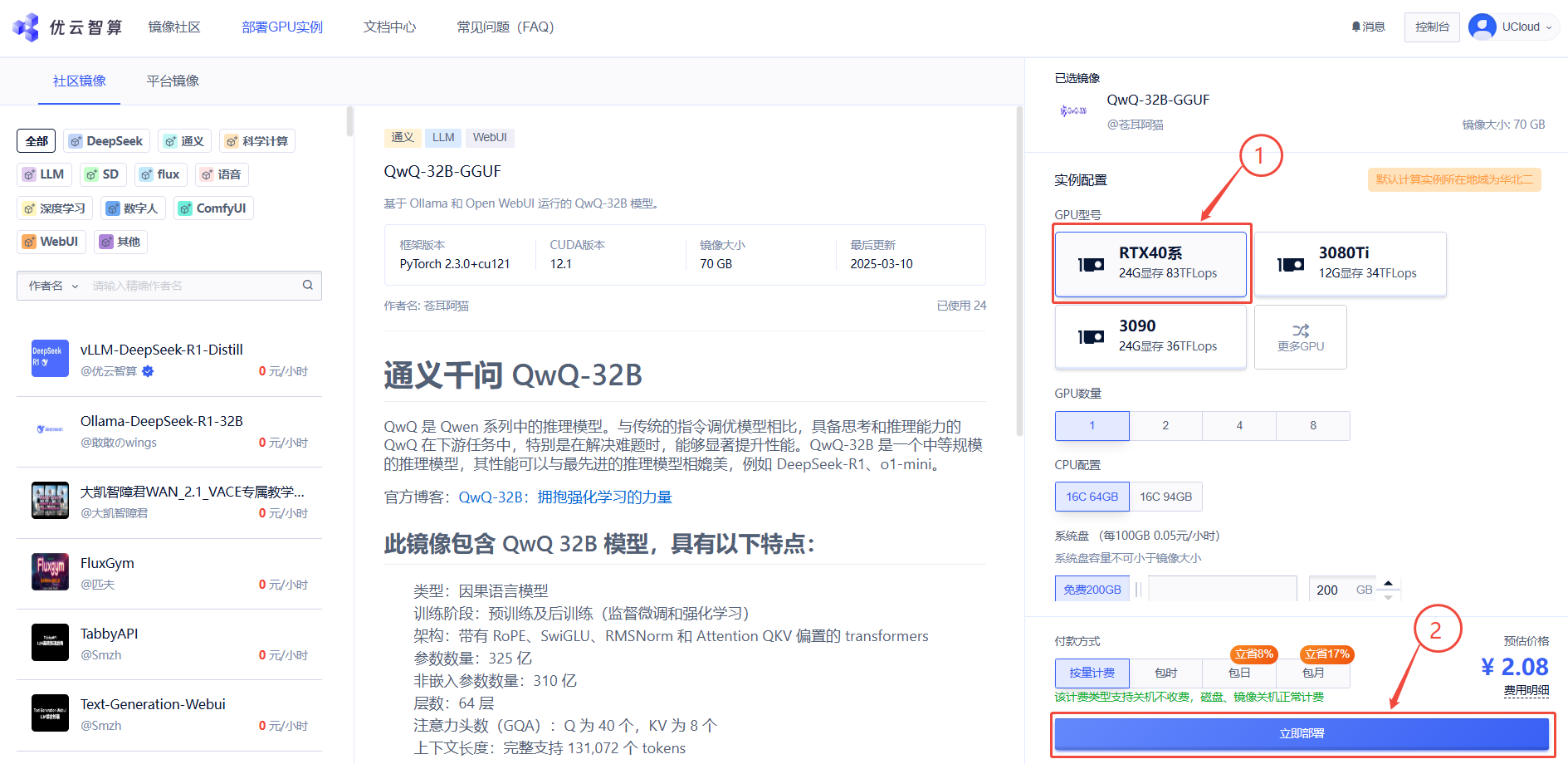
1. 先选择GPU型号(以RTX40系为例),再点击“立即部署”
2. 待实例初始化完成后,在控制台-应用中点击“JupyterLab”进入

3. 进入JupyterLab后,新建一个终端Terminal,输入以下指令启动ollama服务
ollama serve
4. 不要关闭前一个终端,再次新建一个终端运行下面命令启动webui服务
open-webui serve
5. 两个终端的命令都执行后,在浏览器中输入 ip:8080 以访问web界面,ip可以在控制台-基础网络(外)获取

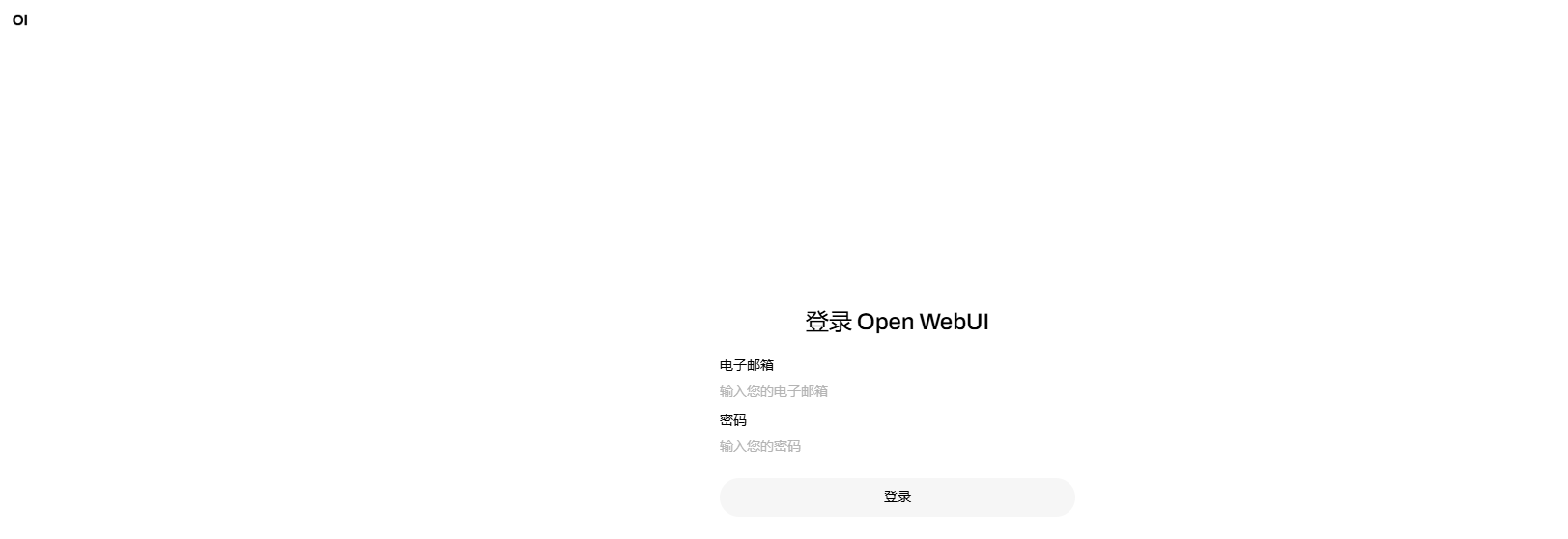
6. 进入web界面后,如下图所示,默认登录的管理员名为root@root.com,密码为root,网页默认使用qwq-32b模型。
成功登录后,界面为如下图所示
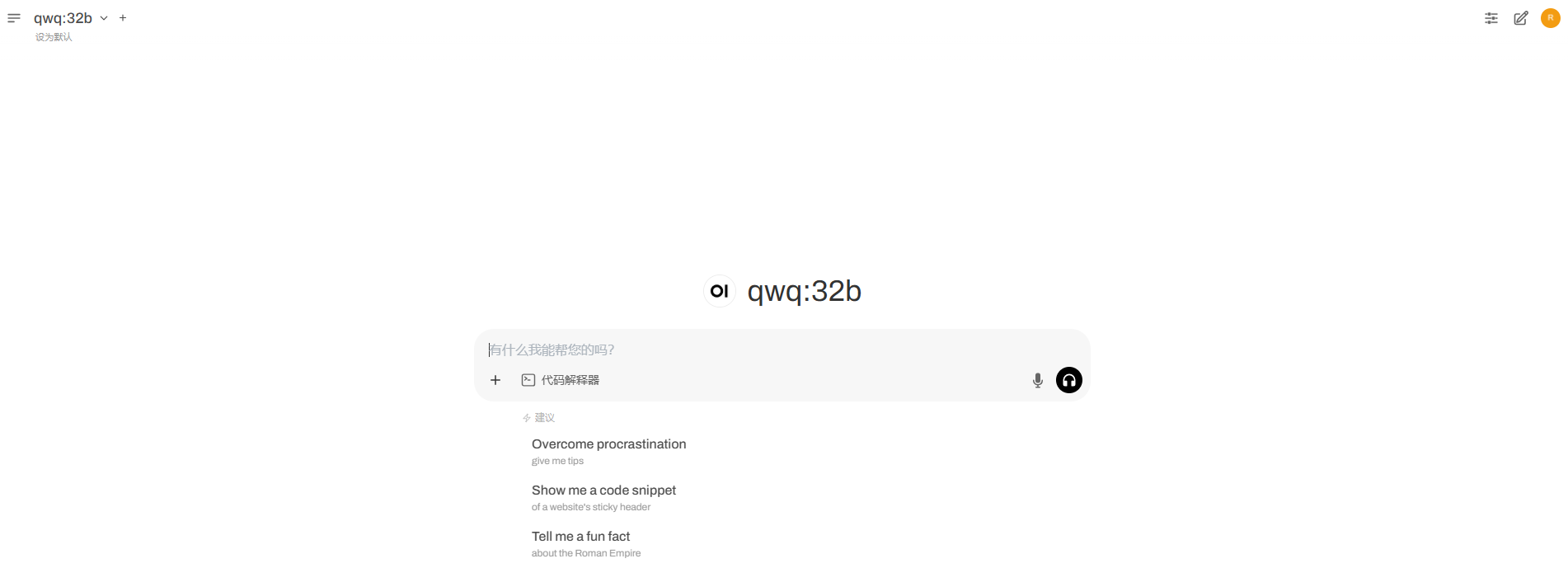
初次问答加载较慢,第二次开始正常。
@苍耳阿猫 认证作者
认证作者
认证作者
镜像信息
已使用44 次
运行时长
51 H
镜像大小
70GB
最后更新时间
2026-02-04
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.1
应用
JupyterLab: 8888
版本
v1.0
2026-02-04