 0
0v-jepa2镜像部署教程
镜像简介
本镜像是基于Meta AI开源的V-JEPA 2(视频联合嵌入预测架构)构建的先进视频表征学习框架,专为自监督视频理解与时空信息建模设计。无需大量标注即可学习视频中的复杂动态与物理规律,适用于机器人感知、自动驾驶、智能监控及具身智能研究等前沿领域,为开发者与研究者提供高效、强大的视频分析基础模型。
1.1 环境要求
- Python 3.11+
- PyTorch 2.0+
- CUDA 11.8+(推荐)
- 至少16GB GPU内存(ViT-L模型)
1.2 快速安装
# 克隆项目
git clone https://github.com/facebookresearch/vjepa2.git
cd jepa
# 创建虚拟环境
conda create -n vjepa python=3.11
conda activate vjepa
# 安装PyTorch (根据CUDA版本选择)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 安装项目依赖
pip install -r requirements.txt
# 安装项目
pip install -e .

1.3 使用torch.hub加载预训练模型
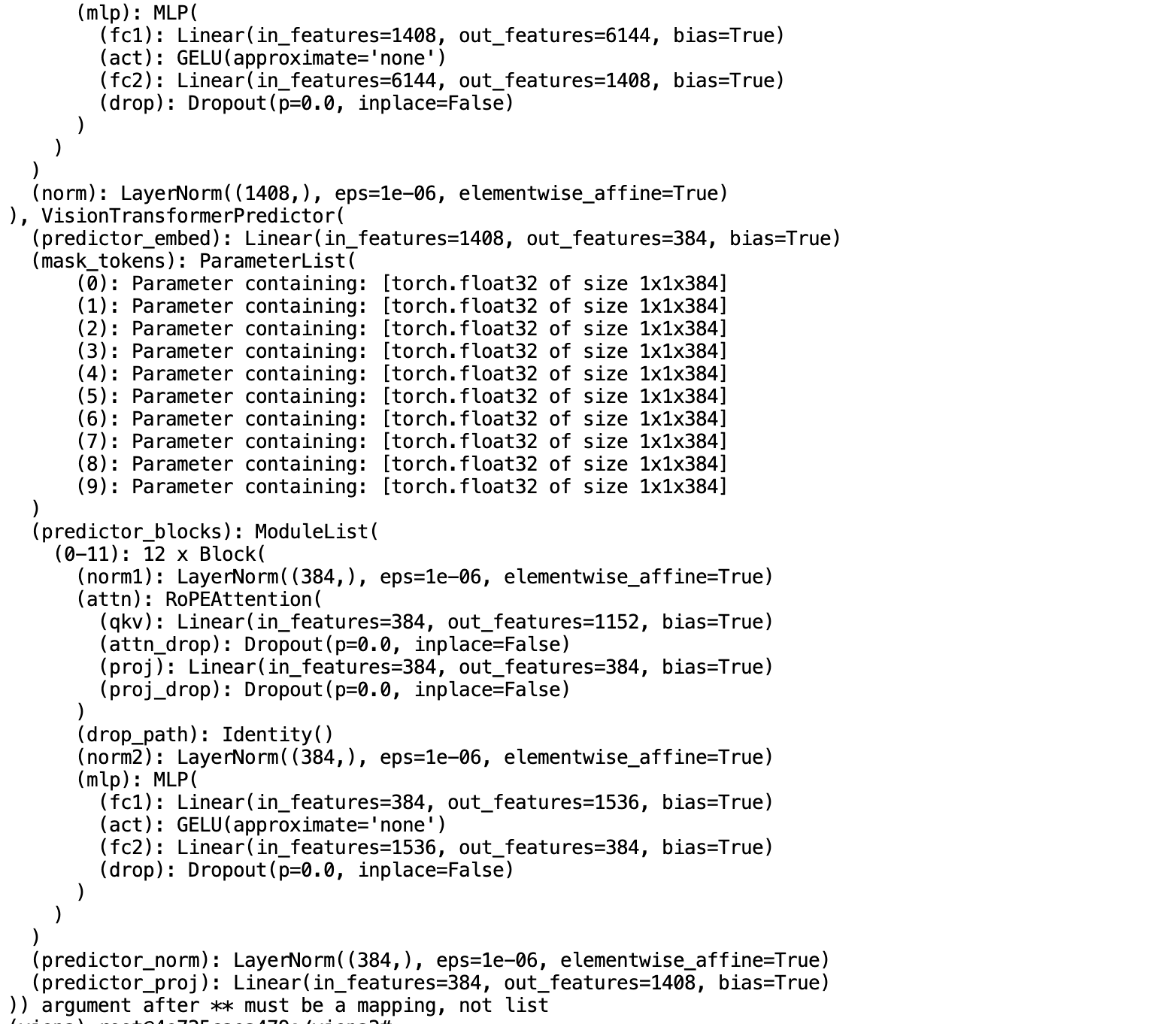
V-JEPA 2提供了通过PyTorch Hub的便捷加载方式,这是目前推荐的使用方法,无需手动下载代码或配置复杂的环境。通过torch.hub.load可以直接获取预训练的编码器和预测器,大大简化了使用流程。
import torch
import numpy as np
# 步骤1:通过PyTorch Hub加载预训练模型
# 可选模型: vjepa2_vit_large, vjepa2_vit_huge, vjepa2_vit_giant, vjepa2_vit_giant_384
encoder = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_vit_giant')
processor = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_preprocessor')
# 步骤2:加载动作条件预测器(用于机器人应用)
vjepa2_encoder, vjepa2_ac_predictor = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_ac_vit_giant')
# 步骤3:准备视频数据(添加输入验证和转换)
video_tensor = torch.randn(1, 64, 3, 256, 256) # [B, T, C, H, W]
# 确保C=3,如果形状不正确,进行转换
if video_tensor.shape[2] != 3: # 检查通道数
video_tensor = torch.cat([video_tensor] * 3, dim=2)[:1, :64, :3, :, :] # 强制转换为3通道
# 步骤4:使用预处理器处理视频数据
inputs = processor(video_tensor)
# 步骤5:特征提取
with torch.no_grad():
# 获取视频特征
features = encoder(**inputs)
print(f"Encoder output shape: {features.shape}")
print("V-JEPA 2模型加载和推理完成")
1.4 使用HuggingFace Transformers
V-JEPA 2也支持通过HuggingFace Transformers库使用,这提供了更标准化的API接口和更好的生态系统集成。
from transformers import AutoVideoProcessor, AutoModel
import torch
import numpy as np
# 步骤1:从HuggingFace加载模型和处理器
hf_repo = "facebook/vjepa2-vitg-fpc64-256"
# 其他可选模型:
# facebook/vjepa2-vitl-fpc64-256
# facebook/vjepa2-vith-fpc64-256
# facebook/vjepa2-vitg-fpc64-256
# facebook/vjepa2-vitg-fpc64-384
model = AutoModel.from_pretrained(hf_repo)
processor = AutoVideoProcessor.from_pretrained(hf_repo)
# 步骤2:准备视频数据(64帧,256x256分辨率)
video = np.random.rand(64, 256, 256, 3).astype(np.float32) # T x H x W x C
# 步骤3:预处理视频
inputs = processor(video, return_tensors="pt").to(model.device)
# 步骤4:模型推理
with torch.no_grad():
outputs = model(**inputs)
# V-JEPA 2编码器输出
encoder_features = outputs.last_hidden_state
print(f"Encoder features shape: {encoder_features.shape}")
# V-JEPA 2预测器输出
if hasattr(outputs, 'predictor_output'):
predictor_features = outputs.predictor_output.last_hidden_state
print(f"Predictor features shape: {predictor_features.shape}")
print("HuggingFace Transformers推理完成")

1.5 视频分类应用示例
对于已经在特定数据集上微调的模型,可以直接用于视频分类任务,这展示了V-JEPA 2在下游应用中的强大能力。
from transformers import AutoVideoProcessor, AutoModelForVideoClassification
import torch
import numpy as np
# 步骤1:加载在Something-Something-V2上微调的分类模型
model = AutoModelForVideoClassification.from_pretrained("facebook/vjepa2-vitl-fpc16-256-ssv2")
processor = AutoVideoProcessor.from_pretrained("facebook/vjepa2-vitl-fpc16-256-ssv2")
# 步骤2:准备视频数据(16帧用于分类)
video = np.random.rand(16, 256, 256, 3).astype(np.float32)
# 步骤3:预处理和推理
inputs = processor(video, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
# 步骤4:获取预测结果
top5_indices = logits.topk(5).indices[0]
top5_probs = torch.softmax(logits, dim=-1).topk(5).values[0]
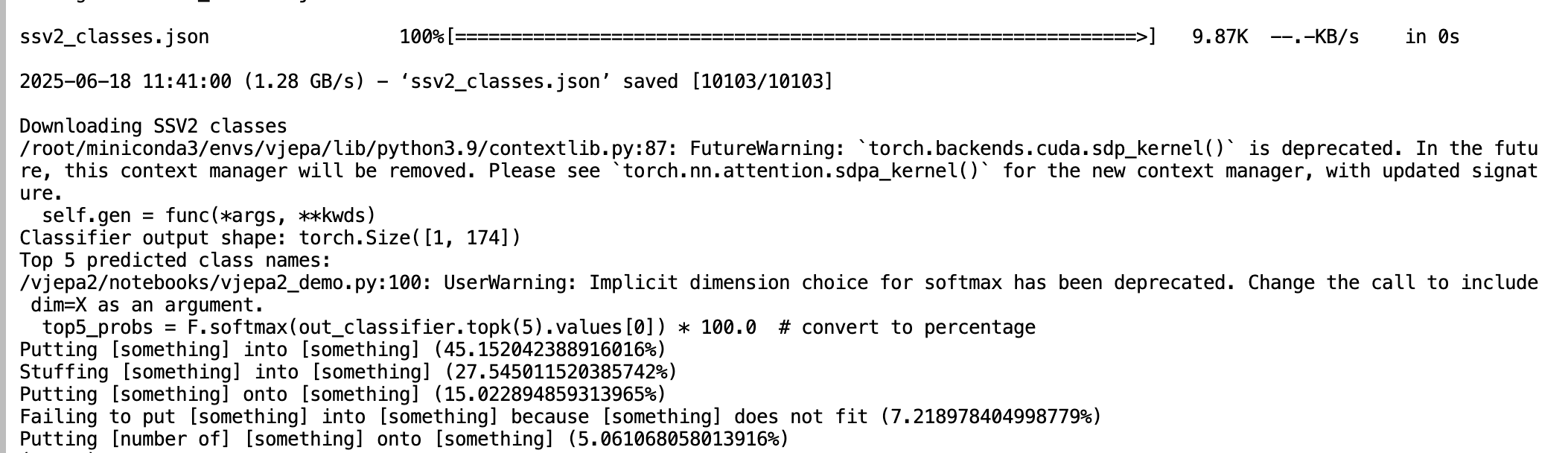
print("Top 5 预测类别:")
for idx, prob in zip(top5_indices, top5_probs):
class_name = model.config.id2label[idx.item()]
print(f" - {class_name}: {prob:.3f}")
 这些使用示例展现了V-JEPA 2在实际应用中的便捷性和强大功能,如果想学习官方的例子可以在
这些使用示例展现了V-JEPA 2在实际应用中的便捷性和强大功能,如果想学习官方的例子可以在vjepa2/notebooks/vjepa2_demo.py中。
该脚本假定已下载模型检查点,因此您需要下载模型权重并更新脚本中的相应路径。例如:
wget https://dl.fbaipublicfiles.com/vjepa2/vitg-384.pt -P /models/
wget https://dl.fbaipublicfiles.com/vjepa2/evals/ssv2-vitg-384-64x2x3.pt -P /models/
# Then update your model paths in vjepa2_demo.py.
pt_model_path = /models/vitg-384.pt
classifier_model_path = /models/ssv2-vitg-384-64x2x3.pt
# Then run the script (assumes your machine has a GPU)
python notebooks/vjepa2_demo.py
从PyTorch Hub的一键加载到HuggingFace生态系统的无缝集成,再到具体的视频分类应用,每个示例都体现了该架构的工程化成熟度和实用价值。V-JEPA 2的核心优势在于其多层次的可用性:研究人员可以通过torch.hub快速获取预训练模型进行特征提取,开发者可以利用HuggingFace标准化接口轻松集成到现有项目中,而应用开发者则可以直接使用微调后的分类模型解决实际业务问题。这种从基础研究到产业应用的完整链条体现了V-JEPA 2不仅在技术创新上的突破,更在工程实现和生态建设方面的成功,为自监督视频理解技术的广泛应用奠定了坚实基础。
 认证作者
认证作者