LiveTalking
LiveTalking镜像提供实时交互数字人解决方案,支持ERNerf、MuseTalk、Wav2Lip,实现单张人脸照片驱动的超低延迟(<100ms)唇形同步、表情及头部运动控制。
 123
1230元/小时
v2.2
v2.1
v2.0
v1.6
v1.5
v1.4
v1.3
v1.2
v1.1
LiveTalking数字人镜像
注意!该镜像华北一C机器不可用,请选择华北二和上海机器!
镜像简介
本镜像提供名为LiveTalking的实时交互式数字人解决方案,支持ERNerf、MuseTalk、wav2lip、ultralight-digitalhuman等多种前沿技术,能够实现流畅的流式音视频对话与驱动。适用于虚拟直播、在线客服、远程互动演示及实时内容创作等场景,为用户提供免费、高效且高度拟真的实时数字人生成与交互体验。 Github: https://github.com/lipku/LiveTalking 使用文档:https://doc.livetalking.ai
镜像使用指南
一、快速使用
1. 先选择GPU型号,再点击“立即部署”
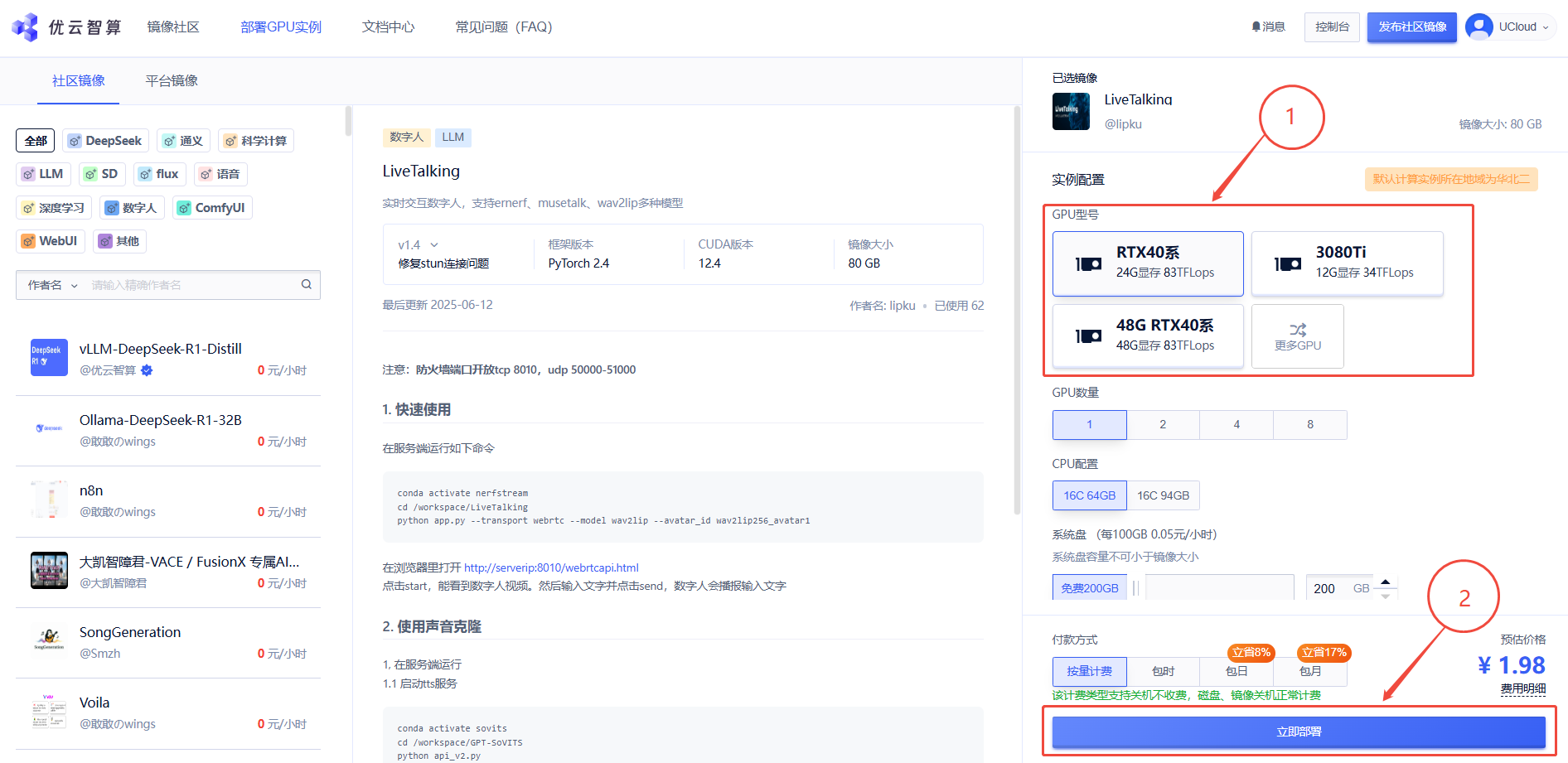
2. 待实例初始化完成后,配置防火墙端口,开放udp50000-51000,具体操作可参考第三部分。然后在浏览器里打开 http://serverip:8010/index.html
serverip可以在控制台-基础网络(外)复制得到

进入web界面后点击开始连接,能看到数字人视频。然后输入文字并点击发送,数字人会播报输入文字
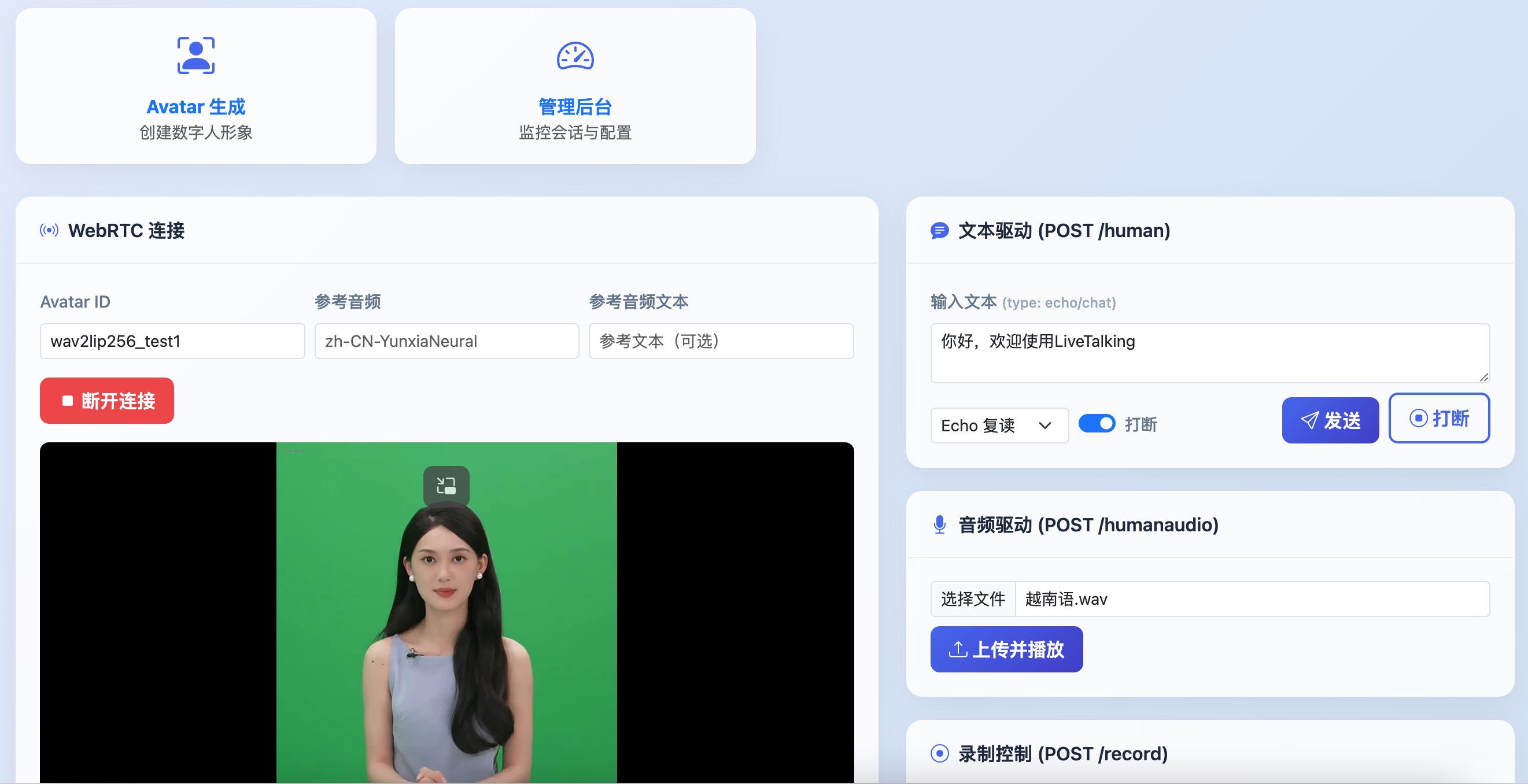
二、使用musetalk模型
1. 在控制台-应用中打开“JupyterLab”

2. 进入JupyterLab后,新建一个终端Terminal,在Terminal中运行如下命令
conda activate livetalking
cd /root/LiveTalking
python app.py --transport webrtc --model musetalk --avatar_id musetalk_avatar1
如果遇到报错提示端口已被占用,ps aux | grep python 找到自启动的livetalking两个进程kill。 也可以删除/start.d/livetalking.sh,重启后把自启动服务关闭
三、防火墙设置教程
使用该镜像时可能出现数字人无法显示的问题,此时需检查防火墙设置是否正确,防火墙端口需开放tcp 8010,udp 50000-51000
1. 如图所示,在控制台-操作中打开配置防火墙
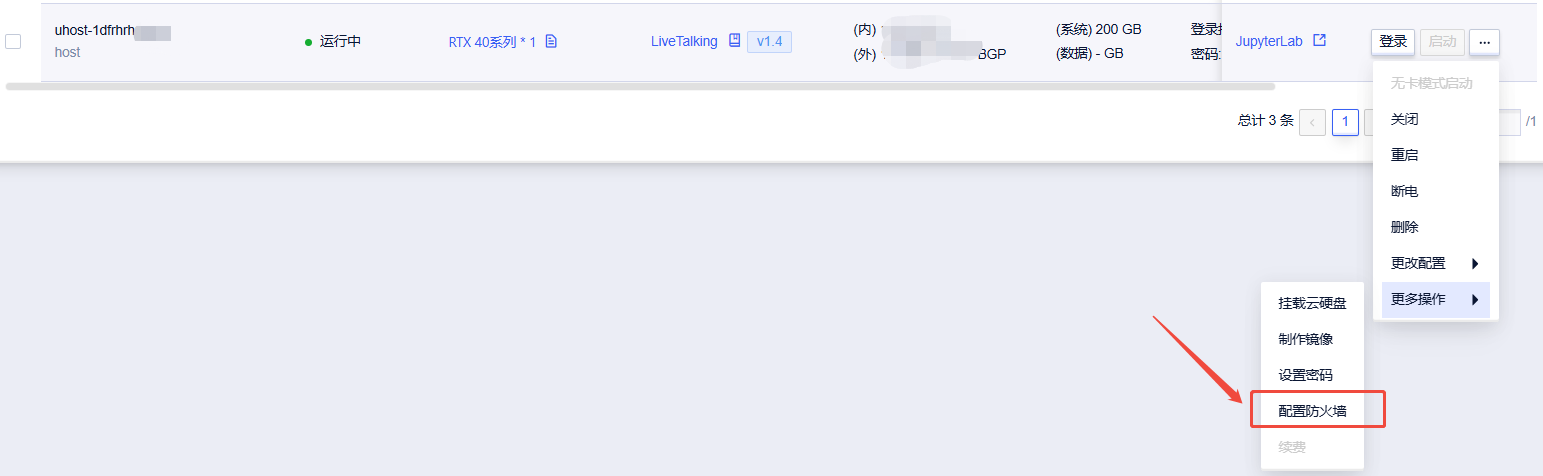
2. 点击“编辑防火墙规则”
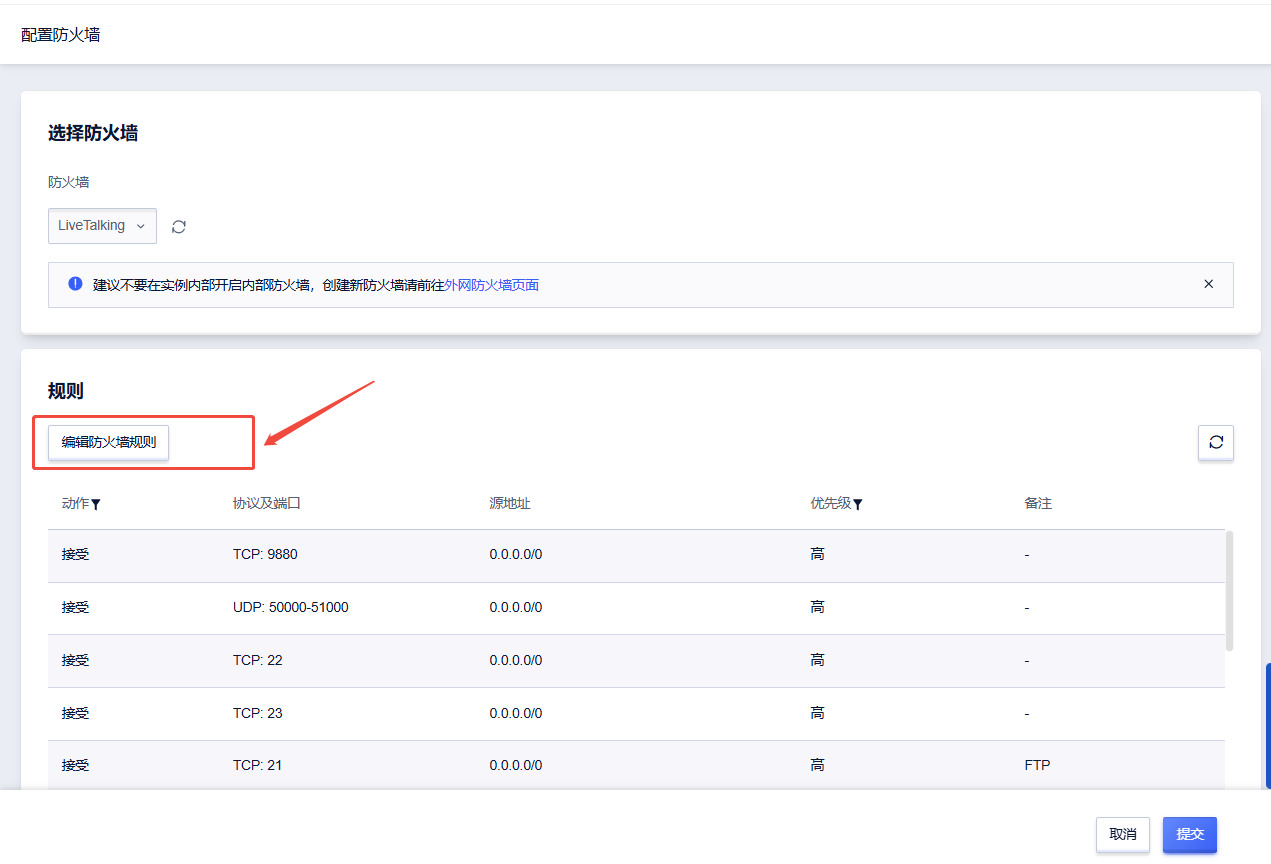
3. 点击“添加规则”
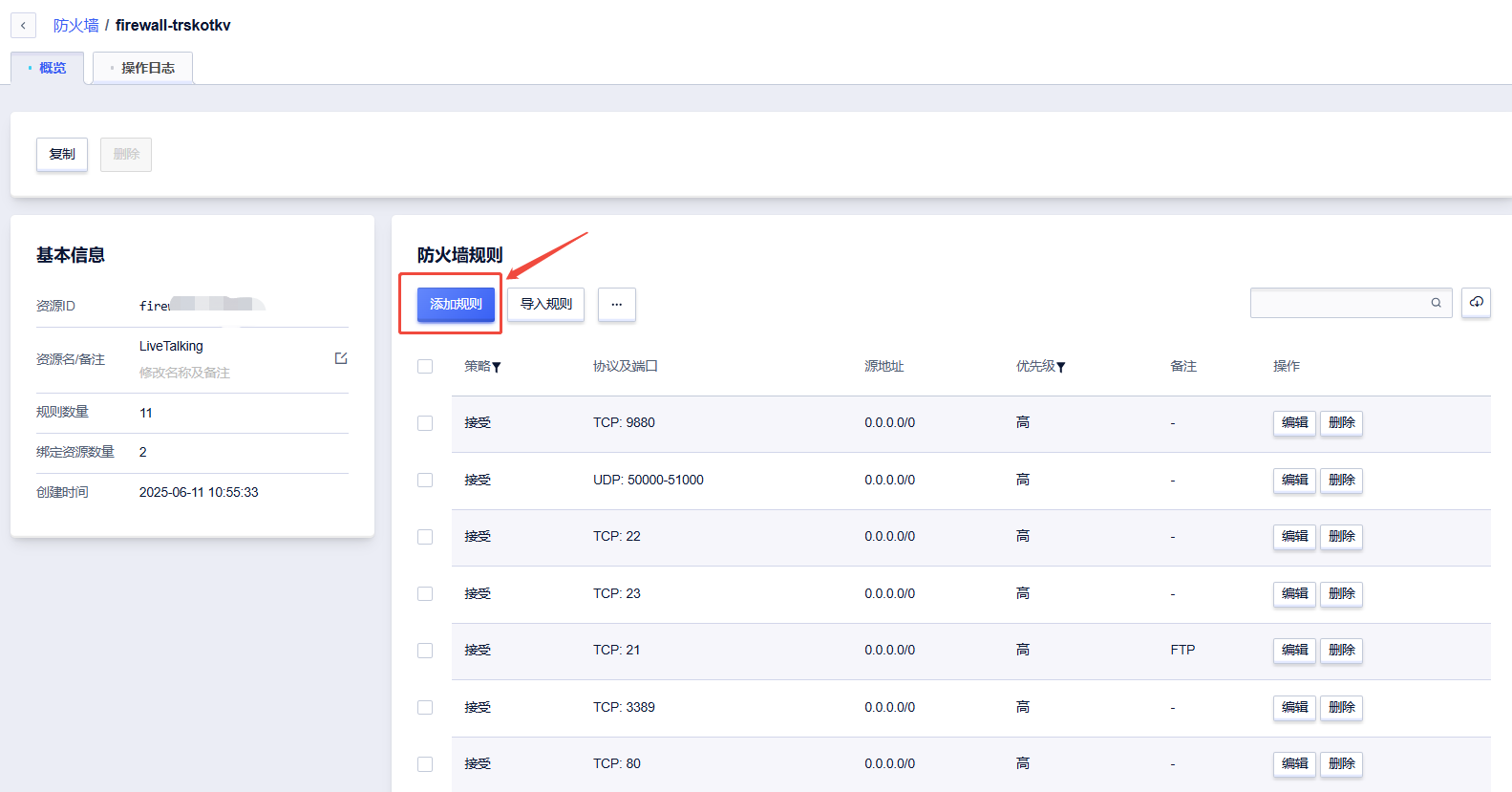
4. 选择指定端口TCP,输入端口号8010;选择全端口UDP,输入端口号50000-51000;再点击下一步
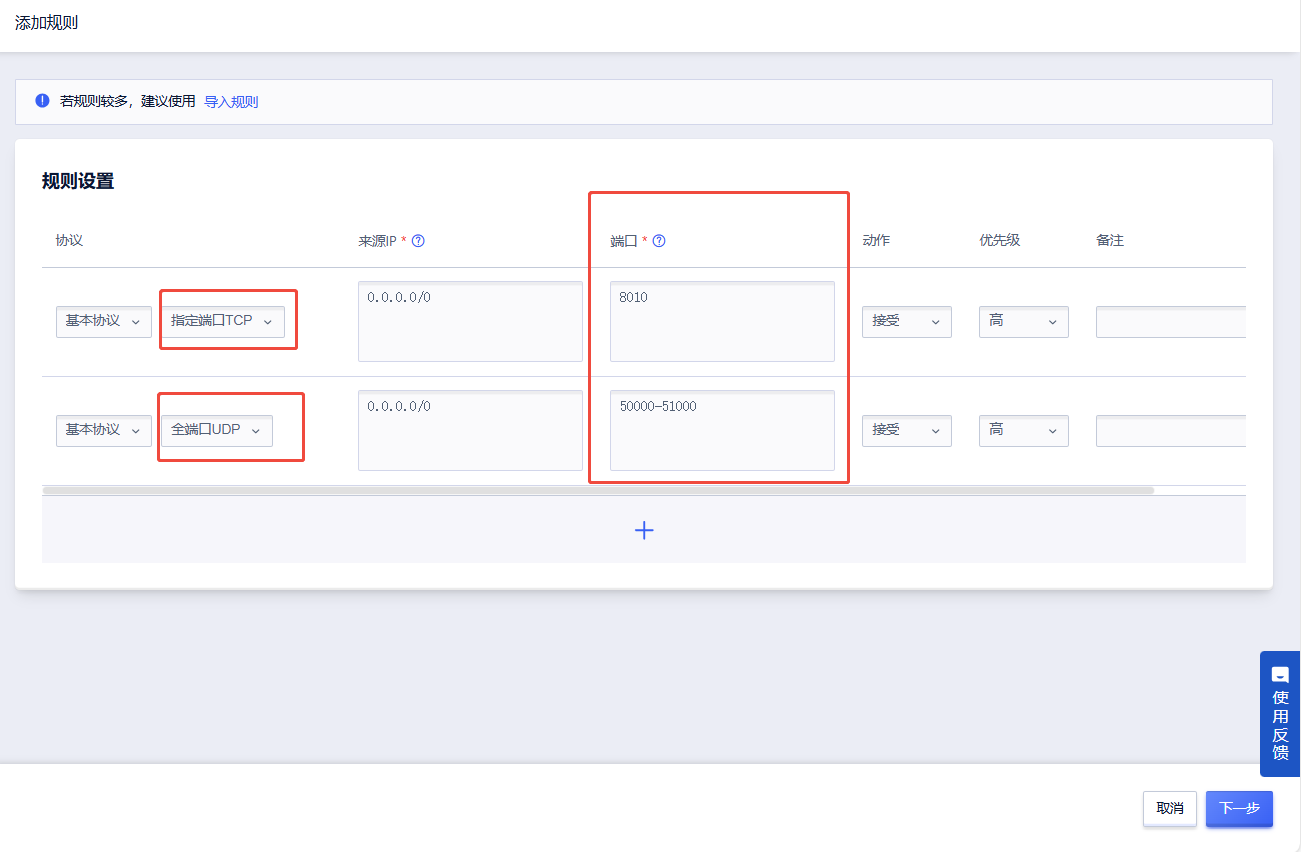
5. 检查端口号,点击“确认”后即添加成功,可以回到防火墙规则中确认是否添加
@lipku 认证作者
认证作者
认证作者

镜像信息
已使用475 次
运行时长
3602 H
 推荐
推荐 支持自启动
支持自启动镜像大小
50GB
最后更新时间
2026-06-16
支持卡型
3090RTX40系RTX50系48G RTX40系3080Ti2080Ti2080P40A100H20A800
+11
框架版本
CUDA版本
13.0
应用
JupyterLab: 8888
自定义开放端口
8010
+1
版本
v2.2
2026-06-16
v2.1
2026-04-13
v2.0
2026-04-01
查看全部