 8
8HuMo: 基于协作多模态条件的人体中心视频生成
镜像简介
HuMo是一款统一的、以人体为中心的AI视频生成框架,支持从文本、图像、姿态等多模态条件输入,智能生成高质量、连贯的人物动作视频。该工具专注于数字人动画、舞蹈合成、虚拟内容创作等应用场景,实现对人体动作与外观的精细化控制,为动态视频制作提供高效、灵活的一体化解决方案。
前言
二次开发仓库:https://github.com/Ikaros-521/HuMo
使用说明
48G以上显存显卡实例启动
打开JupyterLab
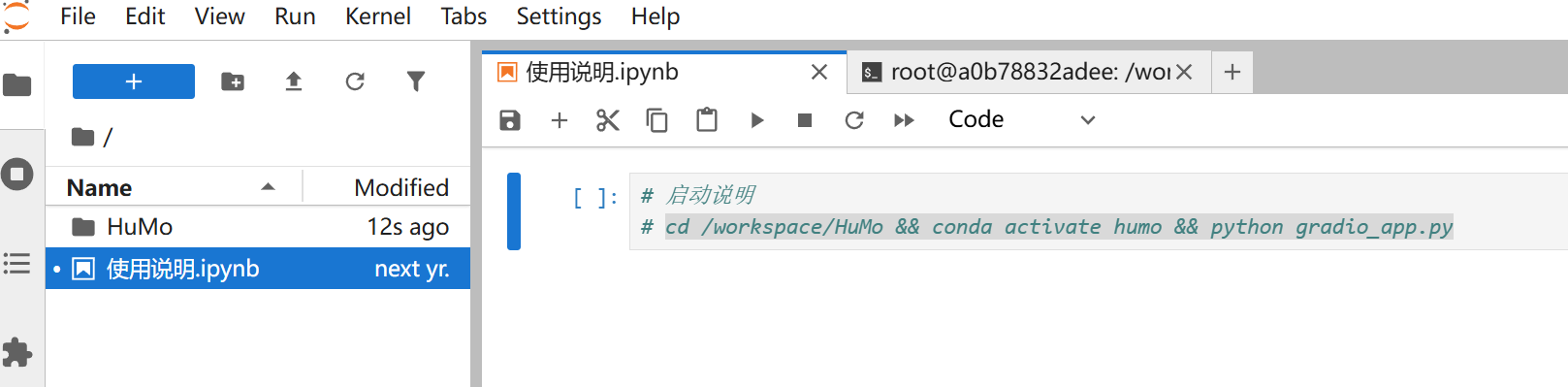 打开使用说明复制命令
打开使用说明复制命令
打开终端粘贴命令运行即可。

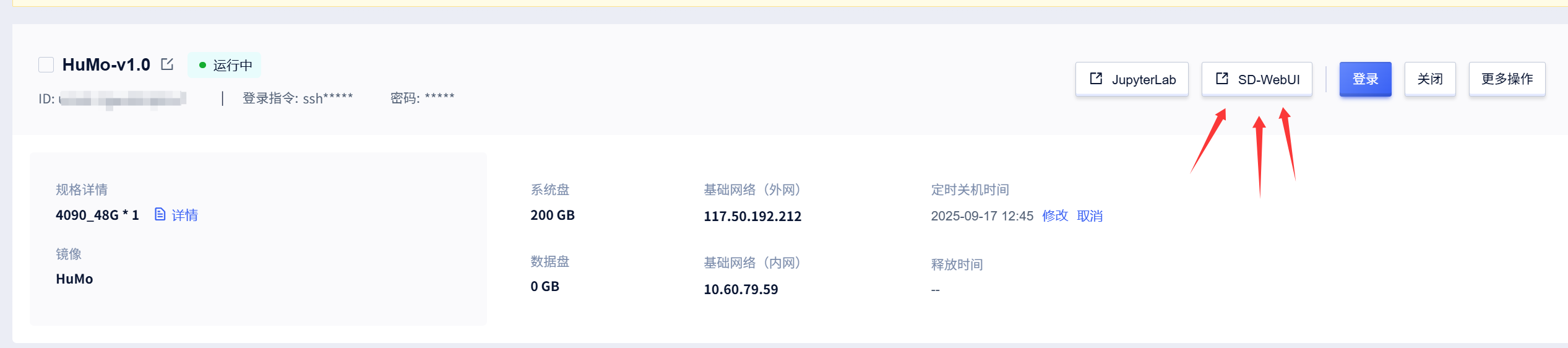
回到实例页面,点击webui跳转使用
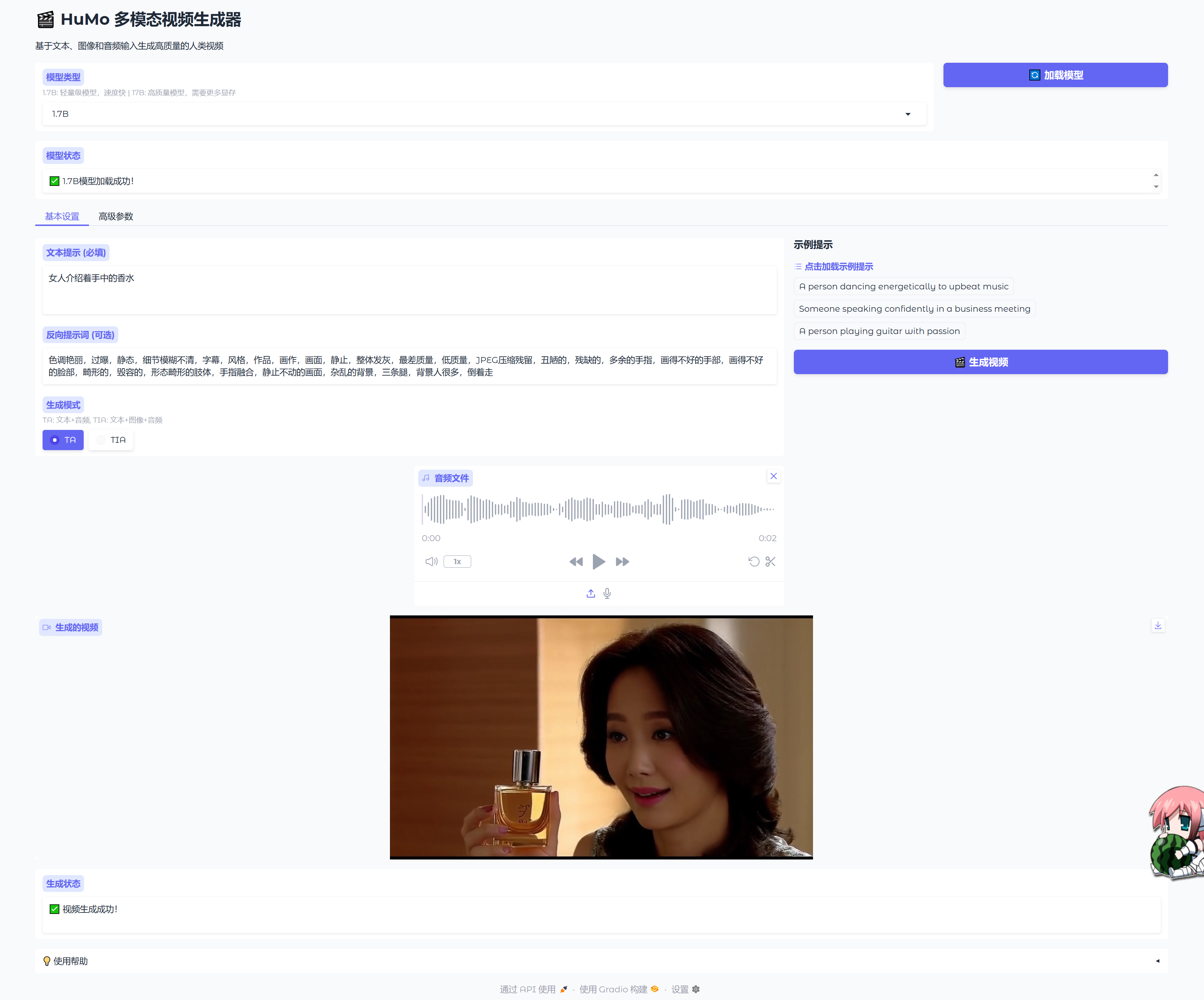
效果参考
交流
AI群:273215887
粉丝群:587663288
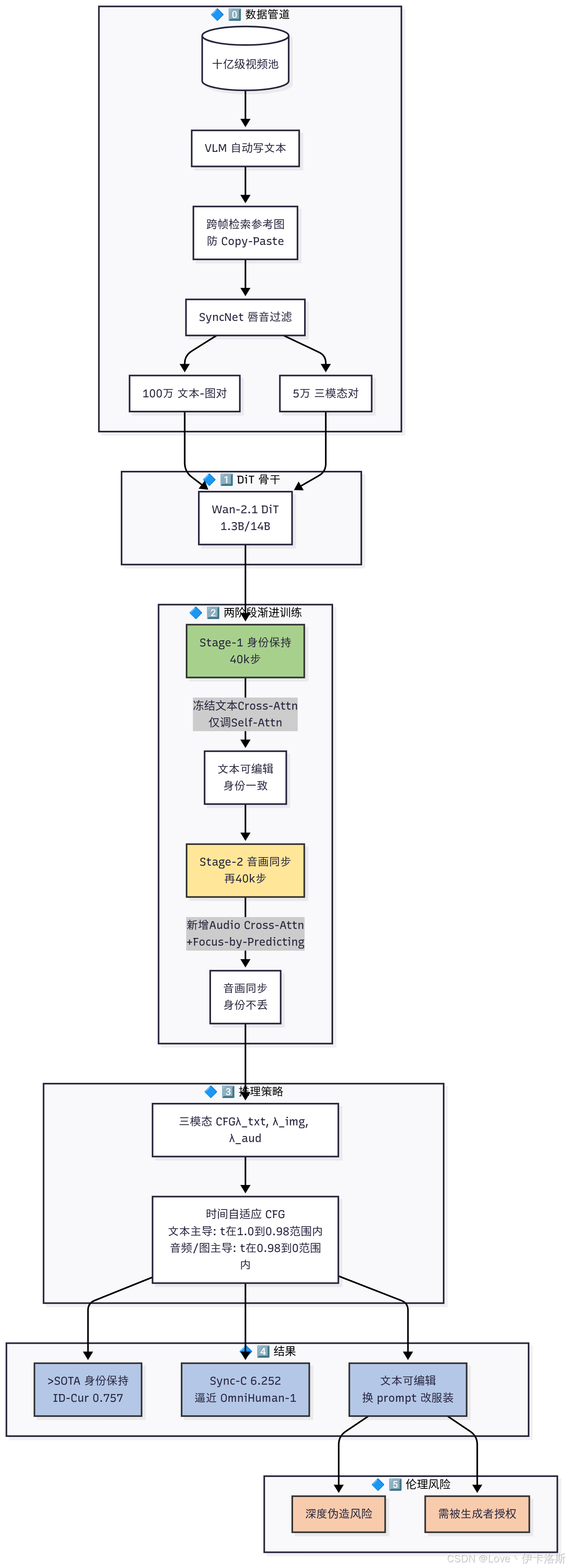
详细版
🧠 论文核心目标
HuMo 的目标是:
从文本、参考图像和音频中生成语义一致、身份一致、音画同步的高质量人类视频。
🔍 两个主要挑战
论文指出当前方法面临的两个核心问题:
| 挑战 | 描述 |
|---|---|
| 1. 数据稀缺 | 缺乏成对的高质量三模态数据(文本+图像+音频),尤其是身份一致、音画同步的数据。 |
| 2. 多模态协同困难 | 同时控制文本语义、图像身份、音频同步非常困难,容易出现“此消彼长”的现象(比如图像控制强了,音频同步就变差)。 |
🧩 HuMo 的核心解决方案
✅ 1. 多模态数据处理流程(解决数据稀缺)
作者构建了一个三阶段数据处理管道,从大规模视频数据中自动提取并配对文本、图像和音频:
- 阶段0:用视觉语言模型(VLM)给视频生成详细文本描述。
- 阶段1:从十亿级图像库中检索与视频中人物语义一致但视觉不同的参考图像(避免复制粘贴问题)。
- 阶段2:筛选出音画同步良好的视频片段(通过语音识别+唇形对齐分析)。
最终构建了一个高质量三模态配对数据集:
- 100万条「文本+参考图像」数据(Stage 1)
- 5万条「文本+参考图像+音频」数据(Stage 2)
✅ 2. 渐进式多模态训练策略(解决协同困难)
HuMo 采用两阶段训练,每阶段聚焦一个子任务,逐步引入新模态,避免能力冲突:
| 阶段 | 任务 | 输入 | 关键技术 |
|---|---|---|---|
| Stage 1 | 身份保持 | 文本 + 参考图像 | 最小侵入式图像注入: - 不改动 DiT 结构 - 只微调 self-attention 层 - 参考图像 latent 放在视频 latent 后面,避免误解为起始帧 |
| Stage 2 | 音画同步 | 文本 + 参考图像 + 音频 | 预测式聚焦策略: - 引入音频 cross-attention - 训练一个「面部区域预测器」引导模型关注人脸区域 - 不硬裁剪,保留全身建模能力 |
✅ 训练时采用渐进任务权重:初期以身份保持为主(80%),逐步过渡到音画同步(50%),避免能力遗忘。
✅ 3. 时间自适应无分类器引导(Time-Adaptive CFG)
在推理阶段,HuMo 提出了一种动态调整引导权重的策略:
- 早期时间步(1.0 → 0.98):以文本和图像为主,建立语义结构和布局。
- 后期时间步(0.98 → 0):加强音频和图像控制,提升身份一致性和音画同步。
这种策略显著提升了多模态协同效果,避免了静态 CFG 的“顾此失彼”。
📊 实验结果
✅ 主观保持任务(文本+图像)
| 方法 | 文本一致性 | 身份一致性 | 视频质量 |
|---|---|---|---|
| Kling 1.6 | 0.645 | 0.501 | 0.714 |
| Phantom | 0.608 | 0.677 | 0.649 |
| HuMo-17B | 0.657 | 0.757 | 0.687 |
✅ HuMo 在文本跟随、身份保持、视频质量上全面超越现有方法,甚至支持4人身份同时保持。
✅ 音画同步任务(文本+图像+音频)
| 方法 | 音画同步↑ | 身份一致性↑ | 视频质量↑ |
|---|---|---|---|
| OmniHuman-1 | 7.784 | 0.682 | 4.503 |
| FantasyTalking | 6.209 | 0.652 | 4.444 |
| HuMo-17B | 8.577 | 0.718 | 4.537 |
✅ HuMo 在音画同步上接近甚至超越商业闭源方法(如 OmniHuman-1),且支持文本编辑,而 I2V 方法无法做到。
🧪 消融实验(Ablation Study)
| 去掉某模块 | 影响 |
|---|---|
| 全参数微调 | 文本能力和视频质量大幅下降 |
| 非渐进训练 | 身份一致性下降,模态冲突严重 |
| 去掉面部预测器 | 音画同步下降,唇形对齐变差 |
🎬 应用场景展示
- 文本编辑能力:同一参考图像,不同文本提示可改变服装、配饰、妆容,身份不变。
- 影视级重拍:用 HuMo 重拍《权力的游戏》场景,仅用一个演员头像+文本+音频,生成高质量片段。
⚠️ 伦理风险
作者也明确指出:
- 可能被用于深度伪造(deepfake)或非自愿内容生成。
- 必须获得被生成者同意,并建立使用规范与检测机制。
✅ 总结一句话
HuMo 是目前首个在「文本+图像+音频」三模态协同人类视频生成任务中,实现高质量、强控制、可扩展的统一框架。
下面用一张图帮你梳理 HuMo 的核心架构和训练流程,并重点解释几个关键术语。
简化版
🎯 一句话看懂 HuMo 的怎么训练的
🔍 1. 阶段 0:文本怎么来?——用视觉语言模型(VLM)给视频写“剧本”
✅ 输入:一个视频片段
✅ 输出:一段详细文本描述(包括人物、动作、场景)
🔍 2. 阶段 1:图像怎么用?——从图库里“找不同”但语义一致的人脸
✅ 核心挑战:避免直接复制粘贴
如果直接把参考图 latent 拼进视频,模型会误以为这是“第一帧”,导致:
- 人物身份虽然一致,但服装、妆容、配饰无法修改
- 文本控制能力弱(比如“穿红外套”无法生成)
🔍 3. 阶段 2:音频怎么用?——让“嘴动”对上“声音”
✅ 核心挑战:音画同步
传统方法:
- 把音频 mel-spectrogram 直接映射到整张图 → 容易嘴形崩坏
- 把音频特征全局平均池化 → 丢失局部细节
✅ HuMo 方法:预测式聚焦
- 训练一个“面部掩码预测器”,让模型自己去“找嘴在哪”
- 只在该区域做音画同步 → 精度高、鲁棒性强
🎯 时间自适应 CFG(Time-Adaptive CFG)
✅ 核心思想:不同阶段用不同“指挥棒”
- 早期(1.0 → 0.98):文本+图像 → 先搭好“骨架”
- 后期(0.98 → 0):再让音频去“对嘴形”
- 动态调整引导权重,避免“一刀切”
📈 举个例子:重拍《权力的游戏》
- 输入:龙妈的头像 + 文本“穿红外套” + 音频“Dracarys”
- HuMo 输出:
- ✅ 人物身份保持(还是龙妈)
- ✅ 外套变成红色(文本控制)
- ✅ 嘴形同步说“Dracarys”
- ✅ 背景、光照、姿势一致
✅ 总结一句话(给非技术读者)
HuMo 就像一个导演:
先让“编剧”(文本)写剧本,再让“演员”(图像)按剧本演,最后让“配音”(音频)对上嘴形。
而不是像传统方法那样,直接把“演员照片”贴到“配音”上。
HuMo: 基于协作多模态条件的人体中心视频生成
![]()

Liyang Chen * , Tianxiang Ma * , Jiawei Liu, Bingchuan Li † ,
Zhuowei Chen, Lijie Liu, Xu He, Gen Li, Qian He, Zhiyong Wu §
* 共同第一作者, † 项目负责人, § 通讯作者
清华大学 | 字节跳动智能创作团队

🔥 最新动态
- HuMo最佳实践指南即将发布,敬请期待。
- 2025年9月16日:🔥🔥 我们发布了1.7B权重,可在32G GPU上8分钟内生成480P视频。虽然视觉质量比17B模型略低,但音视频同步效果几乎不受影响。
- 2025年9月13日:🔥🔥 17B模型已集成到ComfyUI-Wan,可在NVIDIA 3090 GPU上运行。感谢kijai的更新!
- 2025年9月10日:🔥🔥 我们发布了17B权重和推理代码。
- 2025年9月9日:我们发布了HuMo的项目主页和技术报告。
✨ 核心特性
HuMo是一个统一的、以人为中心的视频生成框架,旨在从多模态输入(包括文本、图像和音频)生成高质量、细粒度且可控的人体视频。它支持强大的文本提示跟随、一致的主体保持和同步的音频驱动动作。
- 文本-图像视频生成 - 使用文本提示结合参考图像自定义角色外观、服装、妆容、道具和场景。
- 文本-音频视频生成 - 仅从文本和音频输入生成音频同步视频,无需图像参考,实现更大的创作自由度。
- 文本-图像-音频视频生成 - 通过结合文本、图像和音频指导实现更高级别的定制和控制。
📑 待办事项
- 发布论文
- HuMo-17B检查点
- HuMo-1.7B检查点
- 推理代码
- 文本-图像输入
- 文本-音频输入
- 文本-图像-音频输入
- 多GPU推理
- HuMo电影级生成最佳实践指南
- 生成无面权游演示的提示词
- 训练数据
⚡️ 快速开始
安装环境
conda create -n humo python=3.11
conda activate humo
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
pip install flash_attn==2.6.3
pip install -r requirements.txt
conda install -c conda-forge ffmpeg
模型准备
| 模型 | 下载链接 | 说明 |
|---|---|---|
| HuMo-17B | 🤗 Huggingface | 支持480P和720P |
| HuMo-1.7B | 🤗 Huggingface | 32G GPU轻量版 |
| Wan-2.1 | 🤗 Huggingface | VAE和文本编码器 |
| Whisper-large-v3 | 🤗 Huggingface | 音频编码器 |
| Audio separator | 🤗 Huggingface | 去除背景噪音(可选) |
使用huggingface-cli下载模型:
huggingface-cli download Wan-AI/Wan2.1-T2V-1.3B --local-dir ./weights/Wan2.1-T2V-1.3B
huggingface-cli download bytedance-research/HuMo --local-dir ./weights/HuMo
huggingface-cli download openai/whisper-large-v3 --local-dir ./weights/whisper-large-v3
huggingface-cli download huangjackson/Kim_Vocal_2 --local-dir ./weights/audio_separator
运行多模态条件视频生成
我们的模型兼容480P和720P分辨率。720P推理将获得更好的质量。
一些建议
- 请按照test_case.json中的描述准备您的文本、参考图像和音频。
- 我们使用FSDP + 序列并行支持多GPU推理。
- 模型在25 FPS的97帧视频上训练。生成超过97帧的视频可能会降低性能。我们将提供用于更长生成的新检查点。
配置HuMo
可以通过修改generate.yaml配置文件来自定义HuMo的行为和输出。 以下参数控制生成长度、视频分辨率以及文本、图像和音频输入的平衡:
generation:
frames: <int> # 生成视频的帧数
scale_a: <float> # 音频指导强度。越高 = 音频运动同步越好
scale_t: <float> # 文本指导强度。越高 = 更好地遵循文本提示
mode: "TA" # 输入模式:"TA"表示文本+音频;"TIA"表示文本+图像+音频
height: 720 # 视频高度(例如720或480)
width: 1280 # 视频宽度(例如1280或832)
dit:
sp_size: <int> # 序列并行大小。设置为使用的GPU数量
diffusion:
timesteps:
sampling:
steps: 50 # 去噪步数。较低(30-40) = 更快生成
1. 文本-音频输入
bash scripts/infer_ta.sh # 使用17B模型推理
bash scripts/infer_ta_1_7B.sh # 使用1.7B模型推理
2. 文本-图像-音频输入
bash scripts/infer_tia.sh # 使用17B模型推理
bash scripts/infer_tia_1_7B.sh # 使用1.7B模型推理
致谢
我们的工作建立在并受到几个优秀开源项目的极大启发,包括Phantom、SeedVR、MEMO、Hallo3、OpenHumanVid、OpenS2V-Nexus、ConsisID和Whisper。我们衷心感谢这些项目的作者和贡献者慷慨分享他们优秀的代码和想法。
⭐ 引用
如果HuMo对您有帮助,请帮助为仓库点⭐。
如果您认为这个项目对您的研究有用,请考虑引用我们的论文。
BibTeX
@misc{chen2025humo,
title={HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning},
author={Liyang Chen and Tianxiang Ma and Jiawei Liu and Bingchuan Li and Zhuowei Chen and Lijie Liu and Xu He and Gen Li and Qian He and Zhiyong Wu},
year={2025},
eprint={2509.08519},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.08519},
}
📧 联系方式
如果您对这个开源项目有任何意见或问题,请提出新的issue或联系Liyang Chen和Tianxiang Ma。
