 16
16👉🏻 IndexTTS2 👈🏻
镜像简介
本镜像搭载IndexTTS2语音合成与克隆系统,作为开源领先的Zero-Shot解决方案,无需训练即可根据短音频样本快速复刻音色并生成高质量语音。支持高拟真的语音合成与克隆,适用于虚拟助手、有声内容创作、语音交互开发等场景,为用户提供零训练门槛、高效便捷的本地化语音AI生成体验。
使用教程
该镜像支持自启动,使用该镜像部署GPU,实例启动完成后,大概2分钟左右,点击SD-WebUi按钮即可

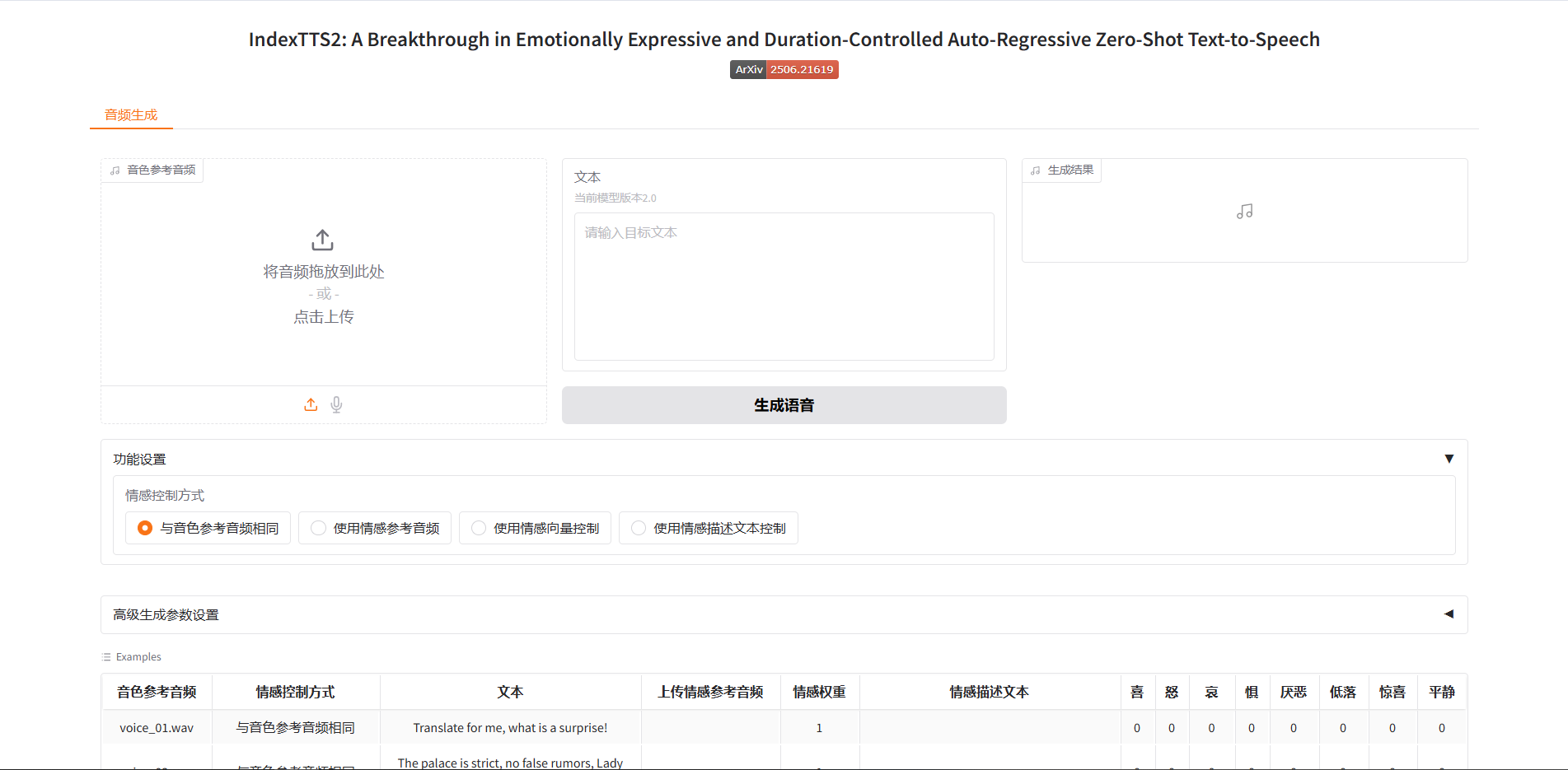
WebUI界面示例
模型介绍
IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech
Abstract
Existing autoregressive large-scale text-to-speech (TTS) models have advantages in speech naturalness, but their token-by-token generation mechanism makes it difficult to precisely control the duration of synthesized speech. This becomes a significant limitation in applications requiring strict audio-visual synchronization, such as video dubbing.
This paper introduces IndexTTS2, which proposes a novel, general, and autoregressive model-friendly method for speech duration control.
The method supports two generation modes: one explicitly specifies the number of generated tokens to precisely control speech duration; the other freely generates speech in an autoregressive manner without specifying the number of tokens, while faithfully reproducing the prosodic features of the input prompt.
Furthermore, IndexTTS2 achieves disentanglement between emotional expression and speaker identity, enabling independent control over timbre and emotion. In the zero-shot setting, the model can accurately reconstruct the target timbre (from the timbre prompt) while perfectly reproducing the specified emotional tone (from the style prompt).
To enhance speech clarity in highly emotional expressions, we incorporate GPT latent representations and design a novel three-stage training paradigm to improve the stability of the generated speech. Additionally, to lower the barrier for emotional control, we designed a soft instruction mechanism based on text descriptions by fine-tuning Qwen3, effectively guiding the generation of speech with the desired emotional orientation.
Finally, experimental results on multiple datasets show that IndexTTS2 outperforms state-of-the-art zero-shot TTS models in terms of word error rate, speaker similarity, and emotional fidelity. Audio samples are available at: IndexTTS2 demo page.
Tips: Please contact the authors for more detailed information. For commercial usage and cooperation, please contact indexspeech@bilibili.com.
Feel IndexTTS2
IndexTTS2: The Future of Voice, Now Generating
(https://www.bilibili.com/video/BV136a9zqEk5)
Click the image to watch the IndexTTS2 introduction video.
Contact
QQ Group:553460296(No.1) 663272642(No.4)
Discord:https://discord.gg/uT32E7KDmy
Email:indexspeech@bilibili.com
You are welcome to join our community! 🌏
欢迎大家来交流讨论!
📣 Updates
2025/09/08🔥🔥🔥 We release IndexTTS-2 to the world!- The first autoregressive TTS model with precise synthesis duration control, supporting both controllable and uncontrollable modes. This functionality is not yet enabled in this release.
- The model achieves highly expressive emotional speech synthesis, with emotion-controllable capabilities enabled through multiple input modalities.
2025/05/14🔥🔥 We release IndexTTS-1.5, significantly improving the model's stability and its performance in the English language.2025/03/25🔥 We release IndexTTS-1.0 with model weights and inference code.2025/02/12🔥 We submitted our paper to arXiv, and released our demos and test sets.
🖥️ Neural Network Architecture
Architectural overview of IndexTTS2, our state-of-the art speech model:
The key contributions of IndexTTS2 are summarized as follows:
- We propose a duration adaptation scheme for autoregressive TTS models. IndexTTS2 is the first autoregressive zero-shot TTS model to combine precise duration control with natural duration generation, and the method is scalable for any autoregressive large-scale TTS model.
- The emotional and speaker-related features are decoupled from the prompts, and a feature fusion strategy is designed to maintain semantic fluency and pronunciation clarity during emotionally rich expressions. Furthermore, a tool was developed for emotion control, utilizing natural language descriptions for the benefit of users.
- To address the lack of highly expressive speech data, we propose an effective training strategy, significantly enhancing the emotional expressiveness of zeroshot TTS to State-of-the-Art (SOTA) level.
- We will publicly release the code and pre-trained weights to facilitate future research and practical applications.
Model Download
| HuggingFace | ModelScope |
|---|---|
| 😁 IndexTTS-2 | IndexTTS-2 |
| IndexTTS-1.5 | IndexTTS-1.5 |
| IndexTTS | IndexTTS |
Usage Instructions
⚙️ Environment Setup
The Git-LFS plugin must also be enabled on your current user account:
git lfs install
- Download this repository:
git clone https://github.com/index-tts/index-tts.git && cd index-tts
git lfs pull # download large repository files
- Install the uv package manager. It is required for a reliable, modern installation environment.
TIP
Quick & Easy Installation Method:
There are many convenient ways to install the uv command on your computer.
Please check the link above to see all options. Alternatively, if you want
a very quick and easy method, you can install it as follows:
pip install -U uv
WARNING
We only support the uv installation method. Other tools, such as conda
or pip, don't provide any guarantees that they will install the correct
dependency versions. You will almost certainly have random bugs, error messages,
missing GPU acceleration, and various other problems if you don't use uv.
Please do not report any issues if you use non-standard installations, since
almost all such issues are invalid.
Furthermore, uv is up to 115x faster
than pip, which is another great reason to embrace the new industry-standard
for Python project management.
- Install required dependencies:
We use uv to manage the project's dependency environment. The following command
will install the correct versions of all dependencies into your .venv directory:
uv sync --all-extras
If the download is slow, please try a local mirror, for example China:
uv sync --all-extras --default-index "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple"
TIP
Available Extra Features:
--all-extras: Automatically adds every extra feature listed below. You can remove this flag if you want to customize your installation choices.--extra webui: Adds WebUI support (recommended).--extra deepspeed: Adds DeepSpeed support (faster inference).
IMPORTANT
Important (Windows): The DeepSpeed library may be difficult to install for
some Windows users. You can skip it by removing the --all-extras flag. If you
want any of the other extra features above, you can manually add their specific
feature flags instead.
Important (Linux/Windows): If you see an error about CUDA during the installation, please ensure that you have installed NVIDIA's CUDA Toolkit version 12.8 (or newer) on your system.
- Download the required models:
Download via huggingface-cli:
uv tool install "huggingface_hub[cli]"
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
Or download via modelscope:
uv tool install "modelscope"
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
NOTE
In addition to the above models, some small models will also be automatically downloaded when the project is run for the first time. If your network environment has slow access to HuggingFace, it is recommended to execute the following command before running the code:
除了以上模型外,项目初次运行时还会自动下载一些小模型,如果您的网络环境访问HuggingFace的速度较慢,推荐执行:
export HF_ENDPOINT="https://hf-mirror.com"
🖥️ Checking PyTorch GPU Acceleration
If you need to diagnose your environment to see which GPUs are detected, you can use our included utility to check your system:
uv run tools/gpu_check.py
🔥 IndexTTS2 Quickstart
🌐 Web Demo
uv run webui.py
Open your browser and visit http://127.0.0.1:7860 to see the demo.
You can also adjust the settings to enable features such as FP16 inference (lower VRAM usage), DeepSpeed acceleration, compiled CUDA kernels for speed, etc. All available options can be seen via the following command:
uv run webui.py -h
Have fun!
📝 Using IndexTTS2 in Python
To run scripts, you must use the uv run <file.py> command to ensure that
the code runs inside your current "uv" environment. It may sometimes also be
necessary to add the current directory to your PYTHONPATH, to help it find
the IndexTTS modules.
Example of running a script via uv:
PYTHONPATH="$PYTHONPATH:." uv run indextts/infer_v2.py
Here are several examples of how to use IndexTTS2 in your own scripts:
- Synthesize new speech with a single reference audio file (voice cloning):
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "Translate for me, what is a surprise!"
tts.infer(spk_audio_prompt='examples/voice_01.wav', text=text, output_path="gen.wav", verbose=True)
- Using a separate, emotional reference audio file to condition the speech synthesis:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "酒楼丧尽天良,开始借机竞拍房间,哎,一群蠢货。"
tts.infer(spk_audio_prompt='examples/voice_07.wav', text=text, output_path="gen.wav", emo_audio_prompt="examples/emo_sad.wav", verbose=True)
- When an emotional reference audio file is specified, you can optionally set
the
emo_alphato adjust how much it affects the output. Valid range is0.0 - 1.0, and the default value is1.0(100%):
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "酒楼丧尽天良,开始借机竞拍房间,哎,一群蠢货。"
tts.infer(spk_audio_prompt='examples/voice_07.wav', text=text, output_path="gen.wav", emo_audio_prompt="examples/emo_sad.wav", emo_alpha=0.9, verbose=True)
- It's also possible to omit the emotional reference audio and instead provide
an 8-float list specifying the intensity of each emotion, in the following order:
[happy, angry, sad, afraid, disgusted, melancholic, surprised, calm]. You can additionally use theuse_randomparameter to introduce stochasticity during inference; the default isFalse, and setting it toTrueenables randomness:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "哇塞!这个爆率也太高了!欧皇附体了!"
tts.infer(spk_audio_prompt='examples/voice_10.wav', text=text, output_path="gen.wav", emo_vector=[0, 0, 0, 0, 0, 0, 0.45, 0], use_random=False, verbose=True)
- Alternatively, you can enable
use_emo_textto guide the emotions based on your providedtextscript. Your text script will then automatically be converted into emotion vectors. You can introduce randomness withuse_random(default:False;Trueenables randomness):
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "快躲起来!是他要来了!他要来抓我们了!"
tts.infer(spk_audio_prompt='examples/voice_12.wav', text=text, output_path="gen.wav", use_emo_text=True, use_random=False, verbose=True)
- It's also possible to directly provide a specific text emotion description
via the
emo_textparameter. Your emotion text will then automatically be converted into emotion vectors. This gives you separate control of the text script and the text emotion description:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "快躲起来!是他要来了!他要来抓我们了!"
emo_text = "你吓死我了!你是鬼吗?"
tts.infer(spk_audio_prompt='examples/voice_12.wav', text=text, output_path="gen.wav", use_emo_text=True, emo_text=emo_text, use_random=False, verbose=True)
Legacy: IndexTTS1 User Guide
You can also use our previous IndexTTS1 model by importing a different module:
from indextts.infer import IndexTTS
tts = IndexTTS(model_dir="checkpoints",cfg_path="checkpoints/config.yaml")
voice = "examples/voice_07.wav"
text = "大家好,我现在正在bilibili 体验 ai 科技,说实话,来之前我绝对想不到!AI技术已经发展到这样匪夷所思的地步了!比如说,现在正在说话的其实是B站为我现场复刻的数字分身,简直就是平行宇宙的另一个我了。如果大家也想体验更多深入的AIGC功能,可以访问 bilibili studio,相信我,你们也会吃惊的。"
tts.infer(voice, text, 'gen.wav')
For more detailed information, see README_INDEXTTS_1_5, or visit the IndexTTS1 repository at index-tts:v1.5.0.
Our Releases and Demos
IndexTTS2: [Paper]; [Demo]; [HuggingFace]
IndexTTS1: [Paper]; [Demo]; [ModelScope]; [HuggingFace]
Acknowledgements
📚 Citation
🌟 If you find our work helpful, please leave us a star and cite our paper.
IndexTTS2:
@article{zhou2025indextts2,
title={IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech},
author={Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, Jingchen Shu},
journal={arXiv preprint arXiv:2506.21619},
year={2025}
}
IndexTTS:
@article{deng2025indextts,
title={IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System},
author={Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, Lu Wang},
journal={arXiv preprint arXiv:2502.05512},
year={2025},
doi={10.48550/arXiv.2502.05512},
url={https://arxiv.org/abs/2502.05512}
}
 认证作者
认证作者
 支持自启动
支持自启动