Wan2.2 S2V 数字人 阿里通义千问出品
Wan2.2 S2V 数字人 阿里通义千问出品 这是一个音频驱动的电影视频生成模型
 17
170元/小时
v1.1
v1.0
Wan2.2-S2V 数字人视频生成模型
镜像简介
Wan2.2-S2V阿里通义千问出品 一个音频驱动的电影视频生成模型,极大地简化了视频制作过程,仅需提供一张静态图片和一段音频,模型便能生成面部表情自然、口型与音频高度一致、肢体动作流畅丝滑的电影级数字人视频。
Wan2.2-S2V支持分钟级长视频稳定生成,不止嘴动,手势、表情、姿态都能动。
使用教程
1. 在镜像详情界面点击“使用该镜像创建实例”
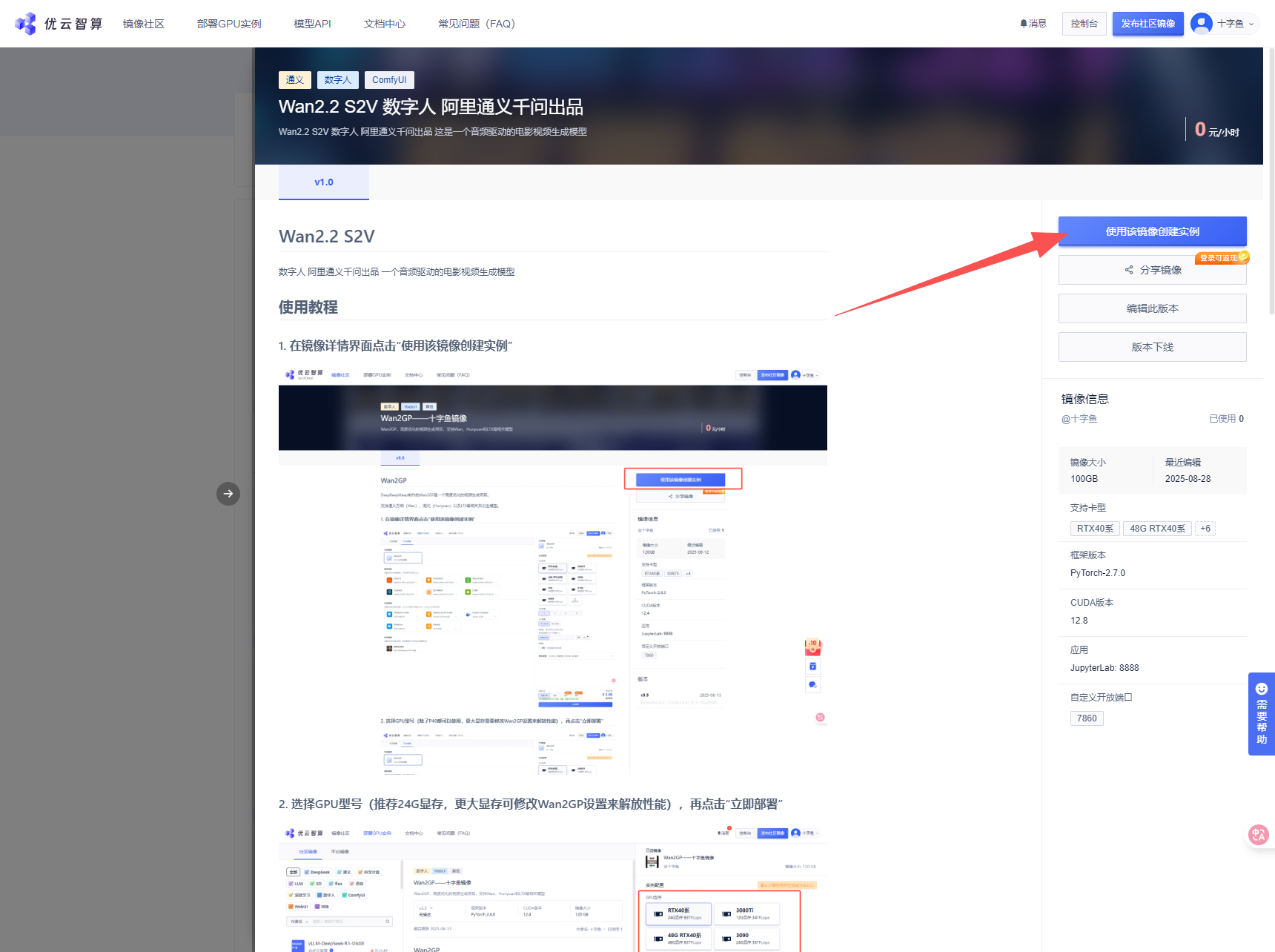
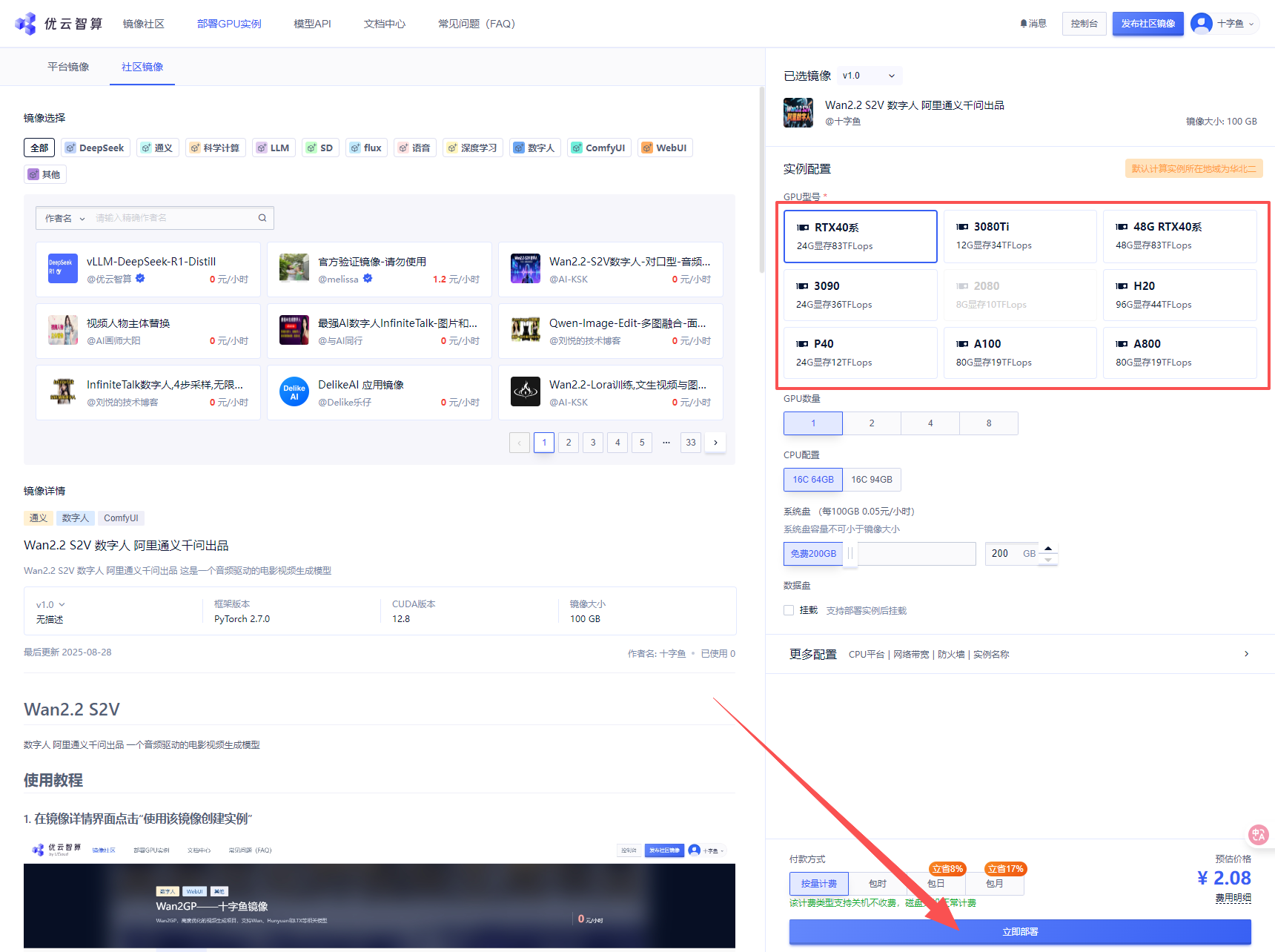
2. 选择GPU型号,再点击“立即部署”
推荐选择4090、4090 48G
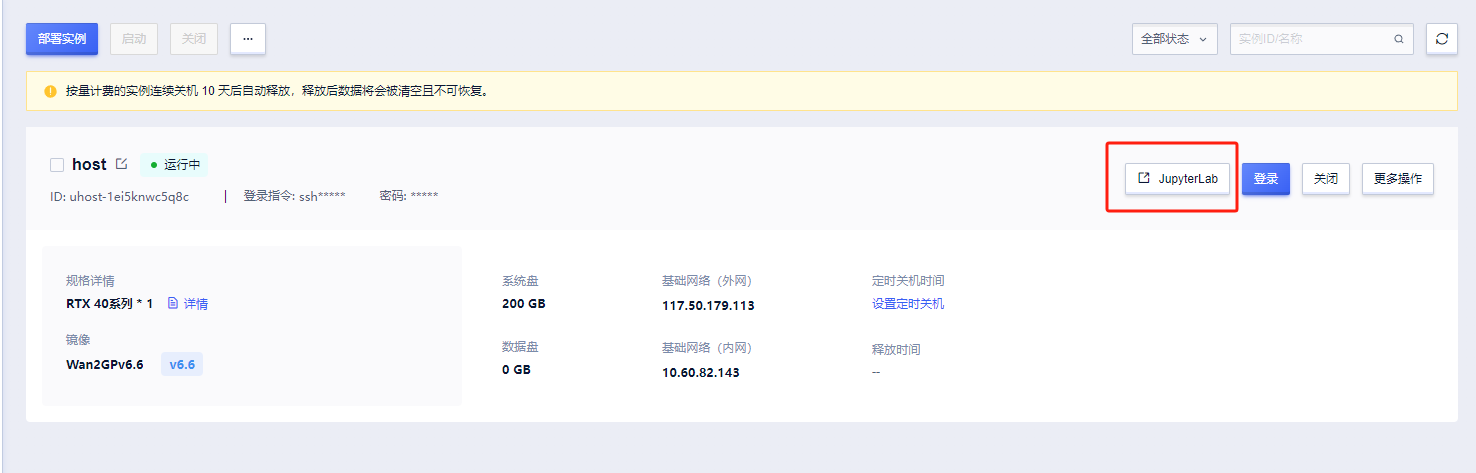
3. 实例启动后,在控制台-应用中点击“JupyterLab”
4.打开JupyterLab页面后,按照数字顺序依次执行——点击快速启动的代码、点击运行按钮

5.如下图所示,则启动成功

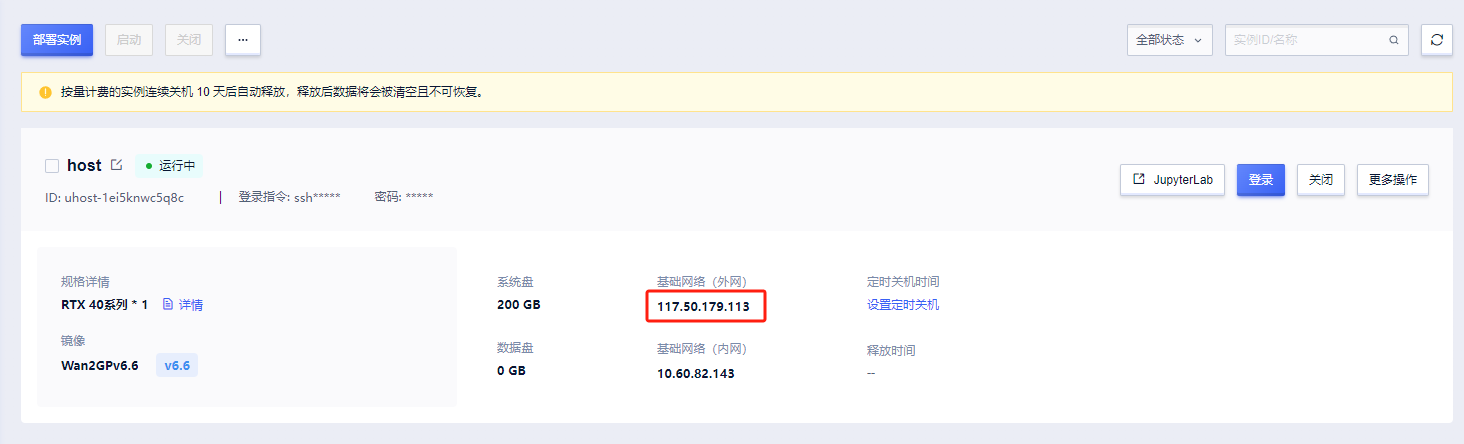
6.输入网址http://{ip地址}:7860访问,{ip地址}替换为下图所示地址
7.浏览器如图显示,就说明启动成功了

8.提示
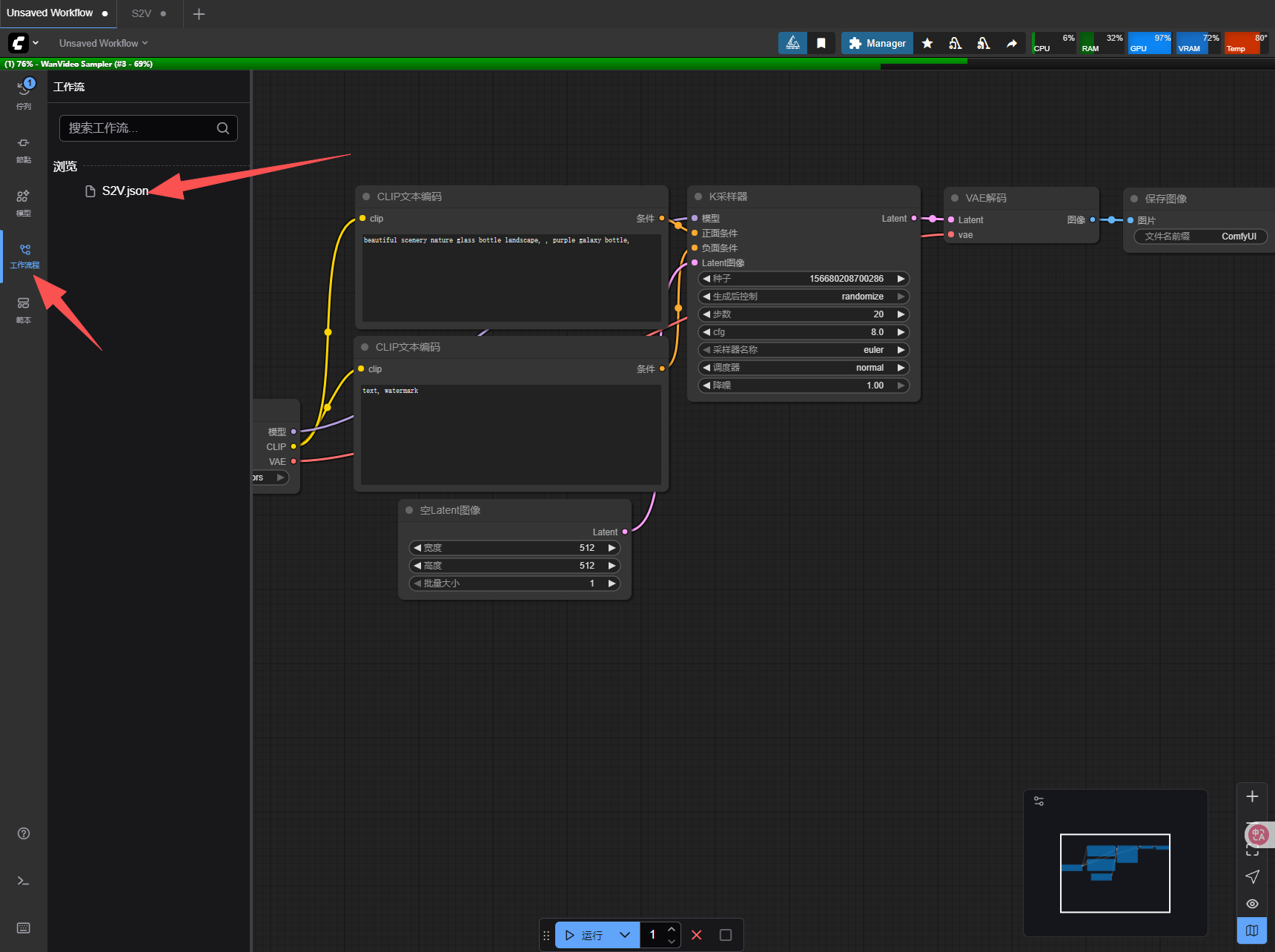
8.1 跑ComfyUI时,工作流可以在工作流程中找到
十字鱼-镜像作者交流群

@十字鱼 认证作者
认证作者
认证作者
镜像信息
已使用150 次
运行时长
239 H
镜像大小
140GB
最后更新时间
2026-02-02
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
自定义开放端口
7860
+1
版本
v1.1
2026-02-02
v1.0
2026-02-02