musubi-qwen-image lora 训练镜像
最简单占用资源最小的lora训练镜像
 22
220元/小时
v1.0
musubi wan2.2 训练镜像
- 该镜像已经下载所有模型,并且准备了训练数据集
- musubi 官房地址:https://github.com/kohya-ss/musubi-tuner
- 官方训练文档 https://github.com/kohya-ss/musubi-tuner/blob/main/docs/wan.md
有趣的80后程序员-镜像作者交流群

关键步骤说明
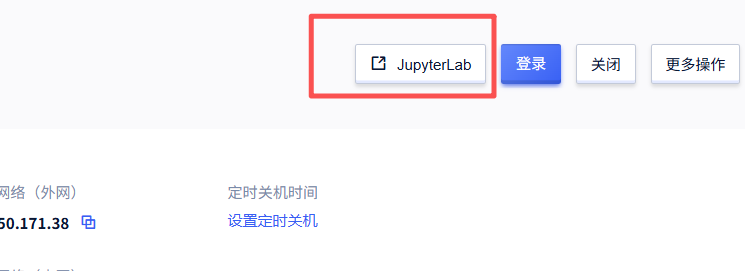
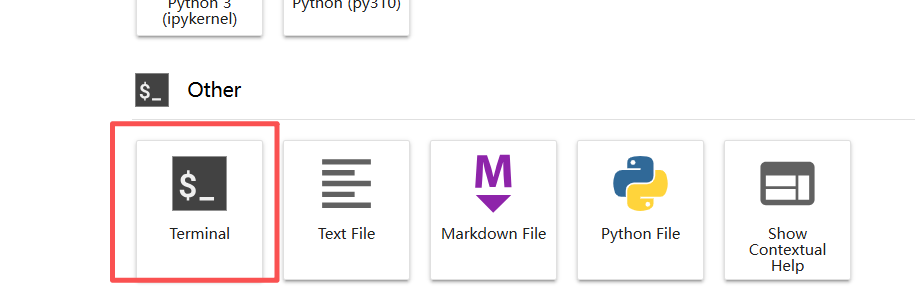
1、打开终端
- 点击jupyterlab点开终端
2、进入musubiTunner主目录
cd /workspace/musubi-tuner/
3、模型下载
- 建议使用huggingface-cli 或 wget 明星进行模型下载
- ditmodel https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/blob/main/split_files/diffusion_models/qwen_image_bf16.safetensors
- textencoder https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/blob/main/split_files/text_encoders/qwen_2.5_vl_7b.safetensors
- vae https://huggingface.co/Qwen/Qwen-Image/blob/main/vae/diffusion_pytorch_model.safetensors
4、数据集前处理
- 数据配置文件格式
[general]
resolution = [1024, 1024]
caption_extension = ".txt"
batch_size = 1
enable_bucket = true
bucket_no_upscale = false
[[datasets]]
image_directory = "dataset/train"
cache_directory = "dataset/cache"
num_repeats = 1
- 图片编码
python src/musubi_tuner/qwen_image_cache_latents.py \
--dataset_config dataset/data_comfy.toml \
--vae models/vae.safetensors
- 提示词编码
python src/musubi_tuner/qwen_image_cache_text_encoder_outputs.py \
--dataset_config dataset/data_comfy.toml \
--text_encoder models/qwen_2.5_vl_7b.safetensors \
--batch_size 1
5、模型训练
accelerate launch --num_cpu_threads_per_process 1 --mixed_precision bf16 src/musubi_tuner/qwen_image_train_network.py \
--dit models/qwen_image_bf16.safetensors \
--vae models/vae.safetensors \
--text_encoder models/qwen_2.5_vl_7b.safetensors \
--dataset_config dataset/data_comfy.toml \
--sdpa --mixed_precision bf16 --fp8_base \
--timestep_sampling shift \
--weighting_scheme none --discrete_flow_shift 2.2 \
--optimizer_type adamw8bit --learning_rate 5e-5 --gradient_checkpointing \
--max_data_loader_n_workers 2 --persistent_data_loader_workers \
--network_module networks.lora_qwen_image \
--network_dim 16 \
--max_train_epochs 300 --save_every_n_epochs 25 --seed 42 \
--output_dir output --output_name cendy-qwen-image-lora-v1 \
--blocks_to_swap 20
6、模型转化
python src/musubi_tuner/convert_lora.py --input output/cendy-qwen-image-lora-v1.safetensors --output output/cendy-qwen-image-lora-comfy-v1.safetensors --target other
注意:在具体使用时需要把文件名路径名按照实际情况修改
@有趣的80后程序员 认证作者
认证作者
认证作者
镜像信息
已使用169 次
运行时长
794 H
镜像大小
100GB
最后更新时间
2025-09-09
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.6
应用
JupyterLab: 8888
版本
v1.0
2025-09-09