 4
4ChatTTS项目介绍
一款适用于日常对话的生成式语音模型。
![]()
![]()
![]()
NOTE
注意此版本可能不是最新版,所有内容请以英文版为准。
部署使用视频
简介
NOTE
这个仓库包含算法架构和一些简单的示例。
TIP
由本仓库衍生出的用户端产品,请参见由社区维护的索引仓库 Awesome-ChatTTS。
ChatTTS 是一款专门为对话场景(例如 LLM 助手)设计的文本转语音模型。
支持的语种
- 英语
- 中文
- 敬请期待...
亮点
你可以参考 Bilibili 上的这个视频,了解本项目的详细情况。
- 对话式 TTS: ChatTTS 针对对话式任务进行了优化,能够实现自然且富有表现力的合成语音。它支持多个说话者,便于生成互动式对话。
- 精细的控制: 该模型可以预测和控制精细的韵律特征,包括笑声、停顿和插入语。
- 更好的韵律: ChatTTS 在韵律方面超越了大多数开源 TTS 模型。我们提供预训练模型以支持进一步的研究和开发。
数据集和模型
- 主模型使用了 100,000+ 小时的中文和英文音频数据进行训练。
- HuggingFace 上的开源版本是一个在 40,000 小时数据上进行无监督微调的预训练模型。
路线图
- 开源 4 万小时基础模型和 spk_stats 文件。
- 支持流式语音输出。
- 开源具有多情感控制功能的 4 万小时版本。
- ChatTTS.cpp (欢迎在 2noise 组织中新建仓库)。
免责声明
IMPORTANT
此仓库仅供学术用途。
本项目旨在用于教育和研究目的,不适用于任何商业或法律目的。作者不保证信息的准确性、完整性和可靠性。此仓库中使用的信息和数据仅供学术和研究目的。数据来自公开来源,作者不声称对数据拥有任何所有权或版权。
ChatTTS 是一款强大的文本转语音系统。但是,负责任和道德地使用这项技术非常重要。为了限制 ChatTTS 的使用,我们在 40,000 小时模型的训练过程中添加了少量高频噪声,并使用 MP3 格式尽可能压缩音频质量,以防止恶意行为者将其用于犯罪目的。同时,我们内部训练了一个检测模型,并计划在未来开源它。
联系方式
欢迎随时提交 GitHub issues/PRs。
合作洽谈
如需就模型和路线图进行合作洽谈,请发送邮件至 open-source@2noise.com。
线上讨论
1. 官方 QQ 群
- 群 1, 808364215 (已满)
- 群 2, 230696694 (已满)
- 群 3, 933639842 (已满)
- 群 4, 608667975
2. Discord
点击加入 Discord。
体验教程
克隆仓库
git clone https://github.com/2noise/ChatTTS
cd ChatTTS
安装依赖
1. 直接安装
pip install --upgrade -r requirements.txt
2. 使用 conda 安装
conda create -n chattts
conda activate chattts
pip install -r requirements.txt
可选 : 如果使用 NVIDIA GPU(仅限 Linux),可安装 TransformerEngine。
NOTE
安装过程可能耗时很长。
WARNING
TransformerEngine 的适配目前正在开发中,运行时可能会遇到较多问题。仅推荐出于开发目的安装。
pip install git+https://github.com/NVIDIA/TransformerEngine.git@stable
可选 : 安装 FlashAttention-2 (主要适用于 NVIDIA GPU)
NOTE
支持设备列表详见 Hugging Face Doc.
pip install flash-attn --no-build-isolation
快速启动
1. 先选择GPU型号,再点击”立即部署“
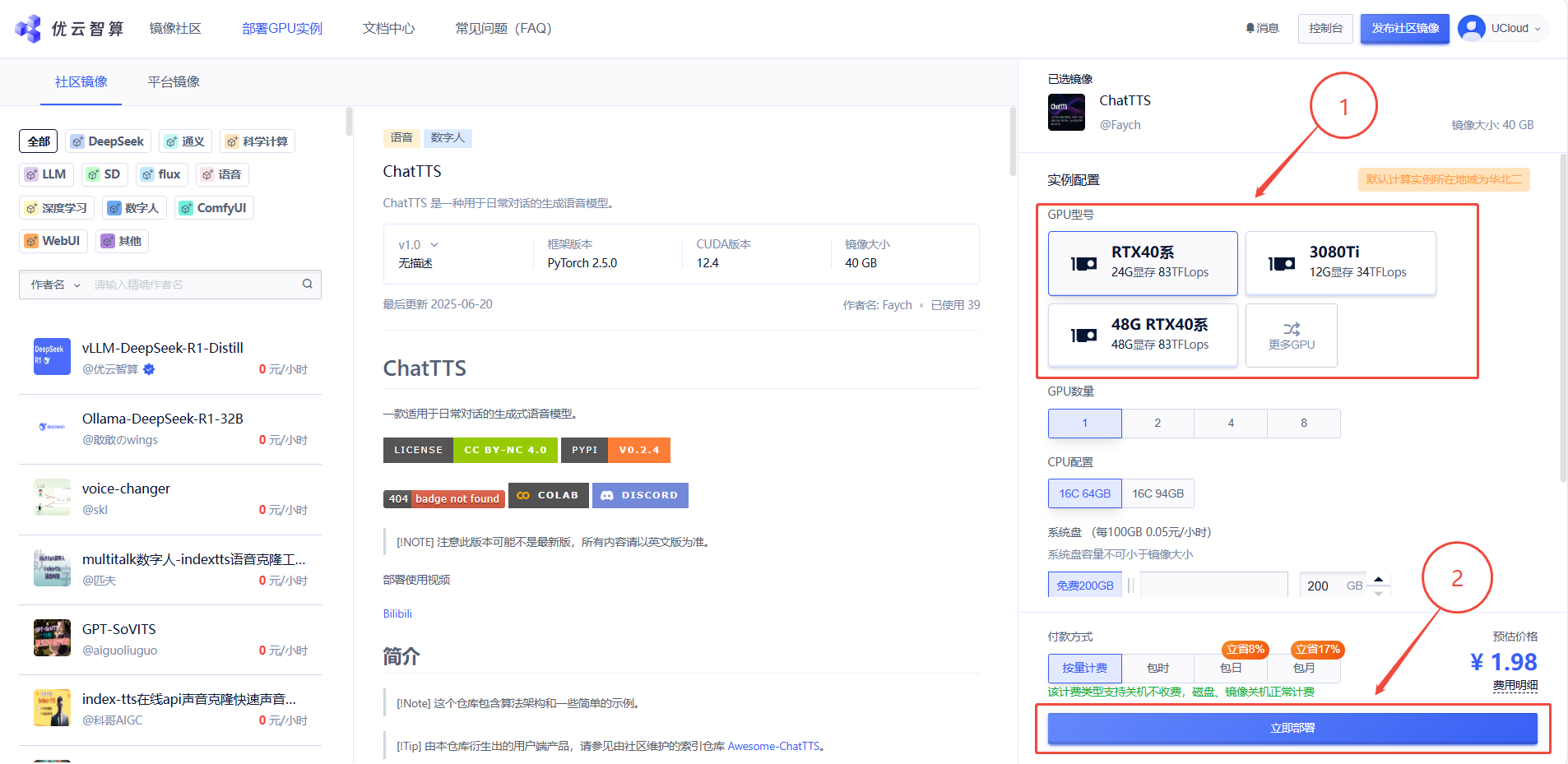
2. 待实例初始化完成后,在控制台-应用中打开”JupyterLab“

3. 进入JupyterLab后,新建一个终端Terminal,在终端中输入以下指令
确保在执行以下命令时,处于项目根目录下。
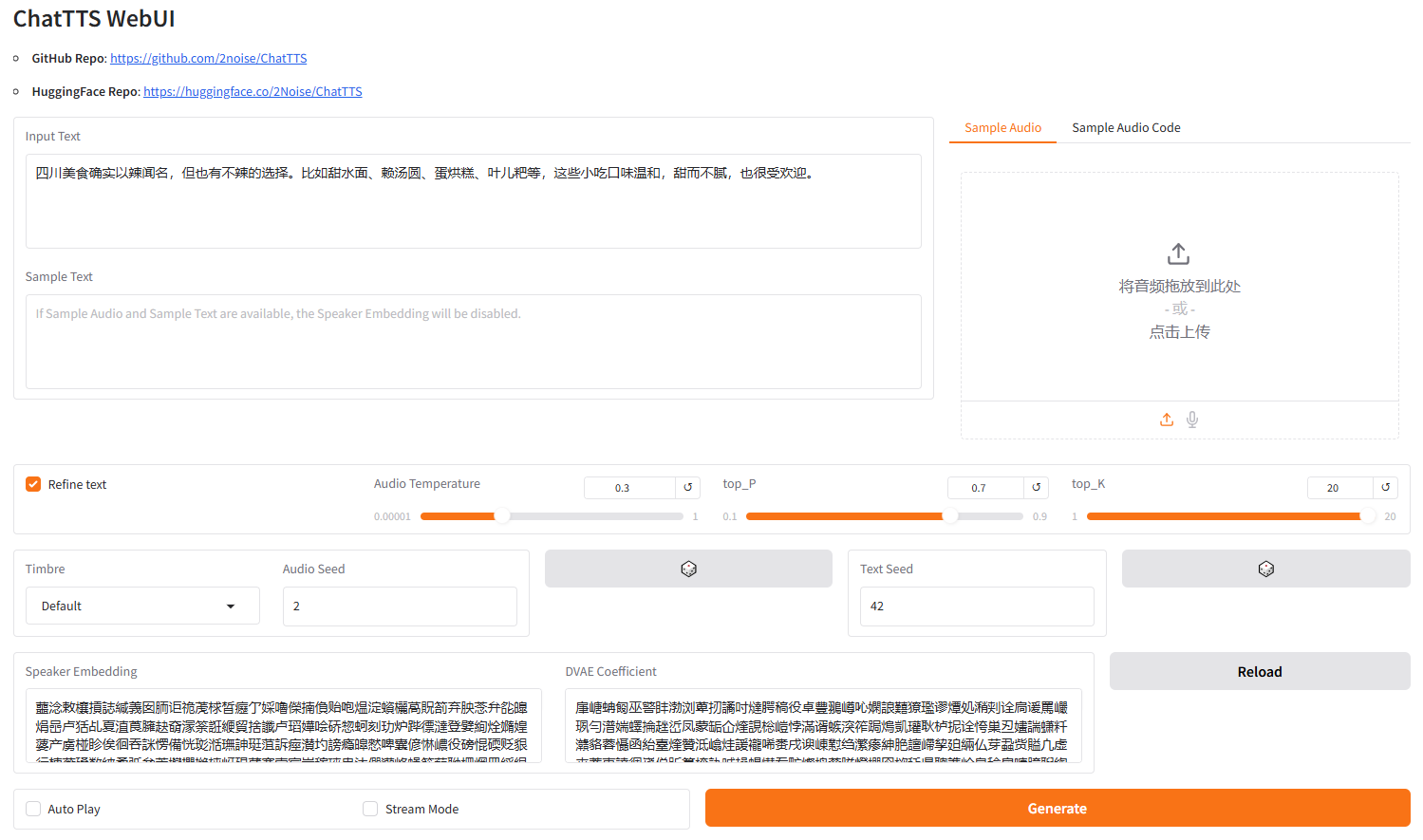
使用WebUI可视化界面交互
python examples/web/webui.py --server_port 3389
运行结果如下图所示时,即可在浏览器中通过 外网ip:3389 访问WebUI界面;外网ip可以在控制台-基础网络(外)中获取

成功访问WebUI界面如下图所示
使用命令行交互
生成的音频将保存至
./output_audio_n.mp3
python examples/cmd/run.py Your text 1. Your text 2.
API调用
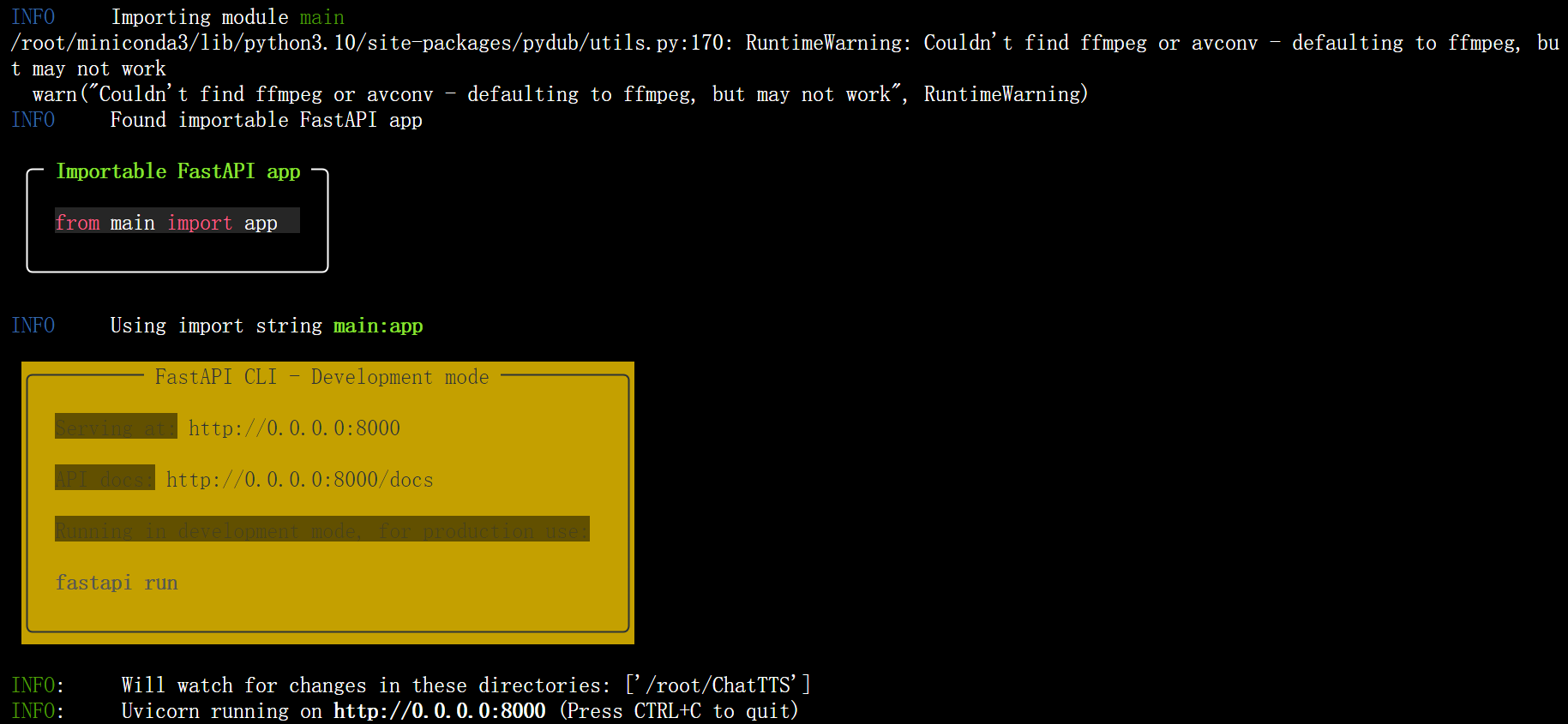
运行API服务器
fastapi dev examples/api/main.py --host 0.0.0.0 --port 3389
使用请求生成音频
python examples/api/client.py

mp3 音频文件将保存到output目录。
开发教程
安装 Python 包
- 从 PyPI 安装稳定版
pip install ChatTTS
- 从 GitHub 安装最新版
pip install git+https://github.com/2noise/ChatTTS
- 从本地文件夹安装开发版
pip install -e .
基础用法
import ChatTTS
import torch
import torchaudio
chat = ChatTTS.Chat()
chat.load(compile=False) # Set to True for better performance
texts = [PUT YOUR 1st TEXT HERE, PUT YOUR 2nd TEXT HERE]
wavs = chat.infer(texts)
torchaudio.save(output1.wav, torch.from_numpy(wavs[0]), 24000)
进阶用法
###################################
# Sample a speaker from Gaussian.
rand_spk = chat.sample_random_speaker()
print(rand_spk) # save it for later timbre recovery
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb = rand_spk, # add sampled speaker
temperature = .3, # using custom temperature
top_P = 0.7, # top P decode
top_K = 20, # top K decode
)
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = ChatTTS.Chat.RefineTextParams(
prompt=[oral_2][laugh_0][break_6],
)
wavs = chat.infer(
texts,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code,
)
###################################
# For word level manual control.
text = What is [uv_break]your favorite english food?[laugh][lbreak]
wavs = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
torchaudio.save(output2.wav, torch.from_numpy(wavs[0]), 24000)
示例: 自我介绍
inputs_en =
chatTTS is a text to speech model designed for dialogue applications.
[uv_break]it supports mixed language input [uv_break]and offers multi speaker
capabilities with precise control over prosodic elements like
[uv_break]laughter[uv_break][laugh], [uv_break]pauses, [uv_break]and intonation.
[uv_break]it delivers natural and expressive speech,[uv_break]so please
[uv_break] use the project responsibly at your own risk.[uv_break]
.replace(\n, ) # English is still experimental.
params_refine_text = ChatTTS.Chat.RefineTextParams(
prompt=[oral_2][laugh_0][break_4],
)
audio_array_en = chat.infer(inputs_en, params_refine_text=params_refine_text)
torchaudio.save(output3.wav, torch.from_numpy(audio_array_en[0]), 24000)
|
男性音色 |
女性音色 |
常见问题
1. 我需要多少 VRAM? 推理速度如何?
对于 30 秒的音频片段,至少需要 4GB 的 GPU 内存。 对于 4090 GPU,它可以每秒生成大约 7 个语义 token 对应的音频。实时因子 (RTF) 约为 0.3。
2. 模型稳定性不够好,存在多个说话者或音频质量差等问题。
这是一个通常发生在自回归模型(例如 bark 和 valle)中的问题,通常很难避免。可以尝试多个样本以找到合适的结果。
3. 除了笑声,我们还能控制其他东西吗?我们能控制其他情绪吗?
在当前发布的模型中,可用的 token 级控制单元是 [laugh], [uv_break] 和 [lbreak]。未来的版本中,我们可能会开源具有更多情绪控制功能的模型。
致谢
- bark, XTTSv2 和 valle 通过自回归式系统展示了非凡的 TTS 效果。
- fish-speech 揭示了 GVQ 作为 LLM 建模的音频分词器的能力。
- vocos vocos 被用作预训练声码器。
特别鸣谢
- wlu-audio lab 对于早期算法实验的支持。
贡献者列表
项目浏览量
