Index-1.9B-Chat
Index-1.9B-Chat镜像集成轻量级开源对话大语言模型,基于Index-1.9B模型经SFT与DPO对齐优化,预训练引入海量网络社区语料,显著增强趣味聊天能力与多轮交互表现,兼顾低资源部署与高响应速度,开箱即用。
 0
00元/小时
v1.0
Index-1.9B-Chat WebDemo 部署
快速运行镜像Demo步骤
1. 先选择GPU型号,再点击“立即部署”
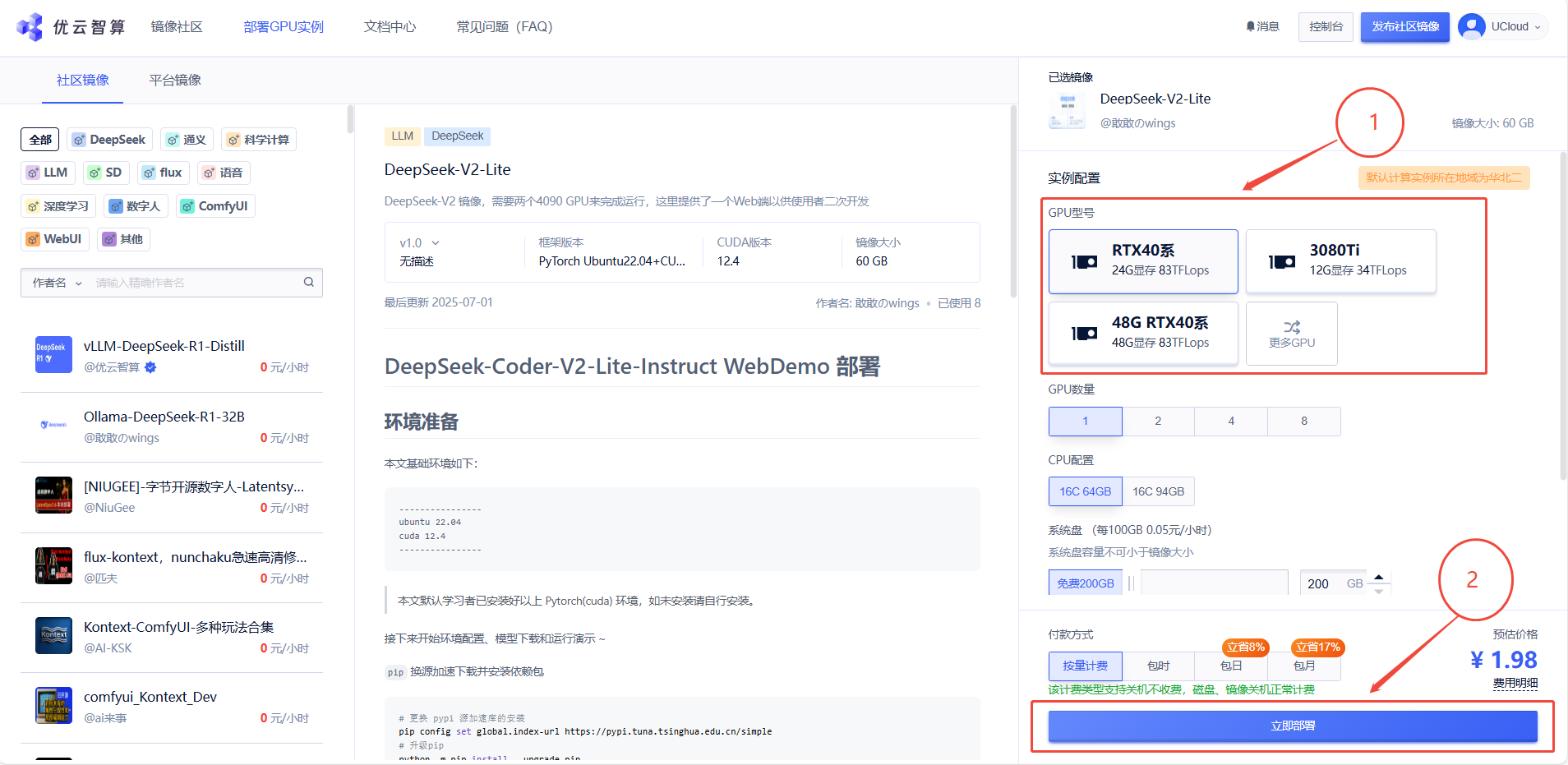
2. 待实例初始化完成后,在控制台-应用中打开“JupyterLab”

3. 进入Jupyter后,新建一个终端Terminal,输入以下指令
streamlit run /workspace/index_1.9/chatBot.py --server.address 0.0.0.0 --server.port 11434
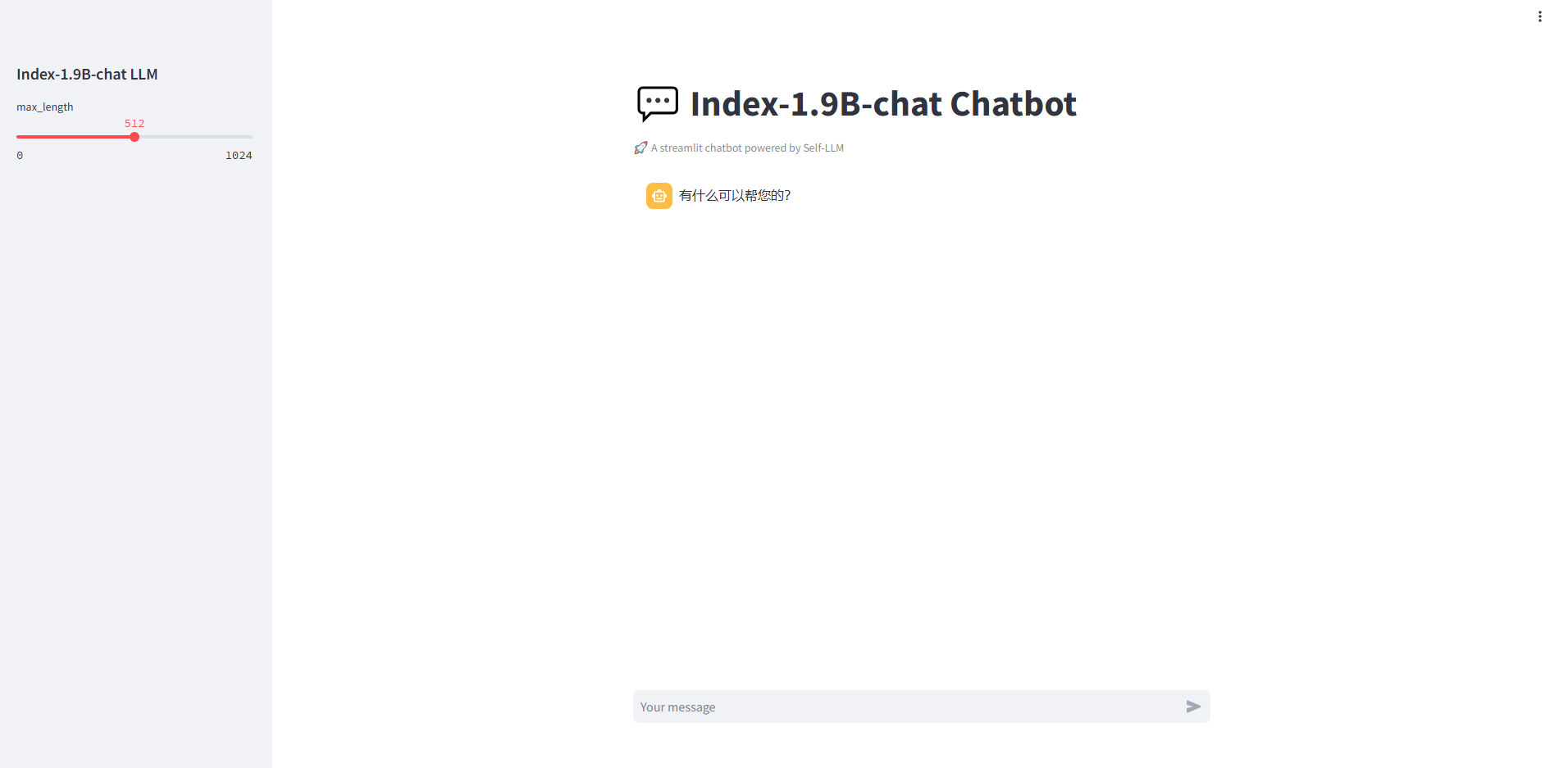
4. 运行出现如下结果时,即可在浏览器中访问 http://0.0.0.0:11434 ,其中0.0.0.0替换为外网ip,外网ip可以在控制台-基础网络(外)中获取

成功进入web界面如下图所示
环境准备
本文基础环境如下:
----------------
ubuntu 22.04
cuda 12.4
----------------
本文默认学习者已安装好以上 PyTorch(cuda) 环境,如未安装请自行安装。
接下来开始环境配置、模型下载和运行演示 ~
pip 换源加速下载并安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.16.1
pip install langchain==0.2.3
pip install streamlit==1.37.0
pip install transformers==4.43.2
pip install accelerate==0.32.1
pip install sentencepiece
模型下载
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为自定义的模型下载路径,参数revision为模型仓库分支版本,master 代表主分支,也是一般模型上传的默认分支。
先切换到 autodl-tmp 目录,cd /root/autodl-tmp
然后新建名为 model_download.py 的 python 文件,并在其中输入以下内容并保存
# model_download.py
from modelscope import snapshot_download
model_dir = snapshot_download(IndexTeam/Index-1.9B-Chat, cache_dir=/workspace/index_1.9/compshare, revision=master)
然后在终端中输入 python model_download.py 执行下载,注意该模型权重文件比较大,因此这里需要耐心等待一段时间直到模型下载完成。
代码准备
在/workspace/index_1.9/compshare路径下新建 chatBot.py 文件并在其中输入以下内容,粘贴代码后记得保存文件。chatBot.py代码如下
# 导入所需的库
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import torch
import streamlit as st
# 在侧边栏中创建一个标题和一个链接
with st.sidebar:
st.markdown(## Index-1.9B-chat LLM)
# 创建一个滑块,用于选择最大长度,范围在0到1024之间,默认值为512
max_length = st.slider(max_length, 0, 1024, 512, step=1)
# 创建一个标题和一个副标题
st.title(💬 Index-1.9B-chat Chatbot)
st.caption(🚀 A streamlit chatbot powered by Self-LLM)
# 定义模型路径
model_name_or_path = /workspace/index_1.9/compshare/IndexTeam/Index-1.9B-Chat
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():
# 从预训练的模型中获取tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False, trust_remote_code=True)
# 从预训练的模型中获取模型,并设置模型参数
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.bfloat16, device_map=auto, trust_remote_code=True)
return tokenizer, model
# 加载 Index-1.9B-chat 的model和tokenizer
tokenizer, model = get_model()
# 如果session_state中没有messages,则创建一个包含默认消息的列表
if messages not in st.session_state:
st.session_state[messages] = [{role: assistant, content: 有什么可以帮您的?}]
# 遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg[role]).write(msg[content])
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 将用户的输入添加到session_state中的messages列表中
st.session_state.messages.append({role: user, content: prompt})
# 在聊天界面上显示用户的输入
st.chat_message(user).write(prompt)
# 构建输入
input_ids = tokenizer.apply_chat_template(st.session_state.messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors=pt).to(cuda)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 将模型的输出添加到session_state中的messages列表中
st.session_state.messages.append({role: assistant, content: response})
# 在聊天界面上显示模型的输出
st.chat_message(assistant).write(response)
# print(st.session_state)
运行demo
在终端中运行以下命令,启动streamlit服务
streamlit run /workspace/index_1.9/chatBot.py --server.address 0.0.0.0 --server.port 11434
在浏览器中打开链接 http://(外部IP):11434/ ,即可看到聊天界面。
@敢敢のwings 认证作者
认证作者
认证作者
镜像信息
已使用2 次
运行时长
0 H
镜像大小
50GB
最后更新时间
2025-07-11
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
自定义开放端口
11434
+1
版本
v1.0
2025-07-11
