Xier-EchoMimicV2
EchoMimicV2是阿里蚂蚁集团推出的半身人体AI数字人项目,基于参考图片、音频剪辑和手部姿势序列生成高质量动画视频,确保音频内容与半身动作的一致性。
 0
00元/小时
v1.0
EchoMimicV2 简化的半身人体动画

EchoMimicV2 数字人生成项目介绍
EchoMimicV2 是阿里蚂蚁集团推出的半身人体 AI 数字人项目。
EchoMimicV2 基于参考图片、音频剪辑和手部姿势序列生成高质量动画视频,确保音频内容与半身动作的一致性。
EchoMimicV2 在前代 EchoMimicV1 生成逼真人头动画的基础上,效果得到进一步提升。
EchoMimicV2 数字人生成项目用途
EchoMimicV2 用音频-姿势动态协调策略,包括姿势采样和音频扩散,增强细节表现力并减少条件冗余。
EchoMimicV2 用头部局部注意力技术整合头部数据,设计特定阶段去噪损失优化动画质量。
EchoMimicV2 能生成完整的数字人半身动画,实现从中英文语音到动作的无缝转换。
EchoMimicV2 数字人生成项目特点
- 音频驱动的动画生成: 用音频剪辑驱动人物的面部表情和身体动作,实现音频与动画的同步。
- 半身动画制作: 从仅生成头部动画扩展到生成包括上半身的动画。
- 简化的控制条件: 减少动画生成过程中所需的复杂条件,让动画制作更为简便。
- 手势和表情同步: 基于手部姿势序列与音频的结合,生成自然且同步的手势和面部表情。
- 多语言支持: 支持中文和英文驱动,根据语言内容生成相应的动画。
EchoMimicV2 数字人生成项目使用
此 EchoMimicV2 镜像已经预装载了 EchoMimicV2 官方仓库的所有预训练模型(main checkpoints of EchoMimic、sd-vae-ft-mse、sd-image-variations-diffusers及audio_processor(whisper)),可以直接进行使用,具体操作流程如下。
1. 先选择GPU型号(以RTX40系为例),再点击“立即部署”
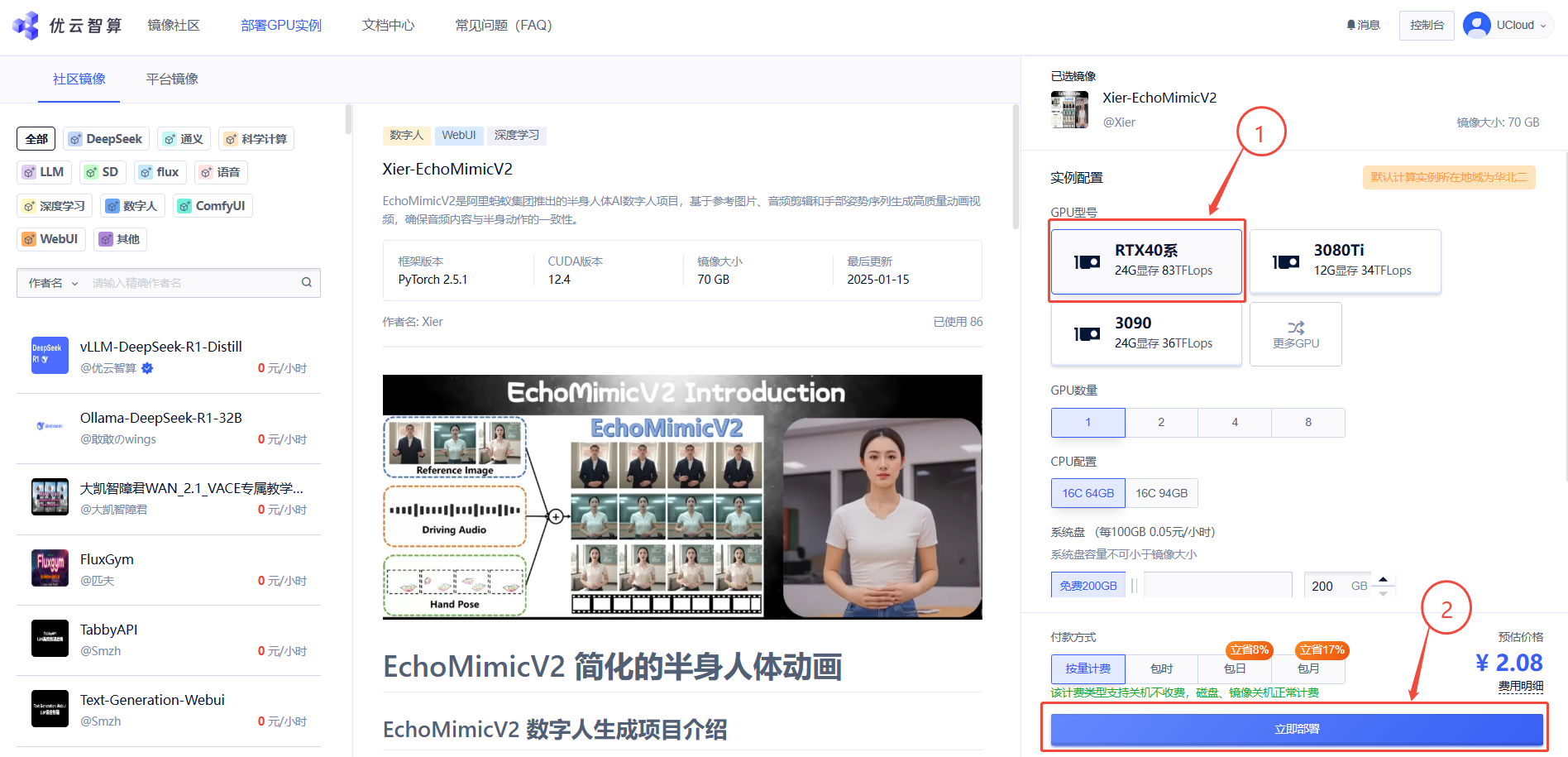
2. 待实例初始化完成后,在控制台-应用中打开“JupyterLab”

3. 进入JupyterLab后,按照图示顺序,先选择Main.ipynb,再点击全部运行
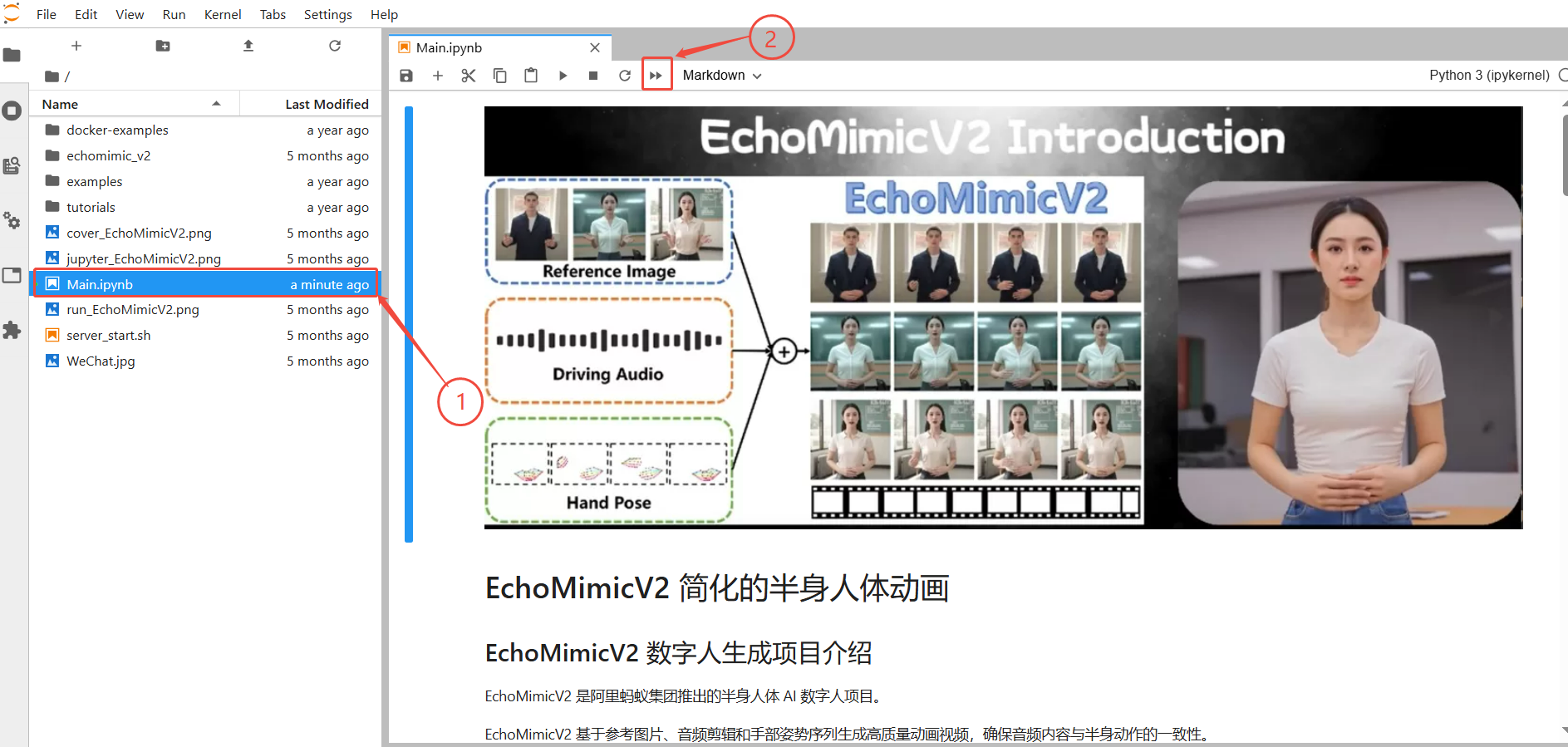
当出现下图所示结果时,即可在浏览器中通过 http://0.0.0.0:3389 访问web界面
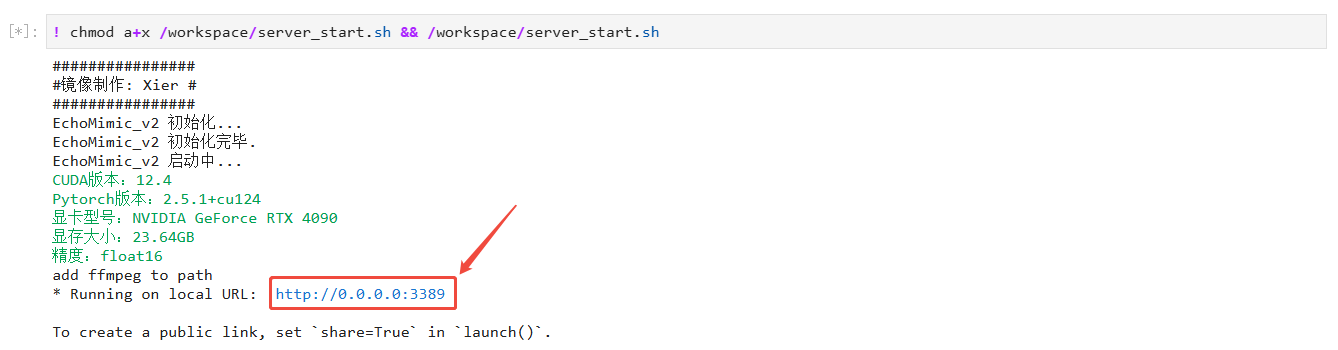
其中0.0.0.0替换为外网ip,外网ip可以在控制台-基础网络(外)获取,如图所示,ip为117.50.250.46

通过浏览器访问后为下图所示web界面即说明启动成功
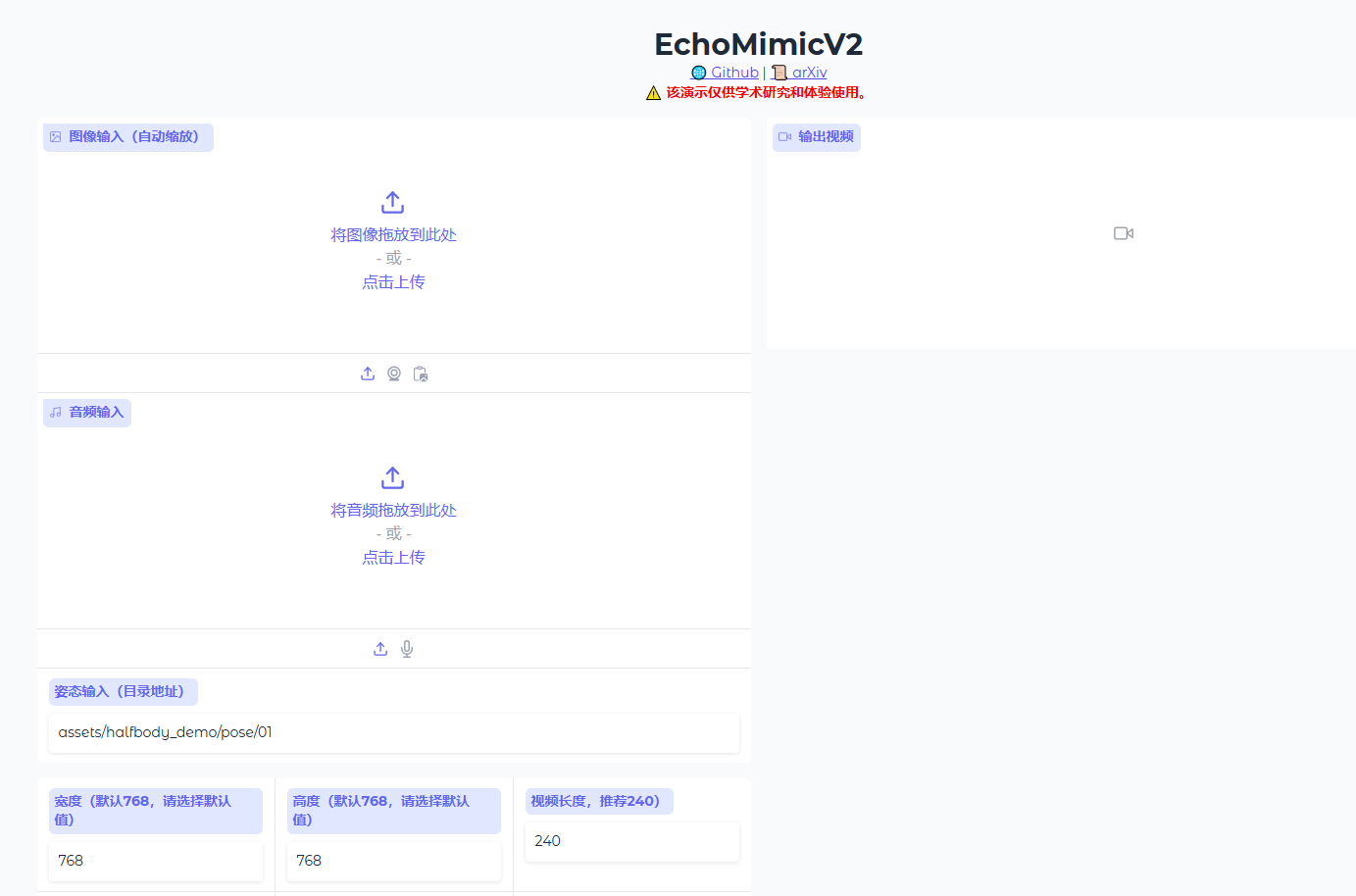
也可通过命令行推理(运行 EchoMimicV2 的 Python 文件)
python infer.py --config=./configs/prompts/infer.yaml
EchoMimicV2 硬件需求
- 显卡要求: 建议
16GB以上显存的NVIDIA显卡 - 内存要求: 建议
32GB以上内存
EchoMimicV2 运行环境
framework_name: PyTorch
framework_version: 2.5.1
cuda_version: 12.4
python_version: 3.10
联系作者
bilibili:
wechat:
@Xier

镜像信息
已使用116 次
运行时长
65 H
镜像大小
70GB
最后更新时间
2025-07-02
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
版本
v1.0
2025-07-02