LLaMA3-8B
Meta Llama3-8B是2024年4月发布的80亿参数自回归大模型,基于15T多语言公开数据预训练,8K上下文Grouped-Query Attention架构,指令版经SFT+RLHF对齐,在通用、推理、代码等基准全面领先同级开源模型
 1
10元/小时
v1.0
LLaMA3-8B-Instruct WebDemo 部署
镜像快速使用教程
1. 待实例初始化完成后,在控制台-应用中打开”JupyterLab“
2. 进入Jupyter后,新建一个终端Terminal,输入以下指令
streamlit run chatBot.py --server.address 0.0.0.0 --server.port 1111
3. 运行出现如下结果时,即可在浏览器中访问 http://0.0.0.0:1111 ,其中0.0.0.0替换为外网ip,外网ip可以在控制台-基础网络(外)中获取
注意检查防火墙设置,确认开启端口TCP 1111

成功进入web界面如下图所示
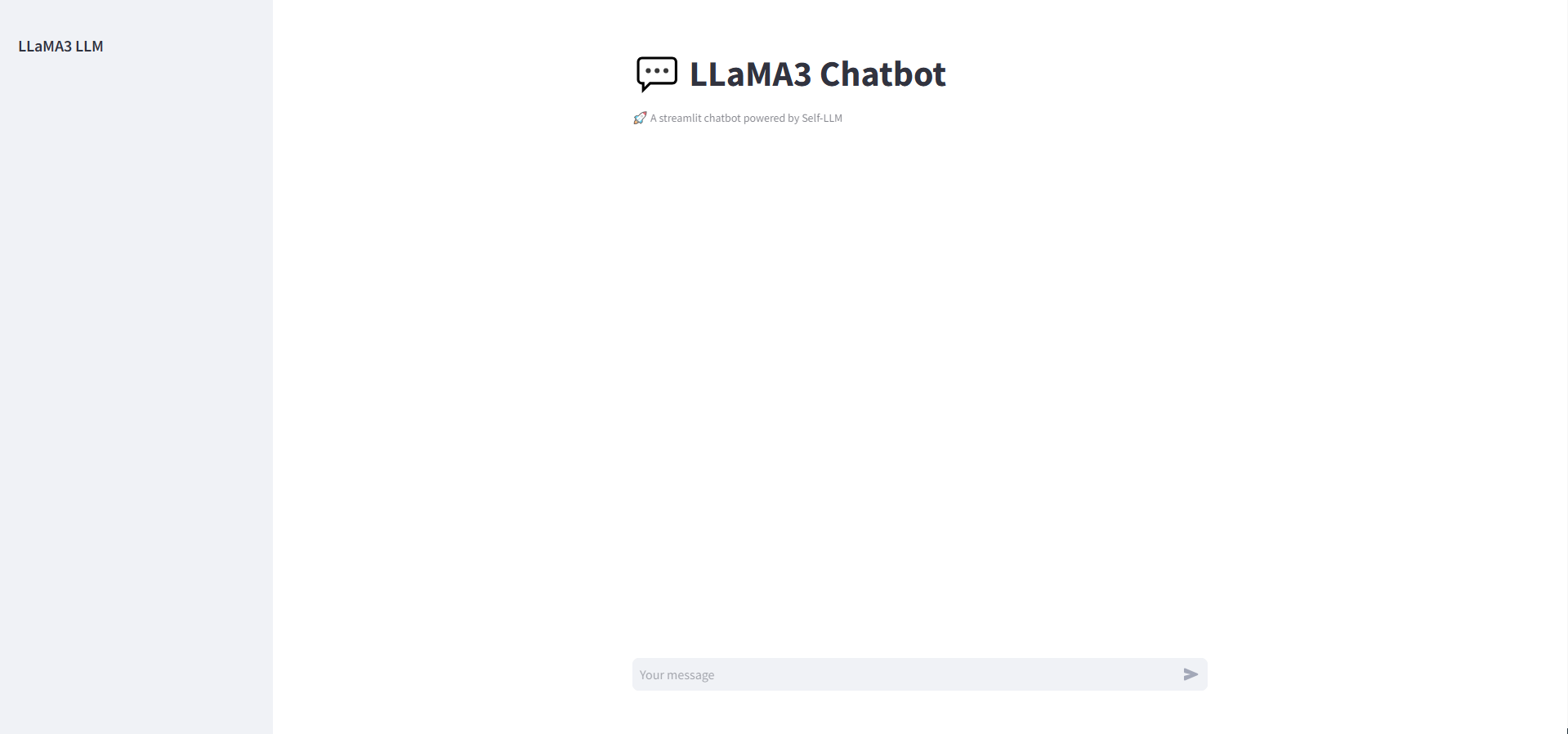
环境准备
本文基础环境如下:
----------------
ubuntu 22.04
cuda 12.4
----------------
可使用RTX40系、P40、3090显卡运行。 接下来开始环境配置、模型下载和运行演示 ~
pip 换源加速下载并安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.11.0
pip install langchain==0.1.15
pip install transformers>=4.40.0 accelerate tiktoken einops scipy transformers_stream_generator
pip install streamlit
模型下载
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
在根目录,即/workspace路径下新建 model_download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python model_download.py 执行下载,模型大小为 15 GB,下载模型大概需要 2 分钟。
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download(LLM-Research/Meta-Llama-3-8B-Instruct, cache_dir=/workspace, revision=master)
代码准备
在根目录,即/workspace路径下新建 chatBot.py 文件并在其中输入以下内容,粘贴代码后记得保存文件。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
# 在侧边栏中创建一个标题和一个链接
with st.sidebar:
st.markdown(## LLaMA3 LLM)
# 创建一个标题和一个副标题
st.title(💬 LLaMA3 Chatbot)
st.caption(🚀 A streamlit chatbot powered by Self-LLM)
# 定义模型路径
mode_name_or_path = /workspace/LLM-Research/Meta-Llama-3-8B-Instruct
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():
# 从预训练的模型中获取tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 从预训练的模型中获取模型,并设置模型参数
model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16).cuda()
return tokenizer, model
def bulid_input(prompt, history=[]):
system_format=<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\n{content}<|eot_id|>
user_format=<|start_header_id|>user<|end_header_id|>\n\n{content}<|eot_id|>
assistant_format=<|start_header_id|>assistant<|end_header_id|>\n\n{content}<|eot_id|>\n
history.append({role:user,content:prompt})
prompt_str =
# 拼接历史对话
for item in history:
if item[role]==user:
prompt_str+=user_format.format(content=item[content])
else:
prompt_str+=assistant_format.format(content=item[content])
return prompt_str + <|start_header_id|>assistant<|end_header_id|>\n\n
# 加载LLaMA3的model和tokenizer
tokenizer, model = get_model()
# 如果session_state中没有messages,则创建一个包含默认消息的列表
if messages not in st.session_state:
st.session_state[messages] = []
# 遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg[role]).write(msg[content])
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 在聊天界面上显示用户的输入
st.chat_message(user).write(prompt)
# 构建输入
input_str = bulid_input(prompt=prompt, history=st.session_state[messages])
input_ids = tokenizer.encode(input_str, add_special_tokens=False, return_tensors=pt).cuda()
outputs = model.generate(
input_ids=input_ids, max_new_tokens=512, do_sample=True,
top_p=0.9, temperature=0.5, repetition_penalty=1.1, eos_token_id=tokenizer.encode(<|eot_id|>)[0]
)
outputs = outputs.tolist()[0][len(input_ids[0]):]
response = tokenizer.decode(outputs)
response = response.strip().replace(<|eot_id|>, ).replace(<|start_header_id|>assistant<|end_header_id|>\n\n, ).strip()
# 将模型的输出添加到session_state中的messages列表中
# st.session_state.messages.append({role: user, content: prompt})
st.session_state.messages.append({role: assistant, content: response})
# 在聊天界面上显示模型的输出
st.chat_message(assistant).write(response)
print(st.session_state)
运行 demo
在终端中运行以下命令,启动streamlit服务。
streamlit run chatBot.py --server.address 0.0.0.0 --server.port 1111
输入实例外部访问IP+:1111的端口号点击访问,即可看到聊天界面。
@liusha

镜像信息
已使用15 次
运行时长
23 H
镜像大小
70GB
最后更新时间
2025-07-14
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
版本
v1.0
2025-07-14