Cogview3
Cogview3 是一个先进的文本到图像生成模型,由清华大学 KEG 实验室和智谱AI公司联合训练。
 0
00元/小时
v1.0
Cogview3 WebDemo 部署
镜像简介
Cogview3 是一个先进的文本到图像生成模型,由清华大学 KEG 实验室和智谱AI公司联合训练。CogView-3-Plus 基于 CogView3 (ECCV'24),引入了最新的 DiT 框架,以进一步提高整体性能。 CogView-3-Plus 使用零信噪比扩散噪声调度,并结合了联合文本图像注意机制。与常用的MMDiT结构相比,它在保持模型基本能力的同时,有效降低了训练和推理成本。 CogView-3Plus 使用潜在维度为 16 的 VAE。
镜像快速使用教程
创建实例
选择合适的机型,立即部署
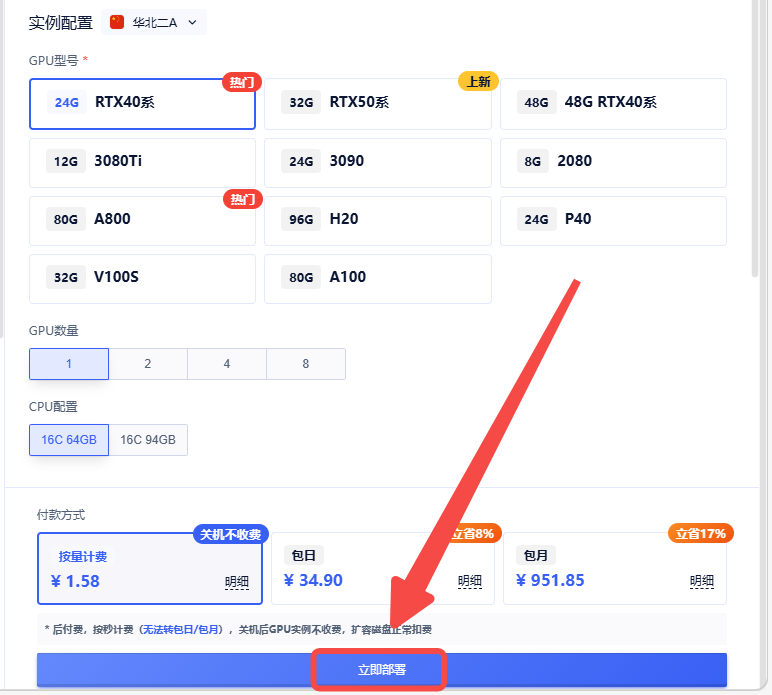
待实例初始化完成后,在控制台-应用中打开”JupyterLab“
进入Jupyter后,新建一个终端Terminal,输入以下指令
python gradio_demo.py
运行出现如下结果时,即可在浏览器中访问 http://0.0.0.0:1111 ,其中0.0.0.0替换为外网ip,外网ip可以在控制台-基础网络(外)中获取
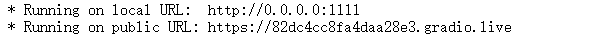
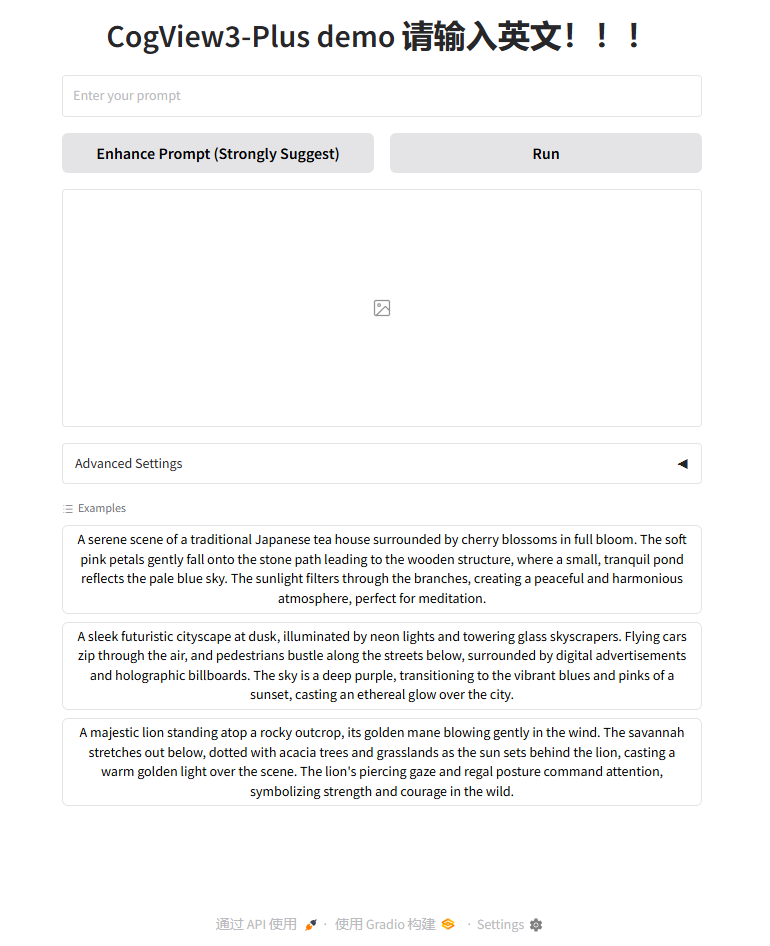
成功进入web界面如下图所示
环境配置
基础环境如下:
----------------
ubuntu 22.04
cuda 12.1
----------------
可使用3090、RTX40系显卡运行
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.20.0
pip install transformers>=4.45.0
pip install gradio>=5.0.2
pip install accelerate>=1.0.0
pip install diffusers
pip install sentencepiece>=0.2.0
pip install torch>=2.4.1
pip install openai
下载 CogView3-Plus-3B模型文件
在根目录,即/workspace路径下新建 model_download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python model_download.py 执行下载,模型大小为 20GB 左右,下载模型大概需要20-30分钟。
from modelscope import snapshot_download
# cache_dir记得修改为自己的目录路径
model_dir = snapshot_download('ZhipuAI/CogView3-Plus-3B', cache_dir='/workspace', revision='master')
代码准备
在根目录,即/workspace路径下新建 gradio_demo.py 文件并在其中输入以下内容,粘贴代码后记得保存文件。
import os
import re
import threading
import time
from datetime import datetime, timedelta
import gradio as gr
import random
from diffusers import CogView3PlusPipeline
import torch
from openai import OpenAI
import gc
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = CogView3PlusPipeline.from_pretrained("/workspace/ZhipuAI/CogView3-Plus-3B", torch_dtype=torch.bfloat16).to(device)
os.makedirs("./gradio_tmp", exist_ok=True)
def clean_string(s):
"""Cleans up the input string by removing extra whitespaces and newlines."""
s = s.replace("\n", " ")
s = s.strip()
s = re.sub(r"\s{2,}", " ", s)
return s
def convert_prompt(prompt: str, retry_times: int = 5) -> str:
"""Converts the user's prompt into a detailed image description using OpenAI's GPT model."""
if not os.environ.get("OPENAI_API_KEY"):
return prompt
client = OpenAI()
system_instruction = """
You are part of a team of bots that creates images. You work with an assistant bot that will draw anything you say.
Create detailed descriptions for images, including subject, medium, style, color, lighting, etc.
Always return the description in English, focusing on visual details.
"""
for _ in range(retry_times):
try:
response = client.chat.completions.create(
messages=[
{"role": "system", "content": system_instruction},
{"role": "user", "content": f'Create an imaginative image description for: "{prompt}"'},
],
model="glm-4-plus",
temperature=0.01,
top_p=0.7,
max_tokens=300,
)
prompt = response.choices[0].message.content
return clean_string(prompt)
except Exception as e:
print(f"Error during API call: {e}")
continue
return prompt
def delete_old_files():
"""Deletes files older than 5 minutes from the temporary directory."""
while True:
now = datetime.now()
cutoff = now - timedelta(minutes=5)
for filename in os.listdir("./gradio_tmp"):
file_path = os.path.join("./gradio_tmp", filename)
if os.path.isfile(file_path):
file_mtime = datetime.fromtimestamp(os.path.getmtime(file_path))
if file_mtime < cutoff:
os.remove(file_path)
time.sleep(600)
threading.Thread(target=delete_old_files, daemon=True).start()
def infer(prompt, seed, randomize_seed, width, height, guidance_scale, num_inference_steps, progress=gr.Progress(track_tqdm=True)):
"""Generates an image based on the prompt using the CogView3Plus model."""
gc.collect()
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
if randomize_seed:
seed = random.randint(0, 65536)
image = pipe(
prompt=prompt,
guidance_scale=guidance_scale,
num_images_per_prompt=1,
num_inference_steps=num_inference_steps,
width=width,
height=height,
generator=torch.Generator().manual_seed(seed),
).images[0]
return image, seed
# Updated examples for better context and detail:
examples = [
"A serene scene of a traditional Japanese tea house surrounded by cherry blossoms in full bloom. The soft pink petals gently fall onto the stone path leading to the wooden structure, where a small, tranquil pond reflects the pale blue sky. The sunlight filters through the branches, creating a peaceful and harmonious atmosphere, perfect for meditation.",
"A sleek futuristic cityscape at dusk, illuminated by neon lights and towering glass skyscrapers. Flying cars zip through the air, and pedestrians bustle along the streets below, surrounded by digital advertisements and holographic billboards. The sky is a deep purple, transitioning to the vibrant blues and pinks of a sunset, casting an ethereal glow over the city.",
"A majestic lion standing atop a rocky outcrop, its golden mane blowing gently in the wind. The savannah stretches out below, dotted with acacia trees and grasslands as the sun sets behind the lion, casting a warm golden light over the scene. The lion's piercing gaze and regal posture command attention, symbolizing strength and courage in the wild.",
]
css = """
#col-container {
margin: 0 auto;
max-width: 640px;
}
"""
with gr.Blocks(css=css) as demo:
with gr.Column(elem_id="col-container"):
gr.Markdown(f"""
<div style="text-align: center; font-size: 32px; font-weight: bold; margin-bottom: 20px;">
CogView3-Plus demo
请输入英文!!!
</div>
""")
with gr.Row():
prompt = gr.Text(
label="Prompt",
show_label=False,
max_lines=3,
placeholder="Enter your prompt",
container=False,
)
with gr.Row():
enhance = gr.Button("Enhance Prompt (Strongly Suggest)", scale=1)
enhance.click(convert_prompt, inputs=[prompt], outputs=[prompt])
run_button = gr.Button("Run", scale=1)
result = gr.Image(label="Result", show_label=False)
with gr.Accordion("Advanced Settings", open=False):
seed = gr.Slider(
label="Seed",
minimum=0,
maximum=65536,
step=1,
value=0,
)
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
with gr.Row():
width = gr.Slider(
label="Width",
minimum=512,
maximum=2048,
step=32,
value=1024,
)
height = gr.Slider(
label="Height",
minimum=512,
maximum=2048,
step=32,
value=1024,
)
with gr.Row():
guidance_scale = gr.Slider(
label="Guidance scale",
minimum=0.0,
maximum=10.0,
step=0.1,
value=7.0,
)
num_inference_steps = gr.Slider(
label="Number of inference steps",
minimum=10,
maximum=100,
step=1,
value=50,
)
gr.Examples(examples=examples, inputs=[prompt])
gr.on(
triggers=[run_button.click, prompt.submit],
fn=infer,
inputs=[prompt, seed, randomize_seed, width, height, guidance_scale, num_inference_steps],
outputs=[result, seed],
)
demo.queue().launch(share=True, server_name="0.0.0.0", server_port=1111)
运行 demo
在终端中运行以下命令
python gradio_demo.py
输入实例外部访问IP+:1111的端口号点击访问,即可看到聊天界面。
@liusha

镜像信息
已使用2 次
运行时长
0 H
镜像大小
20GB
最后更新时间
2026-02-04
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.1
应用
JupyterLab: 8888
版本
v1.0
2026-02-04