 7
7vLLM-DeepSeek-R1-Distill 项目介绍
蒸馏技术可以将大型模型的推理能力迁移到小型模型中,从而显著提升小型模型的性能。通过使用DeepSeek-R1生成的推理数据,DeepSeek 团队对多个常用的小型密集模型进行了微调,开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 蒸馏模型——DeepSeek-R1-Distill系列模型。 详细 DeepSeek 模型名称及其对应的推荐配置如下:
| 模型名称 | 推荐配置 |
|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 4090 1卡 |
| DeepSeek-R1-Distill-Qwen-7B | 4090 1卡 |
| DeepSeek-R1-Distill-Llama-8B | 4090 1卡 |
| DeepSeek-R1-Distill-Qwen-14B | 4090 2卡 |
| DeepSeek-R1-Distill-Qwen-32B | 4090 4卡 |
| DeepSeek-R1-Distill-Llama-70B | 4090 8卡 |
蒸馏模型的优势:
- 性能提升:在减少参数量的同时,尽可能保留原模型的性能。蒸馏后的小型模型在推理任务上表现优于通过强化学习(RL)训练的小型模型。
- 资源节约:小型模型适合在资源有限的硬件(如单卡或多卡 GPU)上运行,能够显著提升推理速度并降低显存占用。
vLLM-DeepSeek-R1-Distill是将DeepSeek-R1-Distill模型与vLLM框架进行集成,vLLM框架针对大语言模型的推理性能进行了优化,支持高效的显存管理和分布式推理,能够显著提升 DeepSeek 系列模型的运行效率。
如何运行 vLLM-DeepSeek-R1-Distill
启动 vLLM 服务
镜像已配置好需要的运行环境和依赖,无需额外安装,一行命令就能快速启动!
在初始化实例后,您可以通过JupyterLab执行以下命令启动 vLLM 服务:
#启动 vLLM api 服务
vllm serve <大模型路径> --port 8000
这里我以部署DeepSeek-R1-Distill-Qwen-7B模型为例,执行以下命令启动 vLLM 服务:
#DeepSeek-R1-Distill-Qwen-7B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --port 8000 --max-model-len 65536
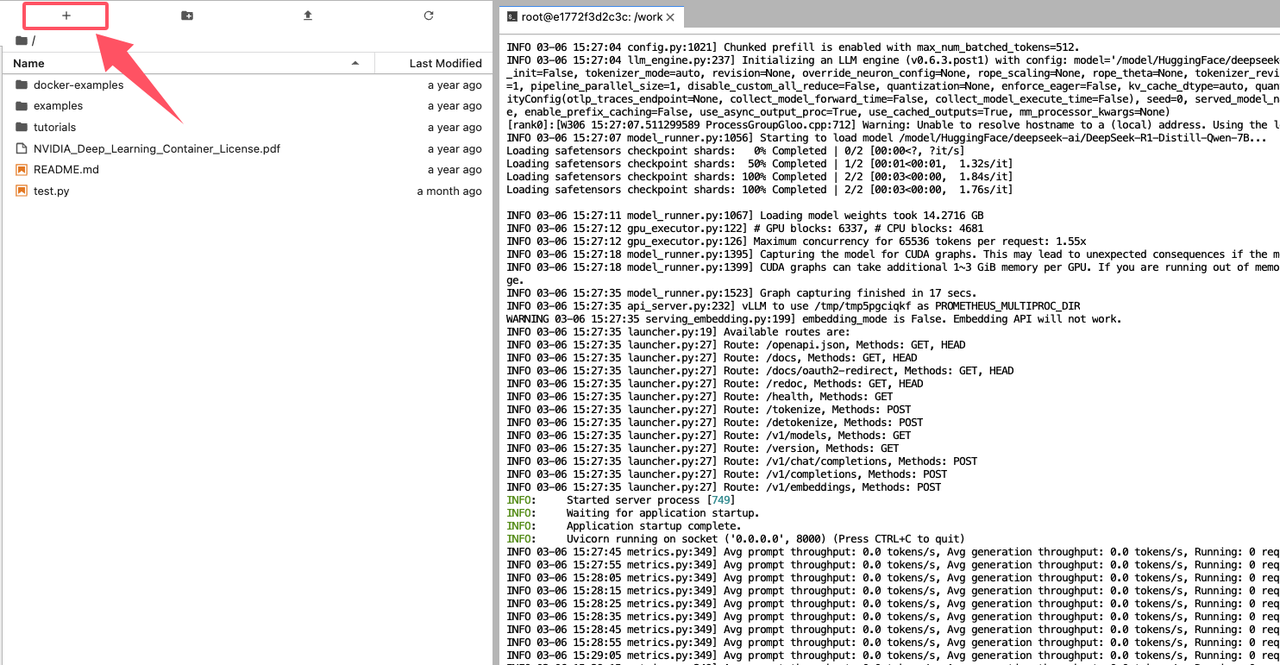
当你在控制台看到如下图所示的输出信息时,说明 vLLM 服务启动成功:

vLLM 服务默认运行在8000端口,如果需在公网使用,需要先到防火墙处开启端口。
推荐 GPU 配置与 vLLM 服务启动命令
根据不同的 GPU 配置,这里推荐按 GPU 配置来部署合适大小的模型,以下是推荐配置和启动 vLLM 服务的命令:
推荐配置 4090 1卡
# DeepSeek-R1-Distill-Qwen-1.5B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --port 8000
# DeepSeek-R1-Distill-Qwen-7B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --port 8000 --max-model-len 65536
# DeepSeek-R1-Distill-Llama-8B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Llama-8B --port 8000 --max-model-len 17984
推荐配置:4090 2卡
# DeepSeek-R1-Distill-Qwen-14B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B --port 8000 -tp 2 --max-model-len 59968
推荐配置:4090 4卡
# DeepSeek-R1-Distill-Qwen-32B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --port 8000 -tp 4 --max-model-len 65168
推荐配置:4090 8卡
# DeepSeek-R1-Distill-Llama-70B
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Llama-70B --port 8000 -tp 8 --max-model-len 88048
运行示例
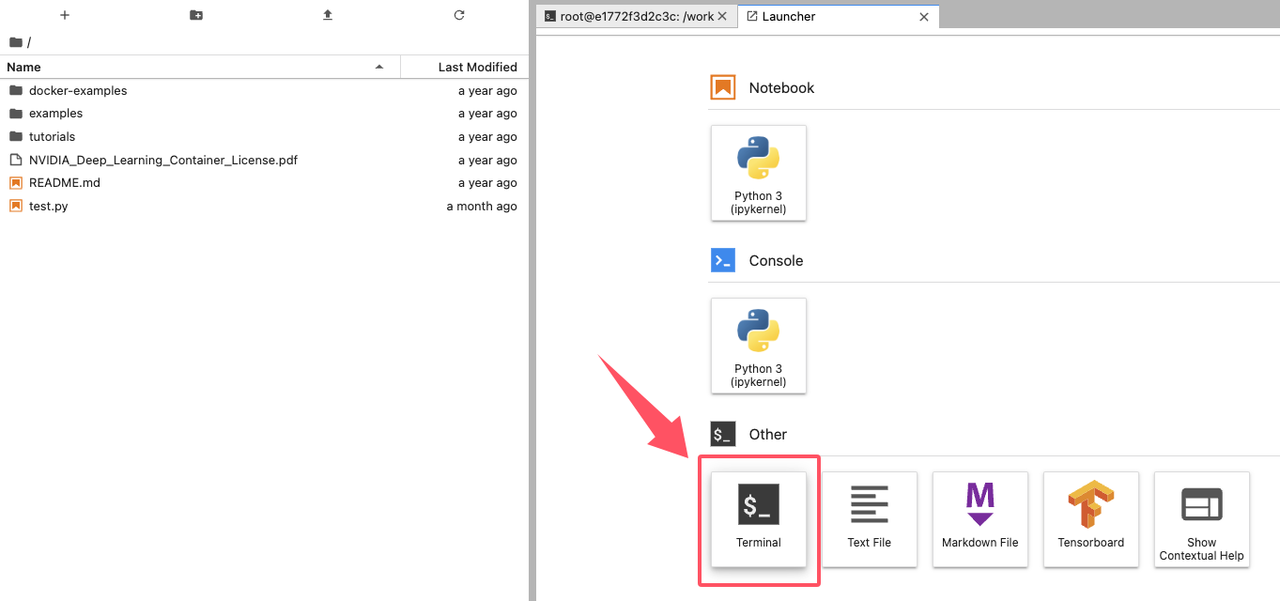
启动 vLLM 服务后,注意不要关闭服务进程,通过点击界面左上角的添加按钮新建一个启动台(Launcher):
通过启动台,我们可以再新建一个新的终端(Terminal):
新建的终端默认运行在workspace/工作目录下,这里我们可以执行下面命令运行测试示例test.py来验证大模型服务,它将调用大模型帮我们写一篇200字的作文:
`
python test.py
你可以直接在
JupyterLab打开test.py文件,查看详细的代码内容。
等待一段时间后,如下图所示,我们可以通过控制台看到模型的回复内容,说明验证成功:

DeepSeek-R1-Distill系列模型是大型推理语言模型,所以它的回复内容有两个部分,其中<think>和</think>包裹的是大模型输出的推理过程,在标签外的才是大模型的最终输出内容,即我们想要的输出结果。
DeepSeek-R1-Distill 系列模型基准成绩对比与使用场景建议
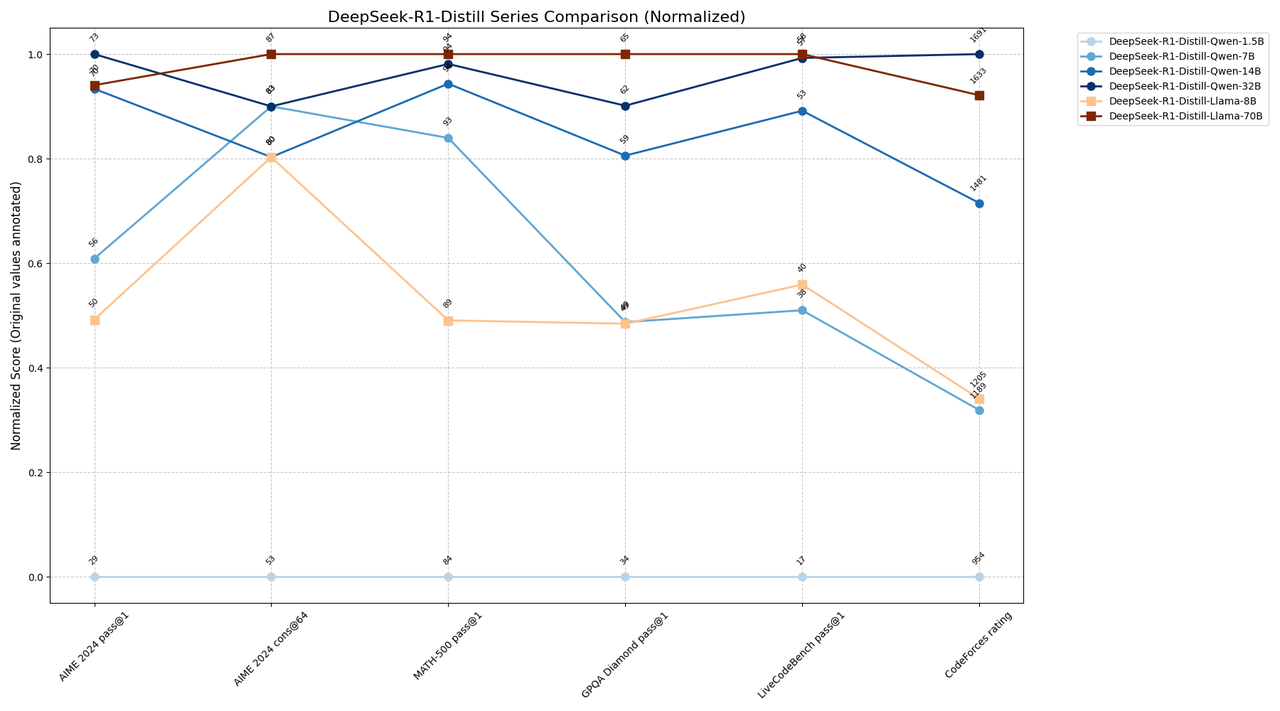
建议使用场景:
- 资源受限场景 :Qwen-7B(1189 CF / 92.8 MATH)
- 平衡性能需求 :Qwen-14B(1481 CF / 93.9 MATH)
- 极致性能需求 :Qwen-32B或Llama-70B(CF 1600+ / MATH 94%+)
- 质量优先场景 :Llama-70B(GPQA 65.2 / AIME cons@64 86.7)
扫码加入DeepSeek使用交流群

