 1
1什么是 vLLM-DeepSeek-chatbot
vLLM-DeepSeek-chatbot是基于原生vLLM镜像扩展的增强版聊天机器人(ChatBot),集成 Gradio 实现了可视化的 WebUI 对话界面,支持实时交互式参数调节和对话历史展示。
相对于原本的vllm镜像,本镜像添加了以下功能:
-
gradio和ray实现可视化大模型对话功能
-
多gpu部署
-
部署蒸馏模型(需要)
-
可自由选择加载模型,模型加载的参数和推理的参数都可在UI界面中选择
如何运行 vLLM-DeepSeek-chatbot
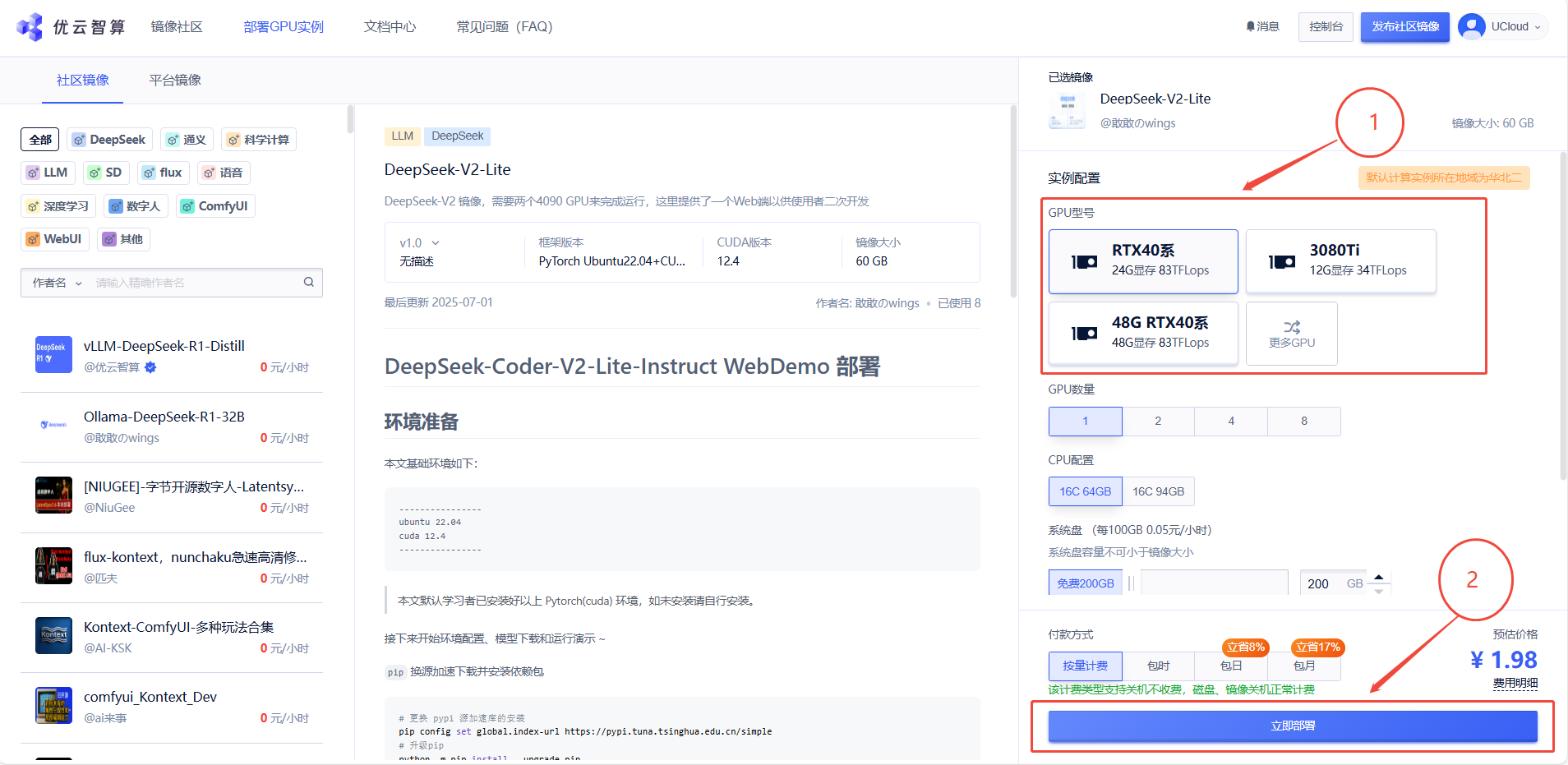
1. 先选择GPU型号,再点击“立即部署”
2. 待实例初始化完成后,在控制台-应用中打开“JupyterLab”

3. 进入JupyterLab后,新建一个终端Terminal,输入以下指令启动 WebUI 服务
python webui.py
当你在控制台看到如下图所示的输出信息时,说明 WebUI 服务启动成功:

WebUI 服务默认运行在
7860端口,镜像实例已默认配置并开启了该端口。所以,这里你需要将0.0.0.0换成实例的公网IP来进行访问。
4. 用本地浏览器打开http://公网ip:7860,外网ip可以在控制台-基础网络(外)中获取,你将看到聊天机器人的可视化页面:
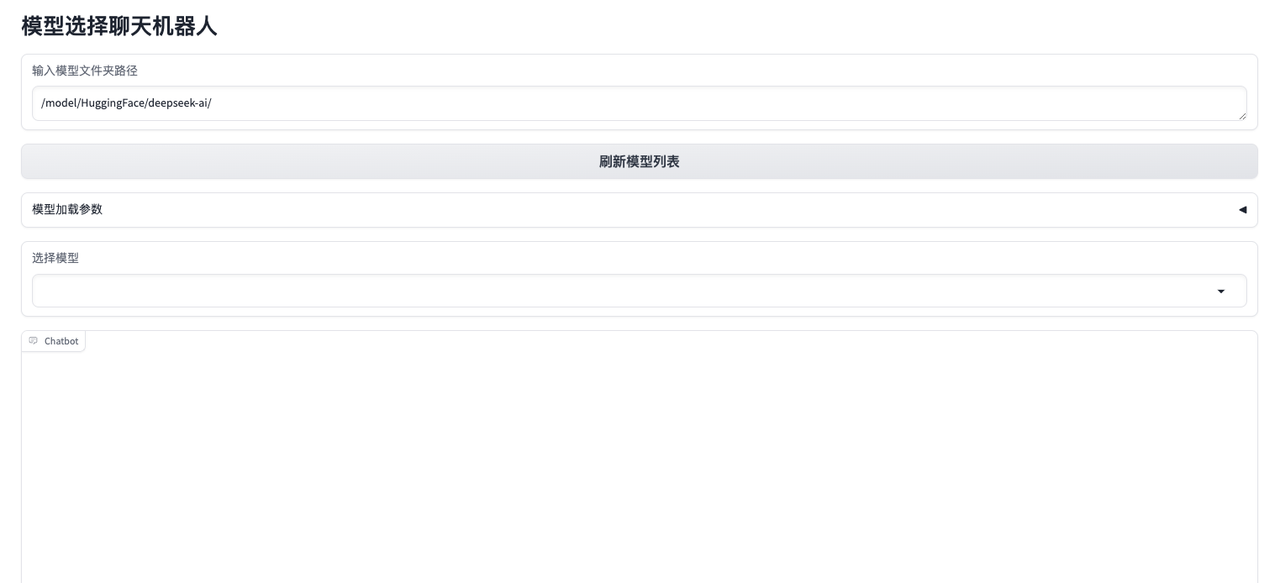
5. 加载可用的模型列表
点击刷新模型列表按钮,从指定的模型文件夹路径中加载可用的模型列表:
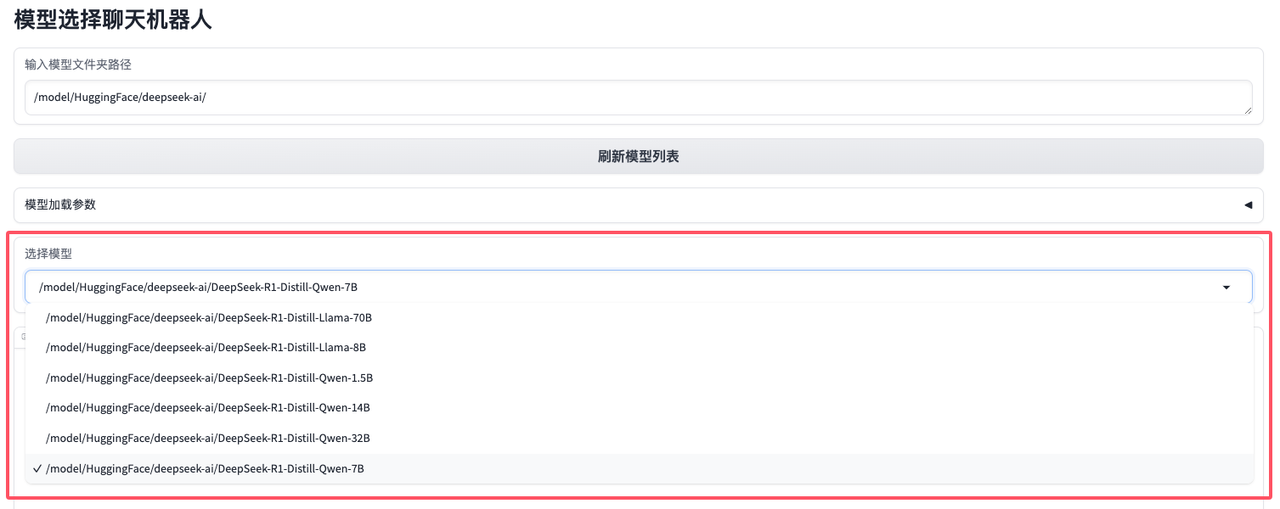
模型文件夹的默认路径为
/model/HuggingFace/deepseek-ai/,更换模型文件夹路径后需要再次点击刷新模型列表按钮
6. 修改加载模型的参数
这一步建议使用默认值,你也可根据实际需求修改,这将会影响模型的加载和推理速度。

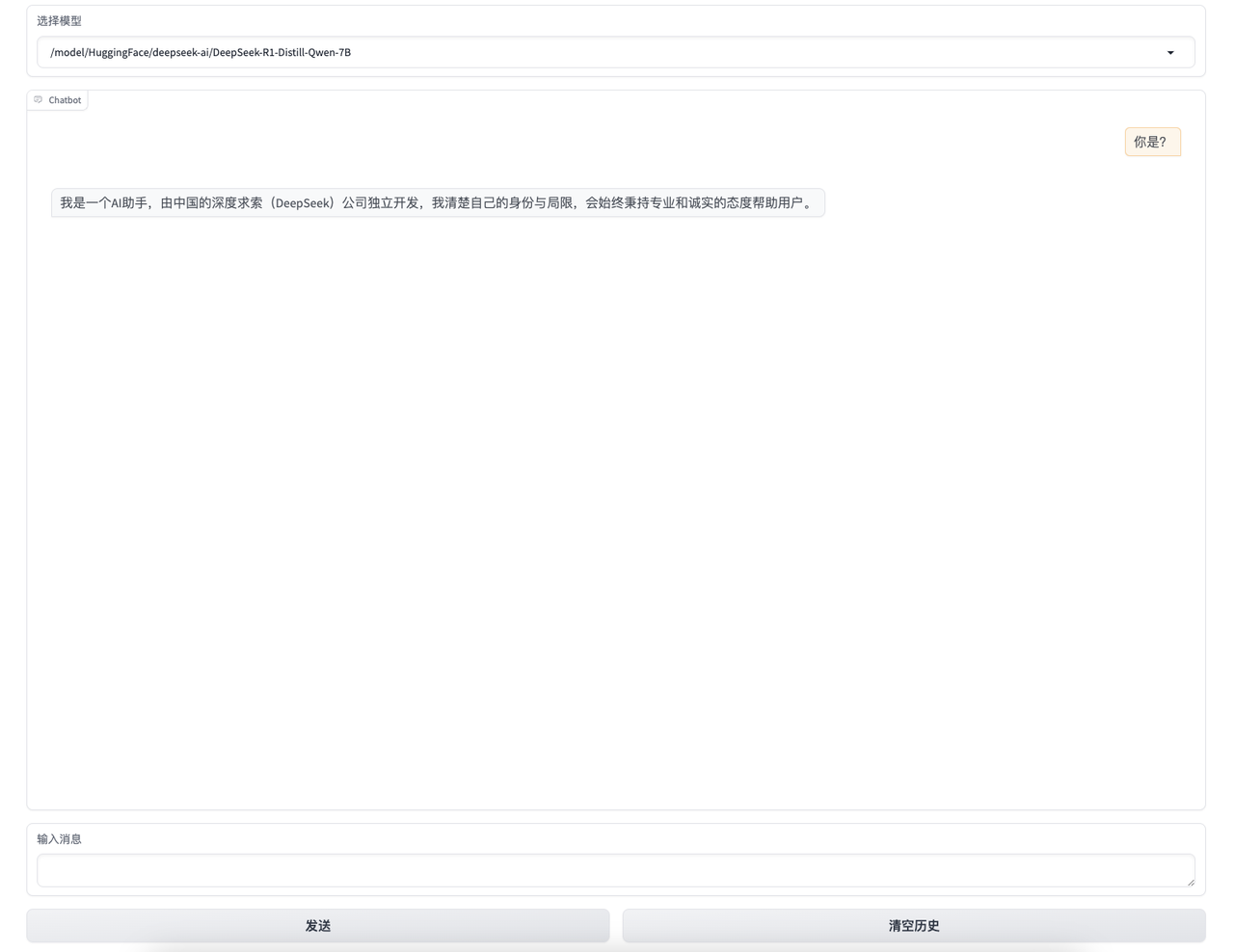
7. 选择模型
这一步需要你根据部署实例的配置来选择合适的模型,这里我选择加载DeepSeek-R1-Distill-Qwen-7B来进行演示:
详细 DeepSeek 模型名称及其对应的推荐配置如下:
| 模型名称 | 推荐配置 |
|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 4090 1卡 |
| DeepSeek-R1-Distill-Qwen-7B | 4090 1卡 |
| DeepSeek-R1-Distill-Llama-8B | 4090 1卡 |
| DeepSeek-R1-Distill-Qwen-14B | 4090 2卡 |
| DeepSeek-R1-Distill-Qwen-32B | 4090 4卡 |
| DeepSeek-R1-Distill-Llama-70B | 4090 8卡 |
越大的模型需要的加载时间越久,选择多GPU部署则会更久,请耐心等待。
8. 调整模型的推理参数
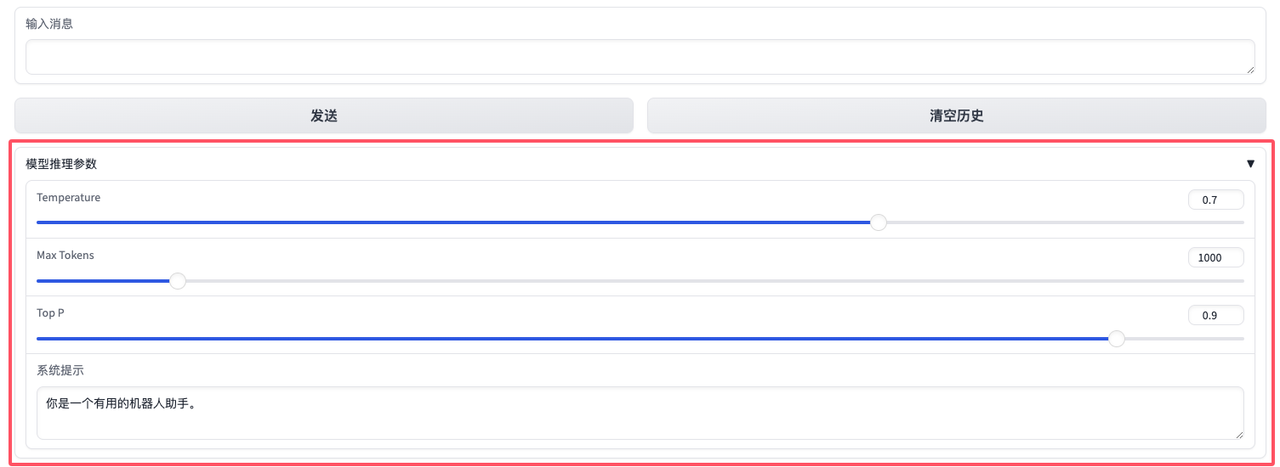
| 可调参数示例 | 作用 | 建议值范围 |
|---|---|---|
| temperature | 平衡模型的创造性与逻辑性,值越低输出的确定性高,值越高输出会更具多样性 | 0.1-1.0 |
| top_p | 作用与temperature相似,可辅助temperature作为微调参数,反之亦可 | 0.5-0.95 |
| max_tokens | 模型的最大生成长度,生成速度与max_tokens成反比 | 512-8192 |
temperature和top_p这两个参数一般只需要调整其中一个。系统提示(System Prompt)是对话系统中的一个关键参数,它对模型推理的影响是多方面的,包括行为引导、风格控制、知识范围限制、逻辑性提升、偏见减少以及任务适配性增强。 合理设置系统提示可以显著优化模型的输出质量,使其更符合用户需求!
9. 输入消息与大模型对话
在输入框中输入你的问题:

输入消息后,点击发送按钮,稍等片刻,大模型将生成回复并在消息历史中展示对话内容:
Enjoy it!
注意事项
-
防火墙需开启7860端口
-
gradio使用的版本是4.43.0,最新版本会出现大模型回答不显示的问题
-
模型文件夹路径默认为/model/HuggingFace/deepseek-ai/,每次更换路径需要再次点击"刷新模型列表"按钮
 认证作者
认证作者