 0
0Langchain-Chatchat 镜像
镜像简介
Langchain-Chatchat 是一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。依托于 Langchain-Chatchat 支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。
Langchain-Chatchat 的过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
支持的GPU型号
- RTX40系列
- 48G RTX40系列
- 3090
- P40
- ...
镜像使用指南
防火墙
为了能够正常使用 Web UI 界面,需要为镜像配置防火墙,放行 8501,7861,9997端口,其中 8501,7861是Langchain-Chatchat项目需要使用的端口,9997是**Xinference(部署LLM和Embedding模型的框架)**项目需要使用的端口
| 动作 | 协议及端口 | 源地址 | 优先级 | 备注 |
|---|---|---|---|---|
| 接受 | TCP: 8501 | 0.0.0.0/0 | 高 | - |
| 接受 | TCP: 7861 | 0.0.0.0/0 | 高 | - |
| 接受 | TCP: 9997 | 0.0.0.0/0 | 高 | - |
环境准备
本镜像包含两个环境(除了base环境):
- py310
- xinference
其中,py310是Langchain-Chatchat项目的环境,xinference是Xinference项目的环境,其中安装Xinference项目的时候,使用的安装方式是:pip install "xinference[vllm]",即推理引擎只安装了vllm。
Xinference模型部署
1. 待实例初始化完成后,新建一个terminal,激活xinference环境:
conda activate xinference
2. 再输入以下指令启动Xinference服务:
XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997
3. 启动成功后,在浏览器中输入:http://外网ip:9997/ ,即可进入Web UI界面进行模型的部署管理。
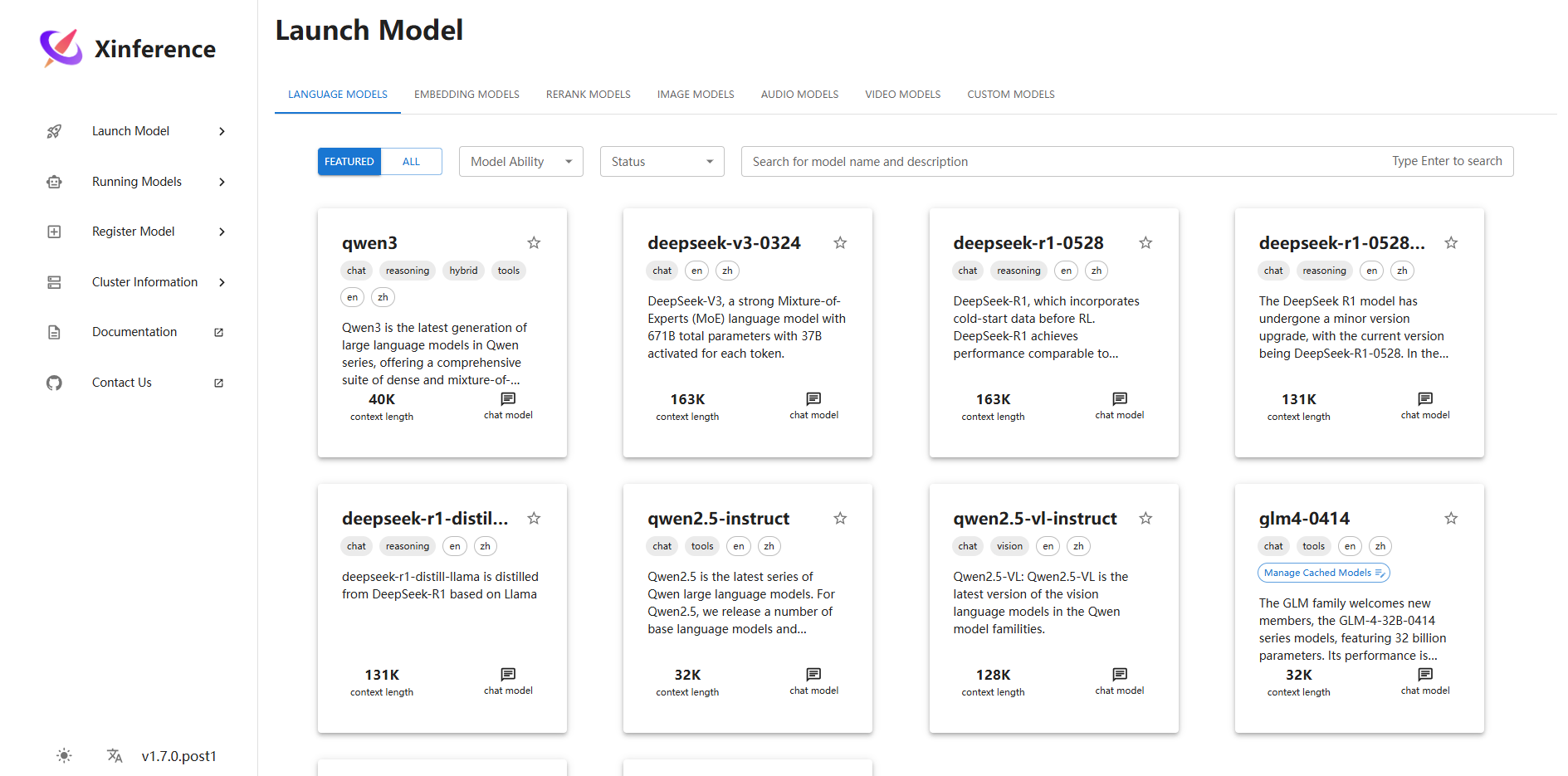
4. 进入Launch Model页面,先部署Embedding模型,再部署LLM模型:
-
对于EMBEDDING MODELS标签页,本镜像已提前下载并配置好了bge-m3 模型(如果想使用其他模型可以自行配置部署,Xinference项目会自动从 ModelScope 下载模型,下载位置默认在
/root/.xinference/cache/目录),配置如下:- (Optional) Model Engine: vllm
- Replica: 1
- Device: GPU
点击左下角的小火箭按钮即可部署
-
对于LANGUAGE MODELS标签页,本镜像已提前下载并配置好了glm4-0414 模型(如果想使用其他模型可以自行配置部署,Xinference项目会自动从 ModelScope 下载模型,下载位置默认在
/root/.xinference/cache/目录),配置如下:- Model Engine: vLLM Cached (ps: Cached代表使用过,对于新模型不会有Cached字样)
- Model Format: pyTorch Cached
- Model Size: 9 Cached
- Quantization: none Cached
- GPU Count per Worker: auto
- Replica: 1
- Additional parameters passed to the inference engine: vLLM
- max_model_len: 4096 (ps: 数值大小和GPU的显存大小有关系,若部署过程中报错,可以按照报错提示修改调小)
点击左下角的小火箭按钮即可部署
5. 若部署成功,进行Running Models页面,可以看到成功部署的glm4-0414 模型和bge-m3 模型。
Langchain-Chatchat 使用
- 新建一个terminal,激活py310环境:
conda activate py310
- 查看 /workspace 目录下的model_settings.yaml配置文件,确保DEFAULT_LLM_MODEL,LLM_MODEL_CONFIG.llm_model和LLM_MODEL_CONFIG.action_model设置为glm4-0414,DEFAULT_EMBEDDING_MODEL设置为bge-m3
- 知识库位置在/workspace/data/knowledge_base/samples/content,初始化知识库(当有新知识的时候需要重新初始化,没有的话本镜像已提前初始化好了,所以这一步可跳过):
chatchat kb -r
- 启动项目:
chatchat start -a
- 启动成功后,在浏览器输入 http://外网IP:8501/ 即可进入Web UI界面,从而进行普通对话、知识库管理、知识库问答;外网ip可以在控制台-基础网络(外)中获取
参考资料
