 3
3Fish Speech 是什么
Fish Speech是一个强大的开源文本转语音(TTS)模型,相较于之前的版本,Fish Speech 1.5版本大幅提升了 Zero-Shot 能力,可以直接使用预训练模型进行推理,只需提供参考音频来指定音色。
Fish Speech 1.5 主要特点:
- 支持中、英、日等多国语言(语言识别切割有待改进)。
- VITS 格式标注文件通用,只需修改标注文件内的路径。
- 支持微调(Fine-tuning),可根据您的数据集训练特定音色和风格的模型。
- 强大的 Zero-Shot 能力,可直接使用预训练模型进行推理,通过参考音频指定音色。
如何运行 Fish Speech 1.5 (WebUI)
创建实例
1.创建实例
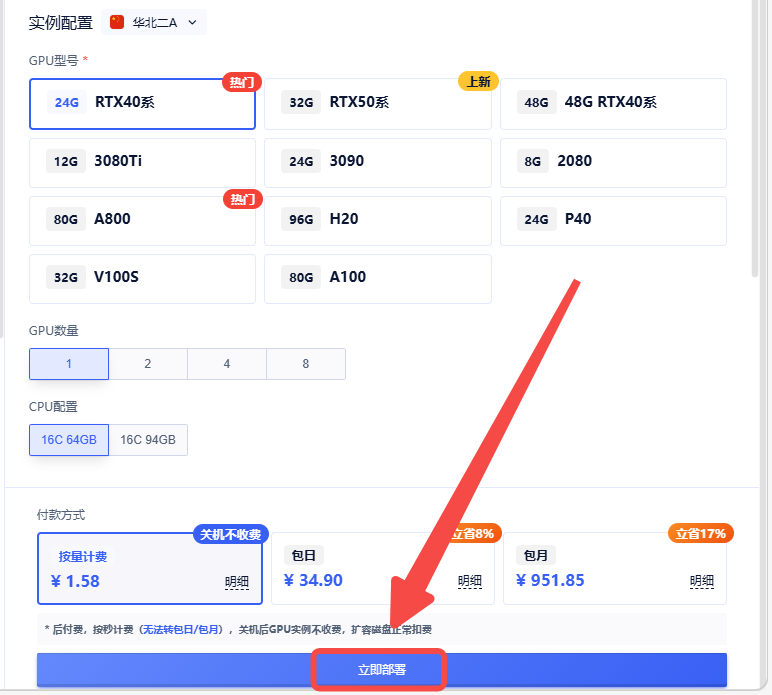
2.选择合适的机型,立即部署
3.返回实例页面,点击【JupyterLab】 此镜像包含了运行 Fish Speech 1.5 所需的所有环境和模型,不需要进行额外的环境搭建操作,咱们直接快速开始!
1. 进入项目目录
cd /root/workdir/fish-speech
2. 如果你想直接使用预训练模型进行推理,可以执行以下命令运行 WebUI 服务:
/root/miniconda3/bin/python tools/run_webui.py --compile
WebUI 服务默认运行在6006端口,启动成功后你可以在控制台看到如下输出:
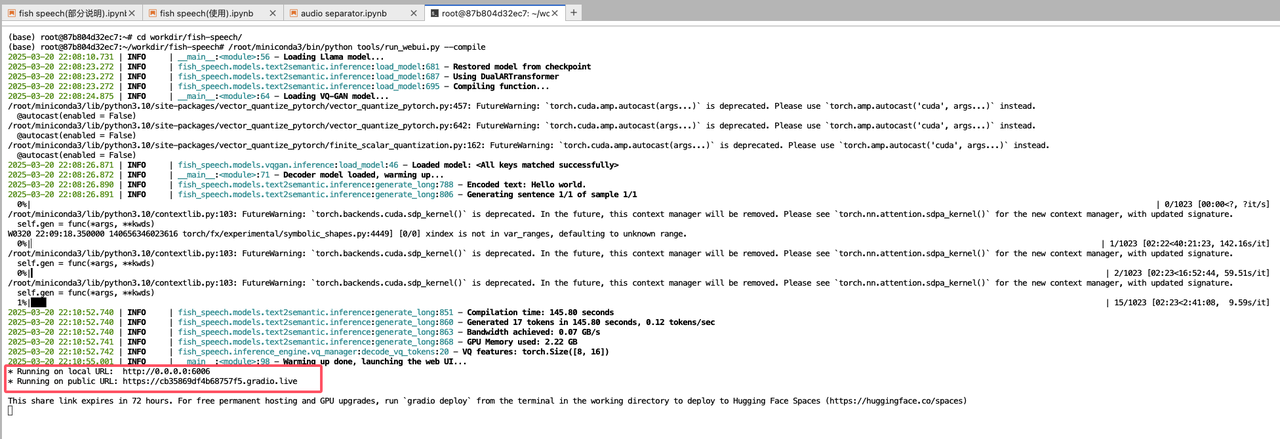
3. 通过本地浏览器访问http://<公网IP>:6006打开 WebUI 页面:
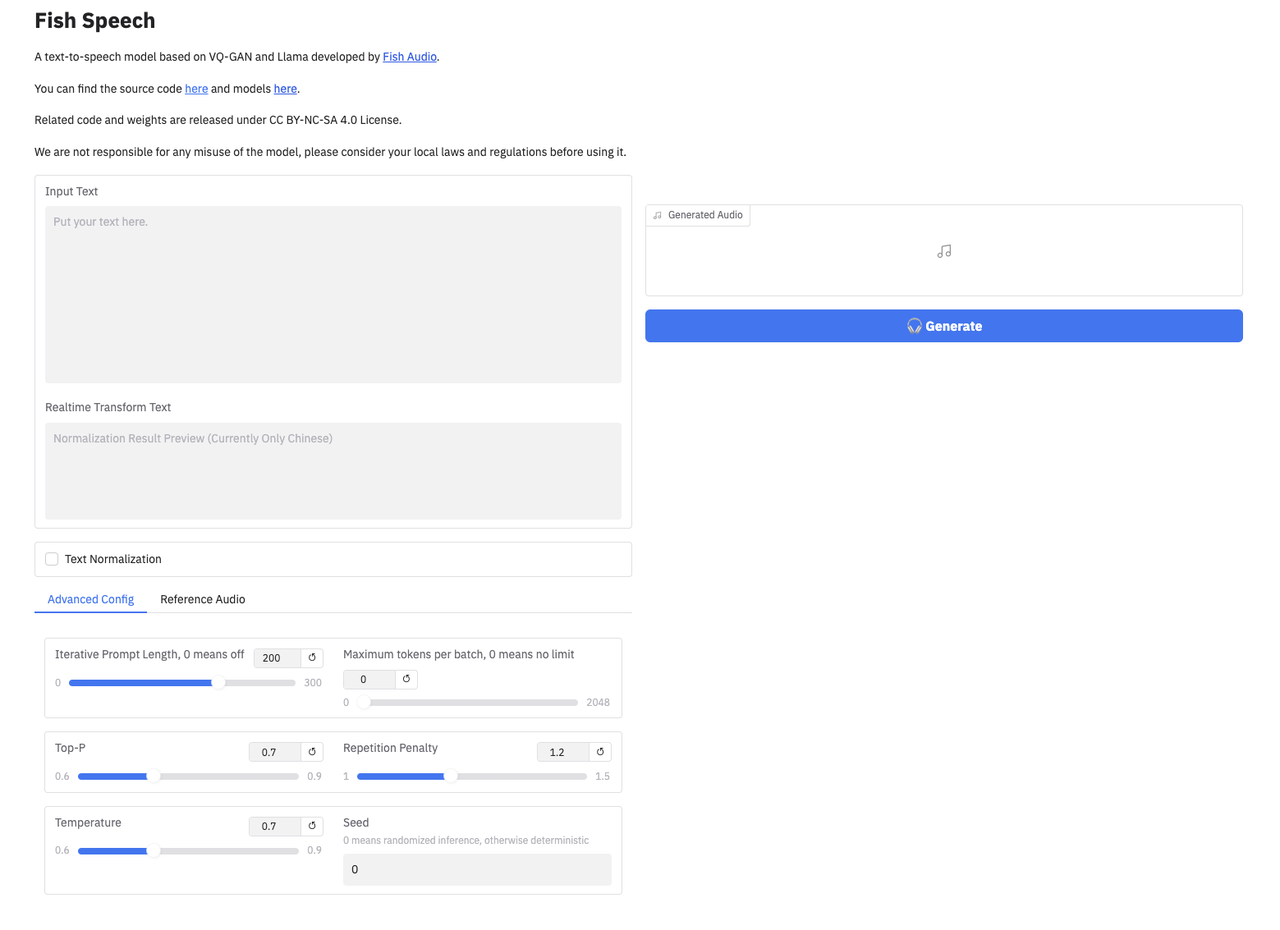
4. 接下来,我们只需要输入文本,按需设置好模型参数,点击Generate按钮模型就可以将我们输入的文本转换成语音了!
5. 如果你想要使用其他音色生成语音也非常简单!只需上传参考的音频和音频的语音内容就可以指定音色了:
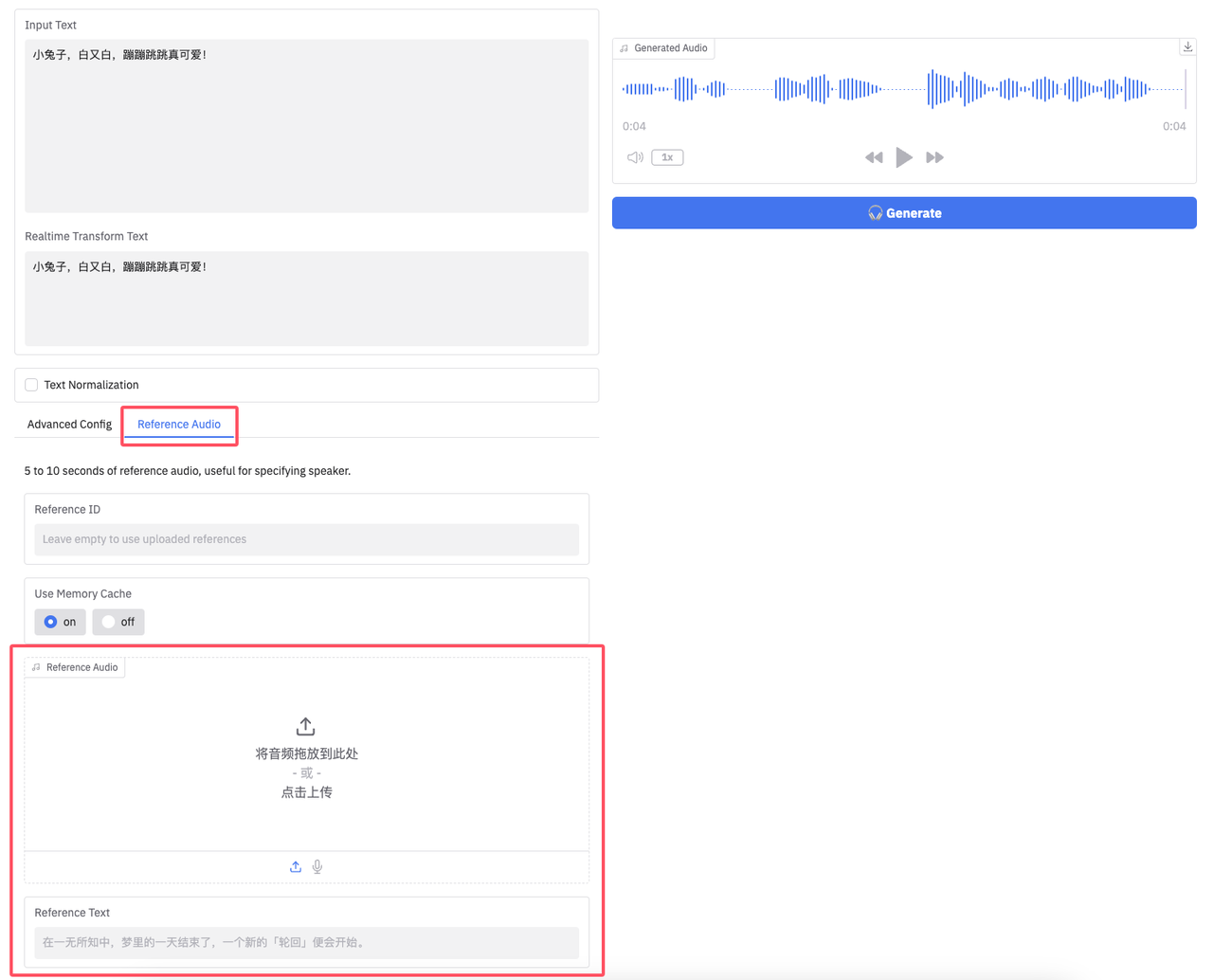
注意事项
- 必须启用参考音频。
- 参考音频时长建议为 5 到 10 秒,否则可能报错。
- 参考音频下方的“参考文本”应与音频内容一致。例如,如果音频内容是“你好,我是永雏塔菲”,则参考文本也应是“你好,我是永雏塔菲”。
- 对于口齿清晰的角色音频,使用预训练模型进行推理的效果会更好。
如何微调 Fish Speech 1.5
对于具有独特音色的角色音频,直接使用预训练模型进行推理的效果可能会比较差,所以需要进行微调模型。镜像中已经预置了三个jupyter文件,用于指导你一步步从数据准备阶段、预处理数据、训练模型直到完成微调,并使用微调后的模型进行推理,下面简单介绍一下主要的微调步骤:
数据准备
1. 将长时长且带有背景音的音频文件放到/root/workdir/MSST/input目录下:

2. 接着,输入以下命令对音频进行人声分离:
bash /root/workdir/MSST/putong.sh
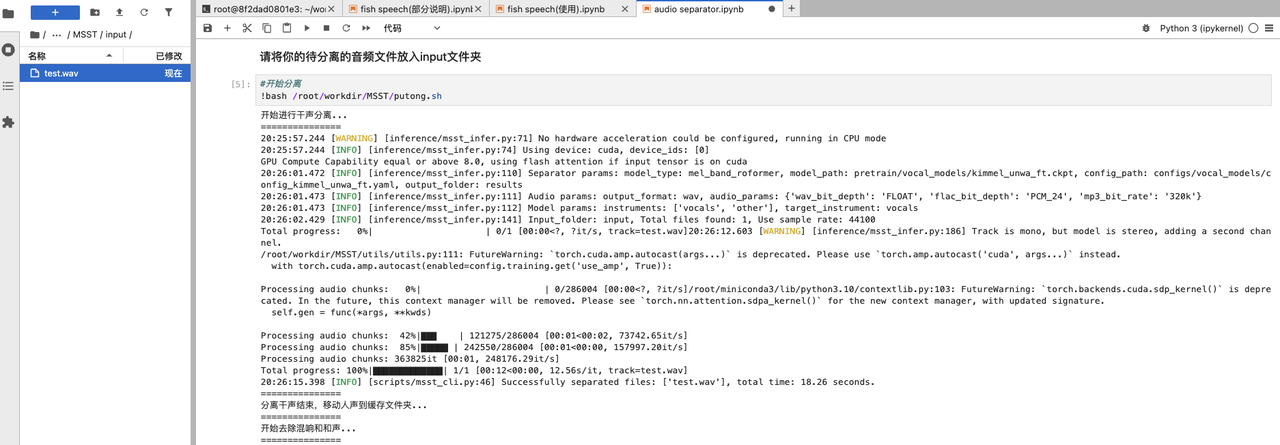
3. 将过处理后的长音频会被保存到/root/workdir/MSST/results目录中,输入以下命令将它移动到/root/workdir/audio-slicer/input目录中:
mv results/*_vocals_noreverb.wav /root/workdir/audio-slicer/input/
4. 接着,需要对长音频进行切割,将长音频切割成一段段短音频:
# 进入切割文件夹
cd /root/workdir/audio-slicer/
# 开始切割
bash start.sh
/root/miniconda3/bin/python audio-killer.py
5. 将已处理的短音频放到标注文件夹auto-VITS-DataLabeling/raw_audio中:
# 移动音频文件到标注文件夹
mv output/*.wav ../auto-VITS-DataLabeling/raw_audio
标注、预处理与训练阶段
准备好音频数据后,可以打开fish speech(使用).ipynb并按照步骤进行操作:
1. 标注与预处理:使用 auto-VITS-DataLabeling 工具对音频进行标注,并对标注后的数据进行预处理:
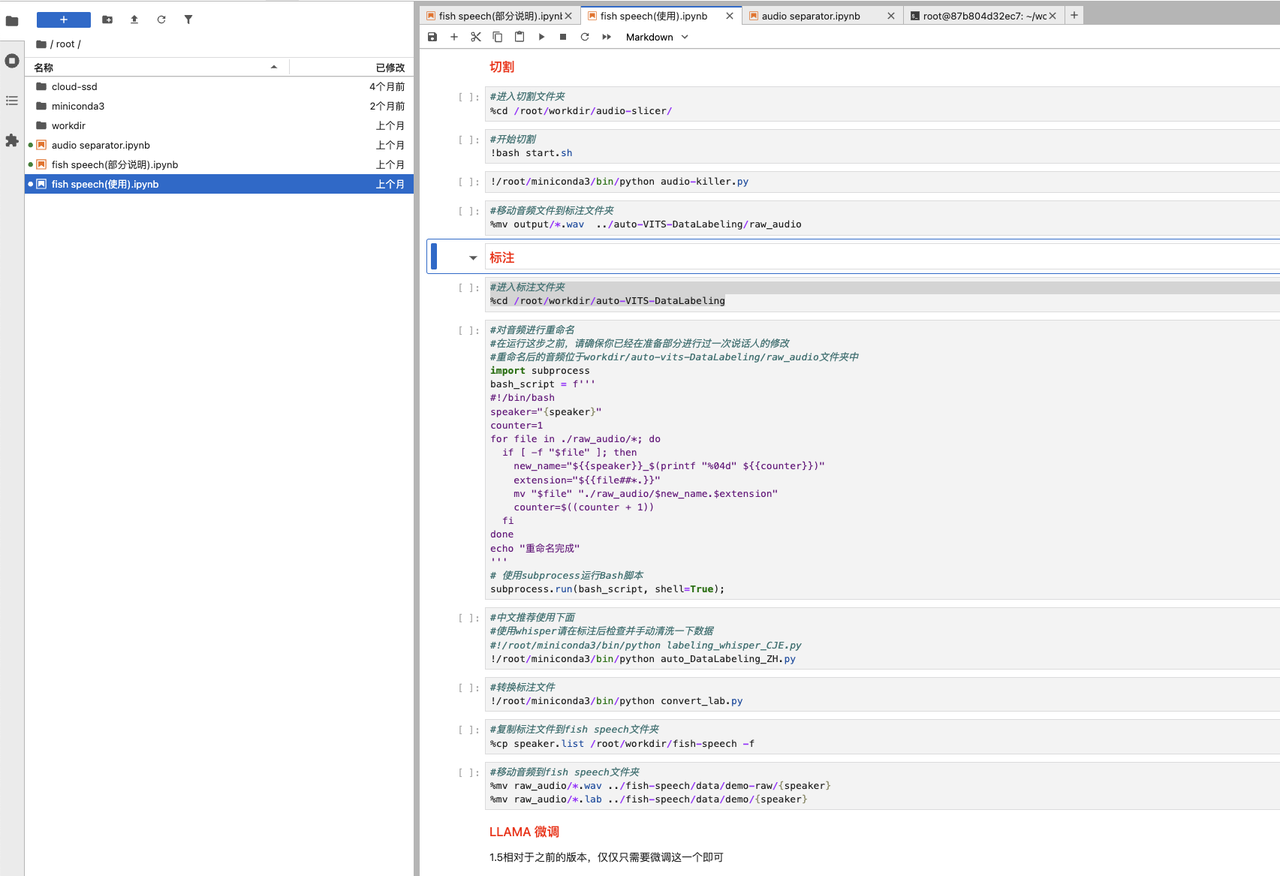
2. 训练(微调): 使用预处理后的数据进行模型训练:
模型的保存格式
<dirname>
——<modeldir 1>
——model.pth
——xxx.json
——<modeldir 2>
——model.pth
——xxx.json
融合后的模型保存在/root/workdir/fish-speech/output/fish-speech-1.5-yth-lora中。,这里只提供一个文件夹,用于测试融合后的模型,后续融合的模型会覆盖掉之前融合的,这是你推理所需要的模型。
推理
不同于前面运行 Fish Speech 1.5 (WebUI)的步骤,为了使用微调后的模型进行推理,这一步需要增加--llama-checkpoint-path参数指定来使用微调后的模型目录路径,默认为output/fish-speech-1.5-yth-lora:
cd /root/workdir/fish-speech
/root/miniconda3/bin/python -m tools.run_webui \
--llama-checkpoint-path "output/fish-speech-1.5-yth-lora" \
--compile
WebUI 服务默认运行在6006端口,启动成功后的使用步骤就跟Fish Speech 1.5 (WebUI)一样啦!
Enjoy it!
aiguoliuguo-镜像作者交流群

资源
 认证作者
认证作者