LLaMAFactory-0.9.2.dev-DeepSeek-R1-Distill
使用[LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory)在多张RTX4090上微调DeepSeek-R1-Distill系列模型
 4
40元/小时
v1.0
LLaMAFactory-0.9.2.dev-DeepSeek-R1-Distill
什么是 LLaMA-Factory-0.9.2.dev-DeepSeek-R1-Distill
LLaMA-Factory-0.9.2.dev-DeepSeek-R1-Distill基于LLaMA-Factory框架,支持在多张 NVIDIA RTX 4090 GPU 上进行模型微调。具体支持的模型及硬件需求如下:
| 模型名称 | 技术特点 | 硬件建议 |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B | 使用 LoRA 技术 | 1~2 张 RTX 4090 |
| DeepSeek-R1-Distill-Qwen-14B | 使用 LoRA 技术,结合 DeepSpeed ZeRO-3(ds3) | 4 张 RTX 4090 |
| DeepSeek-R1-Distill-Qwen-32B | 使用 LoRA 技术,结合 DeepSpeed ZeRO-3 Offload(ds3-offload) | 4 张 RTX 4090 |
如何运行 LLaMA-Factory-0.9.2.dev-DeepSeek-R1-Distill
创建实例
选择合适的机型,立即部署
待实例初始化完成后,在控制台-应用中打开”JupyterLab";进入JupyterLab后,新建一个终端Terminal输入以下指令
cd ~/LLaMA-Factory/
接着,运行以下命令可以对相应尺寸的模型进行监督微调(SFT):
7B 模型微调
llamafactory-cli train examples/train_lora/deepseek-r1-distill-qwen-7b_lora_sft.yaml
14B 模型微调
llamafactory-cli train examples/train_lora/deepseek-r1-distill-qwen-14b_lora_sft_ds3.yaml
32B 模型微调
llamafactory-cli train examples/train_lora/deepseek-r1-distill-qwen-32b_lora_sft_ds3.yaml
运行日志分析
这里以微调 DeepSeek-R1-Distill-Qwen-7B 模型为例,具体分析一下LLaMA-Factory的运行日志,了解使用LLaMA-Factory微调模型的过程。
一、初始化阶段
1. OMP_NUM_THREADS提示

这个提示是建议设置环境变量OMP_NUM_THREADS=1避免CPU资源争用,不过这个对训练影响较小,可以忽略设置。
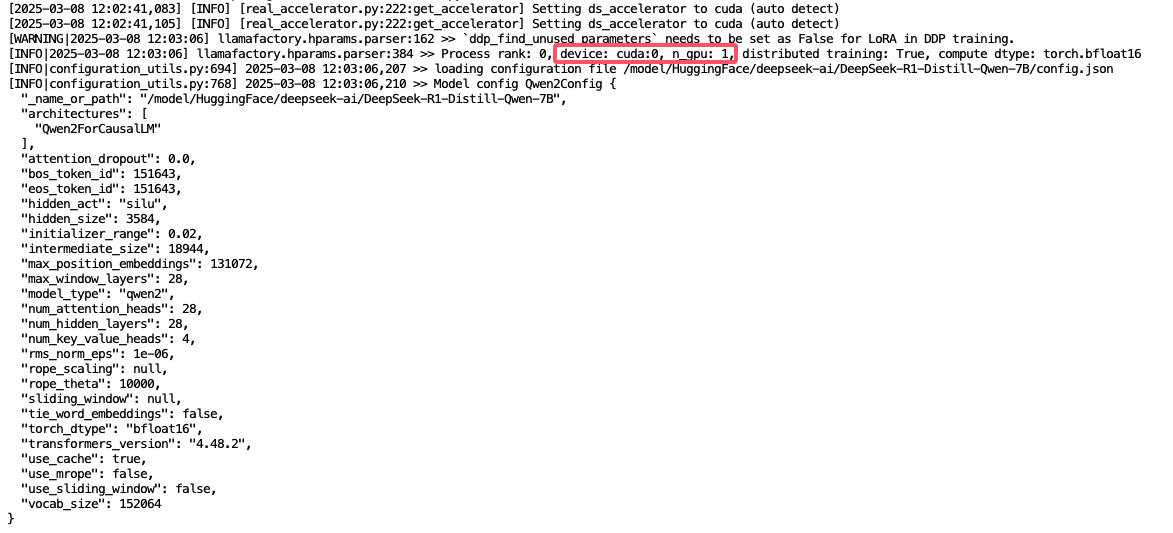
2. 分布式训练
- 分布式端口:29019,批次大小:16(通过梯度累积实现)
- 使用
torch.bfloat16混合精度训练,兼顾精度与显存效率。 - 因为使用的是 2 张 4090 显卡,所以这里提示检测到 2 个GPU
-
cuda:0
-
cuda:1
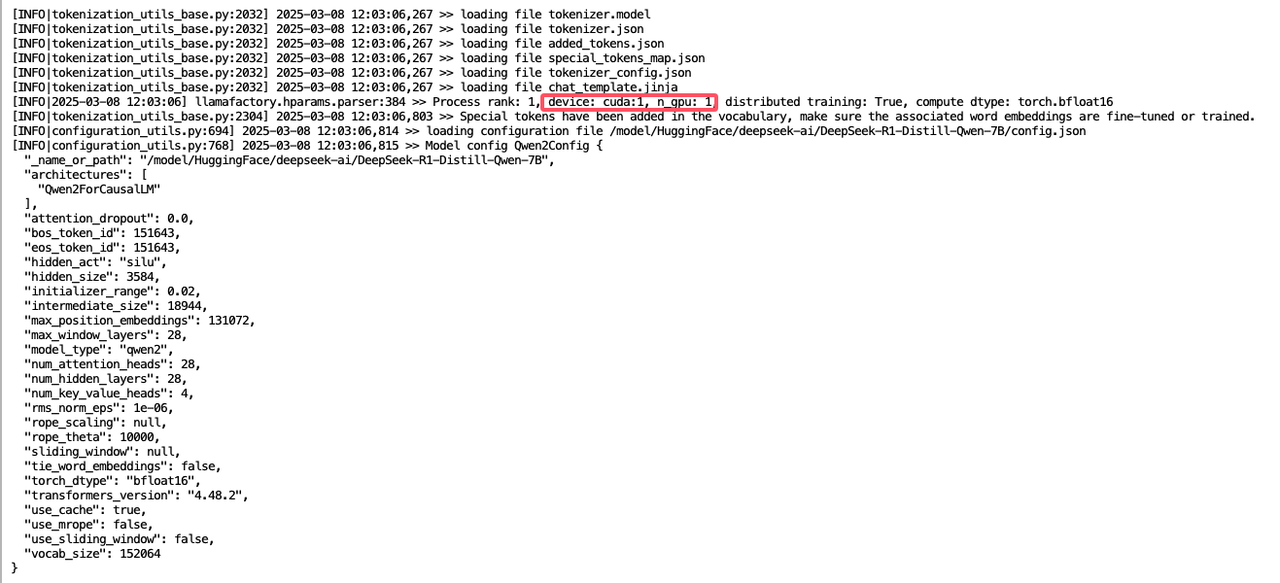
-
3. 从配置文件加载模型的基本信息
运行模型微调后,一开始会解析并加载DeepSeek-R1-Distill-Qwen-7B模型的配置文件,模型类型为Qwen2ForCausalLM,用于因果语言建模(文本生成):

- 核心参数:
hidden_size=3584 # 隐藏层维度
num_hidden_layers=28 # 总层数
num_attention_heads=28 # 注意力头数
vocab_size=152064 # 词表大小
max_position_embeddings=131072 # 支持最大上下文长度128K
4. 加载数据集
加载了identity.json和alpaca_en_demo.json两个数据集,共191个训练样本:

- 加载预训练权重
从
model.safetensors加载预训练权重(安全格式的模型文件):

二、训练阶段
- LoRA微调 使用LoRA(Low-Rank Adaptation)高效微调,可训练参数占比仅0.26%(20M/76亿):

- 适配层:
target_modules=[
"k_proj", "down_proj", "o_proj",
"q_proj", "v_proj", "gate_proj", "up_proj"
]
- 保存微调结果 每10步保存检查点(checkpoint-10/12):

最终模型保存在:

cd saves/DeepSeek-R1-Distill-Qwen-7B/lora/sft/
- 目录中包含:
- LoRA适配器权重
- 分词器配置
- 训练损失曲线图(training_loss.png)
三、训练结果分析

- 总训练步数:12步(1个epoch)
- 最终loss:2.3343(初始loss 2.3779)
- 训练速度:6.537样本/秒
- 总浮点运算量:846029 GFLOPS
- 训练耗时:29秒(含模型保存时间)
destroy_process_group()警告是PyTorch分布式训练的正常退出提示,不影响训练结果:

模型配置文件说明
以 DeepSeek-R1-Distill-Qwen-7B 模型为例,以下是配置文件的调整建议:
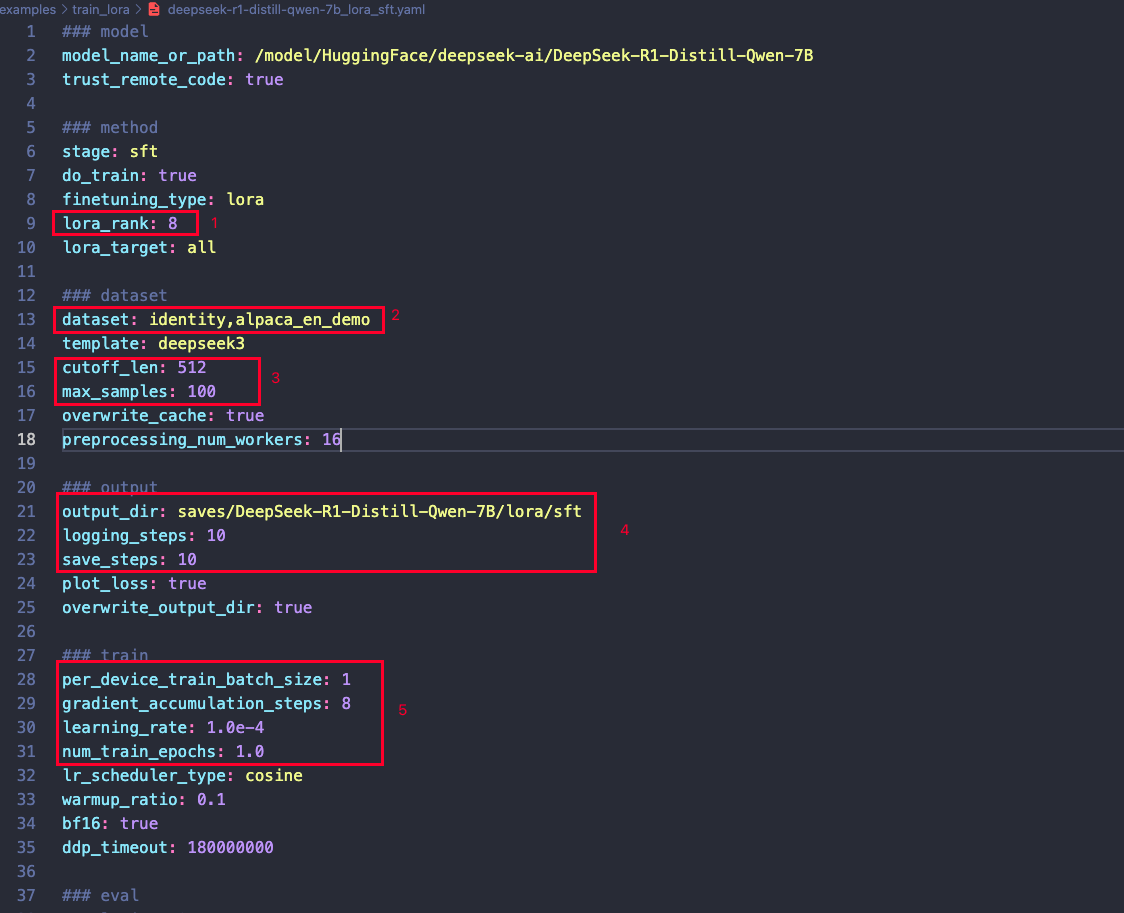
- 模型配置:根据任务需求和显存大小,调整截图中标注1️的LoRA配置部分。
- 数据集准备:在运行前,请确保已准备好数据集,并替换截图中标注2的dataset配置部分。
- 序列长度与样本量:截图中3️标注3,可根据需要调整最大序列长度和训练样本量。
- 训练设置:截图中标注4,可根据需要自行调整保存步数、日志频率、输出目录等参数。
- 训练参数:截图中标注5,可根据需要自行调整学习率、批量大小等训练参数。
本镜像由llamafactory.cn 提供支持。
@llamafactory_cn 认证作者
认证作者
认证作者
镜像信息
已使用227 次
运行时长
498 H
镜像大小
80GB
最后更新时间
2026-02-04
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.0
2026-02-04