ollama
Ollama镜像提供轻量级大语言模型本地运行框架,支持-R1 (7B/4.7GB)、Llama3.3 一键拉取与运行包括但不限于以下模型:DeepSeek、Llama3.2 、Phi4 、Gemma2:2b 、Mistral
 1
10元/小时
v1.0
Ollama
让大型语言模型在本地运行变得简单。
镜像快速部署教程
1. 在镜像详情界面,点击“使用该镜像创建实例”
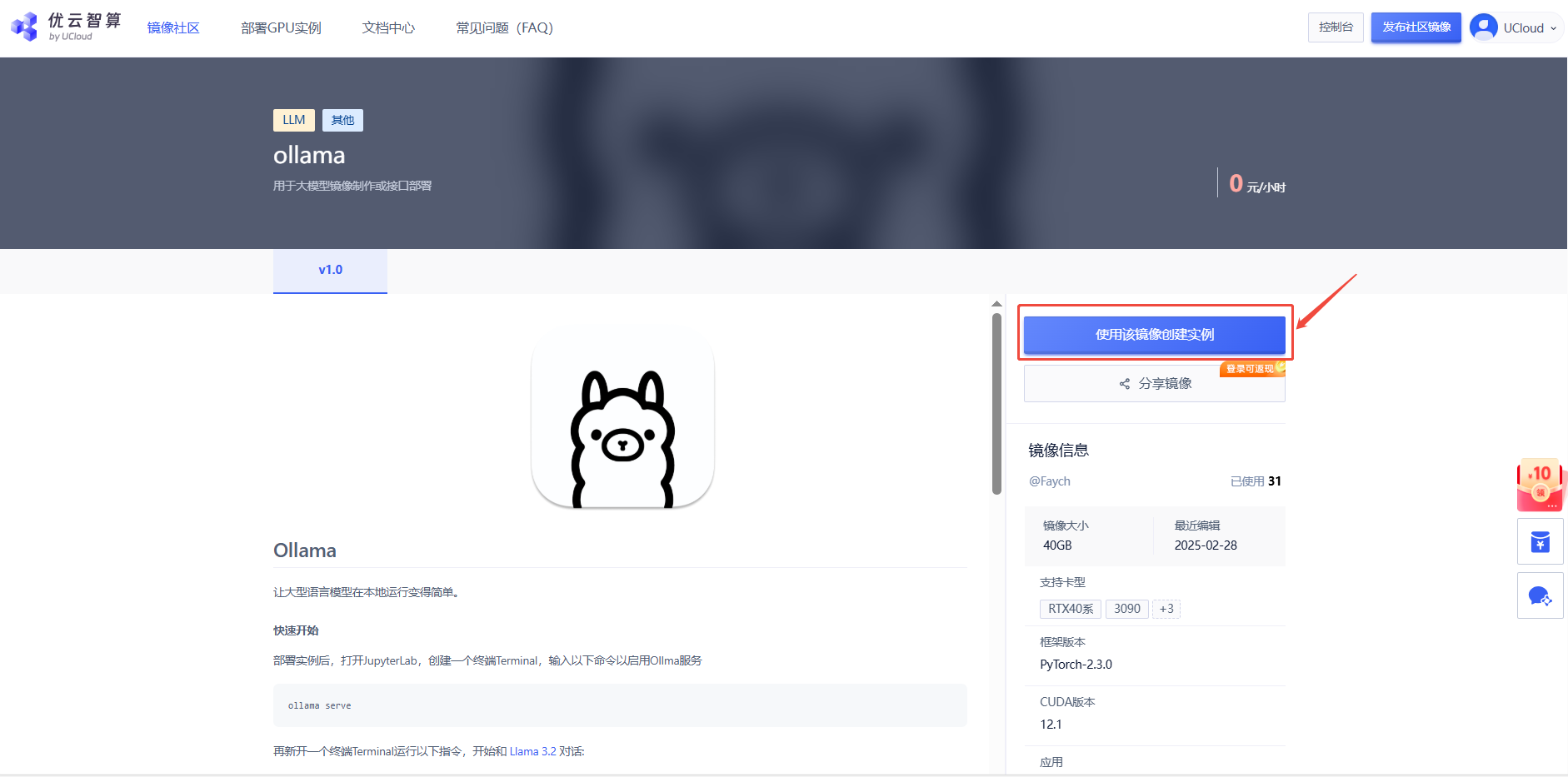
2. 先选择GPU型号(以RTX40系为例),再点击“立即部署”
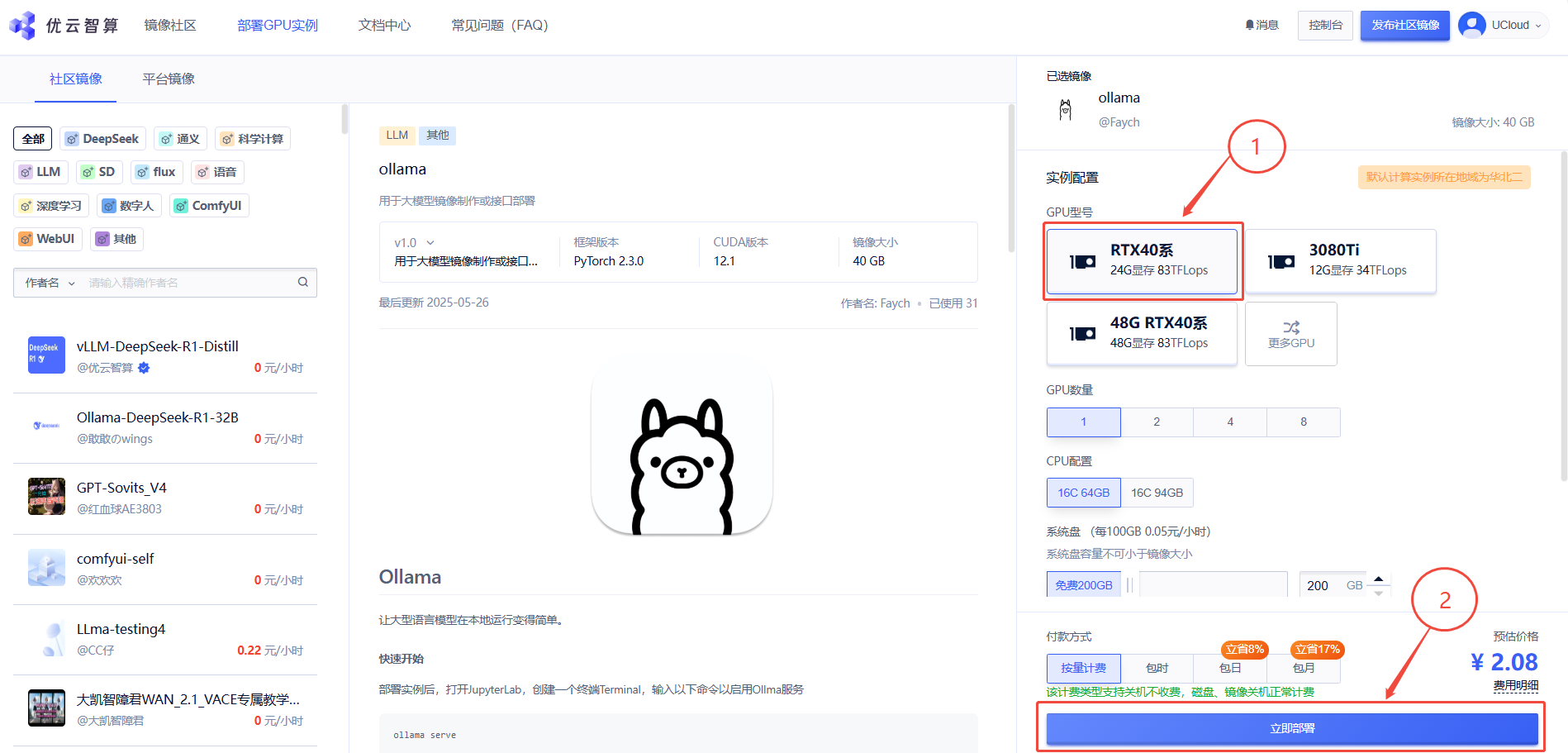
3. 待实例初始化完成后,在控制台-应用中点击“JupyterLab”

4. 进入JupyterLab后,新建一个终端Terminal,输入以下命令以启用Ollma服务
ollama serve
不要关闭前一个终端,再新开一个终端Terminal,输入以下指令
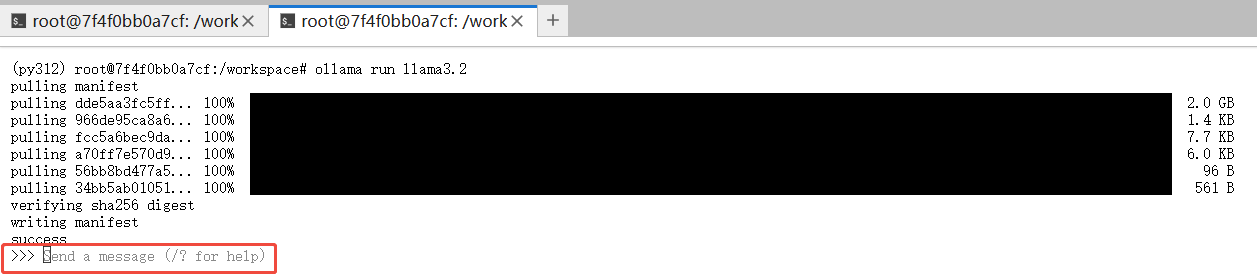
ollama run llama3.2
运行成功后如下图所示,在>>>后输入问题,即可开始和Llama开始对话
CLI 命令参考
创建模型
ollama create mymodel -f ./Modelfile
拉取模型
ollama pull llama3.2
移除模型
ollama rm llama3.2
复制模型
ollama cp llama3.2 my-model
多行输入
使用 """ 包装文本:
>>> """Hello,
... world!
... """
查看模型信息
ollama show llama3.2
列出本地模型
ollama list
查看正在运行的模型
ollama ps
停止运行中的模型
ollama stop llama3.2
REST API
Ollama 提供 REST API 用于运行和管理模型。
生成回答
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt":"Why is the sky blue?"
}'
与模型对话
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
自定义模型
可以通过 Modelfile 自定义模型:
FROM llama3.2
# 设置温度参数 [更高更具创造性,更低更连贯]
PARAMETER temperature 1
# 设置系统消息
SYSTEM """
你是超级马里奥。请以马里奥的口吻回答问题。
"""
支持库
社区交流
可用模型库
Ollama 支持多种模型,可在 ollama.com/library 查看。以下是部分示例:
| 模型 | 参数 | 大小 | 下载命令 |
|---|---|---|---|
| DeepSeek-R1 | 7B | 4.7GB | ollama run deepseek-r1 |
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Phi 4 | 14B | 9.1GB | ollama run phi4 |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Mistral | 7B | 4.1GB | ollama run mistral |
NOTE
运行 7B 模型需要至少 8GB RAM, 运行 13B 模型需要 16GB RAM, 运行 33B 模型需要 32GB RAM。
@Faych

镜像信息
已使用76 次
运行时长
139 H
镜像大小
40GB
最后更新时间
2025-07-14
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.1
应用
JupyterLab: 8888
版本
v1.0
2025-07-14