 1
1Gemma 3 镜像
Gemma 3 镜像简介
- 镜像预先下载了 Gemma 3 尺寸为 1B、4B、12B 和 27B 的大模型,无需重复下载模型,加载模型快人一步!
- 基于 Ollama 可以快速部署 Gemma 3 不同尺寸的大模型,并安装了 Open-WebUI 以快速实现可视化聊天。
- 在
bashrc中已设置export AIOHTTP_CLIENT_TIMEOUT_MODEL_LIST=5,设置 Open-WebUI 在连接不上 API 只需要暂停加载 5 秒,默认是暂停 5 分钟。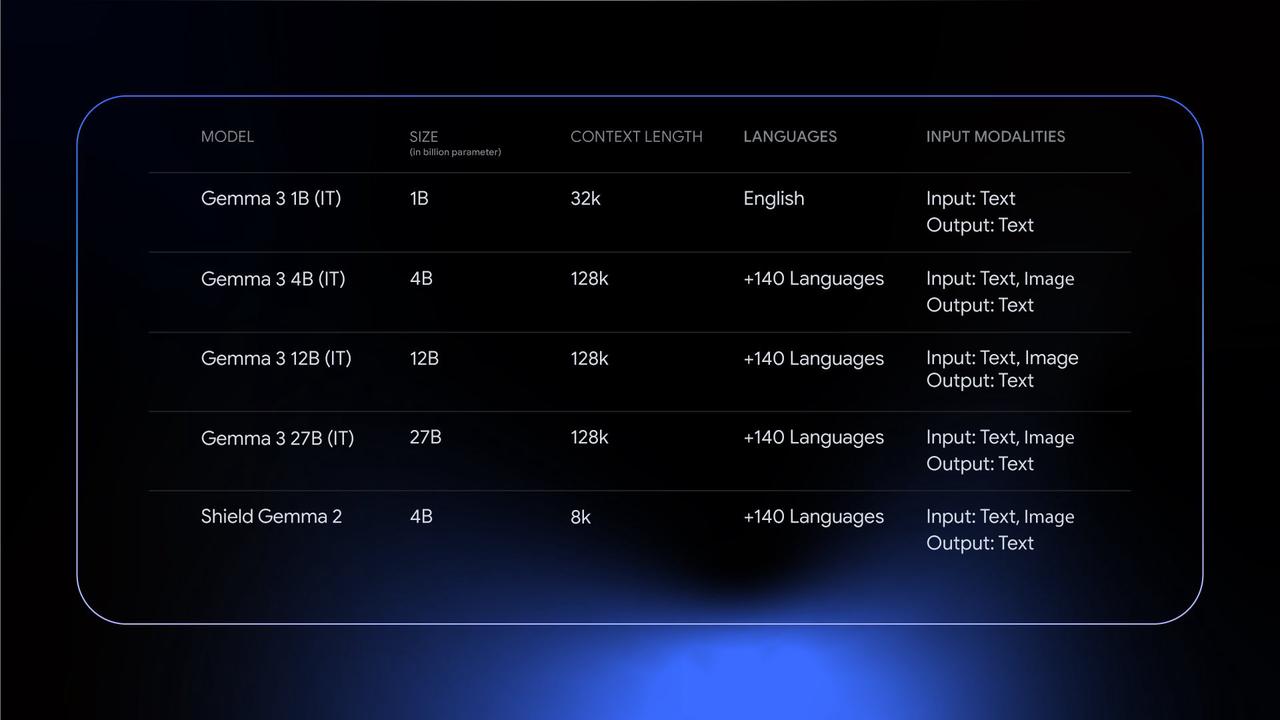
Gemma 3 是谷歌最新推出的开源轻量级多模态模型,被称为全球最强的单加速器模型,在单 GPU 或 TPU 环境下表现显著优于其他同类模型。它支持超过 140 种语言的预训练,直接支持超过 35 种语言,具备分析文本、图像及短视频的能力,提供了四种不同尺寸的模型(1B、4B、12B 和 27B),满足不同硬件和性能需求,支持在多种设备上进行 AI 应用开发。
如何运行 Gemma 3
1、启动 Ollama 服务和 Open-WebUI 服务
待实例初始化完成后,在控制台-应用中打开JupyterLab,新建一个终端Terminal,运行以下命令启动 Ollama 服务: `
ollama serve
如图所示,成功启动 Ollama 后服务默认运行在 11434 端口:

注意不要关闭前一个终端窗口。下一步,另外新建一个终端,运行以下命令启动 Open-WebUI 服务:
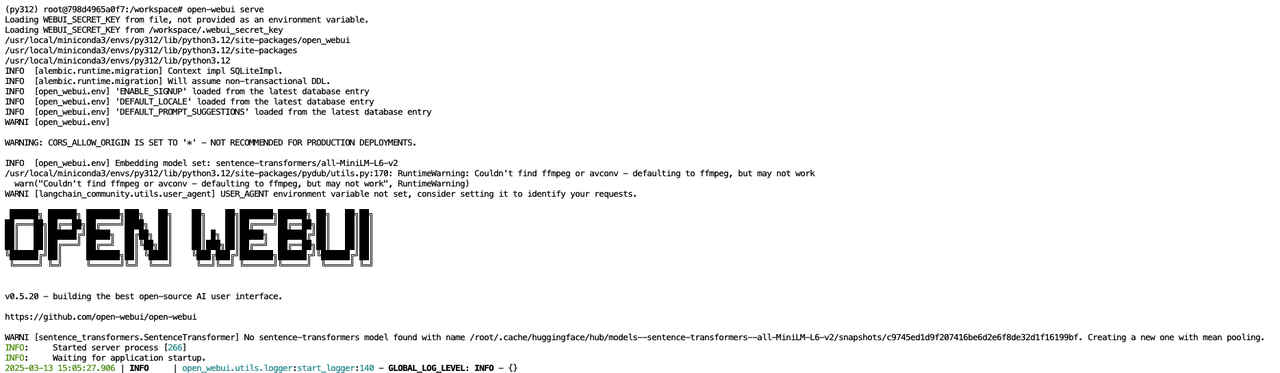
open-webui serve
Open-WebUI 服务默认运行在 8080 端口,当出现以下输出信息时说明服务已经成功启动:
2、打开可视化页面
成功启动 Ollama 服务和 Open-WebUI 服务后,通过本地浏览器访问实例外网ip:8080,外网ip可以在控制台-基础网络(外)中获取,打开可视化页面并登录用户:

登录 Open-WebUI 默认的管理员邮箱是 root@root.com,密码是 root。
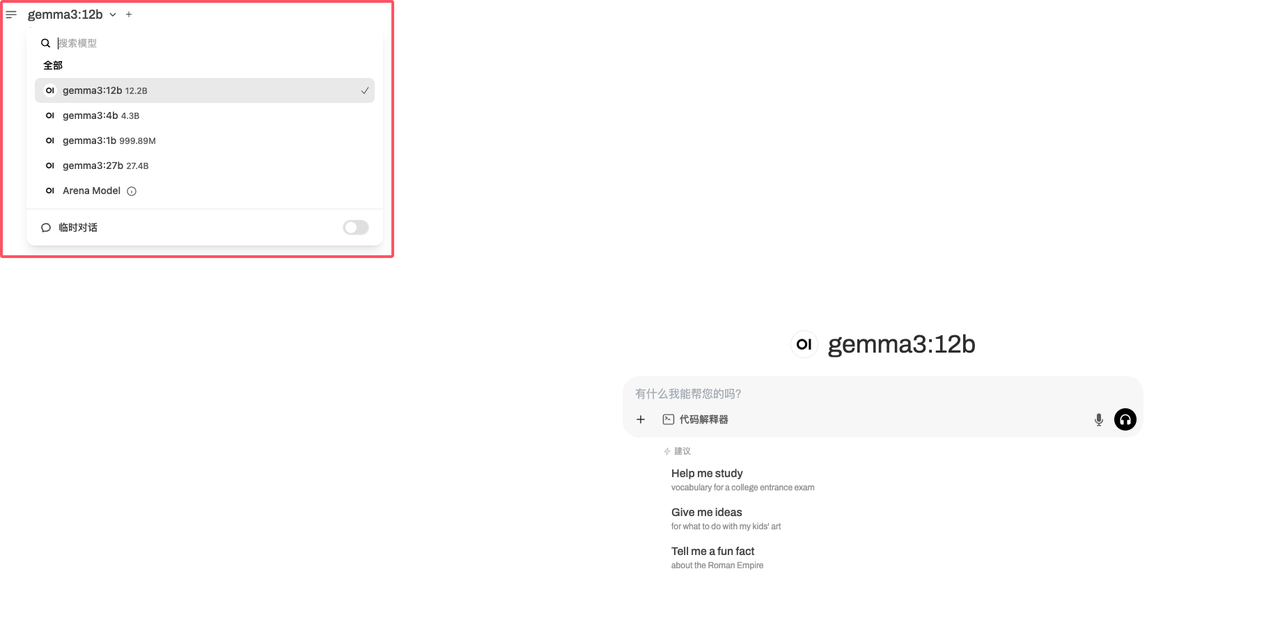
3、选择模型
默认使用gemma3:12b模型,可以在页面的左上角切换其他尺寸的 Gemma 3 模型:
4、开始对话
在对话框在输入问题后点击发送消息按钮即可跟模型开始对话,模型的回复结果也会在对话历史记录中以流式输出进行展示:

因为模型初始化需要经过模型加载阶段、GPU 初始化与显存分配、模型参数初始化、并行化配置、服务端预热等过程,所以首次延迟是本地部署大模型的典型现象,后续推理速度会显著提升!
运行官方的代码示例
在/model/HuggingFace/google下有gemma-3所有的开源模型。其中,pt结尾是预训练基座模型,it结尾的是指令微调版本,建议使用it结尾的模型来运行官方的代码示例:
python demo.py --model_id /model/HuggingFace/google/gemma-3-4b-it
运行这个代码示例试试让 Gemma-3-4b 模型描述以下图片中的细节:

输出结果如下:

Really Good!Let‘s enjoy it!
资源
 认证作者
认证作者