MSST
MSST-webUI版本,更简单,加入一键处理,效率更高,更好用的干声分离以及去和声混响的项目,可以作为传统UVR的上位替代,并兼容UVR的模型,简单且快。
 44
440元/小时
v2.0
v1.0
MSST镜像使用教程
镜像作者:bilibili@爱过_留过
交流群:172701496
详细文档地址:https://r1kc63iz15l.feishu.cn/wiki/JSp3wk7zuinvIXkIqSUcCXY1nKc
aiguoliuguo-镜像作者交流群

视频
# MSST 是什么 这是一个用于 [Music-Source-Separation-Training (MSST) ](https://github.com/ZFTurbo/Music-Source-Separation-Training)的 WebUI,MSST 是一个用于训练音乐源分离模型的仓库。 你可以使用这个 WebUI 推断 MSST 模型和 VR 模型,`预设流程`页面允许您自定义处理流程。在`安装模型`界面安装模型。如果你之前已经下载了 [Ultimate Vocal Remover (UVR)](https://github.com/Anjok07/ultimatevocalremovergui),则无需重新下载VR模型。直接进入`设置`页面,选择你的 UVR5 模型文件夹。在 WebUI 中还提供了一些便捷的工具,例如 [Singing-Oriented MIDI Extractor (SOME)](https://github.com/openvpi/SOME/)、更高级的合奏模式等。如何运行 MSST
通过镜像可以一键部署实例,部署成功后,可以在实例列表中看到实例对应的公网IP:

启动 WebUI 服务 按顺序执行以下命令,启动 WebUI 服务:
- 进入项目目录:
cd /root/MSST
- 设置 Matplotlib 的默认渲染后端为 Agg:
export MPLBACKEND=Agg
- 启动 WebUI 服务:
/root/miniconda3/bin/python webUI.py --use_cloud --language "zh_CN" -d --model_download_link "hf-mirror.com" --ip_address "0.0.0.0" --port "7860"
WebUI 服务默认运行在7860端口,启动成功后你可以在控制台看到如下输出:

接着,通过本地浏览器访问http://<公网IP>:7860打开 WebUI 页面:
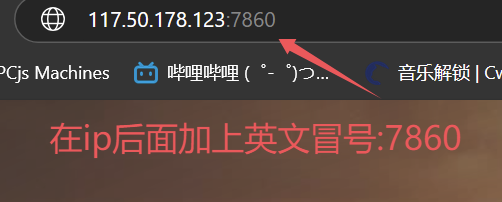
官方为中文用户提供了一些详细的中文文档,点击 这里 跳转,下面我以
MSST分离功能作为示例进行演示。
MSST 分离演示示例
点击顶部导航栏中的MSST分离选项,来到MSST分离功能页。
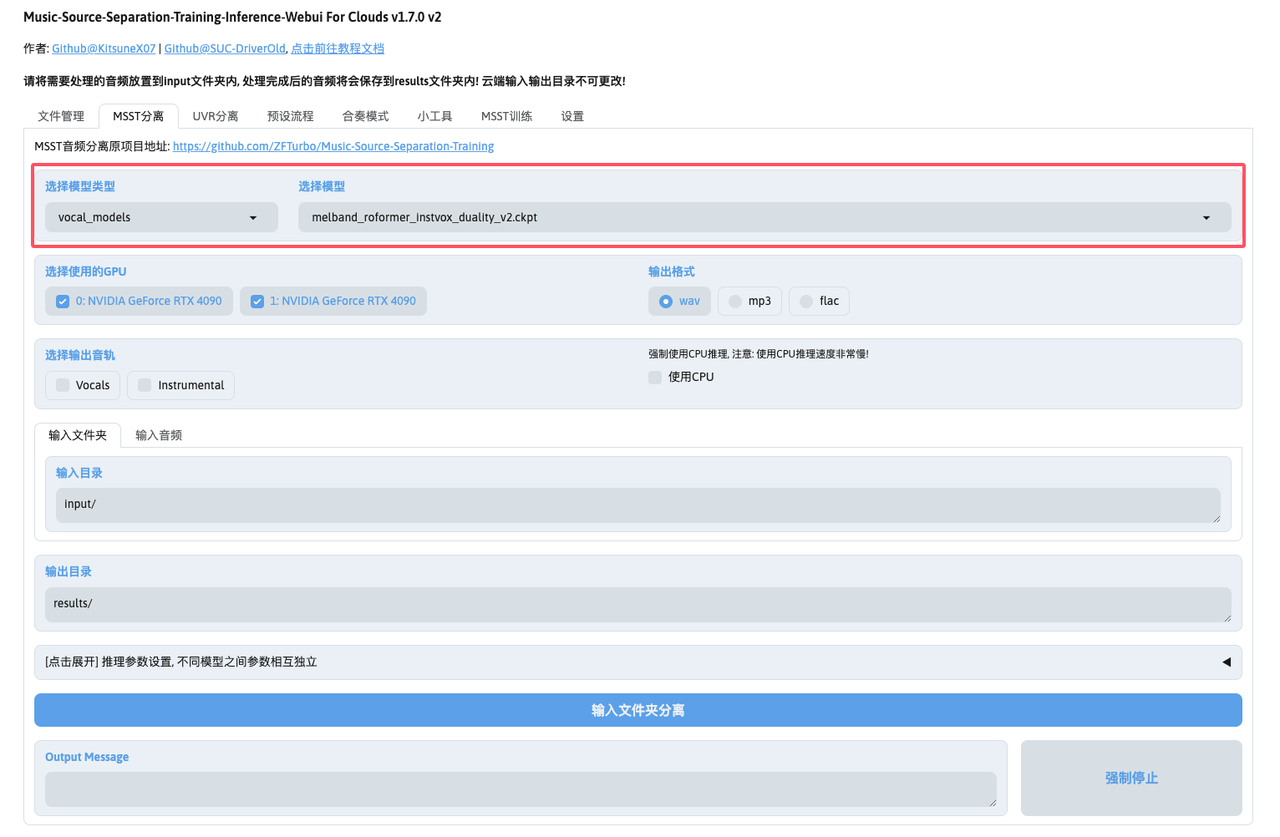
1. 设置模型类型
MSST提供了三种模型类型:
- 多音轨分离模型 (
multi_stem_models) - 单音轨分离模型 (
single_stem_models), 通常只提取两个音轨:目标音轨和剩余音频 - 人声和伴奏分离模型 (
vocal_models) 这里我选择使用vocal_models类型和melband_roformer_instvox_duality_v2.ckpt模型来分离人声和伴奏:
2. 设置基本参数
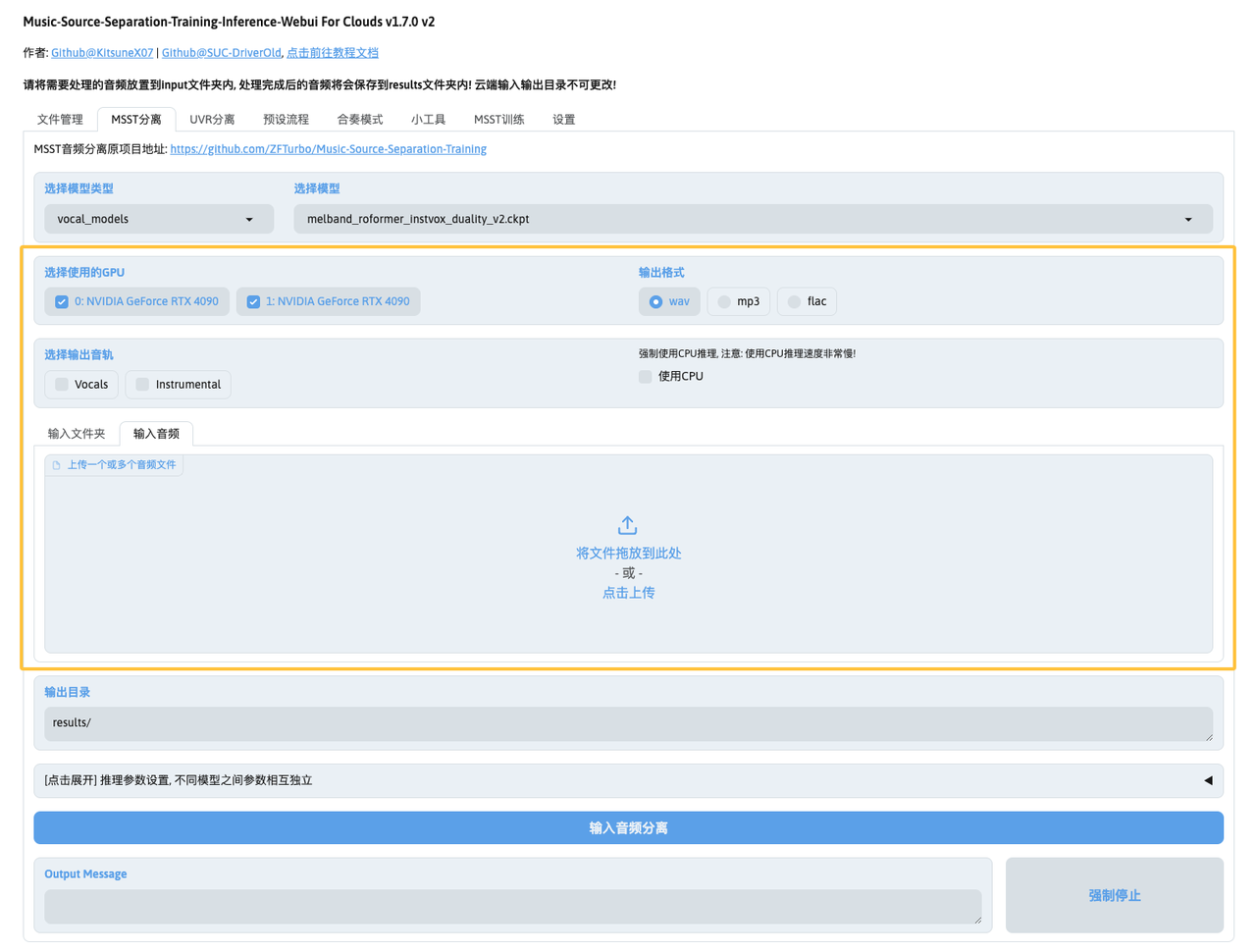
- 输出格式:支持
wav、flac和mp3格式输出。高级输出设置请参阅音频输出设置。 - 输出音轨:不同模型对应不同的输出音轨,按需选择即可,支持多选;如果不勾选,则默认输出所有音轨。
- 推理设备:不建议使用CPU。例如,4分钟的音频在AMD Ryzen 7 6800H(12核)上推理就需要30-40分钟。建议使用GPU以加快处理速度。
- 输入音频:可以上传一个或多个音频文件,或选择一个文件夹以处理该文件夹中的所有音频文件(通过
输入文件夹上传)。 这里我部署实例时选择了2张RTX4090显卡,所以可以看到两个GPU选项,两个都可以勾选上:
3. 设置推理参数
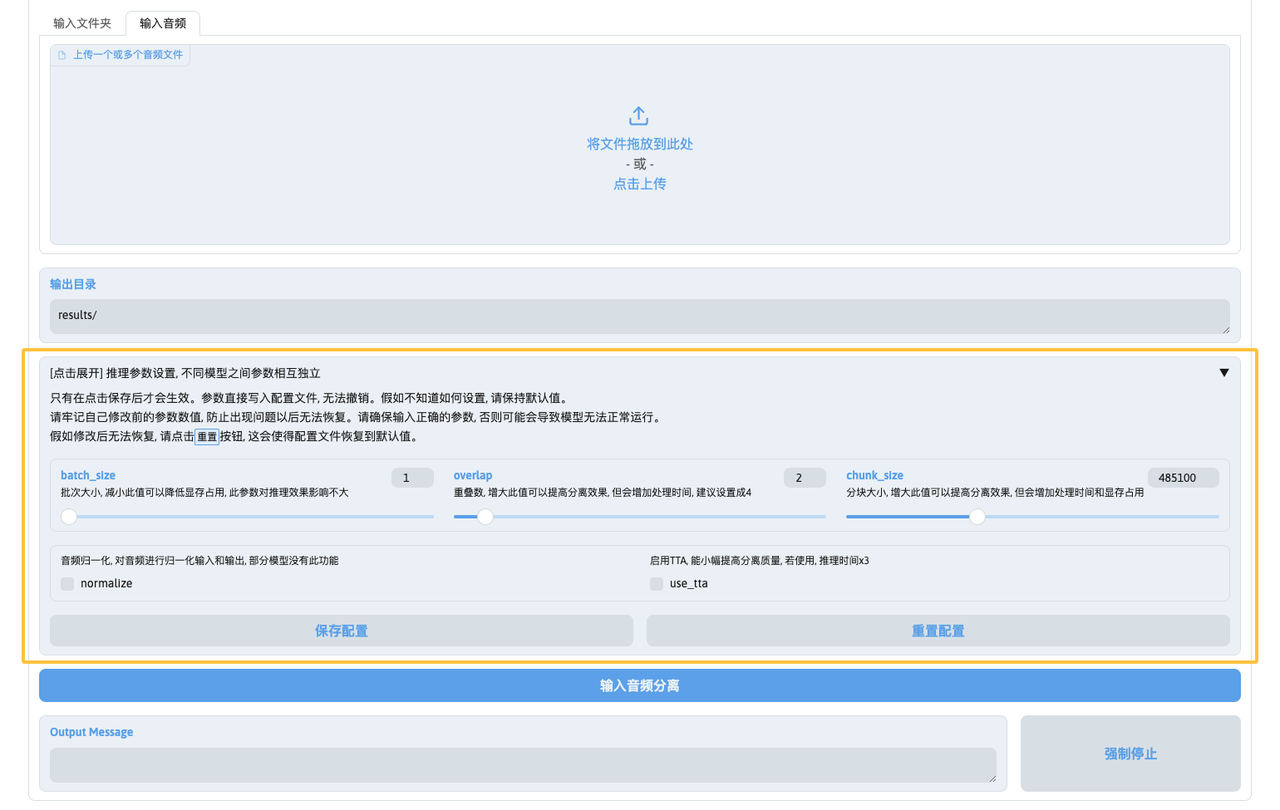
3.1. 常见参数解释
batch_size:一次处理的批次数。默认为1,增大此值会增加显存占用,但对速度提升有限。建议保持默认值。num_overlap:窗口重叠长度。数值越小推理速度越快,但效果会有所牺牲。建议设为4以平衡速度和质量,设为2可显著提升速度但牺牲部分质量。chunksize:音频切片大小。增大此值可以提高分离效果,但会增加处理时间和显存占用。建议设为44100的整数倍或0.5倍(如5倍、7.5倍、10倍等),以确保模型正常工作。
3.2. 其他注意事项
- 启用TTA会将处理时间增加三倍,但对质量提升不明显,不建议启用。
- 部分模型支持音频归一化功能,可以启用以优化输出效果。
- 不同模型的参数相互独立,修改的参数仅对当前选择的模型生效。
- 修改参数后需点击保存,参数才会生效。若需恢复默认设置,可点击重置按钮。
4. 上传文件
这里我选择输入音频,上传了一个待处理的音频文件:
这里建议将超长音频进行切分,最好每段不超过1小时,以避免出现内存不足的问题。
5. 开始分离
完成上述参数设置,并且等待音频上传完成后,点击输入音频按钮即可开始分离:
你的硬件配置、选择的模型以及模型的参数设置将会影响到音频分离所需的时间,稍等片刻,分离完成后将会在输出信息(Output Message)中提示处理结果和保存文件的目录路径:
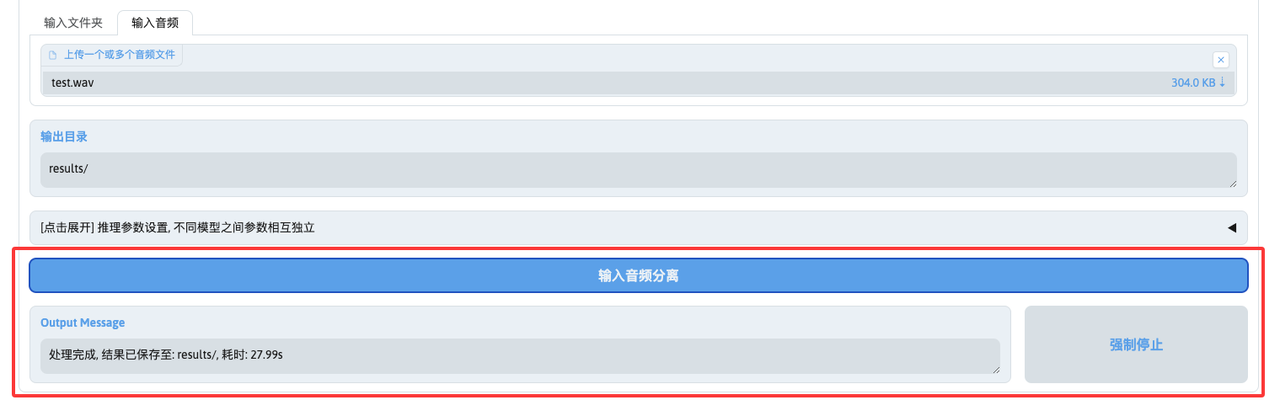
6. 下载文件
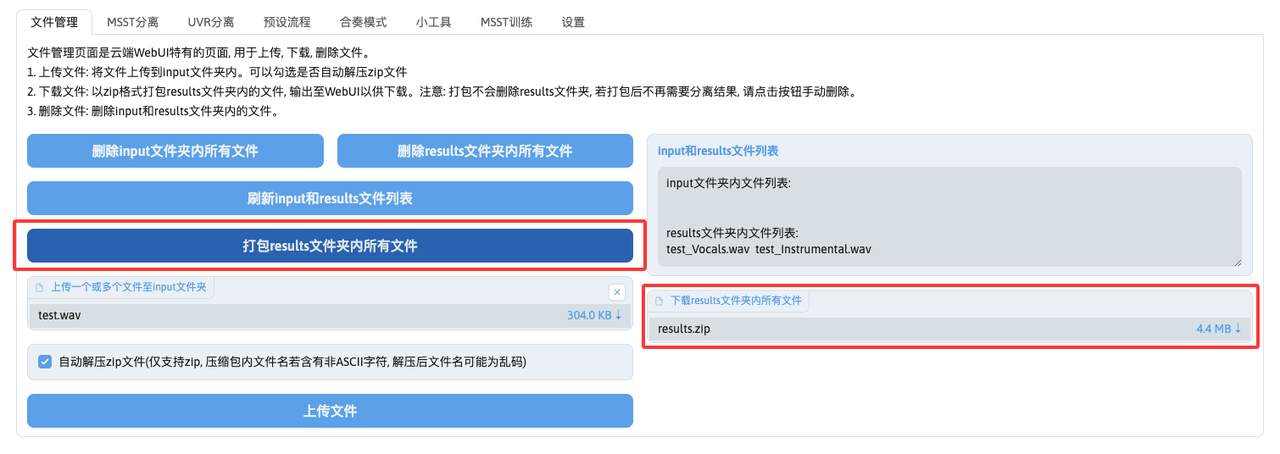
分离完成后,我们需要到文件管理页点击刷新input和results文件列表按钮,必须刷新后才能看到上一步完成分离后的文件列表。
刷新后,在results文件列表中可以看到分离的人声和伴奏音频文件:

最后,点击打包results文件夹内所有文件按钮,将results文件夹内所有的音频文件打包成压缩包后,就可以点击下载了:
资源
@aiguoliuguo 认证作者
认证作者
认证作者
镜像信息
已使用1085 次
运行时长
3106 H
镜像大小
50GB
最后更新时间
2025-10-05
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100SV100S
+14
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
自定义开放端口
7860
+1
版本
v2.0
2025-10-05
v1.0
2025-07-03