Qwen-vLLM-Series
包含Qwen2.5-VL多模态、QWQ-32B两个模型,并带有WebUI界面,立即部署即可快速使用
 3
30元/小时
v1.0
Qwen系列大模型集合
镜像简介
本镜像是阿里官方提供的Qwen系列模型高效推理框架,集成Qwen2.5-VL多模态与QWQ-32B大语言双模型,并内置直观的WebUI操作界面。支持开箱即用的快速部署,适用于视觉理解、复杂推理、智能对话及多模态应用开发等场景,为用户提供一站式、零成本的专业级模型服务体验。
- 此次主要推出了两个大模型Qwen2.5-VL-32B-Instruct、QwQ-32B,及其使用方式。
操作步骤
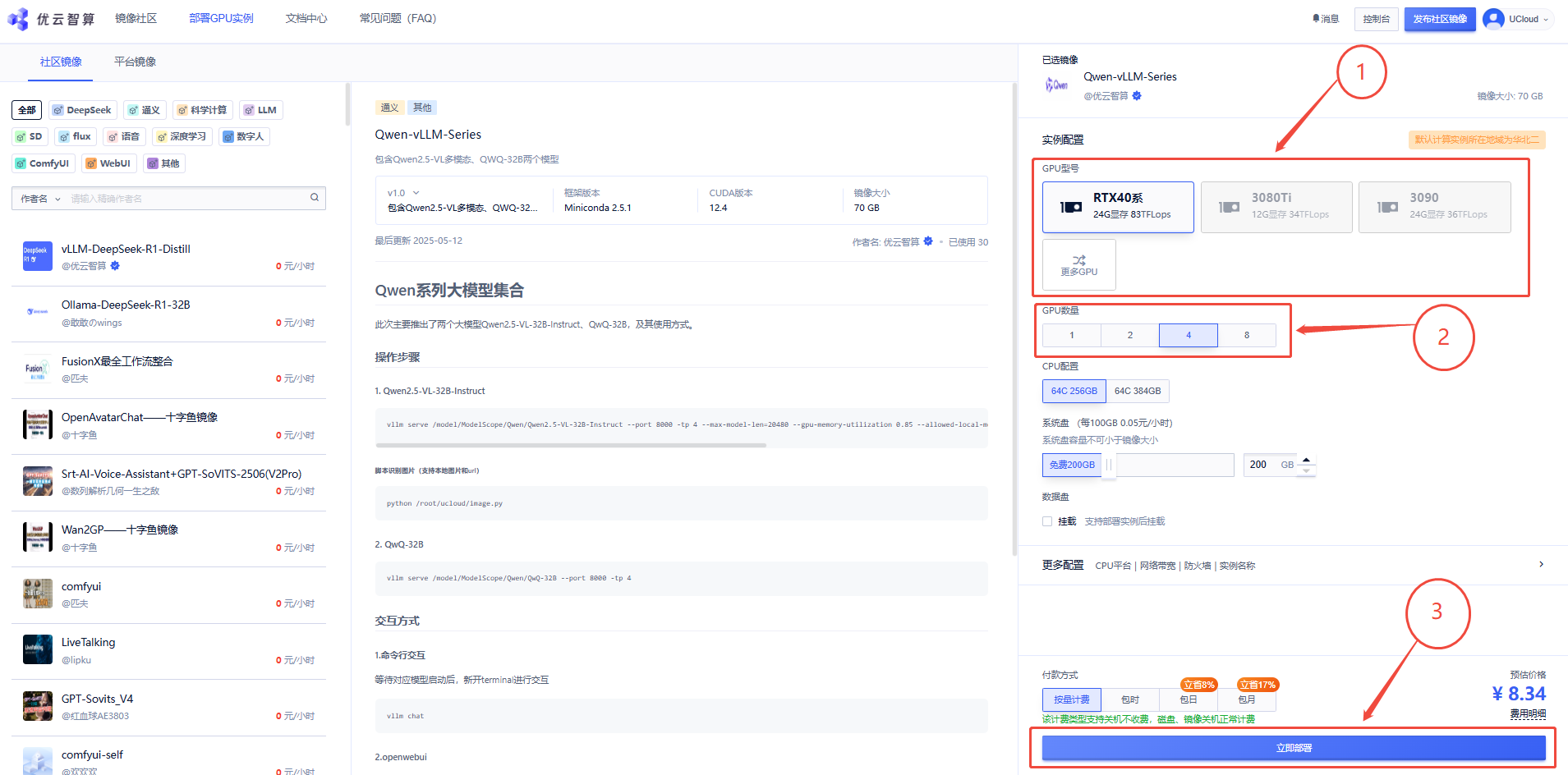
1. 先选择GPU型号,再选择GPU数量(注意!要运行该镜像需要RTX40系4卡运行),再点击“立即部署“
2. 待实例初始化完成后,在控制台-应用中点击”JupyterLab“进入

3. 进入JupyterLab之后,新建一个终端Terminal,根据想要运行的模型来选择对应指令输入
Qwen2.5-VL-32B-Instruct
vllm serve /model/ModelScope/Qwen/Qwen2.5-VL-32B-Instruct --port 8000 -tp 4 --max-model-len=20480 --gpu-memory-utilization 0.85 --allowed-local-media-path /root --mm_processor_kwargs '{"max_pixels": 589824,"min_pixels": 3136}'
脚本识别图片(支持本地图片和url)
python /root/ucloud/image.py
QwQ-32B
vllm serve /model/ModelScope/Qwen/QwQ-32B --port 8000 -tp 4
交互方式
等待模型启动后,再进行交互方式的启动
1.命令行交互
等待对应模型启动后,新开终端Terminal输入以下指令
vllm chat
启动后,即可在命令行中进行交互

2.OpenWebUI
等待对应模型启动后,启动open webui 服务
conda activate openwebui
open-webui serve --port 8080
待WebUI启动后,即通过浏览器访问:http://ip:8080 ,ip替换为虚机实例的外网ip,登陆邮箱:ucloud@ucloud.cn 密码:ucloud.cn
扫码加入优云智算使用交流群

@优云智算

镜像信息
已使用98 次
运行时长
2742 H
镜像大小
70GB
最后更新时间
2026-02-04
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
自定义开放端口
8080
+1
版本
v1.0
2026-02-04