 118
118GPT-SoVITS
镜像简介
GPT-SoVITS-V4是一款先进的语音合成与克隆工具,支持使用极少量语音样本快速训练出高质量的音色模型。它在情绪控制与自然度上表现突出,显著缩短了训练耗时,适用于个性化虚拟人配音、有声内容制作、语音助手定制等场景,为创作者提供了高效且富有表现力的语音生成方案。
GPT-SoVITS镜像使用教程
aiguoliuguo-镜像作者交流群

1:镜像准备
官方测试通过3080ti,推荐租用:3090、3080ti、4090。对于GPT-SoVITS来说够用了
2:处理数据集
请认真准备数据集!以免后面出现各种报错,和炼出不理想的模型!好的数据集是炼出好的模型的基础!
2.1:上传原音频
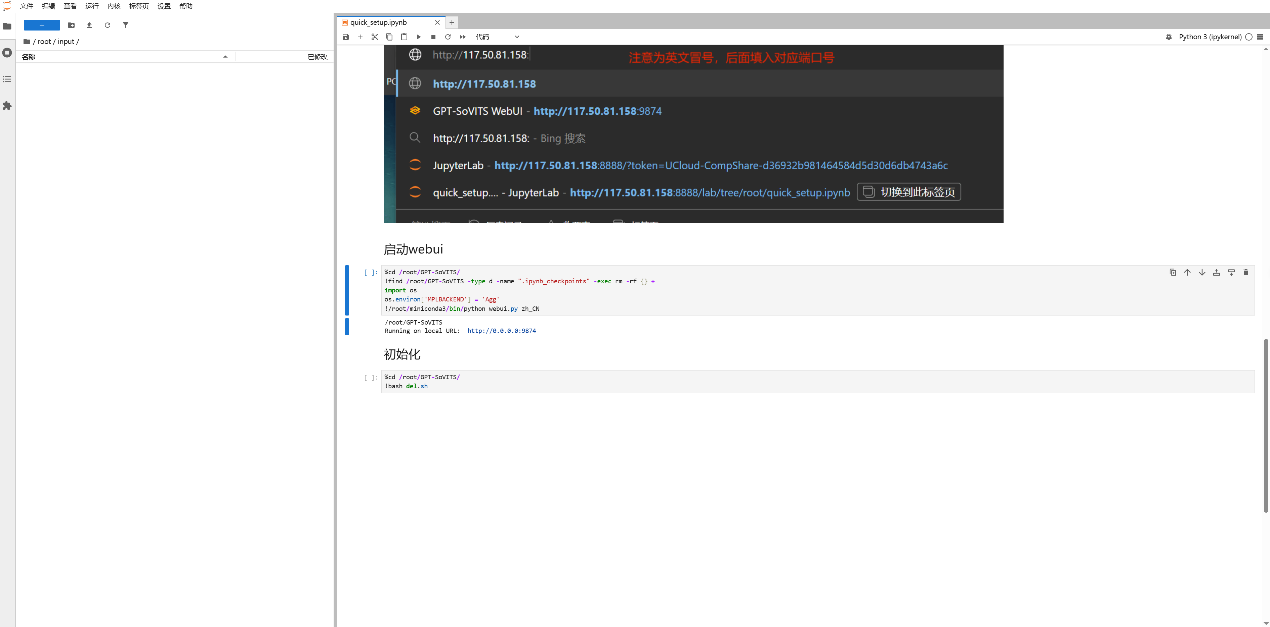
开机后点JupyterLab

然后打开input文件夹,将音频上传到这里面
2.2:开启WebUI
然后来到JupyterLab打开的页面,点击启动webui下面这个,然后点击上面的启动键
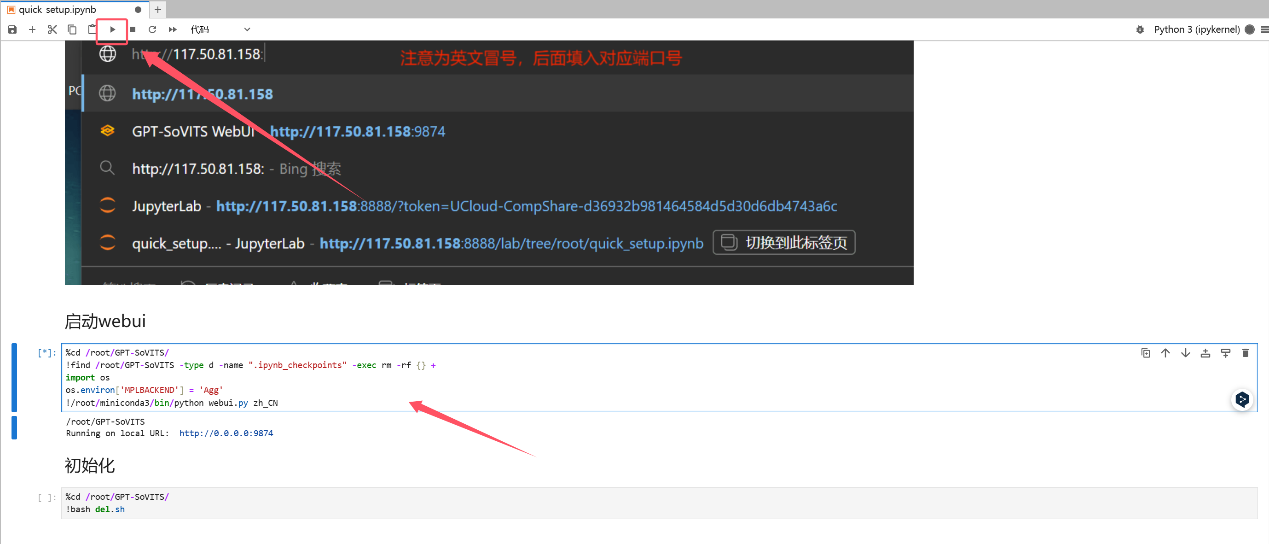
然后回到控制台复制这个外网链接,在后面加上:9874,在浏览器中打开。 比如外网链接是:117.50.241.83,端口是9874,对应的链接就是117.50.241.83:9874
注意!不要把外网链接发给陌生人!

然后就是和整合包一样的内容,更详细的看整合包教程
2.3:UVR5提取人声
2.3.1:方法1:使用自带的UVR5处理音频
点击开启UVR5-WebUI,打开外网链接:9873这个网址,uvr5对应端口是9873

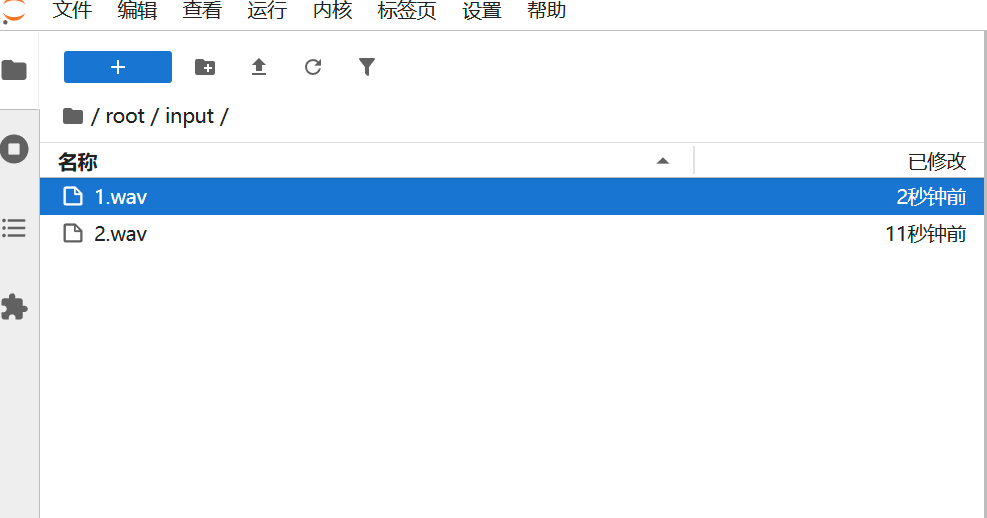
上传音频到input 文件夹内或者网页直接上传
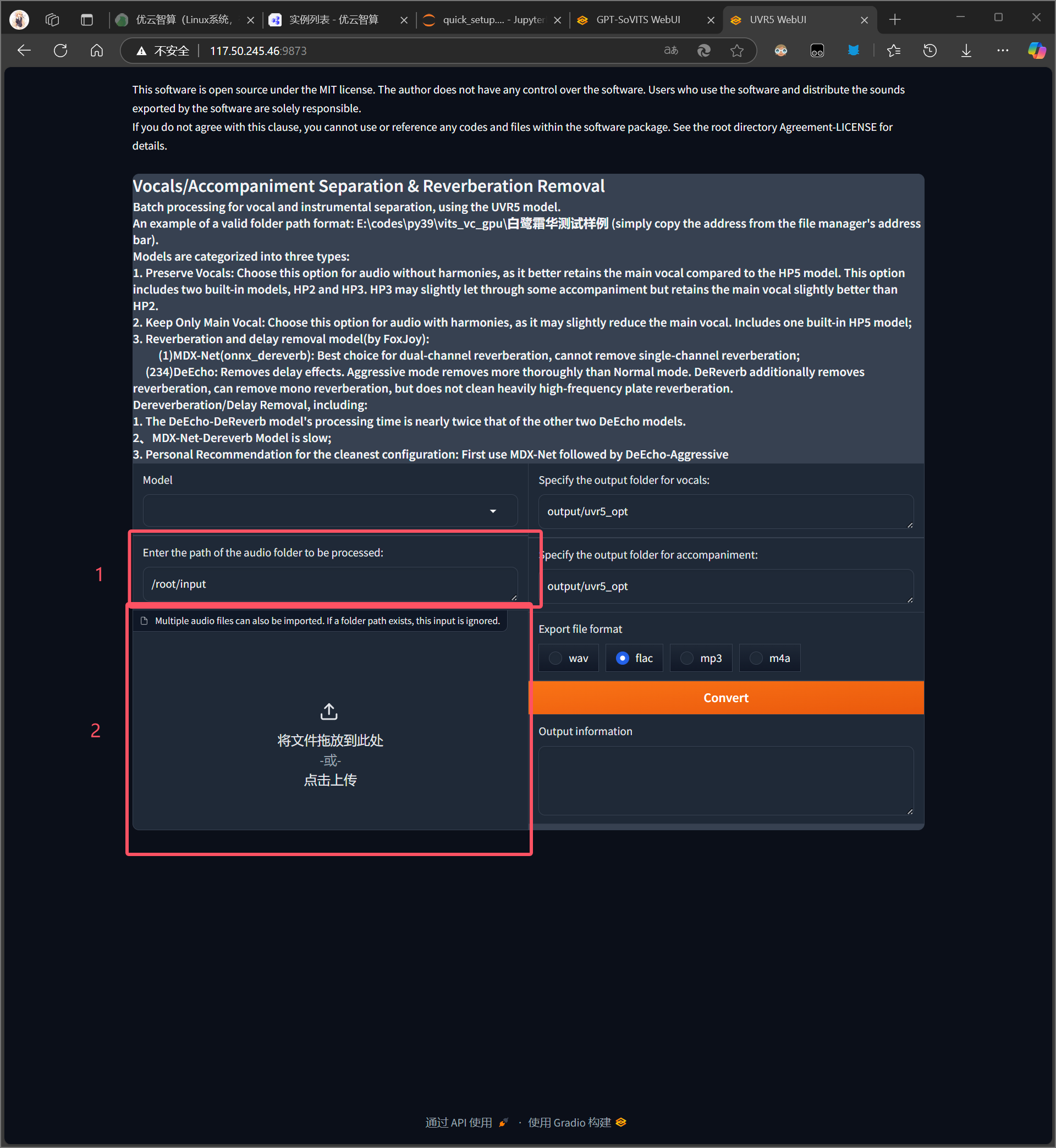
先用model_bs_roformer_ep_317_sdr_12.9755模型(已经是目前最好的模型)处理一遍(提取人声),然后将输出的干声音频再用onnx_dereverb最后用DeEcho-Aggressive(去混响),输出格式选wav。
输出的文件默认在GPT-SoVITS\output\uvr5_opt这个文件夹下,建议不要改输出路径,到时候找不到文件谁也帮不了你。处理完的音频(vocal)的是人声,(others)是伴奏,(_vocal_main_vocal)的没混响的,(others)的是混响。(vocal)(_vocal_main_vocal)才是要用的文件,其他都可以删除。结束后记得到WebUI关闭UVR5节省显存。
2.4:切分
在切割音频前建议把所有音频拖进音频软件(如au、剪映)调整音量,最大音量调整至-9dB到-6dB,过高的删除
输入路径是上面的原音频的文件夹路径,如果刚刚经过了UVR5处理那么就是output/uvr5_opt这个文件夹。输出路径默认是output/slicer_opt。建议可以调整的参数有min_length、min_interval和max_sil_kept单位都是ms。min_length根据显存大小调整,显存越小调越小。min_interval根据音频的平均间隔调整,如果音频太密集可以适当调低。max_sil_kept会影响句子的连贯性,不同音频不同调整,不会调的话保持默认。其他参数不建议调整。当然也可以使用其他切分工具切分。
切分完后文件在/root/GPT-SoVITS/output/slicer_opt。打开切分文件夹,排序方式选大小,检查下有没有太长的。将时长超过 显存数 秒的音频手动切分至 显存数 秒以下。比如显卡是4090 显存是24g,那么就要将超过24秒的音频手动切分至24s以下,音频时长太长的会爆显存。如果语音切割后还是一个文件,那是因为音频太密集了。可以调低min_interval,实在不行用au手动切分。
2.5:打标
2.5.1:开启标注
路径输入就是上面的切片输出路径,默认是output/slicer_opt。终端中有进度条就说明在跑,不在跑就会Error报错
如果有字幕的可以用字幕标注,准确多了。内嵌字幕或者外挂字幕都可以,教程使用字幕标注(更准确)
标注文件默认在otput/asr_opt
2.5.2:校对(这步比较费时间,可以跳过)
将标注文件的路径输入进去可以然后开启标注校对,就可以点终端里最下面那个链接进入校对界面了。
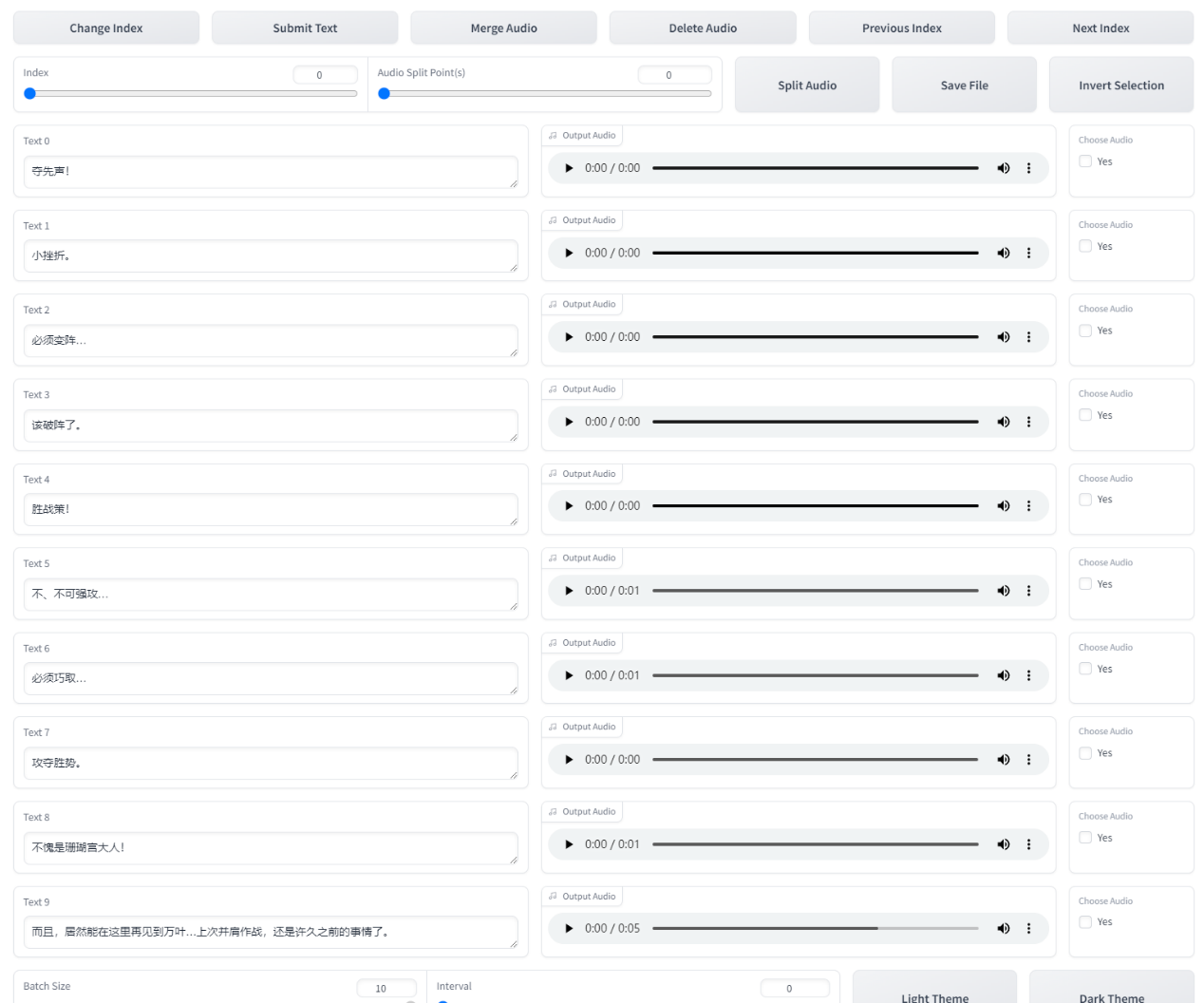
打开后就是SubFix,从左往右从上到下依次意思是:跳转页码、保存修改、合并音频、删除音频、上一页、下一页、分割音频、保存文件、反向选择。每一页修改完都要点一下保存修改(Submit Text),如果没保存就翻页那么会重置文本,在完成退出前要点保存文件(Save File),做任何其他操作前最好先点一下保存修改(Submit Text)。合并音频和分割音频不建议使用,精度非常差,一堆bug。删除音频先要点击要删除的音频右边的yes,再点删除音频(Delete Audio)。删除完后文件夹中的音频不会删除但标注已经删除了,不会加入训练集的。这个SubFix一堆bug,任何操作前都多点两下保存。
3:训练
3.1:输出logs
填实验名也就是模型名称,可以是中文!
上面选择v3版本,默认自动填好了路径直接点击一键三连等结束就好了
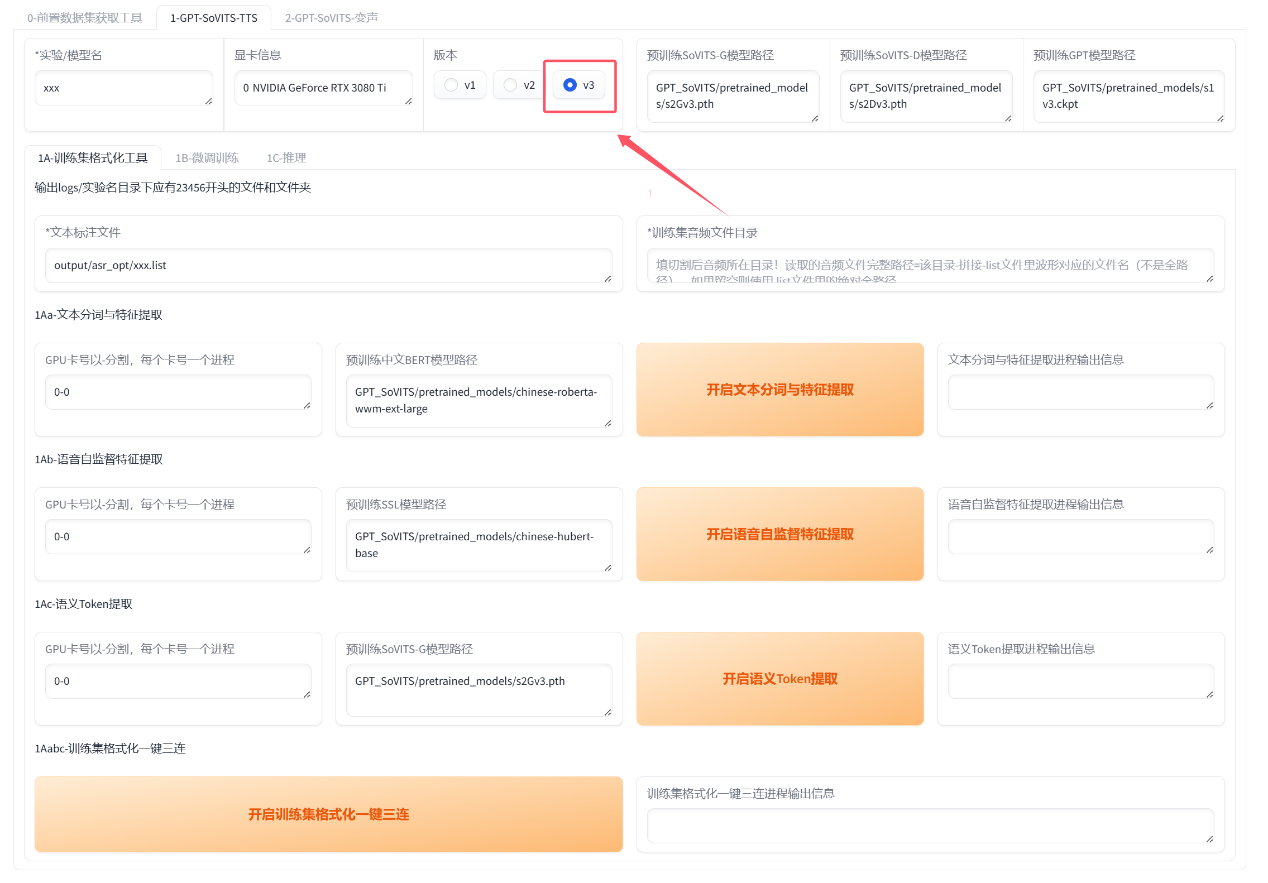
如果你要更改路径第一个输入的是标注文件路径,**注意是文件路径!不是文件夹路径!示例:/root/GPT-SoVITS/output/asr_opt/slicer_opt.list,注意后面的文件名必须要输进去!打不开就再三检查路径是否正确!必须要有.list的后缀!!!第二个输入的是切分音频文件夹路径 示例:/root/GPT-SoVITS/output/slicer_opt。注意复制的路径都不能有引号!!!千万不能有引号!**然后点一键三连等结束就好了。如果有报错会在终端呈现
如果是英语或日语的话logs里的3-bert文件夹是空的,是正常的不用管。
3.2:微调训练
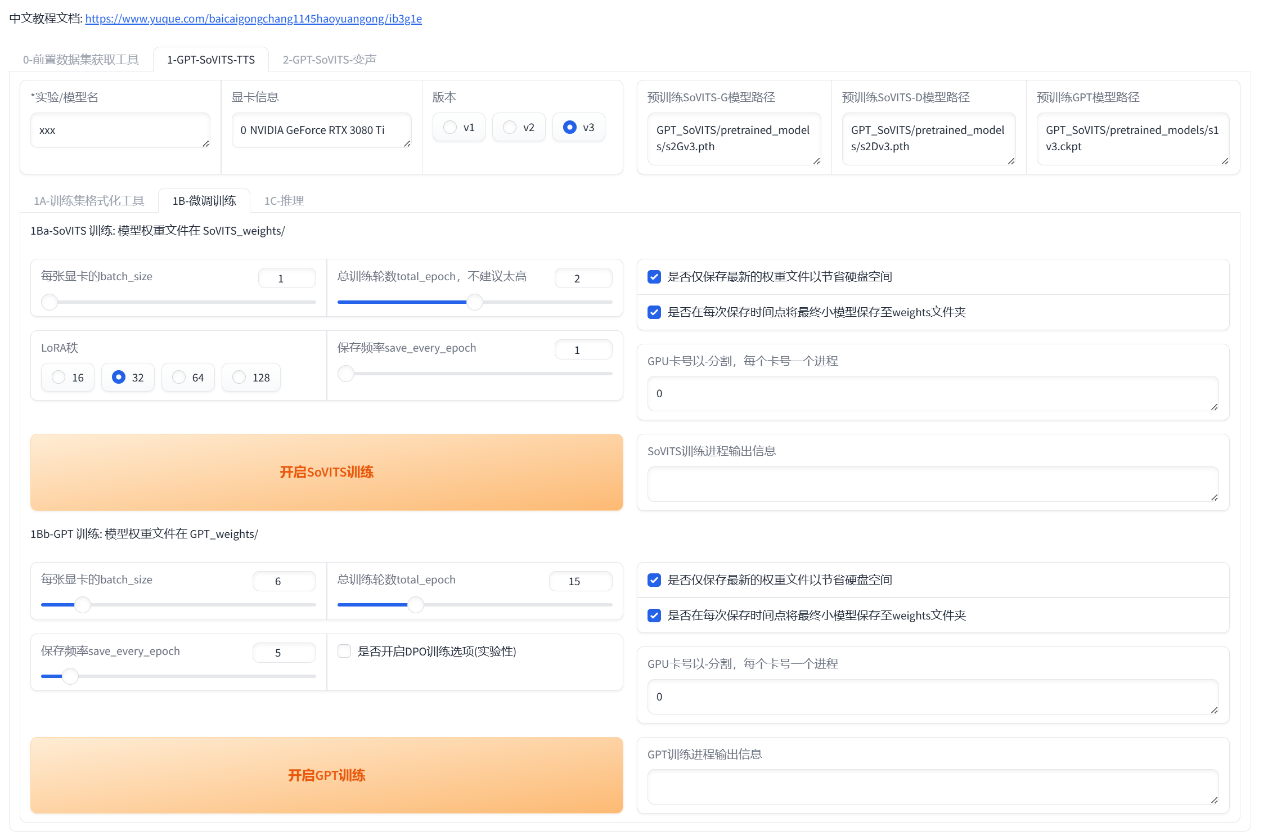
首先设置batch_size,sovits训练建议batch_size设置为显存的一半以下,高了会爆显存。**bs并不是越高越快!**batch_size也需要根据数据集大小调整,也并不是严格按照显存数一半来设置,比如6g显存需要设置为1。如果爆显存就调低。当显卡3D占用100%的时候就是bs太高了,使用到了共享显存,速度会慢好几倍。
以下是切片长度为10s时实测的不同显存的sovits训练最大batch_size,可以对照这个设置。如果切片更长、数据集更大的话要适当减少。
| 显存 | batch_size | 切片长度 |
|---|---|---|
| 8g | 1 | 10s |
| 12g | 2 | 10s |
| 16g | 8 | 10s |
| 22g | 12 | 10s |
| 24g | 14 | 10s |
| 32g | 18 | 10s |
| 40g | 24 | 10s |
| 80g | 48 | 10s |
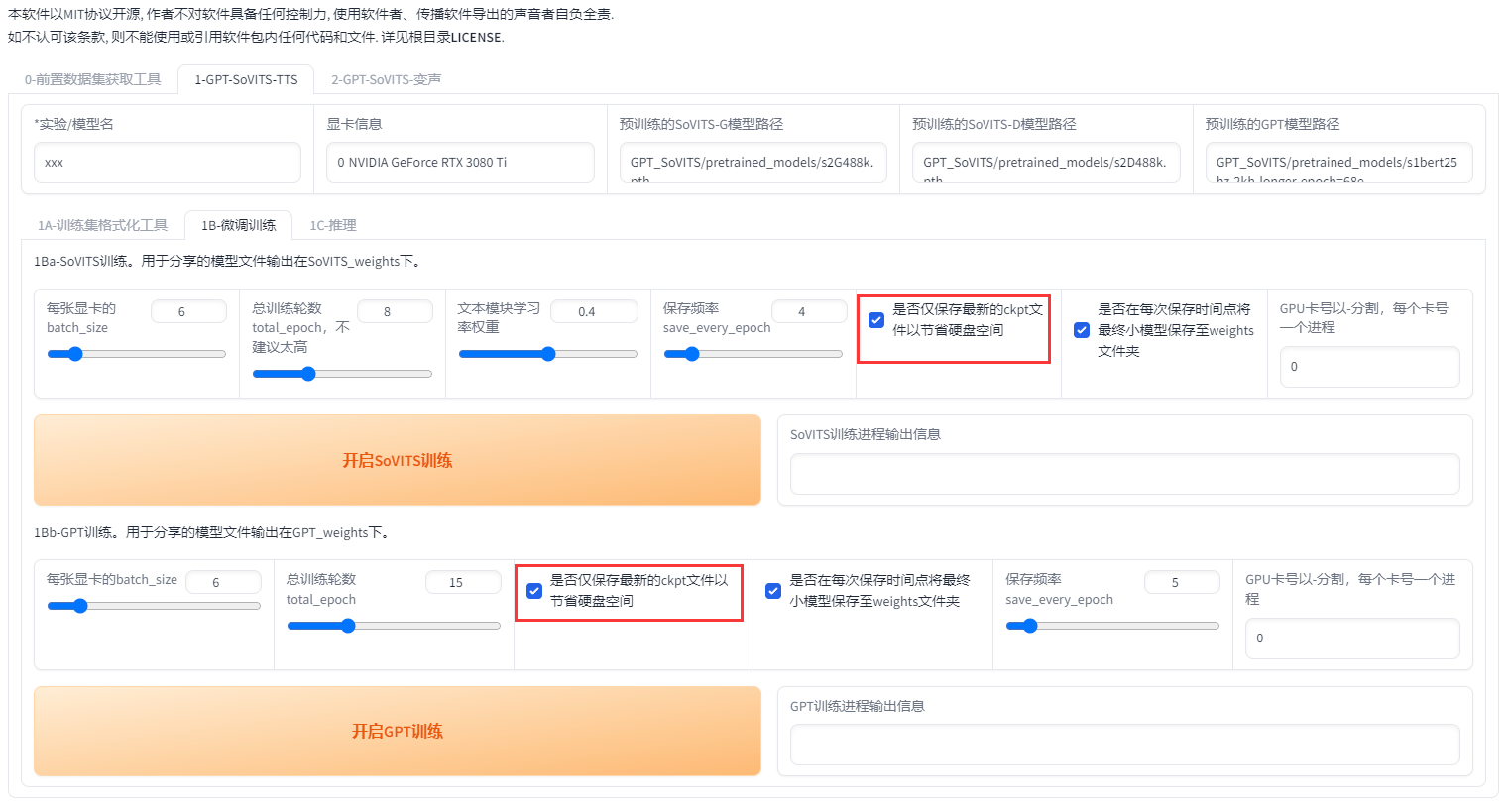
在0213版本之后添加了dpo训练。dpo大幅提升了模型的效果,几乎不会吞字和复读,能够推理的字数也翻了几倍,但同时训练时显存占用多了2倍多,训练速度慢了4倍,12g以下显卡无法训练。数据集质量要求也高了很多。如果数据集有杂音,有混响,音质差,不校对标注,那么会有负面效果。
如果你的显卡大于12g,且数据集质量较好,且愿意等待漫长的训练时间,那么可以开启dpo训练。否则请不要开启。下面是切片长度为10s时实测的不同显存的gpt训练最大batch_size。如果切片更长、数据集更大的话要适当减少。
| 显存 | 未开启dpo batch_size | 开启dpo batch_size | 切片长度 |
|---|---|---|---|
| 6g | 1 | 无法训练 | 10s |
| 8g | 2 | 无法训练 | 10s |
| 12g | 4 | 1 | 10s |
| 16g | 7 | 1 | 10s |
| 22g | 10 | 4 | 10s |
| 24g | 11 | 6 | 10s |
| 32g | 16 | 6 | 10s |
| 40g | 21 | 8 | 10s |
| 80g | 44 | 18 | 10s |
接着设置轮数,相比V1,V2对训练集的还原更好,但也更容易学习到训练集中的负面内容。所以如果你的素材中有底噪、混响、喷麦、响度不统一、电流声、口水音、口齿不清、音质差等情况那么请不要调高SoVITS模型轮数,否则会有负面效果。GPT模型轮数一般情况下不高于20,建议设置10。然后先点开启SoVITS训练,训练完后再点开启GPT训练,不可以一起训练(除非你有两张卡)!如果中途中断了,直接再点开始训练就好了,会从最近的保存点开始训练。
训练完成会显示训练完成,并且控制台显示的轮数停在设置的(总轮数-1)的轮数上。
关于学习率权重,轮数该多少好,如何制作出好模型,Tensorboard都在整合包教程训练章节
4:推理
4.1:开启推理界面
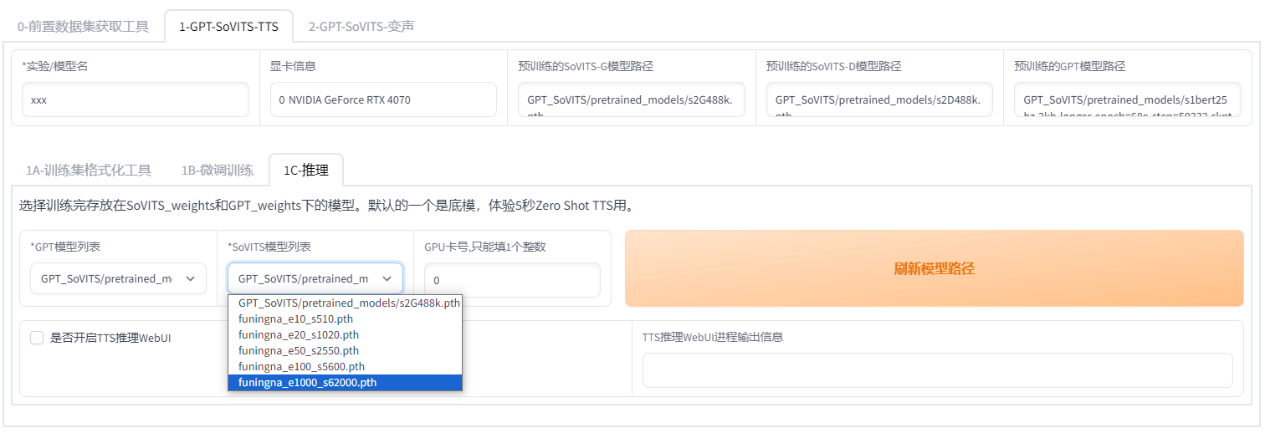
下拉选择模型推理,e代表轮数,s代表步数。不是轮数越高越好。选择好模型点开启TTS推理,还是点终端中最下面的链接。
请严格区分轮数 (Epoch) 和步数 (Step):1 个 Epoch 代表训练集中的所有样本都参与了一次学习,1 Step 代表进行了一步学习,由于 batch size 的存在,每步学习可以含有数条样本,因此,Epoch 和 Step 的换算如下:
4.2:开始推理
最上面可以切换模型,在刚练完挑模型的时候很重要
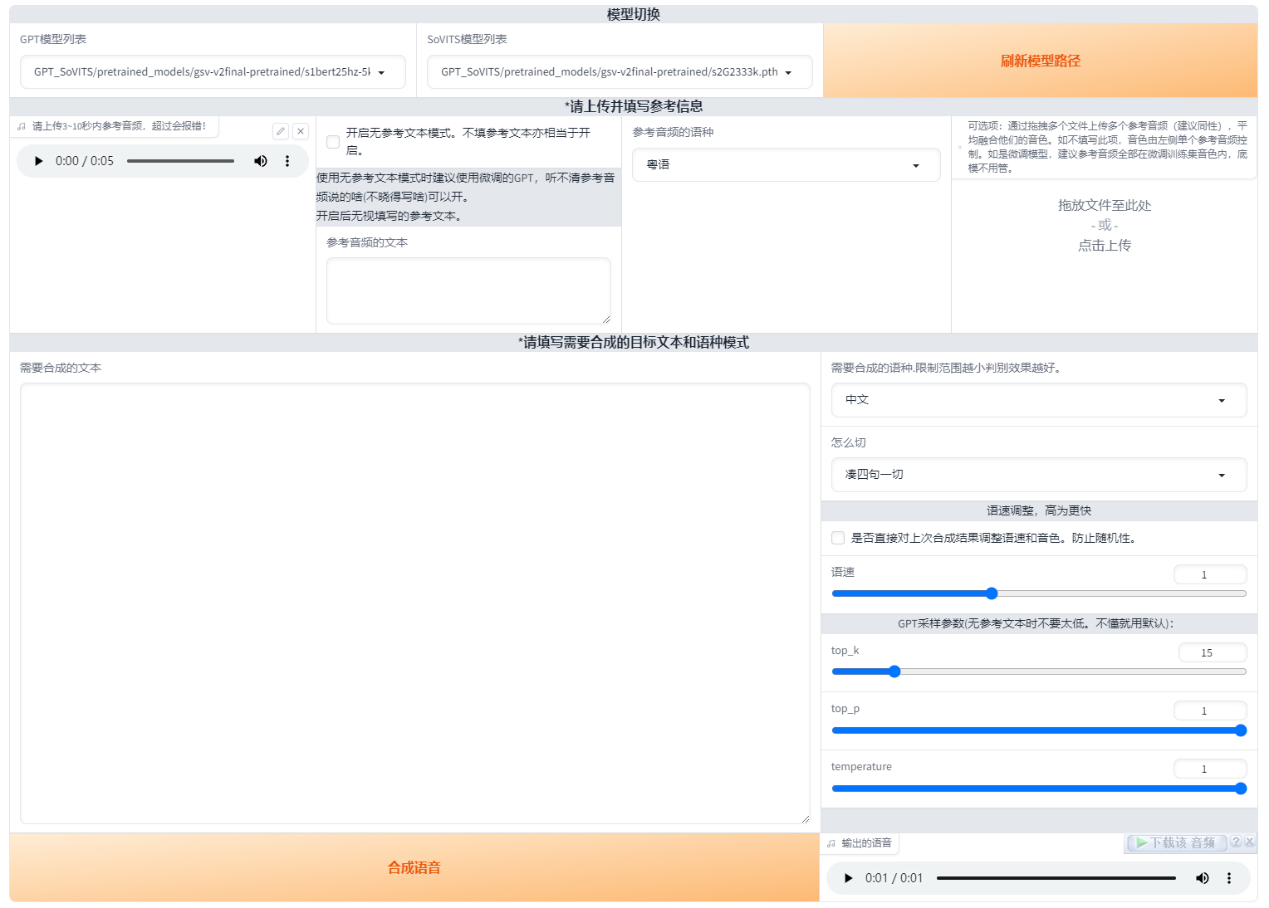
然后上传一段参考音频,建议是数据集中的音频。最好5秒。参考音频很重要!会学习语速和语气,请认真选择。参考音频的文本是参考音频说什么就填什么,语种也要对应。在0217版本之后可以选择无参考文本模式,但非常不建议使用,效果非常拉胯,就几秒钟打个字的事就这么懒吗?而且注意:是无参考文本!不是无参考音频!参考音频无论什么情况都要的!
右上角有个融合音色的可选项,先将要融合的音频放在一个文件夹然后一起拖进去(没啥实用性的功能)
接着就是输入要合成的文本了,注意语种要对应。目前可以中英混合,日英混合和中日英混合。切分建议无脑选凑四句一切,低于四句的不会切。如果凑四句一切报错的话就是显存太小了可以按句号切。如果不切,显存越大能合成的越多,实测4090大约1000字,但已经胡言乱语了,所以哪怕你是4090也建议切分生成。合成的过长很容易胡言乱语。
0213版本加入了top_p,top_k和temperature,保持默认就行了。这些控制的都是随机性,拉大数值,随机性也会变大,所以建议默认就好
5:下载模型到本地
打开/root/GPT-SoVITS/GPT_weights_V3和SoVITS_weights_V3这两个文件夹,分别将需要的模型右键下载。
6.关机
**千万要记得关机!**不然余额马上扣光。回到控制台点关闭就好了

7.本地推理
将GPT模型(ckpt后缀)放入GPT_weights_V3文件夹,SoVITS模型(pth后缀)放入SoVITS_weights_V3文件夹,刷新下模型就能选择模型推理了。
关于变声部分
目前还没做完,每个人打开都是【施工中,请静候佳音】。不是缺文件了,就是还没做好。敬请期待吧

 认证作者
认证作者