Qwen3-Ollama-Series
Qwen3-0.6B-235B量化模型,支持OpenWebUI。Qwen3-0.6B-235B 是通义千问开源的完整量化模型矩阵,覆盖 0.6B-235B 共 8 个规模(含 MoE 235B-A22B 旗舰),均已 AWQ/FP8/GGUF 量化
 2
20元/小时
v1.0
Qwen3-0.6B-235B 镜像试用教程
模型介绍
Qwen3 的亮点包括:
- 各种尺寸的密集和混合专家 (MoE) 型号,有 0.6B、1.7B、4B、8B、14B、32B 和 30B-A3B、235B-A22B 可供选择。
- 思维模式(用于复杂的逻辑推理、数学和编码)和非思维模式(用于高效的通用聊天)无缝切换,确保在各种场景中的最佳性能。
- 推理能力显著增强,超越之前的 QwQ(思维模式)和 Qwen2.5 指导模型(非思考模式)进行数学、代码生成和常识性逻辑推理。
- 卓越的人类偏好对齐,擅长创意写作、角色扮演、多轮对话和指导遵循,以提供更自然、更吸引人和身临其境的对话体验。
- 在智能体能力方面拥有丰富的专业知识,能够在思考和非思考模式下与外部工具进行精确集成,并在基于智能体的复杂任务中实现开源模型的领先性能。
- 支持 100+ 种语言和方言,具有强大的多语言教学遵循和翻译能力。
官方介绍页:https://github.com/QwenLM/Qwen3
使用方法
注:模型越大,需要的显存和显卡数越多,0.6B-32B单卡4090均可运行,235B的则需要8卡运行
1. 在镜像详情界面,点击“使用该镜像创建实例”
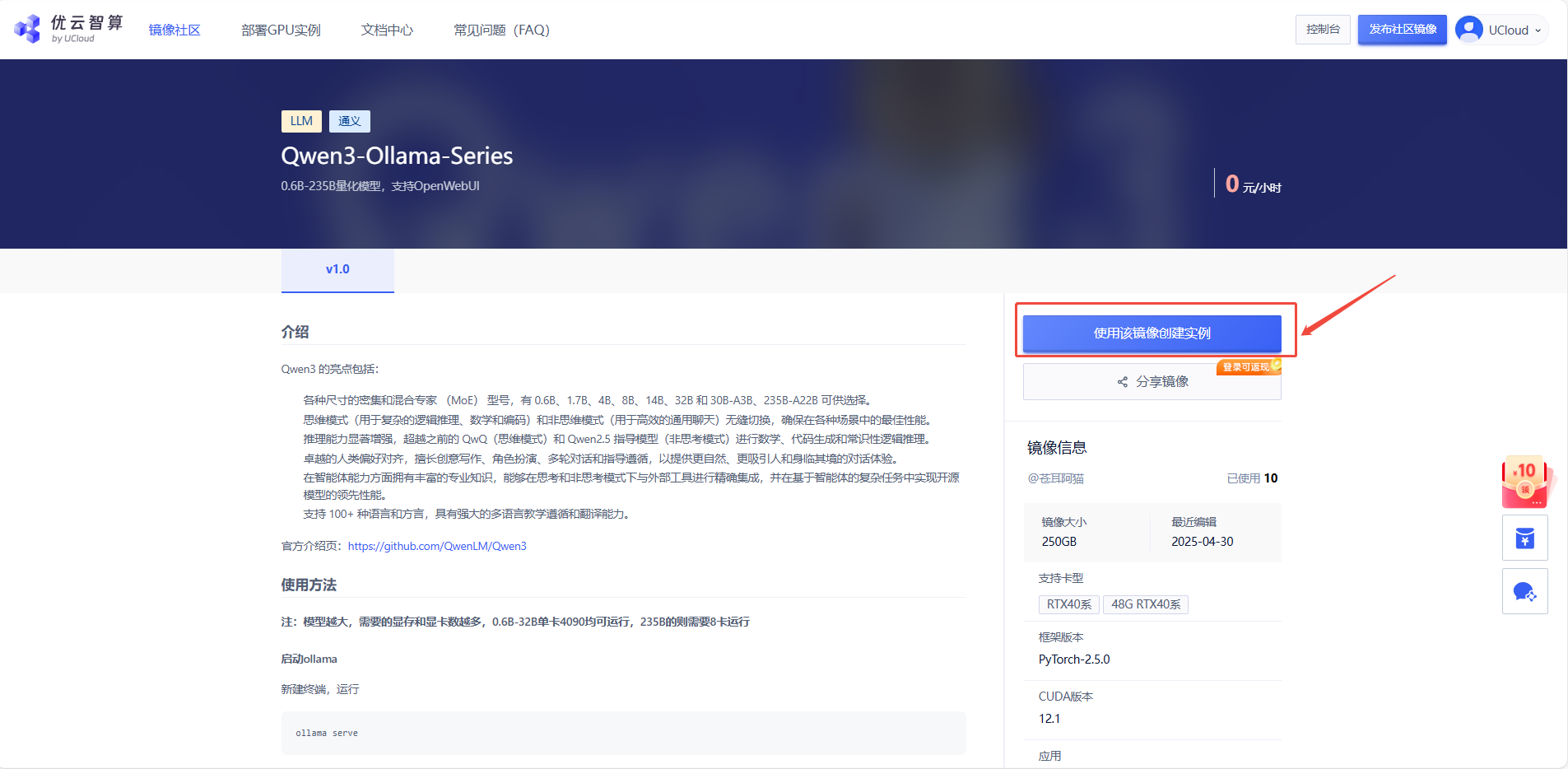
2. 先选择GPU型号,再点击“立即部署”
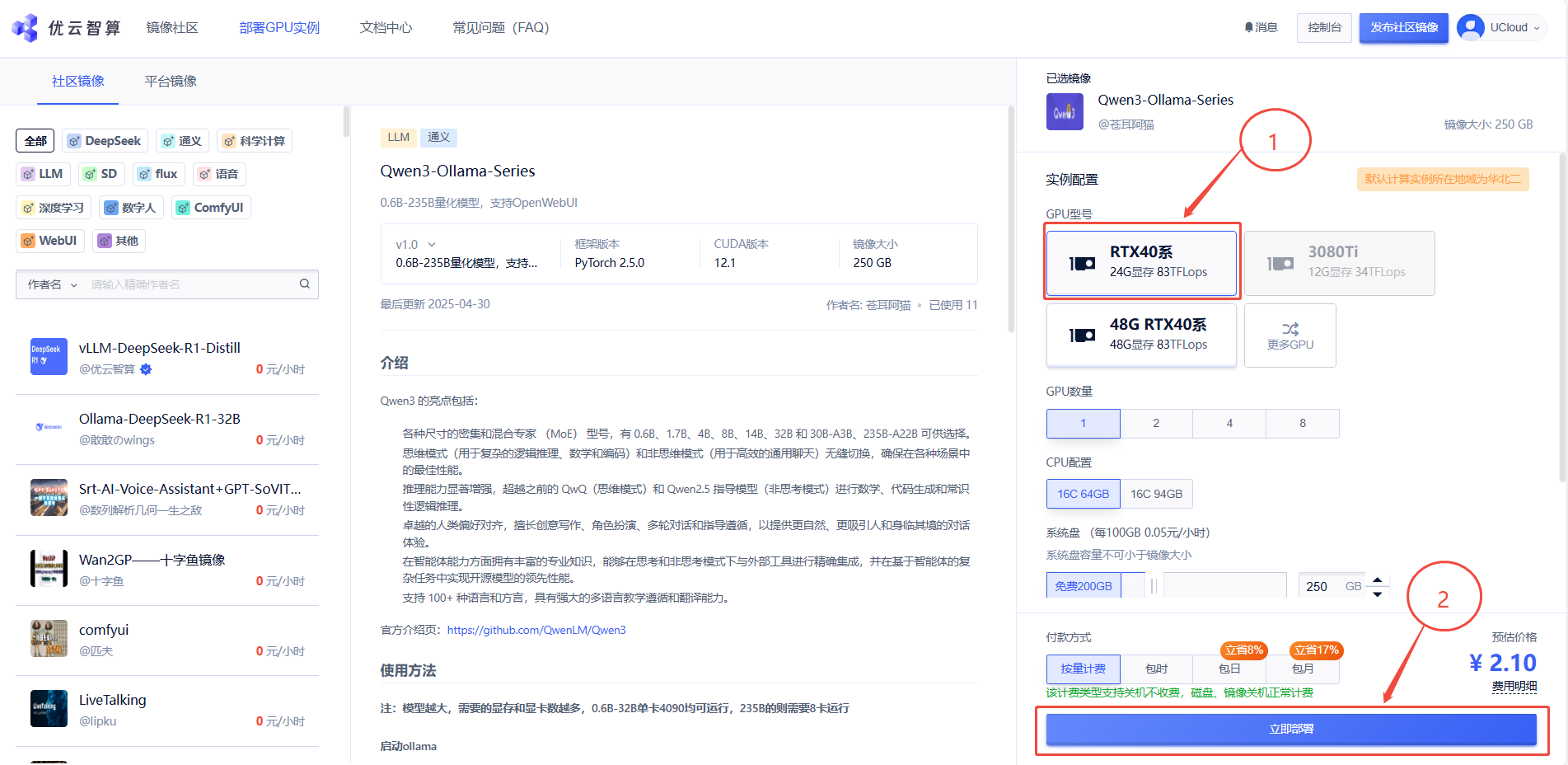
3. 待实例初始化完成后,在控制台-应用中点击“JupyterLab”

4. 进入JupyterLab后,新建终端Terminal,运行以下指令启动ollama
ollama serve
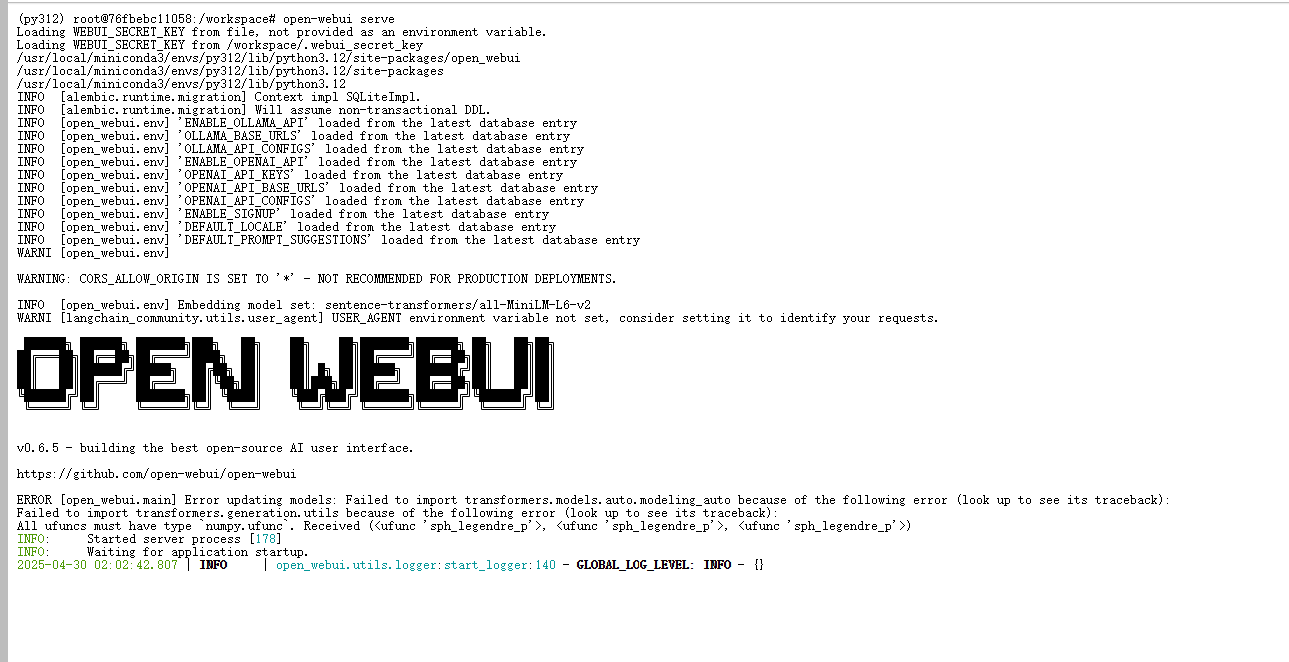
运行结果如下图所示,即可新建终端运行下方命令启动open-webui

启动open-webui
本实例安装好了open-webui,可以实现可视化对话.
1. 不要关闭前面正在运行的终端,再新建一个终端Terminal,运行以下指令
open-webui serve
如下图所示,表示启动成功
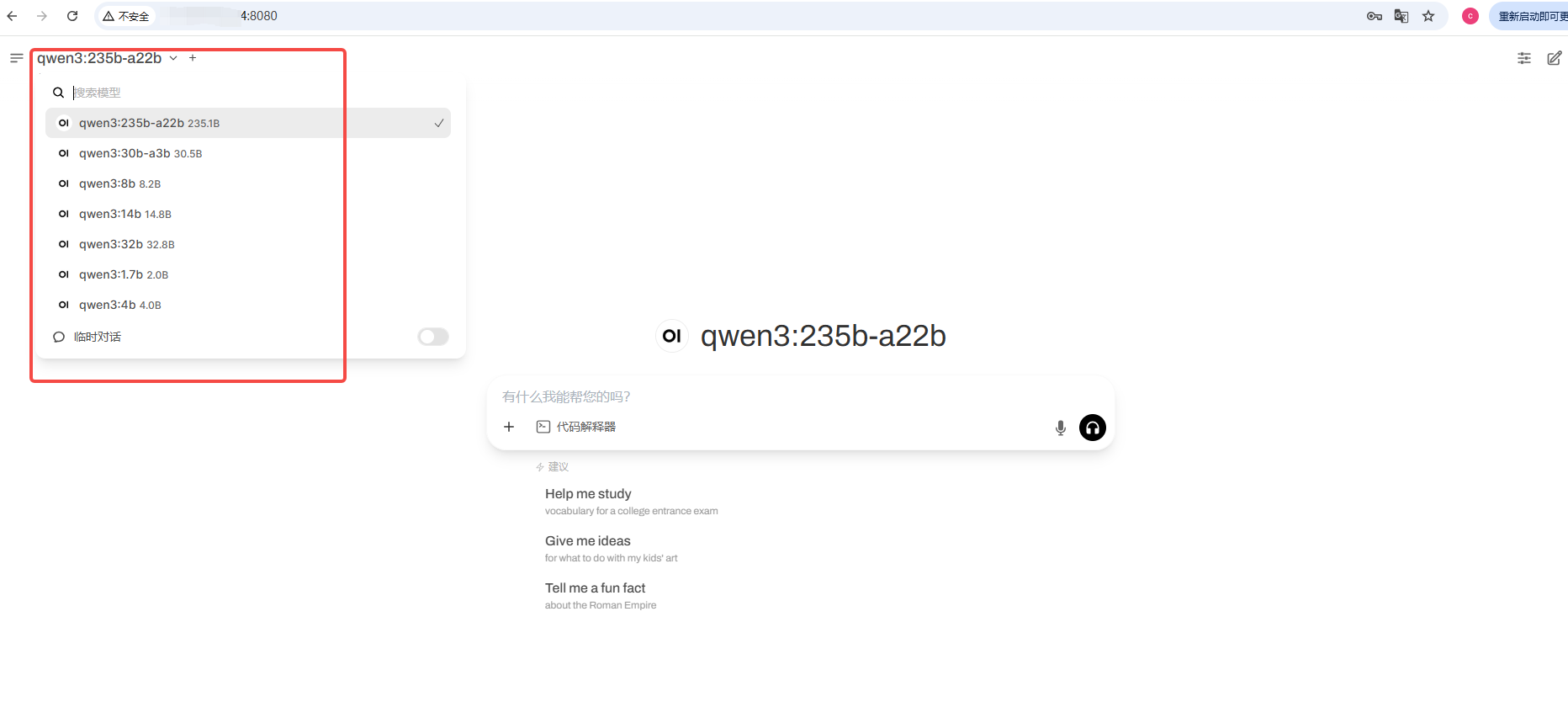
2. 访问open-webui:http://{你的实例ip}:8080/ ,实例ip可以在控制台-基础网络(外)通过复制获取

3. 登录open-webui: 账号:root@root.com ;密码:root
4. 进入后,左上角切换模型即可使用
@苍耳阿猫 认证作者
认证作者
认证作者
镜像信息
已使用57 次
运行时长
287 H
镜像大小
250GB
最后更新时间
2025-07-14
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.1
应用
JupyterLab: 8888
自定义开放端口
8080
+1
版本
v1.0
2025-07-14