InternVL
InternVL 系列:GPT-4o 的开创性开源替代品。 接近GPT-4o表现的开源多模态对话模型
 0
00元/小时
v1.0
InternVL
项目介绍
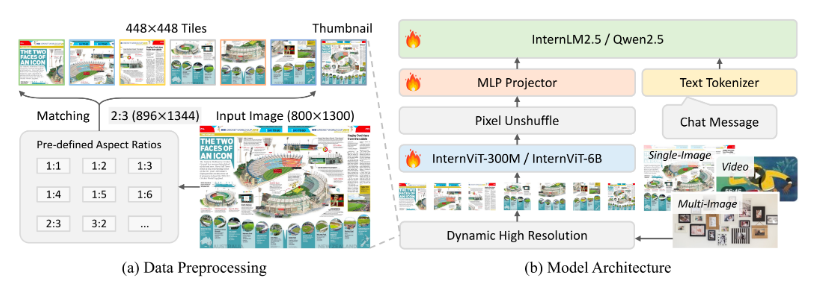
InternVL2.5系列基于以下设计:
-
渐进式缩放策略:我们提出了一种渐进式缩放策略,以有效地将视觉编码器与 LLM 对齐。该策略采用分阶段训练方法,从较小、资源高效的 LLM 开始,逐步扩展到较大的 LLM。这种方法源于我们的观察:即使使用 NTP 损失联合训练 InternViT 和 LLM,得到的视觉特征也是可泛化的表示,可以被其他 LLM 轻松理解。具体而言,InternViT 与较小的 LLM(例如 20B)一起训练,重点是优化基本视觉能力和跨模态对齐。此阶段避免了直接使用大型 LLM 进行训练所带来的高昂计算成本。使用共享权重机制,训练好的 InternViT 可以无缝迁移到更大的 LLM(例如 72B),而无需重新训练。因此,在训练更大的模型时,所需的数据要少得多,计算成本也显著降低
-
改进的训练策略:为了增强模型对实际场景的适应性和整体性能,我们引入了两项关键技术:和。对于随机 JPEG 压缩,我们采用质量等级在 75 到 100 之间的随机 JPEG 压缩来模拟互联网来源图像中常见的质量下降问题。对于损失重加权,我们以统一的格式表达了广泛应用的策略(即标记平均和样本平均),并提出使用平方平均来平衡梯度对长响应或短响应的偏差。
-
结构良好的数据组织:在模型开发过程中,我们观察到即使少量异常样本也可能导致推理过程中模型行为异常。为了解决这个问题,我们提出了一个由基于 LLM 的质量评分和基于规则的过滤组成的过滤流程,显著减少了异常行为的发生,尤其是重复生成,并在 CoT 推理任务中取得了显著的改进。此外,我们还实施了数据打包策略,以提高 GPU 利用率并提升训练效率。
InternVL 镜像使用教程
使用说明
1. 先选择GPU型号,再点击“立即部署”

2. 本镜像预装了InternVL2.5-1B模型,已设置自启动程序,实例开机运行后,直接打开浏览器输入[外网IP]:10003,即可在线访问体验
外网IP可以在控制台-基础网络(外)复制得到

注意:若无法访问,自行确认防火墙是否放行端口:10003 ;若未放行,需要在控制台-操作-更多操作-配置防火墙中添加TCP端口10003
@CC仔

镜像信息
已使用7 次
运行时长
9 H
 支持自启动
支持自启动镜像大小
40GB
最后更新时间
2026-02-10
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.1
应用
-
版本
v1.0
2026-02-10