LLaMAFactory-0.9.3.dev-Qwen3-8B
本镜像基于 LLaMA-Factory 框架,支持在多张 4090 GPU 上进行模型微调。
 7
70元/小时
v1.0
LLaMAFactory-0.9.3.dev-Qwen3-8B 镜像使用教程
镜像环境介绍
本镜像基于 LLaMA-Factory 框架,支持在多张 NVIDIA RTX 4090 GPU 上进行模型微调。具体支持的模型及硬件需求如下:
- Qwen3-8B:使用 LoRA 技术,结合 DeepSpeed ZeRO-3 Offload(ds3-offload),建议使用 1~2 张 RTX 4090
环境配置
- Python: 3.12.8
- PyTorch: 2.7.0.dev20250215+cu128
- CUDA: 12.8
- LLaMA-Factory: 0.9.3.dev
使用指南
创建实例
1.创建实例
2.选择合适的机型,立即部署
 点击【Jupyterlab】进入操作页面
点击【Jupyterlab】进入操作页面
模型微调
分别运行以下命令即可对相应尺寸的模型进行监督微调(SFT):
注意需要切换到LLaMA-Factory目录下运行
# 8B 模型微调
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_lora/qwen3_lora_sft_ds3.yaml
注意事项
以 8B 模型为例,以下是配置文件的调整建议:
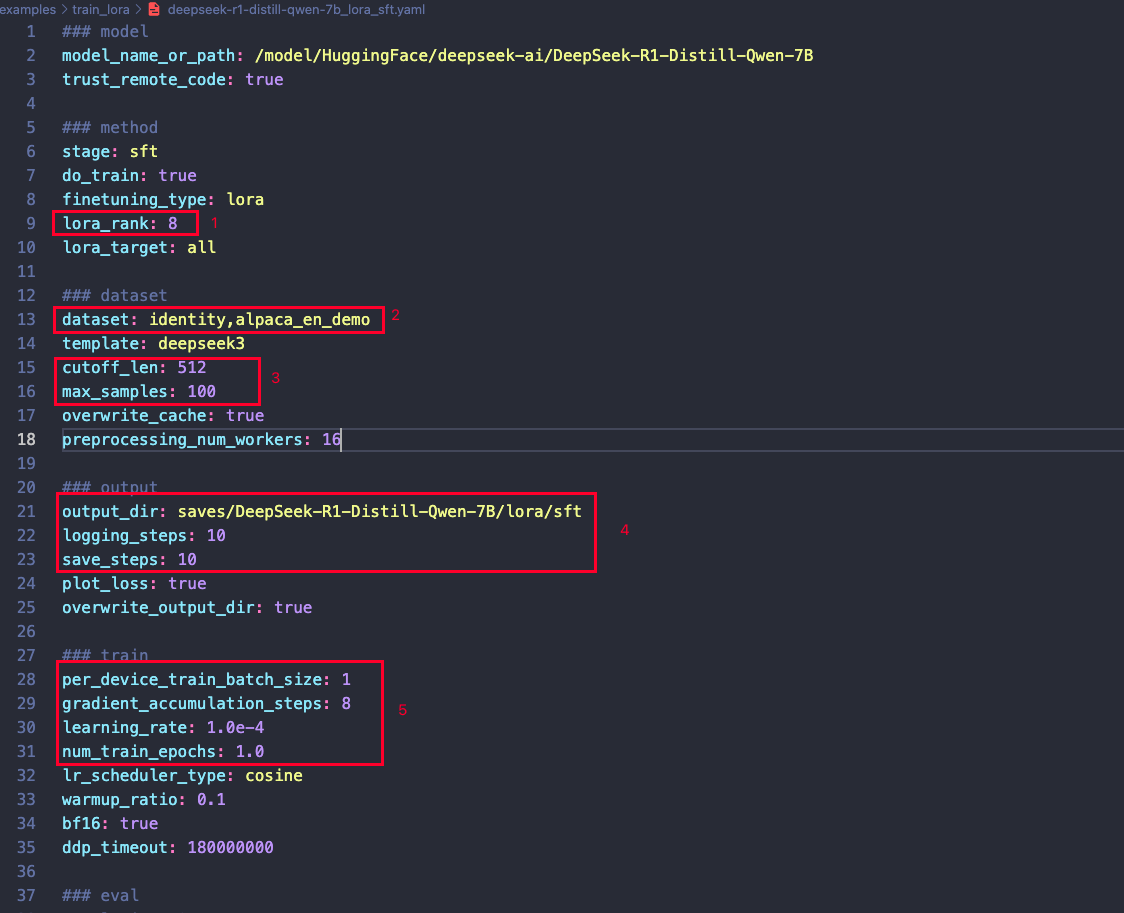
- 数据集准备:在运行前,请确保已准备好数据集,并替换截图中标注的 2️⃣
dataset部分。 - 模型配置:根据任务需求和显存大小,调整截图中标注1️⃣的LoRA配置部分。
- 序列长度与样本量:根据实际需求,调整截图中3️⃣最大序列长度和训练样本量。
- 训练设置:截图中4️⃣保存步数、日志频率、输出目录等可根据需要自行调整。
- 训练参数:截图中5️⃣学习率、批量大小等训练参数可根据任务需求灵活调整。
本镜像由 LLaMA-Factory 提供支持。
@llamafactory_cn 认证作者
认证作者
认证作者
镜像信息
已使用164 次
运行时长
5687 H
镜像大小
80GB
最后更新时间
2026-02-04
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.0
2026-02-04