 3
3index-tts-api-v1.5 在线推理服务镜像使用教程
镜像简介
本镜像提供基于IndexTTS 1.5模型的在线推理API服务,集成DeepSpeed加速技术,显著提升语音合成与语音克隆的响应速度与吞吐量。支持通过标准接口进行高质量、高拟真的语音生成与音色复刻,适用于虚拟助手、有声内容创作、语音交互开发等场景,为用户提供高效、稳定的云端语音AI服务。
镜像使用指南
1.创建实例
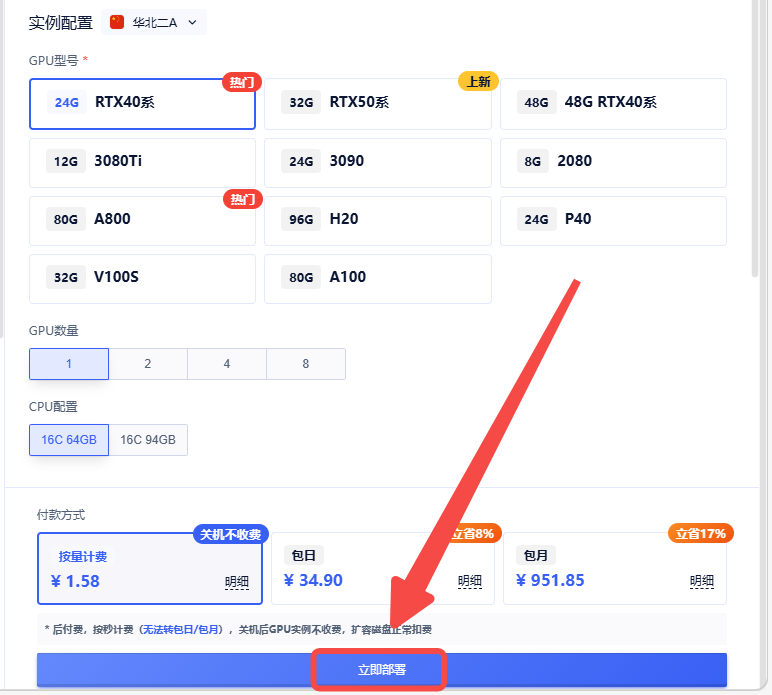
2.选择合适的机型,立即部署
 3.在浏览器中访问地址
3.在浏览器中访问地址
API使用说明
API请求地址: http://实例IP地址:8080/?text={文本}&speaker=女主播1.pt
例如:http://i-1.gpushare.com:21637/??text=测试一下看看&speaker=女主播1.pt
重启或者运行调试执行:bash /root/run.sh
1、音频上传:
import requests import json
url = "http://ip:8080/upload" # 将此替换为您的API端点
data = { "audio": "你的base64编码音频数据", }
headers = { "Content-Type": "application/json" }
response = requests.post(url, data=json.dumps(data), headers=headers)
print(response.text)
2、音频请求,url请求格式:https://ip:8080/?text=欢迎大家使用index-tts,这个是测试音频&speaker=jok老师.pt
i
mport requests import json
url = "https://你的实例id-8080.container.x-gpu.com/" # 将此替换为您的API端点
data = { "text": "测试测试,这里是测试", "speaker": "output_123.wav", "speed": 1.0, }
headers = { "Content-Type": "application/json" }
response = requests.post(url, data=json.dumps(data), headers=headers)
检查响应状态码
if response.status_code == 200: print("请求成功!") # 处理响应数据 with open("new.wav", "wb") as f: # 使用 "wb" 模式以二进制写入模式打开文件 for chunk in response.iter_content(chunk_size=8192): # 逐块读取响应数据,避免内存溢出 f.write(chunk)
else: print(f"请求失败,状态码:{response.status_code}")
3、多并发 修改 /opt/index-tts/app.py 的 worker 参数即可,比如:2 即两个并发。
默认是2:如:uvicorn.run(app="cy_app:app", host="0.0.0.0", port=8080, workers=2)
4、关于多并发的问题
通过豆包咨询: 1、ubuntu 系统中 ,uvicorn,的worker如何设置才是最优的?
回复: Uvicorn 官方推荐的 worker 数量计算公式为: workers = (2 × CPU核心数) + 1
2、在 Ubuntu 系统中,查询 CPU 核心数有以下几种常用方法:
grep 'processor' /proc/cpuinfo | wc -l # 逻辑CPU数
grep 'cpu cores' /proc/cpuinfo | uniq # 每个物理核心数
官方更新源码在这里: https://github.com/index-tts/index-tts
有bug请微信科哥: 312088415
pt模型放置说明:
1、路径:/root/index-tts/voices
2、调用地址:
API请求地址: http://实例IP地址:8080/?text={文本}&speaker=女主播1.pt
开机启动的配置在这里:/usr/supervisor/supervisord.conf
第132行处修改
重启或者运行调试执行:bash /root/run.sh
 认证作者
认证作者
