 16
16AnchorCrafter-WebUI
镜像简介
AnchorCrafter-WebUI是一款开箱即用的数字人视频生成工具,专注于快速创建真实、生动的电商带货视频。用户可通过简洁的Web界面,轻松将产品与虚拟数字人结合,生成可用于直播切片、产品展示及营销推广的动态内容,大幅降低视频制作门槛,提升电商宣传的吸引力与转化效率。
惊艳!AI 虚拟主播带货新突破——AnchorCrafter
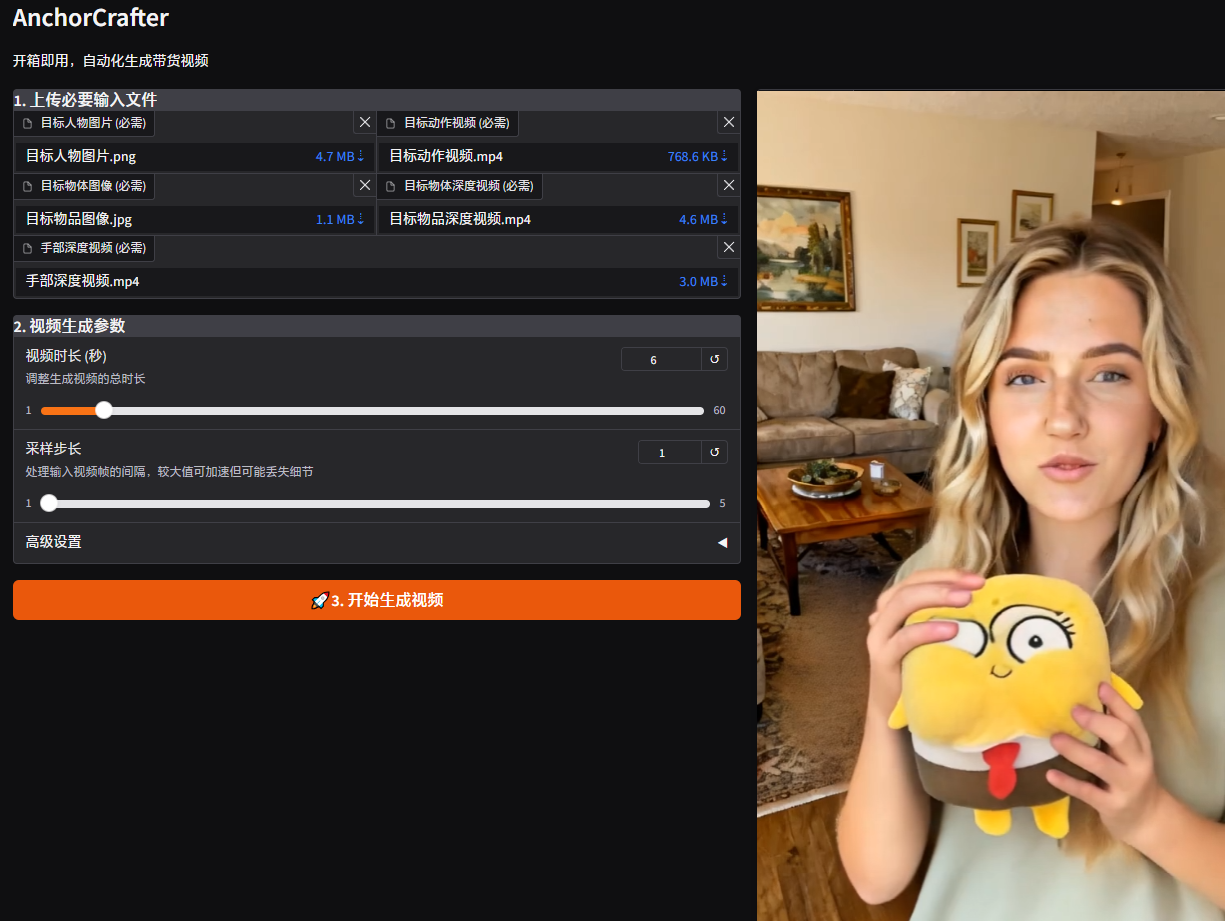
开箱即用,自动化生成带货视频
项目来源:https://github.com/cangcz/AnchorCrafter/
本镜像由:AiMusicLab@乔大峰 搭建
镜像部署教程
1. 开箱即用:部署完成点击启动
2. 界面展示
前言
在 AI 技术飞速发展的今天,虚拟主播已不再是新鲜概念。它们以逼真的面部表情和流畅的肢体动作逐渐进入大众视野。然而,以往的 AI 虚拟主播在与商品互动时,常因“不真实”的表现而受到诟病,例如手与物体接触不自然、出现伪影或产品外观不一致等问题,这无疑阻碍了 AI 虚拟主播在电商领域的广泛应用。
现在,一项由中国科学院和腾讯合作研发的创新技术——AnchorCrafter,正在彻底改变这一现状,为 AI 虚拟主播带来了新的活力。
AnchorCrafter 简介
AnchorCrafter 是一个基于扩散模型的 AI 系统,旨在自动化生成具有目标人物和定制对象的 2D 视频,以实现高视觉保真度和可控交互。它特别适用于电商、广告和消费者互动等场景。
其核心目标是将**人-物交互(HOI)**集成到姿态引导的人体视频生成中,让虚拟人物可以像真人主播一样,自然地与目标产品进行互动,并进行带货展示。

核心优势与功能
AnchorCrafter 的厉害之处在于:
- 自动化生成带货视频: 用户只需上传主播照片和商品图片,系统即可自动生成高质量的电商带货视频。
- 自然逼真的人-物交互: AI 虚拟主播能够以极其自然的方式展示商品,动作流畅,如同真人一般。
- 精准控制产品运动轨迹: 能够精确控制产品在视频中的运动路径。
- 人物与物体外观一致性: 在展示产品的过程中,确保人物和物体的外观保持一致,避免伪影和产品变形。
- 高效与成本节约: 大幅降低电商内容制作成本和效率,省去了寻找真人主播和拍摄带货视频的费用。
技术原理揭秘
AnchorCrafter 的强大功能得益于其独特的框架,主要包含以下两个关键创新组件和一种训练策略:
1. HOI-外观感知模块 (HOI-Appearance-Aware Module)
该模块旨在增强从任意多视角识别物体外观的能力,并解耦物体和人物的外观,以实现更逼真的人-物交互效果。
- 多视角物体特征融合: 从多个视角捕捉目标物体的完整外观信息,并进行融合,以获得更全面的物体外观表征。
- 人-物双重适配器: 将融合后的多视角物体特征与目标人物的参考特征输入适配器,分别处理人物和物体特征,并学习它们之间的相互关系,从而增强物体外观识别,并解耦人物和物体外观。
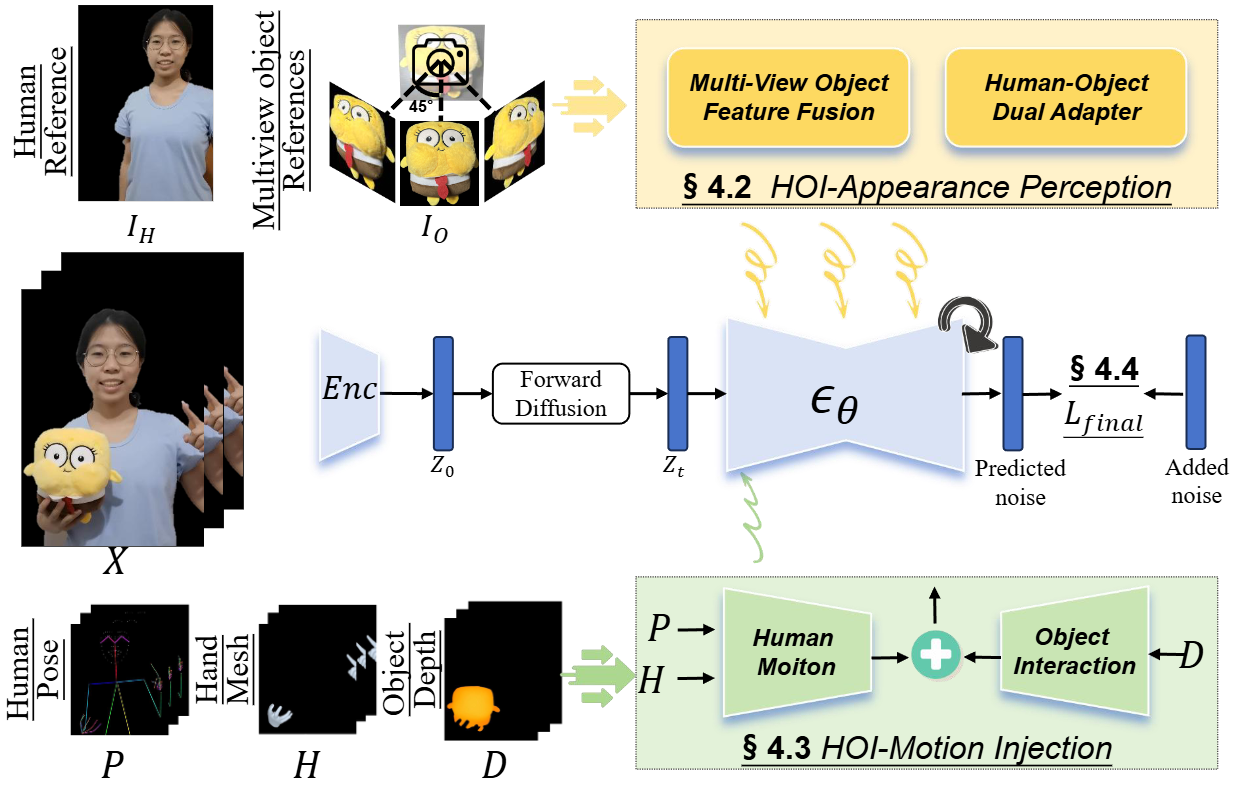
2. HOI-运动注入模块 (HOI-Motion-Injection Module)
该模块是 AnchorCrafter 的核心组件之一,其主要功能是将人体与物体的交互动作精准地注入到生成视频中,解决物体轨迹表征、遮挡处理和空间一致性等问题。
- 深度图引导物体轨迹: 利用深度图 (D) 控制物体的运动轨迹,通过卷积网络提取特征并注入到视频扩散模型中。
- 3D 手部网格处理遮挡: 除了人体骨骼序列 (P) 外,引入 3D 手部网格序列 (H) 来更精确控制人手与物体的交互。在物体遮挡手部时,对相应 3D 网格进行掩码处理,确保生成结果的准确性。
- 空间位置匹配: 根据动作序列的第一帧和参考图像的姿态估计相似性矩阵,并应用于所有运动条件 (P, H, D),使其与参考图像的空间位置相匹配,保证生成视频的一致性。

3. HOI-区域重加权损失训练策略 (HOI-Region-Reweighting Loss)
为了提升模型对物体细节的学习能力,AnchorCrafter 采用了一种特殊的训练策略。
- 克服标准损失函数局限: 传统的扩散模型损失函数难以充分学习物体外观信息。
- 聚焦交互区域: 该策略将训练重点放在手部-物体交互区域,因为该区域包含物体外观的关键信息。
- 加权损失函数: 通过对交互区域的损失值进行加权(利用交互区域占图像面积的倒数作为权重),放大该区域的损失值,促使模型更关注物体细节的学习,同时保持人体姿态驱动能力。
展望未来
AnchorCrafter 项目的发展,无疑为未来的电商带货领域带来了新的动力。它不仅能帮助电商商家节省成本、提高效率,还能通过 AI 试衣等类似技术,进一步提升购物体验。
随着 AI 技术的不断深入,我们有理由相信,未来的电商带货会变得更加智能、高效,AnchorCrafter 正是这一趋势中的重要里程碑。它为在线商务、广告和消费者互动提供了新的可能性。
 认证作者
认证作者
 支持自启动
支持自启动