 10
10AnchorCrafter通过人-物交互视频生成来销售您的产品
镜像简介
AnchorCrafter 是一款专注于电商带货场景的数字人视频生成工具,能够基于人体与物体互动的参考视频,智能生成动画化的产品销售数字人内容。该工具可自动将真人演示转化为自然、生动的数字人动作,适用于产品展示、直播切片、广告营销等场景,帮助商家快速制作高质量、低成本的推广视频,提升产品表现力与转化效率。
镜像使用说明
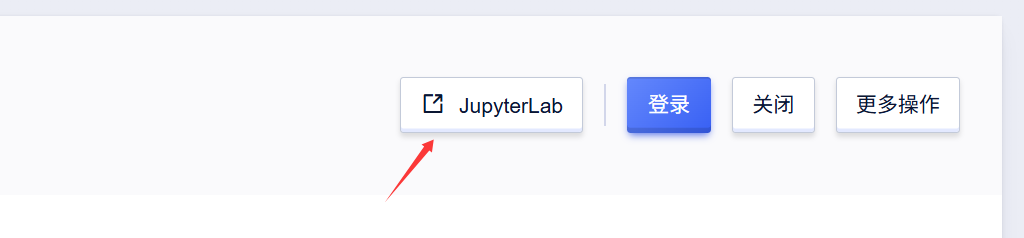
1、通过该镜像创建实例,推荐使用4090显卡,启动后打开JupyterLab
2、打开终端,进入项目路径cd /workspace/AnchorCrafter,激活虚拟环境ac conda activate ac,
运行python gradio_app.py

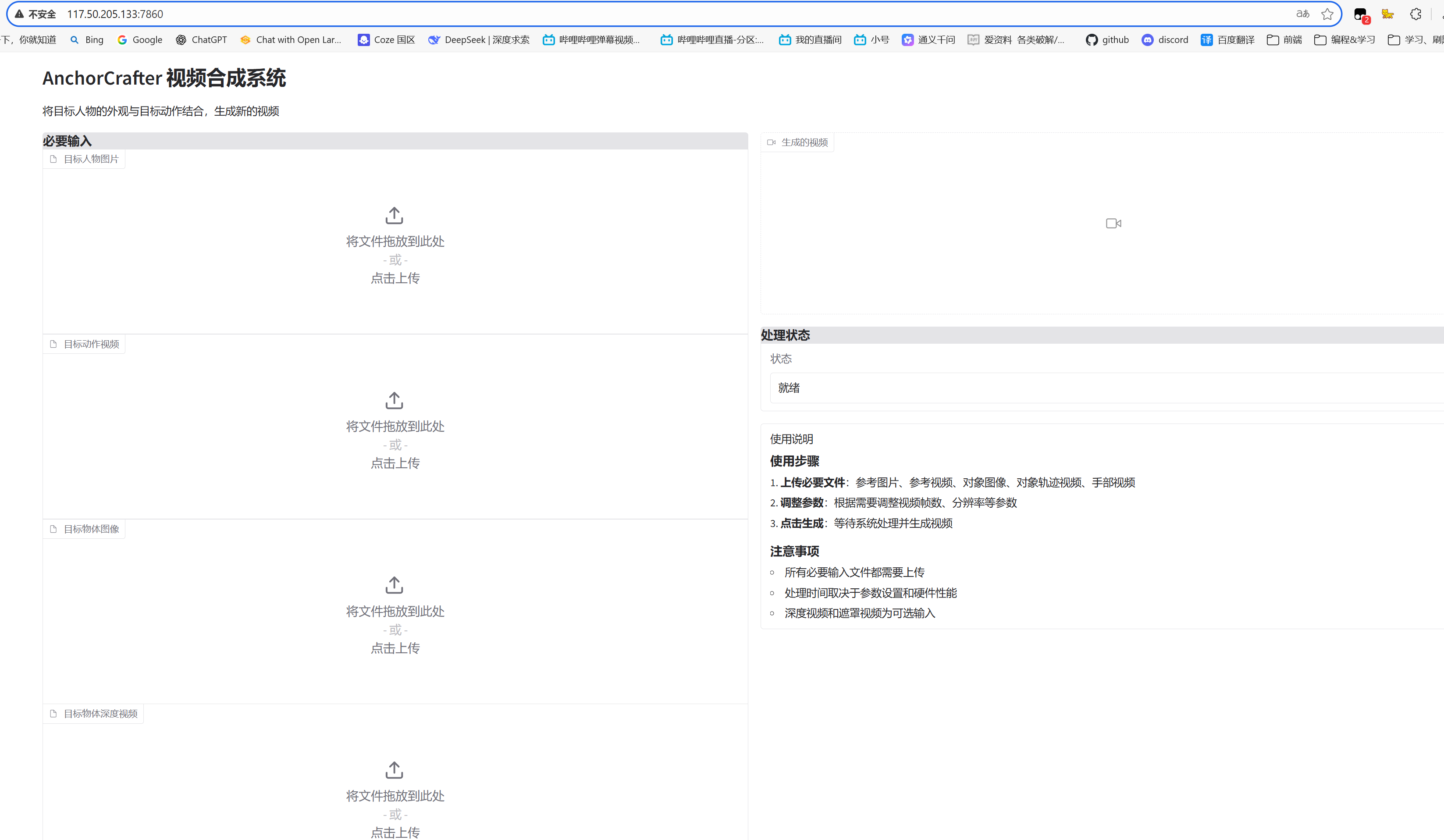
3、正常运行后,访问对应公网ip对应端口服务即可,例如:http://117.50.205.133:7860/

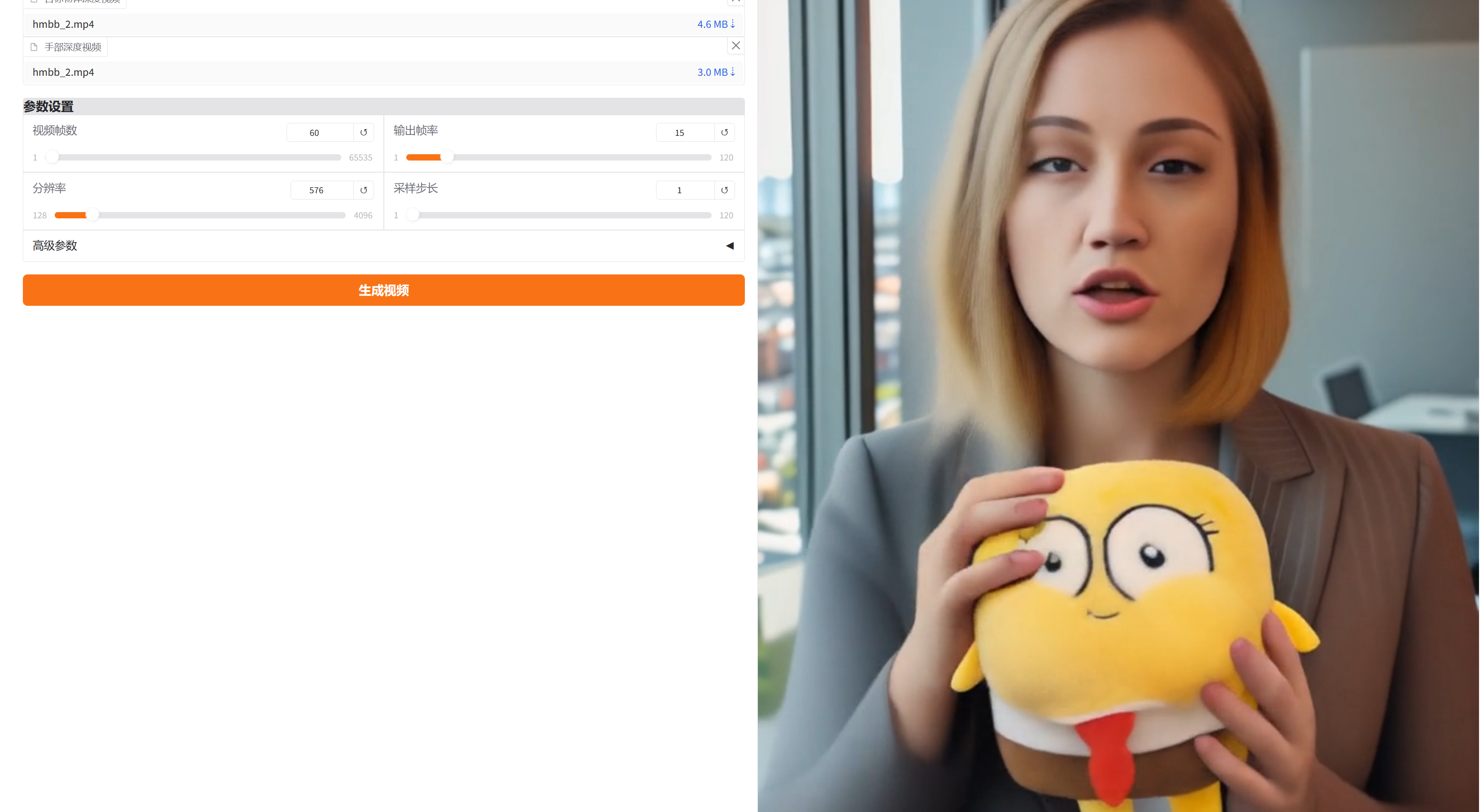
4、上传符合要求的图片视频,完成配置后,点击生成即可。
测试数据可以从项目内下载
最终效果如下:
交流
粉丝Q群:587663288
AI Q群:273215887

🎯 一句话总结
AnchorCrafter 是一个可以根据一张人物图和多视角产品图,生成人物与产品自然互动视频的AI系统。
🔍 核心问题
传统的人物视频生成方法(如 MimicMotion、StableAnimator)虽然能生成高质量人物动作视频,但无法处理“人物与物体的交互”,比如手拿杯子、打开盒子等动作,常见的问题包括:
把物体当成衣服的一部分(粘在身上) 手穿模或抓不住物体 物体不动或变形 ✅ AnchorCrafter 的解决方案 系统分为两个核心模块:
1️⃣ HOI-Appearance Perception(人-物外观感知) 目的:让人和物体的外观清晰分离,避免“粘在一起”或“互相污染”
关键技术: 多视角物体特征融合:用三张产品图(正面、左侧、右侧)提取3D一致的物体特征 人-物双分支注意力机制(Human-Object Dual Adapter): 人和物体分别用不同的注意力分支处理 避免人物特征影响物体,反之亦然 2️⃣ HOI-Motion Injection(人-物动作注入) 目的:让人物的动作和物体的运动协调一致,比如手抓物体时,物体要跟着手走
关键技术: 输入控制信号: 人体骨架(OpenPose) 手部3D网格(HaMeR) 物体深度图(ViTA) 遮挡处理:当手被物体挡住时,系统仍能推理出手的正确位置 物体轨迹控制:用深度图引导物体在三维空间中的移动路径 3️⃣ HOI-Region Reweighting Loss(交互区域加权损失) 目的:让模型更关注“手和物体交互”的区域,提升细节真实感
在训练时,手和物体的区域损失权重更高 避免模型只关注人脸或身体,忽略手和物体的细节
🧠 训练与推理流程
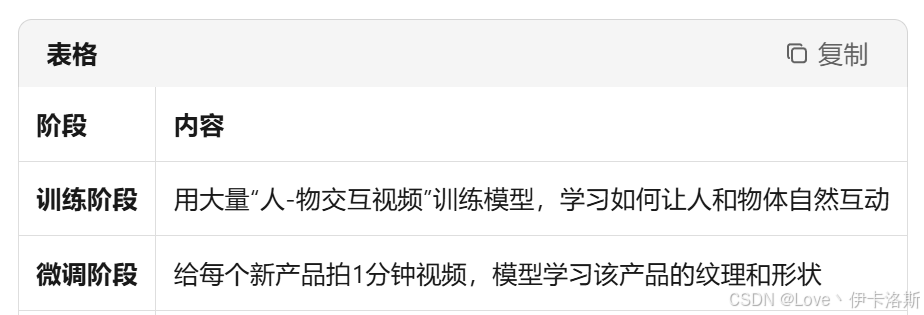
🧪 实验效果
物体保留度提升 7.5% 物体定位精度提升 2 倍 手部动作更自然 用户主观评分最高(外观、动作、真实感)
🧩 举个例子
你可以这样用它:
输入一张主播图 + 三张 iPhone 图 + 一段“打开盒子”的动作视频 👉 输出:主播自然地拿起 iPhone,打开盒子,展示手机
⚠️ 局限性
对透明物体(如玻璃杯)效果差 对非刚性物体(如毛巾、衣服)支持不好 依赖预处理模型(如姿态估计),如果输入错了,输出也会错
✅ 总结一句话
AnchorCrafter 是第一个真正把“人-物交互”做进视频生成的系统,能让虚拟主播自然地“拿产品、展示、操作”,非常适合电商、广告、虚拟直播等场景。
训练简析
AnchorCrafter 训练脚本的主文件,用于训练一个扩散模型(diffusion model)来生成人物与物体交互的视频。它整合了多个模块(U-Net、姿态网络、物体跟踪、注意力机制等),并通过大量参数配置支持分布式训练、混合精度、EMA、断点续训等功能。
🧠 一、核心目标
训练一个模型,使其能够:
- 输入:一张人物图 + 多视角产品图 + 动作控制信号(姿态、手部、深度)
- 输出:人物与产品自然互动的视频(如拿杯子、打开盒子)
🧱 二、核心模块结构
| 模块名 | 作用 |
|---|---|
Net | 主模型,整合所有子网络 |
unet | 扩散模型的主干,用于去噪生成图像 |
pose_net | 处理人体姿态特征 |
track_net | 处理物体跟踪特征(如深度图) |
obj_proj_net | 投影物体类别特征 |
obj_attn_net | 对物体特征做注意力处理 |
IPAttnProcessor | 自定义注意力处理器,支持图像提示(image prompt) |
🧪 三、训练流程概览
1. 数据加载
train_dataset = AnchorDataset(...)
- 加载HOI(人-物交互)视频帧
- 包括:人物图、产品图、姿态图、手部图、物体掩码图等
2. 图像编码
encoder_hidden_states, obj_embeddings = _encode_image(...)
- 人物图 → CLIP → 嵌入向量
- 产品图 → DINOv2 → 嵌入向量(多视角拼接)
3. 加噪与 timestep 采样
sigmas = rand_log_normal(...)
noisy_latents = latents + noise * sigmas
- 使用 log-normal 分布 采样噪声强度(模仿Stable Video Diffusion)
- 构造扩散训练输入
4. 模型前向传播
model_pred = net(...)
- 输入:噪声潜变量 + 条件图 + 姿态 + 手部 + 物体嵌入
- 输出:预测的噪声(用于去噪)
5. 损失计算(重点)
loss = torch.mean(... * loss_weight)
- MSE损失:预测噪声 vs 真实噪声
- 加权损失:对“手+物体”区域加权(
loss_rate_hoi控制权重) - 目的:让模型更关注交互区域,提升细节质量
6. 反向传播与优化
accelerator.backward(loss)
optimizer.step()
- 使用 AdamW 优化器
- 支持混合精度(fp16/bf16)
- 支持梯度累积、梯度裁剪、EMA等
⚙️ 四、关键参数说明(args)
| 参数名 | 含义 |
|---|---|
--base_folder | HOI视频数据集路径 |
--noobj_folder | 无物体视频数据集路径 |
--pretrained_model_name_or_path | 预训练模型路径(如Stable Video Diffusion) |
--dino_path | DINOv2模型路径(用于物体特征提取) |
--num_frames | 每段视频采样帧数(默认16) |
--resolution | 图像分辨率(默认576) |
--loss_rate_hoi | 交互区域损失权重(默认1.0) |
--finetune | 是否进入微调模式(只训练物体细节) |
🧩 五、特色设计详解
✅ 1. 多视角物体特征融合
obj_all_embeddings = []
for obj in obj_pixels:
obj_embeddings = obj_image_encoder(obj).last_hidden_state
obj_all_embeddings.append(obj_embeddings)
obj_all_embeddings = torch.cat(obj_all_embeddings, dim=1)
- 每个物体3张图(左、正、右)→ DINOv2 → 拼接 → 19个token
- 提供3D一致的物体表示
✅ 2. 人-物双分支注意力(IPAttnProcessor)
attn_procs[name] = IPAttnProcessor(
hidden_size=hidden_size,
cross_attention_dim=cross_attention_dim,
scale=1.0,
num_tokens=19
)
- 在U-Net的cross-attention层中插入
- 支持将物体特征作为“图像提示”注入生成过程
✅ 3. 交互区域加权损失(HOI Region Reweighting)
loss_weight_frame[no_zero == 1] = resize_weight
- 根据物体掩码+手部掩码计算交互区域
- 对这些区域赋予更高损失权重 → 提升细节还原
✅ 4. 支持微调模式(finetune)
if not args.finetune:
no_zero[hand_pixels_sum[0][idx] != -3] = 1
- 微调时不强制加入手部区域
- 更专注于物体纹理而非交互动作
🧪 六、调试与监控
| 功能 | 文件/路径 |
|---|---|
| 训练日志 | logs/ |
| 模型保存 | outputs/checkpoint-*/ |
| 参数冻结记录 | params_freeze.txt |
| 参数训练记录 | params_train.txt |
✅ 七、总结一句话
这段代码是 AnchorCrafter 的完整训练系统,它通过:
- 多视角物体特征
- 人-物注意力分离
- 交互区域加权损失
- 扩散模型去噪训练
实现了高质量的人-物交互视频生成,支持微调、分布式、混合精度等工业级训练需求。
如果你想,我可以给你画一个训练流程图,或者单独讲某一部分(如损失设计、注意力机制、数据加载)。
训练通俗话简析
好的!下面我把这段代码拆成 7 个生活化的“小剧场”,用买菜、做菜、拍照、画画这些日常例子来解释。你完全不需要 AI 背景,就能明白每一大段到底在干什么。
🧃 0. 先把整件事想成“做一段炒菜 Vlog”
| 真·AI 术语 | 生活化翻译 |
|---|---|
| 训练模型 | 教一个新手剪辑师(模型)怎样把你拍的生肉素材剪成漂亮 Vlog |
| 数据集 | 你之前拍过的几百条做菜视频 |
| 损失函数 | 观众弹幕:“手遮住了锅!”“菜颜色不对!”——这些差评就是损失 |
| 优化器 | 剪辑师根据差评改剪法 |
| 预训练模型 | 剪辑师已经会剪旅游 Vlog,你只要微调他让他学会剪做菜即可 |
带着这个比喻,我们进入正式板块。
🧺 板块 1. 数据加载(AnchorDataset)
原始代码位置
train_dataset = AnchorDataset(base_folder, noobj_folder, ...)
生活剧
- 你把硬盘里的“做菜视频”分成两堆
- 有锅/铲出现的 →
base_folder(HOI 视频) - 只有人没锅的 →
noobj_folder(纯人视频)
- 有锅/铲出现的 →
- 每段视频剪成 16 张关键帧(
num_frames=16),相当于从“洗菜→切菜→下锅”里抽 16 张代表性照片。 - 同时额外导出 5 种“小抄”:
- 人物证件照(
image_pixels) - 锅的证件照 3 张(左、正、右,
obj_pixels) - 人物骨架简笔画(
pose_pixels) - 手部特写(
hand_pixels) - 锅的位置遮罩图(
box_video_pixels)
- 人物证件照(
一句话
Dataset 就是“视频+小抄”打包机,让模型后面看图说话。
📷 板块 2. 图像编码器(_encode_image)
原始代码位置
encoder_hidden_states, obj_embeddings = _encode_image(...)
生活剧
- 人物证件照 → 交给“人像描述员”(CLIP 模型)→ 得到 1 句 768 字的文字简历。
- 锅的 3 张证件照 → 交给“物体描述员”(DINOv2 模型)→ 得到 19 句 1024 字的简历。
- 这些简历后续会被 U-Net 当成“提示词”使用,就像你告诉剪辑师“这段要剪成温馨风格”一样。
🌪 板块 3. 加噪与 timestep(rand_log_normal 等)
原始代码位置
sigmas = rand_log_normal(...)
noisy_latents = latents + noise * sigmas
生活剧
- 把原始 16 帧清晰图 → 压成“马赛克”潜变量(VAE 编码)。
- 随机决定今天要“糊”到什么程度:
- 有时轻雾(σ 小)
- 有时重雾霾(σ 大)
- 模型任务:从雾霾图猜回原图。
为什么这么做?
就像给剪辑师出练习题:先故意把视频打码,让他练习“去码”,练多了以后遇到真实模糊他也能还原。
🧠 板块 4. 主模型 Net(U-Net + 小菜网络)
原始代码位置
model_pred = net(inp_noisy_latents, encoder_hidden_states, ...)
生活剧
U-Net 是“主剪辑师”,但他需要 4 位助理不断递小抄:
| 助理 | 递的小抄 | 作用 |
|---|---|---|
pose_net | 人物骨架简笔画 | 提醒“手在哪个位置” |
track_net | 锅的深度/轨迹图 | 提醒“锅要往哪儿移动” |
obj_proj_net | 锅的 3 句简历 | 提醒“锅长啥样” |
obj_attn_net | 锅的 19 句详细简历 | 提醒“锅的细节纹理” |
主剪辑师把这些小抄与雾霾图一起放进时间轴,输出“去码后的清晰图”。
🎯 板块 5. 损失函数(MSE + 手锅加权)
原始代码位置
loss = torch.mean(... * loss_weight)
生活剧
- 观众弹幕差评分为两种:
- 普通区域差一点点颜色 → 扣 1 分
- 手或锅区域严重穿帮 → 扣 10 分(因为
loss_weight在这里加了倍)
- 剪辑师根据“扣分地图”重点练手锅区域,下次手不会穿模,锅也不会变形。
🔧 板块 6. 优化器 & 学习率调度
原始代码位置
optimizer = torch.optim.AdamW(...)
lr_scheduler = get_scheduler(...)
生活剧
- 剪辑师每次剪完一条视频,观众给他打分(损失)。
- 他根据扣分多少决定下次剪法微调幅度(学习率)。
- 初期步子大(warm-up),后期步子小(cosine/constant),防止“矫枉过正”。
💾 板块 7. 断点保存 & 恢复
原始代码位置
accelerator.save_state(save_path)
生活剧
- 每剪 500 条视频自动存档(checkpoint)。
- 电脑突然死机 → 重新打开脚本,选择“从最新存档点继续”,之前练的不会白费。
🧪 板块 8. 微调模式(finetune 开关)
原始代码位置
if not args.finetune: ...
生活剧
- 预训练阶段:剪辑师既要学“手怎么握锅”,也要学“锅长啥样”。
- 微调阶段:你已经有一个很会握锅的剪辑师,只想让他记住“新锅的花纹”,于是把手部差评关掉,只专注锅的外观。
🎬 总结成一句人话
整段代码就是——
“手把手教一个会剪片的新手,先随便给视频打码,再让他靠‘骨架小抄+锅的简历’反复练习去码,观众专门挑手锅区域给差评,他越剪越精,最后能把你给的任何证件照变成一段流畅的做菜 Vlog。”
进一步简化讲解
🔍 1. VAE(变分自编码器)——“高清图 ↔ 小方块”的魔法复印机
📌 你只需要知道:
- VAE 就像一个魔法复印机,能把高清图压成小方块(潜变量),也能把小方块还原回高清图。
- 为什么要压小?因为小方块处理得快,训练时省时间、省显存。
🧃 生活例子:
想象你有一本厚厚的菜谱:
- 压缩:你把每页菜谱拍成一张缩略图(小方块),方便快速浏览。
- 还原:当你看到缩略图,魔法复印机又能还原成清晰原图,让你看清每道菜细节。
🎬 在代码里:
latents = tensor_to_vae_latent(video_pixels, vae)
- 把原始视频帧(清晰图)→ 压成小方块(潜变量)
- 后续所有“加噪”、“去噪”操作都在小方块上进行,速度飞快!
🔍 2. DINOv2(物体描述员)——“只用三张照片,生成物体简历”
📌 你只需要知道:
- DINOv2 是一个专门描述物体的 AI 模型。
- 你给 DINOv2 三张产品图(左、正、右),它会输出19 句“简历”,每句 1024 个字,描述物体的形状、纹理、颜色。
🧃 生活例子:
你去面试,HR 让你交三张照片(正面、左侧、右侧),然后 HR 给你写一份 19 句的简历:
- 第 1 句:“此人圆脸,戴眼镜。”
- 第 2 句:“头发黑色,微卷。”
- …
- 第 19 句:“整体看起来科技感强。”
🎬 在代码里:
obj_embeddings = obj_image_encoder(obj).last_hidden_state
- 三张产品图 → DINOv2 → 19 句简历(19×1024 维向量)
- 这些简历后续会喂给 U-Net,提醒它“锅长啥样”。
🔍 3. 手锅遮罩(hand_pixels & box_video_pixels)——“告诉模型哪里是手、哪里是锅”
📌 你只需要知道:
- 遮罩就是一张黑白图,白色区域表示“这里很重要”,黑色区域表示“这里可以忽略”。
- 代码里有两类遮罩:
hand_pixels:白色区域是“手”box_video_pixels:白色区域是“锅”
🧃 生活例子:
你拍照后,用美图软件手动涂白两个区域:
- 把手涂白:告诉修图师“手要精修”
- 把锅涂白:告诉修图师“锅也要精修” 其余背景保持黑色:修图师可以随便压画质,观众看不出来。
🎬 在代码里:
no_zero[hand_pixels_sum[0][idx] != -3] = 1
- 如果某像素不是“空白”(-3 表示空白),就认为它是手,涂白。
- 最终生成一张白色=手或锅的遮罩图,用于后续损失加权。
🔍 4. 损失加权(loss_weight)——“观众弹幕扣分地图”
📌 你只需要知道:
- 原本的损失函数是“整张图平均扣分”。
- 现在用遮罩图,把手 & 锅区域的扣分乘以倍数,让模型更关注这些区域。
🧃 生活例子:
老师改作文:
- 原来:整篇作文错 10 个字,扣 10 分。
- 现在:老师用红笔圈出标题 & 结尾(关键区域),这里错 1 个字扣 5 分,其余段落错 1 个字扣 1 分。
- 结果:你下次写作文,会特别小心标题和结尾,因为扣分重。
🎬 在代码里:
loss_weight_frame[no_zero == 1] = resize_weight
- 白色区域(手/锅)乘以高权重(例如 5 倍)
- 黑色区域(背景)乘以 1 倍
- 最终模型会重点优化手锅区域,减少穿模、变形。
🔍 5. 潜变量(latents)——“在缩略图上画画,再放大成高清图”
📌 你只需要知道:
- 所有“加噪”、“去噪”操作,都在**小方块(潜变量)**上进行,而不是直接改高清图。
- 好处:速度快、显存省、训练稳定。
🧃 生活例子:
你要画一幅巨幅海报:
- 直接画大海报?—— 累得慌,容易画错。
- 先画一张 A4 草图(小方块),画错也不怕,随便改。
- 画完后,用投影仪放大成海报(VAE 解码),又快又清晰。
🎬 在代码里:
inp_noisy_latents = noisy_latents / ((sigmas ** 2 + 1) ** 0.5)
model_pred = net(inp_noisy_latents, ...)
denoised_latents = model_pred * c_out + c_skip * noisy_latents
- 所有“去噪”操作都在小方块上进行。
- 最后用小方块→VAE→还原成高清视频帧。
🎯 总结成一张图(文字版)
| 步骤 | 生活比喻 | 代码中的体现 |
|---|---|---|
| 1. 高清图 → 小方块 | 把大海报拍成 A4 缩略图 | tensor_to_vae_latent |
| 2. 产品图 → 19 句简历 | 三张证件照 → HR 写简历 | obj_image_encoder(obj) |
| 3. 手/锅涂白 | 美图软件局部精修 | hand_pixels, box_video_pixels |
| 4. 扣分加重 | 老师圈重点,错一字扣 5 分 | loss_weight[white_area] *= 5 |
| 5. 小方块 → 高清图 | A4 草图 → 投影仪放大 | vae.decode(latents) |
🔍6. U-Net
把 U-Net 想成一位**“修图师”,专门干“去雾霾”这一件事。
它手里有两把刷子、一张草稿纸、一本小抄册**,工作流程特别固定,但效果奇好——现在几乎所有 AI 画图/视频都离不开它。
🧃 1. 先上一张“身份证照片”
输入(雾霾图) 输出(清晰图)
│ │
▼ ▲
[ 收 缩 路 ] → → → [ 扩 张 路 ]
越来越小 越来越大
特征变抽象 特征变具体
- 收缩路 = 把图“挤”成几颗小豆豆,抓住“大轮廓”
- 扩张路 = 把小豆豆“吹”回全尺寸,恢复“细节”
- 中间还有“跳连接”= 把早期草稿直接复印回来,防止画歪。
🧃 2. 生活版小故事——“帮奶奶修复老照片”
- 你先把老照片复印一份(跳连接)放旁边。
- 把原图缩印 4 次,越缩越小——
- 第一次还能看见“人脸”。
- 最后一次只剩“黑白大色块”。
- 在最小色块上,你拿粗笔把“划痕”涂掉——这一步叫“去噪/去雾霾”。
- 再把图放大回来,每放大一次,都拿早期草稿对一下位置:
- “鼻子原来在这儿,别画歪。”
- “皱纹保留,别当划痕全抹了。”
- 最后得到一张干净、不歪、细节全的新照片。
→ 这套“缩-涂-放-对草稿”的流程,就是 U-Net 的核心。
🧃 3. 技术黑话对照表(一看就懂)
| 黑话 | 生活翻译 |
|---|---|
| 编码器(Encoder) | 收缩路:把图越压越小,抓大轮廓 |
| 解码器(Decoder) | 扩张路:把小图吹回来,补细节 |
| 跳连接(Skip Connection) | 早期草稿复印机:防止“画歪” |
| 特征图(Feature Map) | 草稿纸:每一层都画一张“内部草图” |
| 卷积层(Conv) | 画笔:在草稿纸上涂涂抹抹 |
| 扩散模型里的 U-Net | 专门负责“去雾霾”的修图师 |
🧃 4. 在 AnchorCrafter 里它具体干什么?
model_pred = self.unet(
inp_noisy_latents, # 雾霾小方块(不是高清图)
timesteps, # 今天雾霾有多重
encoder_hidden_states, # 小抄:人物简历+锅的简历
pose_latents, # 小抄:骨架简笔画
obj_track_latents, # 小抄:锅的深度轨迹
added_time_ids, # 小抄:帧率、运动强度
).sample
一句话:
U-Net 拿着“雾霾小方块”和一堆“小抄”,一层层缩、一层层放,最后给你一张“去雾霾后的清晰小方块”。
🧃 5. 为什么叫“U-Net”?
把模型图竖起来看,就是一个大写字母 U——先下去(收缩)再上来(扩张),所以干脆叫 U-Net。
🧃 6. 一句话总结
U-Net 就是**“先缩后放、草稿对位”的修图师,
在 AnchorCrafter 里专门负责把雾霾小方块还原成清晰小方块**,
让最终视频手不歪、锅不变形、动作流畅。
AnchorCrafter项目介绍
主播风格产品宣传视频的生成在电子商务、广告和消费者互动方面展现出广阔前景。 尽管姿态引导的人体视频生成取得了进展,但创建产品宣传视频仍然充满挑战。 为了应对这一挑战,我们将人-物交互(HOI)集成到姿态引导的人体视频生成中,作为核心问题。 为此,我们引入了 AnchorCrafter,一个新颖的基于扩散的系统,旨在生成具有目标人物和定制对象的2D视频,实现高视觉保真度和可控交互。 具体来说,我们提出了两项关键创新:HOI-外观感知,它增强了从任意多视角识别对象外观的能力,并解耦了对象和人物外观;以及HOI-运动注入,它通过克服对象轨迹条件和相互遮挡管理方面的挑战,实现了复杂的人-物交互。 大量实验表明,与现有最先进的方法相比,我们的系统将对象外观保留率提高了7.5%,对象定位精度提高了一倍。它还在保持人体运动一致性和高质量视频生成方面优于现有方法。
入门
环境设置
conda create -name anchorcrafter python==3.11
pip install -r requirements.txt
检查点
- 下载 DWPose 模型并将其放置在 ./models/DWPose 中。
wget https://huggingface.co/yzd-v/DWPose/resolve/main/yolox_l.onnx?download=true -O models/DWPose/yolox_l.onnx
wget https://huggingface.co/yzd-v/DWPose/resolve/main/dw-ll_ucoco_384.onnx?download=true -O models/DWPose/dw-ll_ucoco_384.onnx
- 下载 Dinov2-large 模型并将其放置在 ./models/dinov2_large 中。
- 下载 SVD 模型并将其放置在 ./models/stable-video-diffusion-img2vid-xt-1-1 中。
- 您需要修改 unet/config.json 文件中的 "in_channels" 参数。
in_channels: 8 => in_channels: 12
- 您可以下载 AnchorCrafter_1.pth 并将其放置在 ./models/ 中。此模型已在 finutune 数据集(五个测试对象)上进行了微调。
最后,所有权重应按以下方式组织在 models 中
models/
├── DWPose
│ ├── dw-ll_ucoco_384.onnx
│ └── yolox_l.onnx
├── dinov2_large
│ ├── pytorch_model.bin
│ ├── config.json
│ └── preprocessor_config.json
├── stable-video-diffusion-img2vid-xt-1-1
└── AnchorCrafter_1.pth
推理
./config 中提供了测试的示例配置。您还可以根据需要轻松修改各种配置。
sh inference.sh
微调
我们提供了训练脚本。请下载 finutune 数据集 AnchorCrafter-finutune 并将其放置在 ./dataset/tune/ 中。
dataset/tune/
├── depth_cut
├── hand_cut
├── masked_object_cut
├── people_cut
├── video_pose
└── video_cut
下载 non-finetuned 权重并将其放置在 ./models/ 中。 训练代码可以执行如下:
sh train.sh
我们使用 DeepSeed 来实现多 GPU 训练,需要至少 5 个 GPU,每个 GPU 具有 40GB 显存。sh train.sh 中的一些参数应根据您的配置填写。
数据集
AnchorCrafter-test
我们发布了测试数据集 AnchorCrafter-test,其中包括五个对象和八张人物图像,每个对象具有两种不同的姿态。
AnchorCrafter-400
我们收集并提供了可供申请的基础 HOI 训练数据集 AnchorCrafter-400,其中包含 400 个视频。它专为学术研究而设计。如果您希望申请使用,请填写 问卷。
引用
@article{xu2024anchorcrafter,
title={AnchorCrafter: Animate CyberAnchors Saling Your Products via Human-Object Interacting Video Generation},
author={Xu, Ziyi and Huang, Ziyao and Cao, Juan and Zhang, Yong and Cun, Xiaodong and Shuai, Qing and Wang, Yuchen and Bao, Linchao and Li, Jintao and Tang, Fan},
journal={arXiv preprint arXiv:2411.17383},
year={2024}
}
致谢
以下是我们受益的一些优秀资源:Diffusers, Stability-AI , MimicMotion, SVD_Xtend
