Ming-UniVision
使用连续统一分词器进行联合图像理解和生成
 2
20元/小时
v1.1
v1.0
Ming-UniVision
Ming-UniVision 是一种突破性的多模态大语言模型(MLLM),它将视觉理解、生成和编辑统一在一个自回归下一词预测(NTP)框架内,由 MingTok 驱动——这是首个连续的统一视觉分词器。通过消除离散量化并利用共享的连续潜在空间,Ming-UniVision 实现了跨不同任务的流畅、端到端的多模态推理。在基于高保真连续视觉表示的训练下,Ming-UniVision 支持多轮、上下文感知的视觉-语言交互,如迭代问答、图像生成和语义编辑——所有这些都不需要将中间状态解码为像素。这使得能够进行高效、连贯且类似人类的、具有一致特征动态的多模态对话。
使用教程
0. 麻烦右上角点个收藏~

1. 在镜像详情界面点击“使用该镜像创建实例”
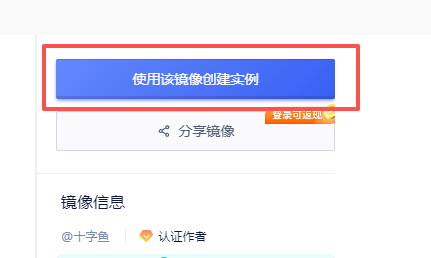
2. 选择GPU型号,再点击“立即部署”
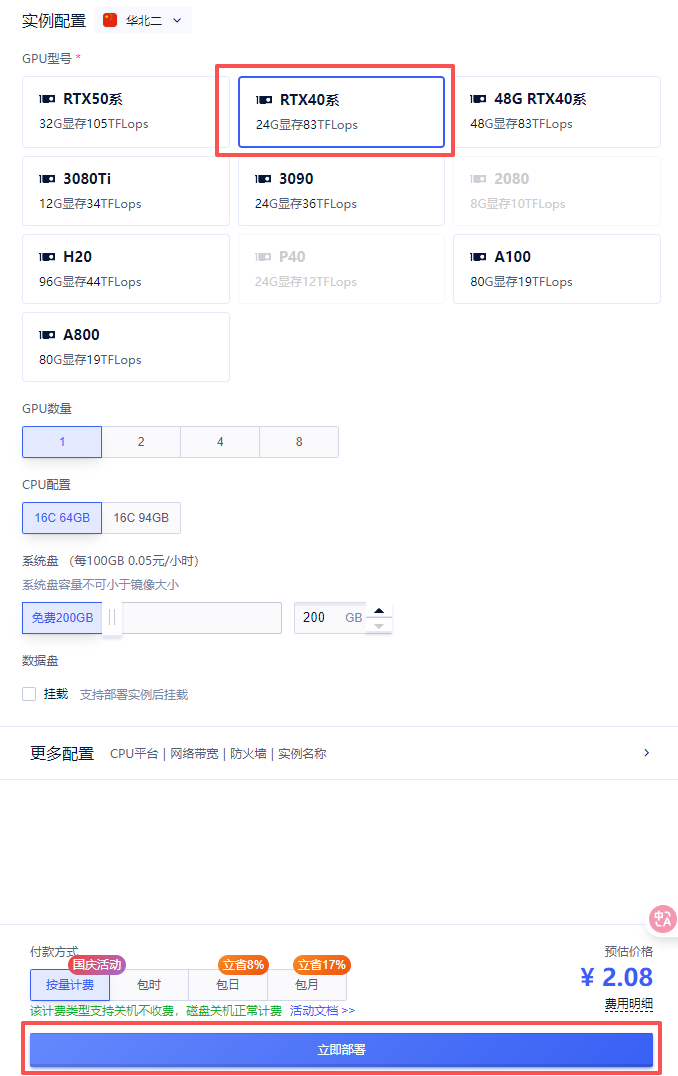
3. 实例启动后,在控制台中点击“SD-WebUI”
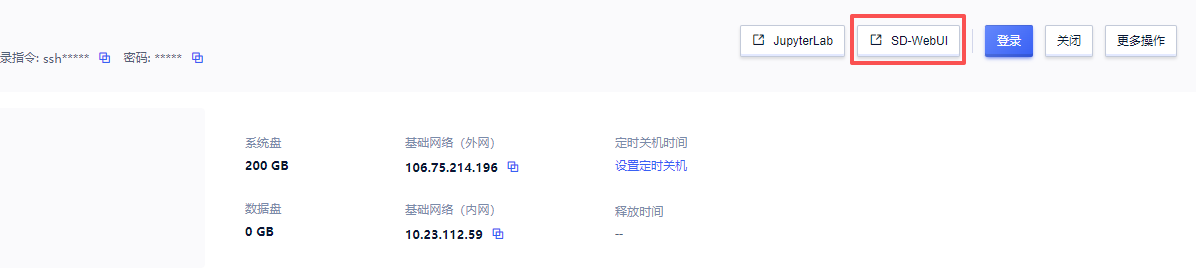
4.浏览器如图显示,就说明启动成功了
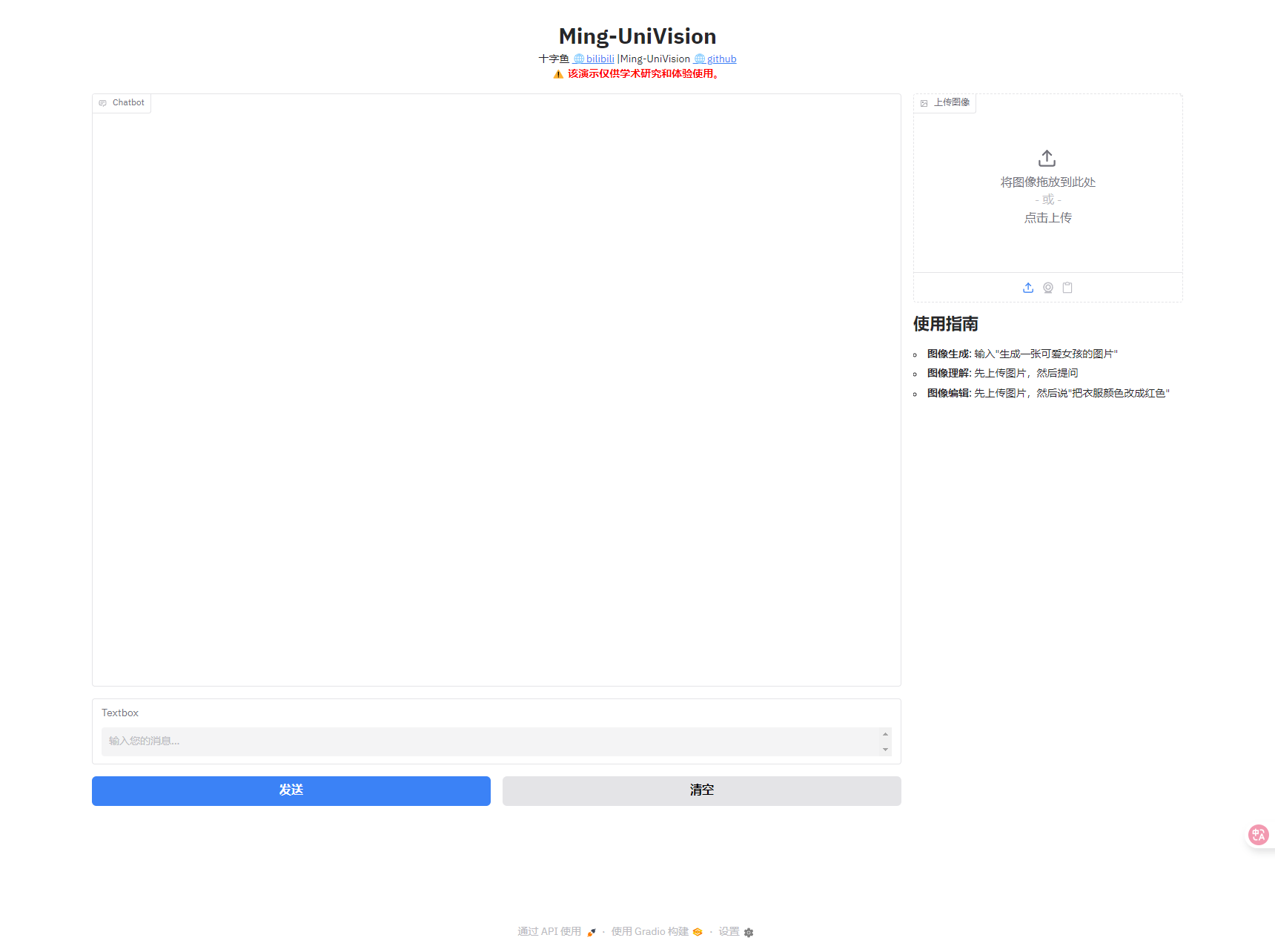
5.如果页面无响应,点击“JupyterLab”,再双击log.txt可查看启动进度
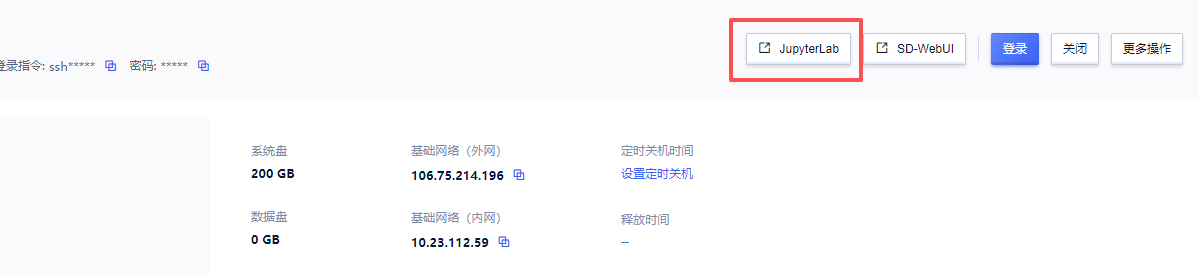
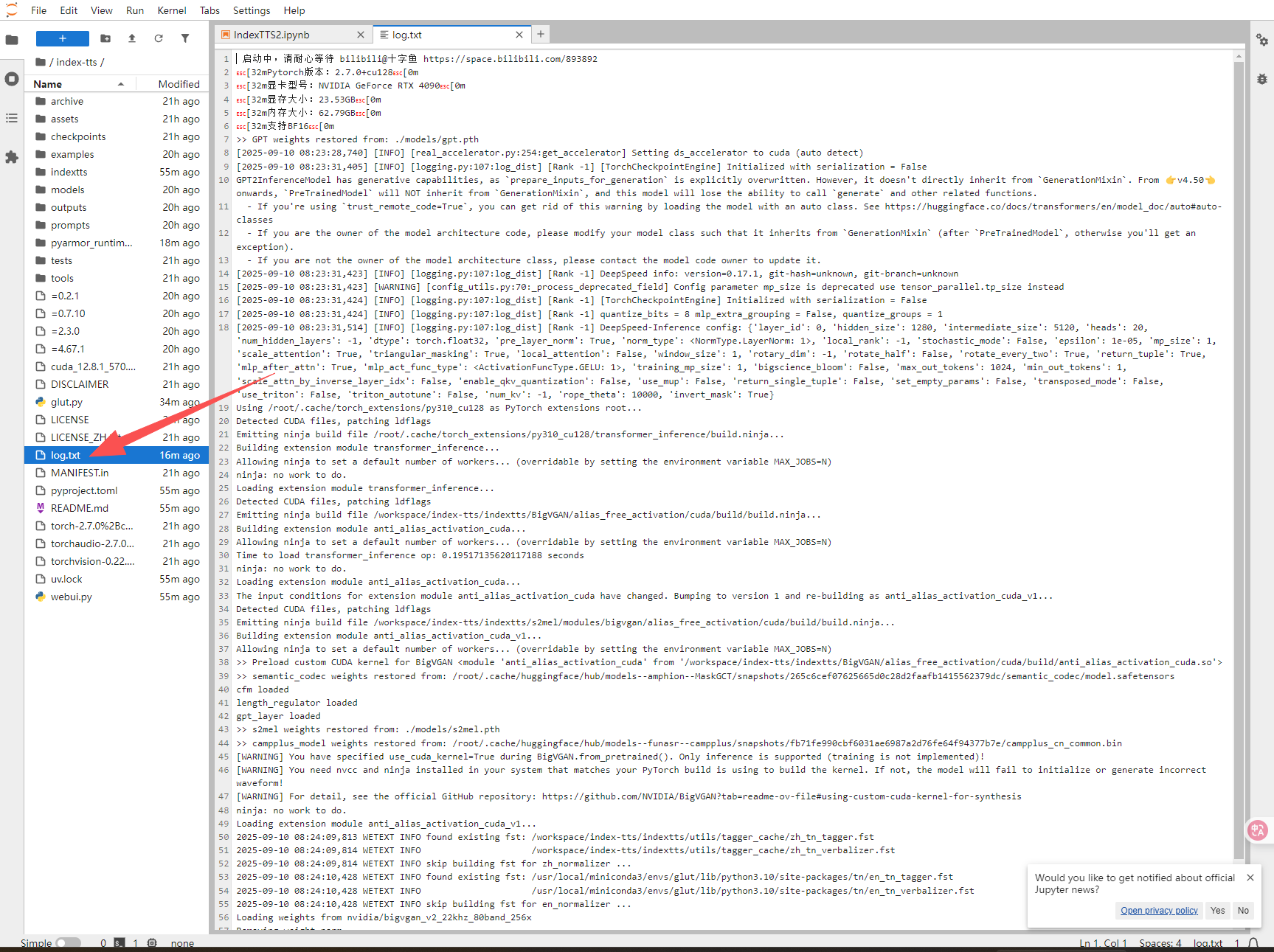
6.如果有报错的话,请下载log.txt发到下面的交流群中
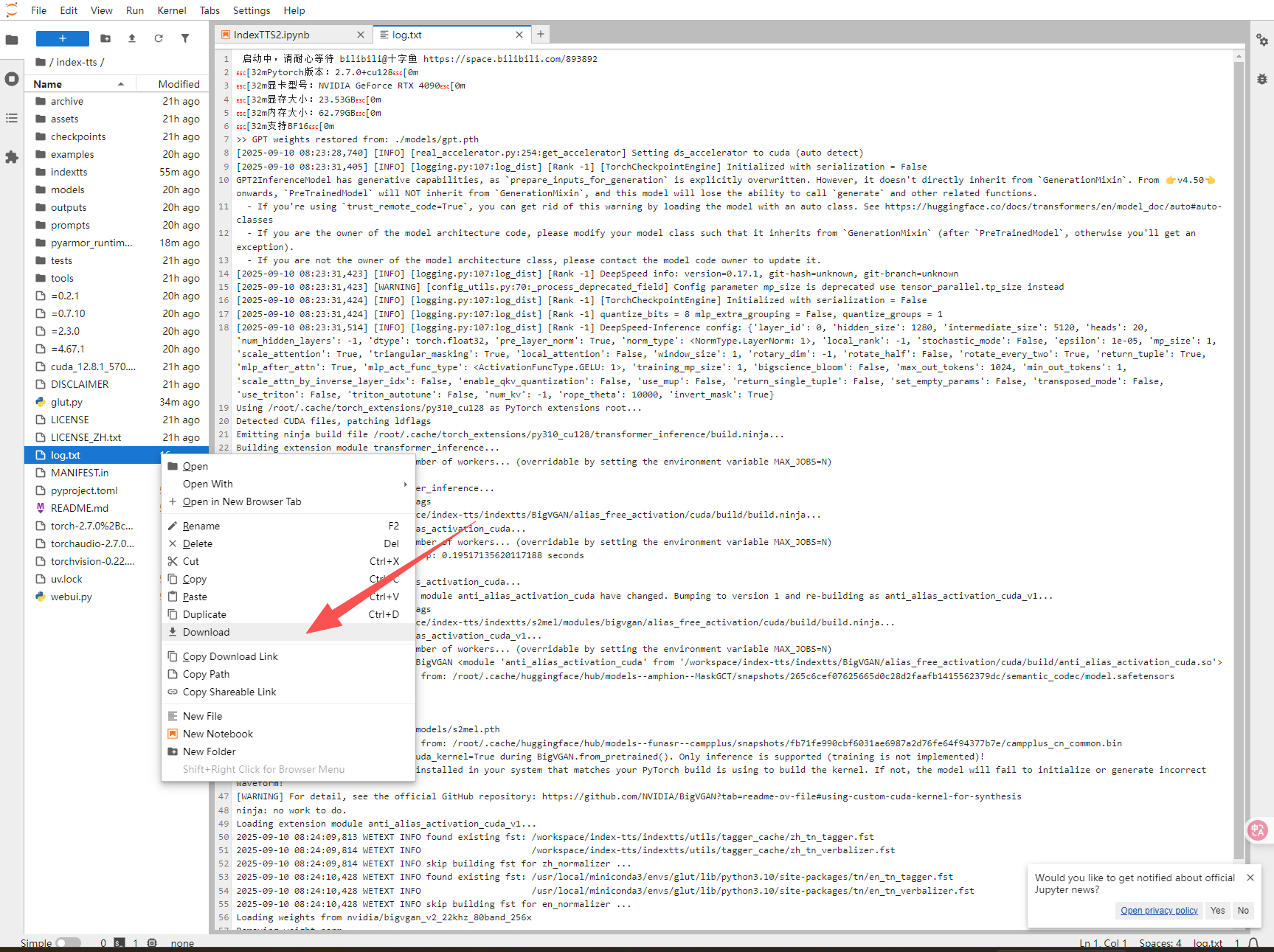
7.提示
7.1 第一次生成会加载模型,所以时间较长。后续生成的速度正常。
十字鱼-镜像作者交流群

@十字鱼 认证作者
认证作者
认证作者
镜像信息
已使用13 次
运行时长
4 H
 支持自启动
支持自启动镜像大小
100GB
最后更新时间
2025-10-12
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100SV100S
+14
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.1
2025-10-12
v1.0
2026-02-02