GLM-ASR智谱开源的语音识别、语音转文本模型 二次开发构建By科哥
智谱开源的语音识别语音转文本声音转文本模型
 0
00元/小时
v1.1
GLM-ASR智谱开源的语音识别、语音转文本模型
镜像简介
本镜像基于智谱开源的GLM-ASR语音识别模型二次开发,能够高效准确地将语音转换为文本。提供便捷的本地部署方案,适用于会议记录实时整理、视频字幕生成、语音资料归档及无障碍信息服务等场景,为用户带来精准可靠的语音转文字解决方案。
优云镜像使用操作一般流程:
1、在社区镜像区域,选择镜像:
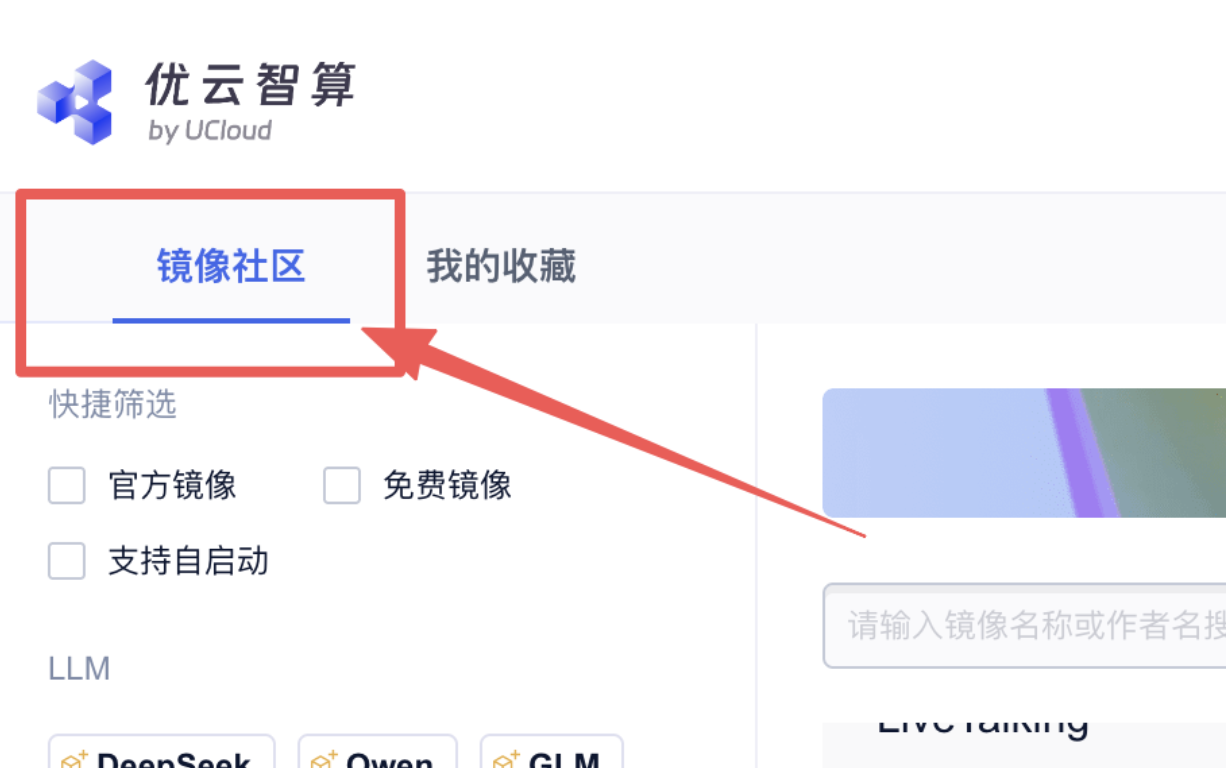
2、在打开的新页面 点击“使用该镜像创建实例”:
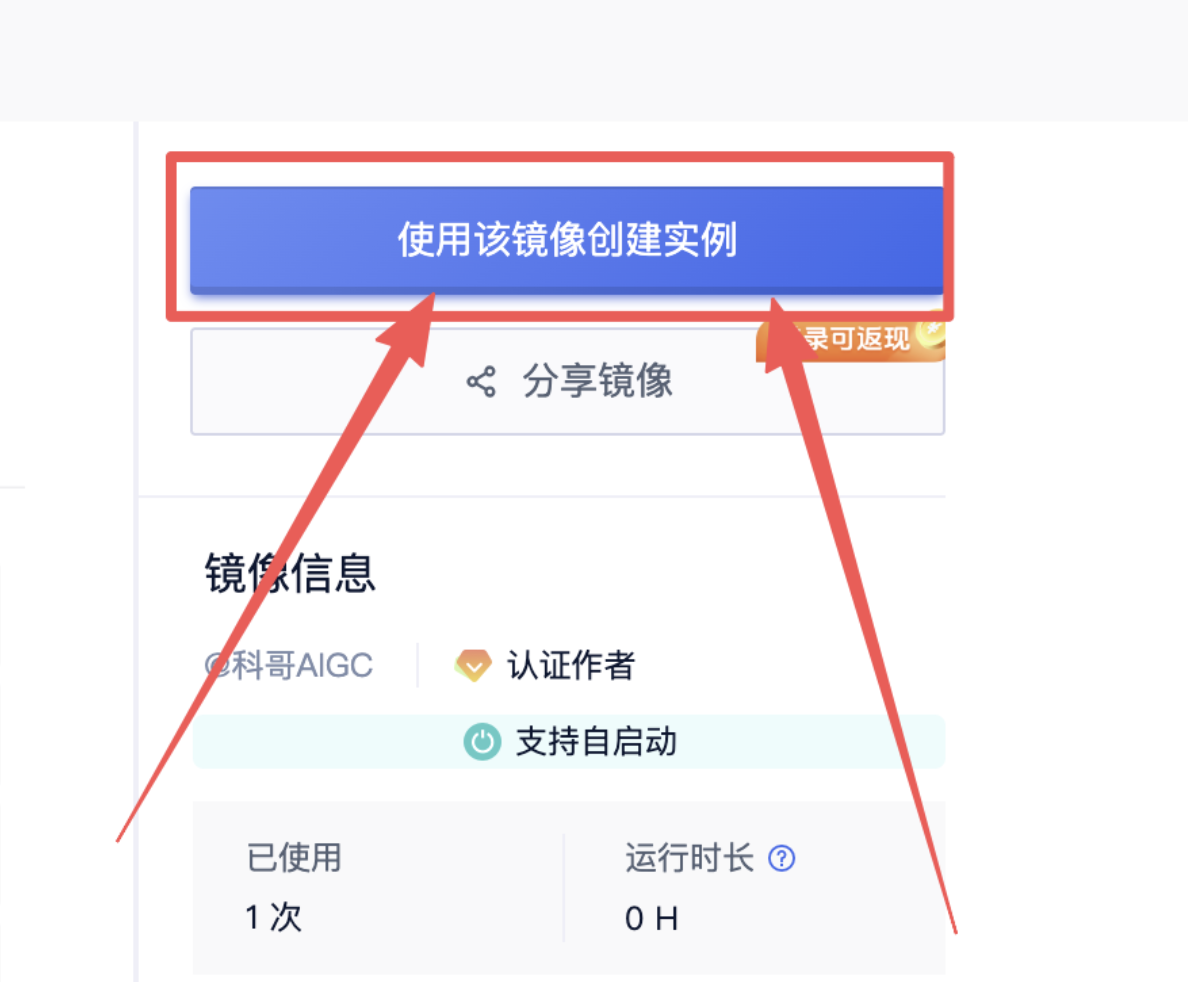
3、选择一个合适的显卡【GPU】根据情况选择:
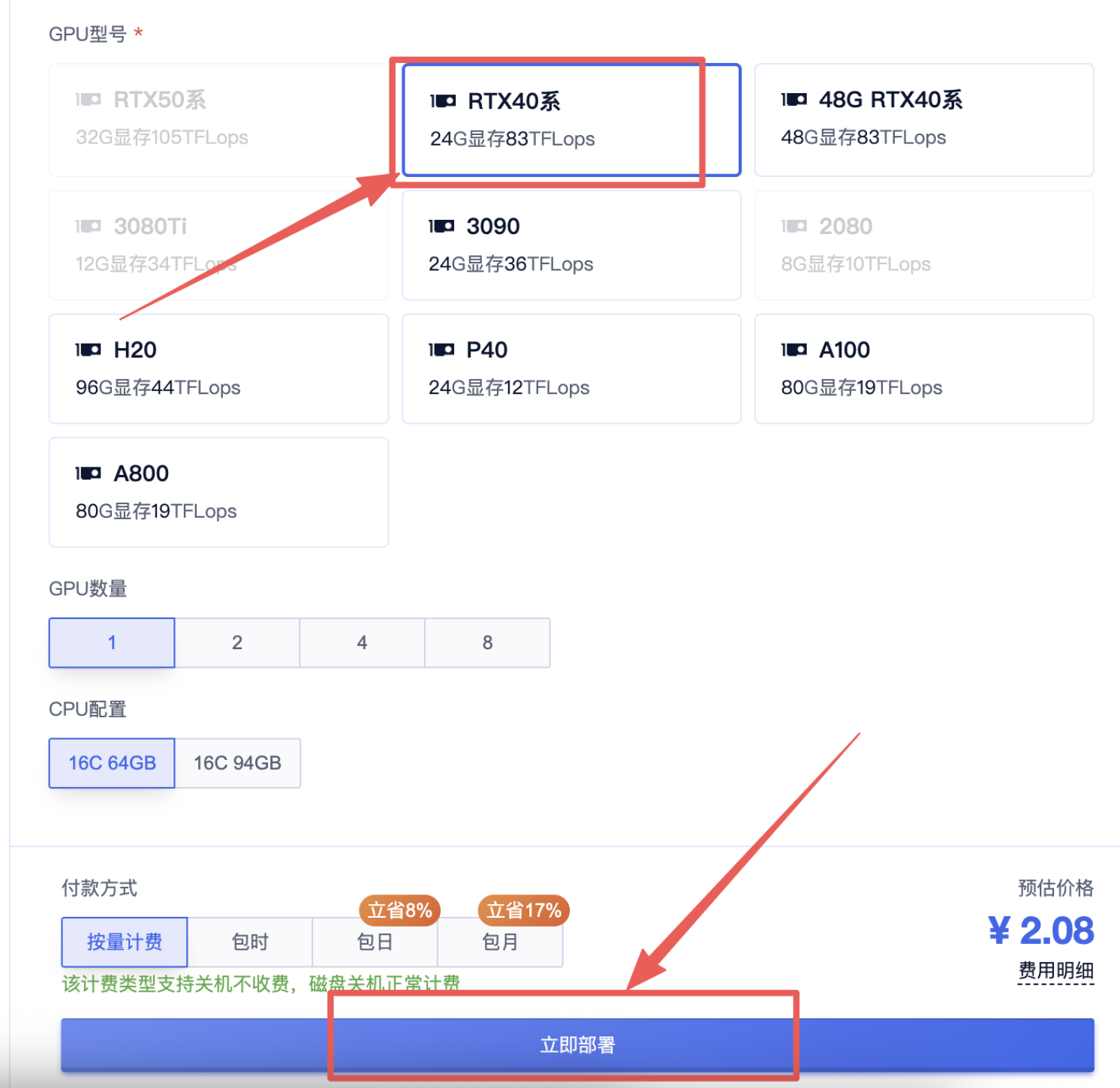
4、确认部署信息无误,点击“开始部署”,然后等待部署完成:
如何启动应用
不是自动运行的应用:
1、手动点击加号新建起始页:
2、打开终端:
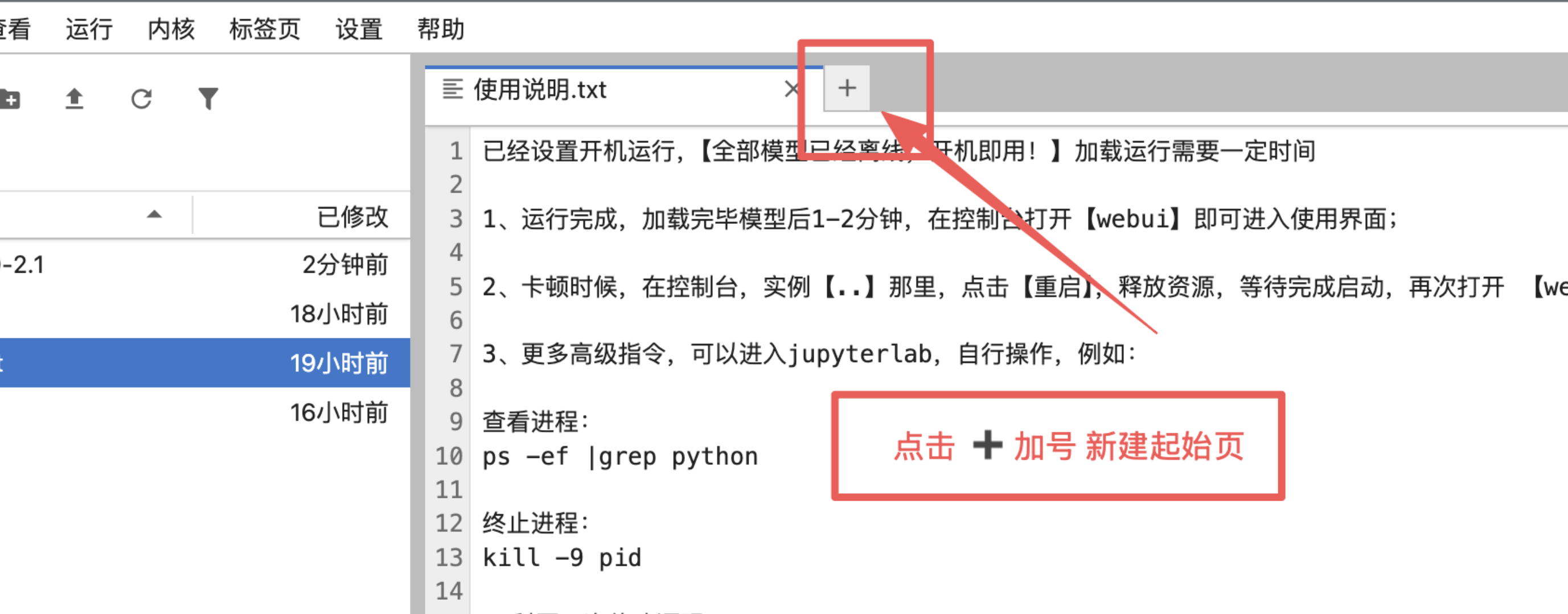
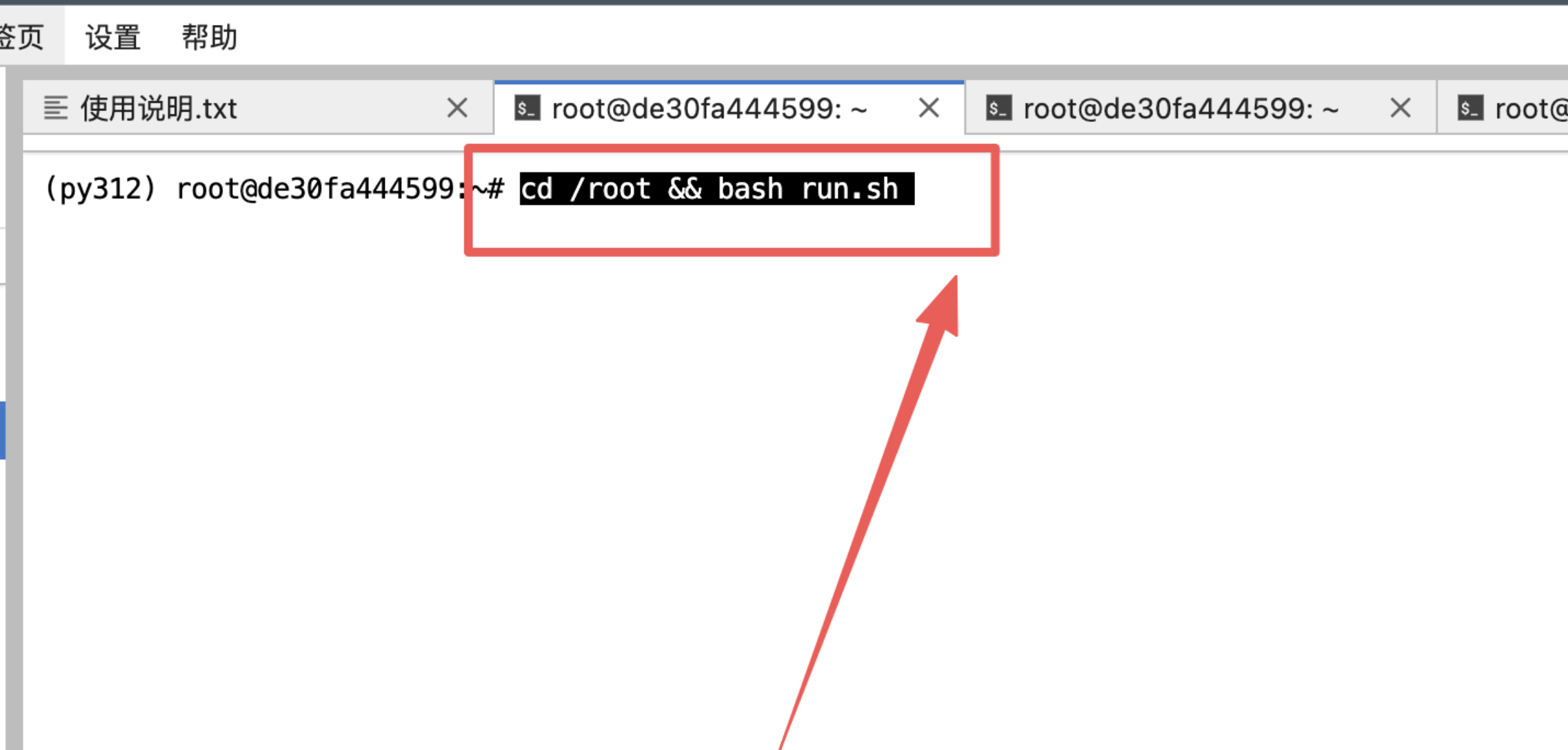
3、输入指令然后回车:
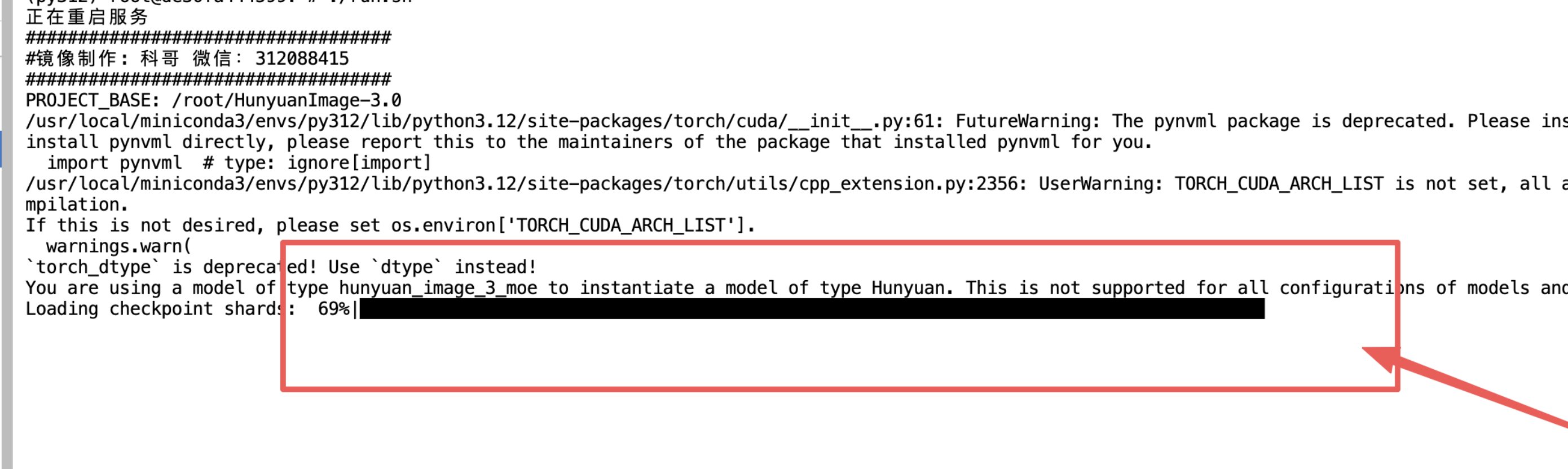
4、等待加载模型完毕:
5、看到这个出现:
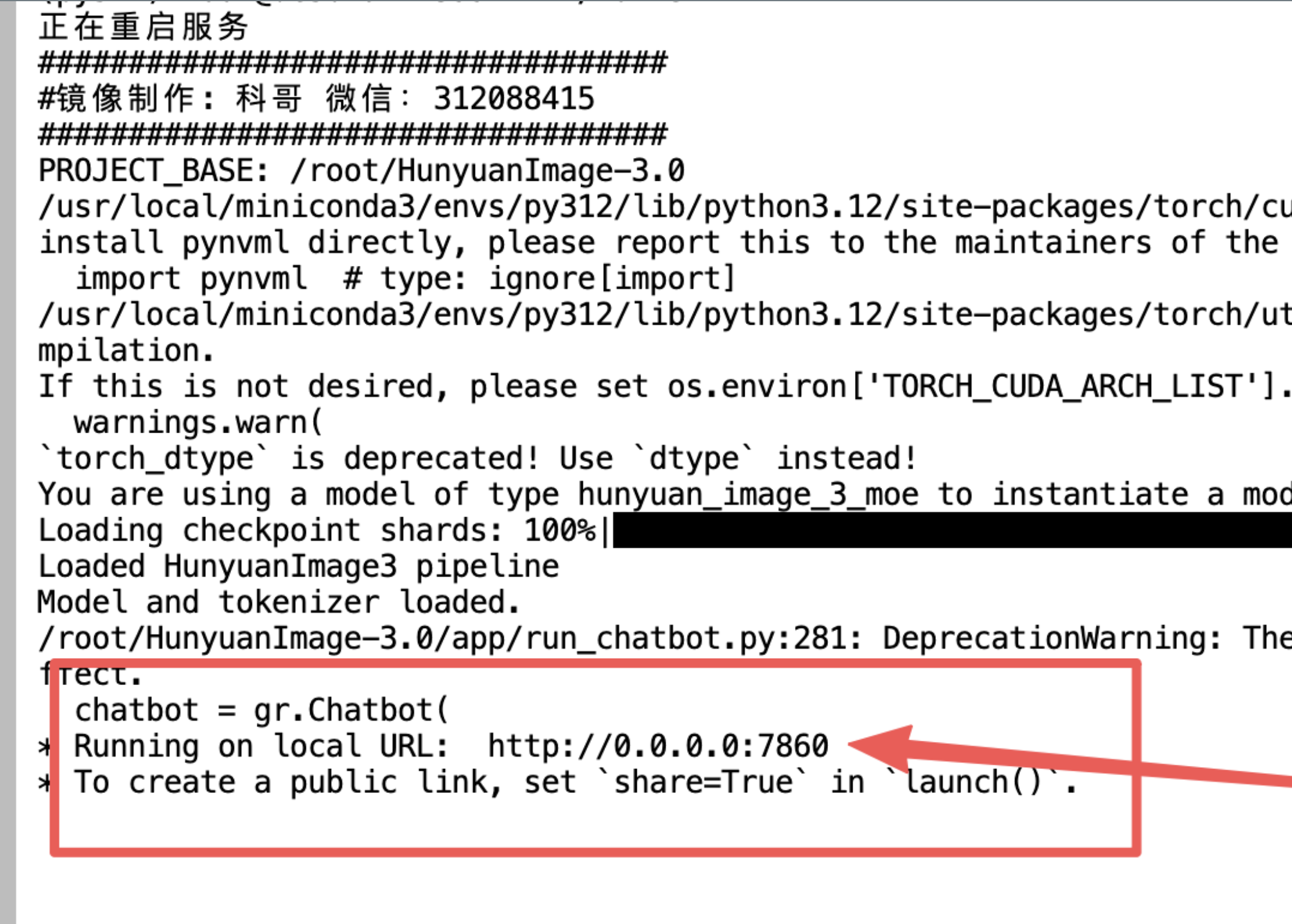
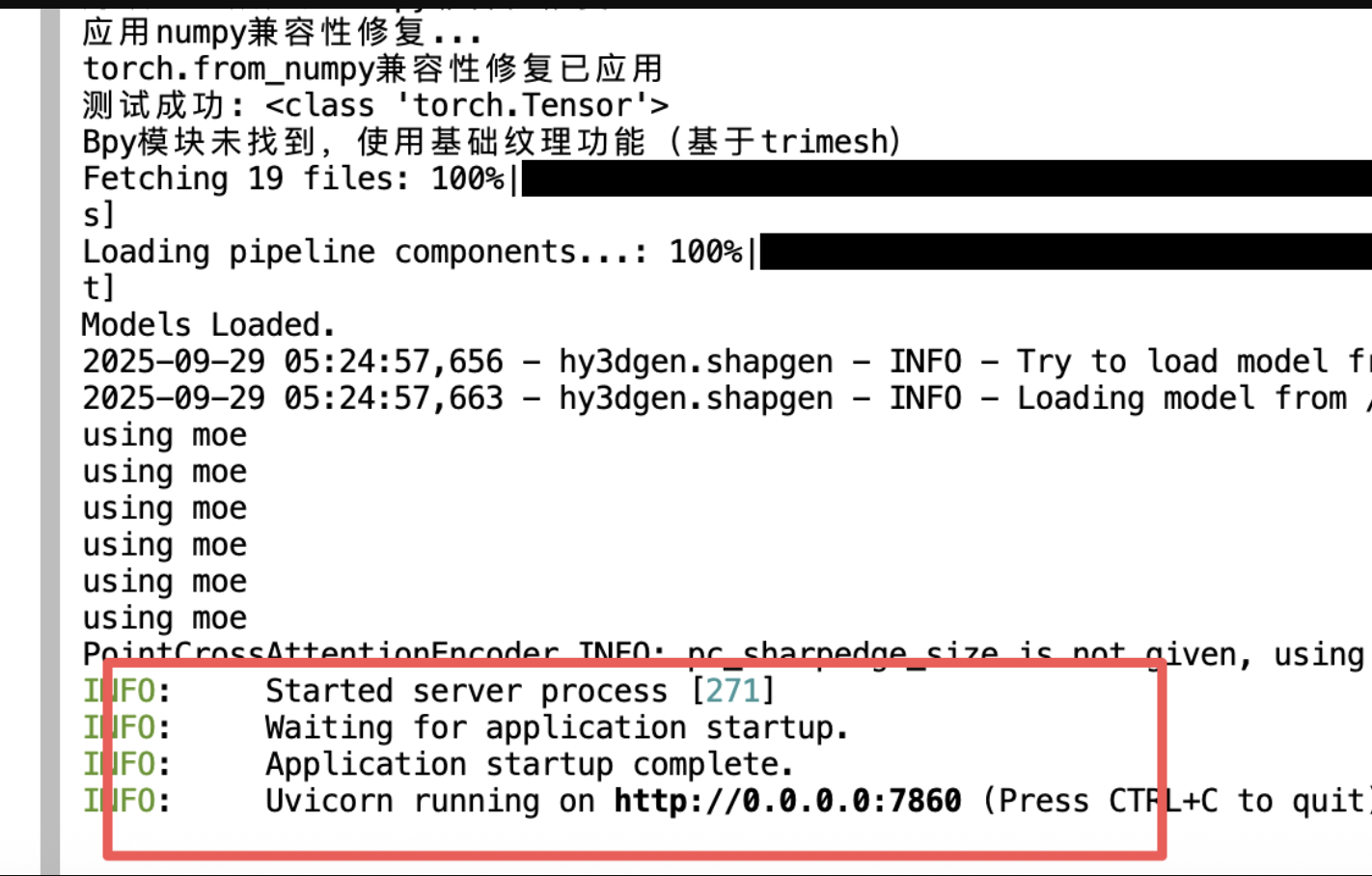
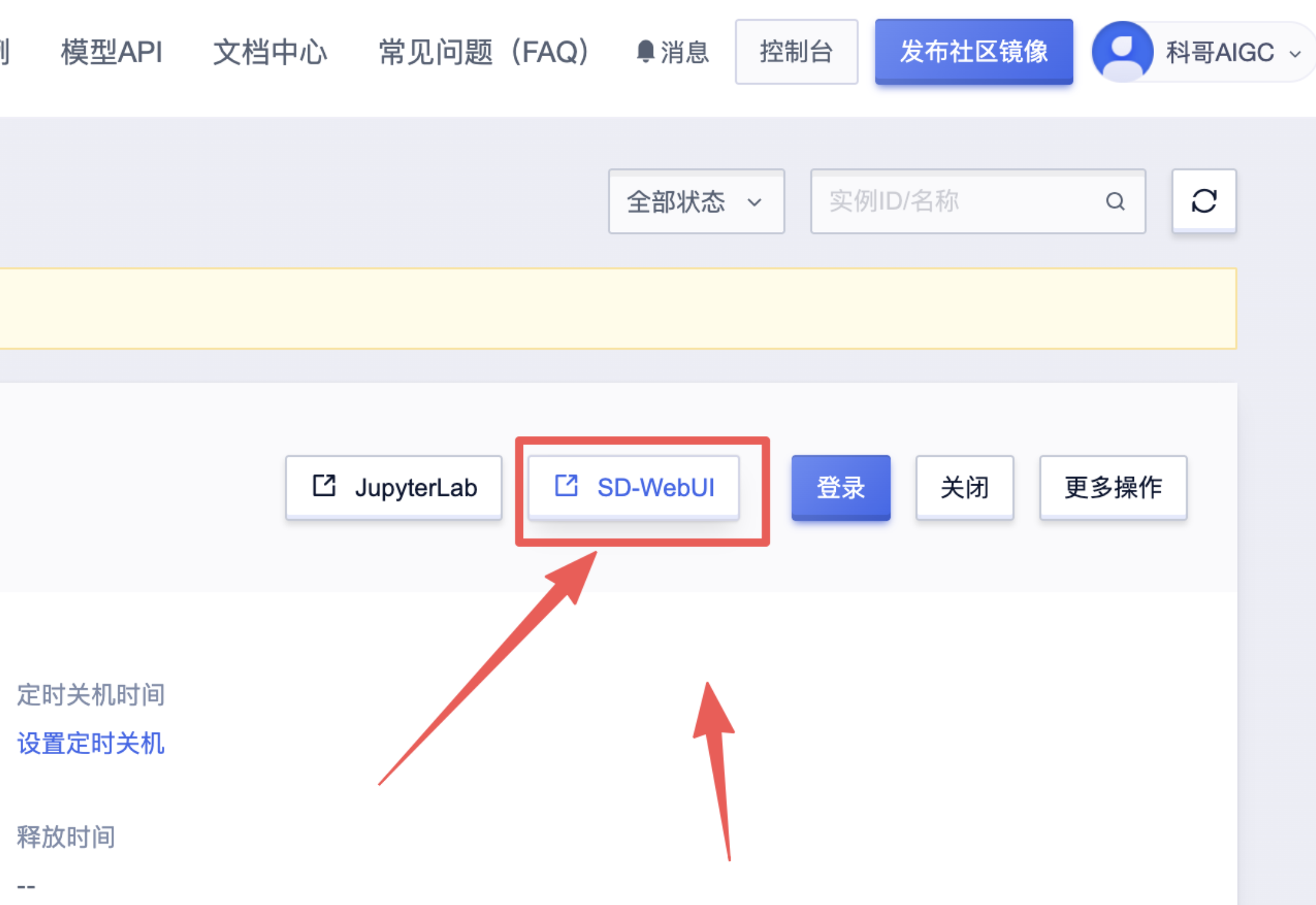
6、返回控制面板打开“SD-WebUI”
- AI数字人直播卖货欢迎来了解: https://kege-aigc.feishu.cn/docx/G271dgZr1o8CvMx9KKrcRuuonDf
以上都是镜像运行打开操作的一般步骤
有其他使用报错问题加群咨询
更多高级指令,可以进入jupyterlab,自行操作,例如:
- 查看进程:
ps -ef |grep python
- 终止进程:
kill -9 pid
- 重启程序:
cd /root && bash run.sh
运行使用界面截图
GLM-ASR 用户使用手册
📖 目录
🚀 快速开始
启动 WebUI
./start_app.sh
启动成功后,在浏览器中访问:
http://localhost:7860
停止服务
按 Ctrl+C 或运行:
# 方式 1:使用端口
lsof -ti:7860 | xargs kill
# 方式 2:使用进程名
pkill -f "python.*webui/app.py"
🎨 WebUI 使用指南
界面概览
WebUI 包含 3 个主要功能 Tab:
- 🎵 单文件转录:转录单个音频文件
- 📁 批量转录:批量处理多个音频文件
- 📜 历史记录:查看和管理转录历史
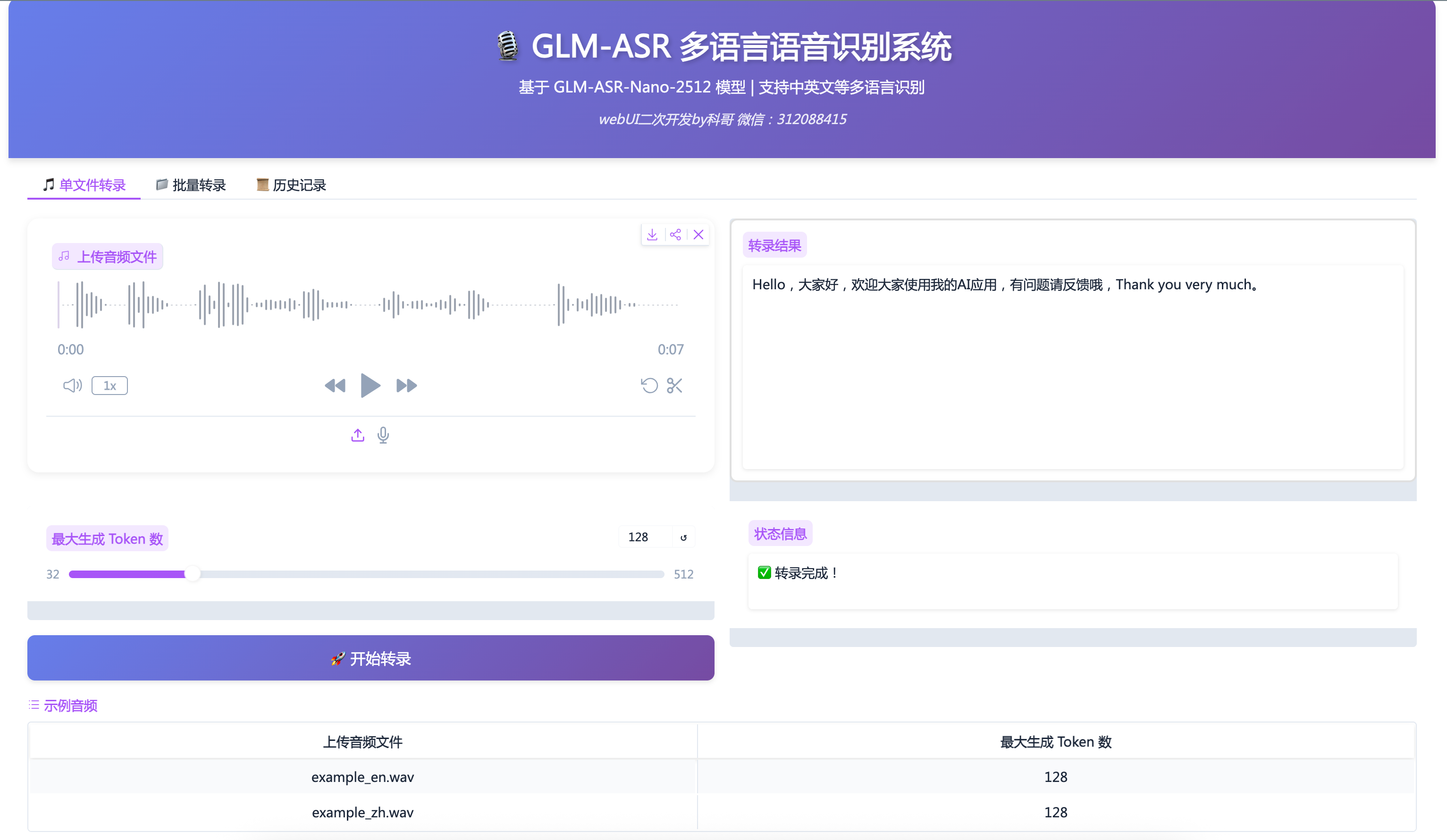
Tab 1: 单文件转录
功能说明
将单个音频文件转换为文字。
使用步骤
-
上传音频文件
- 点击"上传音频文件"区域
- 选择音频文件(支持 WAV、MP3、FLAC 等格式)
- 或直接拖拽文件到上传区域
-
设置参数(可选)
- 最大生成 Token 数:控制输出长度
- 默认值:128
- 范围:32-512
- 建议:短音频用 128,长音频用 256-512
- 最大生成 Token 数:控制输出长度
-
开始转录
- 点击"🚀 开始转录"按钮
- 等待处理(GPU 模式约 2-5 秒)
- 转录结果会显示在右侧文本框
-
查看结果
- 转录结果自动显示
- 状态信息显示处理进度
- 结果自动保存到历史记录
示例音频
界面底部提供了示例音频:
example_en.wav:英文示例example_zh.wav:中文示例
点击示例可快速测试功能。
注意事项
- ✅ 支持格式:WAV、MP3、FLAC、M4A 等
- ✅ 音频长度:建议 < 5 分钟
- ✅ 采样率:自动重采样到 16kHz
- ✅ 声道:自动转换为单声道
- ⚠️ 超过 30 秒的音频会自动分块处理
Tab 2: 批量转录
功能说明
一次性处理多个音频文件,提高工作效率。
使用步骤
-
上传多个文件
- 点击"上传多个音频文件"区域
- 按住
Ctrl(Windows/Linux)或Cmd(Mac)选择多个文件 - 或直接拖拽多个文件到上传区域
-
设置参数(可选)
- 最大生成 Token 数:同单文件转录
- 建议使用默认值 128
-
批量转录
- 点击"🚀 批量转录"按钮
- 进度条显示处理进度
- 等待所有文件处理完成
-
查看结果
- 结果以表格形式显示:
- 文件名:音频文件名称
- 状态:✅ 成功 / ❌ 失败
- 转录结果:文字内容或错误信息
- 状态信息显示成功/失败统计
- 结果以表格形式显示:
处理逻辑
- 串行处理:文件按顺序逐个处理(GPU 是瓶颈)
- 失败重试:失败的文件会显示错误信息
- 自动保存:成功的结果自动保存到历史记录
性能参考
| 文件数量 | GPU 模式 | CPU 模式 |
|---|---|---|
| 10 个文件 | 约 30 秒 | 约 5 分钟 |
| 50 个文件 | 约 2.5 分钟 | 约 25 分钟 |
| 100 个文件 | 约 5 分钟 | 约 50 分钟 |
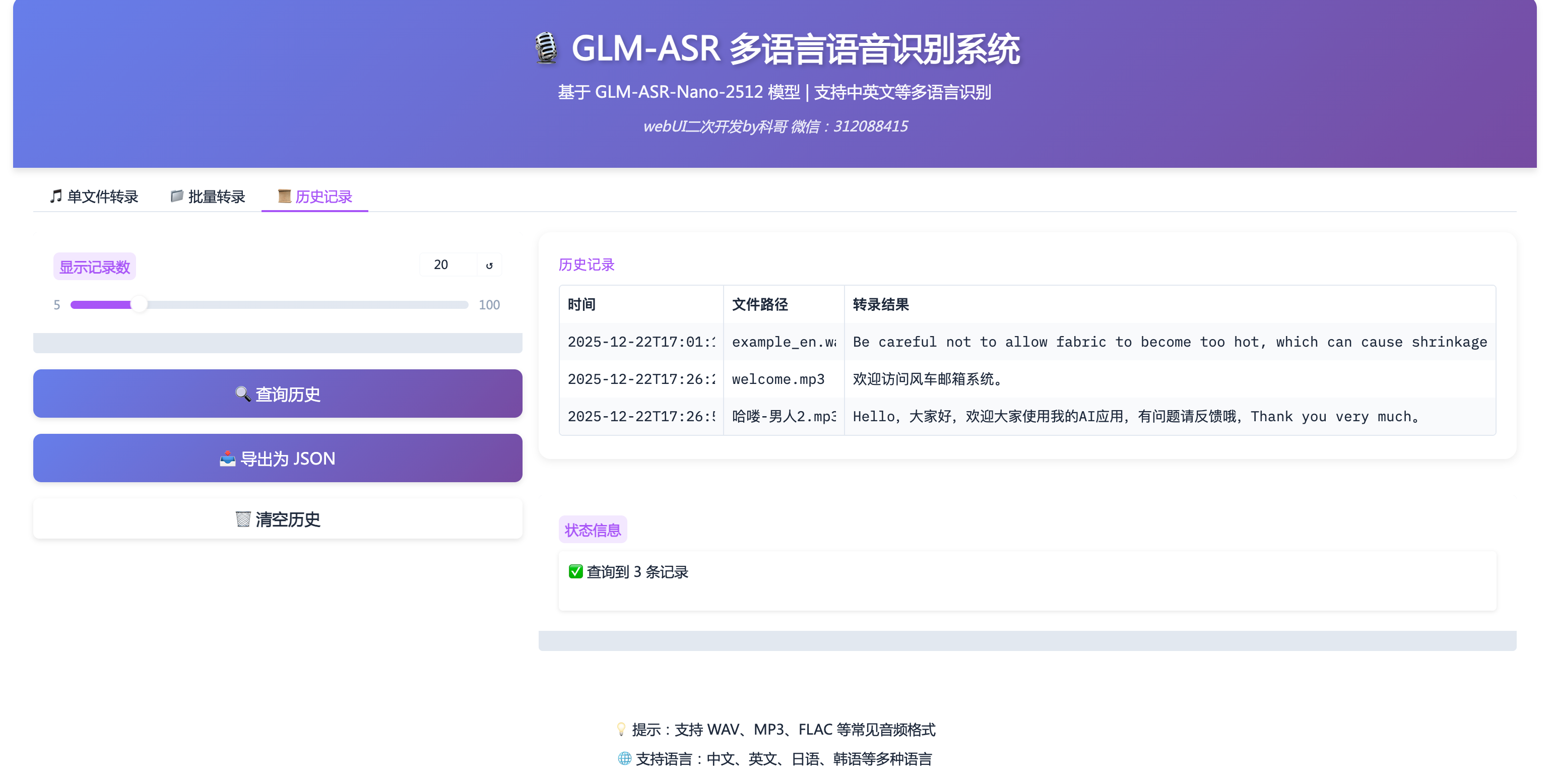
Tab 3: 历史记录
功能说明
查看、导出和管理所有转录历史记录。
使用步骤
1. 查询历史记录
-
设置显示数量
- 拖动"显示记录数"滑块
- 范围:5-100 条
- 默认:20 条
-
点击查询
- 点击"🔍 查询历史"按钮
- 结果以表格形式显示:
- 时间:转录时间(精确到秒)
- 文件路径:音频文件名
- 转录结果:文字内容(前 100 字符)
2. 导出历史记录
-
点击导出按钮
- 点击"📥 导出为 JSON"按钮
- 文件自动保存到
.history/export.json
-
导出格式
[ { "timestamp": "2025-12-22T17:00:00", "audio_path": "/path/to/audio.wav", "transcript": "转录文字内容", "duration": null, "metadata": {} } ] -
使用导出文件
- 可用于数据分析
- 可导入到其他系统
- 可作为备份
3. 清空历史记录
-
点击清空按钮
- 点击"🗑️ 清空历史"按钮
- 注意:此操作不可恢复!
-
确认清空
- 系统会显示"历史记录已清空"
- 所有历史记录将被永久删除
历史记录存储
- 存储位置:
.history/transcriptions.jsonl - 格式:JSONL(每行一个 JSON)
- 优点:
- 追加写入,性能高
- 无需加载整个文件
- 易于备份和迁移
💻 CLI 命令行使用
基础语法
python cli.py [全局参数] <子命令> [子命令参数]
全局参数
| 参数 | 说明 | 默认值 |
|---|---|---|
--checkpoint_dir | 模型目录 | models/GLM-ASR-Nano-2512 |
--tokenizer_path | Tokenizer 目录 | 同模型目录 |
--device | 设备(cuda/cpu) | 自动检测 |
--max_new_tokens | 最大生成 Token 数 | 128 |
子命令 1: transcribe(单文件转录)
语法
python cli.py [全局参数] transcribe <音频文件> [选项]
参数
<音频文件>:必需,音频文件路径--no-history:可选,不保存历史记录
示例
# 基础用法
python cli.py transcribe examples/example_en.wav
# 使用 CPU
python cli.py --device cpu transcribe examples/example_en.wav
# 不保存历史
python cli.py transcribe examples/example_en.wav --no-history
# 自定义 Token 数
python cli.py --max_new_tokens 256 transcribe examples/example_zh.wav
输出示例
----------
Be careful not to allow fabric to become too hot, which can cause shrinkage or in extreme cases, scorch.
子命令 2: batch(批量转录)
语法
python cli.py [全局参数] batch <音频文件1> <音频文件2> ...
参数
<音频文件>:必需,一个或多个音频文件路径- 支持通配符:
examples/*.wav
示例
# 批量转录多个文件
python cli.py batch examples/example_en.wav examples/example_zh.wav
# 使用通配符
python cli.py batch examples/*.wav
# 递归搜索
python cli.py batch "**/*.wav"
输出示例
找到 2 个音频文件
Transcribing: 100%|████████████| 2/2 [00:10<00:00, 5.00s/it]
✓ examples/example_en.wav
✓ examples/example_zh.wav
完成:2/2 成功
子命令 3: history(历史记录)
语法
python cli.py history [选项]
参数
--limit N:显示最近 N 条记录(默认 10)--audio PATH:按音频路径过滤--export FILE:导出到文件--format FORMAT:导出格式(json/csv)--clear:清空历史记录
示例
# 查询最近 10 条记录
python cli.py history
# 查询最近 20 条记录
python cli.py history --limit 20
# 按文件名过滤
python cli.py history --audio example_en.wav
# 导出为 JSON
python cli.py history --export history.json --format json
# 导出为 CSV
python cli.py history --export history.csv --format csv
# 清空历史记录
python cli.py history --clear
输出示例
时间:2025-12-22T17:00:00
文件:examples/example_en.wav
转录:Be careful not to allow fabric to become too hot...
时间:2025-12-22T17:01:00
文件:examples/example_zh.wav
转录:请注意不要让织物过热...
❓ 常见问题
1. 转录速度慢
问题:转录一个音频需要很长时间
原因:
- 使用 CPU 模式
- 音频文件过大
- 系统资源不足
解决方案:
# 1. 确认使用 GPU
python -c "import torch; print(f'CUDA: {torch.cuda.is_available()}')"
# 2. 检查 GPU 状态
nvidia-smi
# 3. 使用 GPU 模式
python cli.py --device cuda transcribe audio.wav
2. 音频加载失败
问题:Couldn't find appropriate backend to handle uri
原因:缺少音频后端
解决方案:
# 安装 soundfile
pip install soundfile
# 验证
python -c "import torchaudio; print(torchaudio.list_audio_backends())"
3. CUDA 不可用
问题:Torch not compiled with CUDA enabled
原因:安装了 CPU 版本的 torch
解决方案:
# 卸载 CPU 版本
pip uninstall -y torch torchaudio
# 安装 CUDA 版本
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu124
# 验证
python -c "import torch; print(f'CUDA: {torch.cuda.is_available()}')"
4. 端口被占用
问题:Address already in use
原因:端口 7860 被其他程序占用
解决方案:
# 方式 1:使用启动脚本(自动处理)
./start_app.sh
# 方式 2:手动终止占用进程
lsof -ti:7860 | xargs kill
5. 转录结果不准确
问题:转录的文字与音频内容不符
可能原因:
- 音频质量差(噪音大、音量小)
- 语言不匹配(模型主要支持中英文)
- 音频过长(超过 5 分钟)
建议:
- 使用清晰的音频
- 确认音频语言
- 将长音频分段处理
- 增加
--max_new_tokens参数
6. 历史记录丢失
问题:查询不到之前的转录记录
原因:
- 历史记录文件被删除
- 使用了
--no-history参数
解决方案:
- 检查
.history/transcriptions.jsonl是否存在 - 确保转录时没有使用
--no-history - 定期备份历史记录文件
🎯 使用技巧
1. 提高转录质量
- ✅ 使用高质量音频(采样率 ≥ 16kHz)
- ✅ 减少背景噪音
- ✅ 确保音量适中
- ✅ 使用单声道音频
- ✅ 音频长度控制在 5 分钟内
2. 提高处理速度
- ✅ 使用 GPU 模式
- ✅ 批量处理多个文件
- ✅ 减少
max_new_tokens参数 - ✅ 关闭不必要的后台程序
3. 管理历史记录
- ✅ 定期导出历史记录
- ✅ 备份
.history/目录 - ✅ 使用
--audio参数过滤查询 - ✅ 定期清理旧记录
4. 批量处理优化
- ✅ 使用通配符批量选择文件
- ✅ 按文件大小排序处理
- ✅ 失败的文件单独重试
- ✅ 使用脚本自动化处理
📊 性能参考
GPU vs CPU
| 模式 | 单文件 | 10 文件 | 100 文件 |
|---|---|---|---|
| GPU (RTX 3090) | 2-5 秒 | 30 秒 | 5 分钟 |
| CPU (8 核) | 30-60 秒 | 5 分钟 | 50 分钟 |
音频长度影响
| 音频长度 | GPU 时间 | CPU 时间 |
|---|---|---|
| 10 秒 | 2 秒 | 20 秒 |
| 30 秒 | 3 秒 | 40 秒 |
| 1 分钟 | 4 秒 | 60 秒 |
| 5 分钟 | 10 秒 | 5 分钟 |
📞 技术支持
联系方式
webUI二次开发by科哥 微信:312088415
问题反馈
如遇到问题,请提供:
- 错误信息截图
- 音频文件信息(格式、大小、时长)
- 系统环境(GPU 型号、CUDA 版本)
- 使用的命令或操作步骤
更新日志
查看 todo.md 了解最新的功能更新和问题修复。
最后更新:2025-12-22 版本:v1.0.0
bug反馈可以加入科哥专属群交流➕ 广告勿进!

有bug请微信科哥或加群: 312088415
科哥在UCloud镜像列表【不断更新中】:
@鸡你太美 认证作者
认证作者
认证作者
镜像信息
已使用8 次
运行时长
1 H
 支持自启动
支持自启动镜像大小
40GB
最后更新时间
2026-04-27
支持卡型
3090RTX40系48G RTX40系2080Ti3080Ti2080A800H20P40A100V100SV100S
+12
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
版本
v1.1
2026-04-27