 67
67SVC-WebUI 一键训练镜像
在线一键训练 AI翻唱SVC模型,支持多种显卡型号部署,支持上传压缩文件,支持无人值守自动依次训练主模型、扩散模型、聚类模型,支持训练完成发送通知提醒,支持网页端一键打包训练好的模型,无需多余的命令行和文件移动,由网页端自动处理,支持网页端一键清空训练环境,追求的就是超高效率 。
镜像信息
- 基于bilibili@羽毛布団大佬
SVC 4.1-Stable v2.3.18 整合包搭建 - 本镜像由:AiMusicLab@乔大峰 搭建并且完全免费
- 本地客户端已支持RTX50系显卡:了解详情
- 如果觉得镜像好用,欢迎关注我的公众号,镜像问题亦可联系我本人,谢谢大家@_@
微信:n a s a j j

公众号:乔大峰

在线训练如需要使用RTX50显卡请选择3.0以前的镜像版本
v3.0之后的不支持使用RTX50在线训练但可支持更多显卡
v3.0更新说明
- 支持更多显卡
- 一些细节优化
支持的功能
- 无需复制ip地址,直接点击公网ip链接访问WebUI
- 框架改为pytorch2.5.1+cu118支持更多显卡
- RTX20-RTX40显卡都测试过均能完美运行
- 支持训练完成自动发送提醒
- 推理界面底部支持一键打包选中的训练好的模型
- 支持导入zip压缩包直接分片,并自动输出到训练目录
- 支持分片时自动对文件进行降噪
- 修复识别数据集时的响度统一
- 修复网页端推理单个文件时接口超时的问题
- 支持网页端批量推理(将文件放置在指定目录即可)
- 除训练素材上传外,其他功能均已在网页端实现
- 网页增加停止训练主模型和扩散模型按钮,不需要按
ctrl+c结束 - 训练过程中自动保存模型的文件名在训练步数后面增加了
reference_loss参数可供参考(如G_12000_32_02.pth表示训练步数12000步时,reference_loss为32.02) - 模型联动选择,模型和配置文件只需要同样编号开头(如1.xxx.pt),即可一键选择
- 网页上新增“清空训练环境”功能,一键清理所有训练相关数据
- 标题显示当前主机的IP地址,方便区分
- 支持一键依次训练主模型、扩散模型、聚类模型
- 一键训练完成自动发送提醒到钉钉群,管理多台主机不再手忙脚乱

视频教程
图文教程
如何部署这个镜像
1.点击直达镜像链接:一键部署:SVC-WebUI
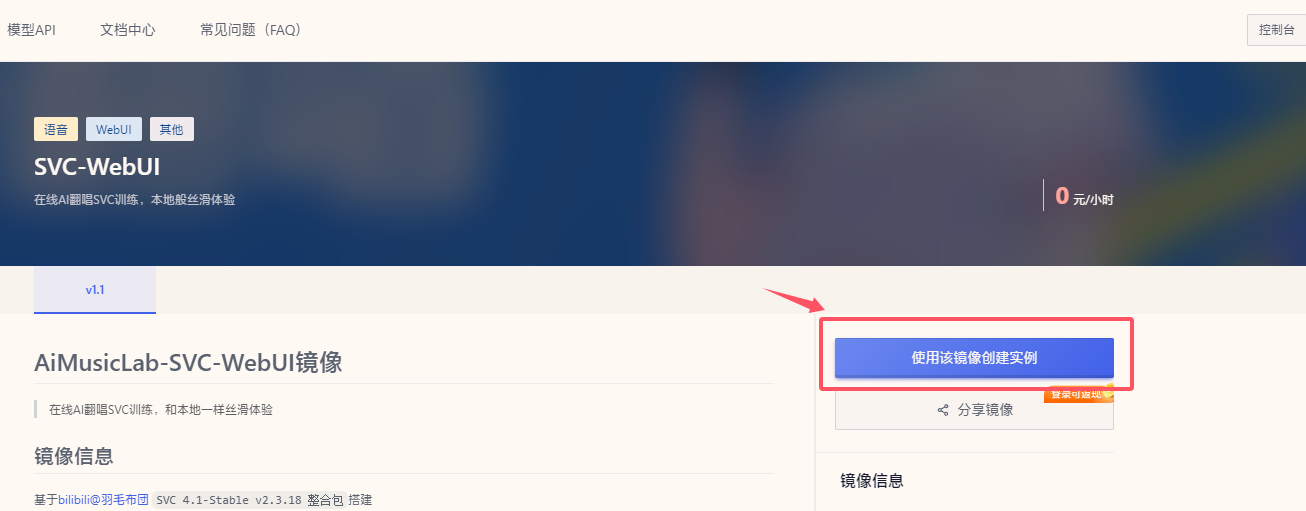
2.在此页面右侧点击使用该镜像创建实例
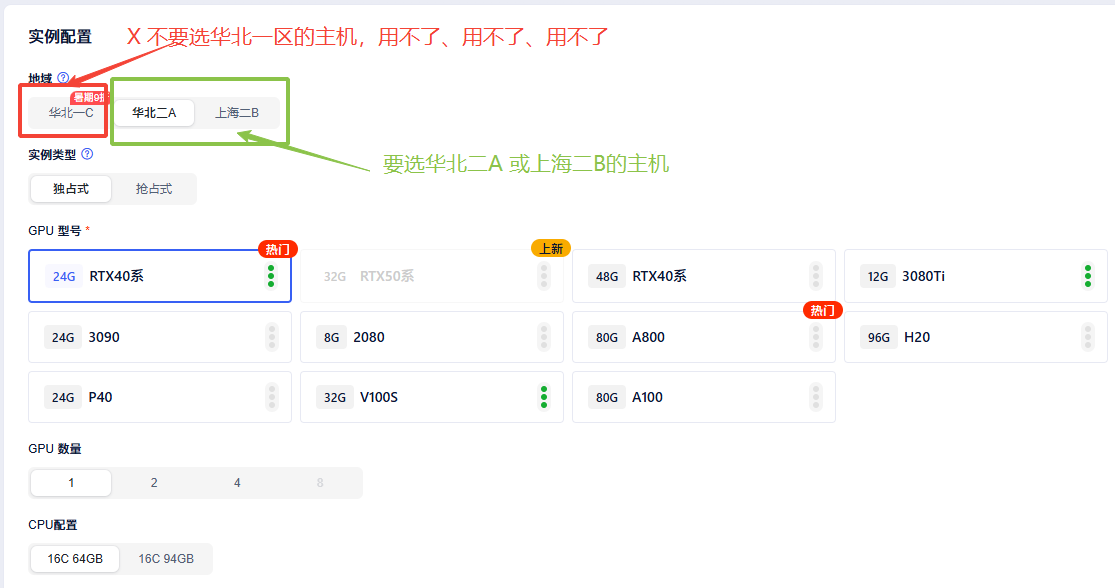
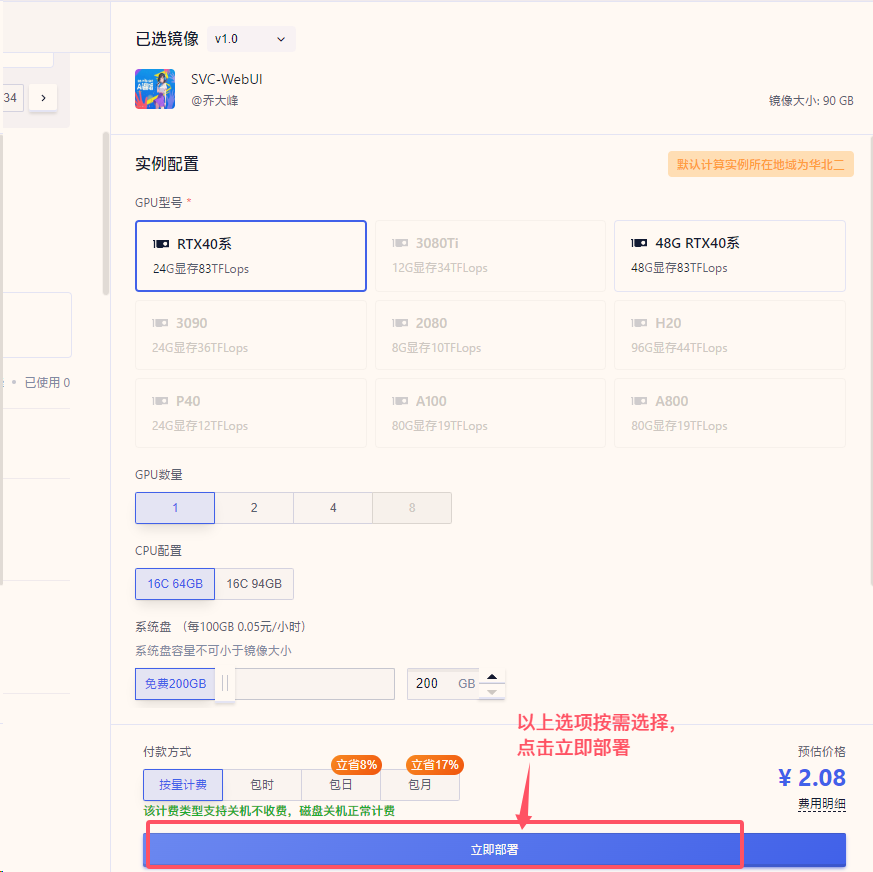
3.在新页面选择配置以及付费方式后,点击立即部署
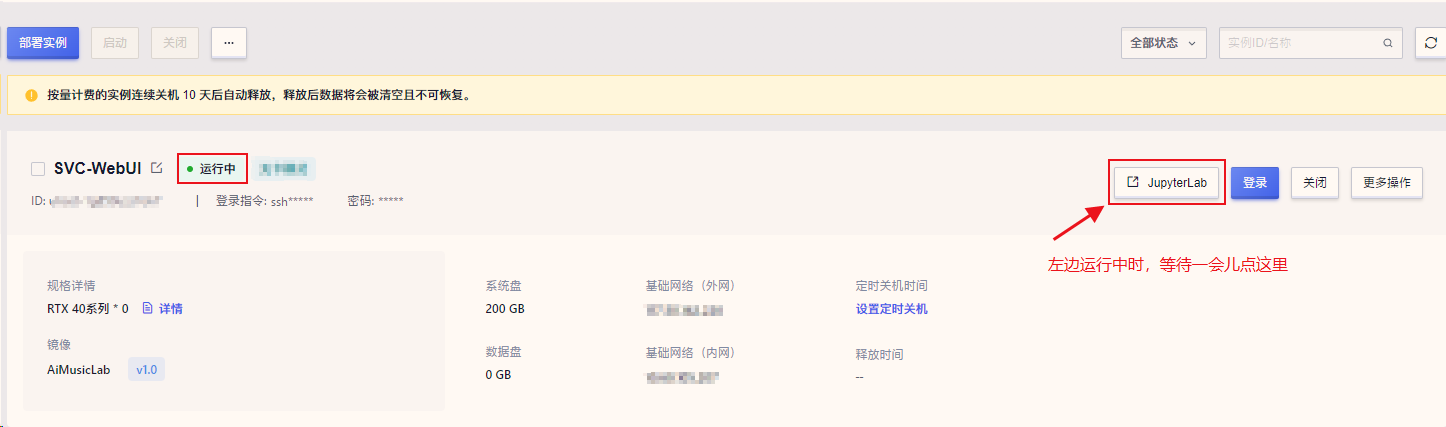
4.开机后,等待左侧显示运行中。再等待1分钟左右,再点击JupyterLab按钮进入后台如下图,如果超过5分钟没显示运行中,点旁边的重启,重新等待。
1. 运行 WebUI(必须) 和 TensorBoard(可选,非必须)
温馨提示:WebUI打开后,不要开网页翻译,大部分问题都是翻译导致的
如何关闭网页翻译?-->页面翻译选项选择:更多 - 一律不翻译此网站
-
运行 WebUI: 点击快速开始.ipynb标签,点击选中
启动webui的代码框,前面会出现一条蓝色方块(🟦),在窗口上面的工具栏,有一个像“播放”符号(▶)的按钮,点它!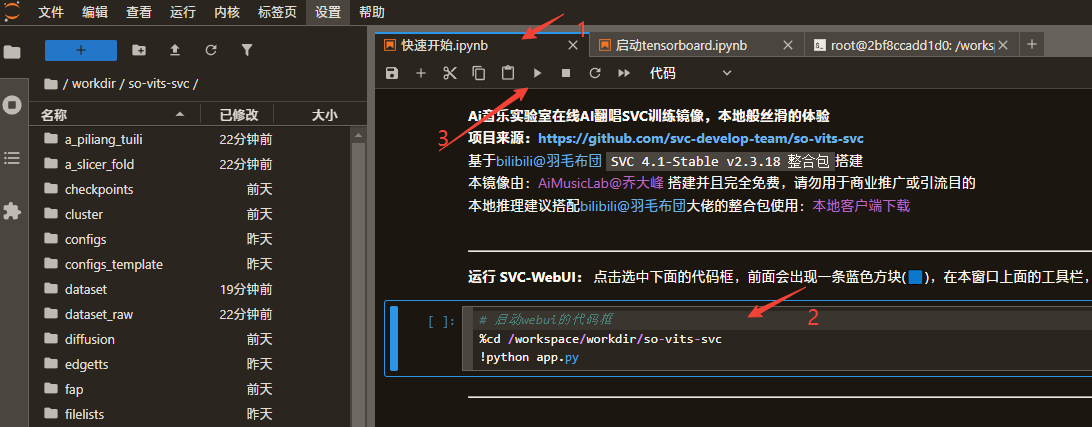
等待片刻
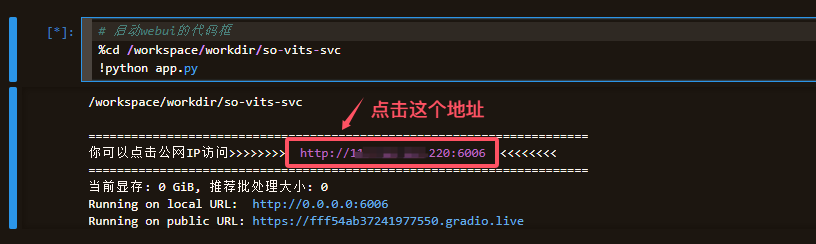
控制台会输出一个公网IP链接,点击即可访问WebUI界面。
- 运行 TensorBoard (可选,用于查看训练曲线):
点击启动ensorBoard.ipynb标签,点击选中
启动tensorboard的代码框,前面会出现一条蓝色方块(🟦),在窗口上面的工具栏,有一个像“播放”符号(▶)的按钮,点它!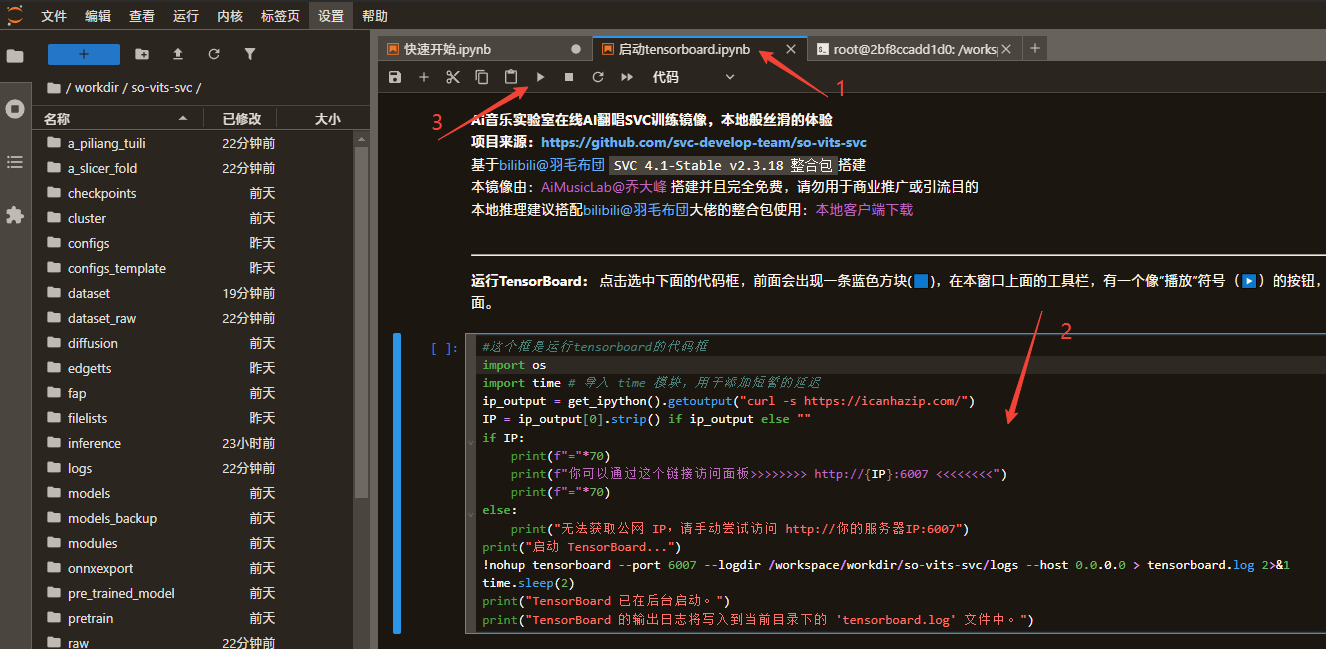 等待片刻
等待片刻 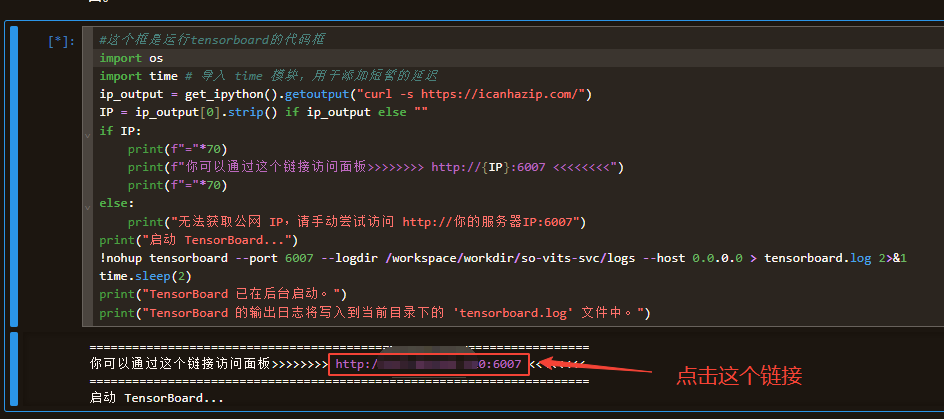 控制台会输出一个公网IP链接,点击即可访问TensorBoard界面。
控制台会输出一个公网IP链接,点击即可访问TensorBoard界面。
2. 导入训练素材
(训练素材需要是30分钟以上的唱歌音频,可以是多个文件,包含高中低音各声线,安静环境录制不要加混响)录音建议
如果遇到网页端导入较慢,我们针对性制作了一款上传工具SFTP文件上传工具
根据您的素材类型,选择以下导入方法:
训练素材种类a:如果你有没有切片的原唱干声(录制的原始音频):
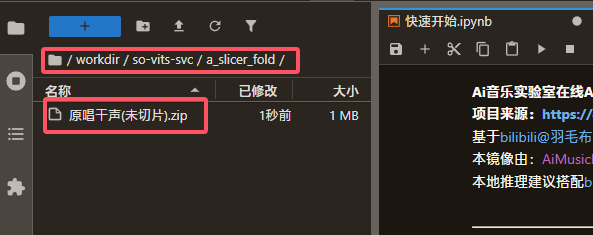
a.1. 上传原始音频: 将您的原始音频文件(例如歌曲干声、录音等)上传到以下目录:
/workspace/workdir/so-vits-svc/a_slicer_fold/
您可以直接拖动音频文件上传到这个目录,也可以上传一个 .zip 格式的压缩包。
a.2. 切片方法:
- 运行WebUI。
- 在 WebUI 界面中,切换到
小工具/实验室特性标签页。 - 点击
智能音频切片子标签。 - 在
原始音频文件夹输入框中,确保路径为/workspace/workdir/so-vits-svc/a_slicer_fold/(通常保持默认)。 - 点击
加载原始音频按钮。系统会识别a_slicer_fold/中的文件,并自动为您建议一个输出目录(例如dataset_raw/speaker0) 。 - 配置降噪: 如果需要修改降噪选项,可以展开
人声降噪设置。 修改后需要点击应用降噪设置按钮 (主要按钮) 保存降噪配置。 (已经默认勾选)。 - 调整
切片的最长秒数和切片的最短秒数(推荐默认值 15 和 4)。 - 点击
开始切片按钮。 - 切片完成后,在
输出信息中会显示切片结果的统计信息。切片后的音频将自动保存到dataset_raw/speaker0/目录下。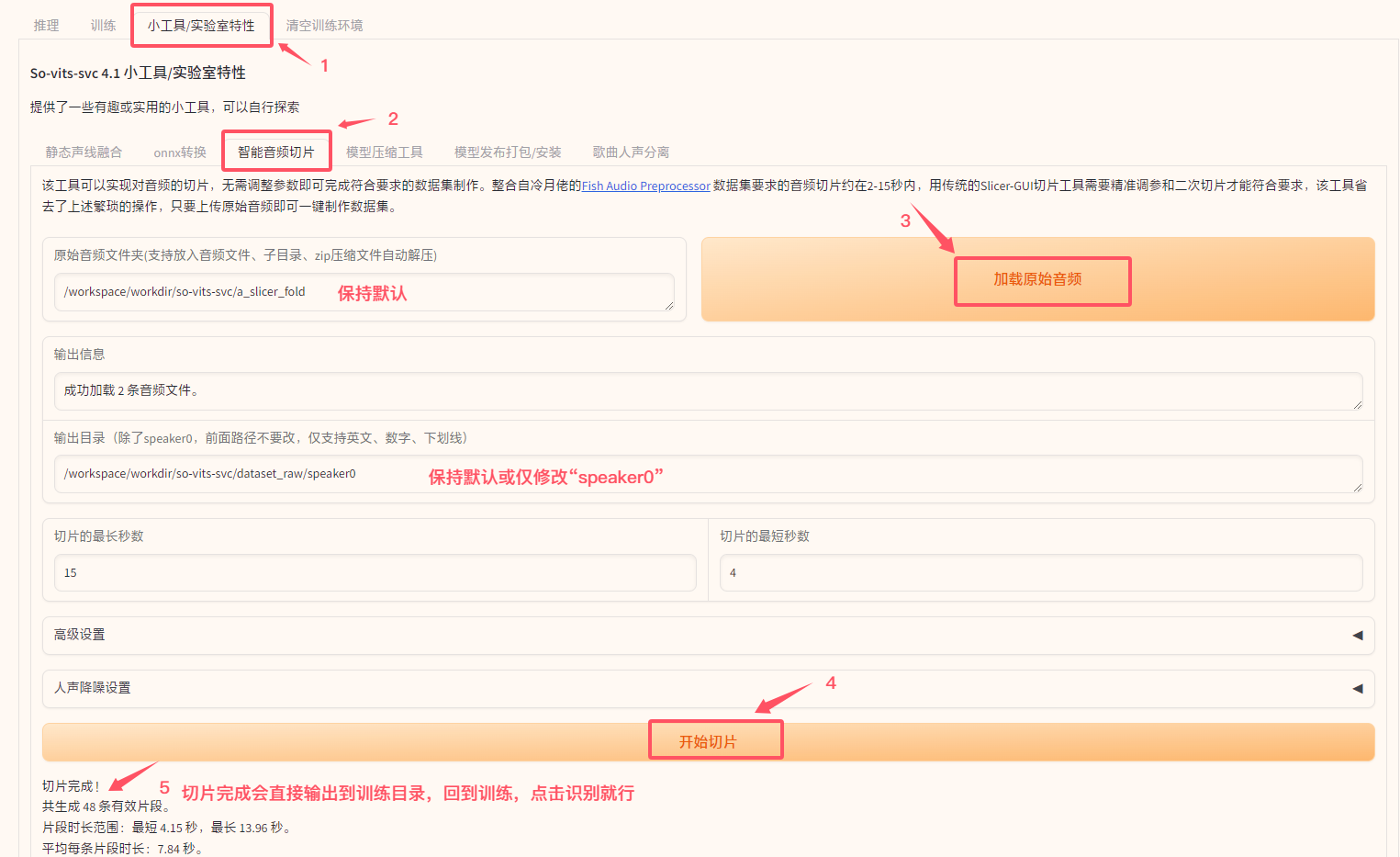
训练素材种类b: 如果你有已经切片的音频文件:
(已经切片的意思是你已经在本地客户端切成了5-15秒左右的片段。如果不熟悉切片流程,建议用上面的方式,即:直接上传录音文件,由系统切片)
b.1 如果切片素材是压缩文件 (.zip):
b.1.1. 上传压缩包: 将包含您已切片音频的 .zip 压缩包上传到以下目录:
/workspace/workdir/so-vits-svc/dataset_raw/
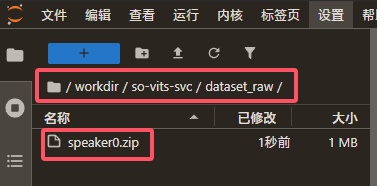
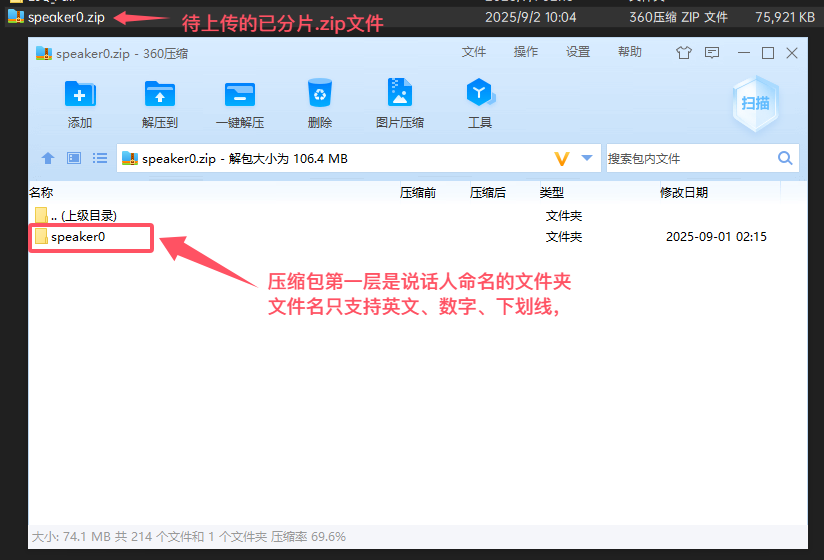
压缩包内部结构要求:
推荐: 压缩包内应该包含一个文件夹(例如 /speaker0/),speaker0 文件夹内是已经切片5-15秒左右的wav格式音频文件。
示例:
your_dataset.zip
├───speaker0/
│ ├───audio_001.wav
│ ├───audio_002.wav
│ └───...
b.2 如果素材是切好片的单个音频文件:
b.2.1. 上传文件:
在/workdir/so-vits-svc/dataset_raw/下面新建说话人目录,(例如 speaker0)
将您已切片音频上传到以下目录:
/workdir/so-vits-svc/dataset_raw/speaker0/
目录内部结构要求:
- 您的文件夹名称应只包含英文、数字、下划线。
- 文件夹内直接是
.wav音频文件。 - 示例:
dataset_raw/
└───speaker0/
├───audio_001.wav
├───audio_002.wav
└───...
3. 数据预处理与开始训练
1. 数据预处理:
- 在 WebUI 界面中,切换到
训练标签页。 - 点击识别数据集。
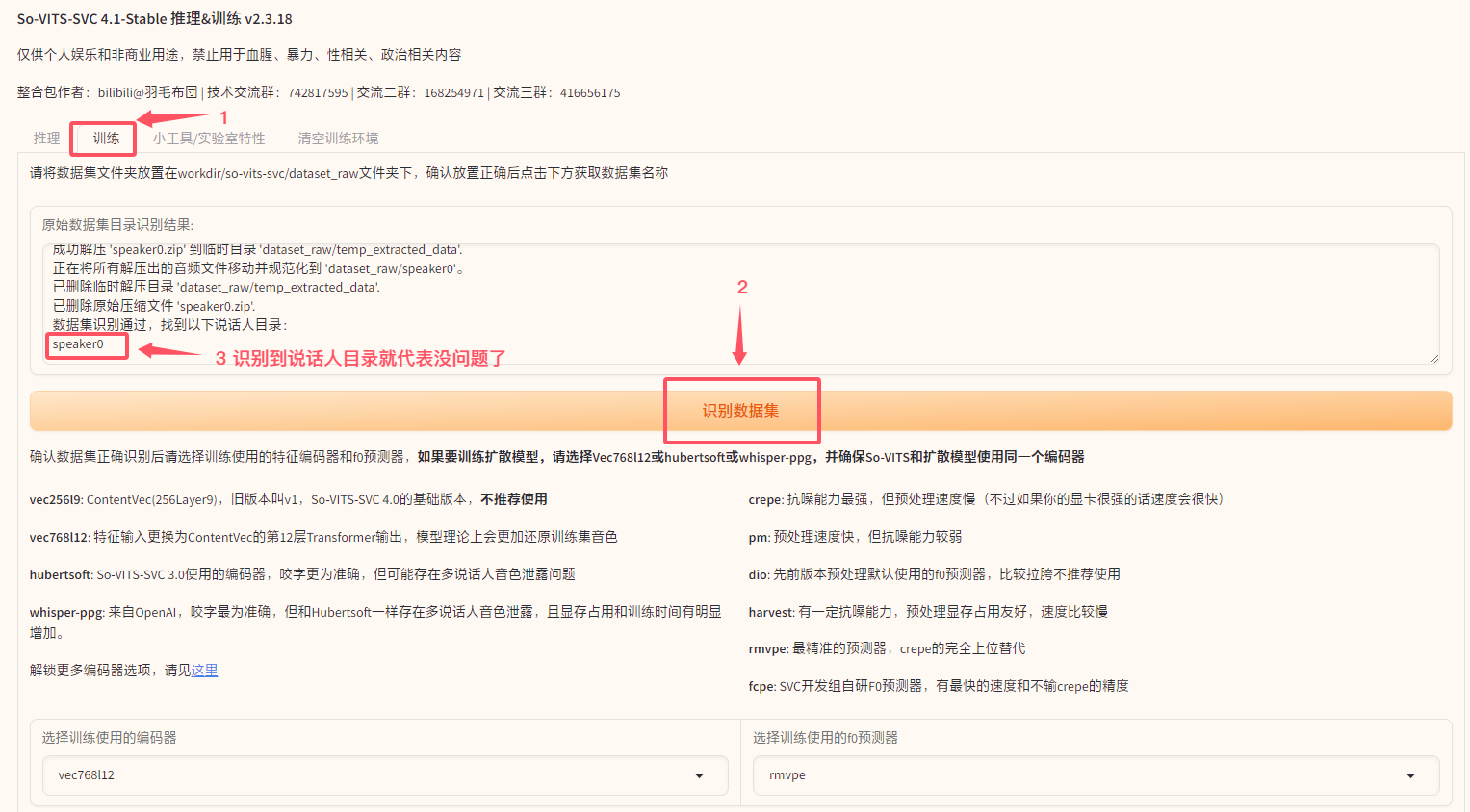
- 确认
原始数据集目录识别结果显示正确。 - 选择
选择训练使用的编码器和选择训练使用的f0预测器(一般情况下保持默认即可)。 - 根据需要勾选
是否使用浅扩散模型、是否启用响度嵌入和音量增强、是否启用TINY训练(一般情况下保持默认即可)。 - 点击
数据预处理按钮。 - 等待预处理完成,并检查
预处理输出信息是否有报错。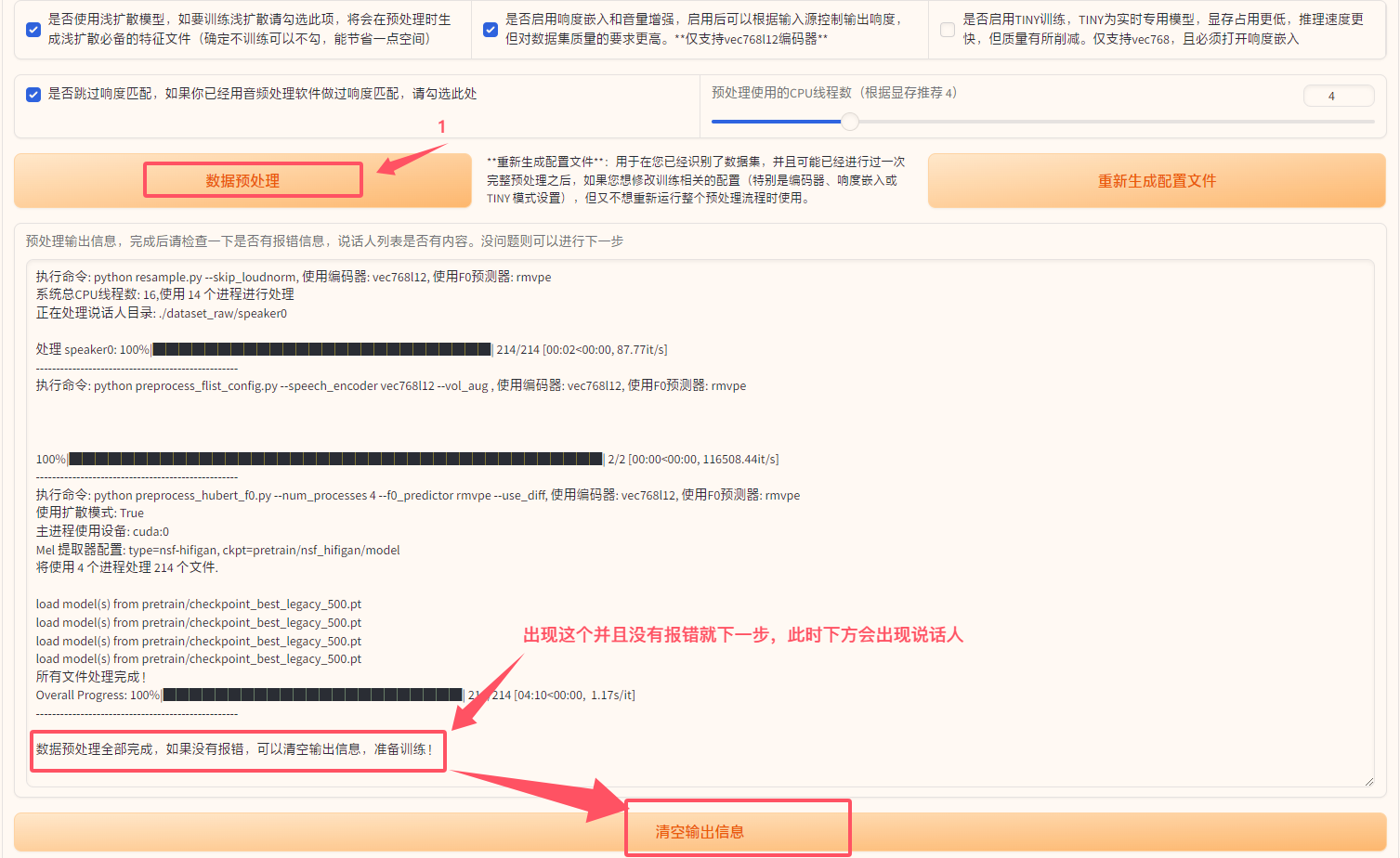
2. 写入配置文件:
- 在
训练标签页,检查并调整填写训练设置和超参数部分的参数(如无特殊需求,可以保持默认)。 - 如果需要训练扩散模型,展开
扩散模型配置并调整相关参数(如无特殊需求,可以保持默认)。 - 依次点击
将当前设置保存成默认设置和写入配置文件按钮。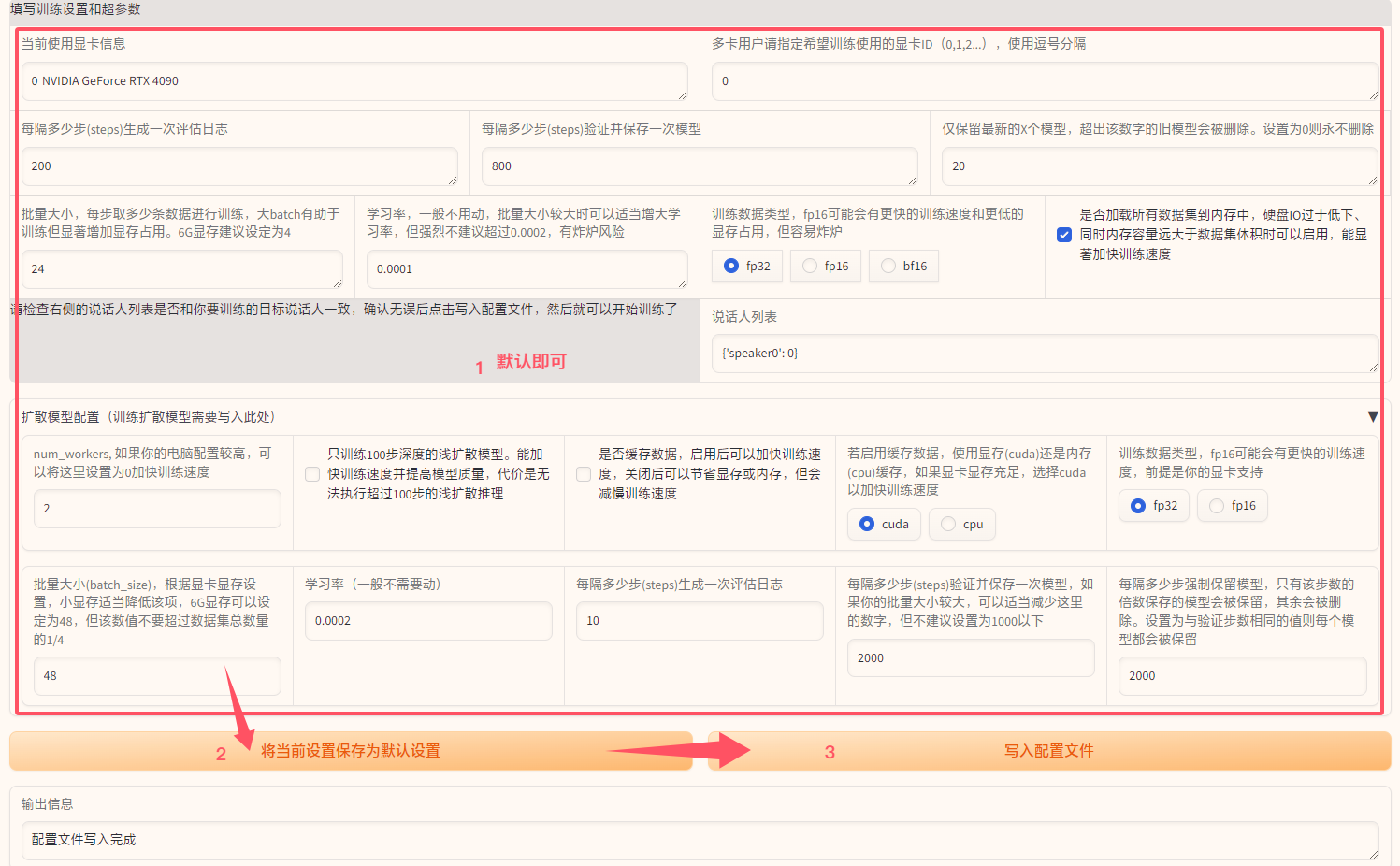
3. 开始训练:
3.1 方法一:一键训练(新增)(推荐!)
- 切换到页面最下面,展开:一键训练(自动化流程)
- 支持在后台一键依次训练主模型、扩散模型、聚类模型
- 修改
主模型目标步数、扩散模型目标步数 - 如果需要钉钉通知,填写
钉钉机器人 Access Token - 点击
开始一键训练即可自动依次训练 - 如不小心关机,开机后点一键训练可以接着上次进度训练

3.2 方法二:常规训练

- 点击
从头训练主模型按钮 或继续上一次的训练进度按钮,后台会开始训练主模型,可在快速开始.ipynb查看训练进度,如下图“step: 1400, reference_loss: 35.6618, lr: 9.827740075511432e-05”,代表1400步。训练步数要看数据集质量,推荐1万步以上。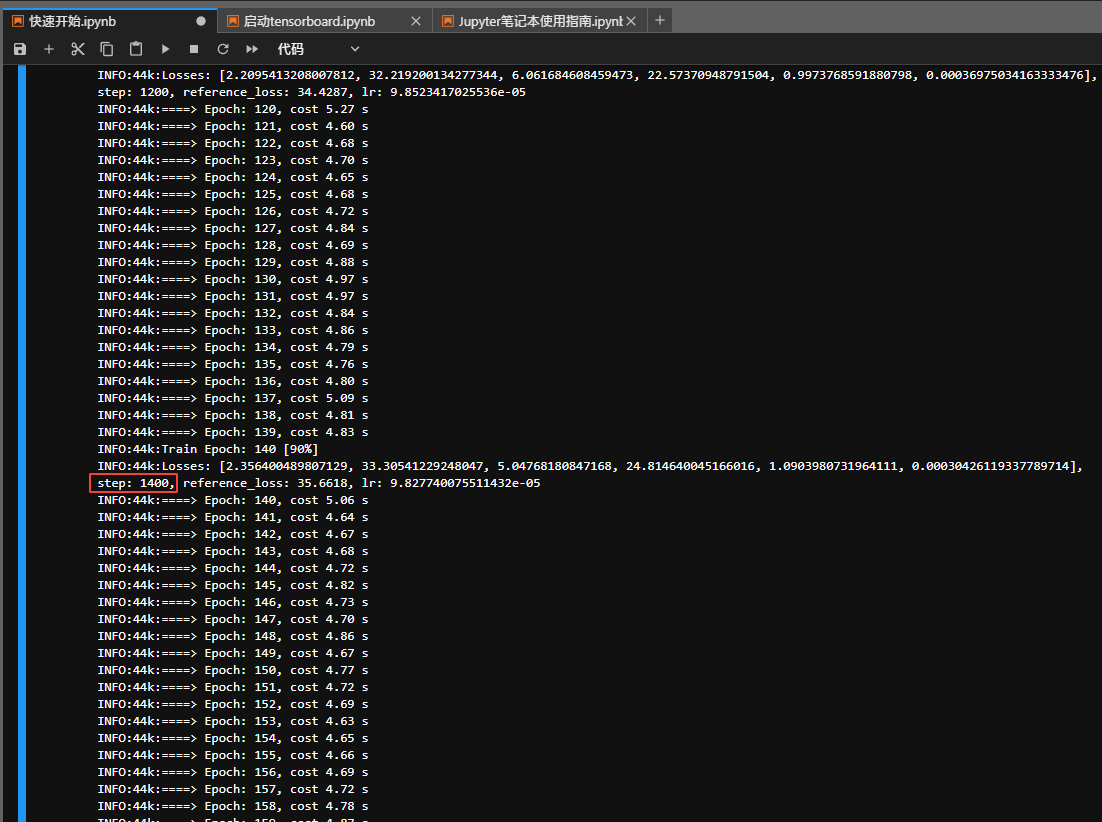
- 如果需要训练扩散模型,点击
从头训练扩散模型按钮或继续训练扩散模型按钮。 - 训练将在后台进行,您可以在运行的ipynb终端窗口查看训练日志,或通过 TensorBoard 监控训练进度。
4. 下载训练好的模型
您可以通过以下几种方式下载训练好的模型:
a. 网页端下载 (推荐!):
- 在 WebUI 界面中,切换到
推理标签页。 (先确保推理标签下当前模式:工作目录模式,将从'./logs/44k'读取模型文件,如不是,需要在页面底端切换模式) - 选择想要打包的模型(在下拉框中选择),可以不用加载模型。
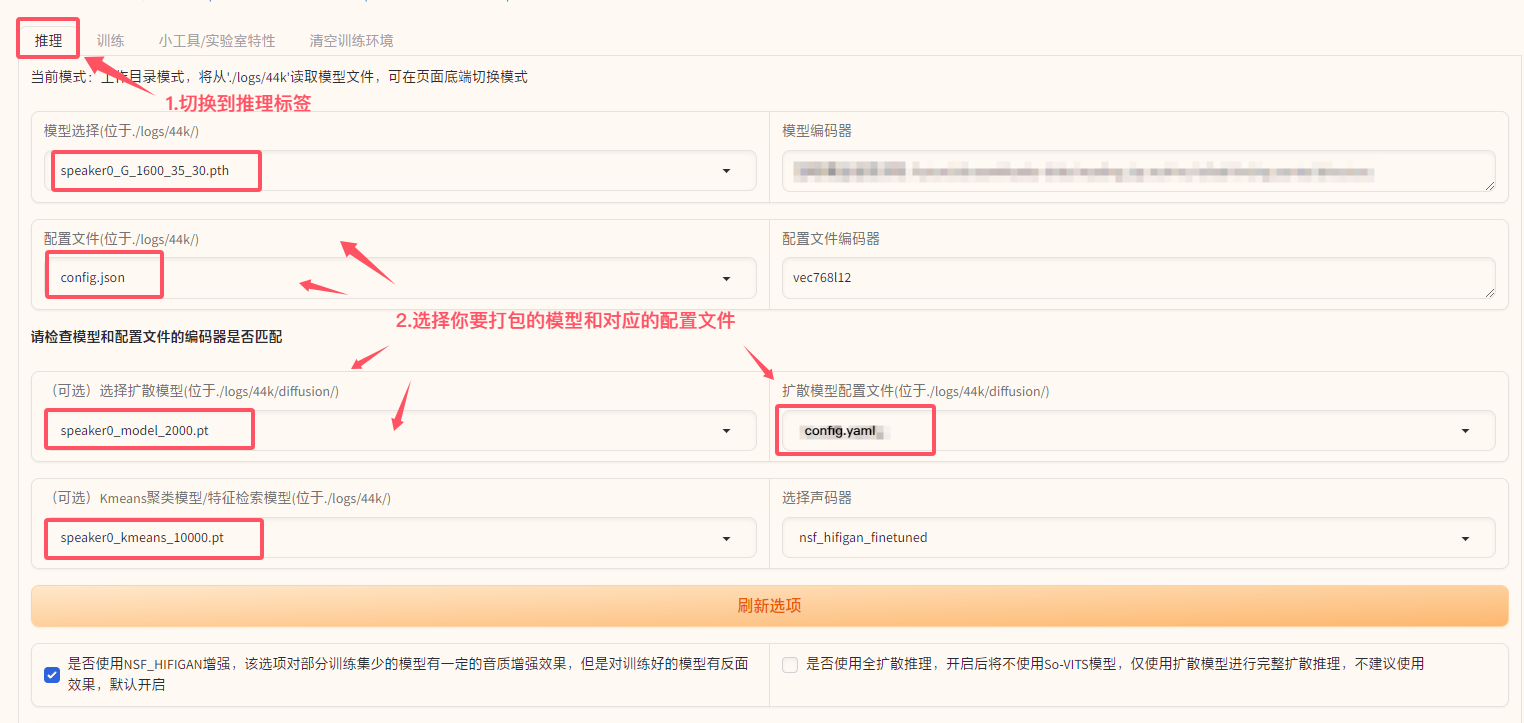
- 在页面底部找到
模型打包部分。 - 在
打包模型名称输入框中填写您希望的模型名称(例如1.speaker0)这里的命名是为了避免不同模型文件导入本地SVC客户端时,产生的模型文件重名。 - 点击
打包当前选择的模型按钮。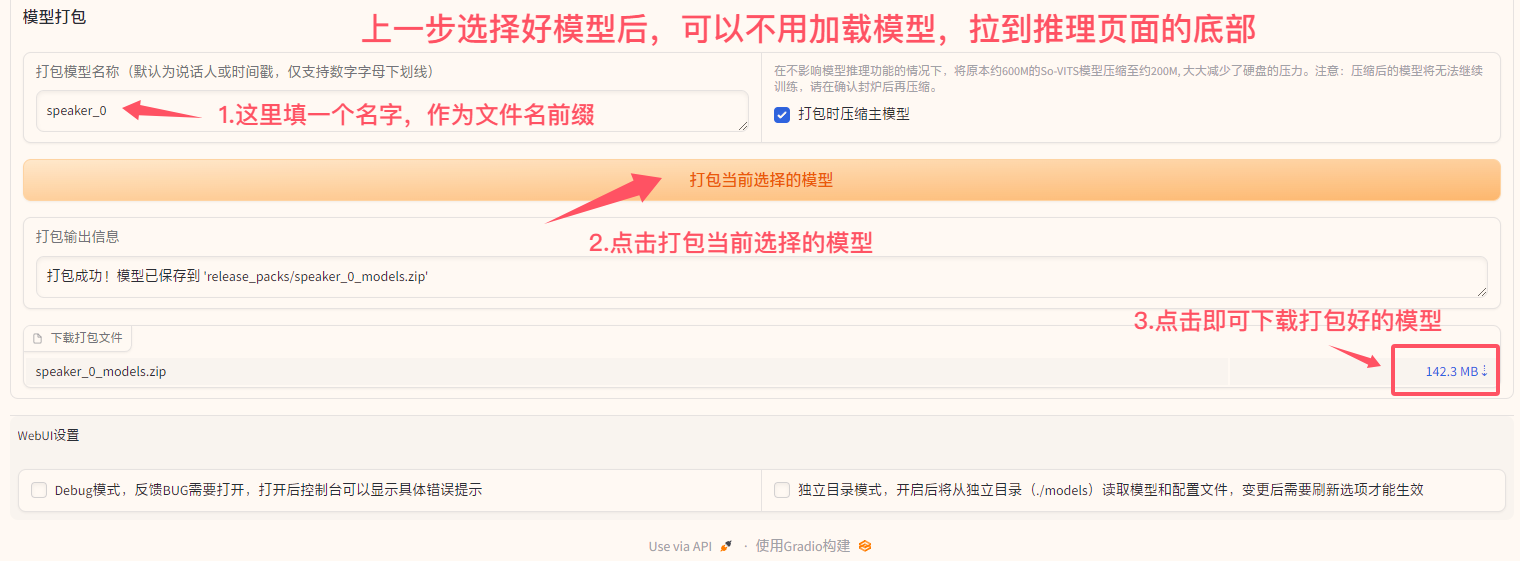
- 打包完成后,在
下载打包文件区域会出现一个可下载的.zip文件链接,点击即可下载。
b.直接在JupyterLab右侧文件管理窗口下载:
前往以下目录下载您的模型文件:
/workspace/workdir/so-vits-svc/logs/44k
在线训练模型目录结构:
/workspace/workdir/so-vits-svc/logs/44k/
├───diffusion/(扩散模型目录)
│ ├───model_步数.pt(扩散模型,在扩散模型目录)
│ ├───config.yaml(扩散模型配置文件,在扩散模型目录)
├───G_步数.loss参数.pth(G开头的主模型)
├───config.json(主模型配置文件)
└─── xxx_kmeans_10000.pt(聚类模型)
c. 使用 SFTP 工具下载 :
推荐使用客户端:winscp 或其他 SFTP 工具。
连接到您的镜像实例,然后前往以下目录下载您的模型文件:
/workspace/workdir/so-vits-svc/logs/44k
在线训练模型目录结构
/workspace/workdir/so-vits-svc/logs/44k/
├───diffusion/(扩散模型目录)
│ ├───model_步数.pt(扩散模型,在扩散模型目录)
│ ├───config.yaml(扩散模型配置文件,在扩散模型目录)
├───G_步数.loss参数.pth(G开头的主模型)
├───config.json(主模型配置文件)
└─── xxx_kmeans_10000.pt(聚类模型)
5.本地SVC客户端导入线上模型文件
本地客户端已支持RTX50系显卡:了解详情
方法一:小工具/实验室特性找到模型导入和导出(或者也叫模型发布与打包) 导入刚下载的模型压缩包
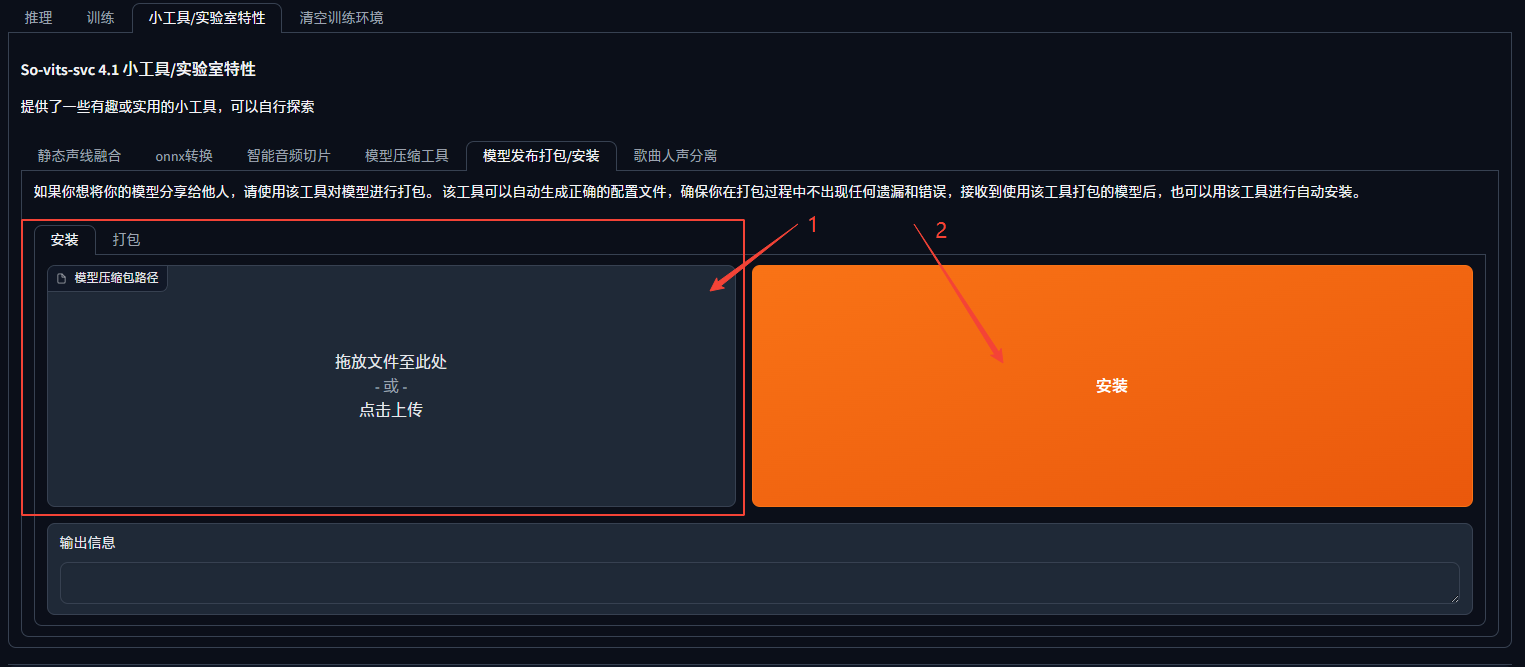
方法二:解压下载的模型文件压缩包,将models目录复制到本地svc的models目录 本地SVC客户端模型目录结构:
/so-vits-svc/models/
├───diffusion/(扩散模型目录)
│ ├───model_步数.pt(扩散模型,在扩散模型目录)
├───G_步数.loss参数.pth(主模型)
├───config.json(主模型配置文件)
├───xxx_kmeans_10000.pt(聚类模型)
└───config.yaml(扩散模型配置文件)
6. 清空线上训练环境,方便下次直接运行(可选)
警告:此操作将删除以下目录中的所有内容,请务必提前备份重要数据!
/workspace/workdir/so-vits-svc/logs/44k/(So-VITS模型和日志)/workspace/workdir/so-vits-svc/dataset_raw/(原始数据集)/workspace/workdir/so-vits-svc/dataset/(预处理后的数据集)/workspace/workdir/so-vits-svc/raw/(原始音频,如果存在)/workspace/workdir/so-vits-svc/results/(推理结果)/workspace/workdir/so-vits-svc/a_slicer_fold/(切片工具临时目录)/workspace/workdir/so-vits-svc/models_backup/(历史模型训练备份目录)/workspace/workdir/so-vits-svc/release_packs/(模型打包临时目录)- 所有
.ipynb_checkpoints目录
请在模型下载完成并检查无误后再执行此操作。
操作步骤: 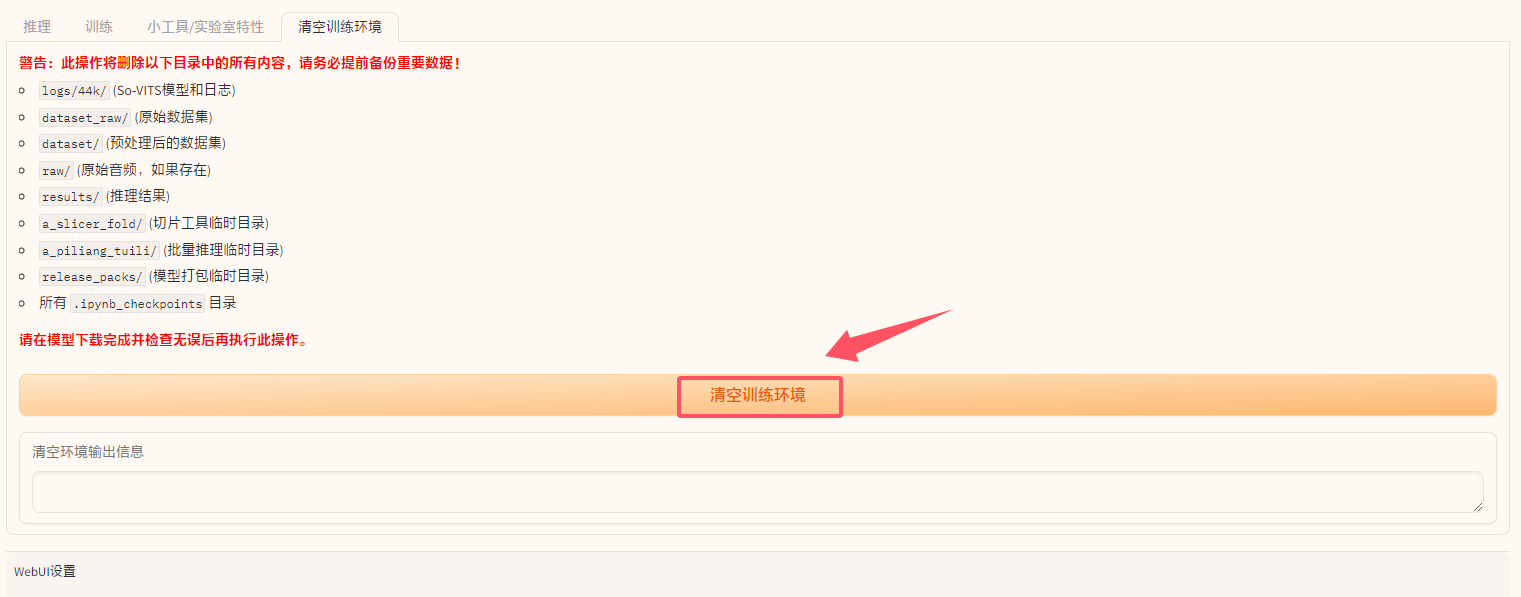
- 在 WebUI 界面中,切换到
清空训练环境标签页。 - 仔细阅读警告信息,确认您已备份所有重要数据。
- 点击
清空训练环境按钮 (主要按钮)。 - 在
清空环境输出信息文本框中,您将看到清理过程的日志。
最后,线上的电脑使用完记得关机,enjoy!
训练素材问题导致的训练效果不理想,联系我们可提供素材修复服务



提供模型代训练服务,对SVC咬字进行了增强
 认证作者
认证作者