智谱开源的AI文本转语音模型支持声音克隆GLM-TTS 语音合成系统 二次开发构建by科哥
智谱开源的AI文本转语音模型支持声音克隆GLM-TTS 语音合成系统 二次开发构建by科哥
 0
00元/小时
v1.1
智谱开源的AI文本转语音模型支持声音克隆GLM-TTS 语音合成系统 二次开发构建by科哥
镜像简介
本镜像基于智谱开源的GLM-TTS模型二次开发,提供高质量的文本转语音服务,并支持个性化的声音克隆功能。用户可通过少量样本快速复制特定音色,生成高度拟真的合成语音。适用于虚拟助手配音、有声内容创作、个性化语音生成等场景,为语音合成应用提供灵活、高效的本地化解决方案。
镜像使用指南
1、在社区镜像区域,选择镜像:
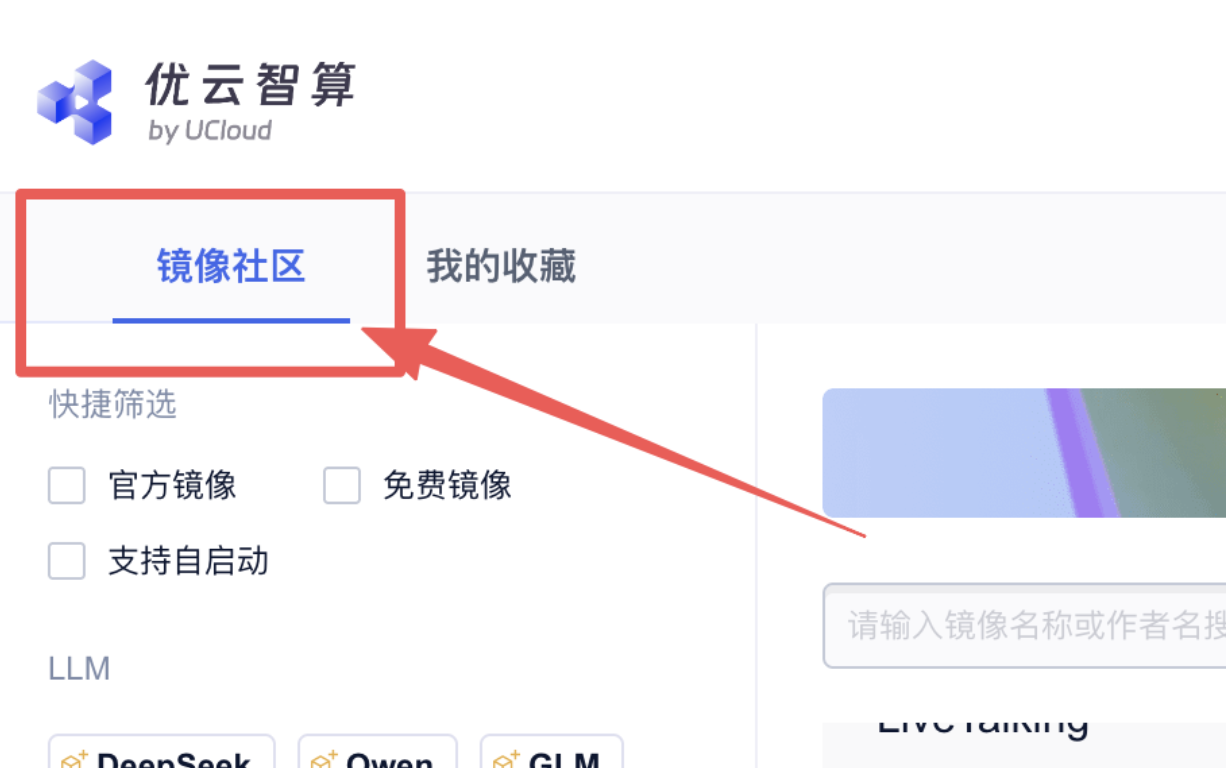
2、在打开的新页面 点击“使用该镜像创建实例”:
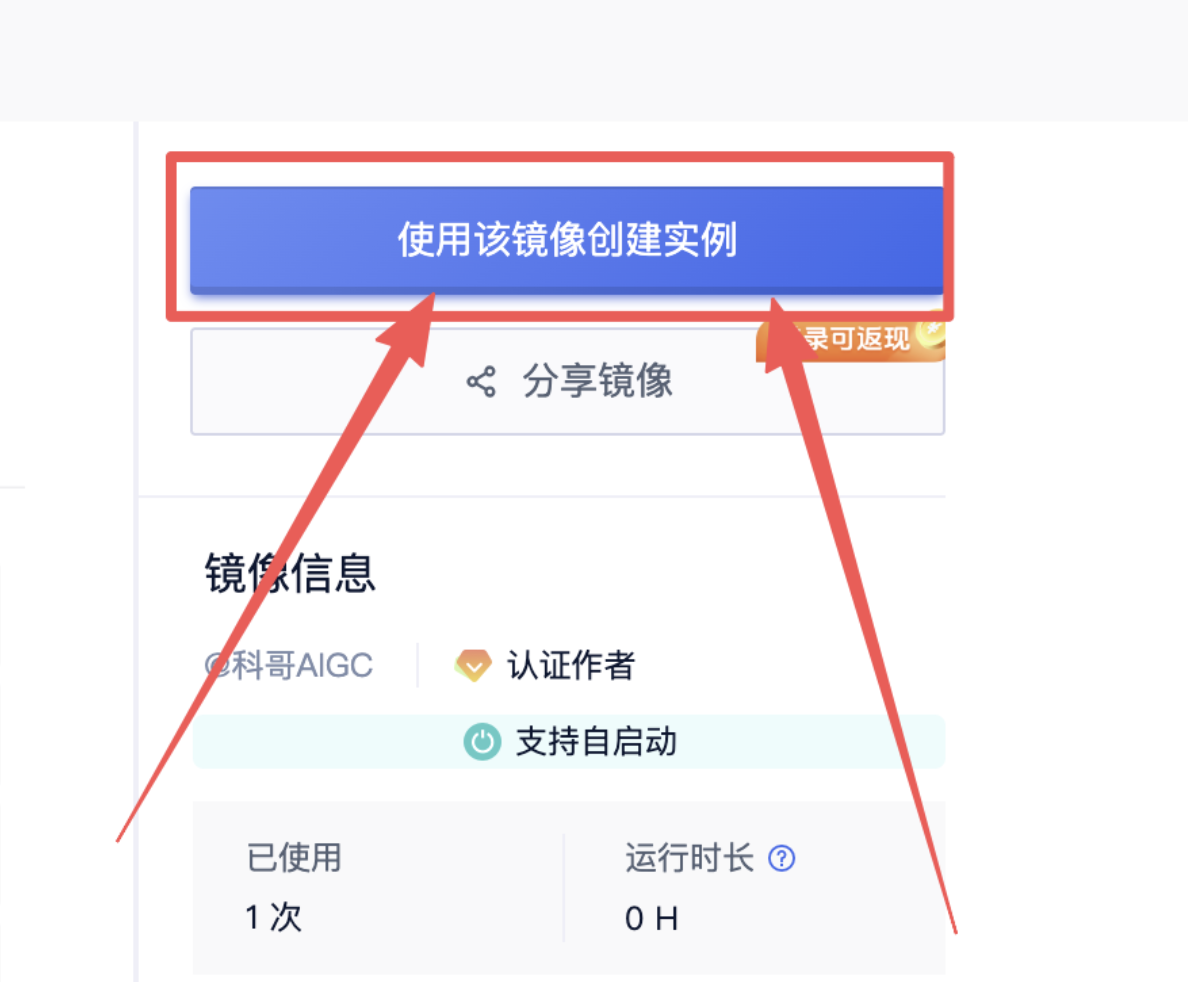
3、选择一个合适的显卡【GPU】根据情况选择:
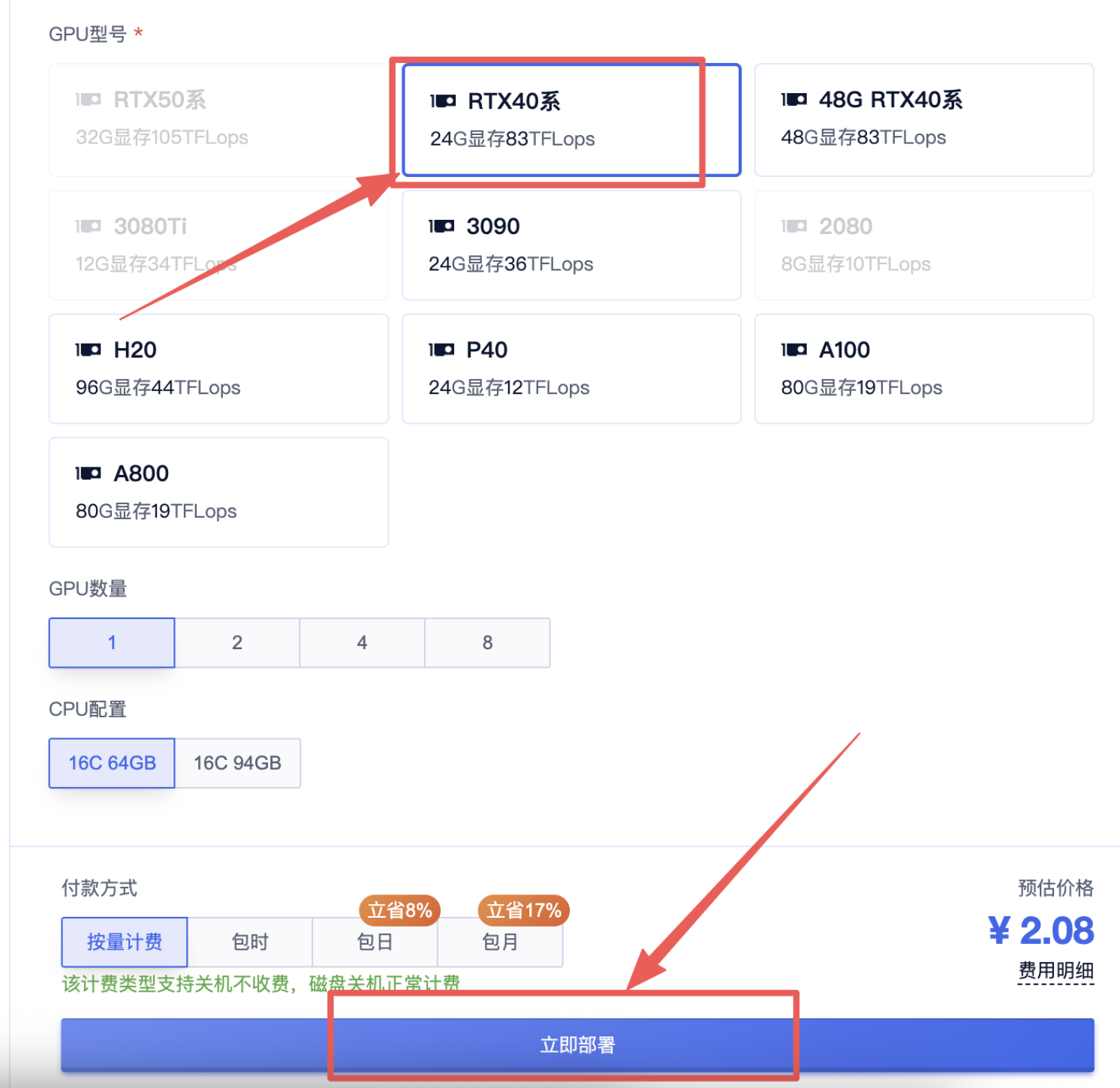
4、确认部署信息无误,点击“开始部署”,然后等待部署完成:
如何启动应用
不是自动运行的应用:
1、手动点击加号新建起始页:
2、打开终端:
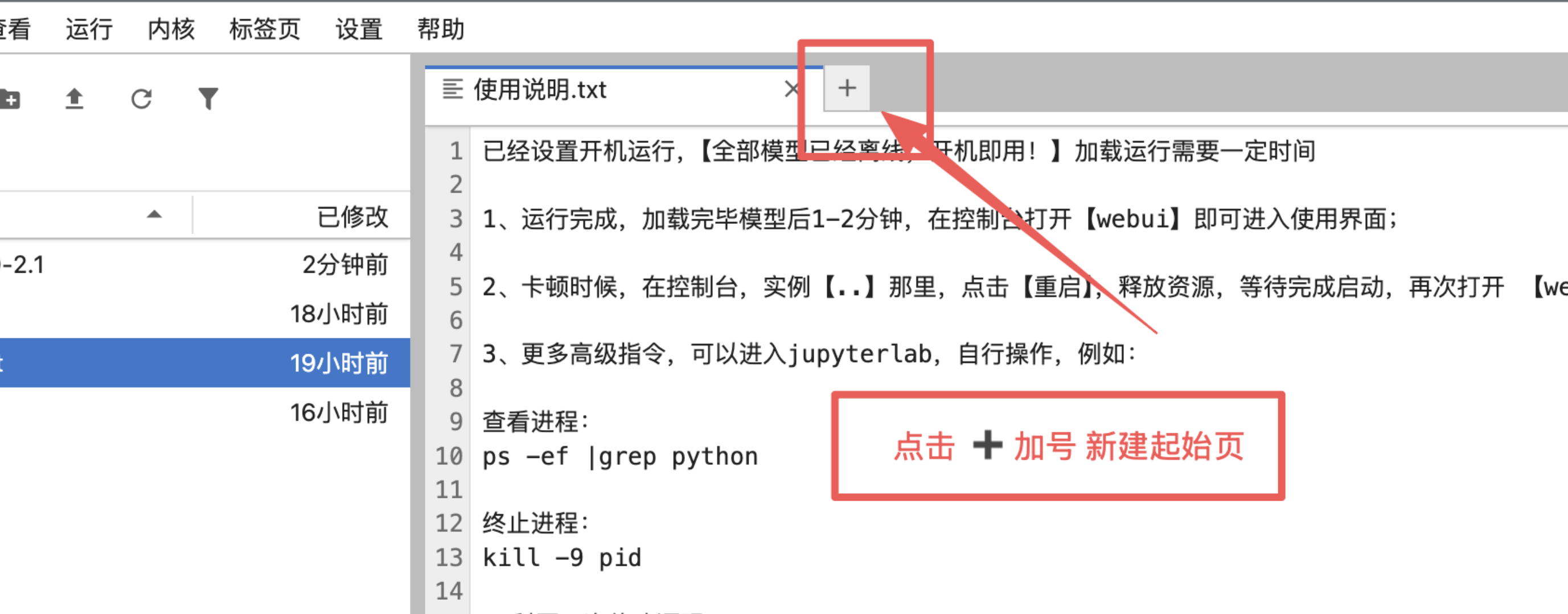
3、输入指令然后回车:
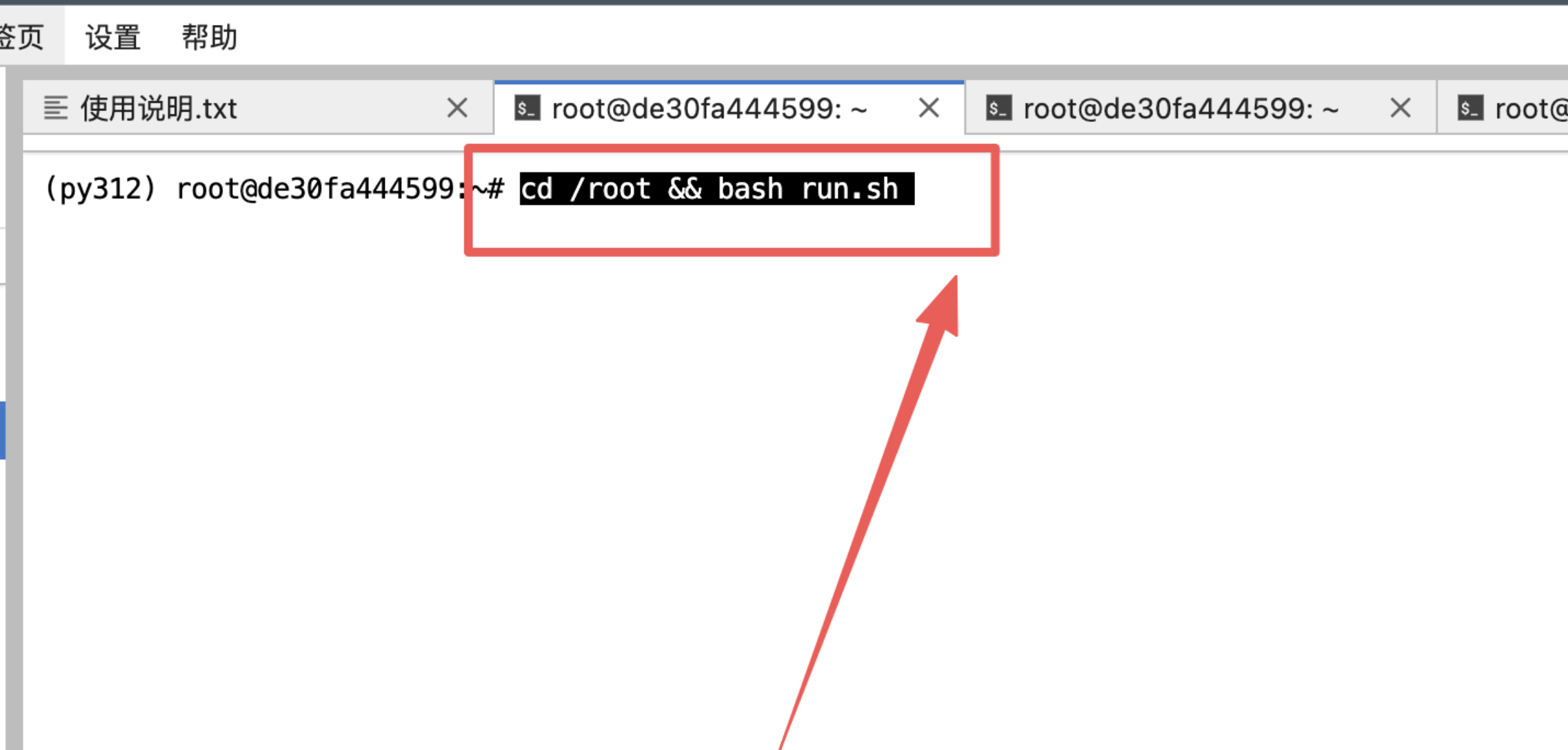
4、等待加载模型完毕:
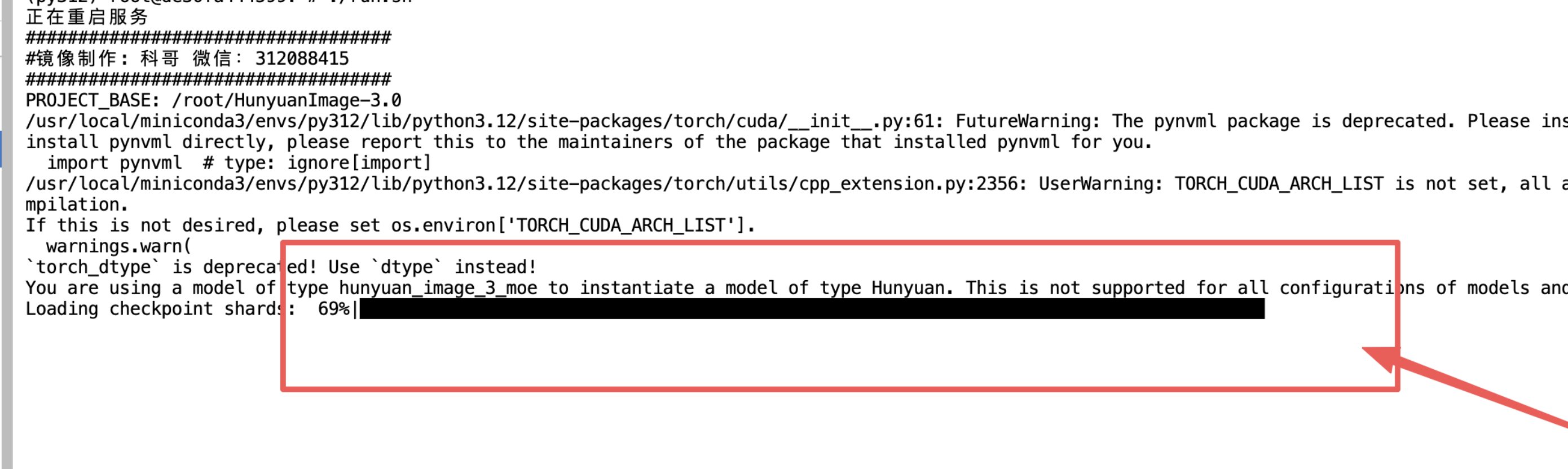
5、看到这个出现:
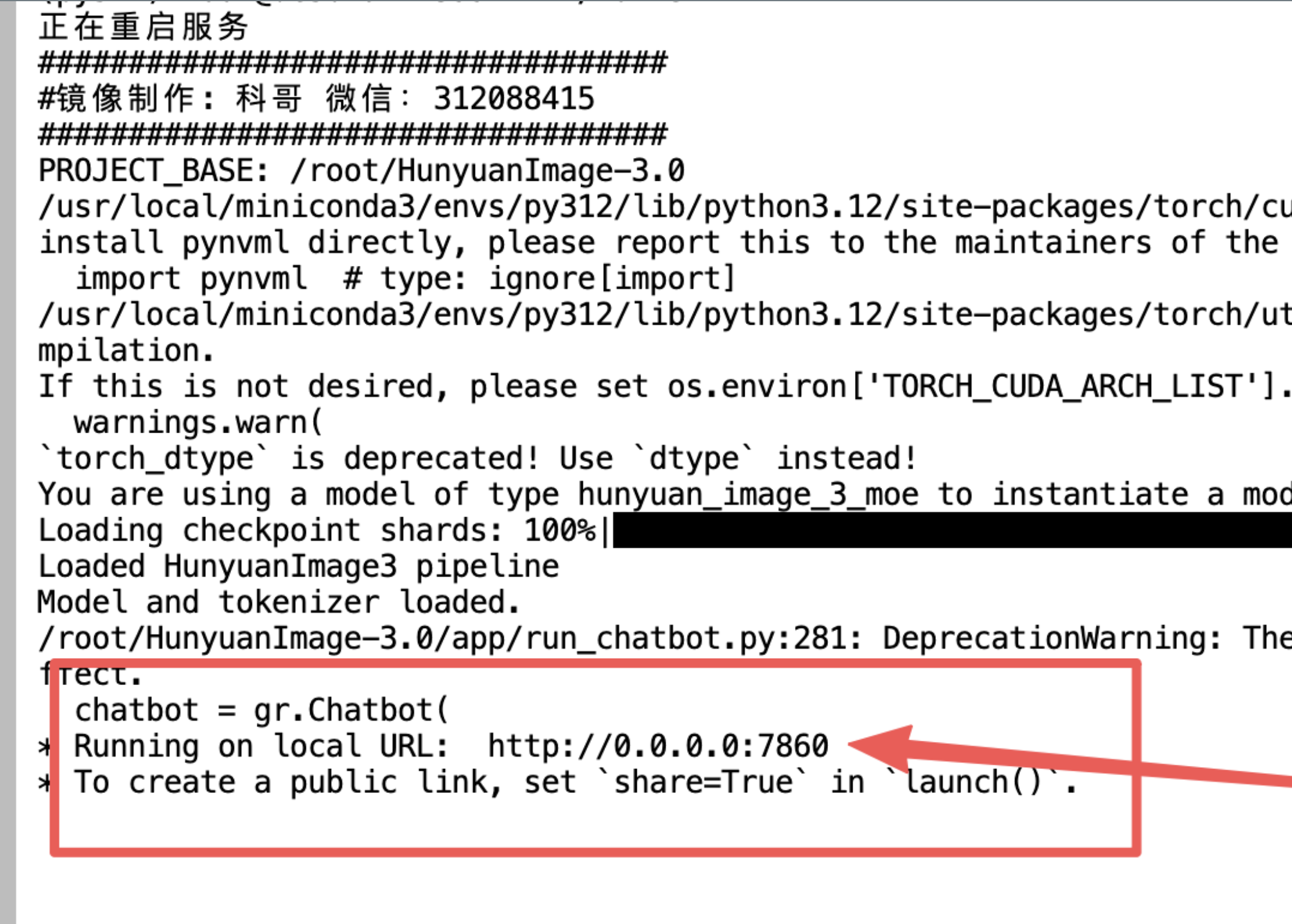
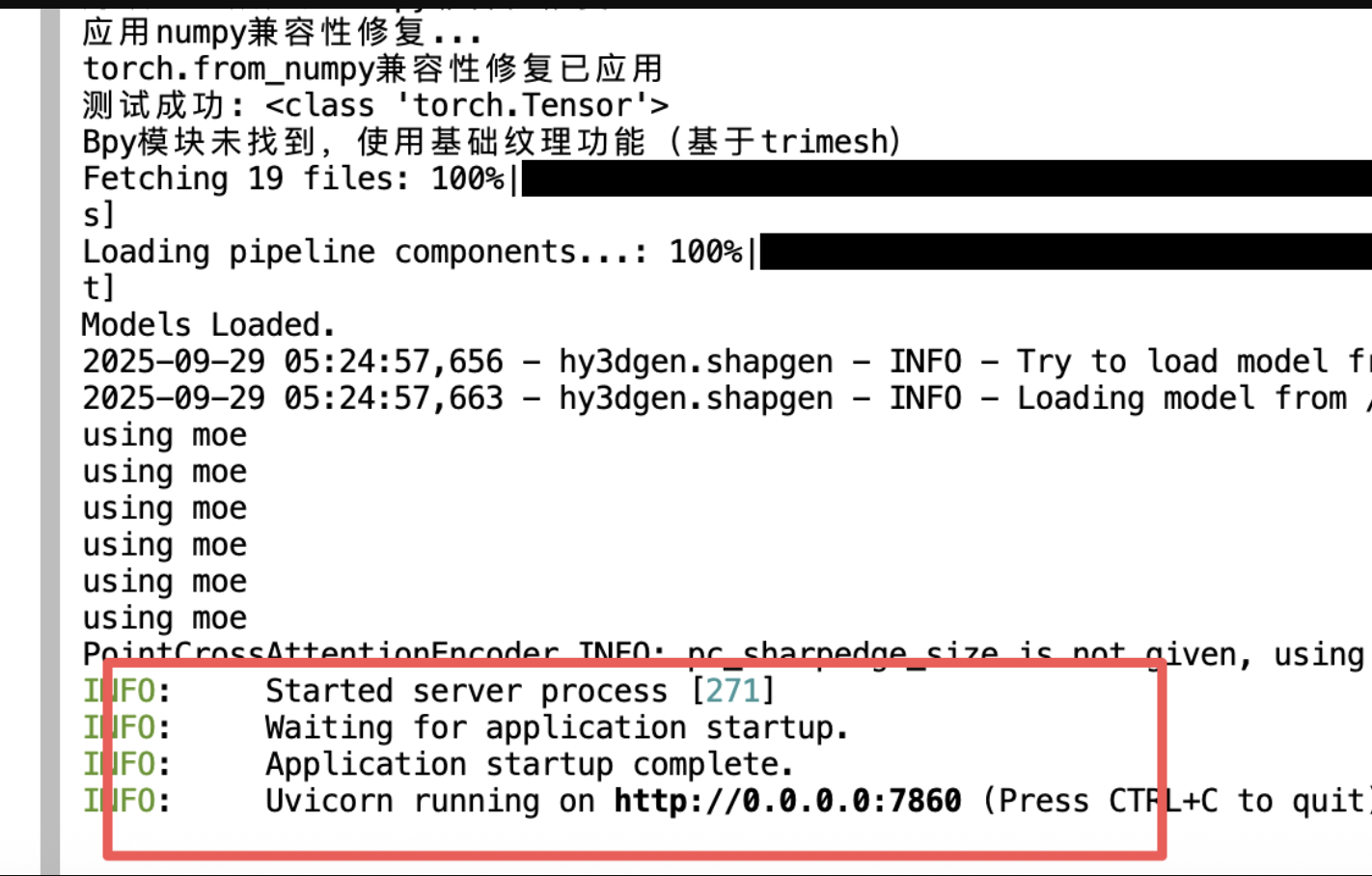
6、返回控制面板打开“SD-WebUI”
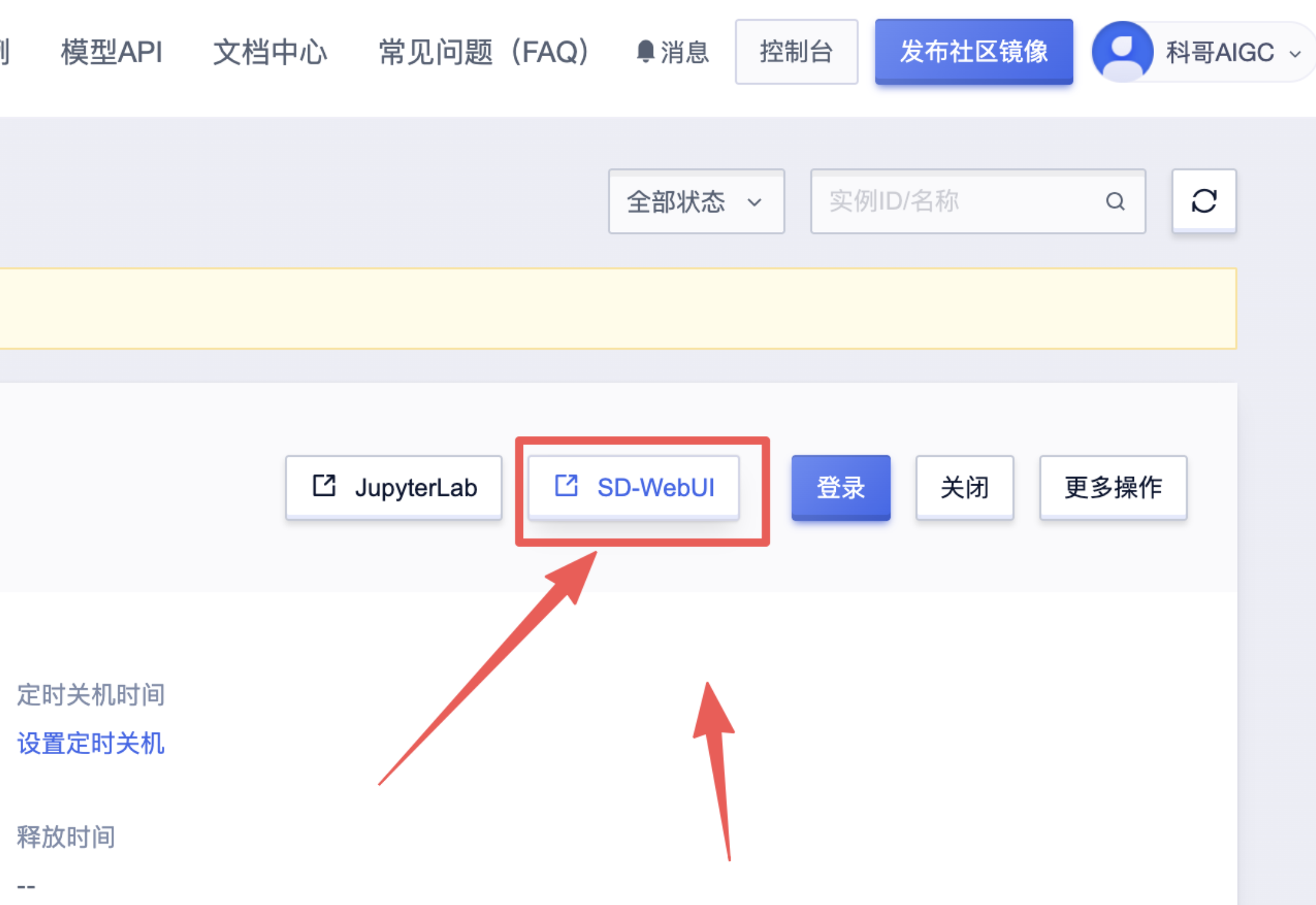
- AI数字人直播卖货欢迎来了解: https://kege-aigc.feishu.cn/docx/G271dgZr1o8CvMx9KKrcRuuonDf
以上都是镜像运行打开操作的一般步骤
有其他使用报错问题加群咨询
更多高级指令,可以进入jupyterlab,自行操作,例如:
- 查看进程:
ps -ef |grep python
- 终止进程:
kill -9 pid
- 重启程序:
cd /root && bash run.sh
- 官方更新源码在这里:
GLM-TTS 用户使用手册
🎵 零样本语音克隆 · 情感表达 · 音素级控制
webUI二次开发by 科哥 微信:312088415
📖 目录
🚀 快速开始
启动 Web 界面
方式一:使用启动脚本(推荐)
cd /root/GLM-TTS
bash start_app.sh
方式二:直接运行
cd /root/GLM-TTS
python app.py
启动后,在浏览器中打开:http://localhost:7860
✅ 说明:
start_app.sh会自动使用 py312 虚拟环境,无需手动激活
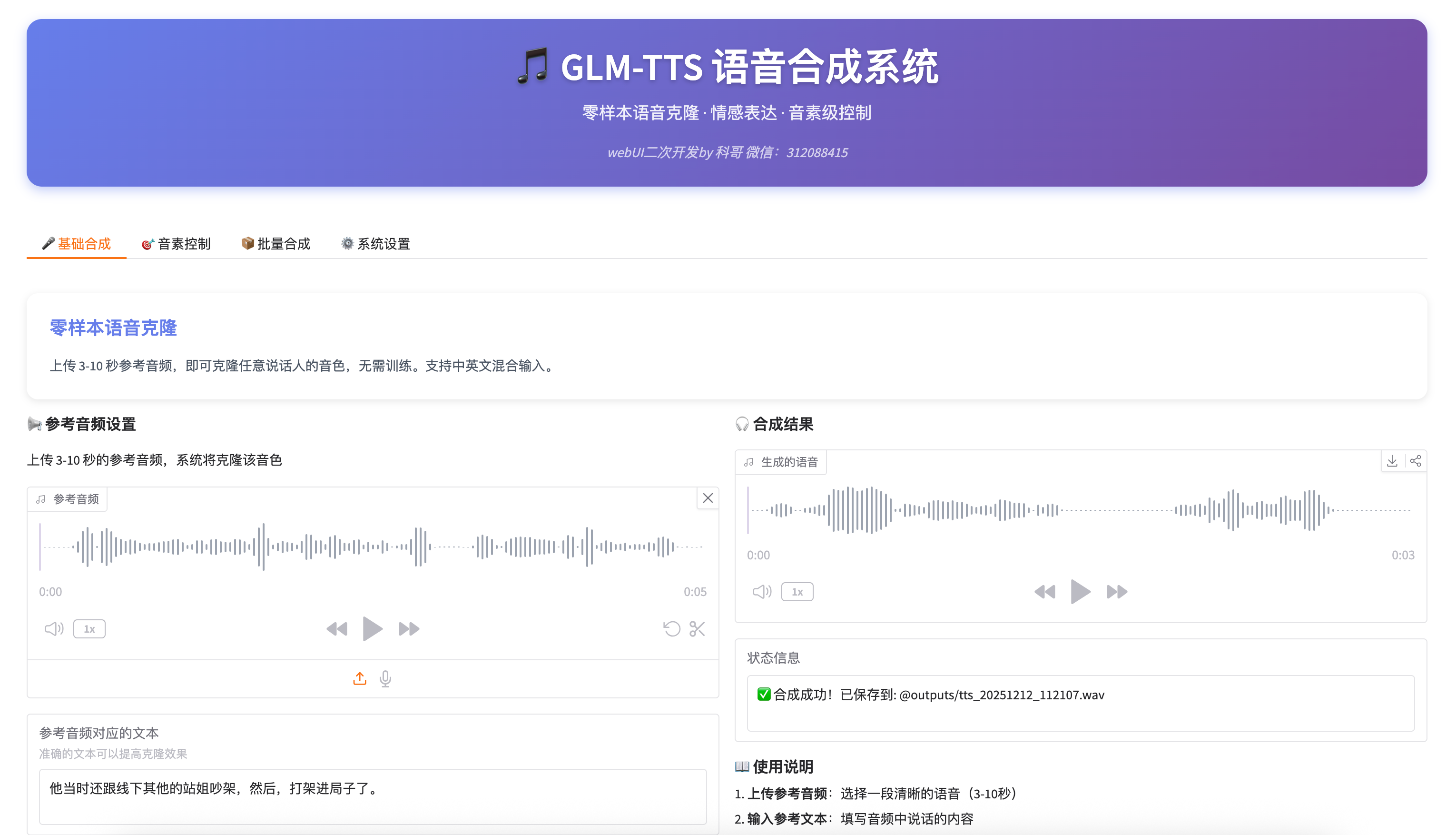
🎤 基础语音合成
操作步骤
1. 上传参考音频
- 点击「参考音频」区域上传音频文件
- 要求:3-10 秒的清晰人声音频
- 格式:支持 WAV、MP3 等常见格式
- 建议:音频越清晰,克隆效果越好
2. 输入参考文本(可选)
- 在「参考音频对应的文本」框中输入音频内容
- 作用:提高音色相似度
- 提示:如果不确定,可以留空
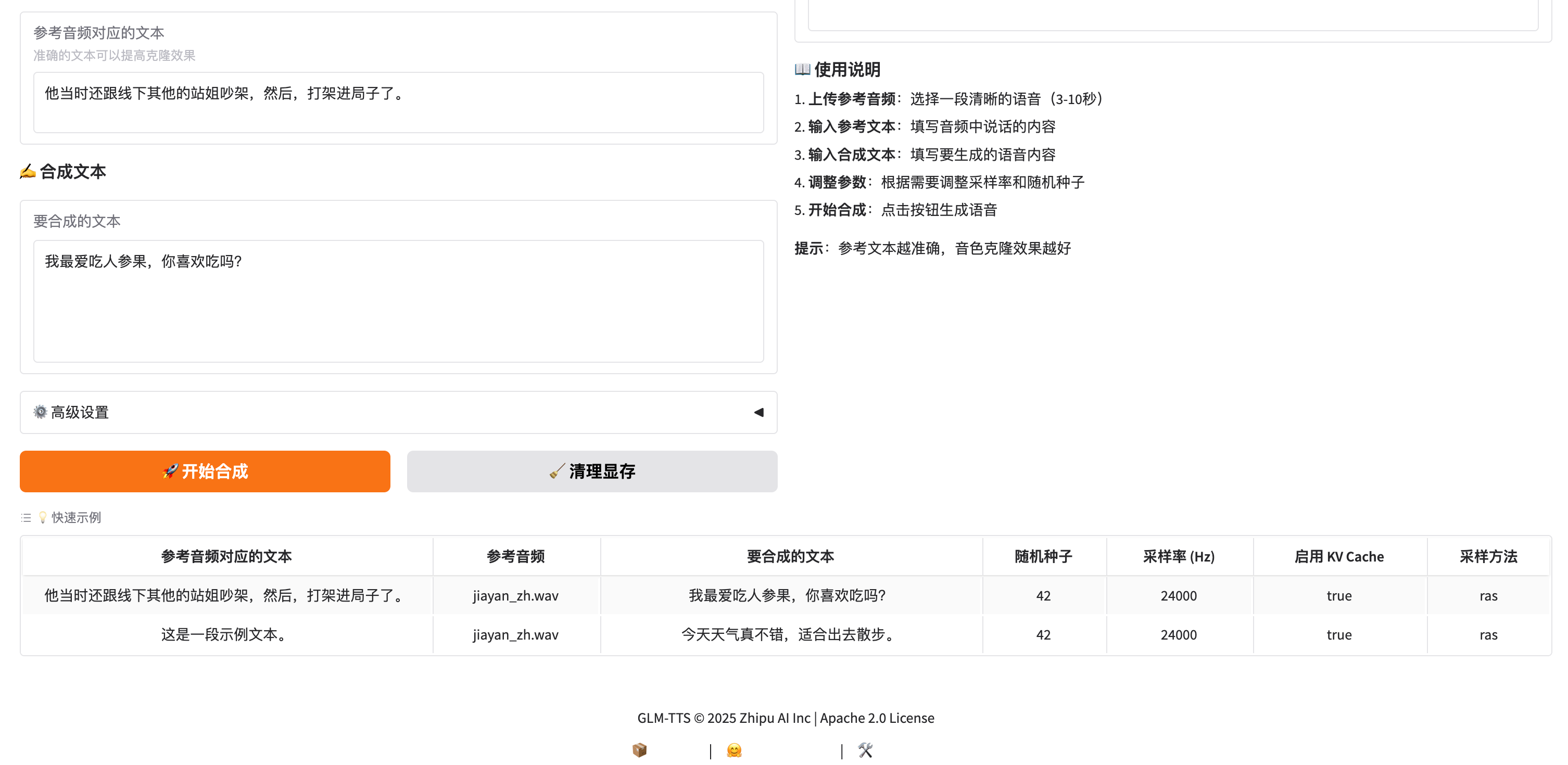
3. 输入要合成的文本
- 在「要合成的文本」框中输入想要生成的语音内容
- 支持:中文、英文、中英混合
- 长度:建议单次不超过 200 字
4. 调整设置(可选)
点击「⚙️ 高级设置」展开:
| 参数 | 说明 | 推荐值 |
|---|---|---|
| 采样率 | 24kHz(快速)/ 32kHz(高质量) | 24000 |
| 随机种子 | 固定种子可复现结果 | 42 |
| 启用 KV Cache | 加速长文本生成 | ✅ 开启 |
| 采样方法 | ras(随机)/ greedy(贪心)/ topk | ras |
5. 开始合成
- 点击「🚀 开始合成」按钮
- 等待生成完成(通常 5-30 秒)
- 生成的音频会自动播放并保存到
@outputs/目录
输出文件位置
@outputs/
└── tts_20251212_113000.wav # 自动命名(时间戳)
📦 批量推理
适用场景
- 需要生成大量音频
- 使用不同的参考音频和文本
- 自动化处理
操作步骤
1. 准备任务文件
创建 JSONL 格式文件(每行一个 JSON 对象):
{"prompt_text": "这是第一段参考文本", "prompt_audio": "examples/prompt/audio1.wav", "input_text": "要合成的第一段文本", "output_name": "output_001"}
{"prompt_text": "这是第二段参考文本", "prompt_audio": "examples/prompt/audio2.wav", "input_text": "要合成的第二段文本", "output_name": "output_002"}
字段说明:
prompt_text:参考音频对应的文本(可选)prompt_audio:参考音频路径(必填)input_text:要合成的文本(必填)output_name:输出文件名(可选,默认 output_0001)
2. 上传任务文件
- 切换到「批量推理」标签页
- 点击「上传 JSONL 文件」
- 选择准备好的任务文件
3. 设置参数
- 采样率:24000 或 32000
- 随机种子:固定值(如 42)
- 输出目录:默认
@outputs/batch(可修改)
4. 开始处理
- 点击「🚀 开始批量合成」
- 查看实时进度和日志
- 处理完成后会生成 ZIP 压缩包
输出文件结构
@outputs/batch/
├── output_001.wav
├── output_002.wav
└── ...
🎯 高级功能
1. 音素级控制(Phoneme Mode)
用途:精确控制多音字和生僻字的发音
使用方法:
# 命令行模式
python glmtts_inference.py --data=example_zh --exp_name=_test --use_cache --phoneme
配置文件:configs/G2P_replace_dict.jsonl
- 可以自定义多音字的发音规则
2. 流式推理(Streaming)
特点:
- 逐 chunk 生成音频
- 降低延迟
- 适合实时应用
Token Rate:25 tokens/sec(固定)
3. 情感控制
方法:通过参考音频的情感来控制生成音频的情感
- 使用带有特定情感的参考音频
- 系统会自动学习并迁移情感特征
💡 使用技巧
获得最佳效果的建议
参考音频选择
✅ 推荐:
- 清晰的人声录音
- 无背景噪音
- 3-10 秒长度
- 单一说话人
- 情感表达自然
❌ 避免:
- 有背景音乐
- 多人对话
- 音质模糊
- 过短(<2秒)或过长(>15秒)
文本输入技巧
- 标点符号:正确使用标点可以控制停顿和语调
- 分段处理:长文本建议分段合成,效果更好
- 中英混合:系统支持,但建议以一种语言为主
参数调优
- 首次使用:使用默认参数(24kHz, seed=42, ras)
- 追求质量:使用 32kHz 采样率
- 追求速度:使用 24kHz + KV Cache
- 可复现:固定随机种子
🔧 常见问题
Q1: 生成的音频在哪里?
A: 自动保存在 @outputs/ 目录下
- 基础 TTS:
@outputs/tts_时间戳.wav - 批量推理:
@outputs/batch/文件名.wav
Q2: 如何提高音色相似度?
A:
- 使用高质量的参考音频
- 填写准确的参考文本
- 参考音频长度 5-8 秒最佳
- 确保参考音频情感自然
Q3: 支持哪些语言?
A:
- ✅ 中文(普通话)
- ✅ 英文
- ✅ 中英混合
- ⚠️ 其他语言效果可能不佳
Q4: 生成速度慢怎么办?
A:
- 使用 24kHz 采样率(而非 32kHz)
- 确保启用 KV Cache
- 缩短单次合成的文本长度
- 检查 GPU 显存是否充足
Q5: 如何清理显存?
A: 点击「🧹 清理显存」按钮,系统会自动释放模型占用的显存
Q6: 批量推理失败怎么办?
A:
- 检查 JSONL 文件格式是否正确
- 确认所有音频路径存在且可访问
- 查看日志中的具体错误信息
- 单个任务失败不会影响其他任务
Q7: 音频质量不满意?
A:
- 尝试更换参考音频
- 使用 32kHz 采样率
- 调整随机种子(尝试不同值)
- 检查输入文本是否有错别字
📊 性能参考
生成速度(参考)
- 短文本(<50字):5-10 秒
- 中等文本(50-150字):15-30 秒
- 长文本(150-300字):30-60 秒
实际速度取决于 GPU 性能和文本复杂度
显存占用
- 24kHz 模式:约 8-10 GB
- 32kHz 模式:约 10-12 GB
🎓 最佳实践
工作流程建议
-
测试阶段
- 使用短文本(10-20字)快速测试
- 尝试不同的参考音频
- 找到最佳的参数组合
-
批量生产
- 准备好所有素材和文本
- 使用批量推理功能
- 设置固定随机种子保证一致性
-
质量检查
- 听取生成的音频
- 记录效果好的参考音频
- 建立自己的音频素材库
📞 技术支持
如有问题或建议,请联系:
科哥 微信:312088415
📄 版权信息
webUI二次开发by 科哥 微信:312088415
基于 GLM-TTS 开源项目:https://github.com/zai-org/GLM-TTS
运行使用界面截图
bug反馈可以加入科哥专属群交流➕ 广告勿进!

最后更新:2025-12-19
最后更新:2025-12-19
@鸡你太美 认证作者
认证作者
认证作者
镜像信息
已使用38 次
运行时长
26 H
 支持自启动
支持自启动镜像大小
40GB
最后更新时间
2026-04-27
支持卡型
30903080Ti2080Ti48G RTX40系RTX40系2080A800P40H20A100V100S
+11
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.1
2026-04-27