VoxCPM1.5面壁智能开源的端到端语音合成模型附训练lora训练器 构建by科哥
语音合成模型+训练lora训练器
 1
10元/小时
v1.5
VoxCPM1.5 – 面壁智能开源的端到端语音合成模型
镜像简介
本镜像基于面壁智能开源的端到端语音合成模型VoxCPM1.5,支持高效生成自然流畅的语音,并内置LoRA训练器,允许用户对音色进行个性化微调。适用于虚拟助手、有声读物、视频配音及定制化语音生成等场景,为用户提供从合成到定制的一站式语音解决方案。
镜像使用指南
1、在社区镜像区域,选择镜像:
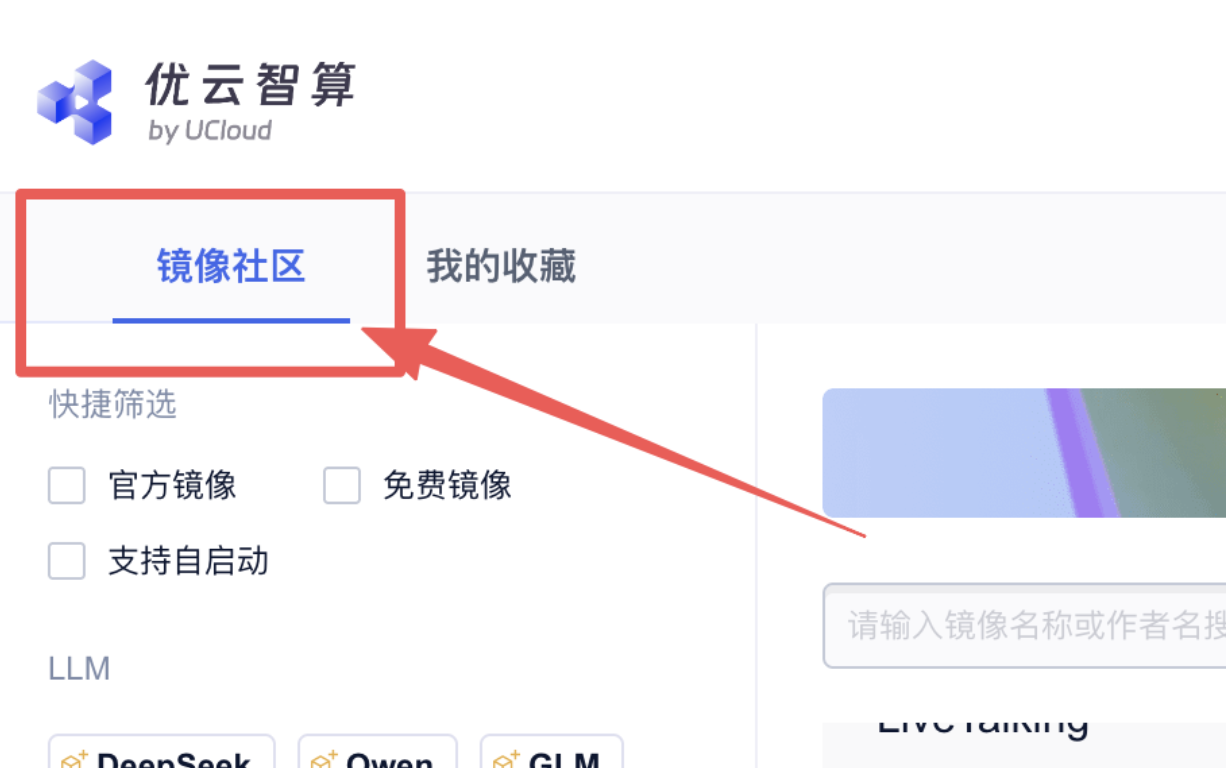
2、在打开的新页面 点击“使用该镜像创建实例”:
2、在打开的新页面 点击“使用该镜像创建实例”:
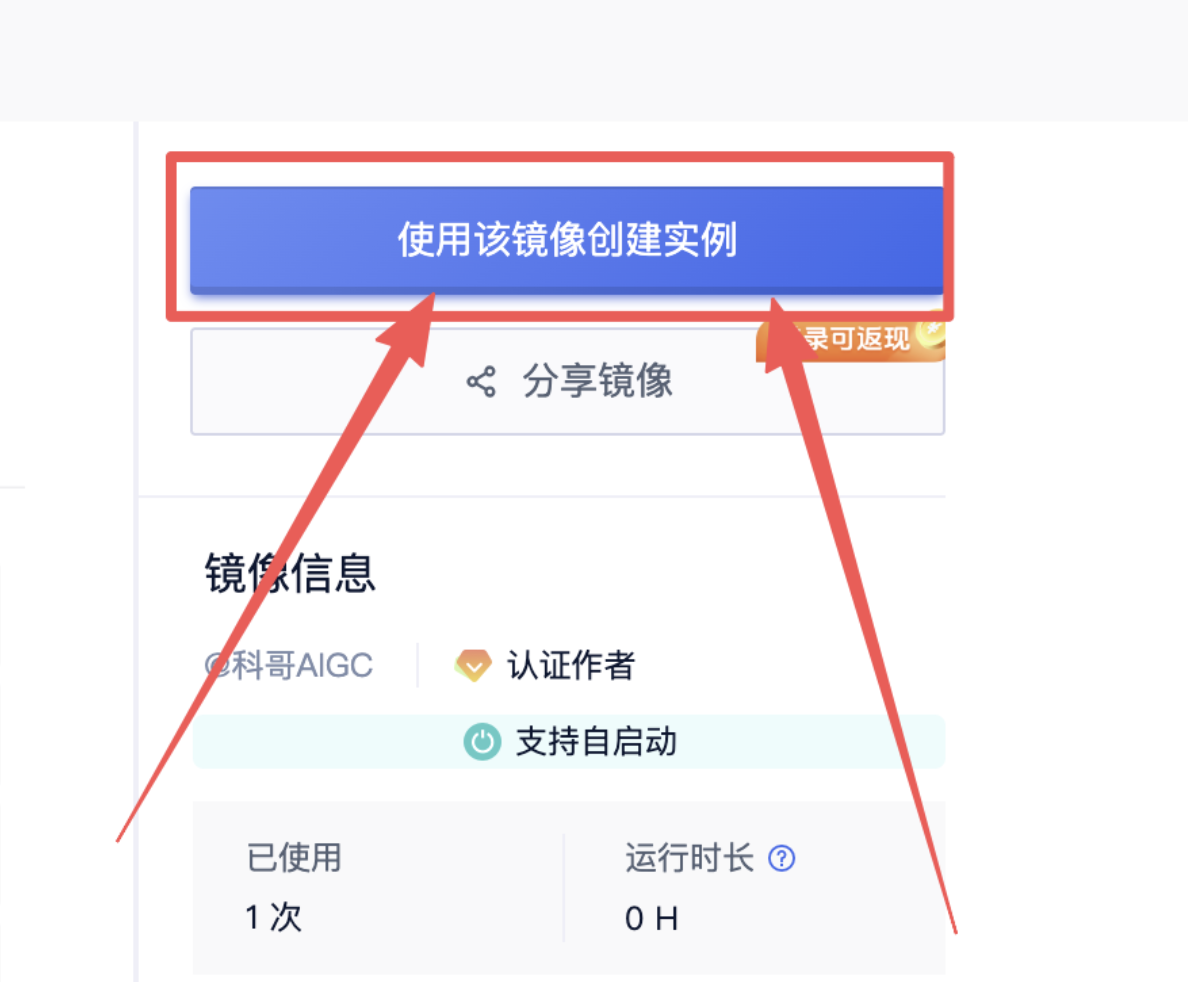
3、选择一个合适的显卡【GPU】根据情况选择,点击“开始部署”,然后等待部署完成:
3、选择一个合适的显卡【GPU】根据情况选择,点击“开始部署”,然后等待部署完成:
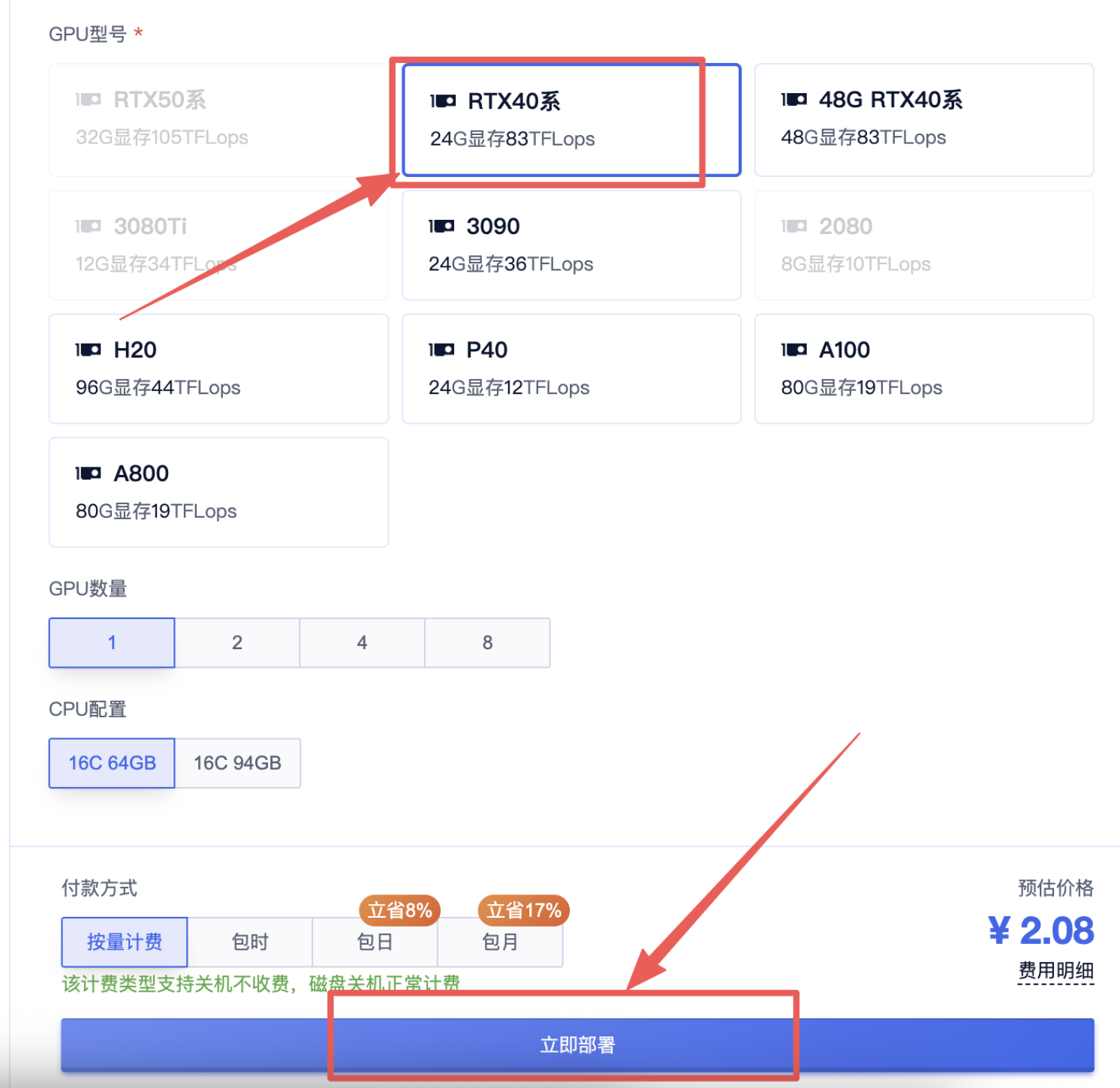
4、实例运行后打开SD-WebUI即可
webui使用界面及训练器界面
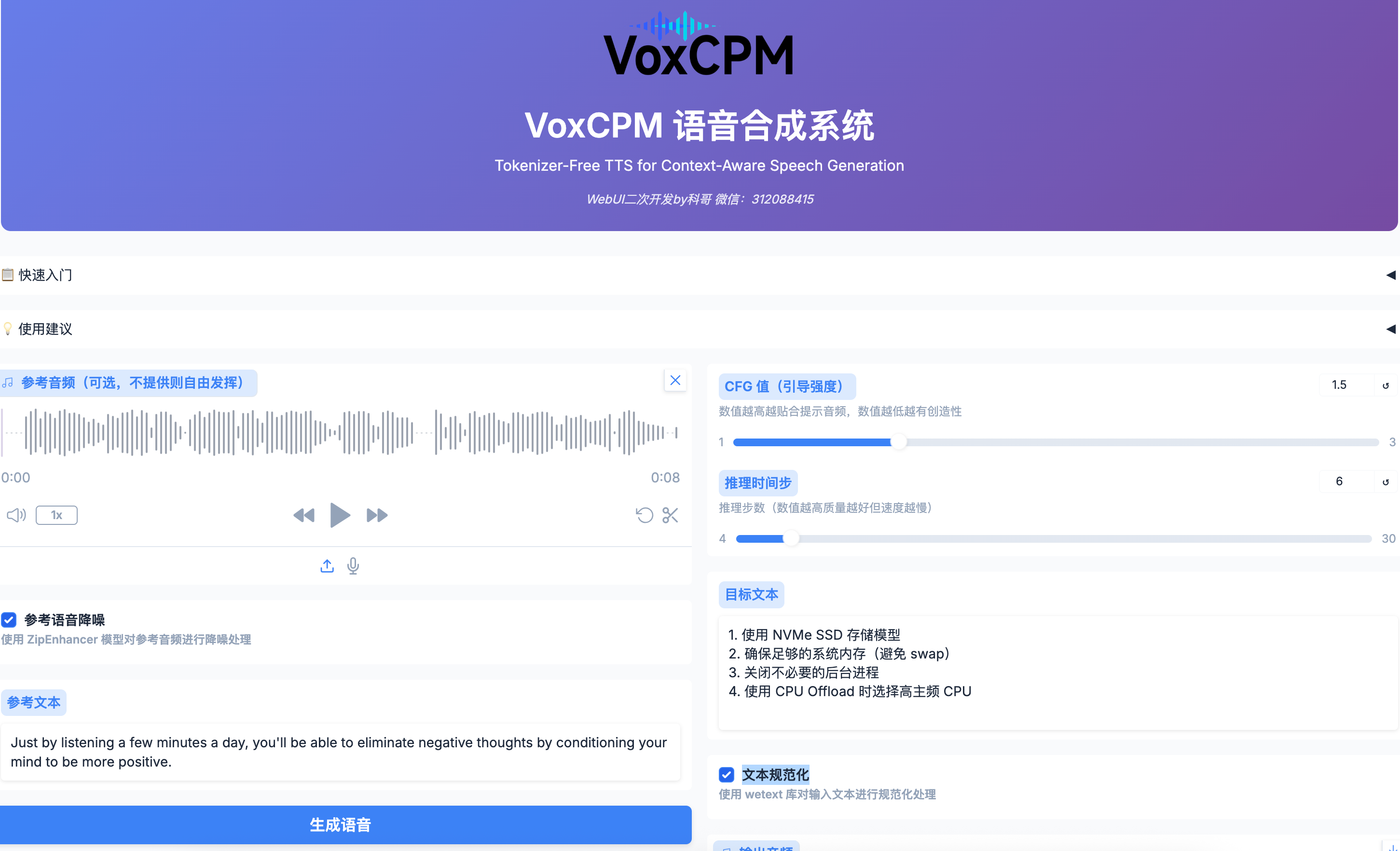
VoxCPM 用户使用手册
目录
快速开始
启动 WebUI
./train.sh
说明: train.sh 会自动处理端口冲突,无需手动操作。
WebUI 使用
界面概览
WebUI 包含两个主要标签页:
- 训练 (Training): 配置和启动 LoRA 微调
- 推理 (Inference): 使用模型生成语音
语言切换
右上角可切换中英文界面。
训练 LoRA 模型
1. 准备训练数据
创建 JSONL 格式的训练数据文件,每行一个 JSON 对象:
{"audio": "path/to/audio1.wav", "text": "对应的文本内容"}
{"audio": "path/to/audio2.wav", "text": "另一段文本"}
{"audio": "path/to/audio3.wav", "text": "更多文本", "duration": 3.5}
字段说明:
audio: 音频文件路径(支持相对路径和绝对路径)text: 音频对应的文本转录duration: (可选) 音频时长,可加速数据加载
音频要求:
- 格式: WAV
- 采样率: 44100 Hz (VoxCPM1.5) 或 16000 Hz (VoxCPM-0.5B)
- 建议时长: 3-10 秒
- 数量: 至少 50 条,建议 500+ 条
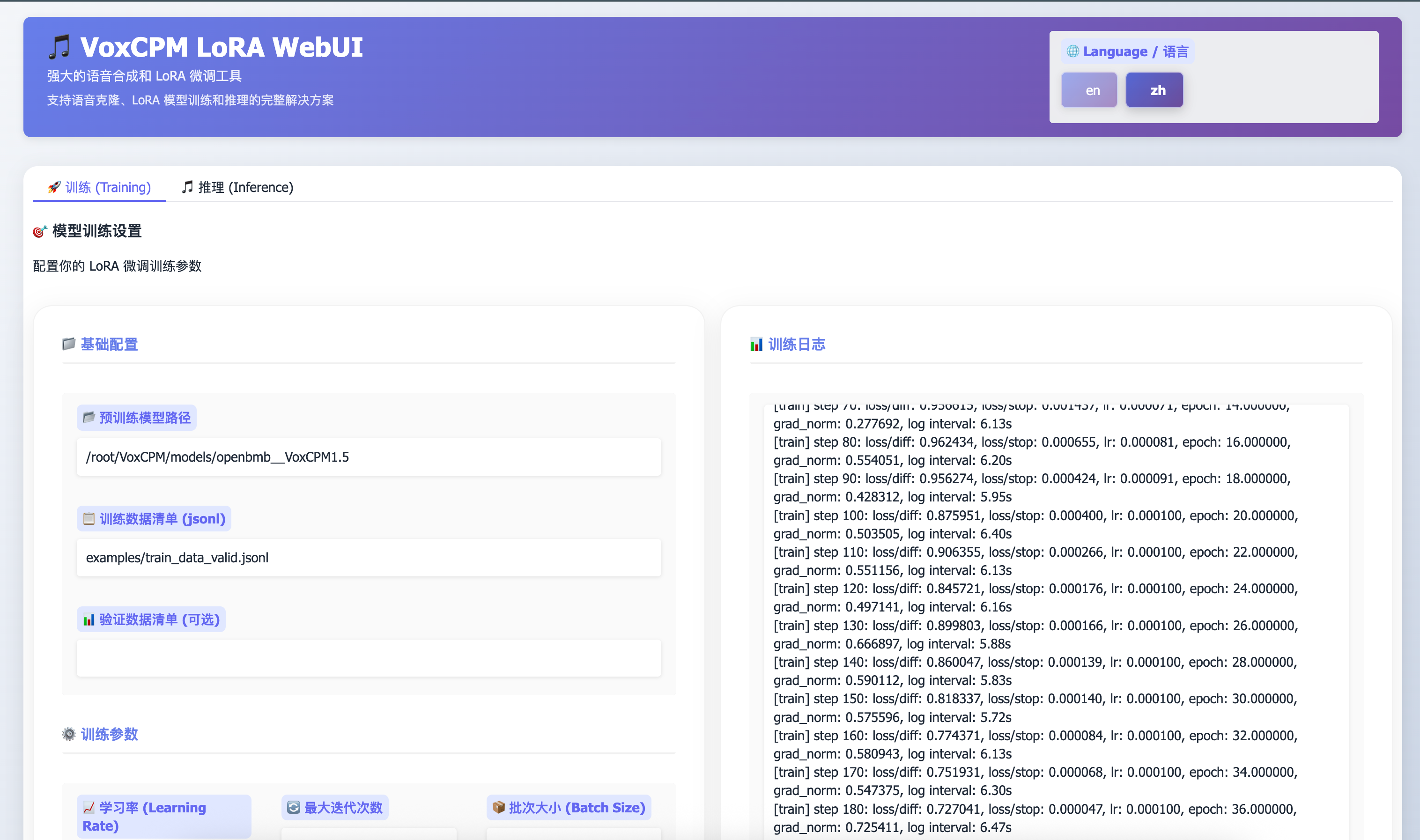
2. 在 WebUI 中配置训练
进入"训练"标签页,配置以下参数:
基础配置
- 预训练模型路径: 默认
models/openbmb__VoxCPM1.5 - 训练数据清单: 你的 JSONL 文件路径,如
data/my_train.jsonl - 验证数据清单: (可选) 用于验证的 JSONL 文件
训练参数
- 学习率: 推荐
1e-4(0.0001) - 最大迭代次数: 根据数据量调整,建议 2000-5000
- 批次大小: 根据显存调整,通常为 1-4
- LoRA Rank: 推荐 32,越大模型容量越大但训练越慢
- LoRA Alpha: 推荐 16,通常设为 rank 的一半
- 保存间隔: 每隔多少步保存一次检查点,推荐 500-1000
高级选项 (可选)
- 梯度累积: 模拟更大的 batch size
- warmup_steps: 学习率预热步数,推荐 100
- weight_decay: 权重衰减,推荐 0.01
3. 启动训练
点击"开始训练"按钮,训练日志会实时显示在右侧面板。
训练输出:
- 配置文件:
lora/<timestamp>/train_config.yaml - 检查点:
lora/<timestamp>/checkpoints/step_XXXXXX/ - TensorBoard 日志:
lora/<timestamp>/logs/
4. 监控训练进度
方法 1: WebUI 日志面板
实时查看训练日志输出。
方法 2: 监控脚本
./monitor_training.sh
方法 3: TensorBoard
tensorboard --logdir=lora/<timestamp>/logs --port=6006 --bind_all
5. 停止训练
点击"停止训练"按钮,或使用命令:
pkill -f train_voxcpm_finetune
音频生成与推理
1. 基础 TTS (零样本)
进入"推理"标签页:
- 输入文本: 在"合成文本"框输入要生成的文本
- 选择模型:
- 选择 "None" 使用基础模型
- 或选择训练好的 LoRA 模型
- 调整参数:
- CFG Scale: 1.0-5.0,越大越贴近提示,推荐 2.0
- 推理步数: 1-50,越多质量越好但越慢,推荐 10
- 随机种子: -1 为随机,固定值可复现结果
- 生成: 点击"生成音频"
2. 声音克隆 (Few-shot)
在基础 TTS 基础上,添加参考音频:
- 上传参考音频: 点击"参考音频"上传 WAV 文件
- 参考文本:
- 留空:自动识别(使用 SenseVoice ASR)
- 手动填写:提供参考音频的文本内容
- 生成: 点击"生成音频"
参考音频要求:
- 格式: WAV
- 采样率: 44100 Hz
- 时长: 3-10 秒
- 质量: 清晰、无噪音、单说话人
3. 使用训练的 LoRA 模型
- 点击"刷新模型列表"按钮
- 在"LoRA 模型"下拉框中选择训练好的模型
- 格式:
<timestamp>/checkpoints/step_XXXXXX
- 格式:
- 输入文本并生成
说明: LoRA 模型会在基础模型上微调,适合特定说话人或风格。
命令行工具
基础推理
voxcpm --text "Hello, world!" --output output.wav
声音克隆
voxcpm \
--text "要合成的文本" \
--prompt-audio reference.wav \
--prompt-text "参考音频的文本" \
--output output.wav
使用 LoRA 模型推理
python scripts/test_voxcpm_lora_infer.py \
--lora_ckpt lora/<timestamp>/checkpoints/step_XXXXXX \
--text "测试文本" \
--output output.wav
训练 (命令行)
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v1.5/voxcpm_finetune_lora.yaml
多 GPU 训练
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 \
scripts/train_voxcpm_finetune.py \
--config_path your_config.yaml
常见问题
Q1: 训练时显示 "FileNotFoundError: audio file not found"
原因: JSONL 文件中的音频路径不存在
解决:
- 检查音频文件路径是否正确
- 使用绝对路径或相对于项目根目录的路径
- 确认音频文件格式为 WAV
Q2: 训练时 GPU 显存不足 (OOM)
解决:
- 减小
batch_size(改为 1) - 减小
lora_rank(改为 16 或 8) - 启用梯度累积
grad_accum_steps(如 4) - 使用更短的音频样本
Q3: 生成的音频质量不好
可能原因:
- 训练数据质量差(噪音、多说话人、音质差)
- 训练步数不足
- 学习率设置不当
- 推理步数太少
建议:
- 使用高质量、清晰的训练数据
- 训练至少 2000 步
- 推理时增加步数到 20-30
- 调整 CFG Scale (1.5-3.0)
Q4: 如何选择最佳检查点?
方法:
- 查看 TensorBoard 中的 loss 曲线,选择 loss 最低的检查点
- 使用验证集评估不同检查点
- 手动测试生成音频质量
经验:
- 通常最后几个检查点效果较好
- 过拟合时,中间检查点可能更好
Q5: 声音克隆效果不理想
优化建议:
- 使用更长的参考音频 (5-10 秒)
- 确保参考音频清晰、无背景噪音
- 参考文本要准确匹配音频内容
- 增加 CFG Scale 到 2.5-3.0
- 使用 LoRA 微调特定说话人
Q6: WebUI 端口被占用
解决:
# 方法 1: 使用启动脚本(自动处理)
./train.sh
# 方法 2: 手动杀掉进程
lsof -ti :7860 | xargs kill
# 方法 3: 使用不同端口
python lora_ft_webui.py --server-port 7861
Q7: 训练中断后如何继续?
方法:
- 在 WebUI 的"输出目录名称"填写之前的时间戳
- 或修改配置文件中的
save_path指向已有目录 - 训练会自动从最新检查点恢复
Q8: 如何评估 LoRA 模型质量?
评估方法:
- 主观评估: 生成多个样本,人工听音质和相似度
- 客观指标: 查看训练日志中的 loss 值
- 对比测试: 与基础模型对比生成效果
- 验证集: 使用验证数据评估泛化能力
最佳实践
数据准备
- 使用高质量录音设备
- 保持一致的录音环境
- 每个样本 3-10 秒为佳
- 文本转录要准确
- 数据量: 至少 50 条,推荐 500+
训练配置
- 从小规模测试开始 (100 步)
- 验证流程无误后进行完整训练
- 定期保存检查点 (每 500-1000 步)
- 使用验证集监控过拟合
- 记录实验参数和结果
推理优化
- 首次推理会较慢(模型加载)
- 批量生成时复用已加载的模型
- 调整 CFG Scale 和步数平衡质量与速度
- 使用固定 seed 复现结果
资源管理
- 训练完成后及时清理不需要的检查点
- 定期备份重要的 LoRA 模型
- 使用 TensorBoard 监控训练,及时发现问题
技术支持
- 项目文档:
CLAUDE.md,DEPLOYMENT.md - 修复记录:
todo.md - 训练脚本:
scripts/train_voxcpm_finetune.py - 监控工具:
monitor_training.sh
附录: 文件结构
VoxCPM/
├── lora_ft_webui.py # WebUI 主程序
├── train.sh # WebUI 启动脚本
├── monitor_training.sh # 训练监控脚本
├── examples/
│ ├── train_data_valid.jsonl # 示例训练数据
│ └── example.wav # 示例音频
├── lora/ # 训练输出目录
│ └── <timestamp>/
│ ├── train_config.yaml
│ ├── checkpoints/
│ │ └── step_XXXXXX/
│ │ ├── lora_config.json
│ │ ├── lora_weights.safetensors
│ │ ├── optimizer.pth
│ │ └── scheduler.pth
│ └── logs/ # TensorBoard 日志
├── models/ # 预训练模型
│ └── openbmb__VoxCPM1.5/
└── scripts/
├── train_voxcpm_finetune.py
├── test_voxcpm_lora_infer.py
└── test_voxcpm_ft_infer.py
版本: 1.0 更新日期: 2025-12-27 适用模型: VoxCPM1.5, VoxCPM-0.5B
bug反馈可以加入科哥专属群交流➕ 广告勿进!

@鸡你太美 认证作者
认证作者
认证作者
镜像信息
已使用25 次
运行时长
23 H
 支持自启动
支持自启动镜像大小
40GB
最后更新时间
2026-04-27
支持卡型
3090RTX40系48G RTX40系2080Ti3080TiRTX50系2080A800H20P40V100SA100
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.5
2026-04-27