 2
2FunASR中文语音识别音频转文本声音转文本系统
镜像简介
-本镜像基于FunASR开源模型,专注于高精度中文语音识别,可将音频快速转换为文本。内置直观的WebUI界面,支持文件上传、实时识别与结果导出,适用于会议记录整理、字幕生成、语音资料转录及无障碍服务等场景,为用户提供便捷高效的本地化语音转文字解决方案。
镜像使用教程
创建实例后点击【SD-WebUI】即可进入操作页面
操作页面截图
操作指南
快速开始 开机自动运行
- 重启
cd /root && bash run.sh
访问地址
启动成功后,在浏览器中访问:
http://localhost:7860
或从远程访问:
http://<服务器IP>:7860
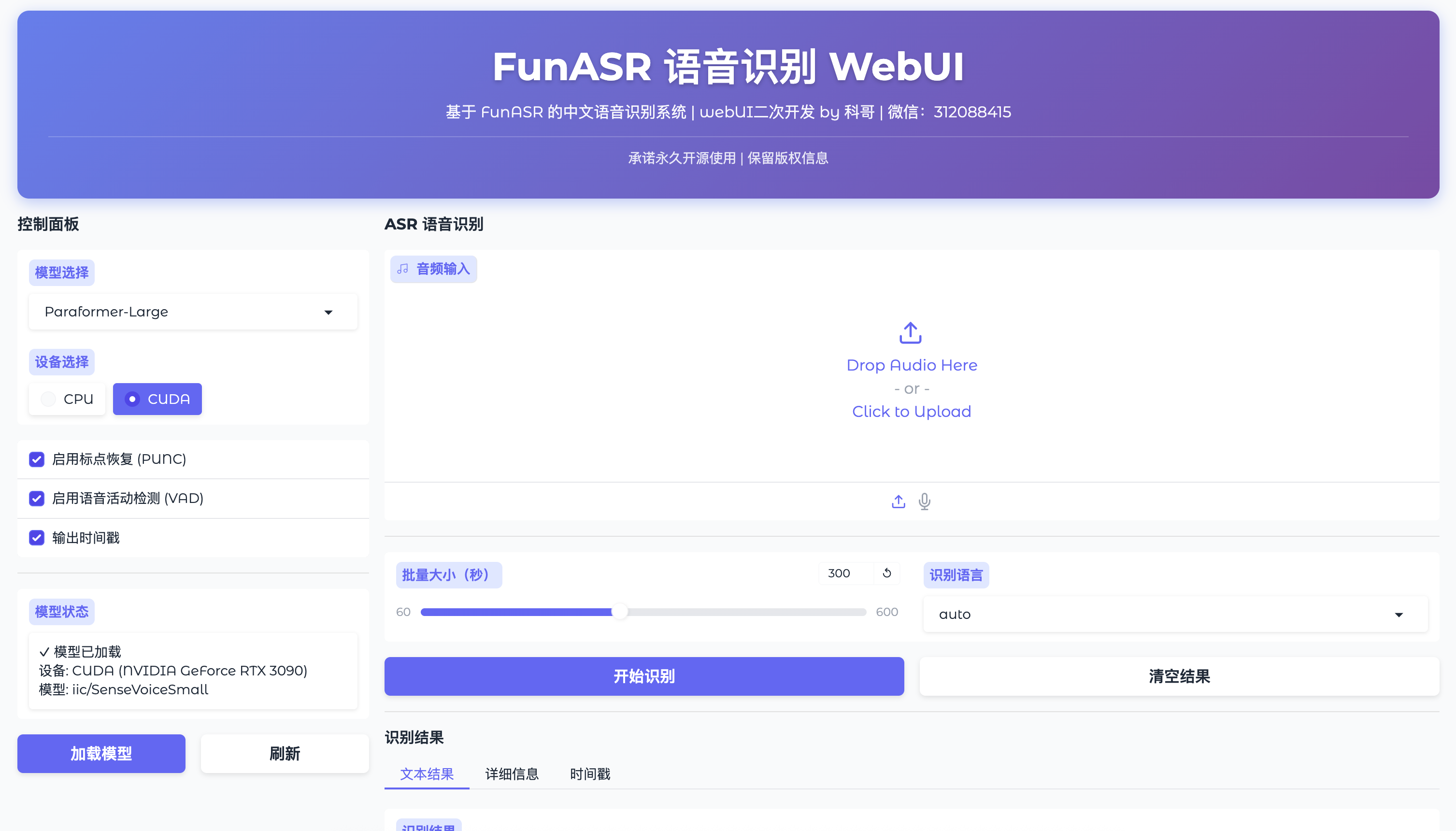
界面介绍
头部区域
显示应用标题、描述和版权信息:
- 标题: FunASR 语音识别 WebUI
- 描述: 基于 FunASR 的中文语音识别系统
- 版权: webUI二次开发 by 科哥 | 微信:312088415
控制面板(左侧)
1. 模型选择
- Paraformer-Large:大模型,高精度(可选)
- SenseVoice-Small:小模型,快速响应(默认)
2. 设备选择
- CUDA:GPU 加速(推荐,有显卡时自动选中)
- CPU:CPU 模式(无显卡时使用)
3. 功能开关
- 启用标点恢复 (PUNC):自动添加标点符号
- 启用语音活动检测 (VAD):自动检测语音段落
- 输出时间戳:在结果中显示时间戳信息
4. 模型状态
显示当前模型加载状态:
- ✓ 模型已加载
- ✗ 模型未加载
5. 操作按钮
- 加载模型:手动加载/重新加载模型
- 刷新:刷新状态信息
使用流程
方式一:上传音频文件识别
步骤 1:准备音频文件
支持的音频格式:
- WAV (.wav)
- MP3 (.mp3)
- M4A (.m4a)
- FLAC (.flac)
- OGG (.ogg)
- PCM (.pcm)
推荐采样率:16kHz
步骤 2:上传文件
- 在 "ASR 语音识别" 区域,点击 "上传音频"
- 选择本地音频文件
- 等待上传完成
步骤 3:配置识别参数
- 批量大小(秒): 默认 300 秒,支持最长 5 分钟音频
- 识别语言:
auto- 自动检测(推荐)zh- 中文en- 英文yue- 粤语ja- 日语ko- 韩语
步骤 4:开始识别
点击 "开始识别" 按钮,等待处理完成
步骤 5:查看结果
识别结果会显示在下方区域,包含三个标签页:
文本结果
- 显示识别的纯文本
- 可直接复制使用
详细信息
- JSON 格式的完整结果
- 包含时间戳、置信度等详细信息
时间戳
- 显示每个词/句的时间范围
- 格式:
[序号] 开始时间 - 结束时间 (时长)
方式二:浏览器实时录音
步骤 1:开始录音
- 点击 "麦克风录音" 按钮
- 浏览器会请求麦克风权限,点击 "允许"
步骤 2:录制语音
- 对着麦克风说话
- 点击 "停止录音" 结束录制
步骤 3:开始识别
点击 "开始识别" 按钮处理录音
步骤 4:查看结果
同"上传音频文件识别"的步骤 5
下载结果
识别完成后,可以下载不同格式的结果:
下载按钮说明
| 按钮 | 文件格式 | 说明 |
|---|---|---|
| 下载文本 | .txt | 纯文本,可直接使用 |
| 下载 JSON | .json | 完整数据,包含时间戳 |
| 下载 SRT | .srt | 字幕文件,可用于视频 |
文件保存位置
所有输出文件保存在:
outputs/outputs_YYYYMMDDHHMMSS/
每次识别会创建一个带时间戳的新目录,例如:
outputs/outputs_20260104123456/
├── audio_001.wav # 原始音频副本
├── result_001.json # JSON 格式结果
├── text_001.txt # 纯文本结果
└── subtitle_001.srt # SRT 字幕文件
高级功能
批量大小调整
- 默认:300 秒(5 分钟)
- 范围:60 - 600 秒
- 用途:处理不同长度的音频文件
语言识别设置
选择正确的语言可以提高识别准确率:
- 中文内容 → 选择
zh - 英文内容 → 选择
en - 混合语言 → 选择
auto - 粤语/日语/韩语 → 选择对应语言
时间戳输出
启用后,结果中会显示每个词/句的时间信息:
- 用于视频字幕制作
- 用于音频编辑定位
结果示例
纯文本输出
你好,欢迎使用语音识别系统。这是一个基于 FunASR 的中文语音识别 WebUI。
SRT 字幕输出
1
00:00:00,000 --> 00:00:02,500
你好
2
00:00:02,500 --> 00:00:05,000
欢迎使用语音识别系统
时间戳信息
时间戳信息:
[001] 0.000s - 0.500s (时长: 0.500s)
[002] 0.500s - 2.500s (时长: 2.000s)
[003] 2.500s - 5.000s (时长: 2.500s)
常见问题
Q1:识别结果不准确怎么办?
解决方法:
- 确保选择正确的识别语言
- 检查音频质量,尽量使用清晰的录音
- 尝试调整音频音量
- 如果背景噪音大,可以后期降噪处理
Q2:识别速度慢怎么办?
可能原因:
- 使用的是 CPU 模式
- 音频文件过长
解决方法:
- 检查设备选择,确保使用 CUDA(GPU)
- 分段处理长音频
- 考虑使用 SenseVoice-Small 模型(速度更快)
Q3:无法上传音频文件?
检查:
- 文件格式是否支持(推荐 MP3/WAV)
- 文件大小是否过大(建议 < 100MB)
- 浏览器是否支持
Q4:录音没有声音?
检查:
- 浏览器是否授予麦克风权限
- 系统麦克风是否正常工作
- 麦克风音量是否打开
Q5:识别结果包含乱码?
解决方法:
- 确保选择正确的识别语言
- 检查音频编码是否正确
- 尝试重新转换音频格式
Q6:如何提高识别准确率?
建议:
- 使用高质量音频(16kHz 采样率)
- 减少背景噪音
- 清晰发音,适当语速
- 选择正确的识别语言
退出使用
停止 WebUI 服务
在终端中按 Ctrl + C 停止服务
或执行:
pkill -f "python.*app.main"
快捷键
| 操作 | 快捷键 |
|---|---|
| 停止服务 | Ctrl + C |
| 刷新页面 | F5 / Ctrl + R |
| 复制文本 | Ctrl + C |
技术支持
- 开发者: 科哥
- 微信: 312088415
- 问题反馈: 请提供详细的错误信息和操作步骤
镜像名称
- FunASR 语音识别 WebUI - SenseVoice Small 中文语音识别 构建by科哥
镜像简介
基于 FunASR 框架的中文语音识别 WebUI 系统,提供简洁易用的浏览器界面。
- 功能: 实时中文语音识别、音频文件转文字、多格式字幕输出(SRT/VTT)、时间戳标注
- 特点: 预装 SenseVoice Small 模型(893MB),支持 GPU 加速,一键启动 WebUI
核心特性
- 模型: iic/SenseVoiceSmall - 多语言 ASR 模型(中/日/韩/粤/英语)
- 界面: Gradio 6.0 现代化 WebUI,紫蓝渐变主题
- 输入方式: 支持音频文件上传 + 浏览器实时录音
- 输出格式: 纯文本、JSON、SRT 字幕、VTT 字幕
- 设备支持: 自动检测 CUDA/CPU,优先使用 GPU 加速
环境与依赖
- 基础镜像: continuumio/miniconda3 (Python 3.12)
- 深度学习框架: PyTorch 2.0+
- 核心依赖:
- FunASR >= 1.3.0
- ModelScope >= 1.0.0
- Gradio >= 6.0.0
- CUDA 11.8+ (GPU 加速)
- Python 包: numpy, scipy, librosa, soundfile, pyyaml, tqdm
模型存储
模型文件位于 /root/speech_ngram_lm_zh-cn/models/ 目录,包含:
iic/SenseVoiceSmall/- 主 ASR 模型(893MB)
目录结构
/root/speech_ngram_lm_zh-cn/
├── app/ # 应用核心代码
│ ├── main.py # WebUI 入口
│ ├── config.py # 配置管理
│ ├── models/ # 模型加载器
│ ├── pipeline/ # ASR 处理管道
│ ├── ui/ # UI 组件
│ └── utils/ # 工具函数
├── models/ # 模型存储目录(可迁移)
├── outputs/ # 输出文件目录
├── logs/ # 日志目录
└── start_app.sh # 启动脚本
配置方法
端口配置
默认端口:7860
可通过环境变量修改:
export WEBUI_PORT=8080
设备配置
自动检测 CUDA,优先使用 GPU。可通过环境变量强制使用 CPU:
export WEBUI_DEVICE=cpu
模型配置
默认使用 SenseVoice Small 模型。可通过环境变量更换:
export WEBUI_ASR_MODEL=iic/SenseVoiceSmall
启动方式
方式一:使用启动脚本(推荐)
cd /root/speech_ngram_lm_zh-cn
bash start_app.sh
方式二:直接启动
cd /root/speech_ngram_lm_zh-cn
conda activate py312
python -m app.main
方式三:Docker 容器启动
docker run -d \
--name funasr-webui \
--gpus all \
-p 7860:7860 \
-v $(pwd)/models:/root/speech_ngram_lm_zh-cn/models \
-v $(pwd)/outputs:/root/speech_ngram_lm_zh-cn/outputs \
your-image-name:latest
访问地址
启动成功后,在浏览器中访问:
http://localhost:7860
或
http://<服务器IP>:7860
环境验证代码
验证 Python 环境
conda activate py312
python --version # 应显示 Python 3.12.x
验证 CUDA 可用性
import torch
print(f"CUDA 可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU 设备: {torch.cuda.get_device_name(0)}")
验证 FunASR 安装
from funasr import AutoModel
print("FunASR 安装成功!")
快速测试模型加载
cd /root/speech_ngram_lm_zh-cn
python -c "
from app.models.loader import ModelLoader
from app.config import Config
loader = ModelLoader()
config = Config()
model = loader.load_asr_only(config)
print('模型加载成功!')
"
相关链接
- FunASR 官方文档: https://github.com/alibaba-damo-academy/FunASR
- ModelScope 模型库: https://modelscope.cn/models
- SenseVoice 模型: https://modelscope.cn/models/iic/SenseVoiceSmall
- Gradio 文档: https://www.gradio.app/docs
常见问题
Q1:启动时提示 "模型加载失败"? A1: 检查 models 目录是否存在且包含模型文件。首次启动会自动从 ModelScope 下载模型(约893MB)。
Q2:GPU 内存不足怎么办? A2: 可以设置环境变量强制使用 CPU:
export WEBUI_DEVICE=cpu
bash start_app.sh
Q3:如何更改模型语言识别设置? A3: 在 WebUI 界面的 "识别语言" 下拉框中选择:auto(自动)、zh(中文)、en(英文)、yue(粤语)、ja(日语)、ko(韩语)
Q4:输出文件保存在哪里?
A4: 输出文件保存在 outputs/outputs_YYYYMMDDHHMMSS/ 目录下,每次识别会创建带时间戳的新目录。
Q5:如何批量处理音频文件?
A5: 目前 WebUI 不支持批量处理。可以编写脚本循环调用 app.pipeline.asr_processor.ASRProcessor 或等待后续版本更新。
Q6:识别结果包含特殊标签怎么办?
A6: 已在代码中实现自动清理功能。如果仍有问题,请检查 app/pipeline/result_formatter.py 中的 _clean_sensevoice_tags() 方法。
Q7:端口 7860 被占用怎么办? A7: 启动脚本会自动检测并终止占用端口的进程。如需自定义端口,设置环境变量:
export WEBUI_PORT=8080
bash start_app.sh
Q8:如何迁移到其他服务器?
A8: 直接复制整个项目目录即可。模型存储在 models/ 目录下,无需重新下载。
版权信息
- 二次开发: 科哥 | 微信:312088415
- 原框架: Alibaba DAMO Academy FunASR
- 开源承诺: 永久开源使用 | 保留版权信息
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
 认证作者
认证作者
 支持自启动
支持自启动