Video-As-Prompt
统一语义控制的视频生成
 2
20元/小时
v1.0
Video-As-Prompt
我们介绍了 Video-As-Prompt (VAP),这是一种新的范式,将统一且可泛化的语义控制视频生成重新定义为情境生成。VAP 利用参考视频作为直接的语义提示,通过即插即用的 Mixture-of-Transformers (MoT) 专家引导冻结的视频扩散 Transformer (DiT)。这种架构防止灾难性遗忘,并由时间偏置的位置嵌入指导,消除虚假映射先验,实现稳健的情境检索。作为一个单一的统一模型,VAP 为开源方法设定了新的最先进水平,实现了 38.7% 的用户偏好率,可与领先的特定条件商业模型相媲美。VAP 强大的零样本泛化能力和对各种下游应用的支持,标志着向通用、可控视频生成的重要进步。
使用教程
0. 麻烦右上角点个收藏~

1. 在镜像详情界面点击“使用该镜像创建实例”
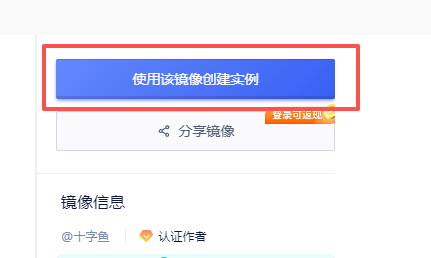
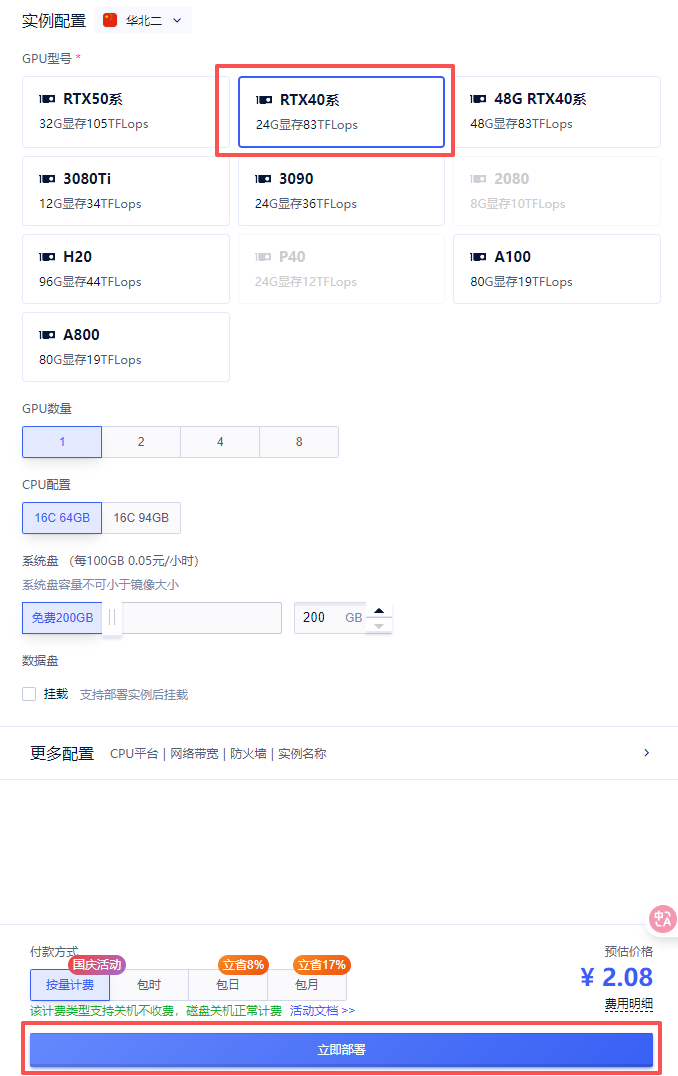
2. 选择GPU型号(目前只能选A800),再点击“立即部署”
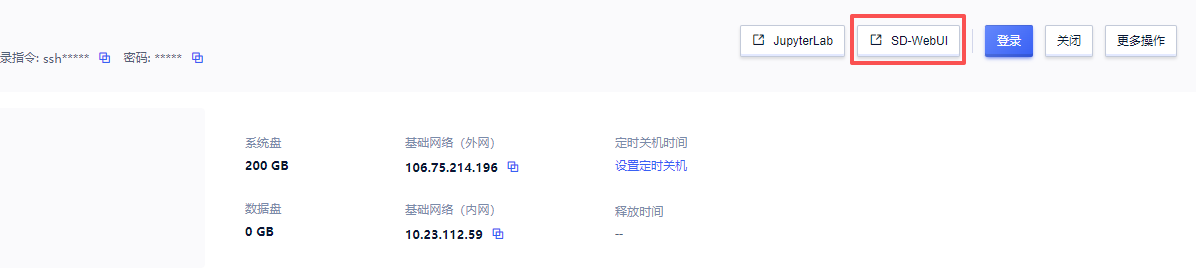
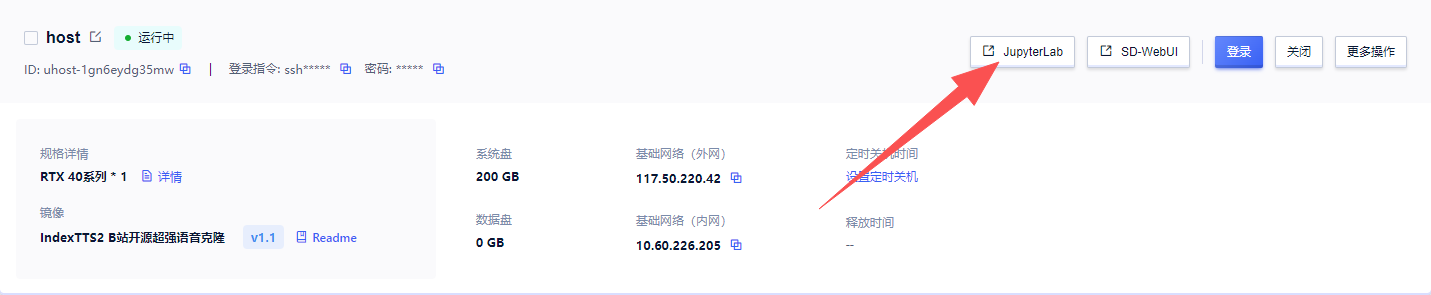
3. 实例启动后,在控制台中点击“SD-WebUI”
4.浏览器如图显示,就说明启动成功了
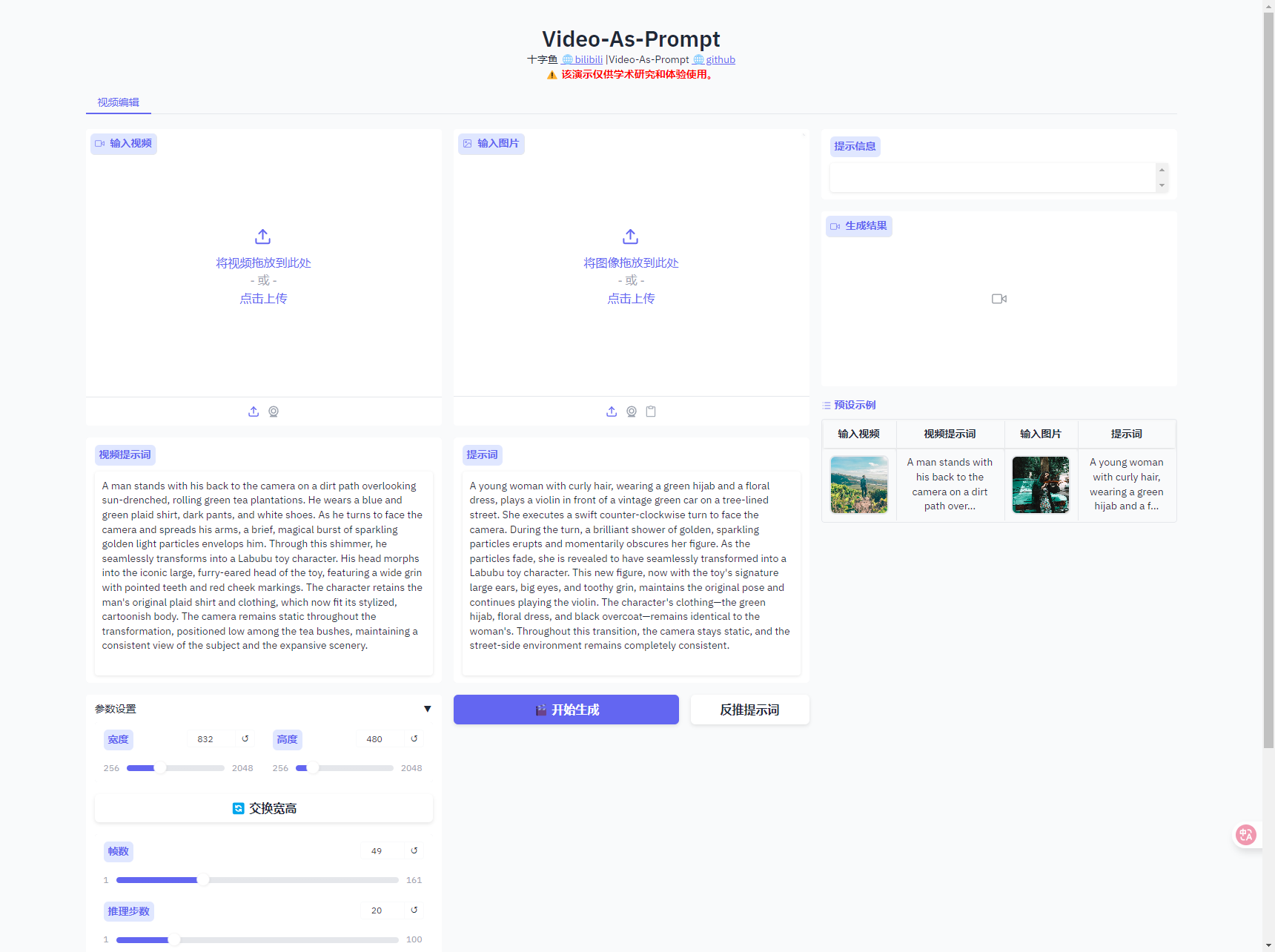
5.如果页面无响应,点击“JupyterLab”,再双击log.txt可查看启动进度
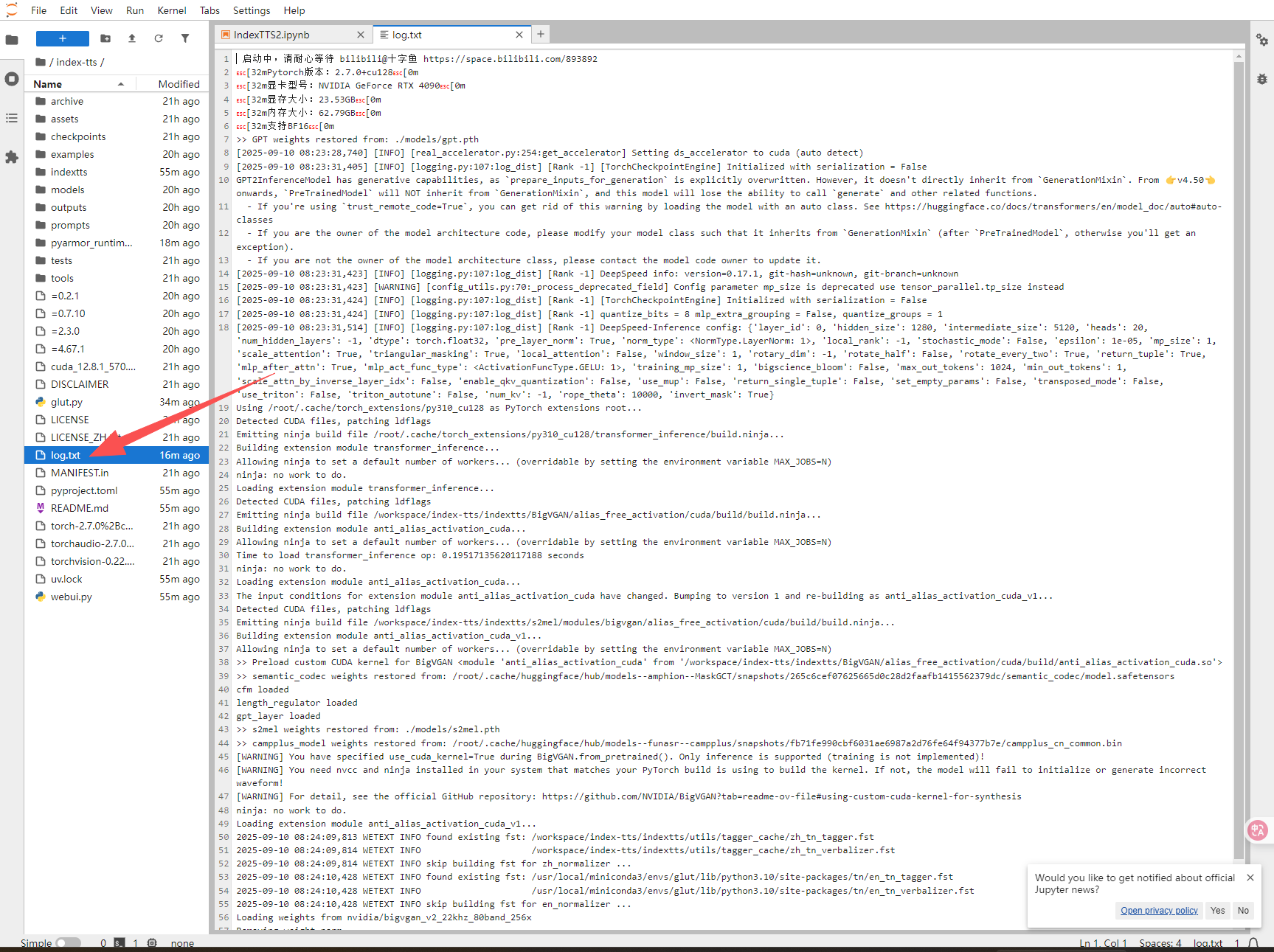
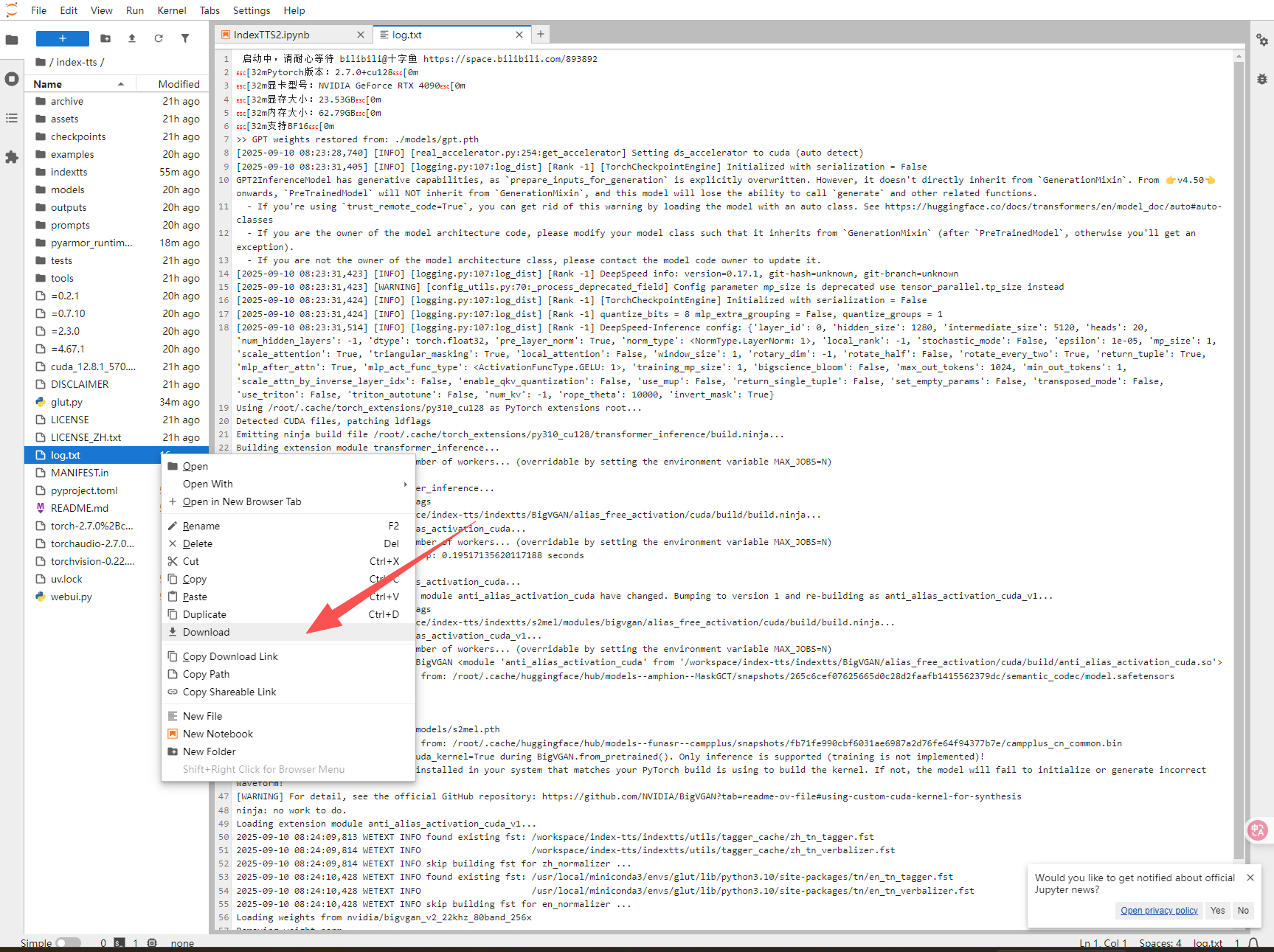
6.如果有报错的话,请下载log.txt发到下面的交流群中
十字鱼-镜像作者交流群

@十字鱼 认证作者
认证作者
认证作者
镜像信息
已使用1 次
运行时长
1 H
 支持自启动
支持自启动镜像大小
60GB
最后更新时间
2025-10-28
支持卡型
A800
+1
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.0
2025-10-28