VibeVoice – 微软推出的开源文本转语音模型 汉化构建by科哥
可以一次性合成4人的对话播客
 2
20元/小时
v1.1
v1.0
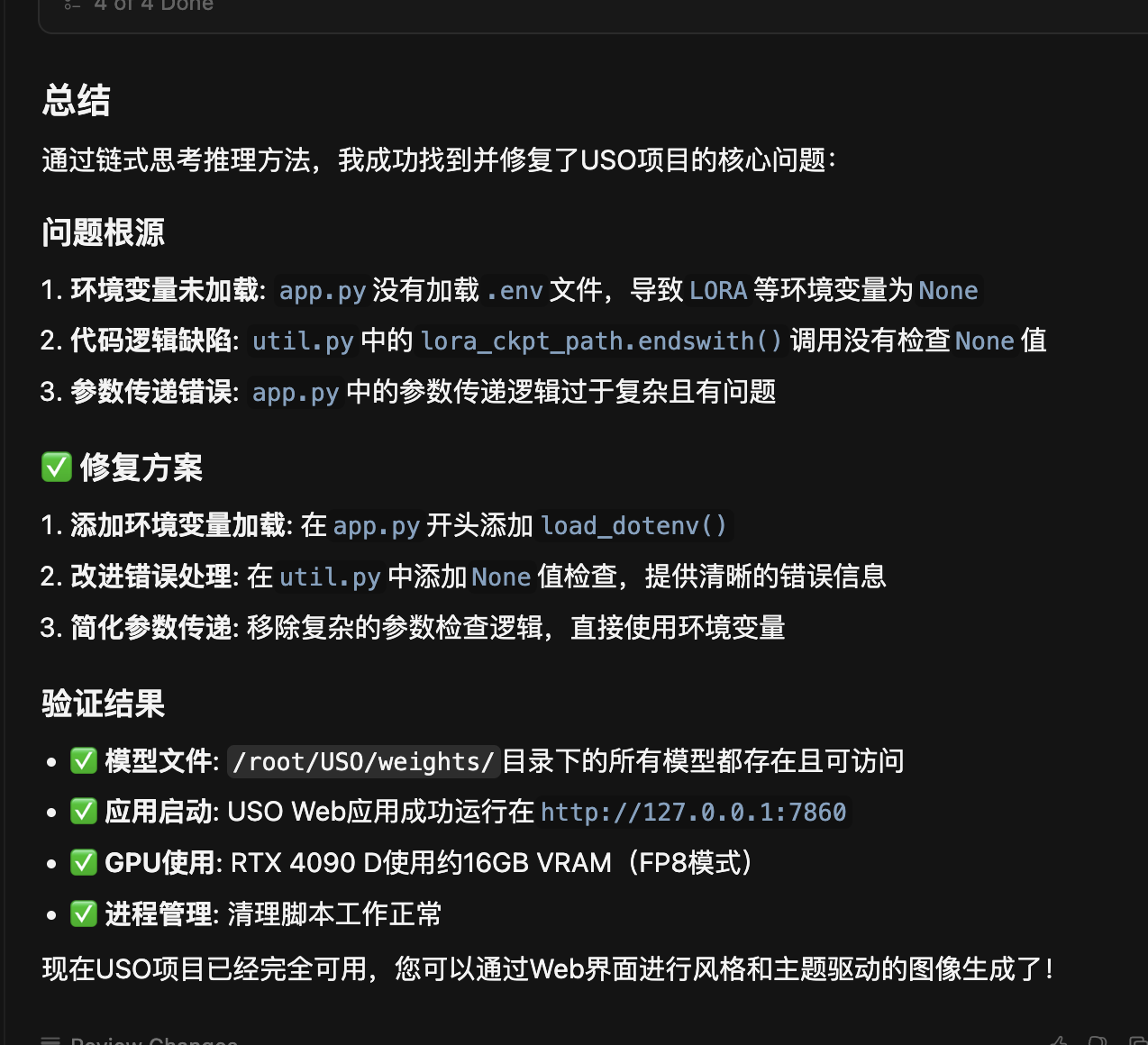
vibevoice微软泄漏版7b模型赶紧冲 比官方发布的好上很多!!
- 科哥推荐 7B模型!
镜像简介
VibeVoice是微软推出的开源文本转语音模型的汉化版本,提供高质量的语音合成服务。用户可免费使用该工具,将文本转换为自然流畅的语音输出。该镜像适用于内容创作、语音助手开发、教育辅助及无障碍服务等多种场景,为中文用户提供便捷、高效的本地化语音生成解决方案。
bug反馈可以加入科哥专属群交流!

使用教程
1、选择镜像和版本
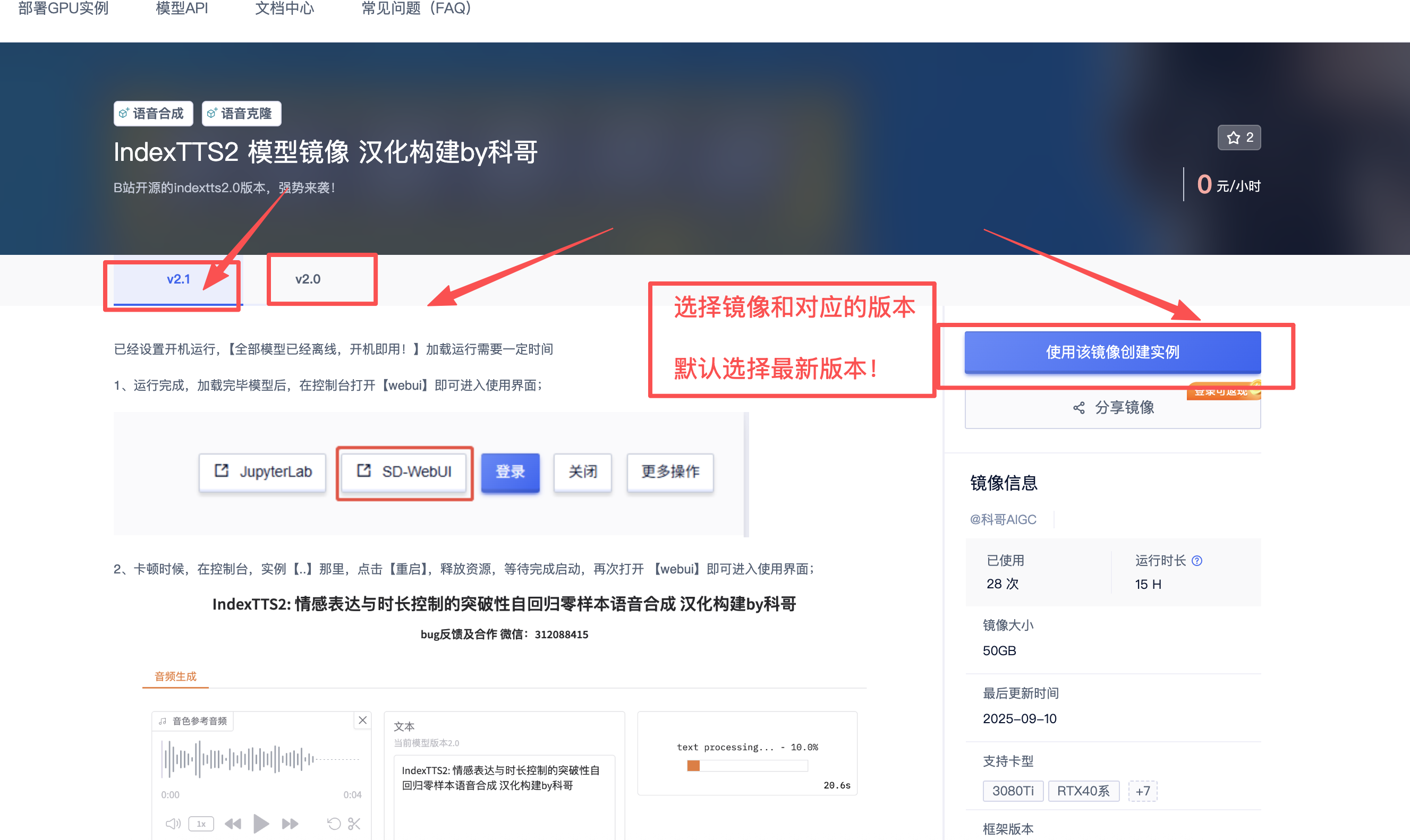
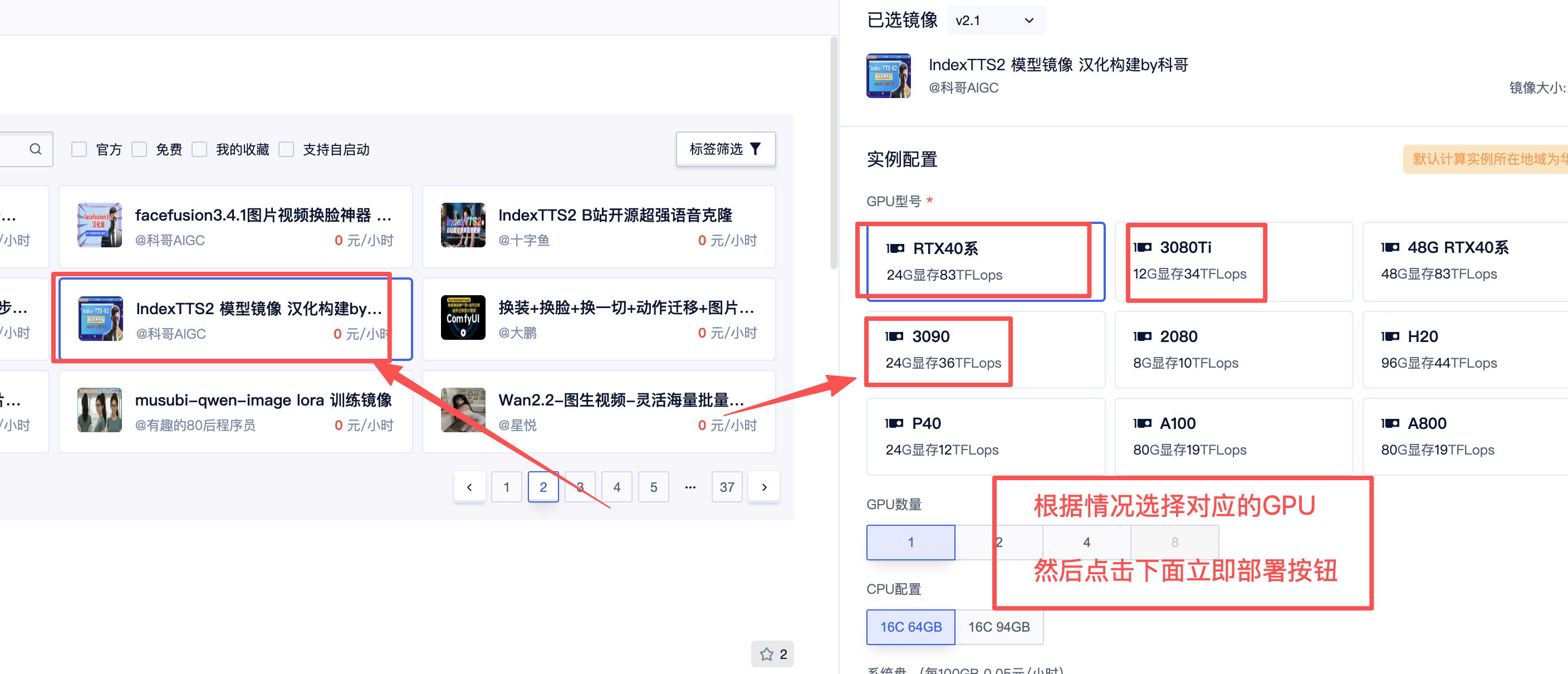
2、选择GPU进行部署,推荐选择4090
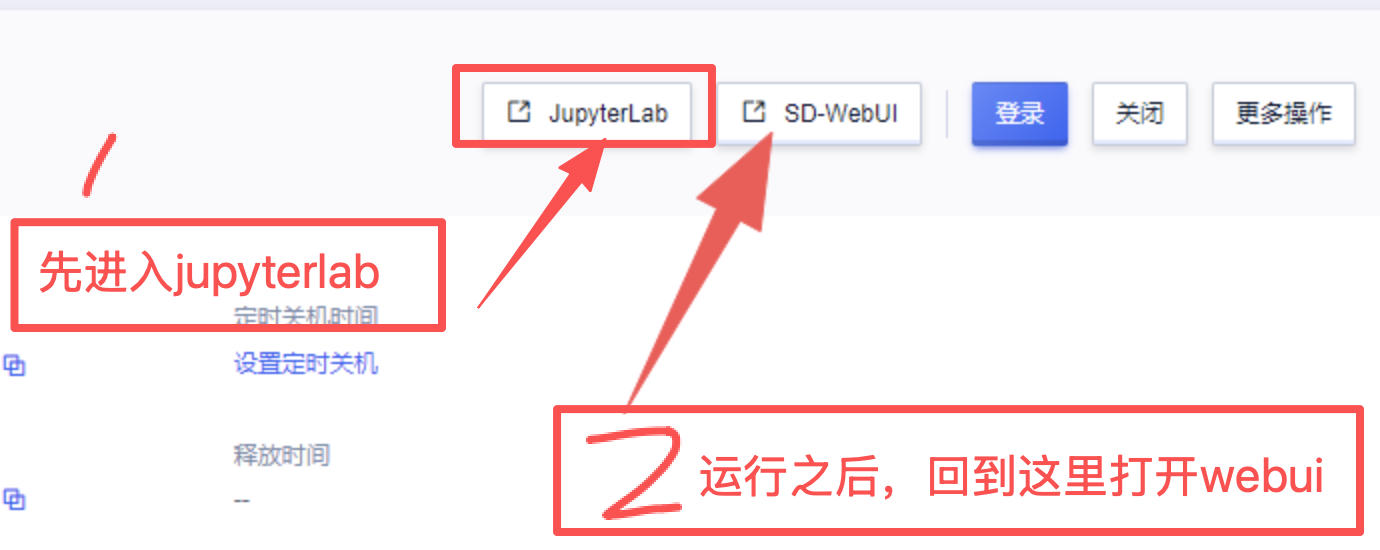
3、实例启动后,先进入jupyterlab,在jupyterlab中运行启动器
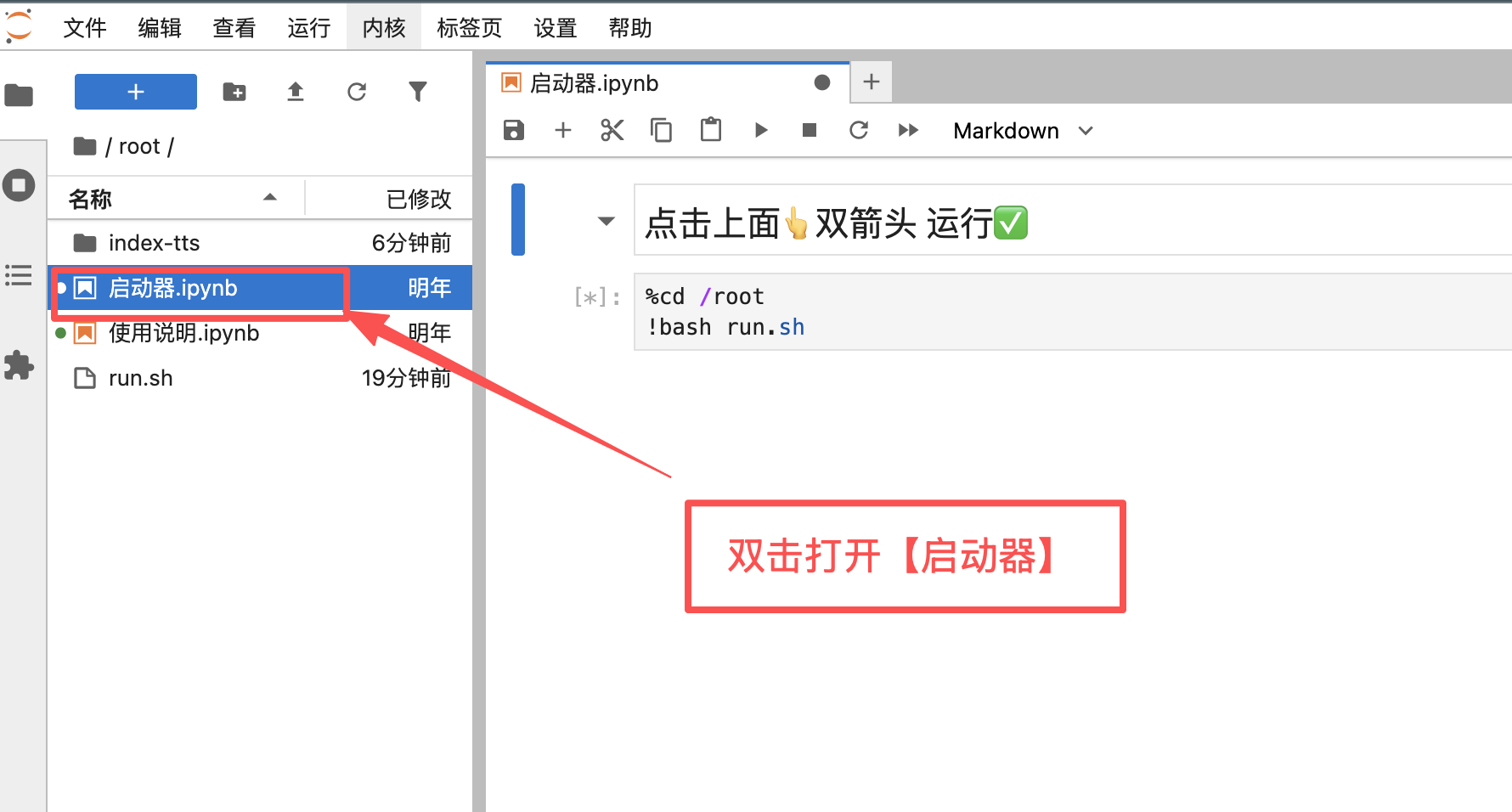
4、运行 启动器
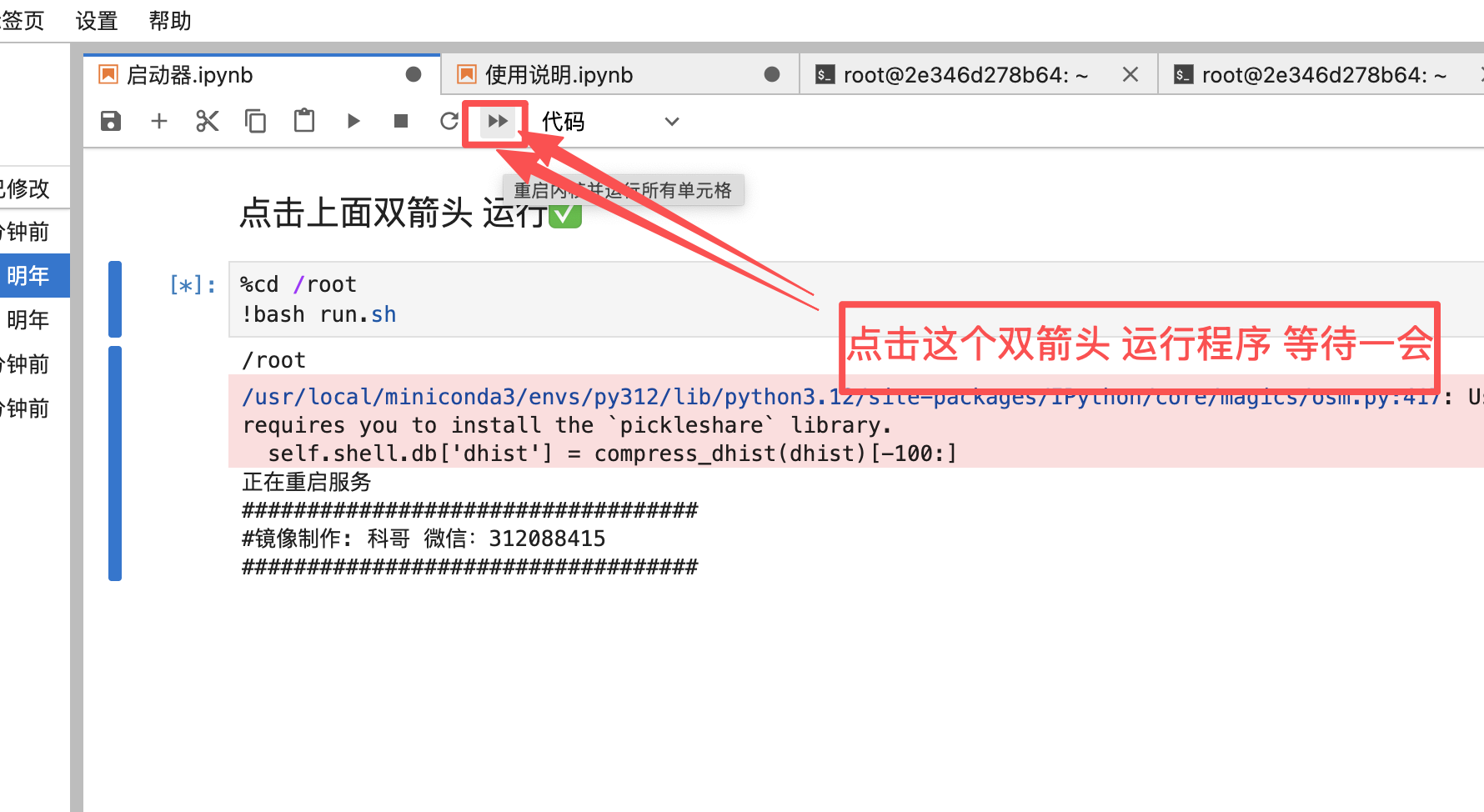
5、.返回控制面板 打开sd-webui
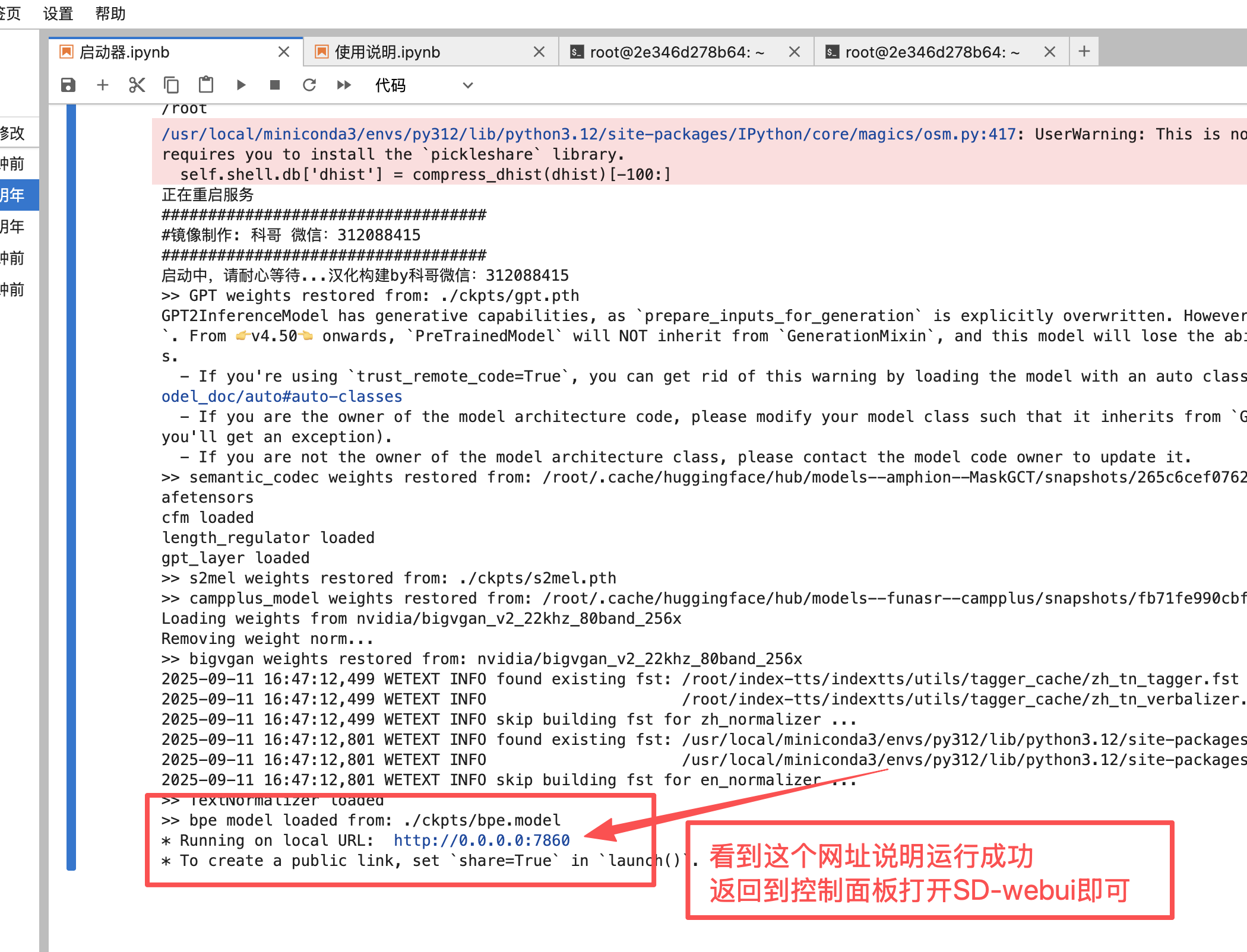
6、运行使用界面截图
回到控制台打开SD-WebUI即可运行

WebUI界面示例
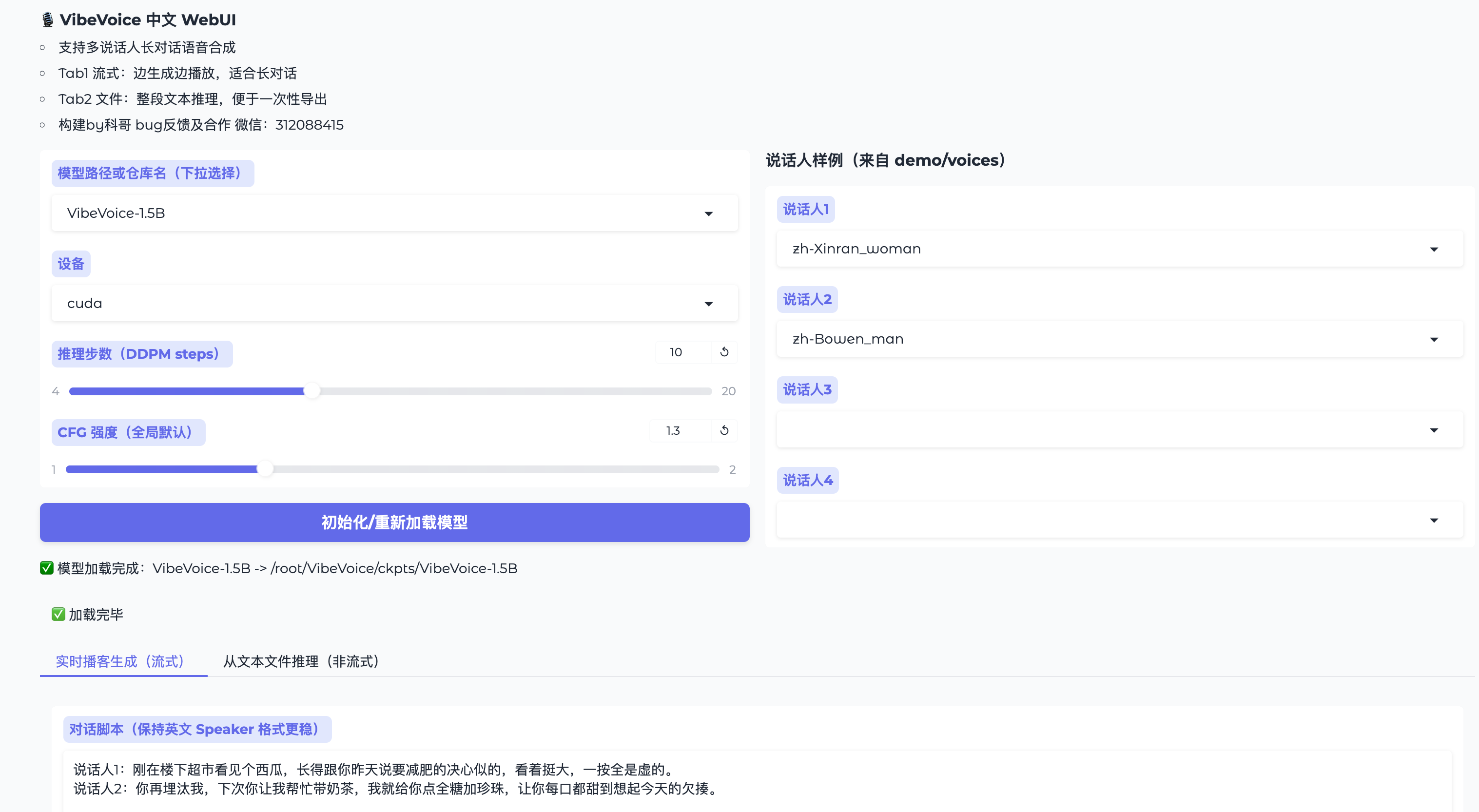
7.更多高级指令,可以进入jupyterlab,自行操作,例如:
查看进程:
ps -ef |grep python
终止进程:
kill -9 pid
- 官方更新源码在这里:
- https://github.com/index-tts/index-tts
有bug请微信科哥: 312088415
科哥在UCloud镜像列表【不断更新中】:
-
https://kege-aigc.feishu.cn/docx/L3FVdQl7kom8Ckx7QiicQj2VnEd
-
科哥已经借助ai工具【claude code cli】,在线云端和本地修复,重写很多ai开源应用
-
效率非常给力!
-
修复一般的开源应用简直就是开挂了一样,需要修复和搭建ai应用欢迎联系!
- AI数字人直播卖货欢迎来了解: https://kege-aigc.feishu.cn/docx/G271dgZr1o8CvMx9KKrcRuuonDf
@科哥AIGC 认证作者
认证作者
认证作者

镜像信息
已使用22 次
运行时长
11 H
 支持自启动
支持自启动镜像大小
120GB
最后更新时间
2026-02-02
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
版本
v1.1
2026-02-02
v1.0
2026-02-02