 11
11AI音乐制作-ACE-Step-1.5
镜像简介
本镜像为专业级AI音乐制作项目ACE-Step-1.5官方包,集成音乐生成、语音分离与识别等核心功能,支持从创作、编辑到后期处理的全流程音乐制作。适用于音乐人、制作人及内容创作者进行AI辅助作曲、音轨分离及音频内容分析,提供开源且开箱即用的专业音乐AI解决方案。
更新说明
修复反推报错,升级到2月11日版
教学视频
镜像部署说明
点击右侧“使用该镜像创建实例”
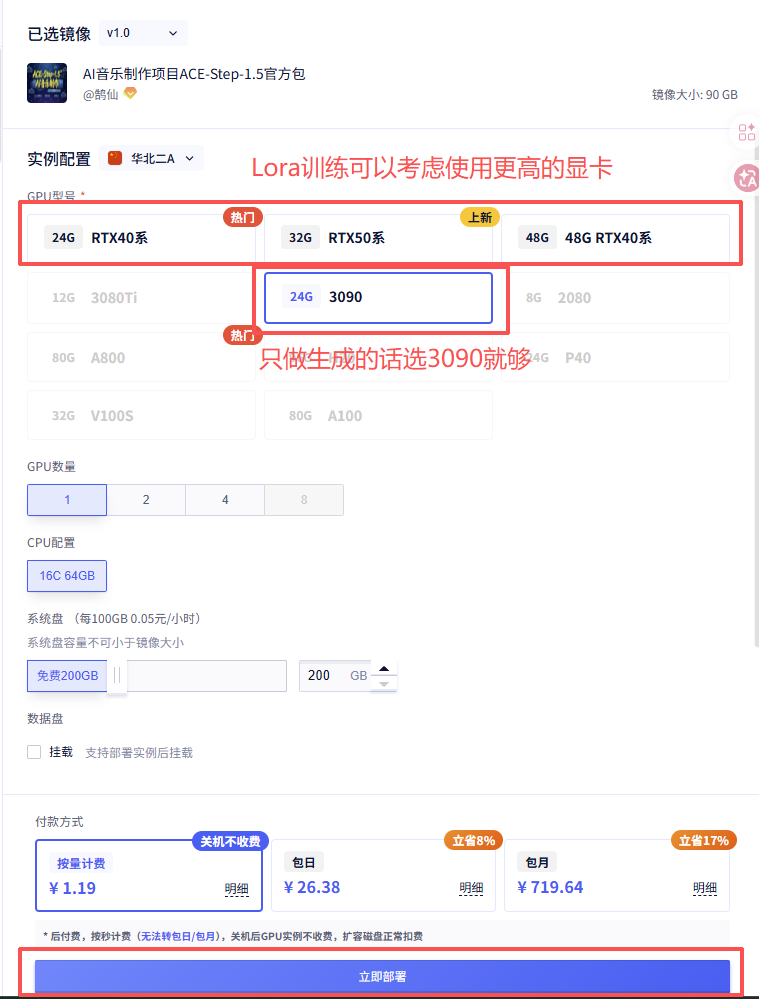 选择显卡,点击立即部署
选择显卡,点击立即部署
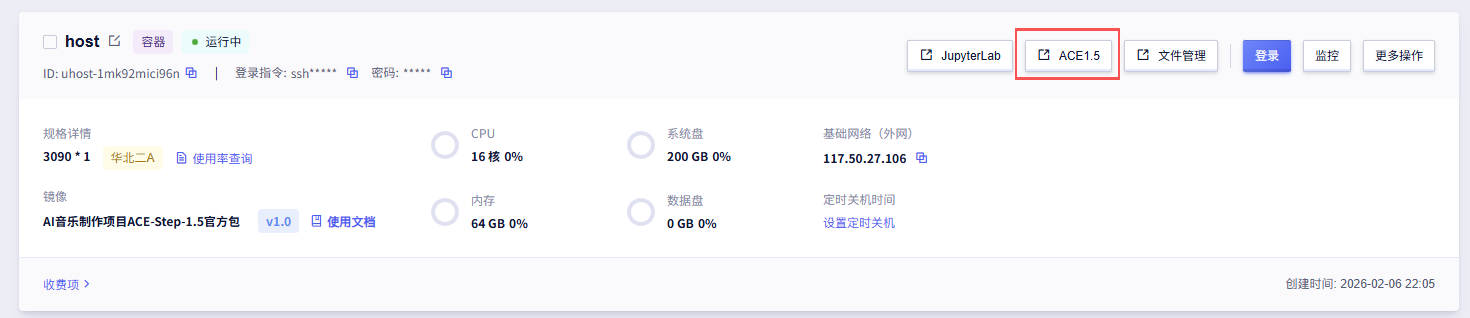
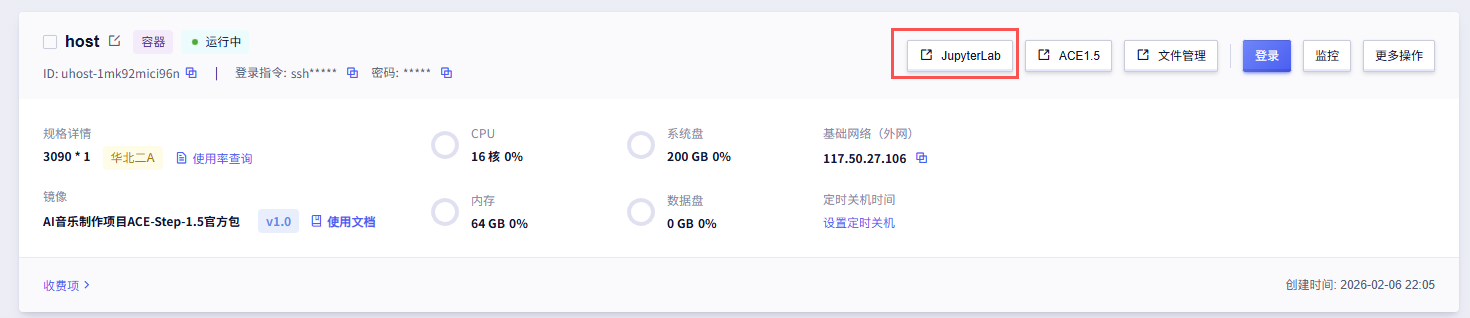 打开后台
打开后台
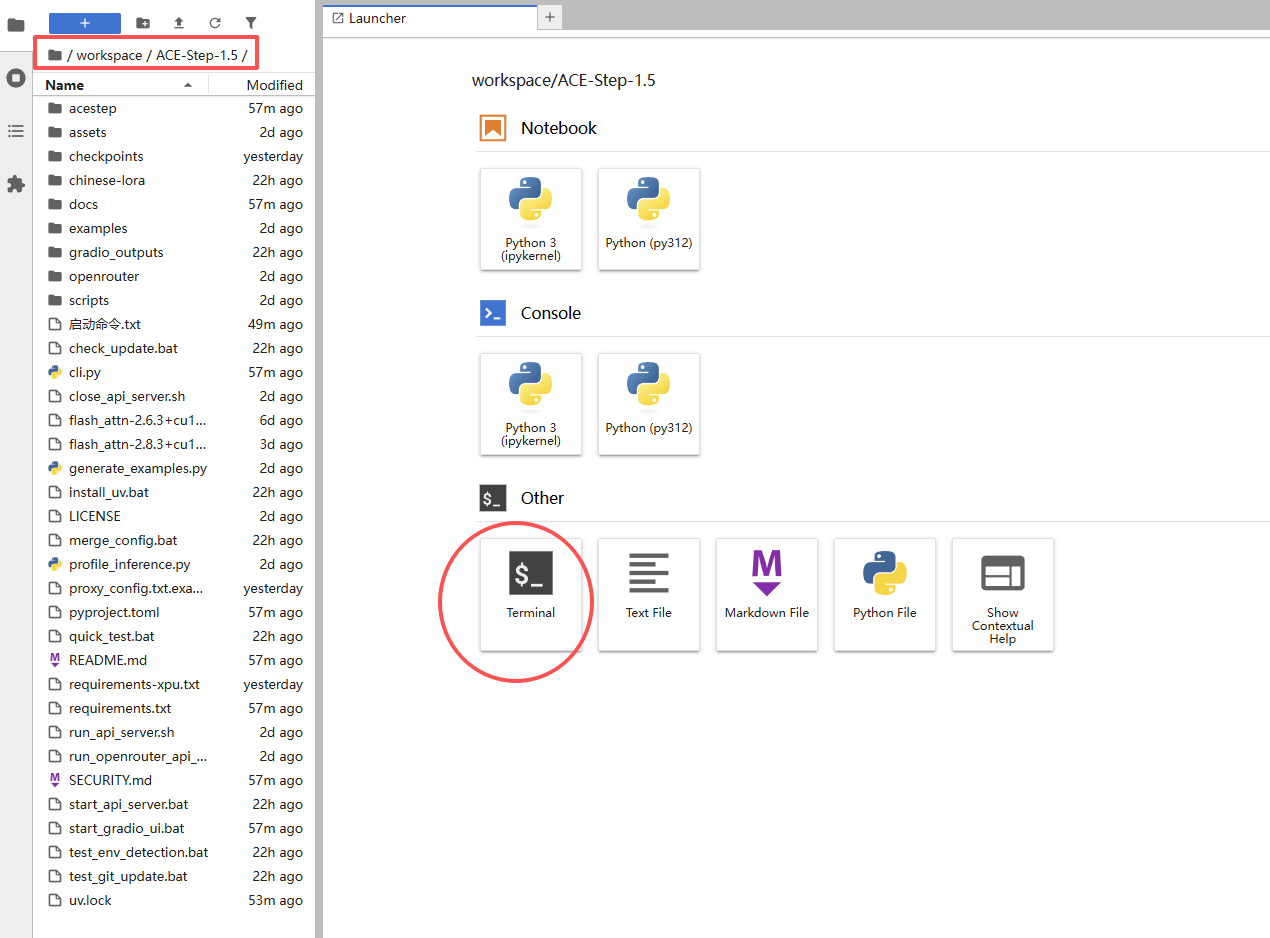 在ACE目录下,点击termial
在ACE目录下,点击termial
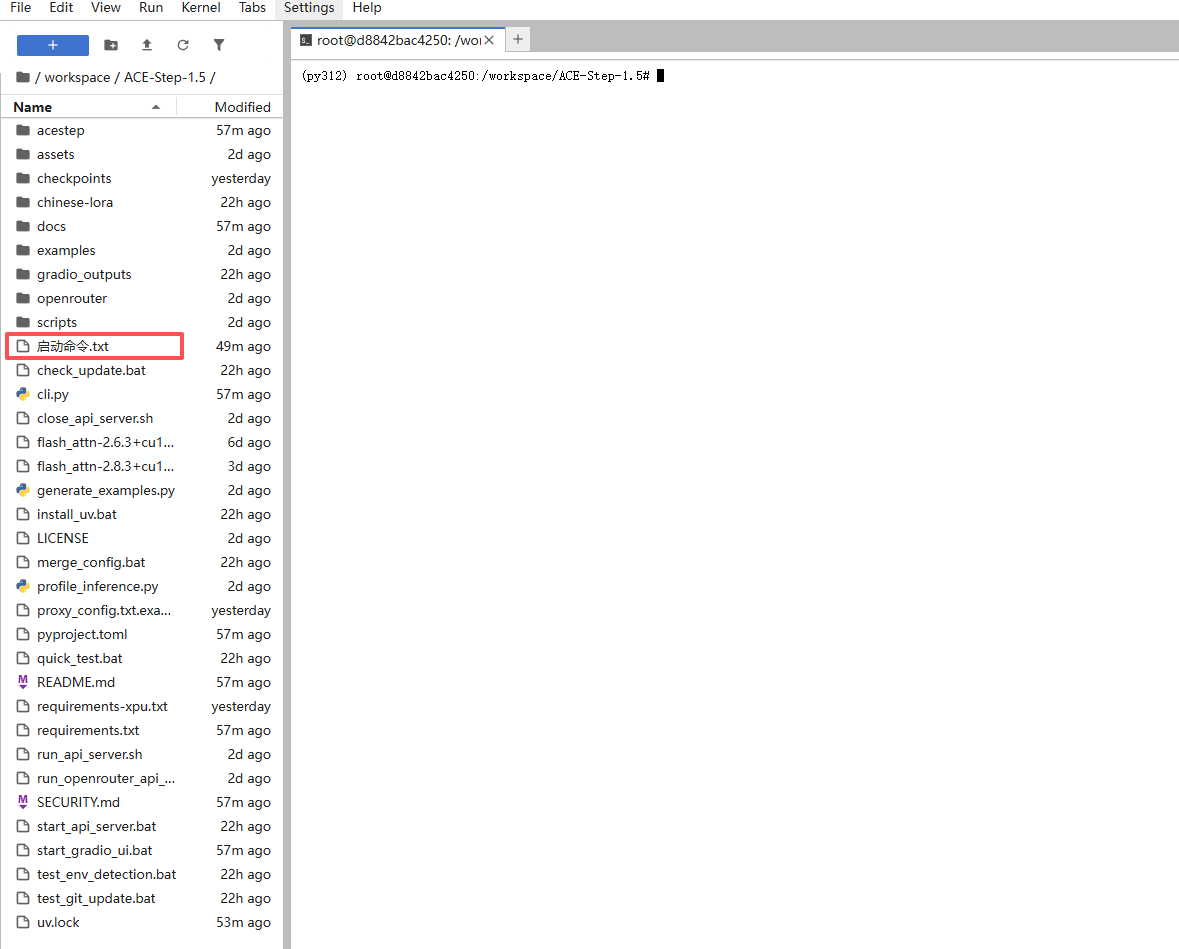 同时打开启动命令
同时打开启动命令
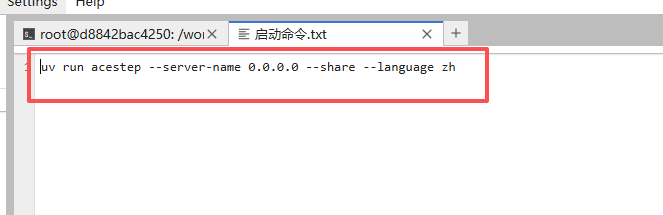

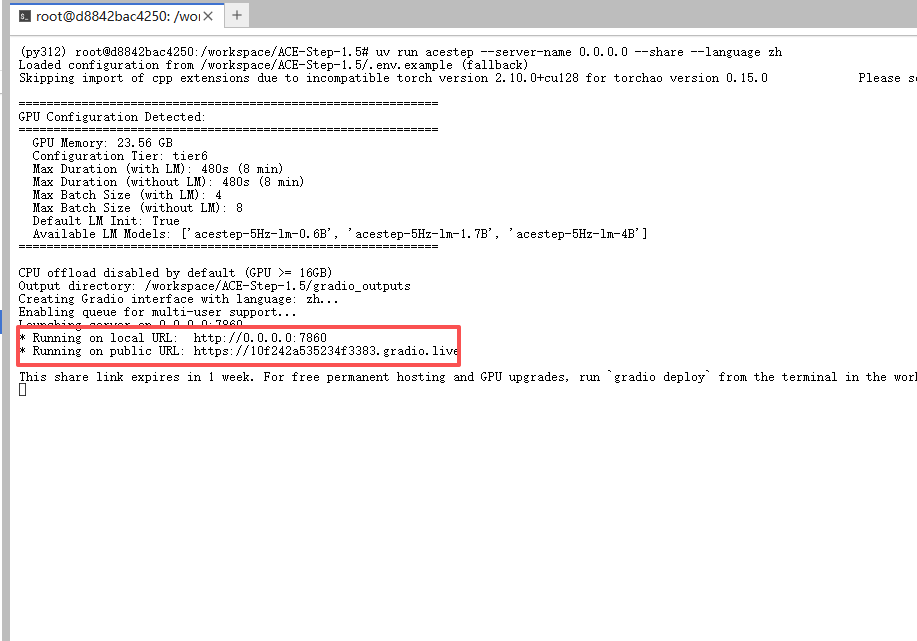 等待7860出现,回到实例列表,点击ACE1.5
等待7860出现,回到实例列表,点击ACE1.5
生成模式
简单模式
使用方法:
- 在生成模式单选按钮中选择"简单"
- 在"歌曲描述"字段中输入自然语言描述
- 如果不想要人声,可选择勾选"纯音乐"
- 可选择首选人声语言
- 点击 创建样本 生成 caption、歌词和元数据
- 在展开的部分中查看生成的内容
- 点击 生成音乐 创建音频
示例描述:
- "一首适合安静夜晚的柔和孟加拉情歌"
- "欢快的电子舞曲,重低音"
- "忧郁的独立民谣,原声吉他"
- "在烟雾弥漫的酒吧里演奏的爵士三重奏"
随机样本: 点击 🎲 按钮加载随机示例描述。
自定义模式
自定义模式提供对所有生成参数的完全控制。
使用方法:
- 在生成模式单选按钮中选择"自定义"
- 手动填写 Caption 和歌词字段
- 设置可选元数据(BPM、调性、时长等)
- 可选点击 格式化 使用 LM 增强您的输入
- 根据需要配置高级设置
- 点击 生成音乐 创建音频
任务类型
text2music(默认)
从文本描述和/或歌词生成音乐。
用例: 基于提示从头创建新音乐。
必需输入: Caption 或歌词(至少一个)
cover
转换现有音频,保持结构但改变风格。
用例: 创建不同风格的翻唱版本。
必需输入:
- 源音频(在音频上传区域上传)
- 描述目标风格的 Caption
关键参数: 音频翻唱强度(0.0-1.0)
- 较高的值保持更多原始结构
- 较低的值允许更多创意自由
repaint
重新生成音频的特定时间段。
用例: 修复或修改生成音乐的特定部分。
必需输入:
- 源音频
- 重绘开始(秒)
- 重绘结束(秒,-1 表示文件末尾)
- 描述期望内容的 Caption
lego(仅 Base 模型)
在现有音频的上下文中生成特定乐器轨道。
用例: 为伴奏添加乐器层。
必需输入:
- 源音频
- 轨道名称(从下拉菜单选择)
- 描述轨道特征的 Caption
可用轨道: vocals、backing_vocals、drums、bass、guitar、keyboard、percussion、strings、synth、fx、brass、woodwinds
extract(仅 Base 模型)
从混音音频中提取/分离特定乐器轨道。
用例: 音轨分离、分离乐器。
必需输入:
- 源音频
- 要提取的轨道名称
complete(仅 Base 模型)
用指定的乐器完成部分轨道。
用例: 自动编排不完整的作品。
必需输入:
- 源音频
- 轨道名称(多选)
- 描述期望风格的 Caption
输入参数
必需输入
任务类型
从下拉菜单选择生成任务。指令字段会根据选择的任务自动更新。
音频上传
| 字段 | 说明 |
|---|---|
| 参考音频 | 用于风格参考的可选音频 |
| 源音频 | cover、repaint、lego、extract、complete 任务必需 |
| 转换为代码 | 从源音频提取 5Hz 语义代码 |
LM 代码提示
可以在此粘贴预计算的音频语义代码来引导生成。使用 转录 按钮分析代码并提取元数据。
音乐描述
期望音乐的文本描述。请具体说明:
- 风格和类型
- 乐器
- 情绪和氛围
- 节奏感(如果不指定 BPM)
示例: "欢快的流行摇滚,电吉他、有力的鼓点和朗朗上口的合成器钩子"
点击 🎲 加载随机示例 caption。
歌词
输入带结构标签的歌词:
[Verse 1]
今天走在街上
想着你曾说过的话
[Chorus]
我在前进,我很坚强
这就是我属于的地方
[Verse 2]
...
纯音乐复选框: 勾选此项以生成纯音乐,无论歌词内容如何。
人声语言: 选择人声语言。对于自动检测或纯音乐,使用"unknown"。
格式化按钮: 点击使用 5Hz LM 增强 caption 和歌词。
可选参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| BPM | 自动 | 每分钟节拍数(30-300) |
| 调性 | 自动 | 音乐调性(例如"C Major"、"Am"、"F# minor") |
| 拍号 | 自动 | 拍号:2(2/4)、3(3/4)、4(4/4)、6(6/8) |
| 音频时长 | 自动/-1 | 目标长度(秒)(10-600)。-1 为自动 |
| 批量大小 | 2 | 要生成的音频变体数量(1-8) |
高级设置
DiT 参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| 推理步数 | 8 | 去噪步数。Turbo:1-20,Base:1-200 |
| 引导比例 | 7.0 | CFG 强度(仅 base 模型)。越高 = 越遵循提示 |
| 种子 | -1 | 随机种子。批量使用逗号分隔的值 |
| 随机种子 | ✓ | 勾选时生成随机种子 |
| 音频格式 | mp3 | 输出格式:mp3、flac |
| 偏移 | 3.0 | 时间步偏移因子(1.0-5.0)。turbo 推荐 3.0 |
| 推理方法 | ode | ode(Euler,更快)或 sde(随机) |
| 自定义时间步 | - | 覆盖时间步(例如"0.97,0.76,0.615,0.5,0.395,0.28,0.18,0.085,0") |
仅 Base 模型参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| 使用 ADG | ✗ | 启用自适应双引导以获得更好的质量 |
| CFG 区间开始 | 0.0 | 何时开始应用 CFG(0.0-1.0) |
| CFG 区间结束 | 1.0 | 何时停止应用 CFG(0.0-1.0) |
LM 参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| LM 温度 | 0.85 | 采样温度(0.0-2.0)。越高 = 越有创意 |
| LM CFG 比例 | 2.0 | LM 引导强度(1.0-3.0) |
| LM Top-K | 0 | Top-K 采样。0 禁用 |
| LM Top-P | 0.9 | 核采样(0.0-1.0) |
| LM 负面提示 | "NO USER INPUT" | CFG 的负面提示 |
CoT(思维链)选项
| 选项 | 默认值 | 说明 |
|---|---|---|
| CoT Metas | ✓ | 通过 LM 推理生成元数据 |
| CoT Language | ✓ | 通过 LM 检测人声语言 |
| 约束解码调试 | ✗ | 启用调试日志 |
生成选项
| 选项 | 默认值 | 说明 |
|---|---|---|
| LM 代码强度 | 1.0 | LM 代码对生成的影响程度(0.0-1.0) |
| 自动评分 | ✗ | 自动计算质量分数 |
| 自动 LRC | ✗ | 自动生成歌词时间戳 |
| LM 批处理块大小 | 8 | 每个 LM 批次的最大项目数(GPU 内存) |
主要生成控制
| 控制 | 说明 |
|---|---|
| Think | 启用 5Hz LM 进行代码生成和元数据 |
| ParallelThinking | 启用并行 LM 批处理 |
| CaptionRewrite | 让 LM 增强输入 caption |
| AutoGen | 完成后自动开始下一批次 |
结果区域
生成的音频
根据批量大小最多显示 8 个音频样本。每个样本包括:
- 音频播放器 - 播放、暂停和下载生成的音频
- 发送到源 - 将此音频发送到源音频输入以进行进一步处理
- 保存 - 将音频和元数据保存到 JSON 文件
- 评分 - 计算基于困惑度的质量分数
- LRC - 生成歌词时间戳(LRC 格式)
详情折叠面板
点击"评分 & LRC & LM 代码"展开并查看:
- LM 代码 - 此样本的 5Hz 语义代码
- 质量分数 - 基于困惑度的质量指标
- 歌词时间戳 - LRC 格式的时间数据
批次导航
| 控制 | 说明 |
|---|---|
| ◀ 上一批 | 查看上一批 |
| 批次指示器 | 显示当前批次位置(例如"批次 1 / 3") |
| 下一批状态 | 显示后台生成进度 |
| 下一批 ▶ | 查看下一批(如果 AutoGen 开启则触发生成) |
恢复参数
点击 应用这些设置到 UI 将当前批次的所有生成参数恢复到输入字段。适用于迭代优化好的结果。
批次结果
"批次结果和生成详情"折叠面板包含:
- 所有生成的文件 - 下载所有批次的所有文件
- 生成详情 - 关于生成过程的详细信息
 认证作者
认证作者
