 5
5谷歌最新本地模型gemma4最强智能助理hermes agent一个本地免token的智能助理模型全部离线
升级中文版webUI 模型默认是gemma:e4b
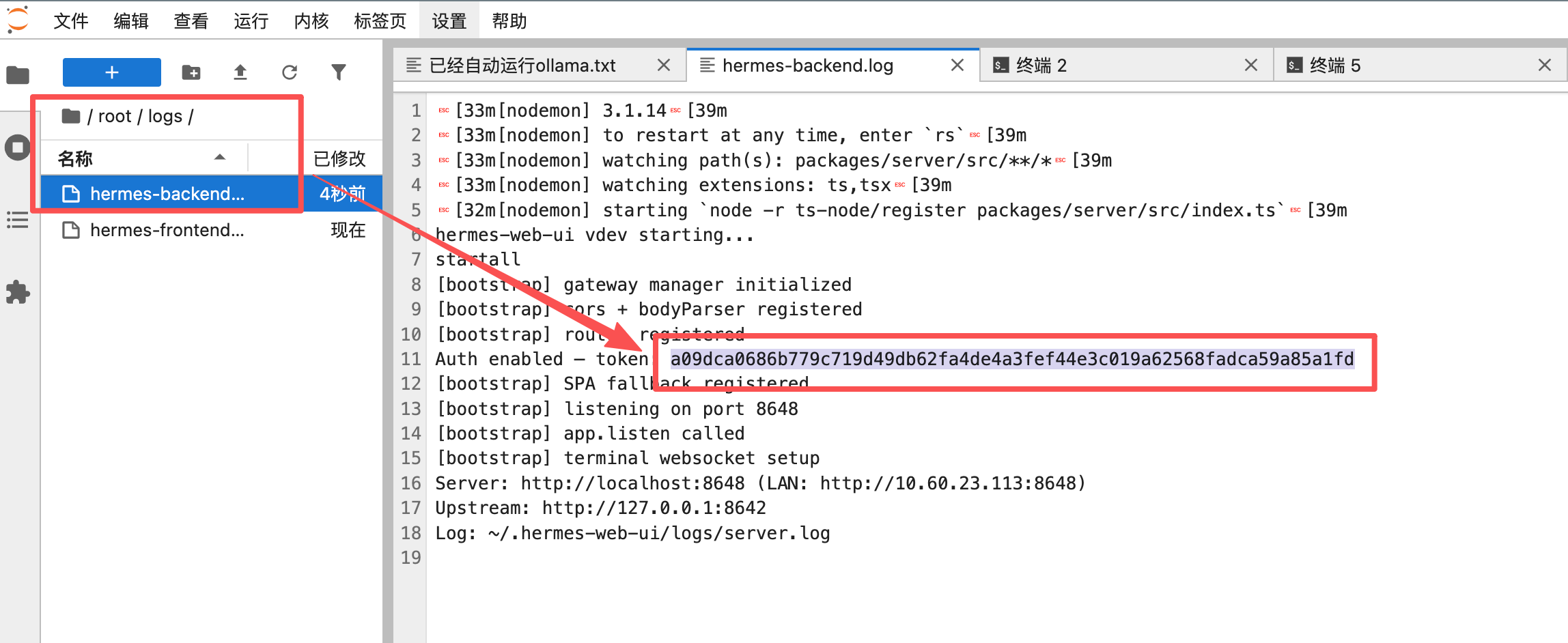
密钥路径:/root/logs/hermes-backend.log
支持webUI打开进行使用 更加简易
- 已经自动运行ollama服务及hermes agent智能助手
- 在控制面板打开【SD-WebUI】即可使用智能助手!
一、运行ollama也可以手动执行:
cd /root && bash run.sh
webUI运行界面截图:
以上指令都是在【jupyterlab】,然后打开【终端】输入回车执行!
打开webUI可以切换模型:全部模型均可使用 e2b速度最快 31B最聪明
/model gemma4:e2b # 切换到 e2b 版本(7.2GB,轻量) /model gemma4:26b # 切换到 26B 版本(19GB,当前默认) /model gemma4:31b # 切换到 31B 版本(19GB)
以上指令都是在【jupyterlab】,然后打开【终端】输入回车执行!
进入hermes里面切换模型: 切换 Ollama 本地模型示例
/model gemma4:e2b # 切换到 e2b 版本(7.2GB,轻量) /model gemma4:26b # 切换到 26B 版本(19GB,当前默认) /model gemma4:31b # 切换到 31B 版本(19GB)
-
源码地址:
Hermes Web UI 用户使用手册
一、简介
Hermes Web UI 是 Hermes Agent 的 Web 管理界面,提供 AI 聊天、会话管理、平台渠道配置、定时任务、 Usage 统计等功能。
二、快速启动
2.1 启动服务
/root/hermes-web-ui/start_app.sh
启动成功后显示:
前端 Web UI: http://localhost:7860
后端服务: http://localhost:8648
Hermes Agent: http://localhost:8642
2.2 登录
- 打开浏览器访问 http://localhost:7860
- 输入访问令牌(首次启动时在日志中查看)
grep token /root/logs/hermes-backend.log - 登录后,左下角应显示"已连接"
2.3 停止服务
# 停止所有服务
lsof -ti :7860 | xargs -r kill -9
lsof -ti :8648 | xargs -r kill -9
lsof -ti :8642 | xargs -r kill -9
三、主要功能
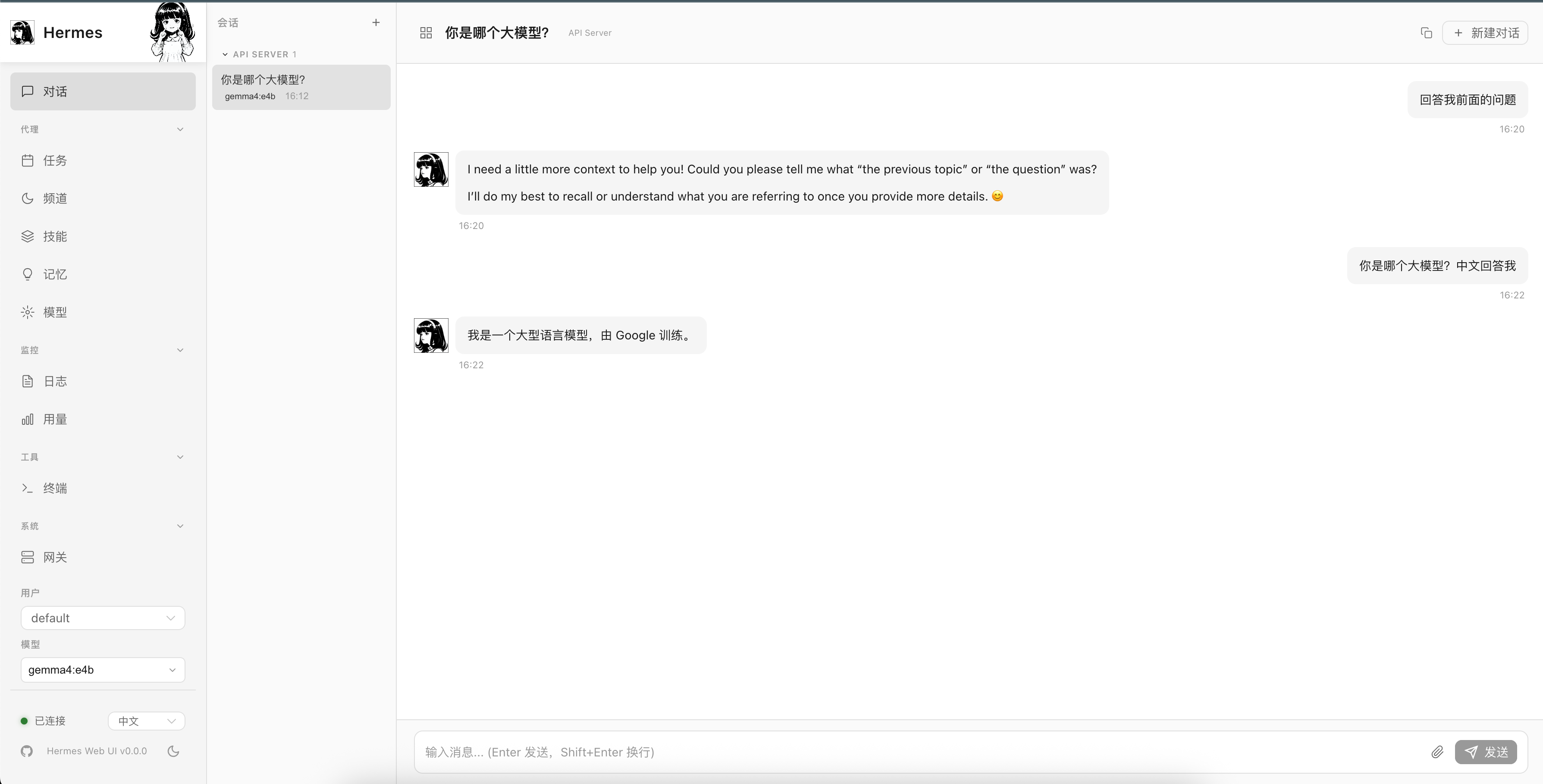
3.1 AI 聊天 (Chat)
位置:左侧菜单 Chat
功能:
- 新建会话:点击右上角 "+" 按钮
- 切换模型:顶部模型选择器,选择 gemma4:e4b
- 发送消息:在输入框输入内容,按 Enter 或点击发送按钮
- 代码高亮:代码块自动语法高亮,点击可复制
- 工具调用:展开查看工具调用详情
会话管理:
- 左侧栏显示所有会话,按最新消息时间排序
- 支持重命名、删除会话
- 按消息来源(Telegram、Discord 等)分组显示
3.2 平台渠道 (Channels)
位置:左侧菜单 Channels
支持的平台:
| 平台 | 说明 |
|---|---|
| Telegram | 配置 Bot Token、提及控制、反应 |
| Discord | 配置 Bot Token、自动创建线程、反应 |
| Slack | 配置 Bot Token、消息处理 |
| 启用/禁用、提及控制 | |
| Matrix | Access Token、 homeserver 配置 |
| Feishu (飞书) | App ID / Secret |
| 二维码登录 | |
| WeCom | 企业微信 Bot ID / Secret |
配置步骤:
- 选择要配置的平台
- 填写平台提供的凭证信息
- 设置行为选项(提及控制、自动化等)
- 保存后 Gateway 自动重启
3.3 定时任务 (Jobs)
位置:左侧菜单 Jobs
功能:
- 创建任务:点击 "+" 按钮
- 设置 Cron 表达式:选择预设或自定义
- 立即执行:点击执行按钮测试
- 管理任务:暂停、恢复、编辑、删除
常用 Cron 预设:
| 预设 | 表达式 | 说明 |
|---|---|---|
| 每小时 | 0 * * * * | 每小时整点 |
| 每天早上9点 | 0 9 * * * | 每天 9:00 |
| 每周一 | 0 9 * * 1 | 每周一 9:00 |
3.4 模型管理 (Models)
位置:左侧菜单 Models
功能:
- 查看可用模型:从已配置的凭证中自动发现
- 添加自定义 Provider:支持 OpenAI 兼容的 API
- 设置默认模型:选择默认使用的模型
当前配置:
- 默认模型:
gemma4:e4b(来自本地 Ollama) - Provider:自定义 (localhost:11434)
3.5 使用统计 (Usage)
位置:左侧菜单 Usage
显示内容:
- Token 使用总量(输入/输出)
- 会话数量及日均
- 预估费用
- 缓存命中率
- 模型使用分布图
- 30天趋势图
3.6 技能 (Skills)
位置:左侧菜单 Skills
功能:
- 浏览已安装的技能
- 查看技能详情
- 管理用户笔记
3.7 记忆 (Memory)
位置:左侧菜单 Memory
功能:
- 用户画像管理
- 对话记忆配置
- 字符限制设置
3.8 网关管理 (Gateways)
位置:左侧菜单 Gateways
功能:
- 查看网关状态(运行中/已停止)
- 启动/停止网关
- 多 Profile 切换
3.9 设置 (Settings)
位置:左侧菜单 Settings
子菜单:
- Display:显示设置(流式输出、紧凑模式、推理显示、成本显示)
- Agent:代理设置(最大轮次、超时、工具强制)
- Memory:记忆设置(启用/禁用、字符限制)
- Session Reset:会话重置(空闲超时、定时重置)
- Privacy:隐私设置(PII 脱敏)
- Model:模型设置(默认模型和 Provider)
- Platform:平台设置
3.10 日志 (Logs)
位置:左侧菜单 Logs
功能:
- 查看 Agent / Gateway / Error 日志
- 按日志级别筛选
- 按关键词搜索
- 格式化日志解析
3.11 终端 (Terminal)
位置:左侧菜单 Terminal
功能:
- Web 集成终端
- 多会话支持
- 实时输入输出
- 窗口大小调整
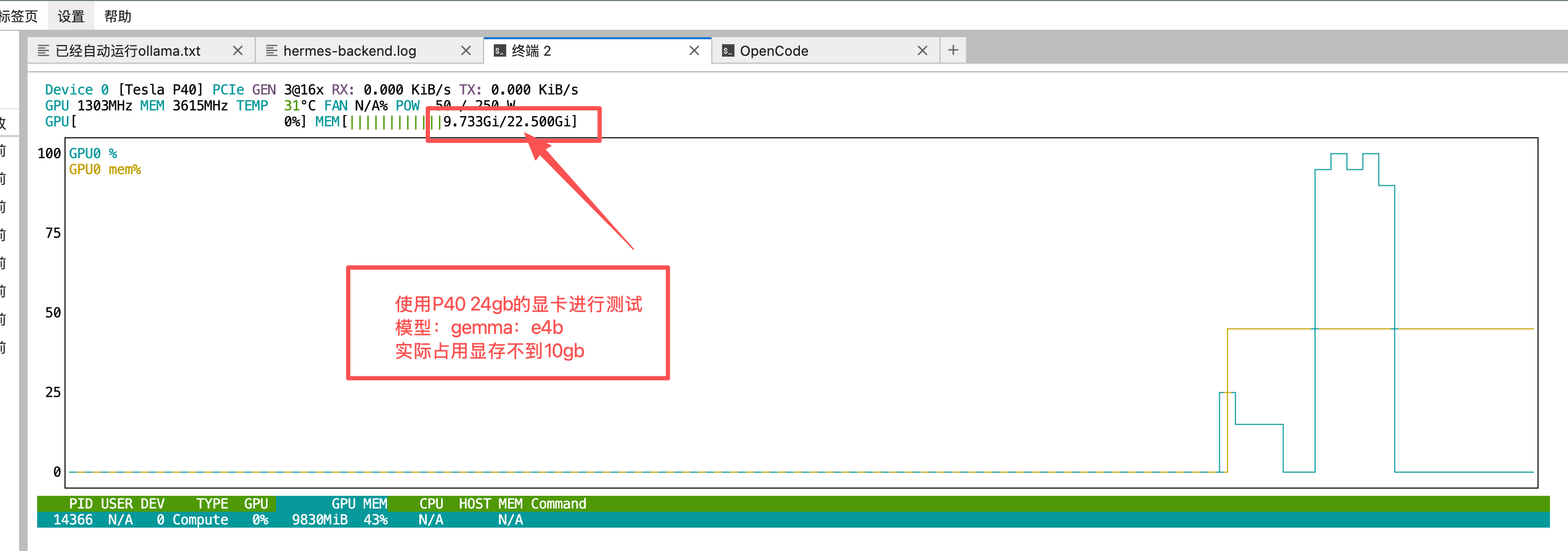
四、配置本地模型 (Ollama)
4.1 启动 Ollama
# 确保 Ollama 服务运行
ollama serve
# 查看已安装模型
ollama list
4.2 配置 Hermes 使用 Ollama
编辑 ~/.hermes/config.yaml:
model:
default: gemma4:e4b
provider: custom
base_url: http://localhost:11434/v1
custom_providers:
- name: Ollama
base_url: http://localhost:11434/v1
model: gemma4:e4b
4.3 在 Web UI 中切换模型
- 进入 Models 页面
- 或在聊天页面顶部模型选择器中选择
五、常见问题 (FAQ)
Q1: 页面显示"未连接"
原因:Hermes Gateway 未启动
解决:
# 重新运行启动脚本
/root/hermes-web-ui/start_app.sh
# 检查服务状态
lsof -i :7860 -i :8648 -i :8642 | grep LISTEN
Q2: 如何查看访问令牌?
grep token /root/logs/hermes-backend.log
Q3: 如何修改前端端口?
编辑 start_app.sh 第 3 行:
PORT=你想要的端口
Q4: 端口被占用怎么办?
启动脚本会自动检测并终止占用端口的进程(jupyterlab 除外)。
如需手动处理:
# 查看端口占用
lsof -i :7860
# 强制终止
kill -9 <PID>
Q5: 如何查看日志?
# 前端日志
tail -f /root/logs/hermes-frontend.log
# 后端日志
tail -f /root/logs/hermes-backend.log
# Gateway 日志
tail -f /root/logs/hermes-agent.log
Q6: Hermes Gateway 启动失败 (PID 冲突)
# 删除 PID 文件
rm -f ~/.hermes/gateway.pid
# 重新启动
/root/hermes-web-ui/start_app.sh
Q7: 如何配置平台渠道?
- 登录 Web UI
- 进入 Channels 页面
- 选择要配置的平台
- 填写凭证信息
- 保存配置,Gateway 会自动重启
Q8: 如何使用 Cron 定时任务?
- 进入 Jobs 页面
- 点击 "+" 创建新任务
- 填写任务名称和 Cron 表达式
- 设置任务内容(要发送的消息)
- 保存并可立即测试执行
六、架构说明
用户浏览器
↓
前端 Web UI (端口 7860)
↓ [API 代理]
后端服务 BFF (端口 8648)
↓ [Upstream]
Hermes Gateway (端口 8642)
↓
Ollama / 其他 LLM 提供商
- 前端:Vue 3 + Naive UI
- 后端:Koa 2 (API 代理、认证、会话管理)
- Gateway:Hermes Agent (多平台消息接入)
七、安全建议
- 令牌保护:访问令牌相当于密码,请妥善保管
- 生产环境:务必配置 API Key,参考日志中的警告信息
- 允许列表:配置平台渠道时,建议设置用户允许列表
- 网络隔离:生产环境使用防火墙限制访问
八、技术支持
项目开发记录
一、环境配置与依赖
1.1 Node.js 版本要求
- 项目要求 Node.js >= 23.0.0
- 当前系统默认 Node.js v20.5.0,不满足要求
- 解决方案:下载 Node.js 22.x 二进制文件到
/tmp/node-v22.14.0-linux-x64 - 启动脚本中设置 PATH 优先使用该版本
1.2 依赖安装
# 使用 Node 22 安装依赖
export PATH=/tmp/node-v22.14.0-linux-x64/bin:$PATH
npm install
二、启动脚本 (start_app.sh)
2.1 核心功能
| 功能 | 说明 |
|---|---|
| 端口清理 | 启动前自动检测并终止占用端口的进程 |
| Jupyter 保护 | 不终止 jupyterlab 相关进程 |
| 延迟启动 | 端口释放后 sleep 2 秒再启动 |
| 多服务启动 | 依次启动前端、后端、Hermes Gateway |
2.2 端口配置
| 端口 | 服务 | 说明 |
|---|---|---|
| 7860 | 前端 Web UI | 可通过脚本变量 PORT 修改 |
| 8648 | 后端服务 (BFF) | 固定端口 |
| 8642 | Hermes Gateway | 固定端口 |
2.3 日志路径
- 统一存放于
/root/logs/目录hermes-frontend.log- 前端日志hermes-backend.log- 后端日志hermes-agent.log- Gateway 日志
2.4 Hermes Gateway 启动命令
- 旧版本:
hermes start(已废弃) - 新版本:
hermes gateway run
2.5 PID 文件冲突
- 问题:
ERROR gateway.run: PID file race lost to another gateway instance - 解决:删除
~/.hermes/gateway.pid
三、配置文件
3.1 模型配置 (~/.hermes/config.yaml)
model:
default: gemma4:e4b # 修改默认模型
provider: custom
base_url: http://localhost:11434/v1
custom_providers:
- name: Local (localhost:11434)
base_url: http://localhost:11434/v1
model: gemma4
3.2 后端认证
- 访问令牌在启动时生成,显示在日志中
- 查看命令:
grep token /root/logs/hermes-backend.log
四、代理配置
4.1 Vite 代理配置 (vite.config.ts)
- 前端请求
/api、/v1、/health、/upload、/webhook代理到后端 8648 - 后端再代理到 Hermes Gateway 8642
五、问题排查
5.1 常见问题
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 端口被占用 | 上次进程未正常关闭 | 脚本自动清理 |
| Hermes 未连接 | hermes-agent 未安装 | pip install hermes-agent |
| 认证失败 | 令牌过期或错误 | 查看日志获取新令牌 |
| Gateway PID 冲突 | 上次异常退出 | 删除 ~/.hermes/gateway.pid |
5.2 健康检查
# 通过前端代理检查
curl http://localhost:7860/health
六、项目结构
hermes-web-ui/
├── packages/
│ ├── client/ # Vue 3 前端
│ │ └── src/
│ │ ├── views/ # 页面视图
│ │ ├── components/ # 组件
│ │ ├── stores/ # Pinia 状态管理
│ │ └── api/ # API 调用
│ └── server/ # Koa 后端
│ └── src/
│ ├── routes/ # 路由定义
│ ├── controllers/ # 控制器
│ └── services/ # 服务层
├── start_app.sh # 启动脚本
└── vite.config.ts # Vite 配置
七、技术栈
| 层 | 技术 |
|---|---|
| 前端 | Vue 3 + TypeScript + Vite + Naive UI + Pinia |
| 后端 | Koa 2 + node-pty (Web Terminal) |
| Agent | Hermes Gateway (Telegram, Discord, Slack 等) |
八、后续优化建议
- 环境变量化:将 Node 路径、端口等配置提取为环境变量
- 服务管理:使用 systemd 或 supervisor 管理进程
- 日志轮转:配置 logrotate 避免日志过大
- 健康检查:添加定时检查脚本,自动重启异常服务
 认证作者
认证作者

 支持自启动
支持自启动