 2
2智普开源GLM-4.7-Flash GGUF推理服务编程文本大模型速度很快 webui开发构建by科哥
增加到五个可选模型 增加api切换模型页面
Q3模型:要求8gb显存;Q4模型:要求显存12gb,Q8模型要求:36gb显存
镜像简介
本镜像基于智普开源GLM-4.7-Flash文本大模型,采用GGUF格式提供高效的本地推理服务,响应速度突出。内置便捷的WebUI界面,支持编程辅助、智能问答与文本生成等任务,适合开发者、研究人员及需要快速文本处理的用户进行高效部署与使用。
镜像使用教程
创建实例后点击【SD-WebUI】即可进入操作页面
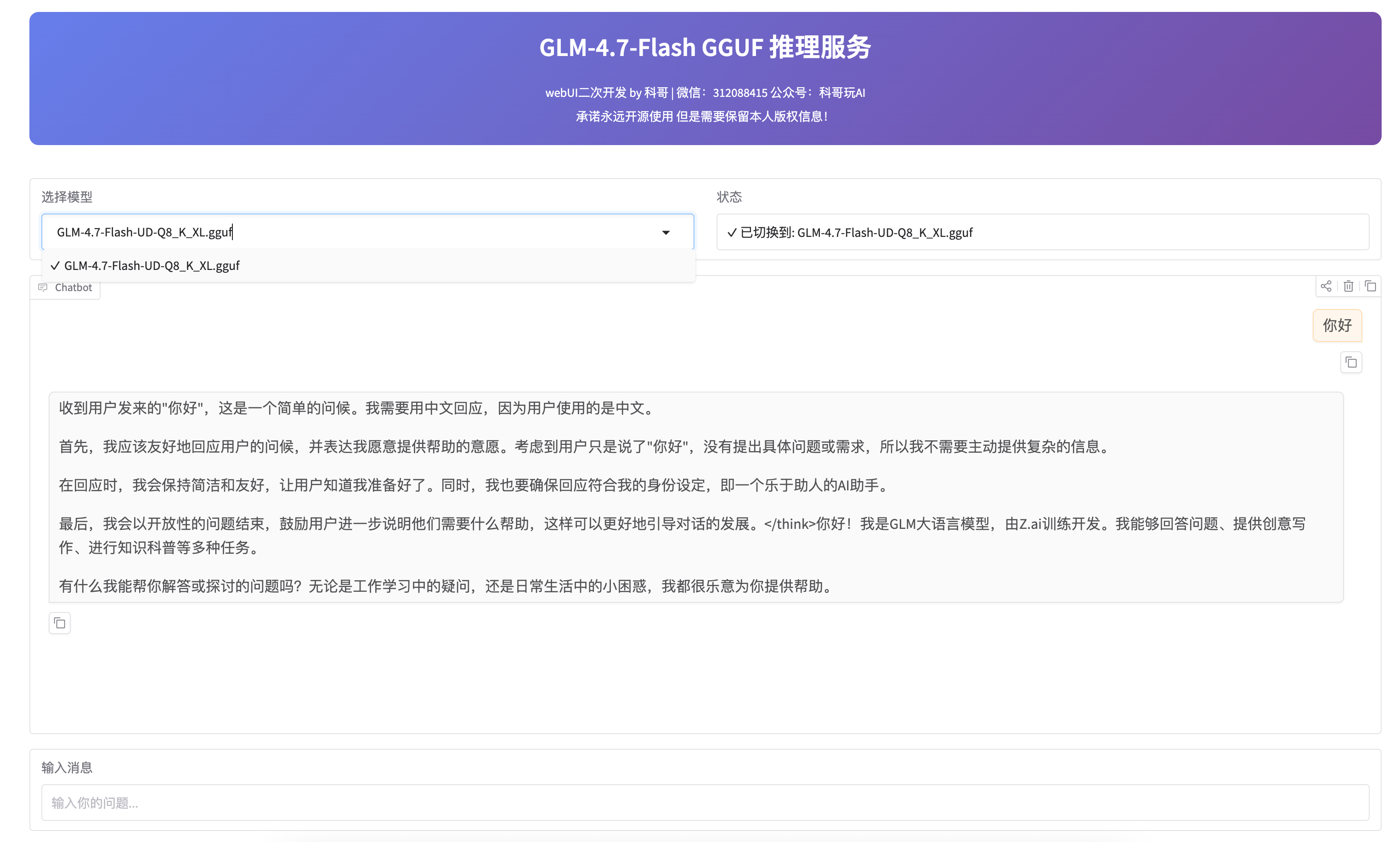
运行截图
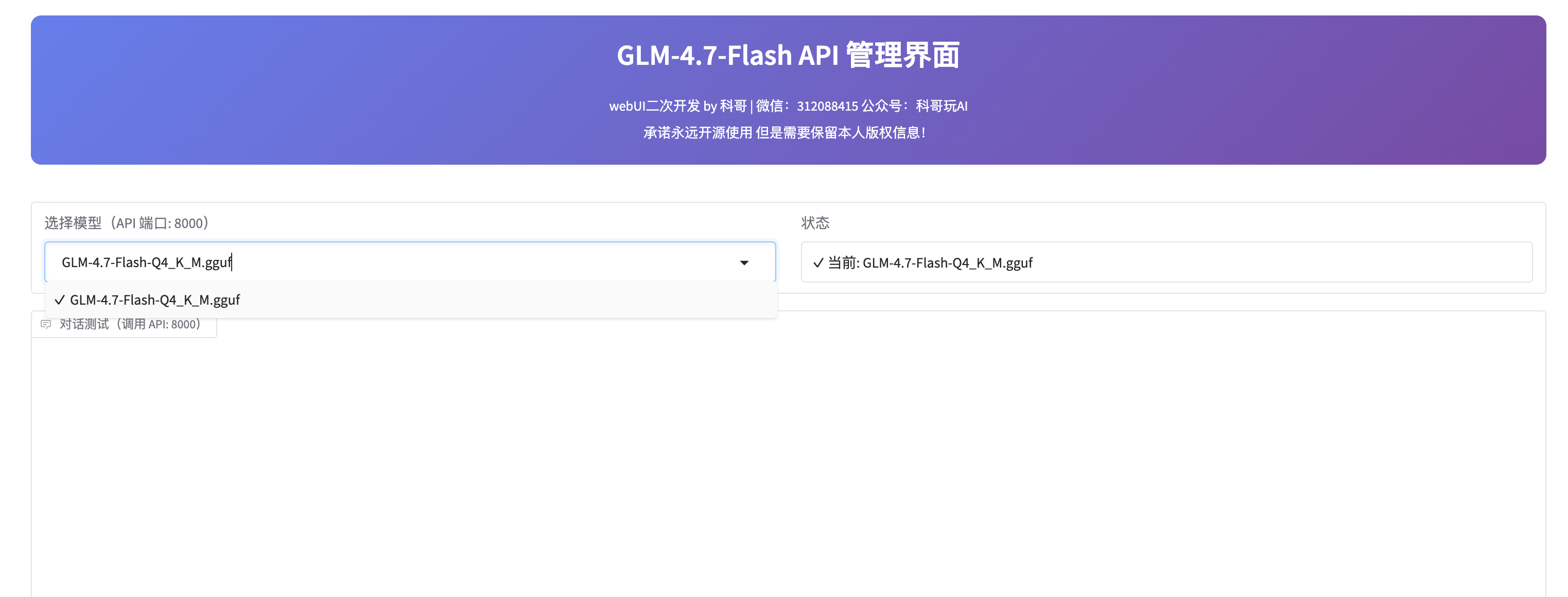

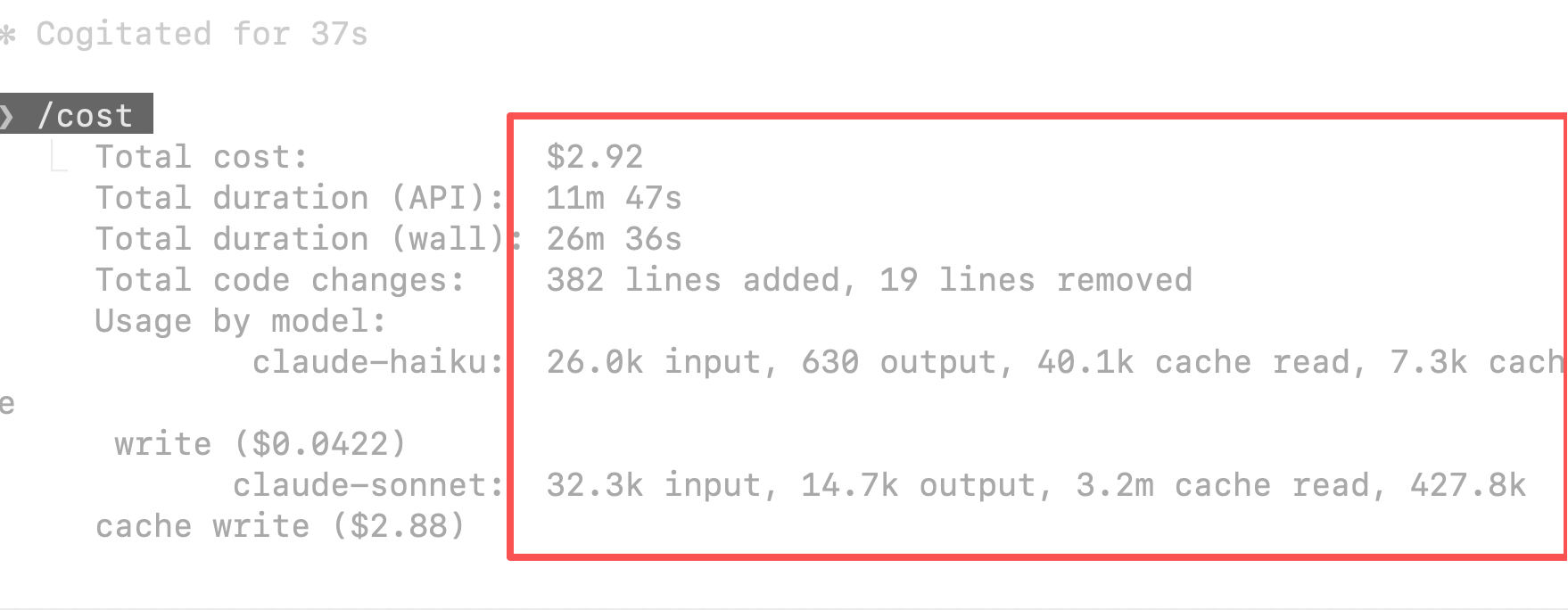
api 是8000端口 使用看下面教程
GLM-4.7-Flash 用户使用手册
欢迎使用 GLM-4.7-Flash!这是一个强大的 AI 对话助手,支持中英文对话、代码生成、问题解答等功能。
📱 访问服务
服务提供两种使用方式:
方式 1: Web 聊天界面(推荐新手)
访问地址:
特点: 简单易用,像使用 ChatGPT 一样聊天
方式 2: API 接口(推荐开发者)
访问地址:
- 本地: http://localhost:8000
- 内网: http://10.60.223.43:8000
- API 文档: http://localhost:8000/docs
特点: 支持编程调用,可集成到其他应用
方式 3: WebUI 管理界面(推荐管理员)
访问地址:
特点:
- 模型切换:从 19 个 GGUF 模型中选择
- 对话测试:直接测试 API 功能
- 参数调整:Temperature、Top P、Max Tokens
使用方法:
- 在下拉框选择模型(如
GLM-4.7-Flash-Q4_K_M.gguf) - 点击"加载选择的模型"按钮
- 等待切换完成(状态框显示 ✓)
- 在对话框测试新模型
💬 使用 Web 聊天界面
基础对话
- 打开浏览器,访问 http://localhost:7860
- 在底部输入框输入你的问题
- 按 Enter 或点击发送
- AI 会实时流式回复(像打字一样逐字显示)
示例对话:
你: 你好,请介绍一下自己
AI: 你好!我是 GLM-4.7-Flash,一个由智谱 AI 开发的大型语言模型...
你: 帮我写一个 Python 函数计算斐波那契数列
AI: 好的,这是一个计算斐波那契数列的 Python 函数:
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
调整参数(高级)
点击"高级参数"展开,可以调整:
| 参数 | 说明 | 推荐值 | 效果 |
|---|---|---|---|
| Temperature | 创造性 | 0.2 | 越低越严谨,越高越有创意 |
| Top P | 采样范围 | 0.95 | 控制回复的多样性 |
| Top K | 候选词数量 | 50 | 影响词汇选择 |
| Max Tokens | 最大回复长度 | 2048 | 回复的最大字数 |
使用建议:
- 写代码: Temperature = 0.2(严谨)
- 创意写作: Temperature = 0.8(有创意)
- 日常对话: 使用默认值即可
清空对话
点击"清空对话"按钮可以开始新的对话,之前的历史会被清除。
🔌 使用 API 接口
快速测试
打开终端,运行:
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "glm-4.7-flash",
"messages": [
{"role": "user", "content": "你好"}
]
}'
Python 调用示例
import requests
# 发送请求
response = requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "glm-4.7-flash",
"messages": [
{"role": "user", "content": "写一个快速排序算法"}
],
"temperature": 0.2,
"max_tokens": 2048
}
)
# 获取回复
result = response.json()
print(result["choices"][0]["message"]["content"])
使用 OpenAI SDK
from openai import OpenAI
# 配置客户端
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="dummy" # 不需要真实 key
)
# 发送消息
response = client.chat.completions.create(
model="glm-4.7-flash",
messages=[
{"role": "user", "content": "解释一下 Python 装饰器"}
]
)
print(response.choices[0].message.content)
多轮对话
import requests
# 对话历史
messages = [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!有什么可以帮你的吗?"},
{"role": "user", "content": "帮我写一个 Python 函数"}
]
response = requests.post(
"http://localhost:8000/v1/chat/completions",
json={"model": "glm-4.7-flash", "messages": messages}
)
print(response.json()["choices"][0]["message"]["content"])
🛠️ 工具调用(API 专属)
API 服务支持执行代码和命令,适合编程助手场景。
执行 Bash 命令
curl -X POST "http://localhost:8000/v1/tools/execute?tool_name=execute_bash" \
-H "Content-Type: application/json" \
-d '{
"command": "ls -la",
"timeout": 10
}'
返回结果:
{
"success": true,
"result": {
"stdout": "total 48\ndrwxr-xr-x ...",
"stderr": "",
"returncode": 0
}
}
执行 Python 代码
curl -X POST "http://localhost:8000/v1/tools/execute?tool_name=execute_python" \
-H "Content-Type: application/json" \
-d '{
"code": "print(2 + 2)",
"timeout": 10
}'
返回结果:
{
"success": true,
"result": {
"stdout": "4\n",
"stderr": "",
"returncode": 0
}
}
📝 常见使用场景
1. 代码生成
提问技巧: 说明需求、语言、功能
你: 用 Python 写一个函数,读取 CSV 文件并统计每列的平均值
AI: [生成完整代码]
2. 代码解释
提问技巧: 直接粘贴代码,询问功能
你: 这段代码是做什么的?
def fib(n):
return n if n <= 1 else fib(n-1) + fib(n-2)
AI: 这是一个递归实现的斐波那契数列函数...
3. 调试帮助
提问技巧: 提供错误信息和相关代码
你: 我的代码报错 "TypeError: 'NoneType' object is not subscriptable"
代码是: result = data[0]
AI: 这个错误说明 data 是 None,可能是因为...
4. 技术问答
提问技巧: 直接提问,可以追问
你: 什么是 Docker?
AI: [解释 Docker]
你: 它和虚拟机有什么区别?
AI: [对比说明]
5. 文档撰写
提问技巧: 说明文档类型和内容要求
你: 帮我写一个 API 接口文档,接口是 POST /api/users,用于创建用户
AI: [生成规范的 API 文档]
💡 使用技巧
1. 提问越具体,回答越准确
❌ 不好的提问: "帮我写代码" ✅ 好的提问: "用 Python 写一个函数,输入是字符串列表,输出是去重后的列表"
2. 提供上下文
如果是多轮对话,AI 会记住之前的内容:
你: 我在用 Flask 开发 Web 应用
AI: 好的,有什么可以帮你的吗?
你: 怎么处理 POST 请求?
AI: 在 Flask 中,你可以使用 @app.route 装饰器...
3. 分步骤提问
复杂问题可以拆分:
你: 我想做一个待办事项应用
AI: [给出整体建议]
你: 先帮我设计数据库表结构
AI: [设计表结构]
你: 现在写后端 API
AI: [生成 API 代码]
4. 要求特定格式
你: 用表格形式对比 Python 和 JavaScript 的特点
AI: [生成 Markdown 表格]
你: 用代码注释的方式解释这段代码
AI: [添加详细注释]
⚙️ 参数调整指南
Temperature(温度)
控制回复的随机性和创造性:
| 值 | 适用场景 | 效果 |
|---|---|---|
| 0.1-0.3 | 代码生成、数学计算、事实问答 | 严谨、确定性强 |
| 0.4-0.7 | 日常对话、技术解释 | 平衡 |
| 0.8-1.0 | 创意写作、头脑风暴 | 有创意、多样性 |
Max Tokens(最大长度)
控制回复的最大字数:
| 值 | 适用场景 |
|---|---|
| 128-512 | 简短回答、代码片段 |
| 512-1024 | 中等长度解释 |
| 1024-2048 | 长文档、完整代码 |
| 2048-4096 | 长篇文章、复杂项目 |
❓ 常见问题
Q1: 回复速度慢怎么办?
原因: 模型正在生成,这是正常的 建议:
- 减少 Max Tokens
- 使用更简洁的提问
- Web UI 支持流式输出,可以看到实时生成
Q2: 回复不准确怎么办?
解决方法:
- 提供更详细的上下文
- 降低 Temperature(提高准确性)
- 分步骤提问
- 明确指出错误,让 AI 重新回答
Q3: 如何让 AI 记住之前的对话?
Web UI: 自动记住当前会话的所有对话 API: 需要在 messages 中包含历史消息
Q4: 可以处理多长的文本?
Web UI: 支持 8k tokens(约 6000 汉字) API: 支持 32k tokens(约 24000 汉字)
Q5: 支持哪些语言?
主要支持中文和英文,可以进行中英互译。
Q6: 可以联网搜索吗?
不支持。模型基于训练数据回答,知识截止到 2025 年 1 月。
Q7: 如何清空对话历史?
Web UI: 点击"清空对话"按钮 API: 发送新请求时不包含历史消息
🔒 使用注意事项
- 不要分享敏感信息: 不要输入密码、密钥等敏感数据
- 验证代码: AI 生成的代码需要测试后再使用
- 内网使用: 当前配置为内网访问,外网需要额外配置
- 工具执行: API 的工具调用会执行真实命令,请谨慎使用
🧪 测试脚本
项目提供两个测试脚本,用于验证 API 功能:
1. 原生 API 测试(test_api.py)
测试所有 API 端点:
python test_api.py
测试内容:
- ✅ 健康检查(/health)
- ✅ 模型列表(/v1/models)
- ✅ 工具列表(/v1/tools)
- ✅ Bash 工具执行
- ✅ Python 工具执行
- ✅ 模型切换(/v1/models/switch)
- ✅ 聊天补全(/v1/chat/completions)
2. OpenAI 兼容性测试(test_openai_compat.py)
使用 OpenAI SDK 测试兼容性:
python test_openai_compat.py
测试内容:
- ✅ 模型列表(通过 OpenAI SDK)
- ✅ 聊天补全
- ✅ 流式输出
前置条件: 需要安装 openai 库
pip install openai
📞 获取帮助
- API 文档: http://localhost:8000/docs
- 健康检查: http://localhost:8000/health
- 技术文档: 查看项目目录下的
API_DOCUMENTATION.md
🎯 快速开始
- 打开浏览器 → 访问 http://localhost:7860
- 输入问题 → "你好,请介绍一下自己"
- 查看回复 → AI 会实时回复
- 继续对话 → 可以追问或提新问题
就这么简单!开始使用吧 🚀
提示: 如果服务未启动,请联系管理员运行 ./start_app.sh 或 ./start_api.sh
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
 认证作者
认证作者
 支持自启动
支持自启动