 5
5LatentSync 1.6 纯净版
镜像简介
本镜像搭载Latent Sync 1.6端到端唇形同步框架,由北京交通大学联合推出,融合稳定扩散与TREPA技术,实现高分辨率、高真实感的唇形与语音精准同步。适用于数字人视频生成、影视配音、虚拟主播及多语言内容制作等场景,为用户提供专业级、逼真动态的AI唇形驱动解决方案。
- 功能: 这个镜像主要用于唇形同步。
- 特点: 完全基于Github部署,无广无额外内容。
环境与依赖
本镜像构建和运行所需的基础环境。
- **框架及版本:**PyTorch 2.5.1
- **CUDA版本:**CUDA 12.1
- 其他依赖: Python 3.10,
配置方法
实例创建后,进入jupyterlab,在终端中按步骤执行
-
conda activate latentsync -
cd /workspace/LatentSync 提供两种调用方式:
提供两种调用方式: -
通过Gradio:
python gradio_app.py -
命令行:
./inference.sh
环境验证代码
检查关键库是否安装成功
python -c "import torch; import diffusers; import transformers; import gradio; import insightface; print('All core libraries imported successfully.')"
检查 CUDA 是否可用
python -c "import torch; print(f'CUDA available: {torch.cuda.is_available()}, Device: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else "N/A"}')"
检查模型文件是否存在
ls -lh checkpoints/latentsync_unet.pt checkpoints/whisper/tiny.pt
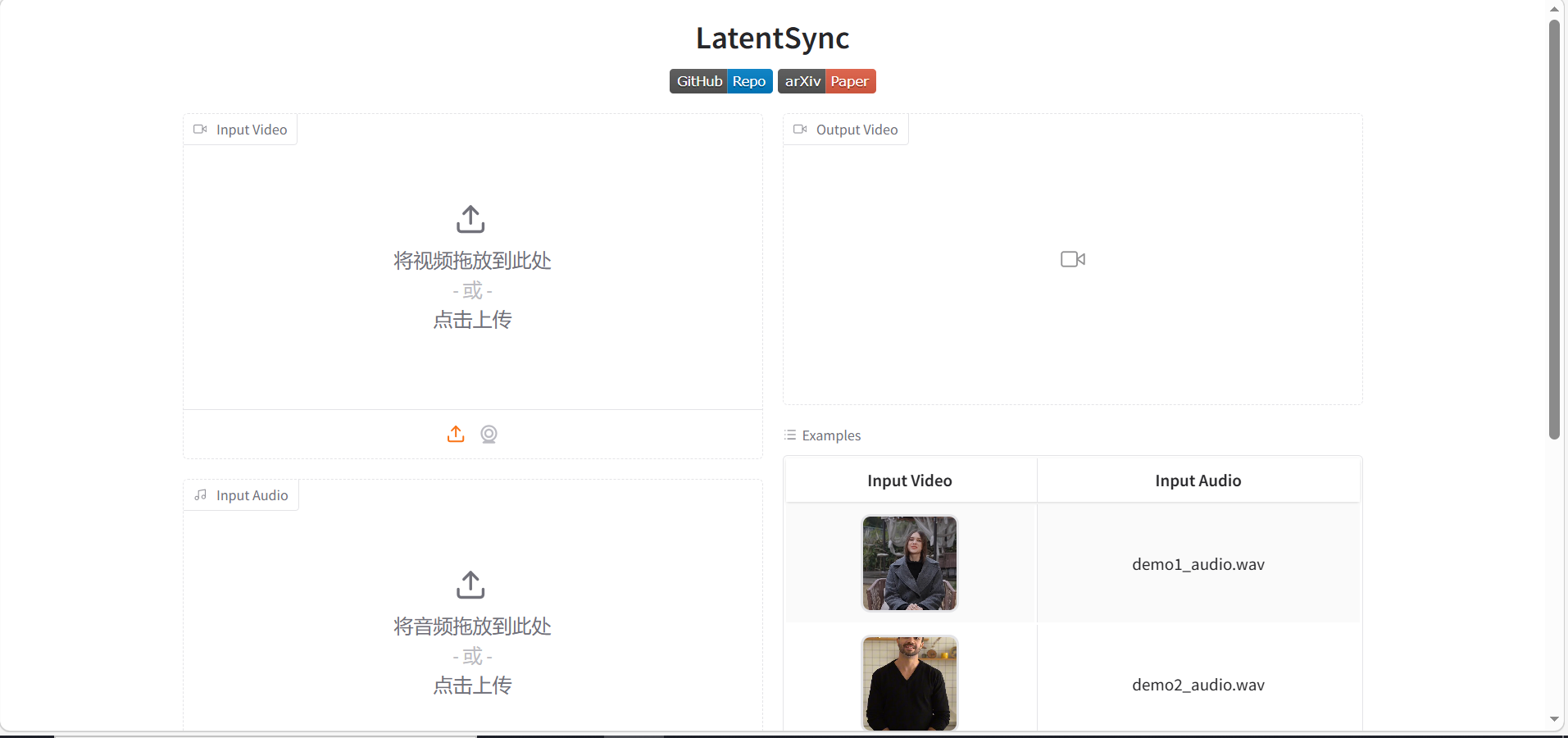
成功进入运行页面截图
相关链接
常见问题
-
Q1: 运行时提示显存不足(OOM)怎么办?
-
A1: LatentSync 1.6 推理建议显存为 18GB。如果显存不足,可以尝试降低 inference_steps 参数(默认 20-50),或在启动脚本中指定使用较低精度的模型(如 FP16)。如果显卡显存非常小(<12GB),建议使用 LatentSync 1.5 版本或显存更大的云服务器实例。
-
Q2: 生成的视频口型不同步怎么办?
-
A2: 可以尝试调整 guidance_scale 参数(范围 1.0-3.0)。增大该值可提高口型同步准确性,但过高可能导致画面扭曲或抖动。同时,确保输入音频清晰且与参考视频的人声语言匹配(LatentSync 1.5+ 对中文视频有优化)。
-
Q3: 如何处理长视频?
-
A3: LatentSync 本身是对视频片段进行处理的。对于长视频,可以使用项目提供的数据处理流水线脚本 data_processing_pipeline.sh,它包含场景检测和分段功能,会自动将长视频分割为 5-10 秒的片段分别处理,最后再拼接。
