0
0🚀 nano-vllm 学习镜像,逐步理解 vLLM 核心原理
📖 镜像简介
本项目基于 nano-vllm 打造,这是一个仅约 1200 行代码的极简版 vLLM 实现。为了让开发者跳过繁琐的环境配置(如 CUDA 驱动冲突、Flash-Attention 编译死锁、RoPE 算子适配等坑),我们封装了该 开箱即用 的学习镜像。
通过本项目,你可以直接跳过“配环境”的苦恼,通过 VSCode 远程断点调试,直观地观察 PagedAttention、KV Cache 管理、张量并行(TP)等大模型推理核心技术的每一行参数变化。
环境与依赖
-
OS: Ubuntu 22.04
-
Python: 3.12 (Miniconda 虚拟环境 py312)
-
核心组件: PyTorch 2.6+, CUDA 12.8+, Flash-Attention 2.8 (已解决高版本编译兼容性问题)
已修复: Qwen2.5/Qwen3 旋转位置编码 (RoPE) 适配问题。
🖥️ 使用说明文档
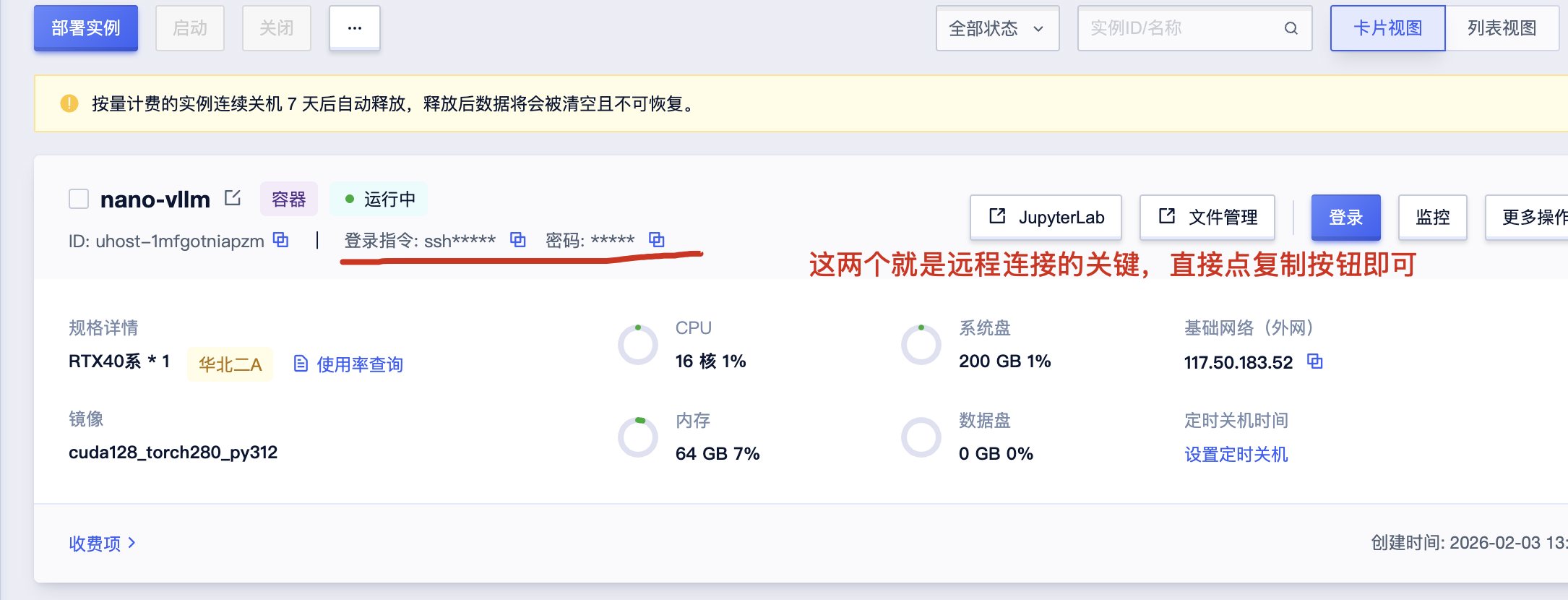
- 构建与启动实例 在宿主机或云平台,选择本镜像构建并启动实例。
确保实例已开启 SSH 端口映射。
- 配置 VSCode 远程开发环境
安装插件:在 VSCode 插件市场搜索并安装 Remote - SSH 插件。
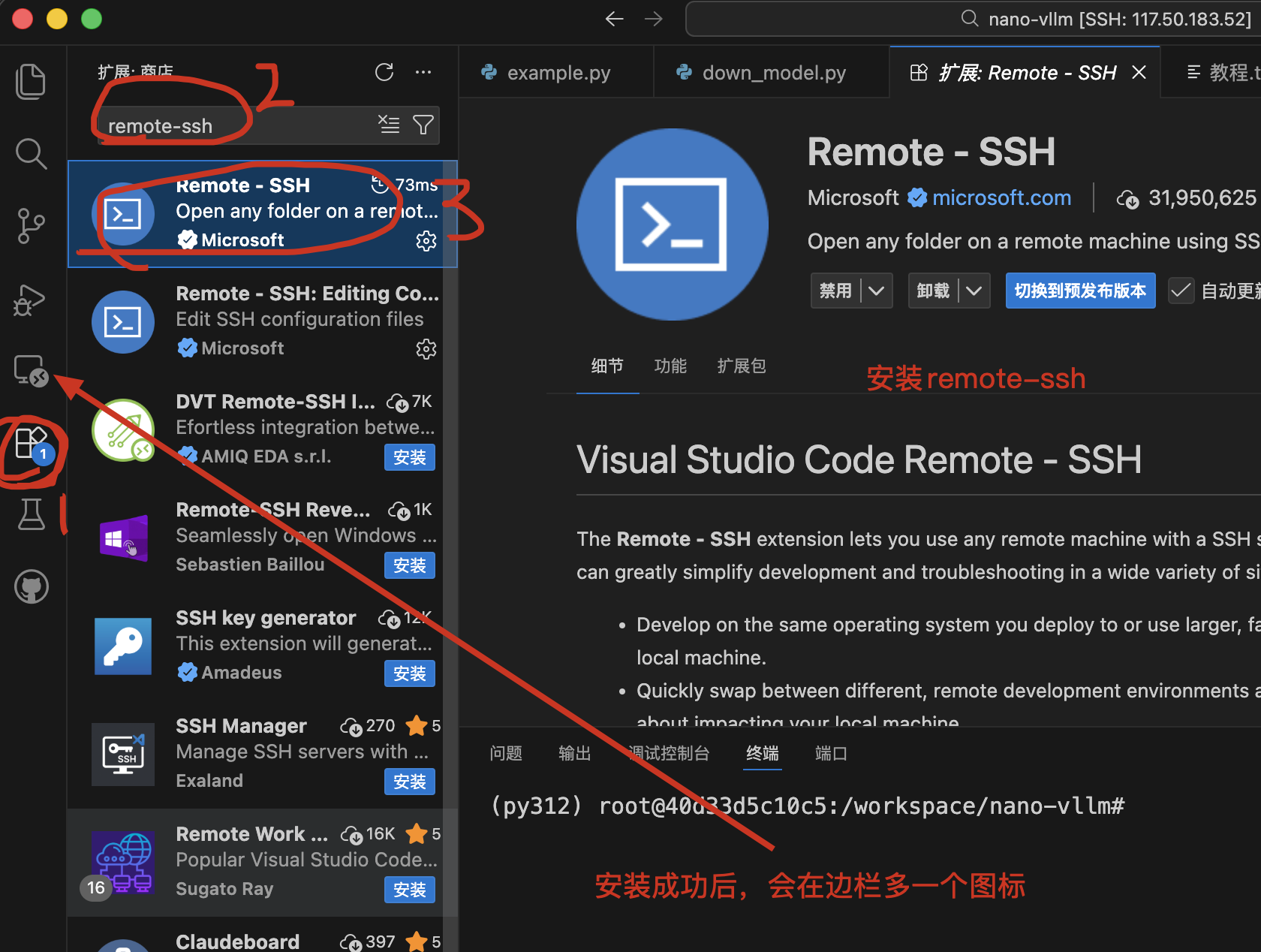
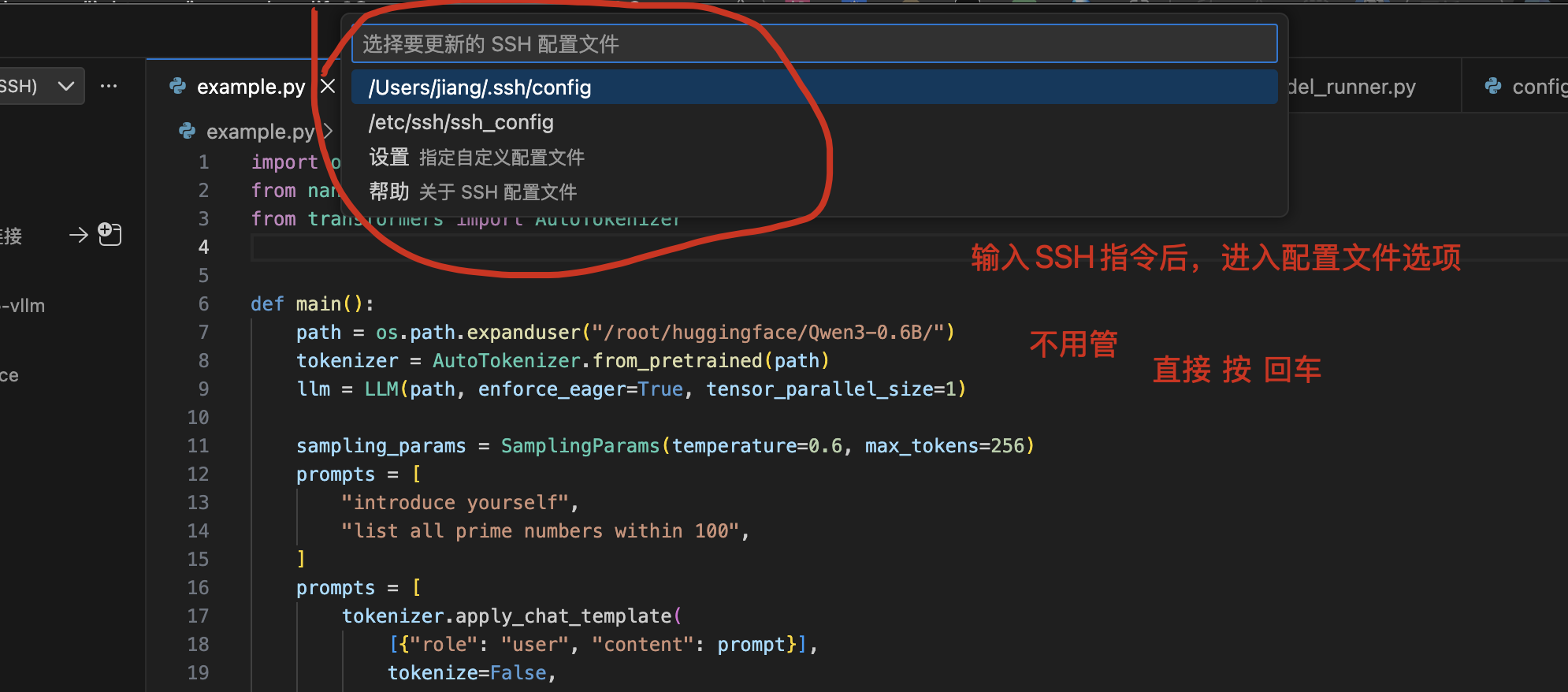
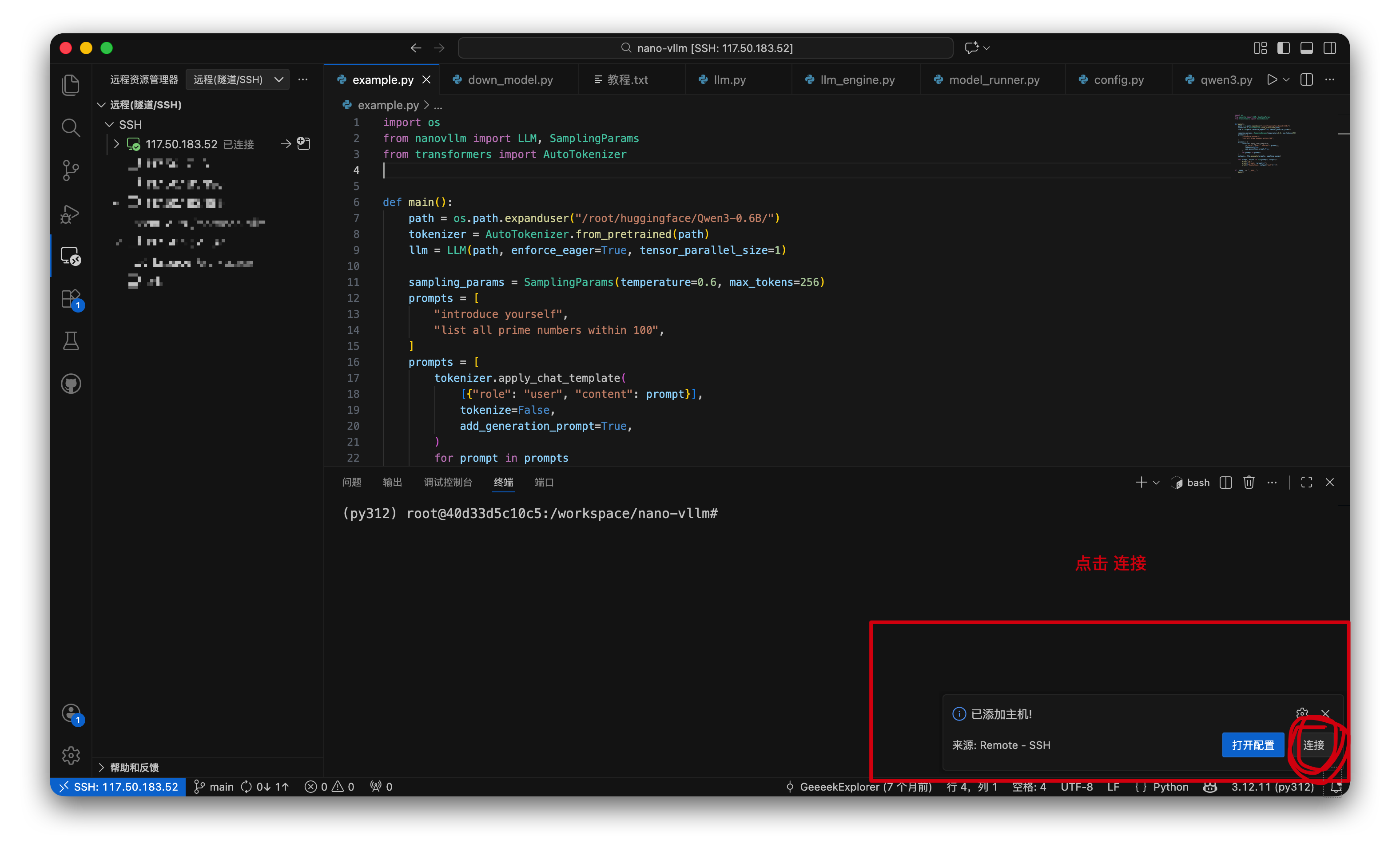
连接服务器:
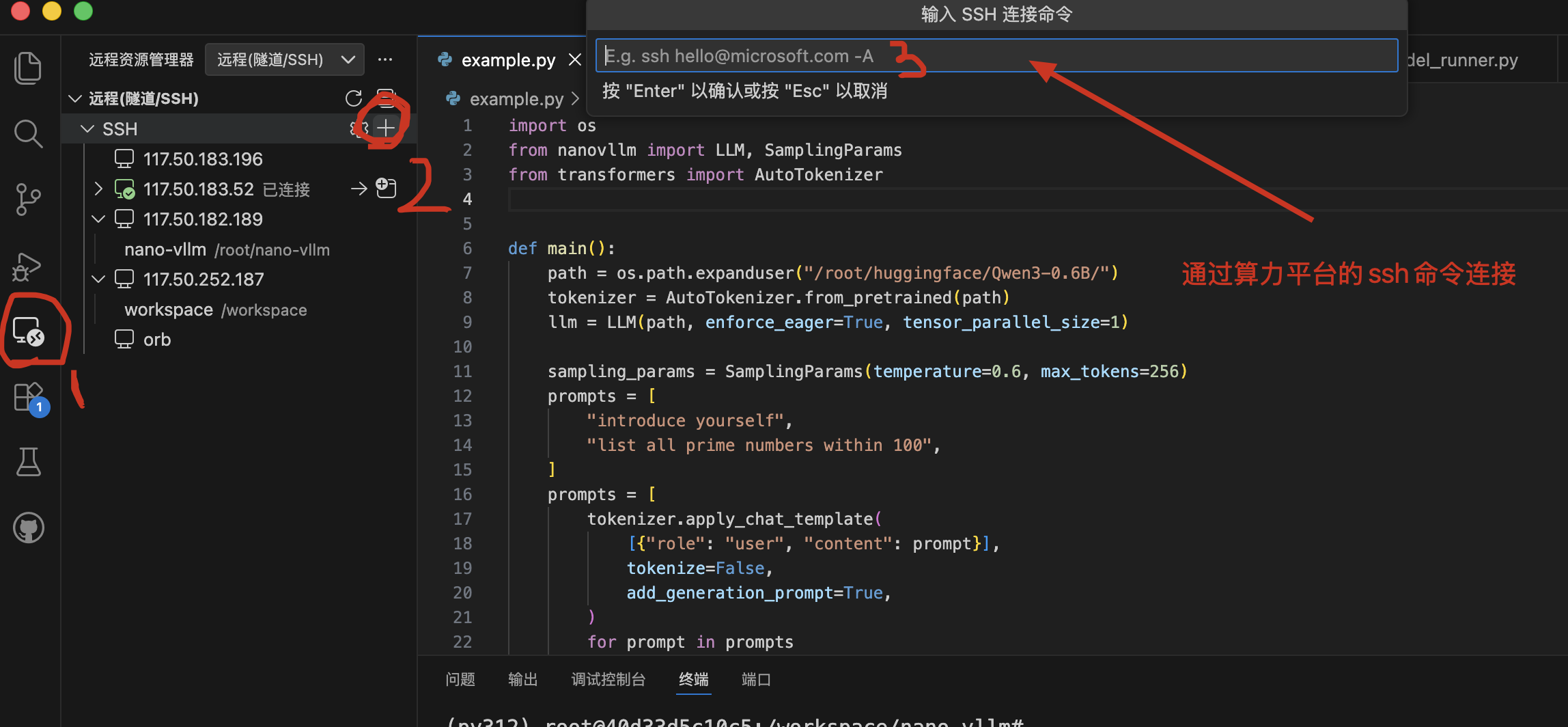
按提示输入密码
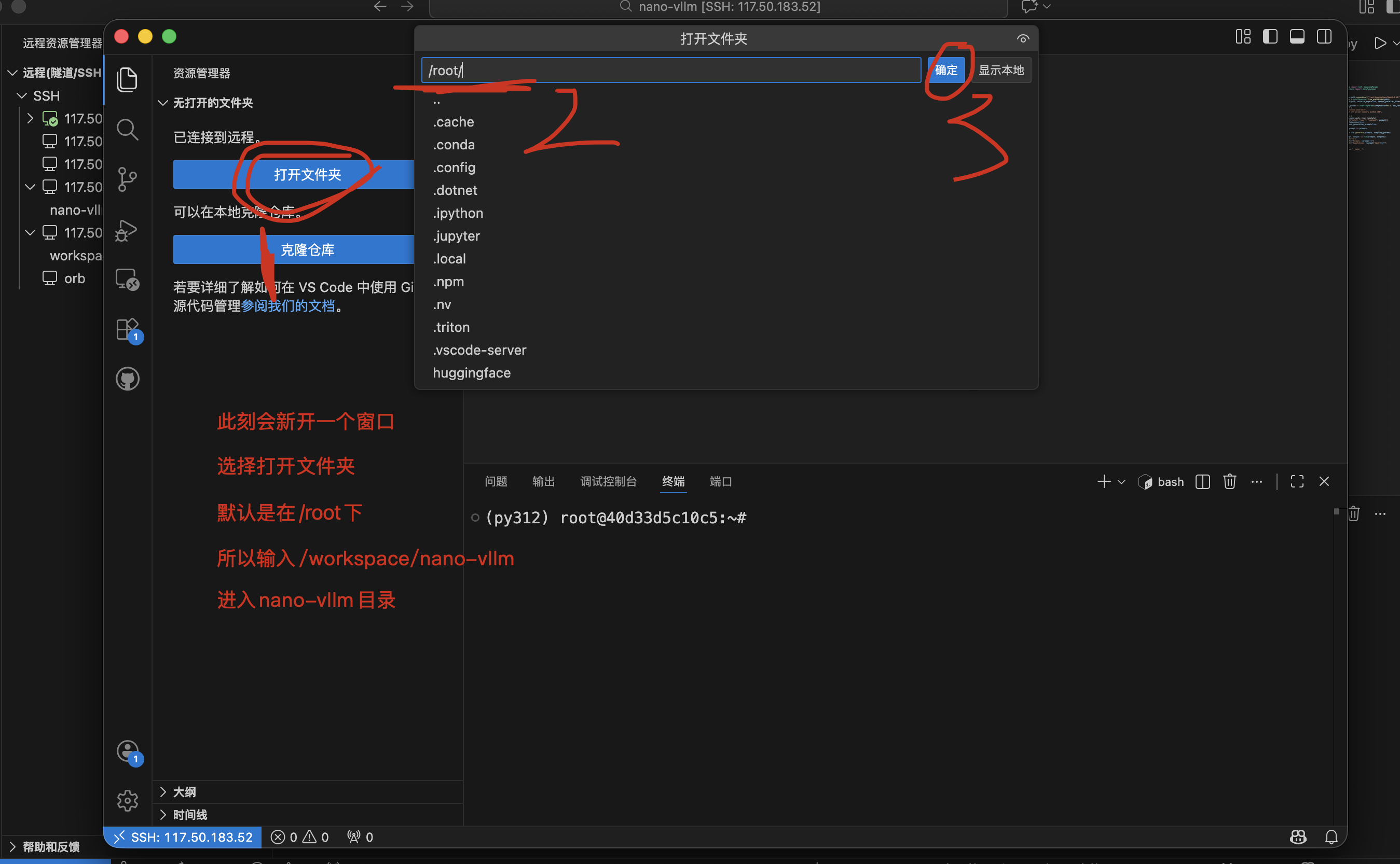
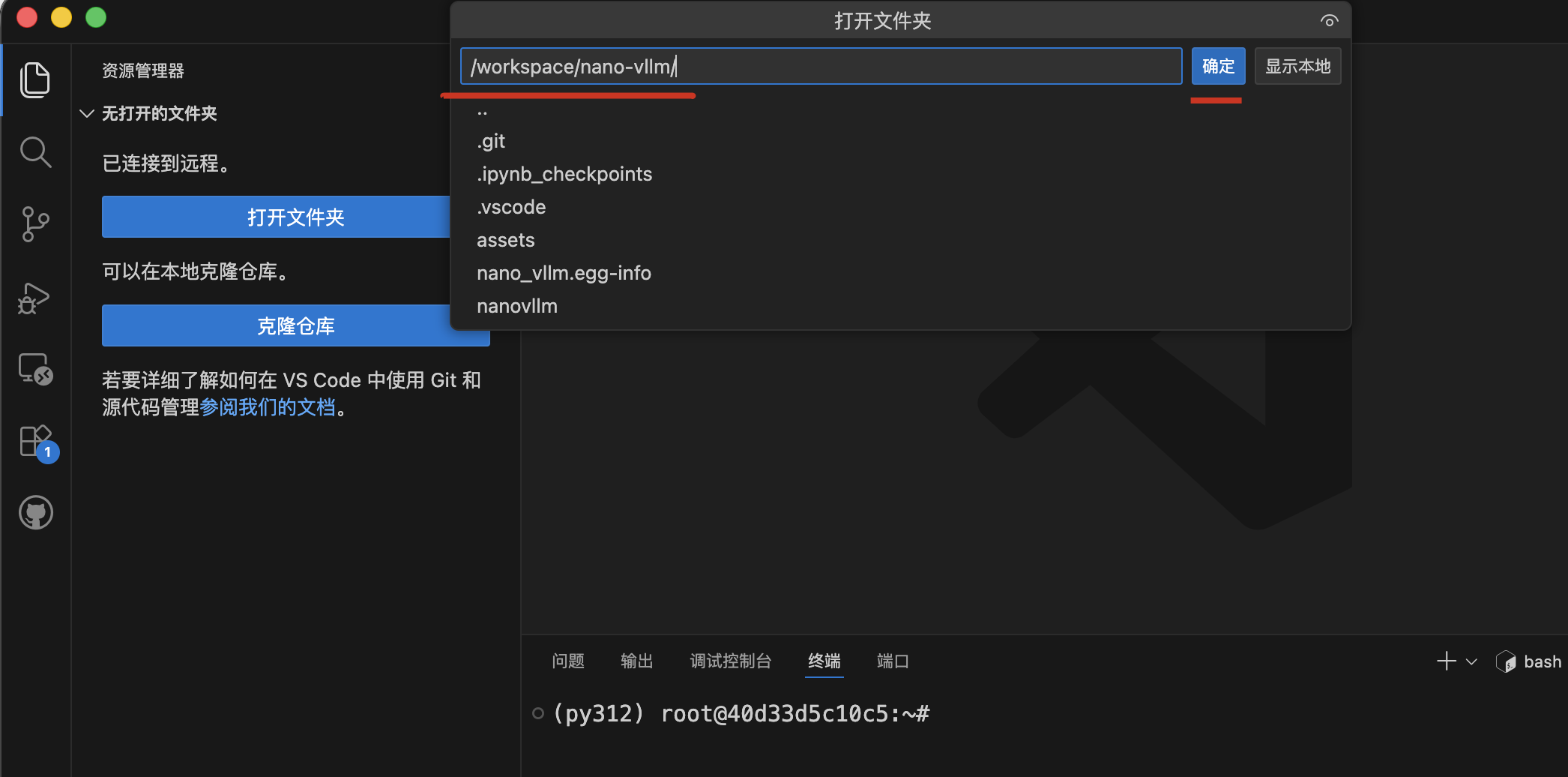
打开项目:选择文件夹路径 /workspace/nano-vllm。
安装 Python 扩展:关键步骤! 在远程连接状态下,再次在插件市场为远程服务器安装 Python 和 Debugger for Python 插件。
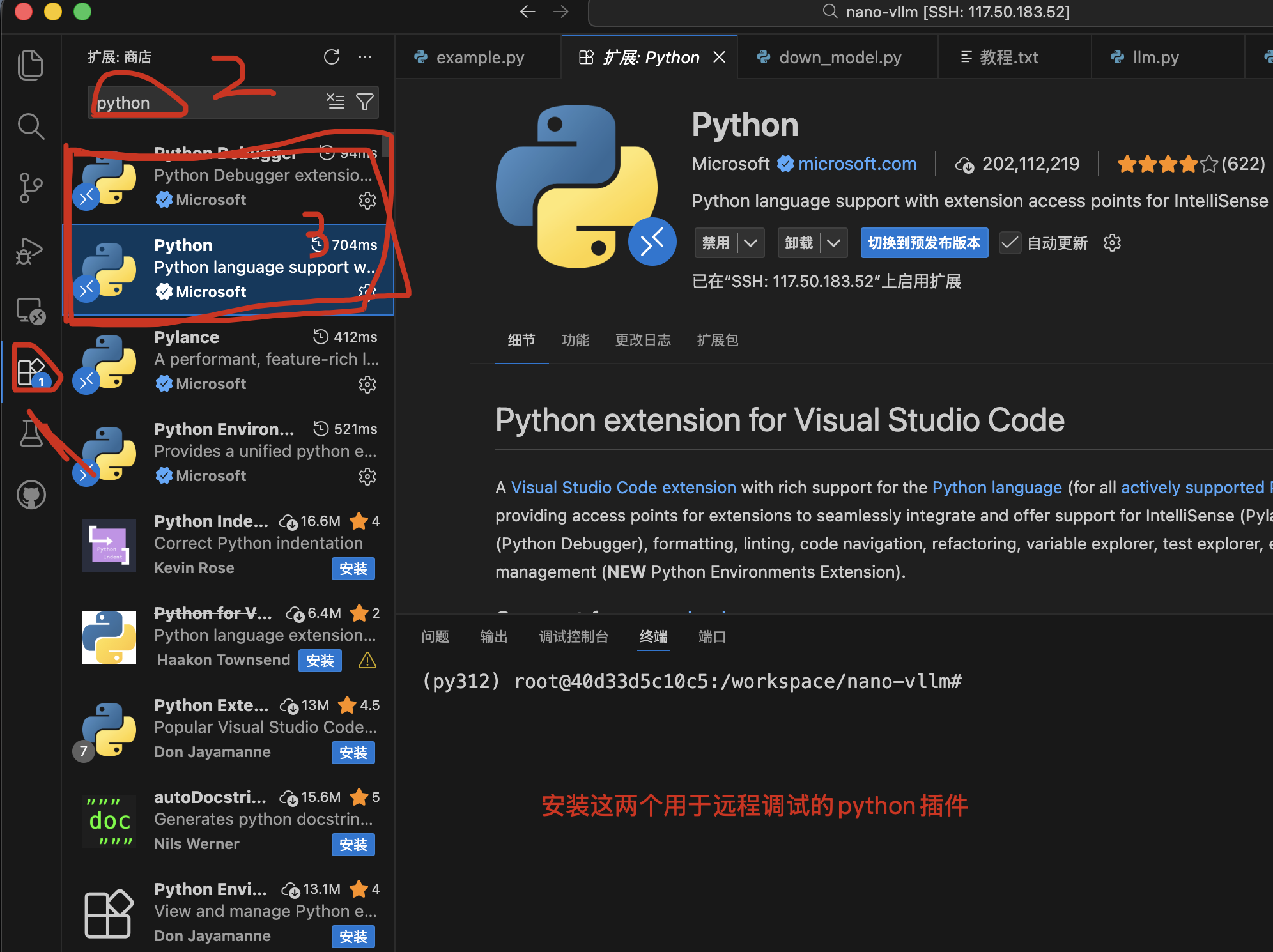
切换解释器:
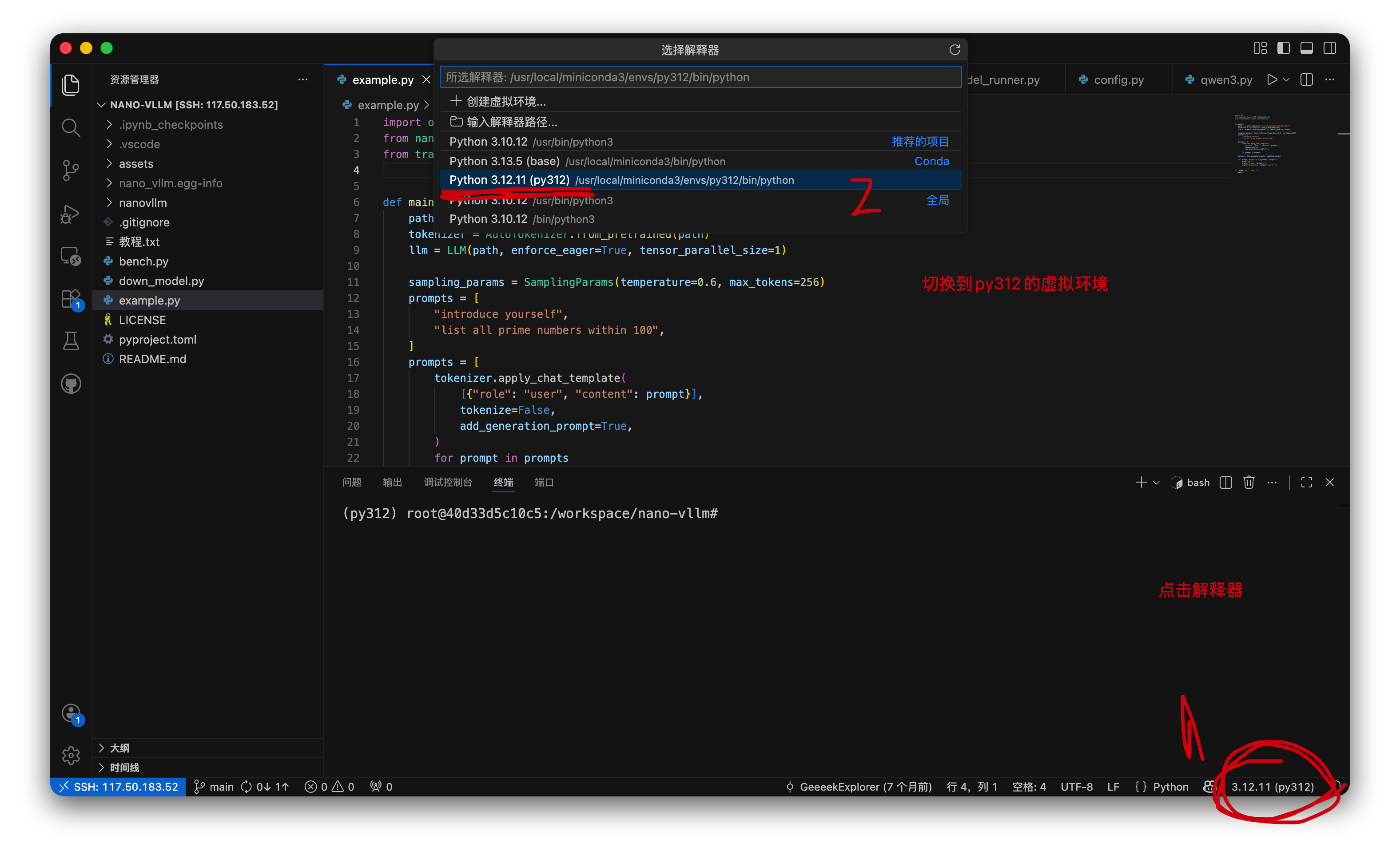
恭喜你,已经可以开始执行代码了
- 准备模型数据 镜像内已内置基础环境,若需运行特定模型:
快速下载:执行 python down_model.py 即可通过镜像站高速下载 Qwen 系列模型(默认已配置国内加速)。
自定义模型:修改 down_model.py 中的 TARGET_REPO 即可获取 Hugging Face 上的任意模型。
- 开启断点调试之旅(核心推荐) 定位入口:打开 example.py。
修改路径:将 model_path 修改为你下载的模型实际路径。
打断点:
在 llm = LLM(...) 处打断点,观察模型配置是如何被解析的。
在 llm.generate(...) 处打断点,追踪 Prompt 如何变成 Token,再如何触发 PagedAttention。
启动调试:按 F5 选择 Python 调试模式。
🎓 推荐学习路线 入门层:通过 example.py 跑通流程,理解 Tokenizer 与 LLM Engine 的交互。
算子层:深入 nanovllm/model_executor/layers/attention.py,看 Flash-Attention 到底如何加速推理。
内存管理层(核心):观察 nanovllm/engine/block_manager.py,这是 vLLM 的精髓,看它是如何像操作系统管理磁盘一样管理显存块(KV Cache)的。
分布式层:尝试修改 tensor_parallel_size,研究多卡环境下权重是如何切分与同步的。
🤝 贡献与交流 如果你在学习过程中发现了问题或者有镜像的优化想法,欢迎沟通交流完善本项目!
致谢:感谢 nano-vllm 原作者提供的极简实现,本镜像旨在降低大模型底层原理的学习门槛。
环境验证代码
运行代码能出来输出,项目构建就没有问题
python example.py
相关链接
- 项目源码: nano-vllm