 11
11镜像名称
- StoryMem基于wan2.2逐镜脚本生成高连贯电影级1分钟多镜头叙事视频 二次开发构建by科哥
镜像简介
给定一份含逐镜头文字描述的故事脚本,StoryMem 可生成兼具吸引力的 1 分钟多镜头叙事视频,人物连贯性极强,且画面具备电影级画质。该效果通过记忆条件控制的单镜头视频扩散模型逐镜头生成实现。更多细节及视频效果详见项目官网。
镜像使用指南
1、在社区镜像区域,选择镜像:
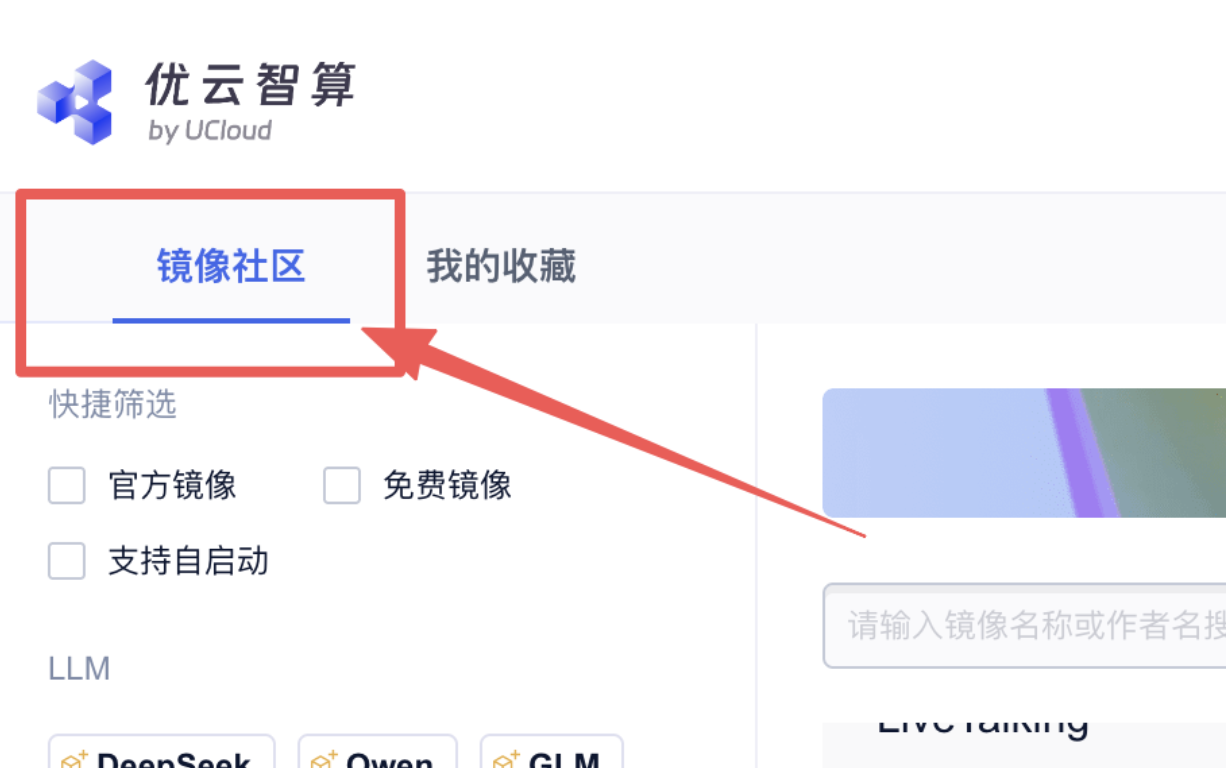
2、在打开的新页面 点击“使用该镜像创建实例”:
2、在打开的新页面 点击“使用该镜像创建实例”:
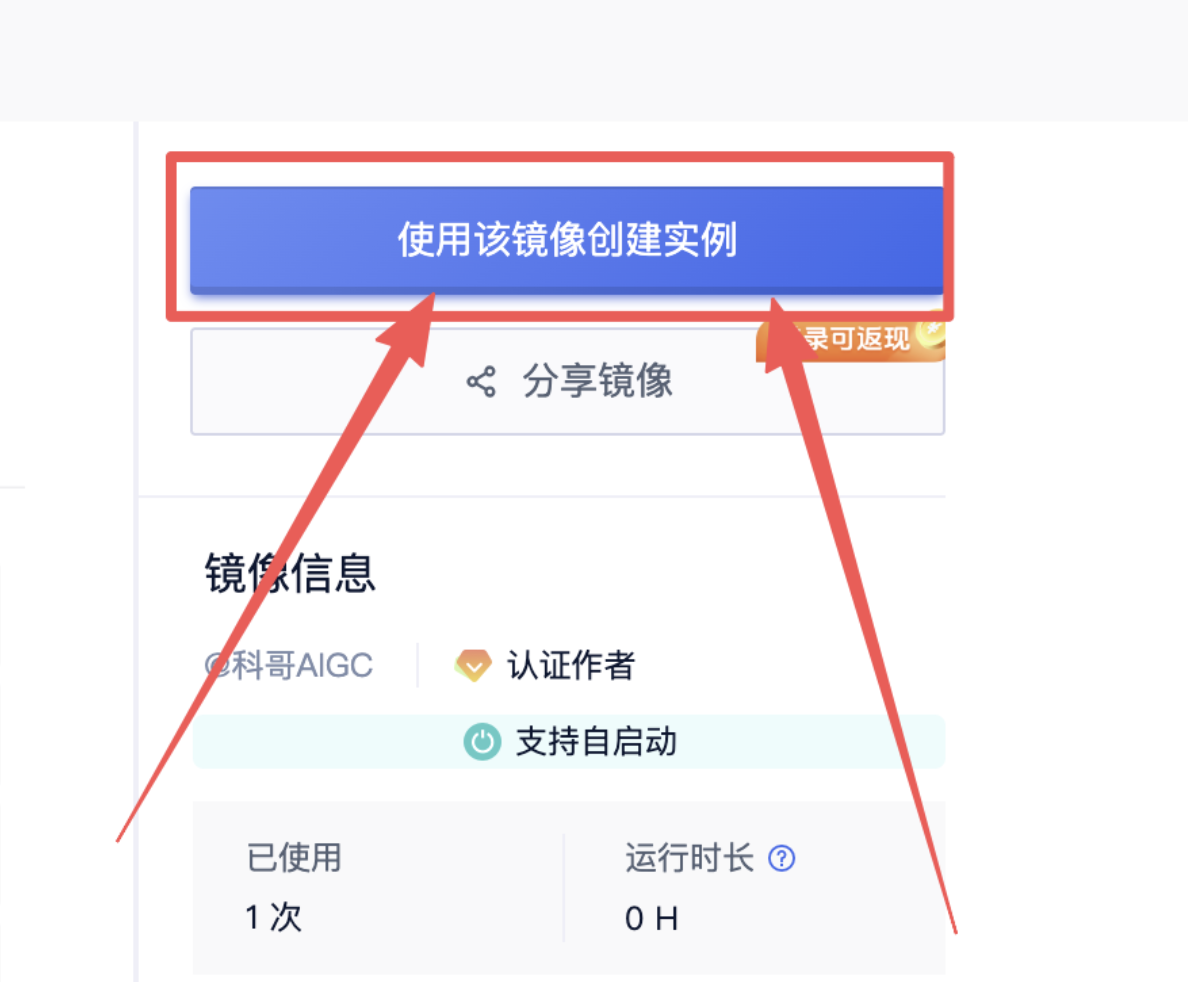
3、选择一个合适的显卡【GPU】根据情况选择,点击“开始部署”,然后等待部署完成:
3、选择一个合适的显卡【GPU】根据情况选择,点击“开始部署”,然后等待部署完成:
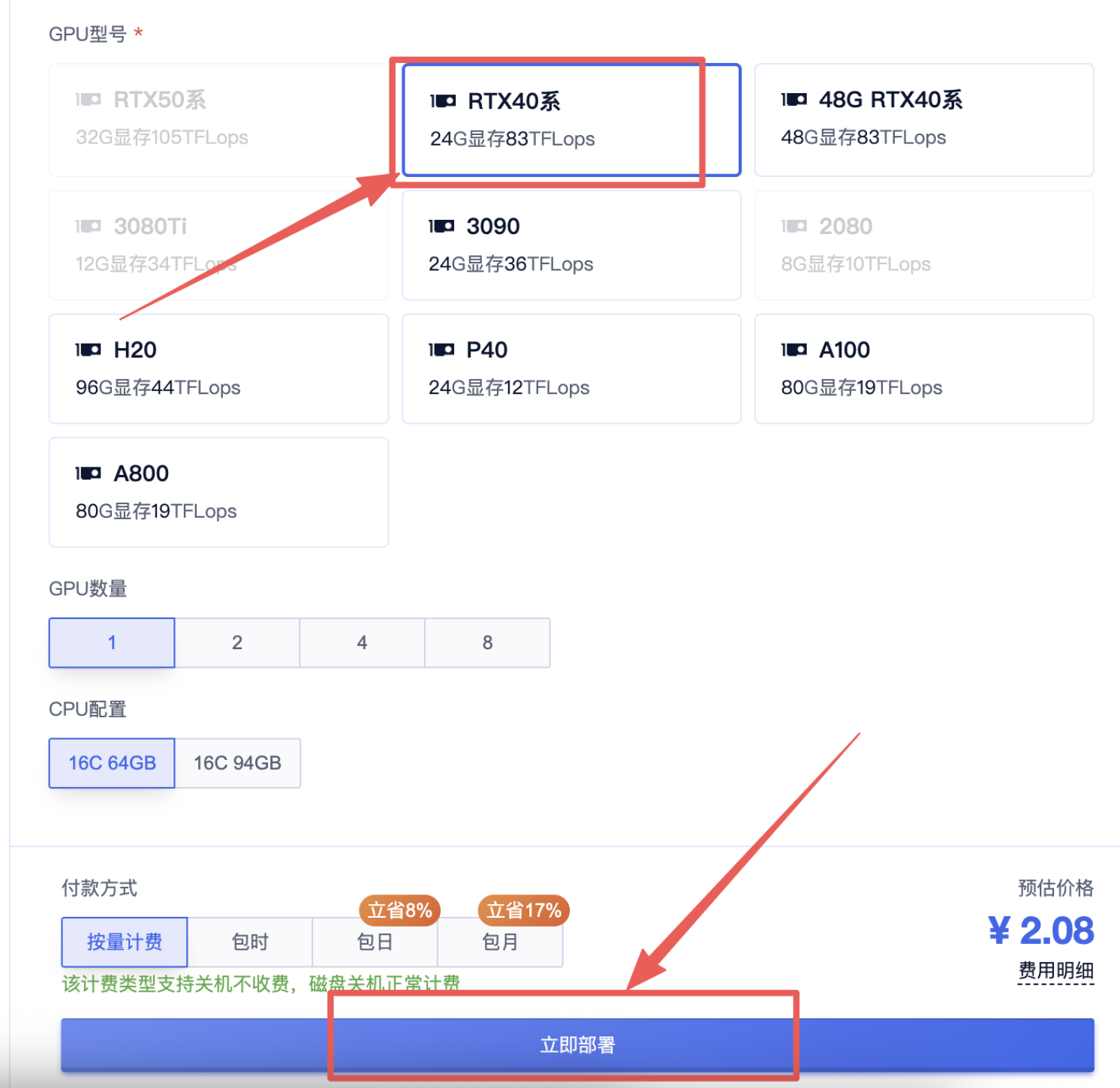
4、实例运行后打开SD-WebUI即可
运行测试截图:



StoryMem 用户使用手册
本手册介绍如何使用 StoryMem WebUI 界面生成多镜头长视频故事。
一、快速入门
1.1 访问界面
启动服务后,在浏览器中打开:
http://localhost:7860
如果使用远程服务器,将 localhost 替换为服务器 IP 地址。
1.2 界面概览
StoryMem WebUI 包含四个主要功能页面(Tab):
| Tab | 功能说明 | 推荐用户 |
|---|---|---|
| ⚡ 快速开始 | 预设模板一键生成 | 新手用户 |
| 铧 高级配置 | 全参数自定义配置 | 高级用户 |
| ✍️ 故事编辑器 | 自定义故事脚本 | 创作用户 |
| 📜 生成历史 | 查看历史记录 | 所有用户 |
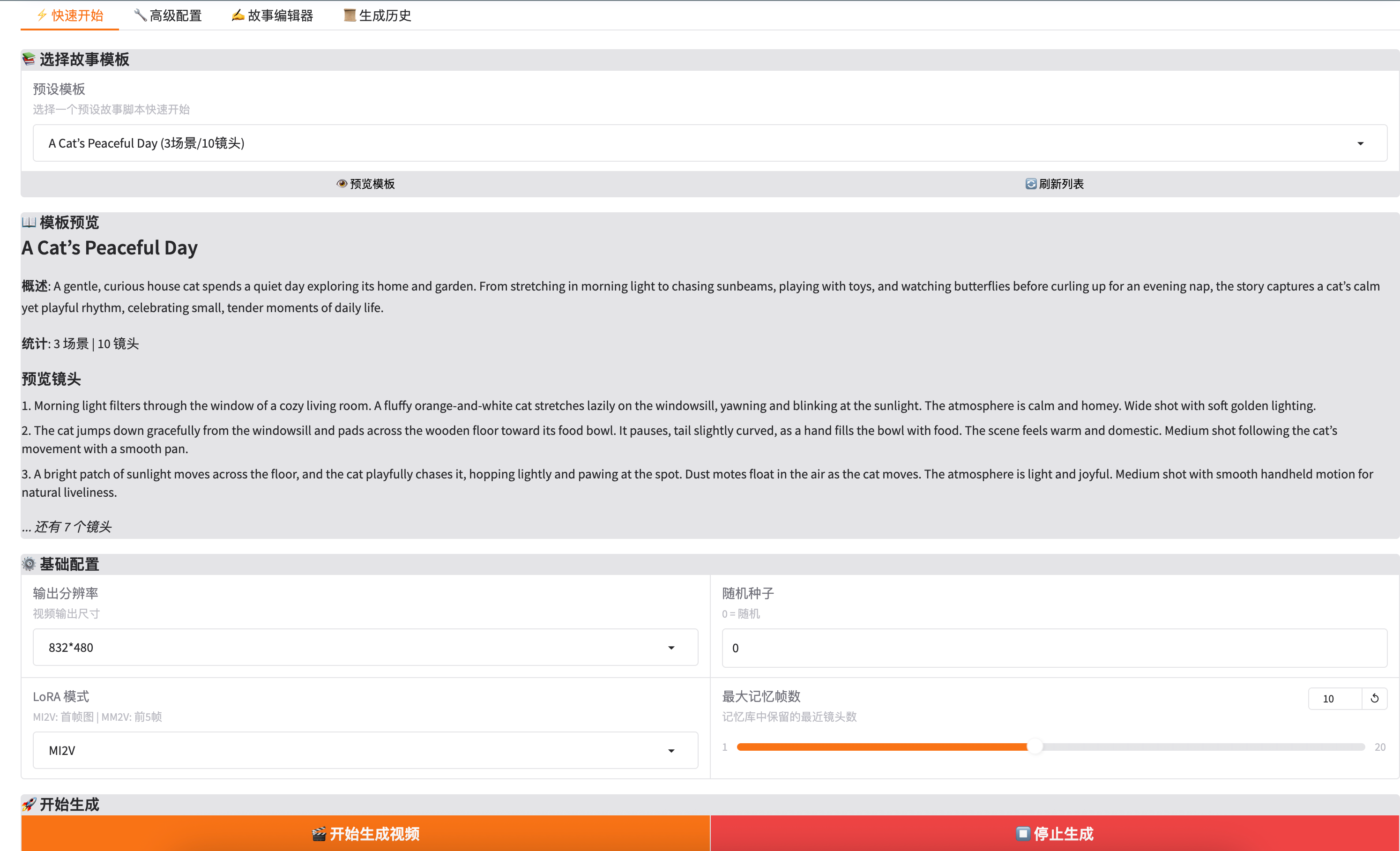
二、快速开始(推荐新手)
2.1 选择故事模板
操作步骤:
- 在「预设模板」下拉框中选择一个故事
- 点击「👁️ 预览模板」查看故事详情
- 预览会显示:
- 故事名称和概述
- 场景数量和镜头数量
- 前几个镜头的描述预览
内置模板示例:
| 模板名 | 描述 | 镜头数 |
|---|---|---|
| 林黛玉传 | 经典文学人物故事 | 20+ |
| 黑客帝国 | 科幻动作风格 | 15+ |
| 海边日落 | 简单风景测试 | 1 |
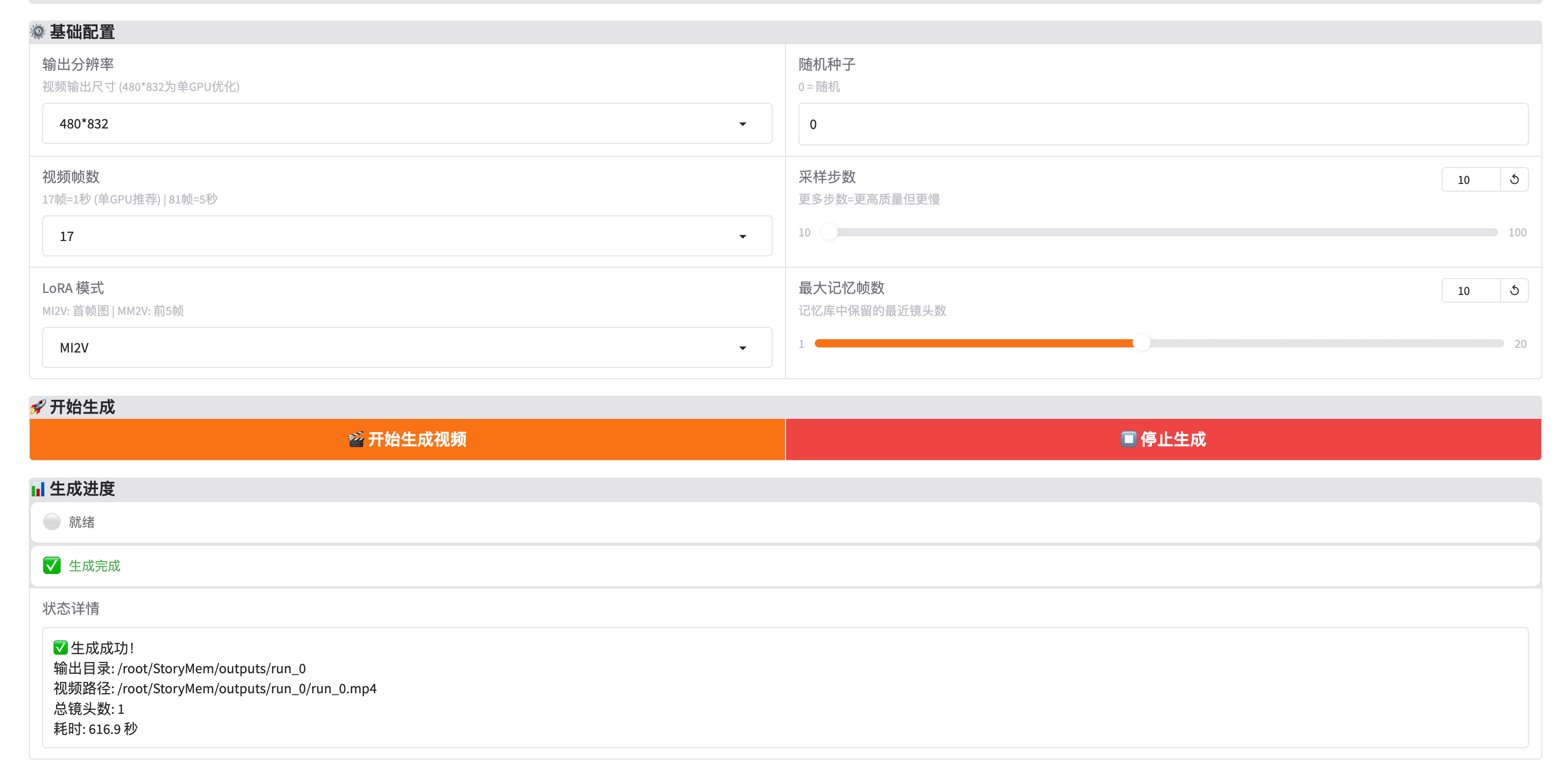
2.2 配置基础参数
| 参数 | 说明 | 推荐值 |
|---|---|---|
| 输出分辨率 | 视频尺寸 | 480*832(竖屏)832*480(横屏)1280*720(高清) |
| 随机种子 | 控制生成随机性 | 0 = 随机固定数字 = 可复现 |
| LoRA 模式 | 连续帧生成策略 | MI2V: 使用首帧参考MM2V: 使用前5帧参考 |
| 最大记忆帧数 | 记忆库容量 | 5-10 帧推荐影响角色一致性 |
2.3 开始生成
- 点击「🎬 开始生成视频」按钮
- 观察进度条和状态信息
- 生成完成后视频自动显示
- 点击视频右下角下载按钮保存
生成时间参考(RTX 3090,40步采样):
- 单镜头约 30-40 秒
- 10 镜头约 6-8 分钟
2.4 进度监控
生成过程中可以实时查看:
- 进度条: 整体完成百分比
- 状态指示器: 当前阶段(准备/生成/完成/错误)
- 状态详情: 具体操作信息(如"生成镜头 3/10")
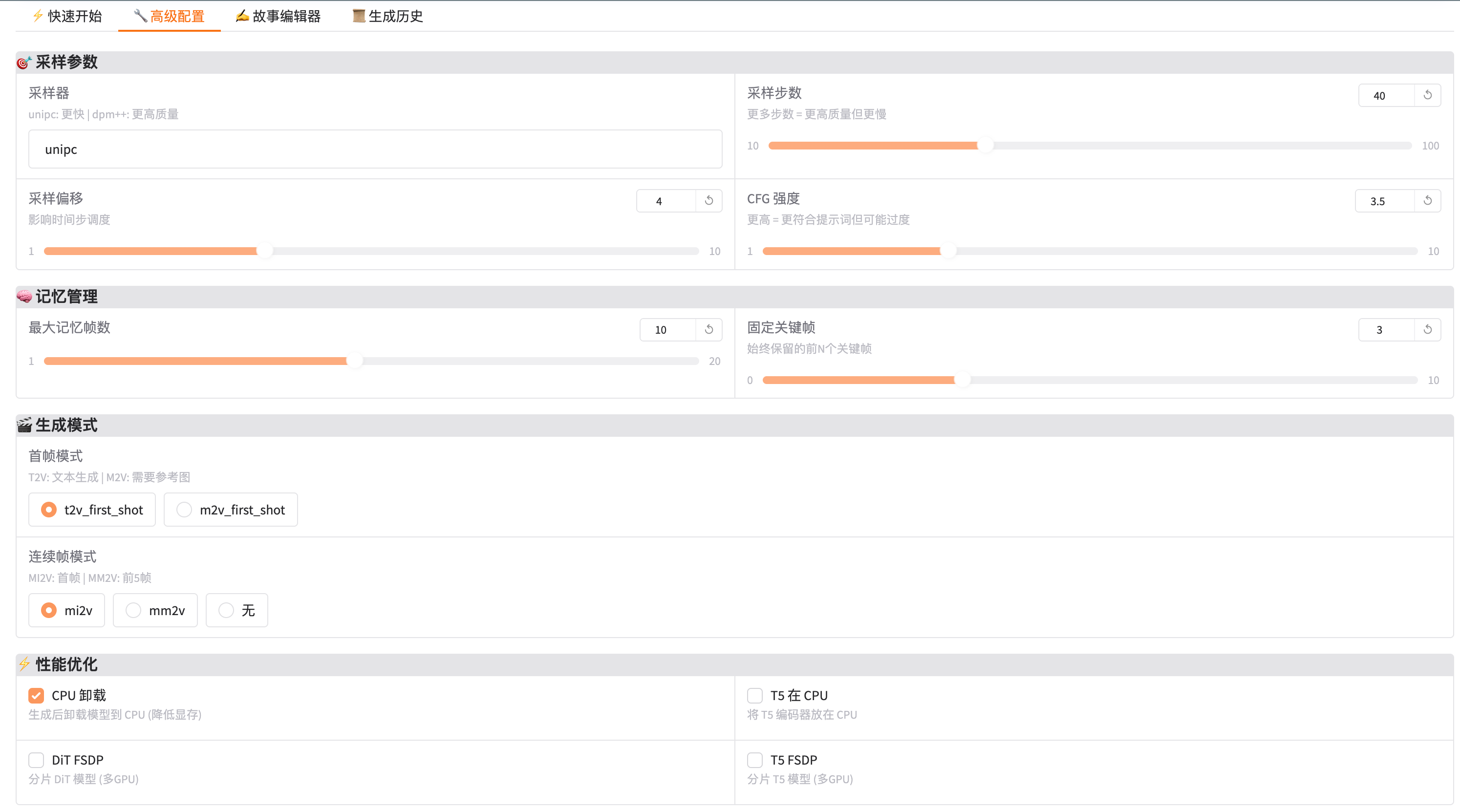
三、高级配置
3.1 采样参数
| 参数 | 说明 | 调优建议 |
|---|---|---|
| 采样器 | 去噪算法 | unipc: 更快dpm++: 更高质量 |
| 采样步数 | 去噪迭代次数 | 40: 推荐10-30: 更快50-100: 更高质量 |
| 采样偏移 | 时间步调度 | 4.0: 默认调高可改善动态效果 |
| CFG 强度 | 提示词遵循度 | 3.5: 默认调高更严格遵循提示词 |
3.2 记忆管理
| 参数 | 说明 |
|---|---|
| 最大记忆帧数 | 记忆库保留的最近镜头数量 |
| 固定关键帧 | 始终保留的前 N 个关键帧(确保开头一致性) |
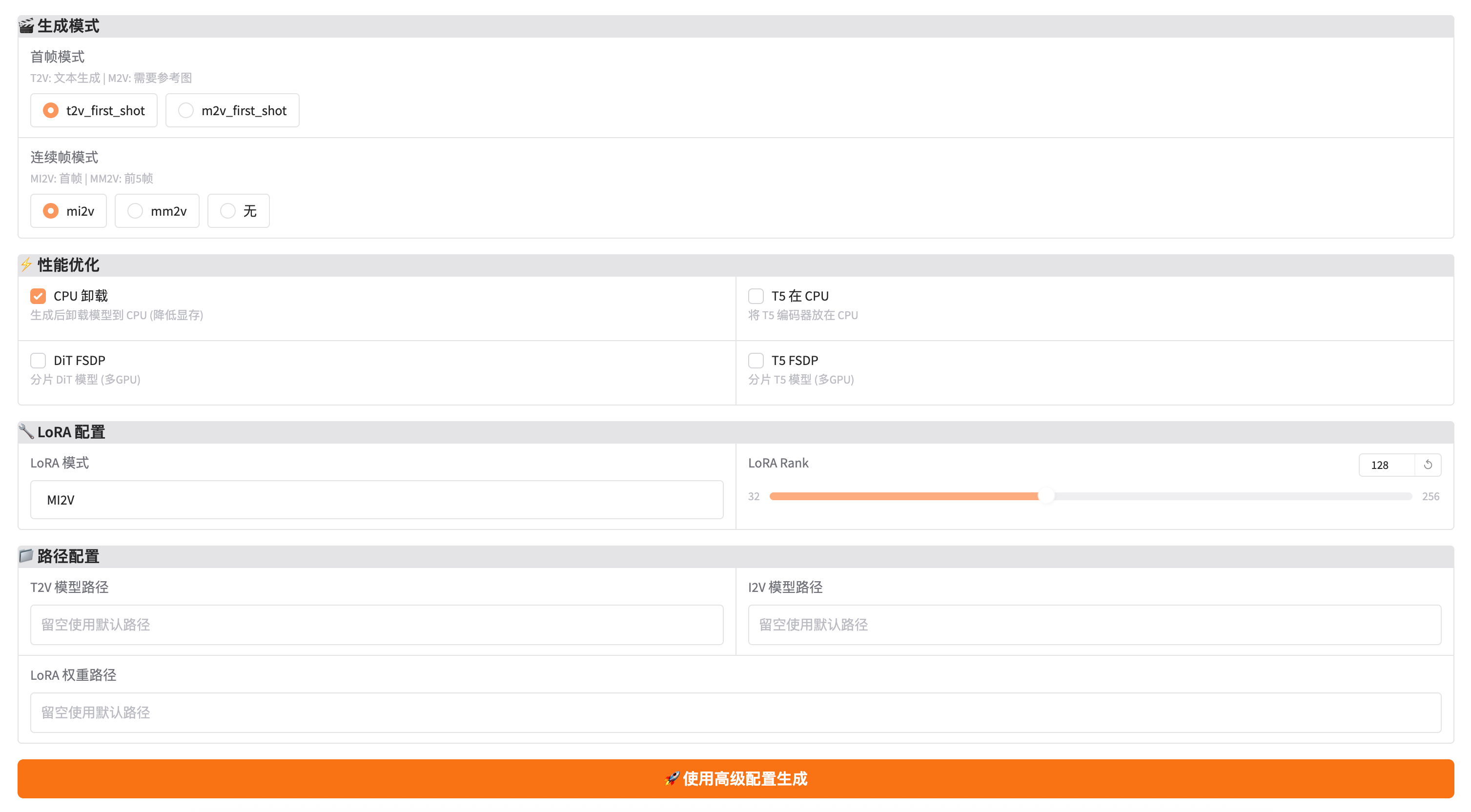
3.3 生成模式
首帧模式:
t2v_first_shot: 第一镜头使用纯文本生成m2v_first_shot: 第一镜头也需要参考图像
连续帧模式:
mi2v: 每个新镜头只参考首帧mm2v: 每个新镜头参考前 5 帧无: 不使用记忆机制
3.4 性能优化
| 选项 | 说明 | 显存节省 |
|---|---|---|
| CPU 卸载 | 生成后释放 GPU 显存 | ~5GB |
| T5 在 CPU | 文本编码器放 CPU | ~3GB |
| DiT FSDP | 多 GPU 并行(需要多卡) | - |
| T5 FSDP | 多 GPU 并行(需要多卡) | - |
3.5 LoRA 配置
| 参数 | 说明 |
|---|---|
| LoRA 模式 | MI2V 或 MM2V 权重 |
| LoRA Rank | LoRA 秩数(通常使用 128) |
3.6 自定义路径
如需使用其他模型版本,可在此配置:
- T2V 模型路径
- I2V 模型路径
- LoRA 权重路径
留空则使用默认路径。
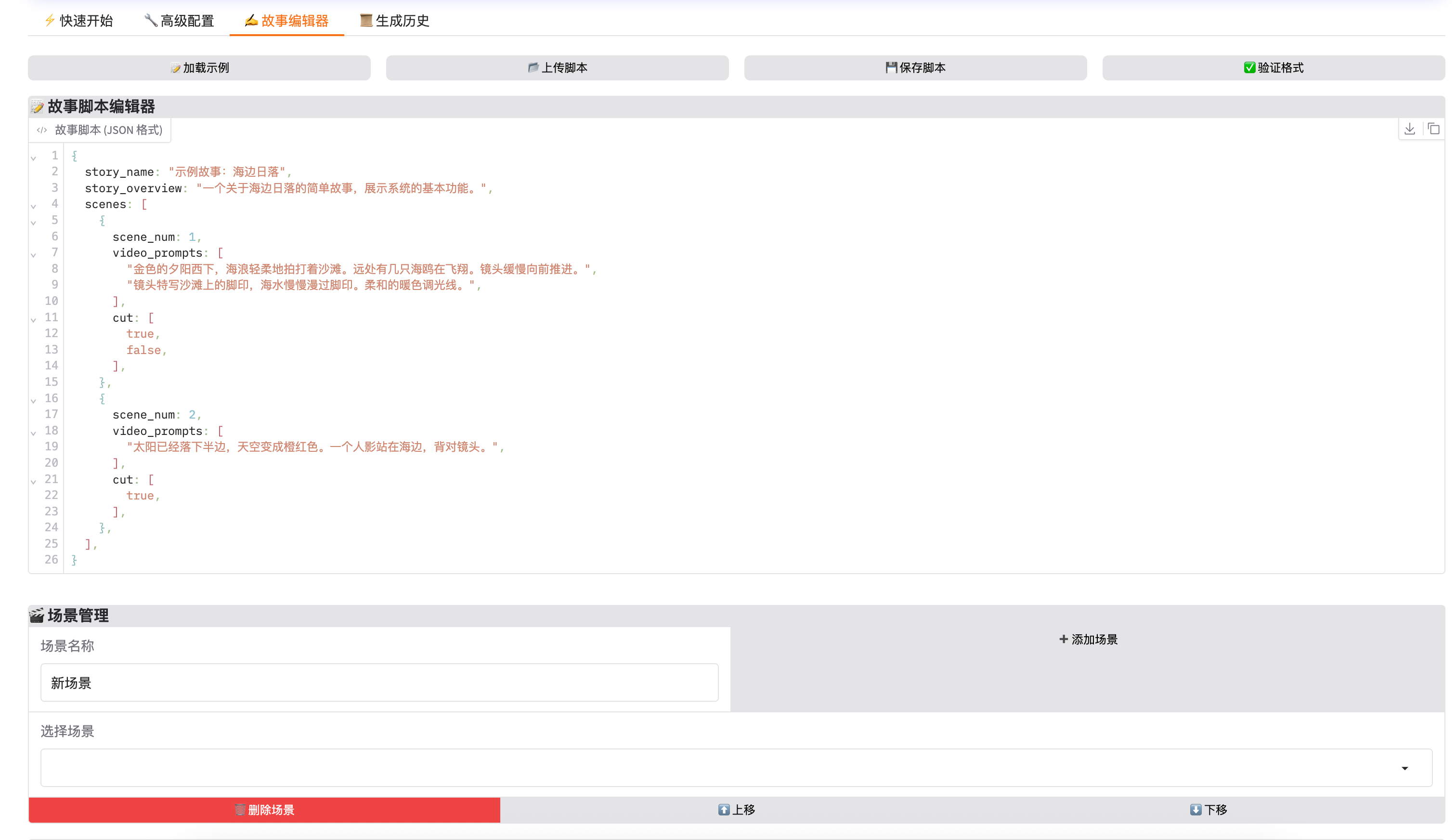
四、故事编辑器
4.1 加载示例
点击「📝 加载示例」查看标准故事脚本格式。
4.2 脚本格式
{
"story_name": "我的故事",
"story_overview": "故事简述",
"scenes": [
{
"scene_num": 1,
"video_prompts": [
"镜头1描述...",
"镜头2描述..."
],
"cut": [true, false]
}
]
}
字段说明:
story_name: 故事名称story_overview: 故事概述scenes: 场景列表scene_num: 场景编号video_prompts: 镜头描述列表cut: 场景切换标记(true 表示新场景开始)
4.3 验证脚本
点击「✅ 验证格式」检查脚本是否符合规范。
4.4 保存脚本
- 输入场景名称
- 点击「💾 保存脚本」
- 脚本将保存到
story/custom/目录
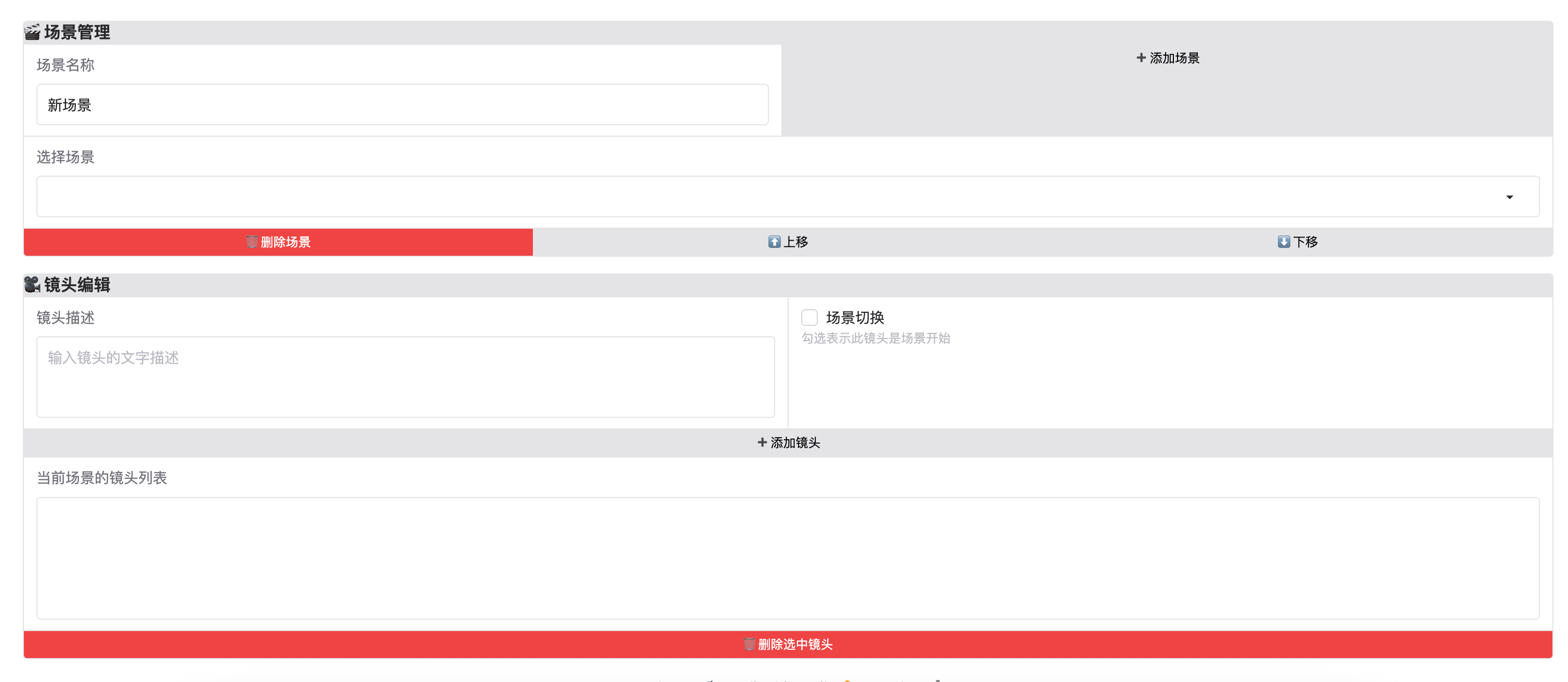
4.5 场景管理
- 添加场景: 输入名称后点击「➕ 添加场景」
- 删除场景: 选中后点击「🗑️ 删除场景」
- 调整顺序: 使用「⬆️ 上移」「⬇️ 下移」
4.6 镜头编辑
- 添加镜头: 输入描述后点击「➕ 添加镜头」
- 场景切换: 勾选表示此镜头是新场景的开始
- 删除镜头: 点击「🗑️ 删除选中镜头」
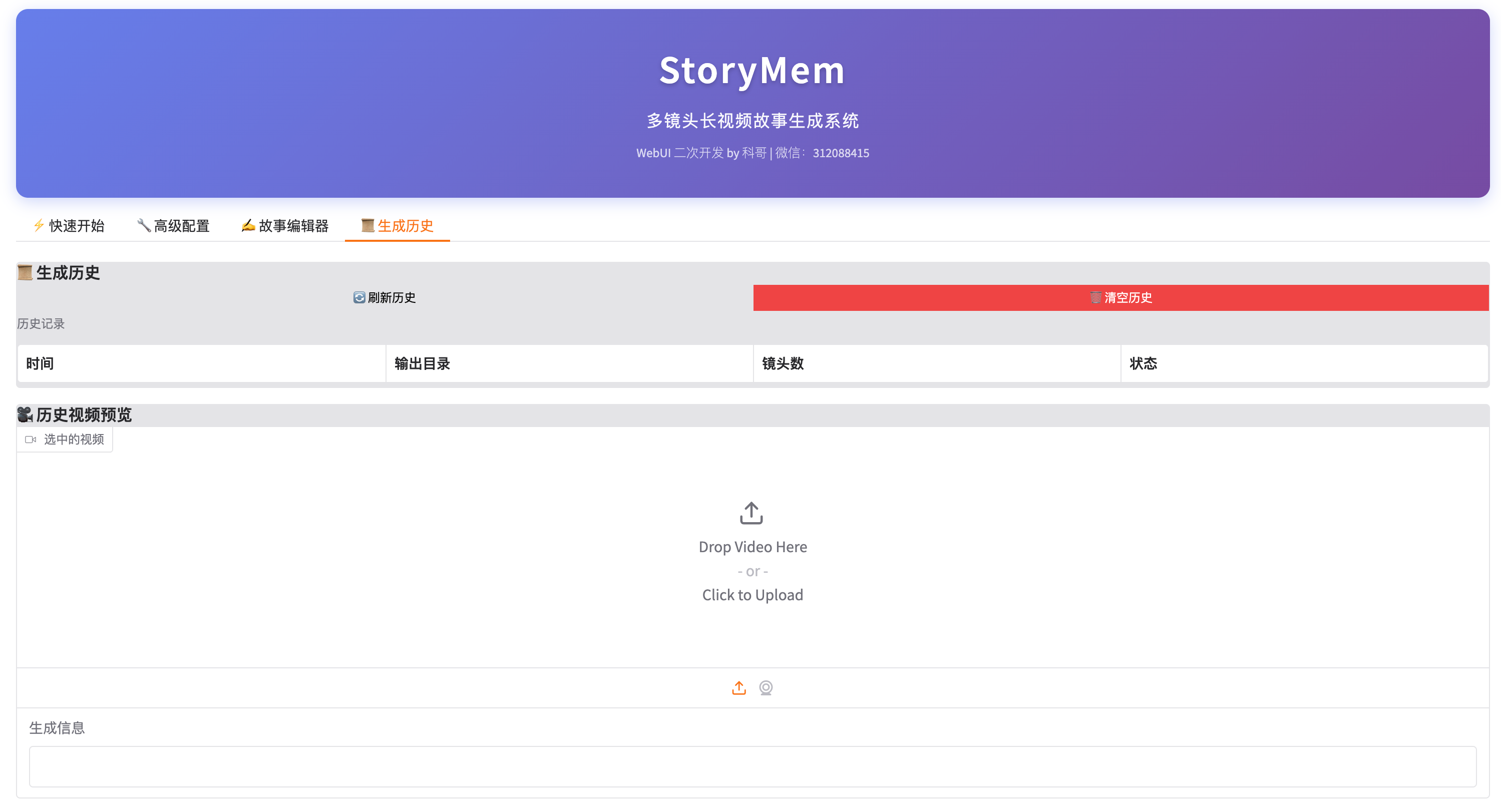
五、生成历史
5.1 查看历史
- 历史记录显示所有生成任务
- 信息包括:时间、输出目录、镜头数、状态
5.2 预览视频
- 点击历史记录中的条目
- 右侧预览区域显示选中视频
- 可查看生成信息
5.3 管理历史
- 🔄 刷新历史: 更新历史列表
- 🗑️ 清空历史: 删除所有历史记录
六、常见问题
6.1 生成失败怎么办?
- 检查「状态详情」中的错误信息
- 常见原因:
- GPU 显存不足 → 尝试启用「CPU 卸载」或「T5 在 CPU」
- 模型文件缺失 → 检查模型路径配置
- 脚本格式错误 → 使用「验证格式」检查
6.2 如何提高生成质量?
- 增加采样步数(50-100)
- 使用
dpm++采样器 - 增大 CFG 强度(4.0-5.0)
- 使用更详细的镜头描述
6.3 如何加快生成速度?
- 减少采样步数(20-30)
- 使用
unipc采样器 - 使用较低分辨率(480*832)
- 启用 CPU 卸载
6.4 角色不一致怎么办?
- 增加最大记忆帧数
- 增加固定关键帧数
- 使用
mm2v模式(更多参考帧) - 在提示词中强调角色特征
七、最佳实践
7.1 故事编写技巧
-
镜头描述要具体:
- ✅ "一位长发女孩穿着白裙子站在海边,夕阳西下,海鸥飞翔"
- ❌ "海边风景"
-
保持风格连贯:所有镜头使用相似的语言风格
-
合理控制长度:
- 测试: 1-3 镜头
- 短故事: 5-10 镜头
- 长故事: 15-30 镜头
7.2 参数推荐配置
快速测试:
分辨率: 480*832
采样步数: 20
采样器: unipc
LoRA 模式: MI2V
高质量输出:
分辨率: 832*480 或 1280*720
采样步数: 50
采样器: dpm++
CFG 强度: 4.5
LoRA 模式: MM2V
记忆帧数: 8
节省显存:
CPU 卸载: 启用
T5 在 CPU: 启用
分辨率: 480*832
7.3 输出文件说明
生成完成后,输出目录包含:
outputs/run_<seed>/
├── shots/ # 单镜头视频
├── scenes/ # 场景拼接视频
└── final/ # 最终完整视频
八、A800 GPU 优化指南
本章节专门针对使用 NVIDIA A800 (80GB) 显卡的用户提供优化配置。
8.1 Flash Attention 说明
重要: A800 是 Ampere 架构 GPU,Flash Attention 2 是最佳选择。
| 版本 | 适用架构 | A800 状态 |
|---|---|---|
| Flash Attention 2 | Ampere (A100/A800) | ✅ 已安装 2.8.3 |
| Flash Attention 3 | Hopper (H100/H800) | ❌ 不适用 |
无需安装 Flash Attention 3,它专为 H100/H800 优化,在 A800 上性能提升有限。
8.2 单卡 A800 配置
适用场景: 单卡 A800 80GB
WebUI 配置:
CPU 卸载: ✅ 启用
T5 在 CPU: ❌ 关闭(显存充足时)
DiT FSDP: ❌ 单卡不适用
T5 FSDP: ❌ 单卡不适用
命令行启动:
python pipeline.py \
--story_script_path ./story/daiyu.json \
--t2v_model_path ./models/Wan2.2-T2V-A14B \
--i2v_model_path ./models/Wan2.2-I2V-A14B \
--lora_weight_path ./models/StoryMem/Wan2.2-MI2V-A14B \
--size "832*480" \
--max_memory_size 10 \
--offload_model \
--t2v_first_shot \
--mi2v \
--output_dir ./results
8.3 多卡 A800 配置
适用场景: 8卡 A800 80GB(最优配置)
WebUI 配置:
CPU 卸载: ❌ 关闭
T5 在 CPU: ❌ 关闭
DiT FSDP: ✅ 启用
T5 FSDP: ⚠️ 可选(显存紧张时启用)
命令行启动 (推荐):
torchrun --nproc_per_node=8 pipeline.py \
--story_script_path ./story/daiyu.json \
--t2v_model_path ./models/Wan2.2-T2V-A14B \
--i2v_model_path ./models/Wan2.2-I2V-A14B \
--lora_weight_path ./models/StoryMem/Wan2.2-MI2V-A14B \
--size "832*480" \
--max_memory_size 10 \
--dit_fsdp \
--ulysses_size 8 \
--t2v_first_shot \
--mi2v \
--output_dir ./results
极致性能配置:
torchrun --nproc_per_node=8 pipeline.py \
--story_script_path ./story/daiyu.json \
--t2v_model_path ./models/Wan2.2-T2V-A14B \
--i2v_model_path ./models/Wan2.2-I2V-A14B \
--lora_weight_path ./models/StoryMem/Wan2.2-MI2V-A14B \
--size "1280*720" \
--max_memory_size 15 \
--dit_fsdp \
--t5_fsdp \
--ulysses_size 8 \
--convert_model_dtype \
--t2v_first_shot \
--mi2v \
--output_dir ./results
8.4 参数详解
| 参数 | 单卡 | 多卡(8x) | 说明 |
|---|---|---|---|
--offload_model | ✅ 启用 | ❌ 关闭 | 模型卸载到CPU节省显存 |
--dit_fsdp | ❌ 不可用 | ✅ 启用 | DiT模型FSDP分片 |
--t5_fsdp | ❌ 不可用 | ⚠️ 可选 | T5文本编码器FSDP |
--t5_cpu | ⚠️ 显存不足时 | ❌ 不推荐 | T5放CPU上 |
--ulysses_size | 1 | 8 | 序列并行大小=GPU数 |
--convert_model_dtype | 可选 | ✅ 推荐 | 转换模型精度 |
8.5 性能参考 (A800 80GB)
| 配置 | 分辨率 | 单镜头耗时 | 10镜头耗时 |
|---|---|---|---|
| 单卡 + offload | 832*480 | ~40秒 | ~7分钟 |
| 8卡 + FSDP | 832*480 | ~15秒 | ~3分钟 |
| 8卡 + FSDP | 1280*720 | ~25秒 | ~5分钟 |
8.6 常见问题
Q: 显存不足 (OOM) 怎么办?
- 单卡: 启用
--offload_model和--t5_cpu - 多卡: 增加 GPU 数量或启用
--t5_fsdp
Q: 生成速度慢怎么办?
- 使用多卡并行
- 启用
--dit_fsdp - 降低分辨率到
480*832
Q: 质量与速度如何平衡?
- 快速: 20步 + unipc
- 平衡: 40步 + unipc
- 高质量: 50步 + dpm++
九、快捷键与技巧
- Ctrl + Enter: 在某些输入框中可快速提交
- 刷新模板: 如果更新了模板文件,点击「🔄 刷新列表」
- 停止生成: 生成过程中点击「⏹️ 停止生成」可中断任务
版本: 1.1 更新日期: 2025-12-28 技术支持: 科哥 | 微信:312088415
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
 认证作者
认证作者
 支持自启动
支持自启动