 0
0谷歌最新翻译模型TranslateGemma支持全世界50多种语言的翻译文本多语言翻译 二次webui开发 构建by科哥
运行截图
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
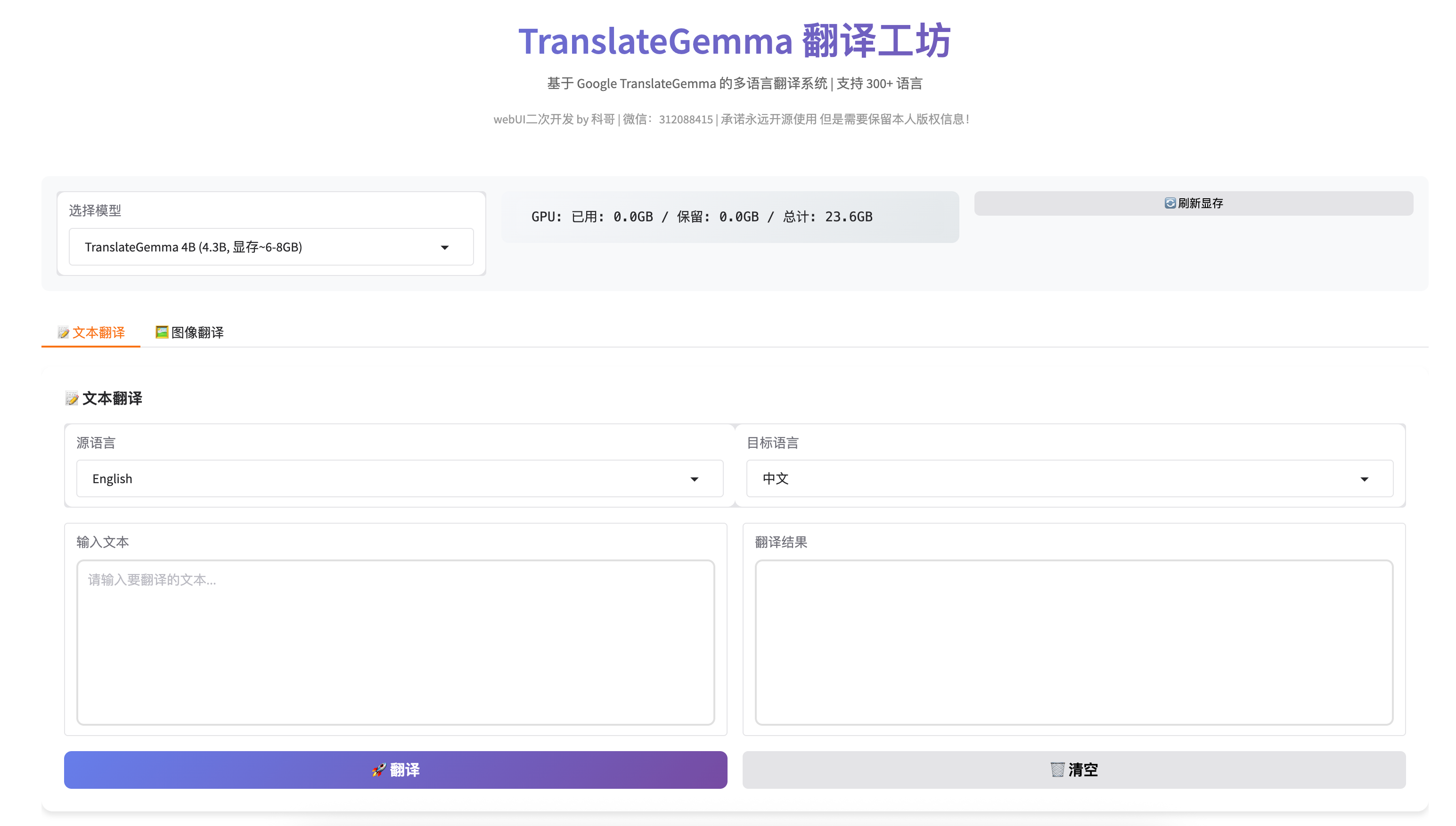
TranslateGemma 翻译工坊 - 用户使用手册
欢迎使用 TranslateGemma 翻译工坊 🎉
这是一个基于 Google TranslateGemma 的多语言翻译系统,支持 300+ 语言的文本翻译和图像 OCR 翻译。
快速开始
启动应用
在项目目录下运行启动脚本:
bash start_app.sh
启动成功后,浏览器访问:http://localhost:7860
功能介绍
1. 文本翻译 📝
适用场景:翻译文字、段落、文章等文本内容
使用步骤
-
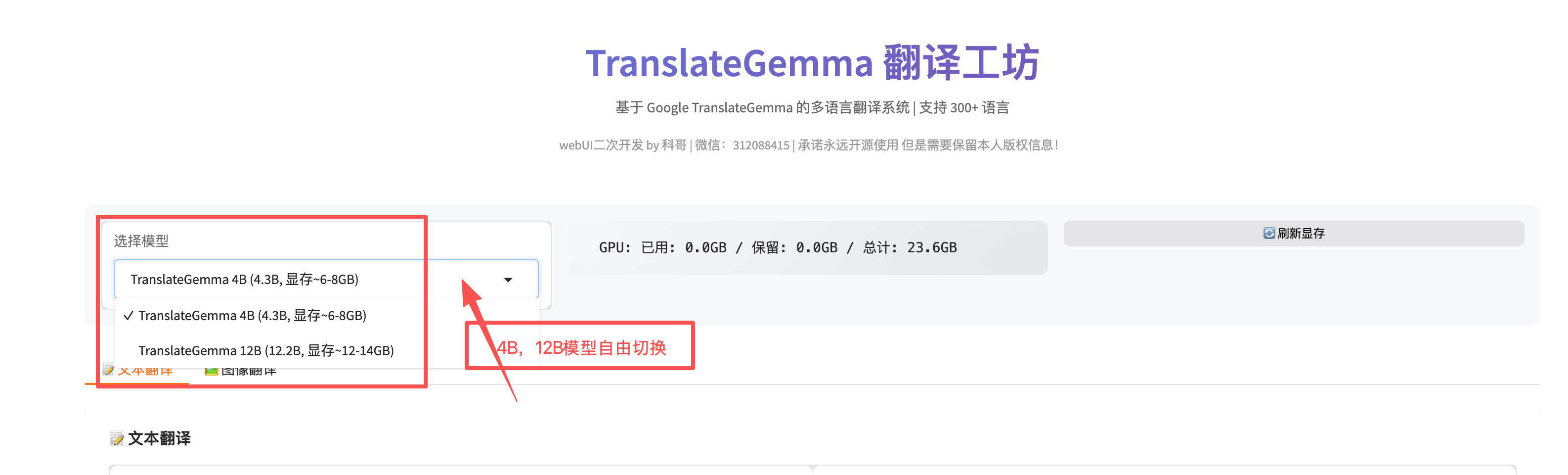
选择模型(页面顶部)
- TranslateGemma 4B:速度快,适合日常使用(推荐)
- TranslateGemma 12B:质量更高,适合专业翻译
-
切换到"文本翻译"标签页
-
选择语言
- 源语言:选择要翻译的文本语言
- 目标语言:选择翻译后的目标语言
-
输入文本
- 在左侧文本框输入要翻译的内容
- 支持多行文本
-
点击"🚀 翻译"按钮
- 翻译结果会显示在右侧文本框
- 翻译结果会自动保存到
outputs/目录
-
清空内容
- 点击"🗑️ 清空"按钮清除输入和输出
支持的语言
常用语言包括:
- 中文 (Chinese)
- English (英语)
- 日本語 (日语)
- 한국어 (韩语)
- Français (法语)
- Deutsch (德语)
- Español (西班牙语)
- Italiano (意大利语)
- Português (葡萄牙语)
- Русский (俄语)
- العربية (阿拉伯语)
- हिन्दी (印地语)
- ไทย (泰语)
- Tiếng Việt (越南语)
注意:系统支持 300+ 种语言,以上仅为常用语言列表。
2. 图像翻译 🖼️
适用场景:翻译图片中的文字(如截图、照片、扫描件等)
使用步骤
-
切换到"图像翻译"标签页
-
上传图片
- 点击上传区域选择图片
- 或直接拖拽图片到上传区域
- 支持格式:JPG、PNG、BMP 等常见图片格式
-
选择目标语言
- 系统会自动检测图片中的文字语言
- 只需选择翻译后的目标语言
-
点击"🚀 提取并翻译"按钮
- 系统会先提取图片中的文字(OCR)
- 然后自动检测文字语言
- 最后翻译成目标语言
-
查看结果
- 提取的文字:显示在左侧文本框
- 翻译结果:显示在右侧文本框
- 结果会自动保存到
outputs/目录
使用技巧
- 图片清晰度:图片越清晰,OCR 识别越准确
- 文字大小:建议文字不要太小,否则可能识别不准
- 背景对比:文字与背景对比度高,识别效果更好
- 多语言混合:支持图片中包含多种语言的情况
模型选择指南
TranslateGemma 4B(推荐)
优势:
- ✅ 速度快(1-2 秒/次)
- ✅ 显存占用小(~8GB)
- ✅ 适合日常使用
适用场景:
- 日常文本翻译
- 快速查词
- 社交媒体内容翻译
- 图片文字翻译
TranslateGemma 12B(专业)
优势:
- ✅ 翻译质量更高
- ✅ 更准确的语义理解
- ✅ 适合专业翻译
适用场景:
- 专业文档翻译
- 学术论文翻译
- 商务合同翻译
- 文学作品翻译
注意:12B 模型需要更多显存(~14GB),如果显存不足,请使用 4B 模型。
翻译结果保存
自动保存
所有翻译结果会自动保存到 outputs/ 目录,文件名格式:
outputs_YYYYMMDDHHmmss.txt
例如:outputs_20260116112535.txt
文件内容格式
==================================================
时间: 2026-01-16 11:25:35
类型: 文本翻译 / 图像翻译
源语言: en
目标语言: zh
==================================================
【原文】
Hello world
【译文】
你好,世界。
常见问题 FAQ
Q1: 首次翻译为什么很慢?
A: 首次翻译需要加载模型到 GPU,大约需要 2-3 秒。后续翻译会很快(1-2 秒)。
Q2: 如何切换模型?
A: 在页面顶部的"选择模型"下拉框中选择,系统会自动切换并清理显存。
Q3: 图像翻译识别不准怎么办?
A:
- 确保图片清晰度足够
- 文字与背景对比度要高
- 避免文字过小或模糊
- 可以尝试调整图片亮度/对比度后重新上传
Q4: 支持哪些图片格式?
A: 支持常见图片格式:JPG、JPEG、PNG、BMP、GIF 等。
Q5: 翻译结果保存在哪里?
A: 所有翻译结果自动保存在项目的 outputs/ 目录下。
Q6: 可以同时翻译多段文本吗?
A: 可以。在文本框中输入多段文本(用换行分隔),系统会一次性翻译。
Q7: 如何查看 GPU 显存使用情况?
A: 页面顶部会显示当前 GPU 显存使用情况,点击"🔄 刷新显存"按钮可以更新。
Q8: 翻译速度慢怎么办?
A:
- 使用 4B 模型(速度更快)
- 减少单次翻译的文本量
- 确保 GPU 显存充足
- 关闭其他占用 GPU 的程序
Q9: 出现错误怎么办?
A:
- 刷新浏览器页面
- 重启应用:
bash start_app.sh - 检查 GPU 显存是否充足
- 查看
outputs/目录下的日志文件
Q10: 如何停止应用?
A:
# 方法1:在终端按 Ctrl+C
# 方法2:使用命令
lsof -ti:7860 | xargs kill -9
使用技巧
1. 批量翻译
将多段文本用换行分隔,一次性输入到文本框,系统会自动翻译所有内容。
2. 翻译历史
所有翻译结果都保存在 outputs/ 目录,可以随时查看历史翻译记录。
3. 快捷操作
- 清空内容:点击"🗑️ 清空"按钮
- 刷新显存:点击"🔄 刷新显存"按钮
- 切换模型:直接在下拉框选择
4. 最佳实践
- 短文本:使用 4B 模型,速度快
- 长文本:使用 12B 模型,质量高
- 图片翻译:确保图片清晰,文字清楚
- 专业翻译:使用 12B 模型,并人工校对
性能参考
翻译速度
| 文本长度 | 4B 模型 | 12B 模型 |
|---|---|---|
| 短文本 (< 50 字) | ~1-2 秒 | ~2-3 秒 |
| 中等文本 (50-200 字) | ~2-3 秒 | ~3-5 秒 |
| 长文本 (> 200 字) | ~3-5 秒 | ~5-8 秒 |
| 图像 OCR | ~5-8 秒 | ~8-12 秒 |
资源占用
| 资源 | 4B 模型 | 12B 模型 |
|---|---|---|
| GPU 显存 | ~8GB | ~14GB |
| 系统内存 | ~750MB | ~1.2GB |
| CPU 使用率 | 3-5% (空闲) | 3-5% (空闲) |
注意事项
⚠️ 重要提示
- 首次使用:首次翻译需要加载模型,会比较慢(2-3 秒)
- 显存要求:确保 GPU 显存充足(4B 需要 8GB,12B 需要 14GB)
- 网络连接:首次运行需要下载模型(约 8-24GB),请确保网络稳定
- 版权信息:本项目开源免费,但请保留版权信息
💡 使用建议
- 日常使用:推荐使用 4B 模型,速度快且质量好
- 专业翻译:推荐使用 12B 模型,质量更高
- 图片翻译:确保图片清晰,文字清楚
- 批量翻译:可以一次性输入多段文本
技术支持
开发者:科哥 微信:312088415 承诺:永远开源使用,但需保留版权信息
版权声明
本项目基于 Google TranslateGemma 开源模型二次开发。
webUI 二次开发 by 科哥 | 微信:312088415
承诺永远开源使用,但是需要保留本人版权信息!
祝您使用愉快!如有问题,欢迎联系技术支持。
最后更新: 2026-01-16
 认证作者
认证作者
 支持自启动
支持自启动