 1
1One-to-All-Animation单图片转换动画视频数字人视频动作模仿器
镜像简介
本镜像集成One-to-All-Animation单图转动画工具,基于Wan2.1代数构建,可将单张人物图片转换为动态视频,并支持动作模仿与驱动。需48GB及以上显存环境运行,适用于数字人短视频创作、动画预演、形象IP动效生成及创意内容制作,为用户提供从静态到动态的一键式角色动画解决方案。
镜像使用指南
1、在社区镜像区域,选择镜像:
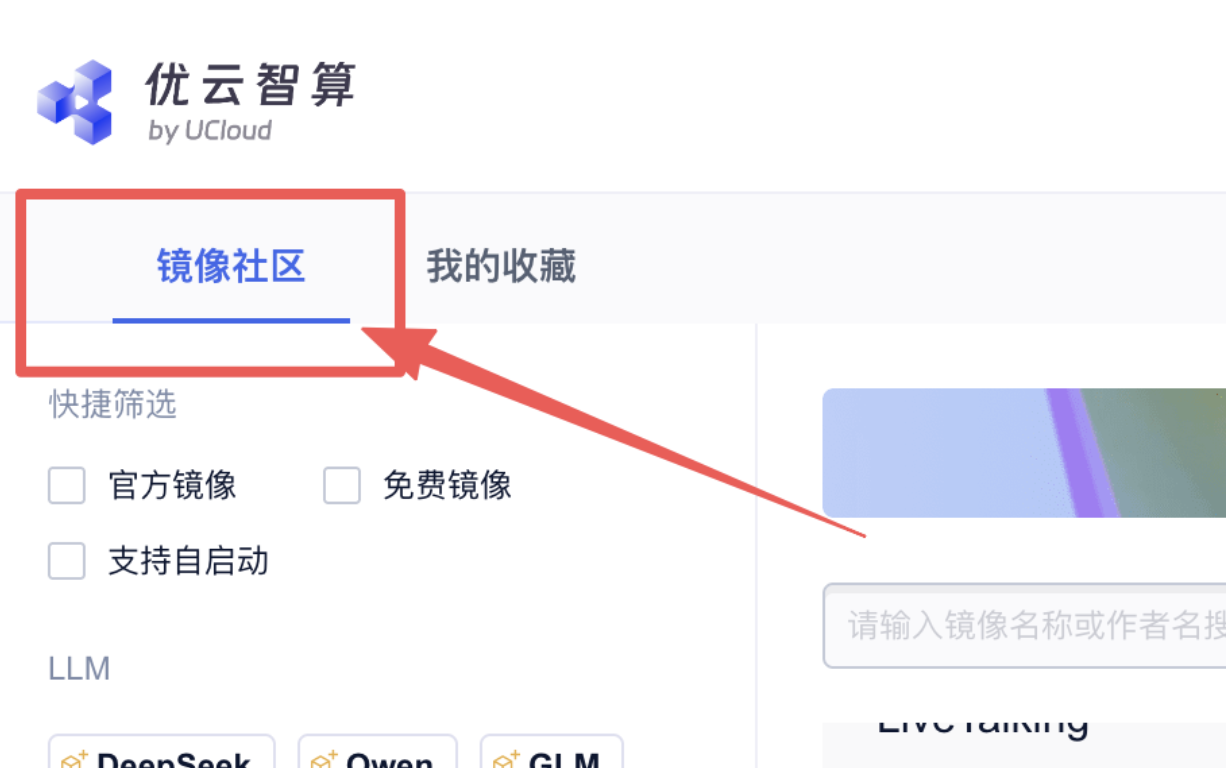
2、在打开的新页面 点击“使用该镜像创建实例”:
2、在打开的新页面 点击“使用该镜像创建实例”:
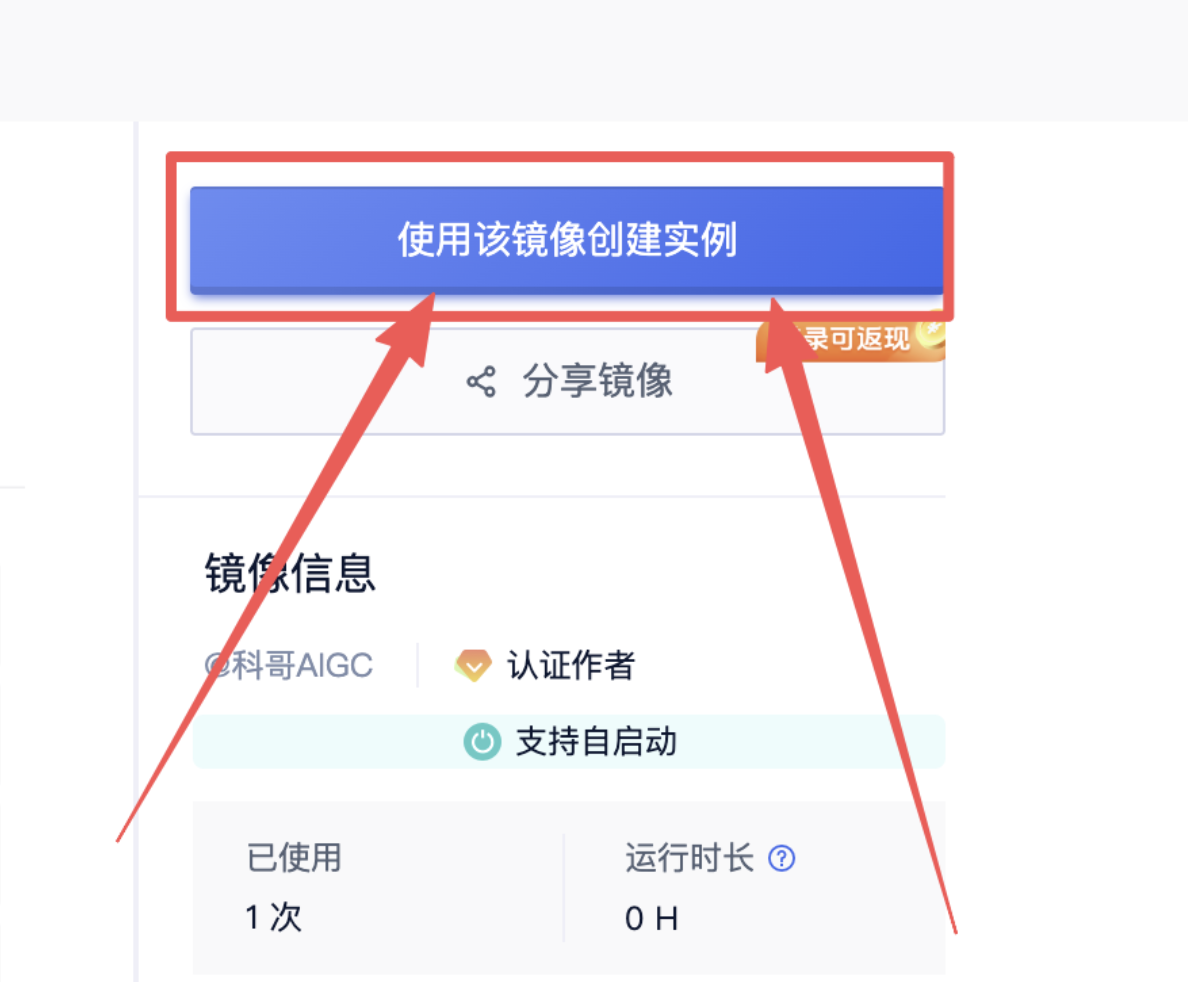
3、选择一个合适的显卡【GPU】根据情况选择,点击“开始部署”,然后等待部署完成:
3、选择一个合适的显卡【GPU】根据情况选择,点击“开始部署”,然后等待部署完成:
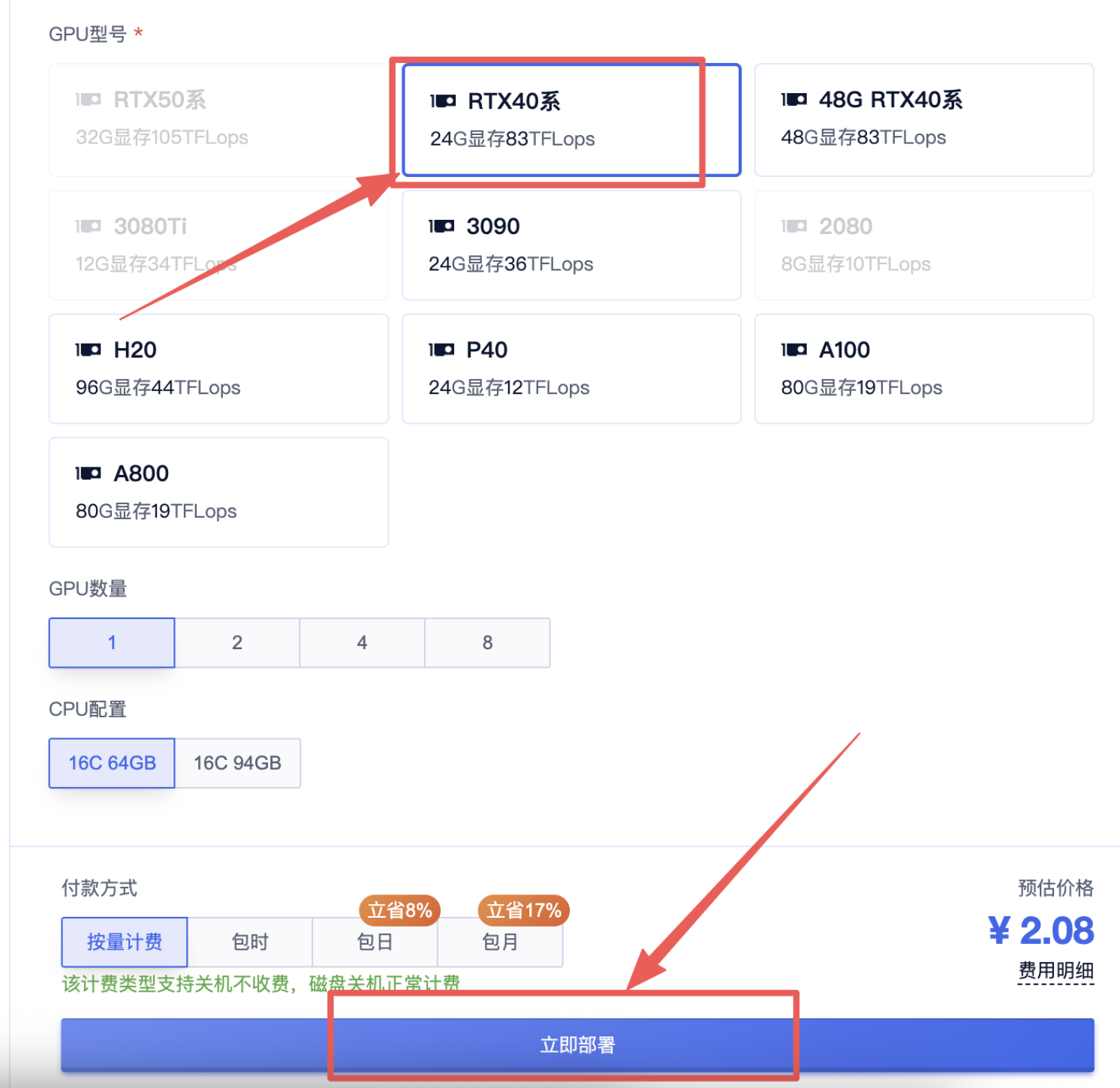
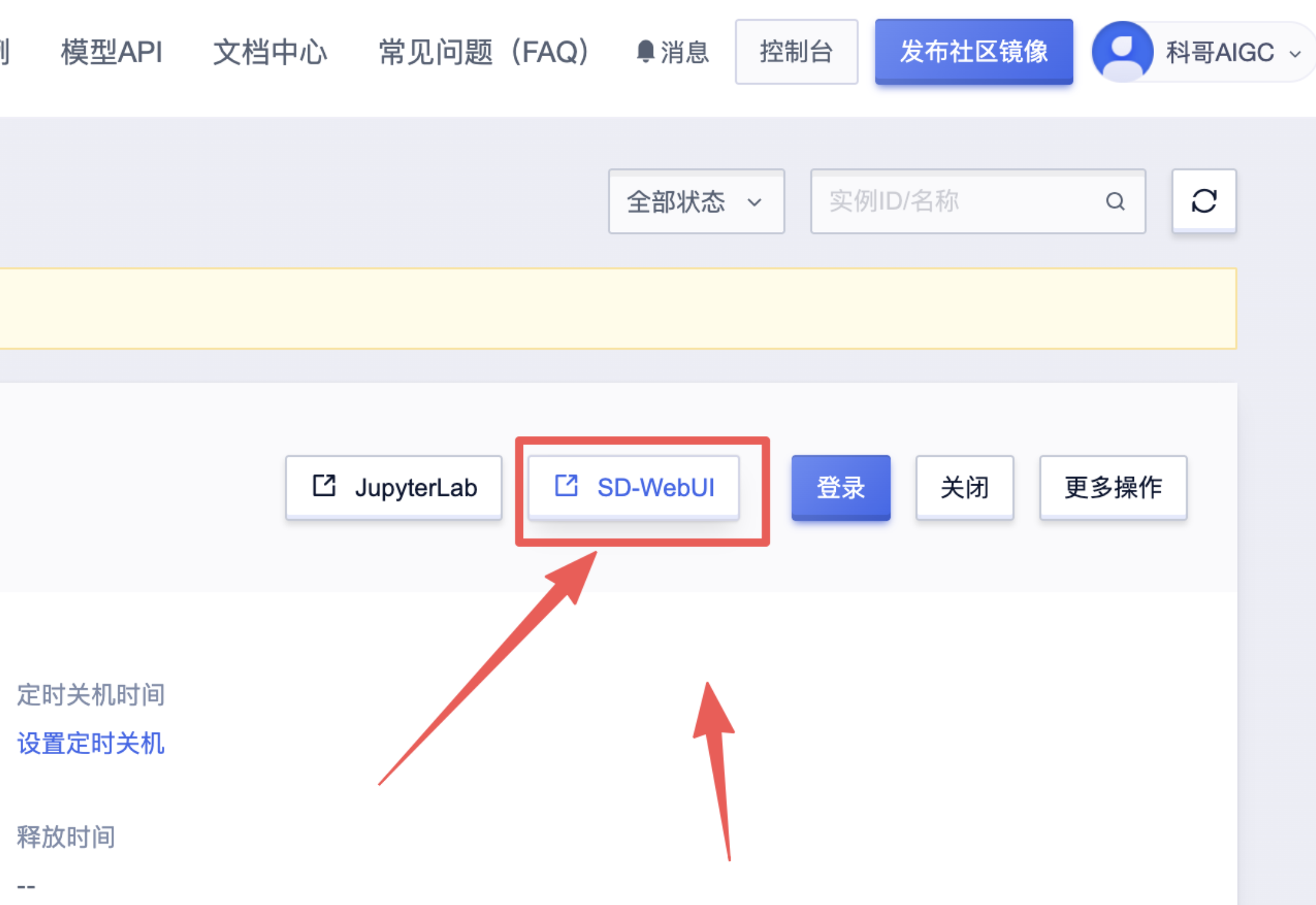
4、实例运行后打开SD-WebUI即可
如何启动应用
不是自动运行的应用:
1、手动点击加号新建起始页:
2、打开终端:
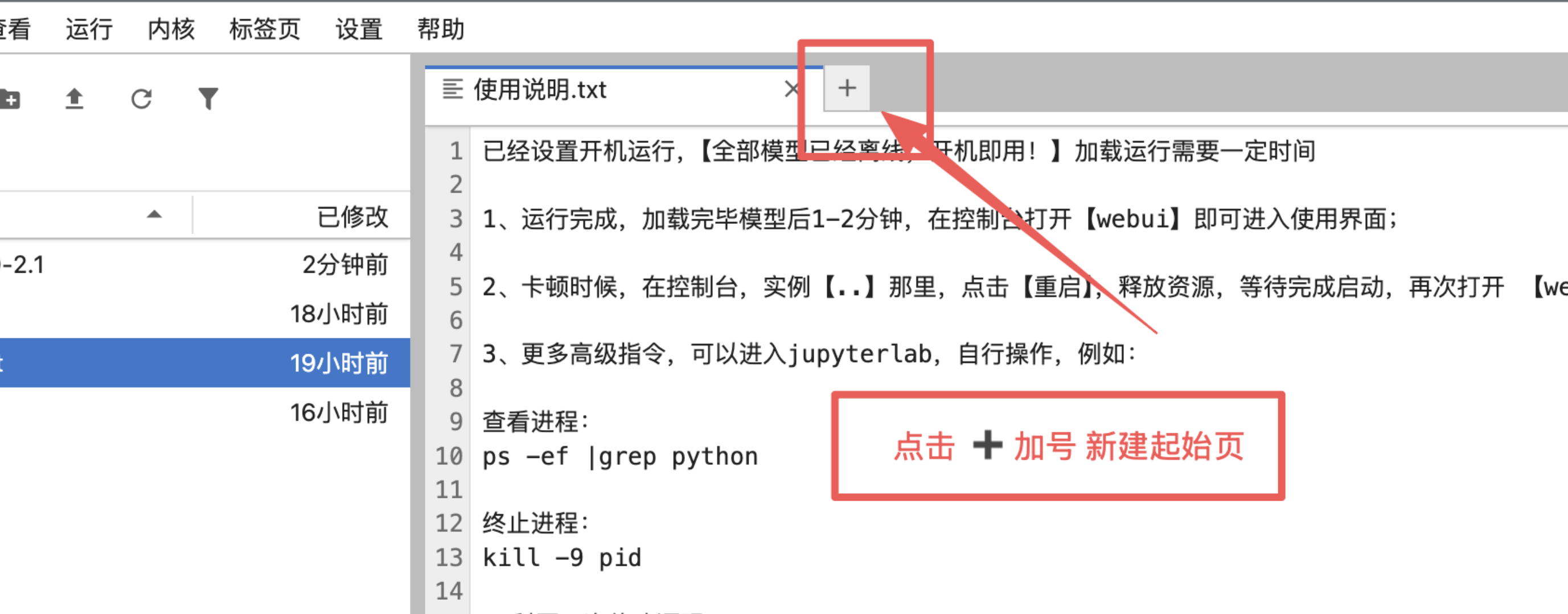
3、输入指令然后回车:
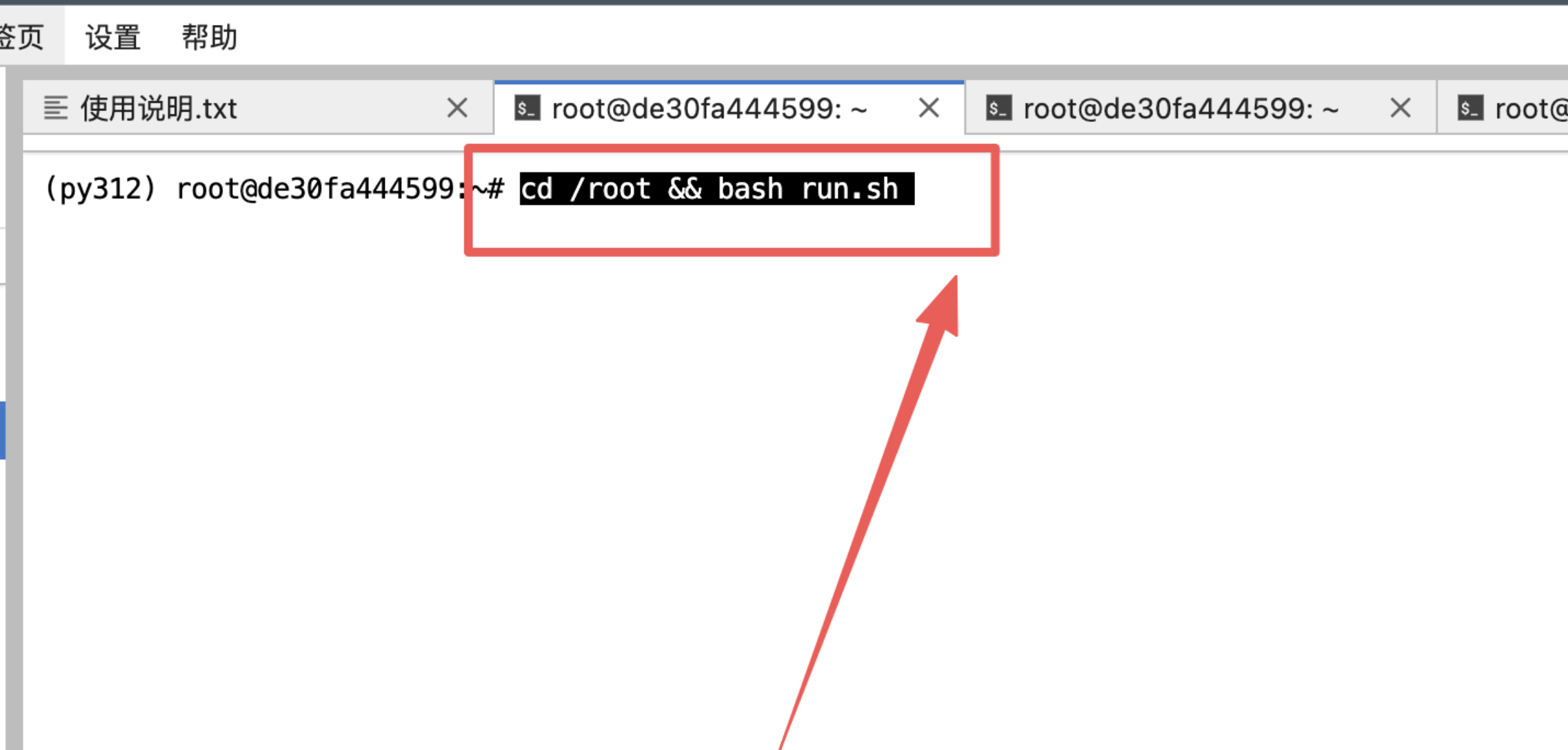
4、等待加载模型完毕:
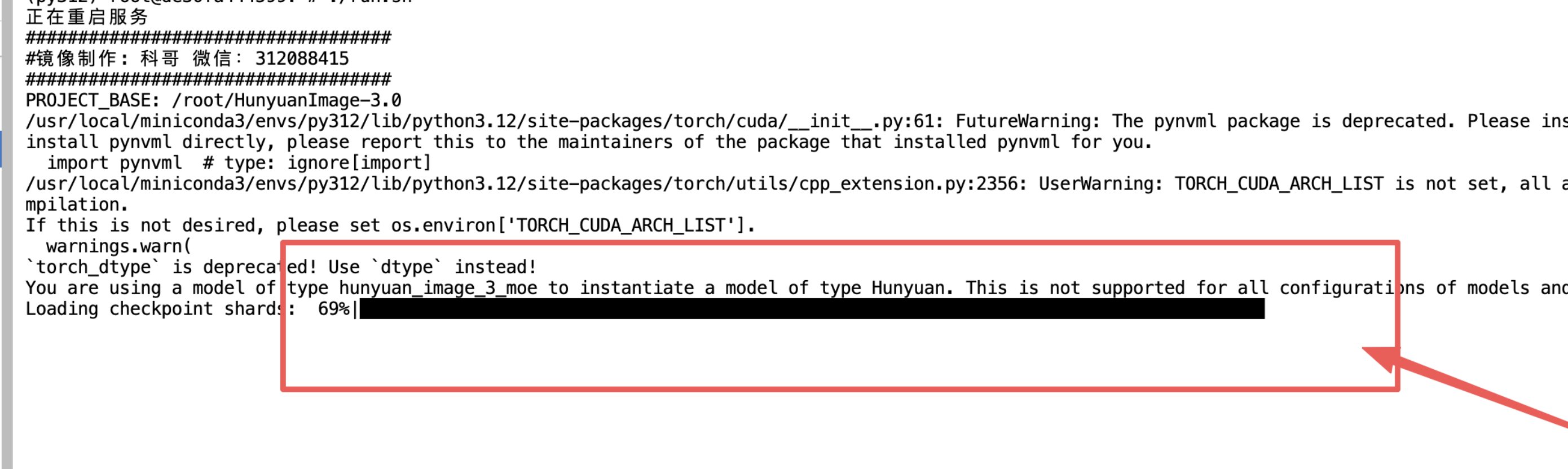
5、看到这个出现:
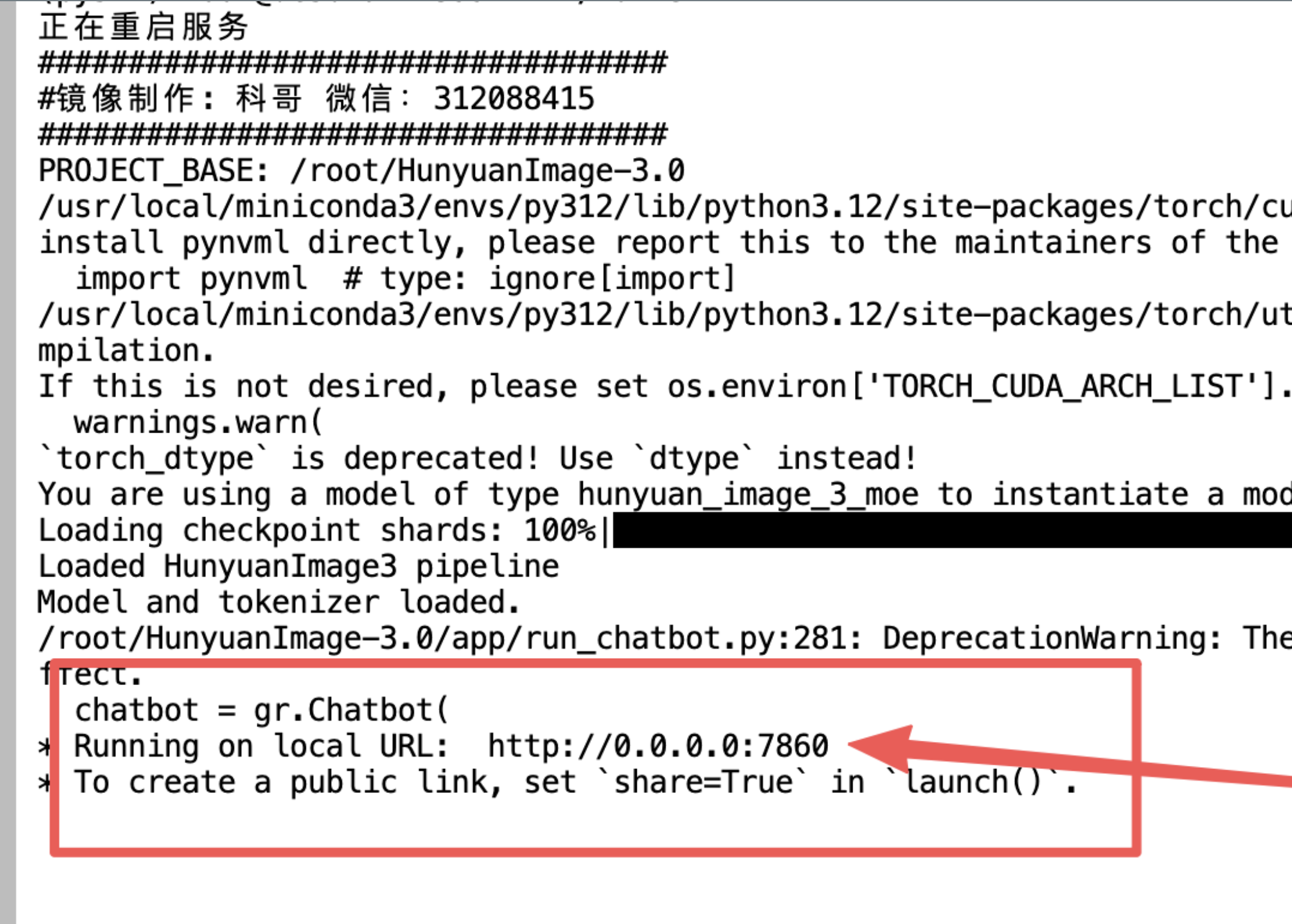
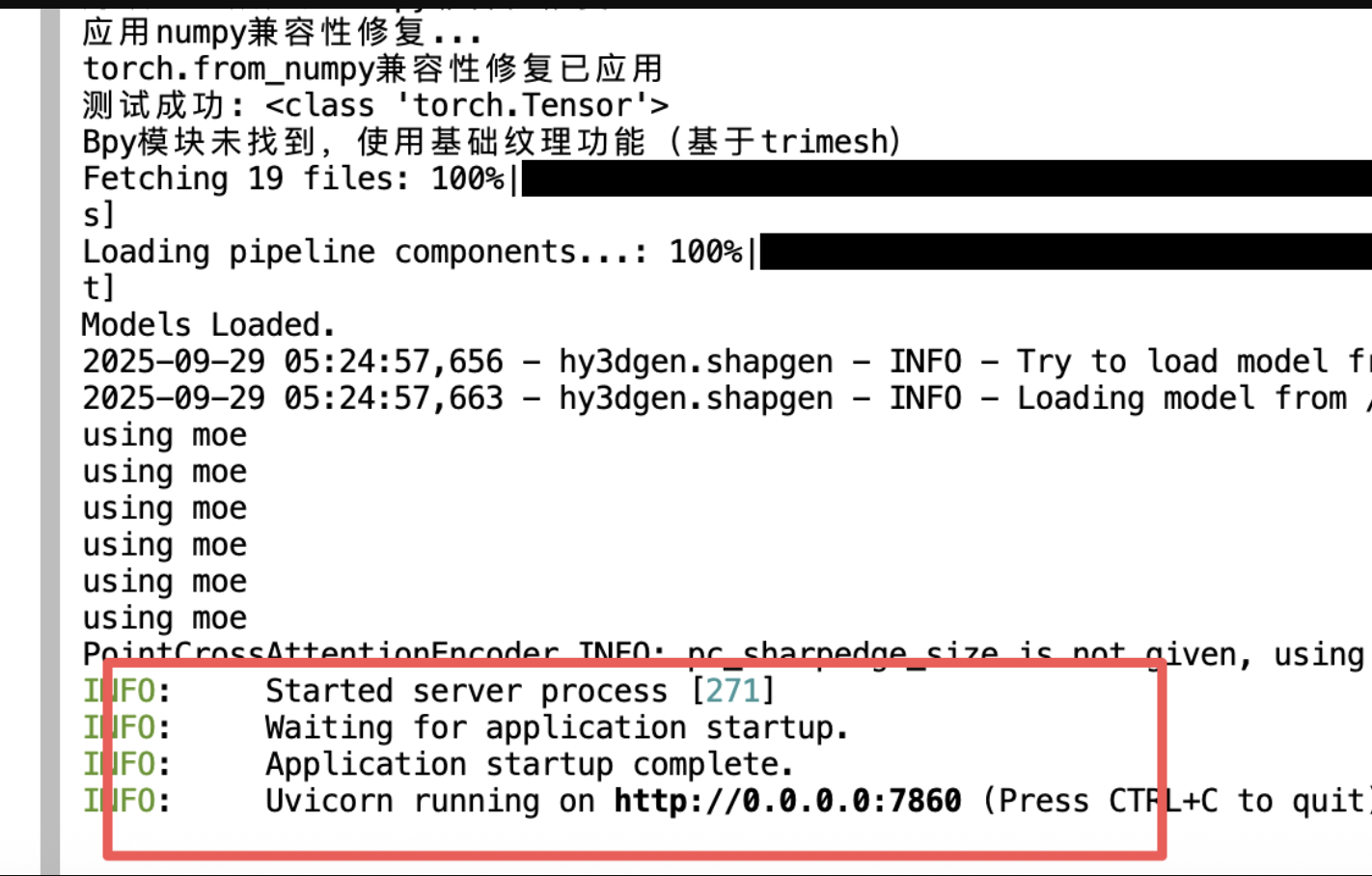
6、返回控制面板打开“SD-WebUI”
- AI数字人直播卖货欢迎来了解: https://kege-aigc.feishu.cn/docx/G271dgZr1o8CvMx9KKrcRuuonDf
以上都是镜像运行打开操作的一般步骤
优其他使用报错问题加群咨询
更多高级指令,可以进入jupyterlab,自行操作,例如:
- 查看进程:
ps -ef |grep python
- 终止进程:
kill -9 pid
- 重启程序:
cd /root && bash run.sh
- 官方更新源码在这里:
有bug请微信科哥或加群: 312088415
科哥在UCloud镜像列表【不断更新中】:
One-to-All Animation - 用户使用手册
简介
One-to-All Animation 是一个基于单张参考图像生成角色动画的系统。通过上传参考图像和驱动视频,系统会根据驱动视频的姿态,生成与参考图像角色相匹配的动画视频。
快速开始
1. 启动服务
bash start_app.sh
等待服务启动完成(首次启动约需 1-2 分钟加载模型),浏览器访问:
- 本地访问: http://localhost:7860
- 远程访问: http://服务器IP:7860
- 源码地址: https://github.com/ssj9596/One-to-All-Animation
2. 界面概览
WebUI 分为左右两栏:
- 左侧: 输入设置区
- 右侧: 输出预览区
使用流程
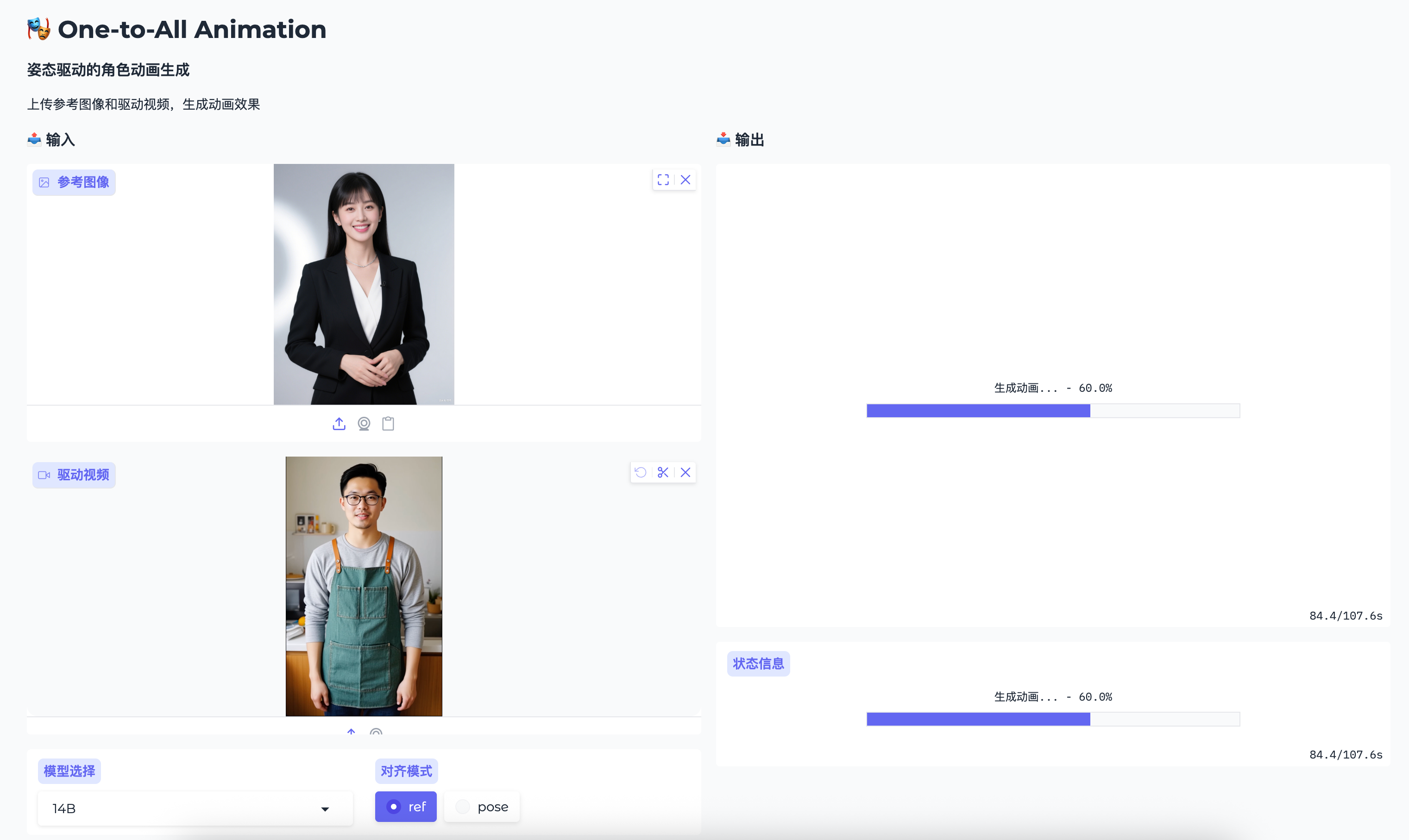
步骤 1: 上传文件
1.1 参考图像
- 作用: 提供角色的外观和身份
- 要求:
- 格式: PNG, JPG, JPEG
- 建议: 人物清晰、正面或半侧面、背景简洁
- 大小: 建议 512x512 以上
1.2 驱动视频
- 作用: 提供动作姿态序列
- 要求:
- 格式: MP4, AVI, MOV 等常见格式
- 时长: 建议不超过 10 秒
- 帧率: 建议 30fps
步骤 2: 选择模型
| 模型 | 特点 | 适用场景 | 显存占用 |
|---|---|---|---|
| 1.3B-v2 | 速度快 | 日常使用、快速预览 | ~15 GB |
| 1.3B-v1 | 备用版本 | 兼容性测试 | ~15 GB |
| 14B | 质量高 | 精品制作、最终输出 | ~50 GB |
💡 提示: 首次使用建议选择 1.3B-v2 模型
步骤 3: 选择对齐模式
| 模式 | 说明 | 效果 |
|---|---|---|
| ref | 参考图像对齐 | 保持参考图像中人物的身份特征 |
| pose | 姿态对齐 | 更好地保持驱动视频的姿态细节 |
💡 推荐: 默认使用
ref模式
步骤 4: 加载模型
点击 "🔄 加载模型" 按钮,等待提示 "✅ 模型加载成功"
⚠️ 注意: 模型只需加载一次,生成多个视频时无需重复加载
步骤 5: 调整参数
5.1 CFG (Classifier-Free Guidance)
Image CFG (图像引导强度)
- 范围: 0 - 5
- 默认: 2.5
- 作用: 控制生成结果与参考图像的相似度
- 值越高: 越像参考图像
- 值越低: 创意越多,可能偏离参考
Pose CFG (姿态引导强度)
- 范围: 0 - 5
- 默认: 1.5
- 作用: 控制生成结果与驱动姿态的贴合度
- 值越高: 动作越接近驱动视频
- 值越低: 动作更自由
💡 推荐组合:
- 保守: Image CFG 2.5 + Pose CFG 1.5
- 激进: Image CFG 3.5 + Pose CFG 2.0
5.2 推理步数
- 范围: 10 - 50
- 默认: 30
- 说明:
- 10 步: 快速预览 (约 5 分钟)
- 30 步: 平衡质量 (约 14 分钟)
- 50 步: 最佳质量 (约 23 分钟)
5.3 最大帧数
- 范围: 16 - 161
- 默认: 81
- 说明:
- 16-49 帧: 短视频 (~1-2 秒)
- 81 帧: 标准 (~2.7 秒)
- 161 帧: 长视频 (~5.3 秒)
5.4 长视频生成
勾选 "启用长视频生成 (Token Replace)" 后:
- 超过 81 帧的视频会自动分块生成
- 每块 81 帧,重叠 5 帧保证连贯性
- 生成时间成倍增加
⚠️ 注意: 长视频生成需要更多显存和时间
5.5 文本提示 (可选)
- 作用: 用文字描述想要的生成效果
- 示例:
- "一个人在跳舞"
- "高质量,细节丰富"
- "电影级画面"
步骤 6: 生成动画
点击 "🎬 生成动画" 按钮,等待生成完成。
生成过程:
- 预处理 (10-30 秒): 提取姿态、生成缓存
- 生成 (5-23 分钟): 根据步数而定
- 保存 (5-10 秒): 保存输出视频
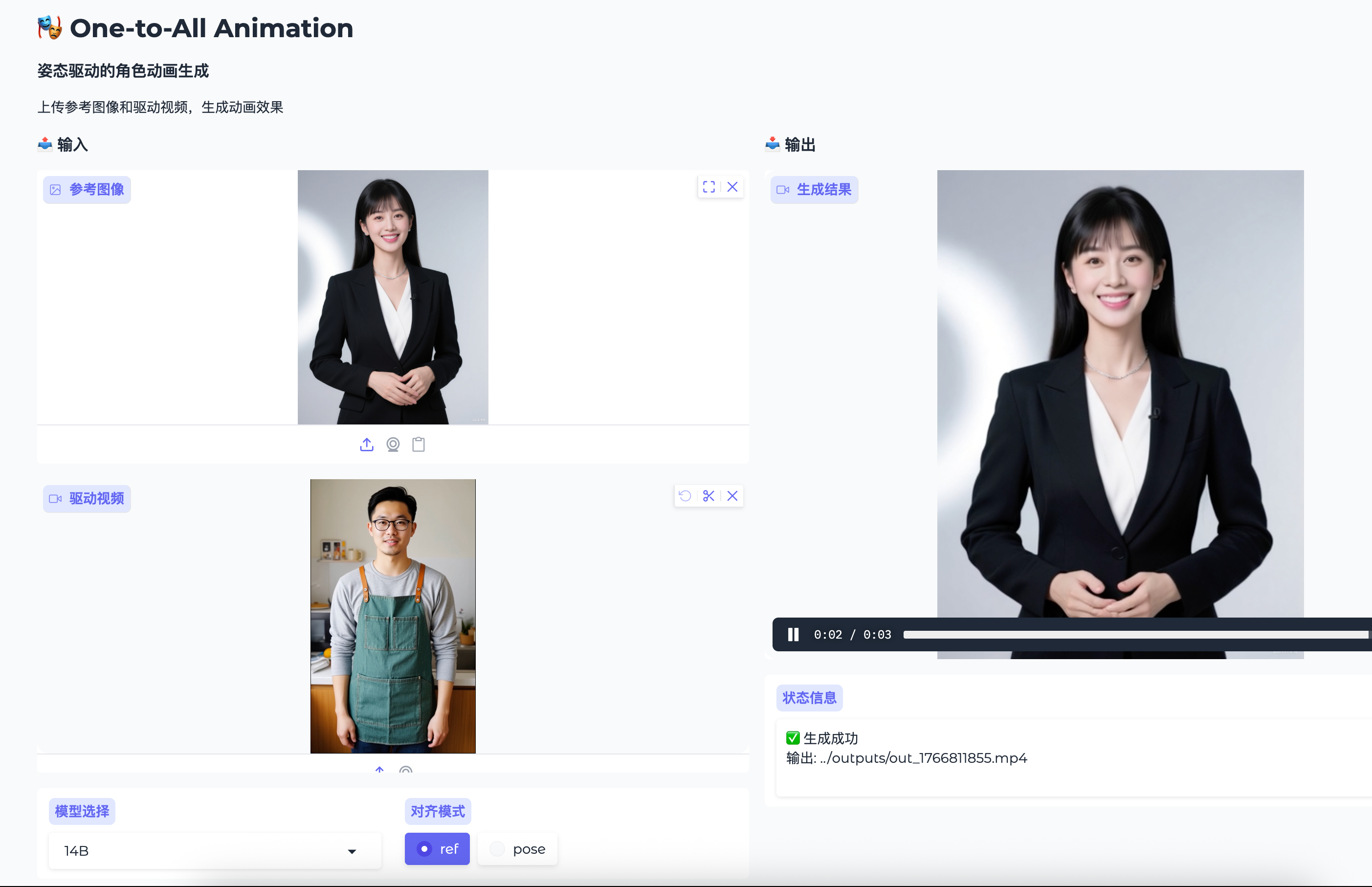
步骤 7: 查看结果
生成完成后:
- 右侧会显示生成的视频预览
- 状态栏会显示输出文件路径
- 视频保存在
outputs/目录
高级用法
1. 批量生成
使用相同参考图像,多个驱动视频:
- 上传参考图像
- 加载模型一次
- 依次上传不同驱动视频并生成
2. 调整分辨率
预处理会自动计算分辨率:
- 最大短边: 768 像素
- 自动裁剪为 16 的倍数 (VAE 要求)
- 最终分辨率由参考图像宽高比决定
3. 使用外部缓存
如果已运行过预处理,可以:
- 将缓存文件复制到
input_cache/目录 - 直接进行生成,跳过预处理步骤
参数调优指南
场景 1: 追求相似度
目标: 让生成结果尽可能像参考图像
推荐设置:
Image CFG: 3.5 - 4.5
Pose CFG: 1.0 - 1.5
推理步数: 30 - 50
对齐模式: ref
场景 2: 追求动作准确性
目标: 让动作尽可能接近驱动视频
推荐设置:
Image CFG: 2.0 - 2.5
Pose CFG: 2.5 - 3.5
推理步数: 30 - 50
对齐模式: pose
场景 3: 快速预览
目标: 快速查看效果
推荐设置:
Image CFG: 2.5
Pose CFG: 1.5
推理步数: 10
最大帧数: 16 - 49
场景 4: 长视频生成
目标: 生成 5 秒以上视频
推荐设置:
Image CFG: 2.5
Pose CFG: 1.5
推理步数: 20 - 30
最大帧数: 120 - 161
启用 Token Replace: ✅
常见问题
Q1: 生成结果面部模糊怎么办?
A: 尝试以下方法:
- 提高推理步数到 40-50
- 增加 Image CFG 到 3.0-3.5
- 确保参考图像人物面部清晰
- 使用 14B 模型获得更好效果
Q2: 动作不够自然怎么办?
A: 尝试以下方法:
- 增加 Pose CFG 到 2.0-2.5
- 切换到
pose对齐模式 - 确保驱动视频动作清晰流畅
- 减少最大帧数避免长视频累积误差
Q3: 生成速度太慢怎么办?
A: 可以:
- 降低推理步数到 10-20
- 减少最大帧数
- 使用 1.3B 模型而非 14B
- 使用较短的驱动视频
Q4: 显存不足怎么办?
A: 可以:
- 减少最大帧数
- 降低推理步数
- 使用 1.3B 模型
- 重启服务释放显存
Q5: 如何获得最佳质量?
A: 建议:
- 使用 14B 模型
- 推理步数设为 40-50
- Image CFG: 2.5-3.0
- Pose CFG: 1.5-2.0
- 使用高质量参考图像和驱动视频
输出文件说明
文件命名
输出视频保存在 outputs/ 目录,文件名格式:
out_{unix_timestamp}.mp4
例如: out_1735250123.mp4
查找最新输出
# 按时间排序查看
ls -lt outputs/
# 查看最新文件
ls -lt outputs/ | head -2
快捷操作
刷新模型
如果需要切换模型:
- 选择新模型
- 点击"加载模型"
- 旧模型会自动卸载
清理缓存
预处理缓存保存在 input_cache/ 目录:
# 查看缓存大小
du -sh input_cache/
# 清理缓存 (谨慎操作)
rm -rf input_cache/*
技巧提示
📌 参考图像选择
推荐:
- 人物居中、正面或半侧面
- 光线均匀、背景简洁
- 分辨率 512x512 以上
- 人物占画面 50% 以上
避免:
- 严重遮挡
- 模糊不清
- 过度侧脸
- 复杂背景
📌 驱动视频选择
推荐:
- 动作清晰流畅
- 人物姿态完整可见
- 时长 3-10 秒
- 帧率 30fps
避免:
- 快速运动导致模糊
- 频繁遮挡
- 过度复杂的动作
- 时长过长
📌 参数调整策略
渐进式调优:
- 先用默认参数生成
- 根据结果微调一个参数
- 对比效果后再调整下一个
- 记录有效的参数组合
示例工作流
示例 1: 人物舞蹈视频
1. 上传人物照片 (正面清晰)
2. 上传舞蹈视频 (3-5 秒)
3. 选择 1.3B-v2 模型
4. 对齐模式: ref
5. Image CFG: 2.5
6. Pose CFG: 1.5
7. 推理步数: 30
8. 最大帧数: 81
9. 点击生成
示例 2: 长视频生成
1. 上传参考图像
2. 上传 8-10 秒驱动视频
3. 选择 1.3B-v2 模型
4. 最大帧数: 161
5. 启用 Token Replace: ✅
6. 推理步数: 20
7. 点击生成 (预计 20-30 分钟)
示例 3: 快速预览
1. 上传参考图像
2. 上传驱动视频
3. 推理步数: 10
4. 最大帧数: 49
5. 点击生成 (预计 5 分钟)
注意事项
-
首次使用: 首次启动需要下载/加载模型,请耐心等待
-
模型切换: 切换模型需要重新加载,约需 1-2 分钟
-
生成时间: 生成时间与步数、帧数成正比,请合理安排
-
显存管理: 生成过程中请关闭其他占用显存的程序
-
保存结果: 生成结果自动保存在
outputs/目录,请注意备份 -
网络访问: 如需外网访问,使用
--share参数启动
运行使用界面截图
联系与反馈
如有问题或建议,请:
- 查看日志文件:
output_test/目录 - 检查错误信息
- 记录复现步骤
最后更新: 2025-12-27
bug反馈可以加入科哥专属群交流➕ 广告勿进!

 认证作者
认证作者
 支持自启动
支持自启动